基于改进YOLACT实例分割网络的人耳关键生理曲线提取
2022-07-12张晓爽
袁 立,夏 桐,张晓爽
北京科技大学自动化学院,北京 100083
人耳作为一种重要的生物特征,对人耳的形态分析和归类对与人耳相关的医疗等工作有着重要的价值.但是由于人耳形态结构复杂,外耳形态结构分型的研究至今难有一个统一标准的分类方法.杨月如与吴红斌[1]从医学角度提出外耳形态分型,依据外耳轮的形态特征以及耳轮结节的形态,将外耳分为六种形态.齐娜等[2]从声学角度分析,主要依据耳甲艇和耳甲腔的连通状态把耳廓分为四大类.耳垂在整个外耳形态中具有非常重要的作用,耳垂形状的不同可以引起视觉上明显的差别感,Azaria等[3]则根据耳垂与面颊交叉点角度对耳垂进行归类.上述研究者分别通过人耳的其中一块关键区域进行分类,这些区域都是人耳结构的重要组成部分,通过提取出耳轮、对耳轮和耳甲等关键区域的轮廓作为人耳的关键曲线,就能够实现对这些关键区域的精细划分,并且描述出它们的形状特征.提取出高精度的人耳的关键曲线进而能够有效的帮助完成对人耳的形态分析和聚类工作,同时也有助于实现人耳外轮廓提取和重要区域的分割.但是,人耳图像在颜色分布上较为一致,部分人耳在重要区域之间的过渡不明显,采集图像时还可能存在光照差异,这些因素都会导致传统边缘提取的方法在提取人耳关键曲线上适应性较差.
在图像分割领域中,语义分割[4-8]任务旨在实现对图像中的每个像素都划分出对应的类别,王志明等[9]提出一种分阶段高效火车号识别算法,而实例分割[10-12]不但要进行像素级别的分类,还需在具体的类别基础上区分该像素属于该类别中的具体实例.Bolya等[13]在2019年提出了实时实例分割网络YOLACT,类比Mask R-CNN[14]之于Faster R-CNN[15],YOLACT是在目标检测分支上添加一个语义分割分支来达到实例分割的目的,但没有使用区域建议网络[16-17].由于语义分割会对像素属性相似的像素点划为同一类别,而人耳区域像素值很相似,部分人耳在重要区域之间的过渡不明显,故语义分割方法不适用于人耳上关键生理曲线区域的分割.
因此,本文提出一种改进YOLACT算法来进行人耳关键区域分割,并提取耳轮、对耳轮和耳甲的关键曲线.为了提高定位和分割精度,将主干网络由ResNet101[18]更换为ResNeSt101[19],并在预测阶段摒弃原有的裁剪模板的处理,设计了新的筛选模板的结构,保证了分割区域边缘的完整性,提高了曲线检测提取精度.
1 基于ResNeSt和筛选模板策略的改进YOLACT算法
提出的改进YOLACT模型用来提取人耳的耳轮、对耳轮和耳甲区域的关键生理曲线,系统框图如图1所示.首先使用主干网络ResNeSt-101结合特征金字塔网络(Feature pyramid networks,FPN)[20]获取不同尺寸下的特征图,接下来特征金字塔提取的特征图传输进两个并行分支.第一个分支接收特征金字塔生成的所有尺寸的特征图作为输入,用来完成目标检测任务预测目标位置、类别,同时也完成对模板叠加系数的预测;第二个分支接收特征金字塔获取的感受野为91的特征图(对应图1中的P3)作为输入,用来生成一系列原型模板,实现对背景和前景的分离,对应第一个分支里的模板系数.通过YOLACT提出的快速非极大值抑制去掉多余的目标后,对原型模板和模板系数进行线性组合,得到每个实例对应的分割模板.上述组合得到的实例模板的过程可描述为:
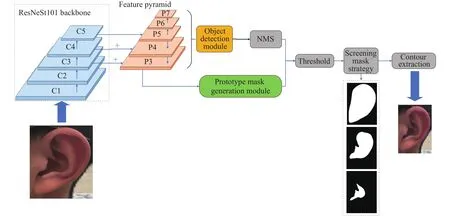
图1 改进YOLACT模型提取人耳关键生理曲线系统框图Fig.1 System block diagram of the improved YOLACT model for extracting the key physiological curves of the human ear

式中,P是分支一产生的一系列模板,维度为x×y×m,分别代表模板的高、宽和数量;C是分支二产生的模板系数,维度为n×m,n为经过快速的非极大值和分数阈值后的实例数量.为了简化网络结构和加快检测过程,使用线性组合的方式得到实例模板.最终得到模板的尺寸为x×y×n,也就是预测出的n个实例模板.在阈值化之后,使用本文提出的模板筛选策略排除实例模板中的误检.对得到的最终实例模板提取其外轮廓即可得到人耳的关键生理曲线,进而可以实现关键区域分割.以下针对系统中的关键模块ResNeSt主干网络、原型模板生成模块、目标检测模块、筛选模板策略等进行详细论述.
