轻量化二维人体骨骼关键点检测算法综述
2022-07-11曾文献马月李伟光
曾文献, 马月, 李伟光
(河北经贸大学信息技术学院, 石家庄 050061)
人体骨骼关键点检测是计算机视觉中的一个重要任务,被广泛应用于运动辅助训练[1- 4],医疗辅助训练[5- 6]和行为识别[7-8]等。人体骨骼关键点检测是从图像或者视频中自动定位人体骨骼关节点,如肩膀,腕部等。目前主流的二维的人体骨骼关键点检测方法在性能和精确度方面都有了很大的提升,网络结构也变得更深更复杂,对运行设备的硬件环境提出了更高的要求。为了解决二维的人体骨骼关键点检测模型结构复杂、参数量和计算量庞大的问题,很多研究者将轻量化方法应用到人体骨骼关键点检测算法中,有效降低了网络参数量和计算量,使模型可以在资源有限的移动设备和嵌入式设备中运行,所以对深度神经网络模型进行轻量化设计是非常有必要的。针对人体骨骼关键点检测的研究很多,已有不少综述文章对二维的人体骨骼关键点检测进行总结,但缺少对轻量化二维的人体骨骼关键点检测算法研究的总结归纳。
为此,针对近几年有关轻量级网络的二维的人体骨骼关键点检测相关工作进行了分类对比,首先介绍了目前常用的人体骨骼关键点检测中常用的数据集、二维的人体骨骼关键点检测方法、轻量化网络结构,然后从二维骨骼关键点检测轻量化的手段进行深入分析,对比了轻量化方法在现有数据集上的效果,最后对当前研究进行了总结和展望。
1 人体骨骼关键点检测方法
二维人体骨骼关键点检测为人体行为检测和识别研究提供基础信息,其检测结果的准确率直接影响后续的应用。二维人体骨骼关键点检测主要可分为单人骨骼关键点检测和多人骨骼关键点检测。
1.1 人体骨骼关键点检测常用数据集
神经网络的发展为二维人体骨骼关键点检测效果带来显著提升,同时出现了许多针对特定场景和任务的人体骨骼关键点检测数据集。数据集的规模对于训练神经网络来说非常重要,数据集太小的话就会造成过拟合。主要介绍规模较大且在人体骨骼关键点检测研究中常用的数据集,如表1所示。
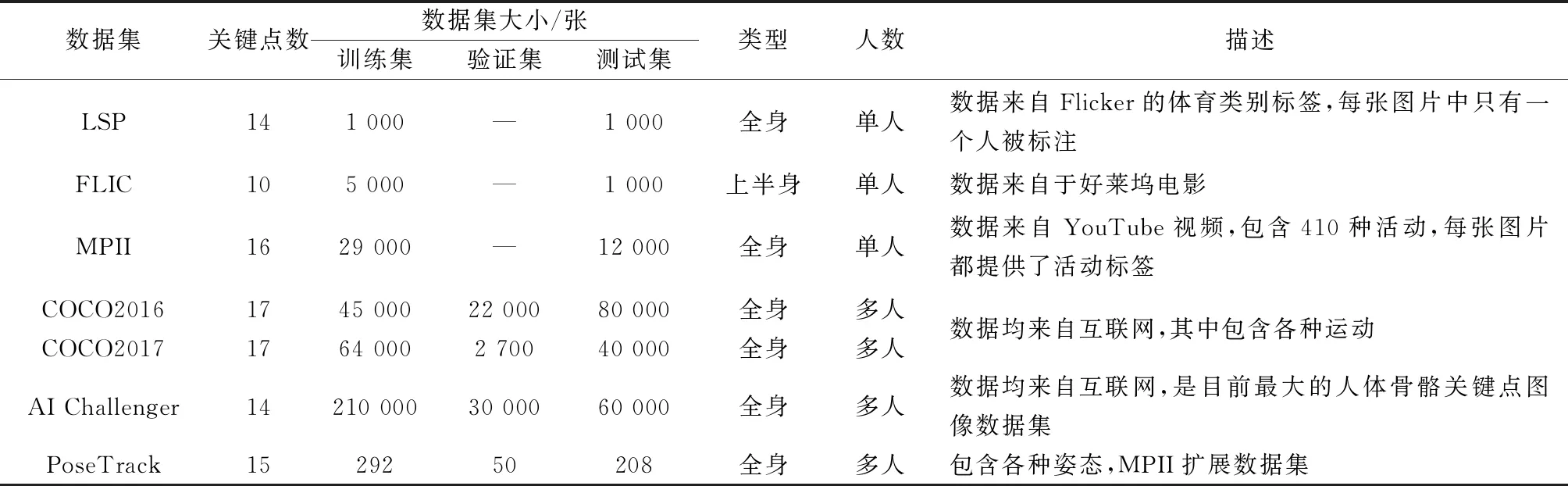
表1 常用人体骨骼关键点数据集
人体姿势估计已经研究了很多年,由于人类的姿势各不相同,很难为这项任务建立一个通用的数据集。为了逐步解决估计问题,数据集的数量和复杂性都在增加。早期的数据集[9]包含有相对简单背景的图像。随着深度学习的发展,这些数据集显然不能满足深度学习的训练条件,随后出现了基于深度学习的方法常用的数据集包括LSP[10]、FLIC[11]、MPII[12]、MSCOCO[13]、AI Challenger[14]和PoseTrack[15],它们包含更多更复杂场景的图像。LSP和FLIC数据集相对较小,只包含特定类别的活动。LSP数据集中的图像来自体育场景。FLIC数据集是从好莱坞电影中收集的。最新的数据集,如MSCOCO和AI Challenger,在规模和类别数量上都比较大。
1.2 二维单人骨骼关键点检测