1.1 ResNeSt主干网络
原始YOLACT中的主干网络是ResNet,ResNet是为了完成图像分类任务,缺少针对目标检测、语义分割和实例分割等计算机视觉任务的相应结构设计,为此ResNeSt在ResNet的基础上设计了拆分注意力模块,而利用ResNeSt作为主干网络的模型能够在图像分类、目标检测、语义分割以及实例分割等任务上达到更高的精度[19].
ResNeSt模块在外层设计上保留了ResNet的跳跃映射连接,延续ResNeXt[21]分组卷积的思想,使用了基数的概念,按照基数的设置,将ResNeSt模块输入按通道拆分成k份输送到k个相同的网络结构,每个网络结构被称作一个是Cardinal,如图2(a).分组卷积的显著优势就是使用少量的参数量和运算量生成更多的特征图,更多的特征图就可以编码更多的特征信息.所以ResNeSt模块外层设计使得ResNeSt相比于其他ResNet变体[22-24],能够在不明显增加参数量级的情况下提升了模型的准确率.

图2 拆分注意力模块结构[19].(a) 整体结构; (b) cardinal内部结构Fig.2 Split attention module structure[19]: (a) entire frame; (b) cardinal internal structure
每个Cardinal的内部结构如图2(b)所示,结构设计主要借鉴了SENet[22]中的基于通道注意力机制的思想和SKNet[23]中的基于特征图注意力机制思想,能够学习出不同特征图之间重要程度以及特征图不同通道之间的重要程度,利于获取更加有效的信息.ResNeSt模块每个Cardinal的大致结构类似于SKNet注意力机制模块,不同之处在于每个分支使用相同尺寸的卷积核,便于外层分组卷积的模块化.
故本文利用ResNeSt对原始YOLCAT网络中的主干网络进行改进,使用ResNeSt101代替ResNet-101嵌入到YOLACT网络,并与YOLACT的特征金字塔结构进行对接,提取出ResNeSt101每个阶段的最后一个ResNeSt模块的输出,选中感受野分别为91、811、971的三层特征图(分别对应图1中的C3、C4、C5)输送到特征金字塔结构参与后续运算.
1.2 原型模板生成模块
原型模板生成模块分支是YOLACT生成语义分割模板的分支,用来实现像素级别的分类任务,原型模板生成模块分支的作用并不是直接生成最终的像素分类模板,而是生成一系列原型模板,在后续阶段用于组合生成整幅图最终的分割模板.原型模板生成模块的网络结构基于FCN[25]设计,以550像素×550像素的输入图像为例的原型模板生成模块网络结构如图3所示,接收主干网络获取的感受野为91的特征图作为输入,首先不改变特征图尺寸和通道数连续使用了3个卷积核大小为3×3步长为1的卷积层,然后利用双线性插值的方式进行了上采样,使得特征图尺寸达到原图尺寸的1/4,提高了后续生成原型模板的分辨率,也就提高了分割模板整体的质量以及对于小目标的分割精度,保持当前尺寸紧接着通过两个卷积层获得一个m通道的输出,输出中的每一个通道就是一个原型模板.
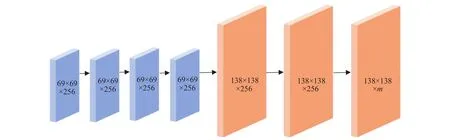
图3 原型模板生成模块Fig.3 Prototype mask generation module
1.3 目标检测模块
目标检测分支以主干网络生成的所有尺寸的特征图作为输入,每个尺寸的特征图都通过相同的网络结构进行处理,图4以感受野为91的特征图为例展示了目标检测分支的网络结构.首先通过一个公共的步长为1的3×3卷积层,公共卷积层的存在使得网络结构利用更高效,运算速度更快,接下来分成3个分支,分别通过一个卷积层预测目标的位置、类别和分割模板.网络在每个位置上设置[0.5,1,2] 3种比例的锚框来检测位置,并且针对特征金字塔生成的5种不同尺寸的特征图设置5种不同的尺寸的锚框.最终目标检测分支针对特征金字塔生成的特征图上每个位置的锚框都预测4个表示位置的参数,d个代表目标类别的参数以及与原型模板个数相对应的m个组合系数.在模板加权组合系数的分支上,补充了一个tanh激活函数,tanh的值域覆盖了正负值,保证在输出的加权系数中存在正负值.
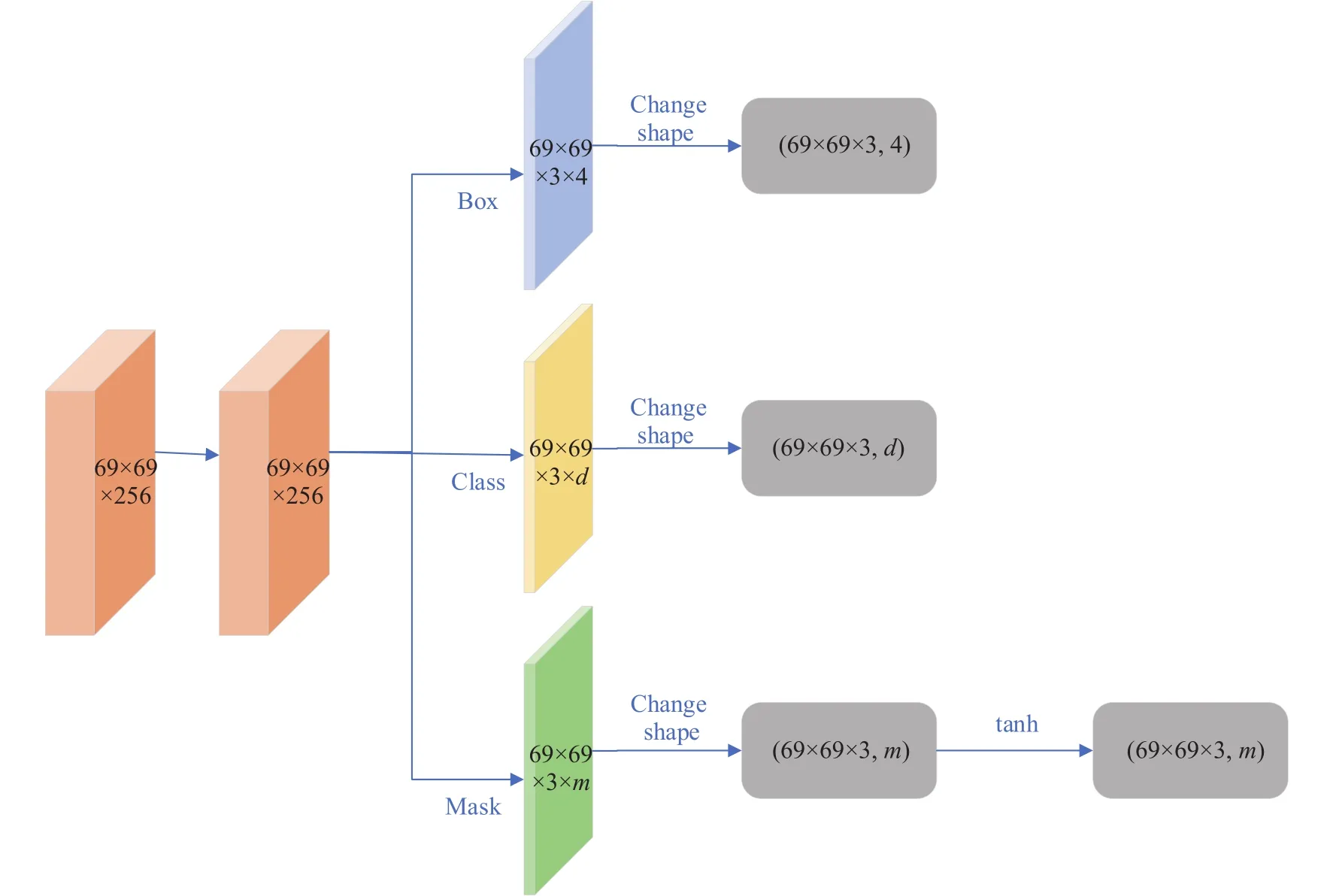
图4 目标检测模块Fig.4 Object detection module
1.4 “筛选模板”策略
YOLACT为了改善小目标的分割效果,在预测时使用目标预测框对加权组合产生的模板进行裁剪,在训练时对真实的边界框进行裁剪,仅保留目标预测框内的分割结果,且并未对输出的结果进行去噪.这样一来,当目标预测框准确的时候,没有什么影响,但是当目标预测框不准确的时候,噪声将会被带入实例模板,造成一些“泄露”(意即目标预测框内含有其他实例的一部分,但这部分被识别为当前实例的情况).当两个目标离得很远的时候也会发生“泄露”的情况,因为裁剪的过程会将当前实例模板的学习内容限定在预测边界框内,裁剪相当于告诉网络远处的目标已经被排除在外了,不用网络去学习.但是假如目标预测框很大,那么该预测模板将包括那些离得很远的实例的一部分模板,这部分模板对于网络来讲就是噪声,网络并不知道应该将这部分模板与当前实例预测模板分开,就造成了“泄露”.在目标预测框比实际边界框偏小的情况下,使用目标预测框对合成模板裁剪就会破坏原有合成模板边缘的完整性,部分分割区域被切割掉之后分割出的模板会出现直线边缘,使模板的质量下降,在图5(a)原图上使用“裁剪模板”策略的效果如图5(c)所示.