二维单人骨骼关键点检测是对图像或视频中的给定的单人进行关键点检测,然后将关键点进行连接,形成人体骨骼。单人骨骼关键点检测方法大致可分为:①基于坐标回归的方法是通过一个端到端的网络框架学习从输入图像到人体骨骼关键点的信息;②基于热力图检测方法是先获得人体关键点的热力图,然后通过热力图推断关键点的位置。基于热力图的检测方法可用于复杂的场景的检测,具有较好的鲁棒性。如表2所示,梳理了二维的单人骨骼关键点检测算法对比。
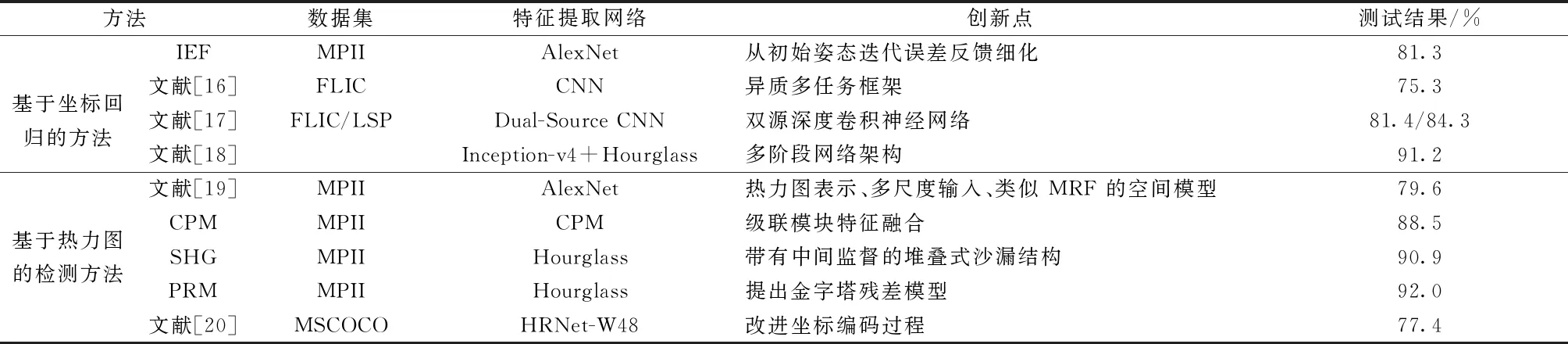
表2 二维单人骨骼关键点检测算法对比
1.2.1 基于坐标回归的方法
许多基于坐标回归的方法直接获得人体骨骼关键点,其框架图1所示。Toshev等[21]最先将深度学习应用到人体关键点检测,提出了可直接预测关键点坐标的级联回归器,并通过一系列回归方法检测出不可见和被遮挡的人体骨骼关键点,它的提出奠定了基于坐标回归方法的基础,也将人体关键点检测从传统方法转向使用卷积神经网络。随后,Carreira等[22]提出了一种迭代误差反馈网络(iterative error feedback,IEF),它是一个自我修正的模型,通过反馈误差预测,逐步改进预测的关键点位置。Sun等[23]提出了基于ResNet-50的结构感知回归方法,该方法没有采用关键点信息,而是利用身体结构信息来设计骨骼姿态信息,骨骼之间的相互作用通过一个损失函数进行编码。这种方法也可以推广到三维的人体关键点检测。对于基于坐标回归的方法来说获取一个具有丰富骨骼关键点信息的特征是非常重要的,可以提高骨骼关键点的预测能力。于是多任务学习方法被应用感到人体骨骼关键点检测。Li等[16]采用异质多任务框架来处理完整图像中的骨骼关键点预测任务。Fan等[17]提出了一个双源深度卷积神经网络,包含两个任务,一个是联合检测来确定补丁是否包含骨骼关键点,另一个任务是找到骨骼关键点的确切位置。 每个任务都对应一个损失函数,两个任务的结合可以优化结果。Luvizon等[18]学习了一个多任务网络来联合处理视频序列中的二维、三维骨骼关键点检测和动作识别。

图1 基于坐标回归的框架
1.2.2 基于热力图的检测方法
目前基于单人关键点检测大多采用基于热力图的检测方法,其框架如图2所示。该方法是通过检测K个骨骼关键点的热力图,每个关键点热力图中的像素值Li(x,y)表示关键点位于(x,y)的概率。骨骼关键点的真实热力图是由二维高斯模型[24]以真实关键点所在位置为中心产生的, 通过最小化预测热力图和真实热力图之间的差异来训练骨骼关键点检测网络。基于热力图的检测方法可以保留更多的空间位置信息,提供更丰富的监督信息。Tompson等[19]将基于CNN的身体部位检测器与基于部位的空间模型结合起来,形成一个统一的二维人体骨骼关键点检测学习框架。Lifshitz等[25]将图像离散为以骨骼关键点为中心的对数极坐标区,并采用VGG网络来预测每个成对骨骼关键点的类别置信度。根据相对置信度的分数,每个关键点的最终热力图可以通过反卷积网络生成。由于热力图表示比坐标表示更稳健,最近的研究大多是基于热力图表示。

图2 基于热力图的框架