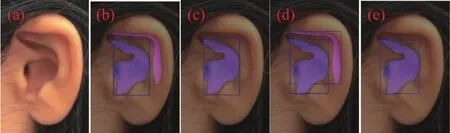
图5 模板处理.(a) 原图; (b) 边框和模板预测结果; (c) 裁剪模板结果;(d) 各区域外接矩形; (e) 筛选模板结果Fig.5 Mask processing: (a) original image; (b) prediction of boxes and masks; (c) segmentation result with the cropping mask strategy; (d)bounding boxes of different regions; (e) segmentation result with the screening mask strategy
针对这一问题,本文在使用YOLACT进行推理时,去掉了原网络中的“裁剪模板”结构,但是去掉裁剪模板结构后,在推理分割模板中会出现多余的误检区域,如图5(b)所示.YOLACT预测的检测框和模板是一一对应的,并且在检测框检测准确的情况下,模板中对应该实例的分割区域应该在检测框内,基于这一特点,为去掉误检区域,本文提出了“筛选模板”策略,表达式为:

式中,av表示预测模板中第v个独立分割区域,abv表示第v个独立分割区域形成的外接矩形框.筛选模板策略中首先对于预测模板中的每个独立区域u都生成外接矩形如图5(d)所示,然后依次计算预测模板对应的预测边界框pb与每个独立区域外接矩形abu之间的交并比值,利用算出的最大的交并比对应的独立区域生成一个新的模板代替原来的模板如图5(e)所示,这样得到的模板边缘完整精确,并且没有误检区域.
1.5 损失函数和评价指标
在网络训练时使用了4种损失函数训练模型,分别是类别置信度损失Lc、目标预测框损失Lb、模板损失Lm以及语义分割损失Ls.总损失公式如下:
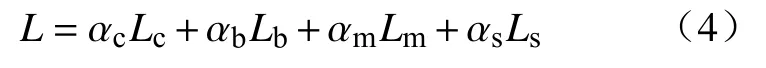
式中,α代表各自损失在叠加时的权重.在YOLACT网络中,权重的预设值为αc=1,αb=1.5,αm=6.125,αs=1.其中类别置信度损失和目标框损失采用和SSD[26]算法中一样的计算方式.
类别置信度的损失计算公式为:
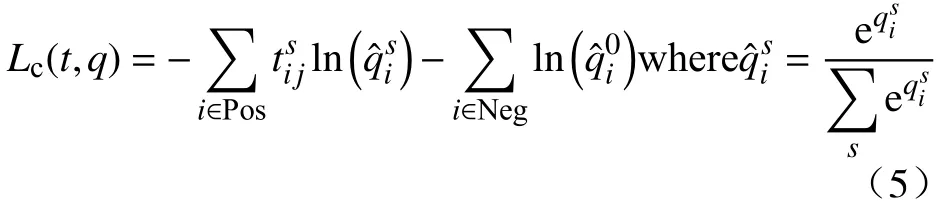
类别置信度损失是多类别置信度的softmax损失,其中,q表示多类别置信度,Pos表示正例,Neg表示反例,i表示预测框的编号,j表示真实目标框的编号,s表示类别序号,其中背景的序号为0,是一个指示参数,取值只有0或者1,取值为1时表示预测框和类别号为s的真实目标框匹配.