采用多阶段细化迭代的方式来设计网络结构,可以有效提高网络预测的准确性。Wei等[26]提出了一个多阶段预测架构(convolutional pose machines,CPM)。CPM模型由多个Stage组成,经过多次优化,对关键点位置的预测越来越准确。CPM通过使用增大感受野的方式获得关键点之间的复杂度关联性,来解决关键点遮挡的问题。同样为了解决关键点遮挡的问题,Newell等[27]提出了级联沙漏网络模型(stacked hourglass module,SHG),该模型由多个Residual Module(残差模块)组成,每个Residual Module有两个通路:卷积路和短接路。Stacked Hourglass Network(堆叠沙漏网络)由四阶Residual Module组成,它捕获和整合所有尺度的信息,输入图像先经过从高分辨率下采样到低分辨率提取特征,然后再上采样从低分辨率到高分辨率进行特征融合,最后基于融合后的特征图输出关节点的热力图。Stacked Hourglass Network有效利用了不同层次的特征图包含不同级别的特征信息,实现对不同尺度的特征图像信息捕获和整合,解决了信息丢失问题。人体骨骼关键点的大小也给检测带来了一定的难度,Yang等[28]设计了一个多分支金字塔残差模块(pyramid residual module,PRM)来代替SHG的残差模块,以此增强了深度卷积神经网络尺度的不变性。PRM在多分支网络中采用不同采样率进行下采样获得不同尺寸的特征图,再通过上采样恢复到原来的分辨率。Zhang等[20]通过对标准坐标解码方法局限性的分析不仅提出了可感知的分布编码方法,同时生成了无偏模型训练的精确热力图分布,改进了标准坐标的编码过程。
1.3 二维多人骨骼关键点检测
由于输入图像中的人数不确定、关键点分组情况不确定,基于多人的关键点检测与单人的相比更加困难。根据多人骨骼关键点检测方法的相关研究大致将多人骨骼关键点检测分成两类:自顶向下(Top-Down)和自底向上(Bottom-Up)。Top-Down方法首先要利用目标检测算法检测出图像中所有人的位置,再使用单人的骨骼关键点检测方法提取出每个人的骨骼关键点。这种方法精度高但是检测实时性差,因为图像中的人数会直接影响检测速度。Bottom-Up方法先检测图像中人体的所有关键点,然后再对不同人体的关键点进行分组,得到最优分组。该方法的精度不高,关键点特征提取难度大,不能很好的解决遮挡问题,但是检测速度快、实时性好。如表3所示,梳理了二维的多人骨骼关键点检测算法对比。

表3 二维多人骨骼关键点检测算法对比
1.3.1 Top-Down方法
自上而下的骨骼关键点检测方法的两个最重要的组成部分是人体区域候选检测器和单人姿势估计器。人体检测器用于获得人体边界框,主要采用Fast-RCNN(fast regions with convolutional neural network)[31]、Faster-RCNN(faster regions with convolutional neural network)[32]、特征金字塔网络(feature pyramid network,FPN)[33]和Mask R-CNN(mask regions with convolutional neural network)[34-35]。Papandreou等[36]提出了一个两阶段的架构,利用Faster R-CNN作为人体检测器,为候选人体创建边界框和一个关键点估计器,通过使用一种热力图-偏移聚合的形式预测关键点的位置。针对多人骨骼关键点检测中常会出现的问题,如关键点被遮挡或重叠等,Chen等[37]提出了一个级联金字塔网络(cascaded pyramid network, CPN),从局部和全局特征中获取更多信息。网络包含两个部分:GlobalNet用来检测简单的关键点,如眼睛、手臂等容易检测的关键点;RefineNet通过整合多个感受野特征和GlobalNet获得的特征,将相同大小的特征图串联起来,用于检测难以识别的人体骨骼关键点。Golda等[38]通过探索优化拥挤场景下的人体骨骼关键点检测方法,提出了OccNet,该网络包含两个分支网络,以ResNet作为骨干网络。其中,遮挡网络(OccNet)为每个关键点位置生成两组热力图,可见关键点热力图和遮挡关键点热力图。遮挡网络交叉分支(OccNetCB)在经过一次转置卷积后分成连个分支,这两个分支可共享提取的信息。由于多人骨骼关键点检测网络模型普遍比较复杂,Xiao等[39]提出了一个简单又高效的网络Simple Baseline架构,在ResNet[40]结构上进行改进,去掉ResNet网络后面的全连接层,加入3个反卷积层和一个1×1的卷积层,将低分辨率的特征图还原输入分辨率,以生成人体骨骼关键点热图。
目前大多数人体骨骼关键点检测算法是将高分辨率特征降采样到低分辨率,然后从低分辨率特征图恢复到高分辨率,这个过程中会丢失高分辨率的特征信息,影响检测结果。为了在整个网络上保持高分辨率特征信息,Sun等[41]提出了一种具有多尺度特征融合的高分辨率网络(high-resolution networks, HRNet),HRNet采用并行网络结构,在保持高分辨率的同时,逐步将不同分辨率的特征网络并行连接,并在多分辨率子网之间进行信息交换,以获得更多的高分辨率信息来保证关键点位置的准确性。为了提高骨骼关键点定位的准确性,Wang等[29]提出了一个基于图和模型的两阶段框架,称为GraphPCNN。它包括一个定位子网以获得粗略的关键点位置,以及一个图形姿势细化模块以获得细化的关键点定位表示。Cai等[42]提出了一个新的网络结构-RSN(residual step network),RSN通过有效的内部特征融合策略学习精致的局部表征,有效保留了丰富的低层空间信息。此外还提出了一种高效的注意力机制-PRM(pose refine machine),PRM在输出特征的局部和全局表征之间平衡,进一步获得关键点位置。这种方法的检测精准度很好,但由于检测性能受检测任务中人体数量的影响,运算速度较慢,不适合用于实时检测。
1.3.2 Bottom-Up方法