目标预测框损失的计算公式为:

预测框损失采用的是 SmoothL1损失,其中,i表示预测框的序号,j表示目标框的序号,l表示边界框的预测值,g表示目标边界框的真值,xc、yc、f和o分别表示默认边界框的中心点横纵坐标、宽度和高度,的含义和类别置信度相同,所以预测框损失仅针对正样本进行计算.其中 SmoothL1函数的计算公式为:
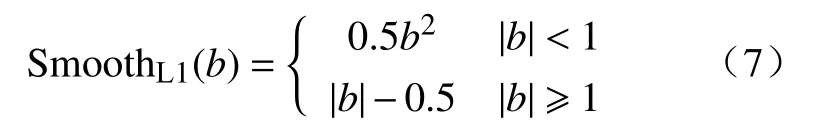
SmoothL1损失在预测值和目标值偏差较大的时候使用了绝对值进行计算,梯度值为1,可以防止梯度爆炸,对离群值和异常值不敏感,更加鲁棒.在偏差较小时,损失使用了平方进行计算,保证模型收敛的精度.
模板损失是通过计算加权组合后的模板与真实模板之间的二分类交叉熵,计算公式为:
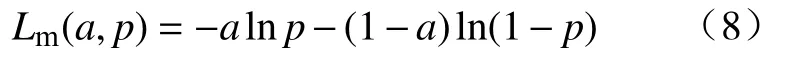
式中,a表 示网络的预测模板中类别的真值,p表示预测模板中预测正确的概率.
语义分割损失项是为了弥补快速非极大值抑制算法带来的精度下降,在训练时添加额外损失可以在不影响速度的情况下提高特征的丰富性.具体做法是在特征金字塔的感受野为91的特征图后增加一个d通道1×1的卷积层,在输出的d通道的特征图上再计算二分类交叉熵损失.在计算完损失后,采用带动量的SGD优化算法,弥补梯度下降的缺陷,加快训练速度.
对于YOLACT的模型性能,本文使用平均准确率(mean Average precision,mAP)来进行评估.AP是基于PR(Precision-recall)曲线计算得来的,PR曲线是以准确率为纵轴,召回率为横轴画出的曲线,AP值就是PR曲线下的面积.在实际应用中,并不直接对该PR曲线进行计算,而是对PR曲线进行平滑处理.即对PR曲线上的每个采样点的准确率值取该点右侧最大的准确率的值.本文采用了COCO[27]数据集的评估方式,为了提高精度,在PR曲线上采样了100个点进行计算.而且IOU的阈值从固定的0.5调整为在0.5 ~ 0.95的区间上每隔0.05计算一次AP的值,取所有结果的平均值作为最终的结果.通常来说AP是在单个类别下的,mAP是AP值在所有类别下的均值.
2 实验与分析
2.1 实验环境
采用Pytorch 1.2.0开源深度学习框架进行实验,操作系统为Windows 10,Python版本为3.7.4,实验采用的GPU型号为GeForce RTX 2080Ti S.
2.2 实验图像集
本文实验中使用的图像集来自于USTB-Hell oear图像库[28].该库采集于户外条件,采集了1570个体的视频,包括姿态、光照、遮挡等变化情况,每个被采集者可获得平均约400幅的左右耳图像,共约61万幅二维图像.
由于同一个体的左右耳结构基本相同,本文实验中随机选取1050个体,每人选取一幅左耳图像,不同个体间存在光照和姿态变化.为提取人耳关键曲线,每幅图像共标注耳轮、对耳轮和耳甲三类,拟提取的关键人耳关键曲线和标注示例如图6(a)~6(c)所示.
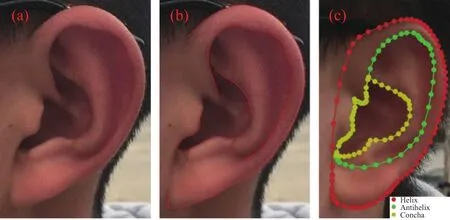
图6 图像集示例.(a) 原图; (b) 关键曲线; (c) 标注示例Fig.6 Image dataset: (a) original image; (b) key curves; (c) annotation examples
2.3 训练和测试结果分析
以下从模型精度和实时性两个方面将本文所述对YOLACT的两点改进与原始YOLACT模型进行比较,以此说明ResNeSt主干网络和“筛选模板”策略这两点改进的有效性.