自底向上的方法主要包含两个步骤,包括关键点检测和和候选关键点分组。该方法先检测图像中的所有关键点,然后将检测出来的候选关键点通过聚类的方式进行最优分组。由于Bottom-Up的方法受图像中人数增加的影响较小,检测速度不会随着人数增加而变慢,适合用于实时检测的场景。Pishchulin[43]将多人骨骼关键点检测问题转换为一个整数线性规划的问题,该方法采用Fast-RCNN进行人体部位检测,组成候选关节点密度图,然后将每个部位标记到其对应部位类别,最后用整数线性规划将这些部位组装成完整的骨架。由于Deepcut网络计算复杂度非常大,随后Insafutdinov[44]提出了Deepercut,为了解决Deepcut复杂度高的问题,通过使用ResNet更强大的身体部位检测器和更好的增量优化策略以及图像条件下的成对条件对身体部位进行分组,从而提高了检测性能和速度。
基于多阶段的卷积神经网络的方法,通过利用前一阶段的结果不断细化检测结果,进而提高骨骼关键点的检测精度。Cao等[45]提出了OpenPose网络,在CPM的基础上引入部位亲合场(part affinity fields,PAFs),其中PAFs是一个矢量场,用于编码四肢的位置和方向信息,以便将获取的人体关键点进行连接,得到不同的人体姿态。OpenPose在很大程度上提高了人体骨骼关键点检测的速度。Zhu等[46]基于OpenPose框架通过添加冗余边缘来增加 PAF 中关节之间的连接来改进 OpenPose 结构,并获得比基线方法更好的性能。尽管基于 OpenPose 的方法在高分辨率图像上取得了令人印象深刻的结果,但它们在处理低分辨率图像和遮挡的情况下表现不佳。与 OpenPose 类似,Kreiss等[30]设计了一个 PifPaf 网络来预测部位强度场 (part intensity fields,PIF) 和部位关联场 (part affinity fields,PAF) 来表示身体关节位置和身体关节关联。由于细粒度的 PAF 和拉普拉斯损失的利用,它在低分辨率图像上运行良好。Rizwan等[47]提出了一种利用编码掩码和关键点检测进行二维人体骨骼关键点检测的神经网络。该网络由连两个个阶段组成,第一阶段用于预测人的掩码,第二阶段包含两个分支,一个分支用于检测关键点的位置,另一个分支用于学习关键点之间的关系。在人体骨骼关键点检测阶段,利用掩码信息和相互连接关系检测人体骨骼关键点的位置热力图,并以此来获得最终的关键点位置。Bottom-Up方法处理速快,一些实时场景的应用均采用这种方法。
2 轻量化神经网络
随着深度学习和卷积神经网络的发展,研究者们提出了许多优秀的深度神经网络,如VGGNet、ResNet、GoogleNet等。
2.1 SqueezeNet
Landola等[48]研究了SqueezeNet,该网络采用非传统的模块化卷积(fire module),它由两部分组,如图3[48]所示,Squeeze层采用1×1卷积核,对上一层的特征图进行卷积,减少特征图的通道数,以达到减少运算量的目的。expand层采用1×1和3×3的卷积核,然后将结果进行级联,与VGG[49]的思想差不多。SqueezeNet与AlexNet[50]相比,参数量少50倍。
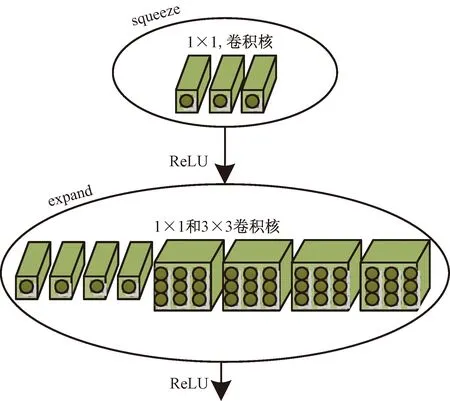
squeez为压缩层;expand为扩展层;ReLU为激活函数
2.2 MobileNet
Howard等[51]提出了MobileNetV1为轻量化网络的设计提供了新的思路,将标准卷积分两步进行,首先进行深度卷积,然后进行点卷积,结构如图4所示。MobileNetV1的计算量与GoogleNet[52]网络模型的运算量相比要少一个数量级。MobileNetV2[53]在MobileNetV1的基础上进行了改进,该网络引入线性瓶颈反残差结构(inverted residual with linear bottlenecks),并将点卷积后面的ReLU函数替换成线性函数。线性瓶颈反残差结构与残差结构不同,首先对输入进行升维,然后利用深度可分离卷代替标准的3×3卷积,再利用1×1的卷积降低维度,并使用线性激活函,避免对低维特征信息造成大量损失。随后,Howard等[54]提出了MobileNetV3,在ImageNet分类上,其精度比MobileNetV2提高了6%。MobileNetV3的主要创新点是:①用NAS[55]通过优化每个网络块来搜索全局网络结构,NetAdapt[56]执行局部搜索;②引入轻量级的通道注意力机制[57]和h-swish(x)激活函数;③将网络结构中最后一个平均池化层前移并且去掉了最后一个卷积层。
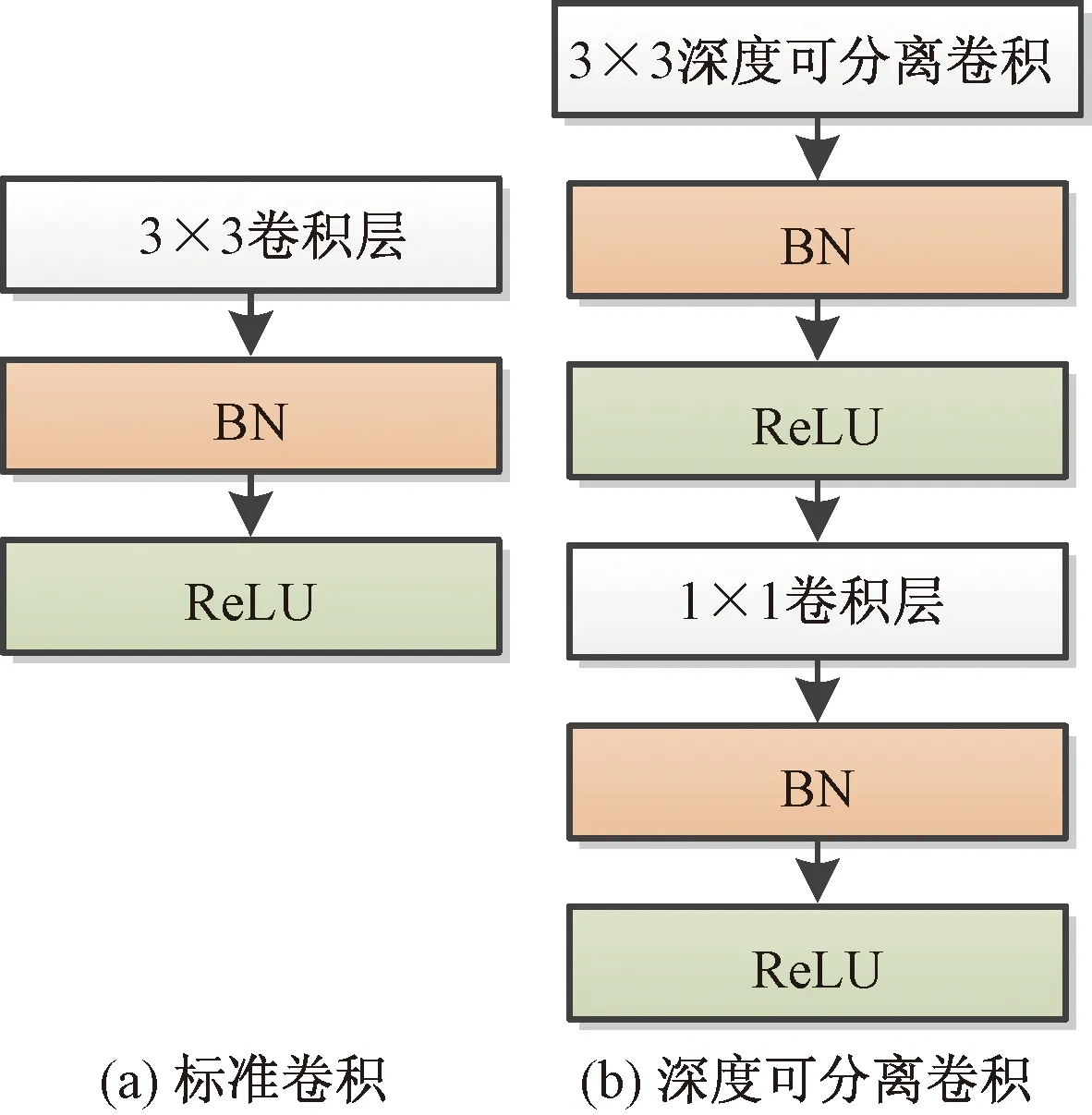
BN为批量归一化;ReLU为激活函数
2.3 ShuffleNets
ShuffleNetV1[58]主要采用了组卷积和通道 shuffle两种方法,用来减少模型使用参数量。其中通道shuffle通过对特征图的通道进行重新排序构成新的特征图,解决了组卷积信息流通不畅的问题。如图5[58]所示,通道shuffle操作有两种结构,图5(a)为基础残差结构,中间包含一个3×3的深度卷积进行特征提取。图5(b)为特征图不变的ShuffleNet unit,利用1×1分组卷积替换基础残差结构中1×1的卷积层,并在第一个卷积层后面添加了通道shuffle。图5(c)为特征图减半的ShuffleNet unit在shortcut中添加了3×3平均池化,减小了特征图的分辨率,所以又将最后的Add操作替换成concat,用来弥补分辨率降低带来的信息损失,增加了输出维度且产生很大的计算量。由于ShuffleNetV1使用了大量的1×1的分组卷积,增加了内存访问成本。ShuffleNetV2[59]在V1的基础上进行了改进,首先引入通道分离(channel split)操作,然后借鉴了DenseNet的思想,将元素级add操作替换成concat,保证前后的channel数相同,最后再进行通道shuffle操作。ShuffleNetV2在ImageNet数据集上的分类精度与ShuffleNetV1相比提高了1.2%。
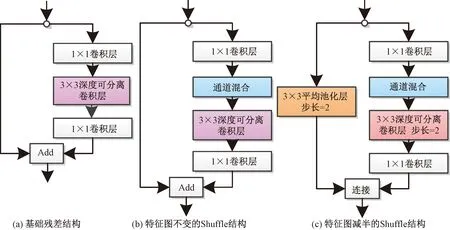
Add为特征图相加操作
2.4 Xception
Chollet[60]提出了Xception,可以看成是Google Inception的进化版,如图6[60]所示。它借鉴了深度可分离卷积,来改进Inception。先进行标准卷积操作,对1×1卷积后的每一个通道进行3×3的卷积操作,再分别通过3×3卷积以进行特征提取。它和深度可分离卷积很相似,但是它的两段卷积过程是相反的,而且后面带了一个ReLU非线性激活函数,这样做提高了网络的效率。