2.3.1 模型精度的比较
实验中将所选1050幅左耳图像分成5份,每份210幅,采用5折交叉验证进行网络训练.改进YOLACT模型的训练超参数如表1所示,其中“max_size”表示输入网络的图像尺寸,默认输入图像尺寸为550像素×550像素,“lr_steps”表示训练过程中下学习率进行衰减的迭代轮数,“max_iter”表示训练的最大迭代轮数,“batch_size”表示同一批次处理的图像数量.

表1 训练超参数Table 1 Training hyperparameters
本文所述改进YOLACT模型训练中的损失曲线如图7所示,横坐标使用训练次数Epoch,纵坐标分别是位置损失(Loss_box)、分类损失(Loss_cls)和模板损失(Loss_mask),从图中可以看出3种损失都呈现收敛的趋势.
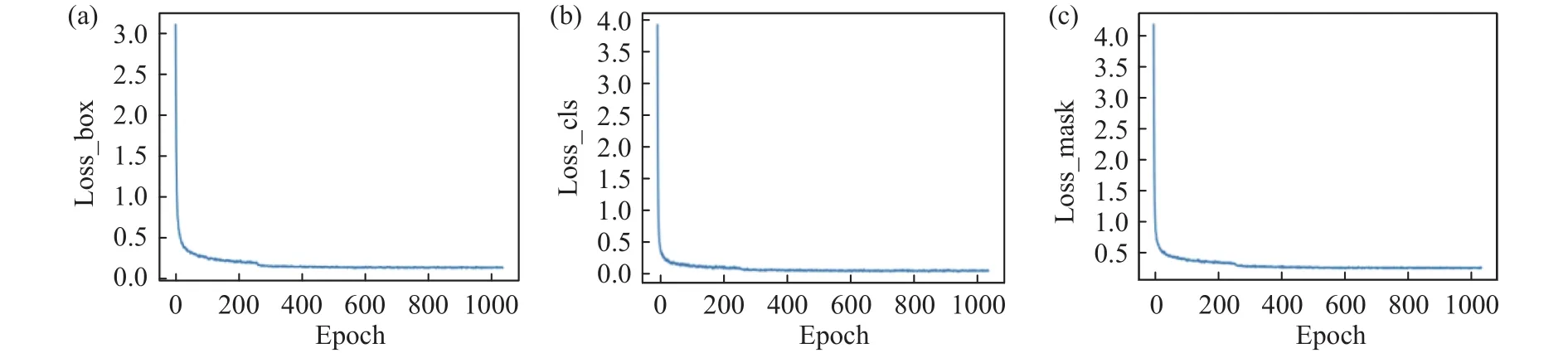
图7 损失曲线.(a) 位置损失; (b) 分类损失; (c) 模板损失Fig.7 Loss curves: (a) box loss; (b) class loss; (c) mask loss
在验证集上分别使用主干网络ResNet101+裁剪模板策略(YOLACT-ResNet101-crop)、主干网络ResNet101+筛选模板策略(YOLACT-ResNet 101-select)、主干网络ResNest101+裁剪模板策略(YOLACT-ResNest101-crop)、主干网络 ResNest101+筛选模板策略(YOLACT-ResNest101-select)4种方法得到的平均交并比(mIOU)和Dice系数(Dice coefficient)如表 2所示.改进 YOLACT模型在验证集上的模型精度如表3所示,其中“Box”代表目标检测的精度,“Mask”代表语义分割的精度.实验中设置不同IOU阈值为0.50、0.55、0.60、0.65、0.70、0.75、0.80、0.85、0.90、0.95,将不同阈值对应的mAP值进行平均得到模型的mAP_all,如表3第2列所示,表3第3列至第5列分别为IOU阈值为0.50、0.70、0.90的mAP值.综合表2、表3可以看出本文所述改进YOLACT模型的精度有所提高.
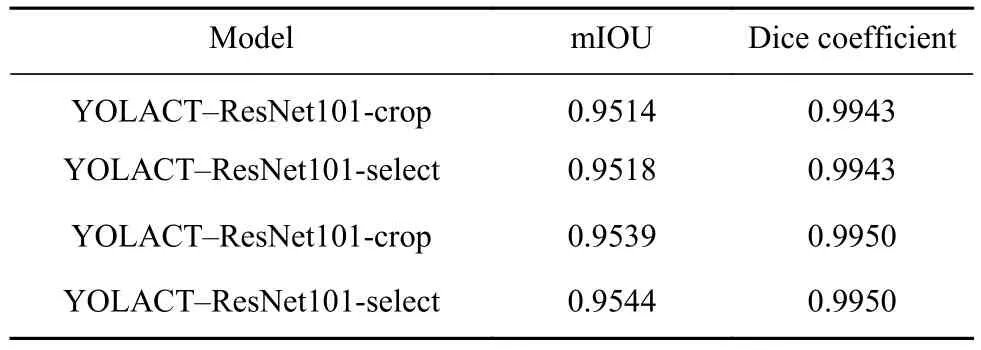
表2 不同YOLACT模型的分割精度Table 2 Segmentation accuracy of different YOLACT models
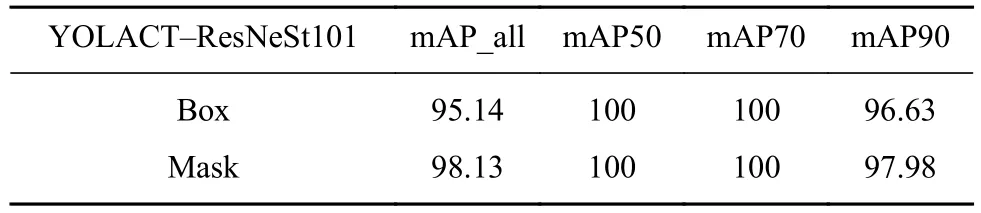
表3 YOLACT-ResNeSt101模型精度Table 3 Accuracy of the YOLACT-ResNeSt101 model %
使用YOLACT-ResNeSt101在410张未参与训练的图像上进行测试,分别使用原始YOLACT的裁剪模板和本文提出的筛选模板策略进行测试实验,在测试结果中分割的曲线基本贴合真实曲线的比例如表4所示,Accuracy表示410张图像中分割准确的张数.通过对比,可以看出:(1)将YOLACT主干网络由ResNet101更换为ResNeSt101后网络性能更佳;(2)筛选模板策略能够比原始的裁剪模板策略获得更高的准确率.

表4 模型改进前后提取关键曲线的准确率对比Table 4 Comparison of curve extraction accuracy before and after model improvement
本文在测试结果中使用不同颜色将不同实例模板中连通域的边缘标识在原图中,以此来判断连通域外轮廓是否贴合真实的曲线,选取具有代表性的测试结果图展示在图8中.

图8 不同人耳的分割结果.(a)裁剪模板的结果; (b)筛选模板的结果Fig.8 Segmentation results for different human ear: (a) cropping mask results; (b) screening mask results
从图8(a)中可以看出裁剪模板结果中出现多处直线边缘,这是由于预测的边界框偏小,将正确的分割区域裁剪去除了,从表2可以看出分割的模板的准确率相比于边界框的准确率更高,所以使用边界框裁剪反而会破坏准确率更高的模板的完整性.从图8(b)中可以看出,本文使用的筛选模板策略能够保证模板的完整性,准确率更高.
2.3.2 算法实时性比较
为判断本文所述两点改进是否影响YOLACT本身的实时性,本文使用410张未参与训练的图像进行测试,结果如表5所示,第三列表示410幅图像总共处理时长.通过对比,可以看出:将YOLACT主干网络由ResNet101更换为ResNeSt101后YOLACT本身的实时性稍有降低;将原始的裁剪模板策略更换为筛选模板策略对YOLACT本身的实时特性几乎没有影响.本文所述方法对于实时性要求不高或者仅处理图像的应用场合是没有影响的.
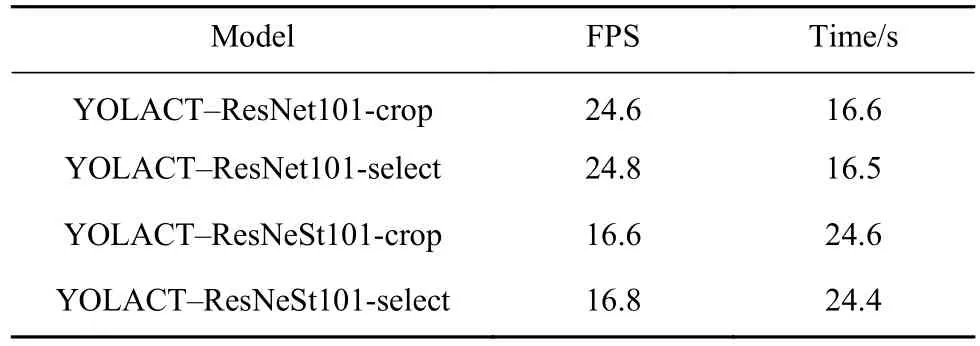
表5 模型改进前后实时性对比Table 5 Real-time performance before and after model improvement
2.4 本文方法与其他方法的比较
为了证明改进YOLACT模型在提取人耳关键曲线时与其他分割算法相比的优越性,选取上述图像集对DeepLabV3+ 模型进行五折交叉训练.两种模型的模型分割精度比较见表6.结果表明,改进的YOLACT模型比DeepLabV3+ 模型具有更高的分割精度.