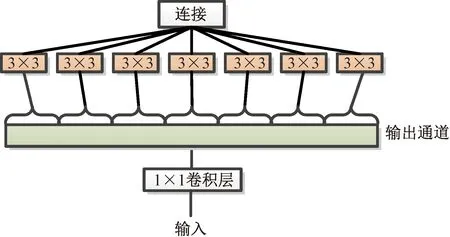
图6 Xception模块[60]
2.5 GhostNet
为了减少网络计算量,GhostNet网络将传统的卷积分成两步进行[61],首先使用少量的卷积核生成一部分特征图,然后通过廉价的线性操作进一步生成新特征图,最后将两组特征图拼接到一起。 GhostNet包含两种瓶颈结构,如图7[61]所示。图7(a)为stride=1瓶颈结构,用于特征提取;图7(b)为stride=2的瓶颈结构,用于减少通道数量。这两种瓶颈结构通过堆叠两个Ghost Module形成。在ImageNet分类实验中,GhostNet达到了94%的精准度,超过MobileNetV3。
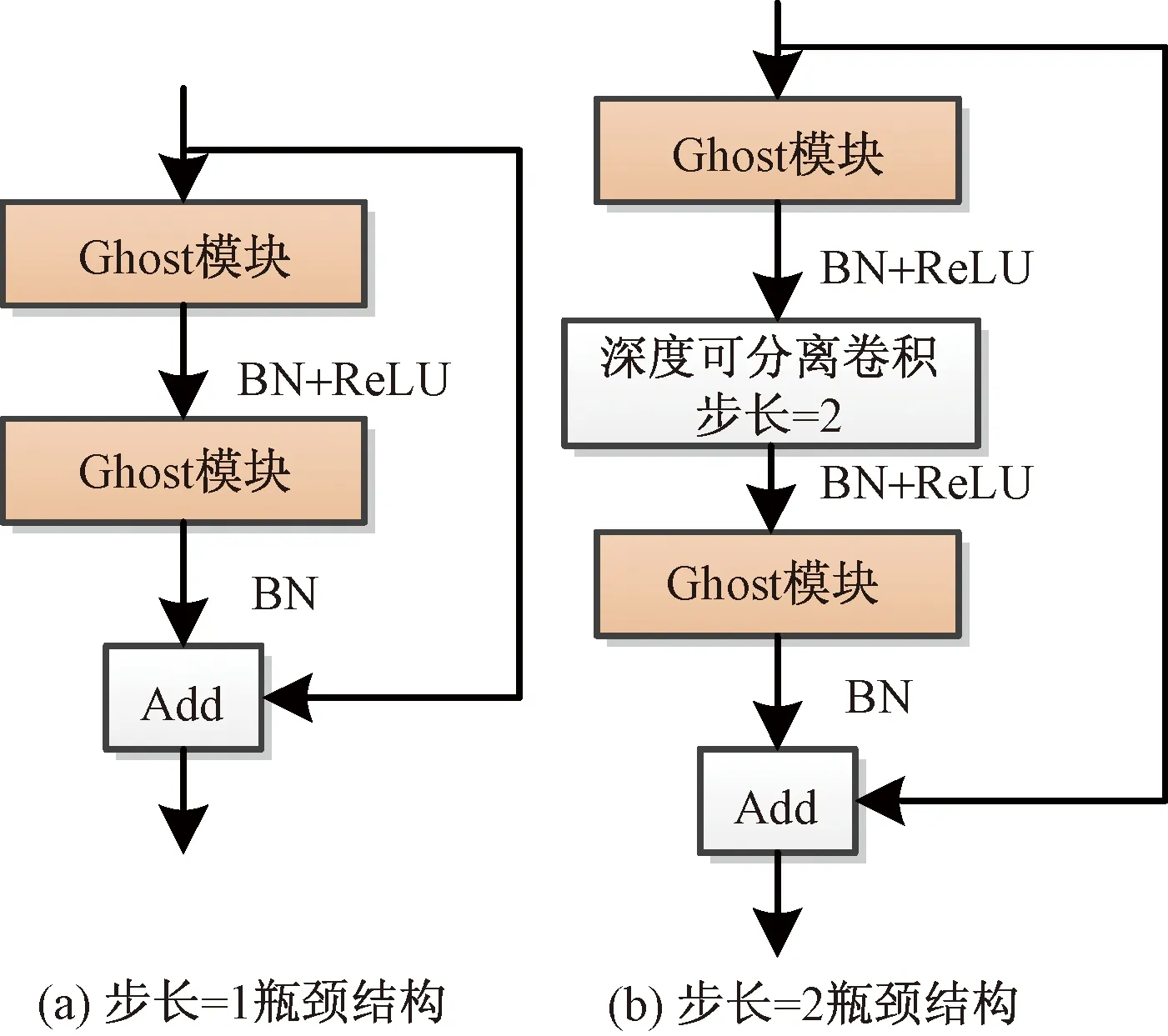
BN为批量归一化;ReLU为激活函数;Add为特征图相加操作
对基于深度可分离卷积的主流轻量化神经网络结构的创新点和优劣势进行分析和对比:①SqueezeNet。创新点为提出Fire Module来压缩网络模型,主要包括1×1的卷积核替换3×3的卷积核,参数减少为原来的1/9;采用1×1的卷积核进行降维,减少输入通道数;池化层往后放,提高准确率。缺点是丧失了网络的并行能力,实时性不好。②MobileNetV1。创新点为引入深度可分离卷积进行网络结构轻量化设计,缺点是网络结构单一,且过量使用激活函数导致神经元易失活。③MobileNetV2。创新点引入线性瓶颈反残差结构。缺点是引入了额外的成本与延时。④MobileNetV3。创新点是使用了互补搜索技术和引入SE模块、h-swish(x)激活函数。⑤ShuffleNetV1。创新点为提出通道shuffle。缺点是过多使用组卷积操作。⑥ShuffleNetV2。创新点为引入通道分离。缺点是运行速度可以进一步提升。⑦Xception。创新点为使用改进的深度可分离卷积替换Inception V3中的卷积模块,有效提高了网络。缺点是训练时迭代速度比较慢。⑧GhostNet。创新点为使用更低的成本获得更多的特征映射,可以用于优化深度神经网络结构。缺点是相对其他轻量化网络来说,不能有效降低参数量。表4为轻量化网络方法对比。

表4 轻量化网络方法对比
3 轻量化二维人体骨骼关键点检测改进方法
近年来,随着轻量化网络的发展,基于二维人体骨骼关键点检测的轻量化方法被广泛研究,通过分析轻量化二维人体骨骼关键点检测方法的轻量化方式,目前的轻量化二维人体骨骼关键点检测研究方法分成五类:轻量化特征提取网络、深度可分离卷积、Dense连接机制和轻量化瓶颈结构。
3.1 轻量化特征提取网络
目前在人体骨骼关键点检测算法中,其特征提取网络大多采用网络模型参数量比较大,如VGG网络、ResNet网络。这些网络可以有效的提取特征信息,但随着网络的加深,网络模型越来越大。为了设计轻量级的网络,为了降低网络的参数量和计算量,可以选择轻量化网络作为特征提取网骨干网络,如MobileNets、SuffleNets、GhostNet等,可以有效降低网络模型参数量和计算量。