表6 不同网络模型分割精度比较Table 6 Accuracy comparison of different segmentation models
图9展示了本文所述改进YOLACT模型、DeepLabV3+ 模型和使用传统轮廓估计的检测效果.可以看出,用改进的YOLACT分割出的模板边缘更接近于人耳的关键曲线,而用DeepLabV3+ 模型分割出的模板边缘与实际曲线有一定的偏离,使用传统轮廓估计检测的边缘很粗糙,无法将耳轮、对耳轮和耳甲3类分割出来.

图9 不同人耳三种方法的分割效果.(a) 原图; (b) 改进的YOLACT;(c) DeepLabV3+; (d) 传统轮廓估计Fig.9 Segmentation effect of three methods for different ears:(a) original image; (b) improved YOLACT; (c) DeepLabV3+; (d)traditional contour estimation
文献[29]应用两阶段卷积神经网络提取了6个人耳关键点,如图10所示.这种关键点检测的方法目前检测精度有待提高,且检测点数比较少,对于提取关键曲线的需求还需要进一步应用曲线拟合.由于不同个体之间人耳关键曲线的差异性,拟合结果不一定和真实曲线完全贴合,所以在提取关键曲线方面本文方法更具有优势.
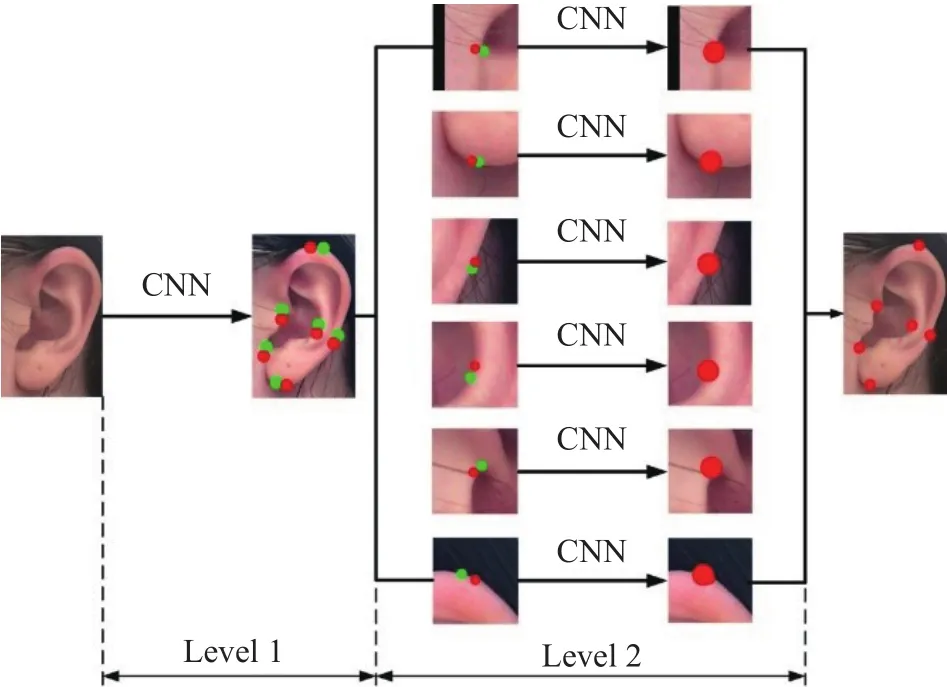
图10 两阶段卷积神经网络提取6个人耳关键点Fig.10 Two-stage convolutional neural network for extracting six key points of the human ear
3 结论
本文提出了一种基于ResNeSt和筛选模板策略的改进YOLACT算法来进行的人耳关键曲线提取方法.其中,将主干网络由ResNet替换为ResNeSt能够提升网络的整体性能,由筛选模板策略代替裁剪模块保证在边界框预测不准确的情况下分割区域的完整性.通过在所选人耳数据集上的实验表明,该方法能够得到较高精度的分割模板,并且模板的边缘更加贴近实际的关键人耳曲线.