OpenPose作为Bottom-Up方法中典型的模型,其检测速度不会受图像中人数的影响,在多人骨骼关键的检测中被广泛应用。但由于OpenPose的特征提取网络为VGG19,使模型的参数进一步增加,所以很多研究者们针对OpenPose模型进行改进。 Daniil Osokin对OpenPose进行了轻量化改进[62],首先,将OpenPose的两个分支合并成一个分支,然后将特征提取网络VGG19替换成MobileNetV1,同时还将网络中的7×7卷积替换成3个连续的1×1、3×3、3×3的卷积核结构,其中最后一个3×3的卷积为空洞卷积,为了防止梯度消失的问题,还加入了一个跳跃连接,如图8所示。朱洪堃等[63]提出了一种轻量化实时人体姿势检测模型,其轻量化方法同样是替换掉VGG19,选择ResNet-18作为特征提取网络,为了增强特征提取网络的非线性拟合能力,在残差块中添加了二阶项和一个较小的偏置。王雨生等[64]通过将OpenPose原有的特征提取网络分别替换成ResNet34和ResNet50进行实验,根据实验结果最终选择采用ResNet50作为特征提取网络。Schirmer等[65]利用MobileNet-V2替换VGG19中的12个卷积模块,提出了一种实时人体骨骼关键点检测模型。苏超等[66]通过对比普通卷积和深度可分离卷积的参数量和实验验证,采用MobileNet作为特征提取网络,其平均识别准确度达到了99.62%。
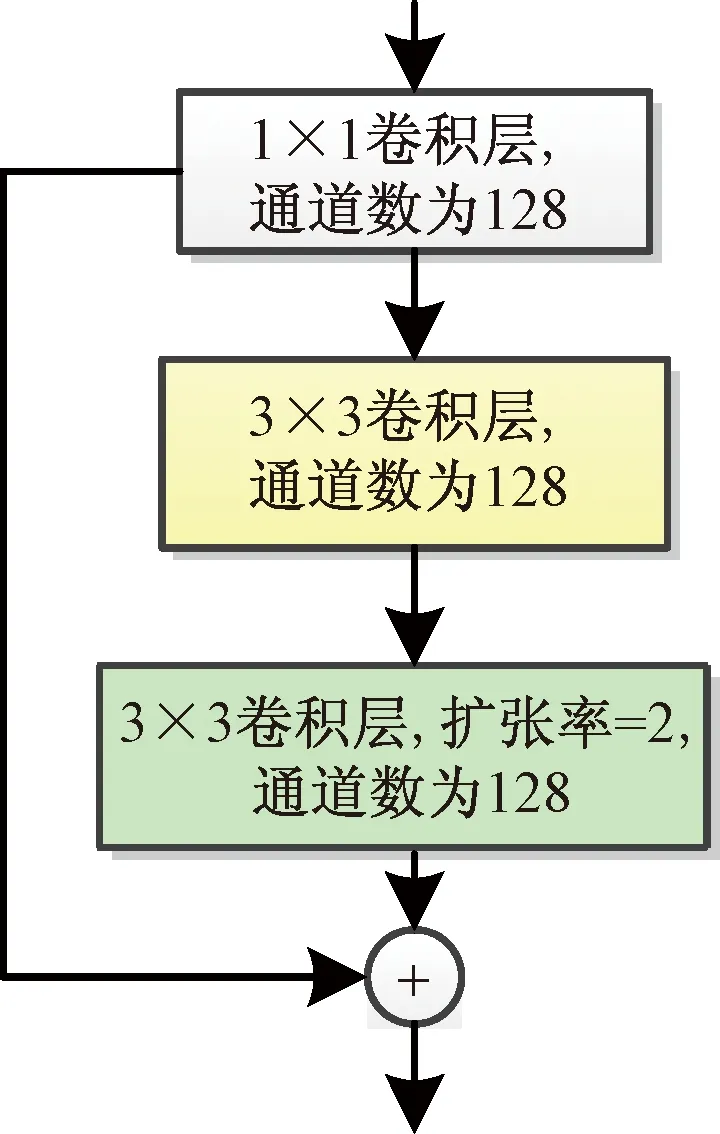
图8 替换7×7的空洞卷积块
胡江颢等[67]提出一种应用于手机上的是人体骨骼关键点检测算法(light-weight network for real-time pose estimation,LWPE),算法采取MobileNetV2作为特征提取主干网络,有效减少了模型参数和运算量。Zhu等[68]提出了一种基于人体骨骼关键点检测的轻量级交叉融合的神经网络。网络由骨干模块和交叉信息融合模块组成。骨干模块使用最新的轻量级网络GhostNet进行特征提取,有效降低计算成本和参数。信息交叉模块将得到的特征信息分解为两个分支:关键点检测和关节连接,消除干扰信息,然后通过交叉信息融合共享足够的信息提高特征提取能力。Zhang等[69]提出了一种专门针对人体骨骼关键点检测有效的网络模型。该模型包括两部分:有效的骨干和有效的头部。为了缩小分类和姿态估计任务之间的差距,骨干网络使用NAS方法自动定制骨干网络,有效降低了计算成本。有效的头部网络包括细长的转置卷积核空心信息矫正模块,用来优化模型的准确率。Chen等[70]对最新的OpenPose进行改进,提出了轻量级神经网络ThermalPose。ThermalPose采用11个轻量级卷积层组成的骨干网络作为特征提取网络,如表5[70]所示,除第一层使用标准卷积外,其他层均使用S-Conv,其中S-Conv是深度可分离卷积。在通道空间卷积中使用了一个大小为2的零填充。在每次卷积之后,都会应用批量归一化和矫正线性单元。S-Conv-2、S-Conv-7和S-Conv-11的输出被串联起来,生成一组特征图。ThermalPose通过使用depthwise S-Conv在牺牲精度的情况下大大减小了模型尺寸和复杂度。
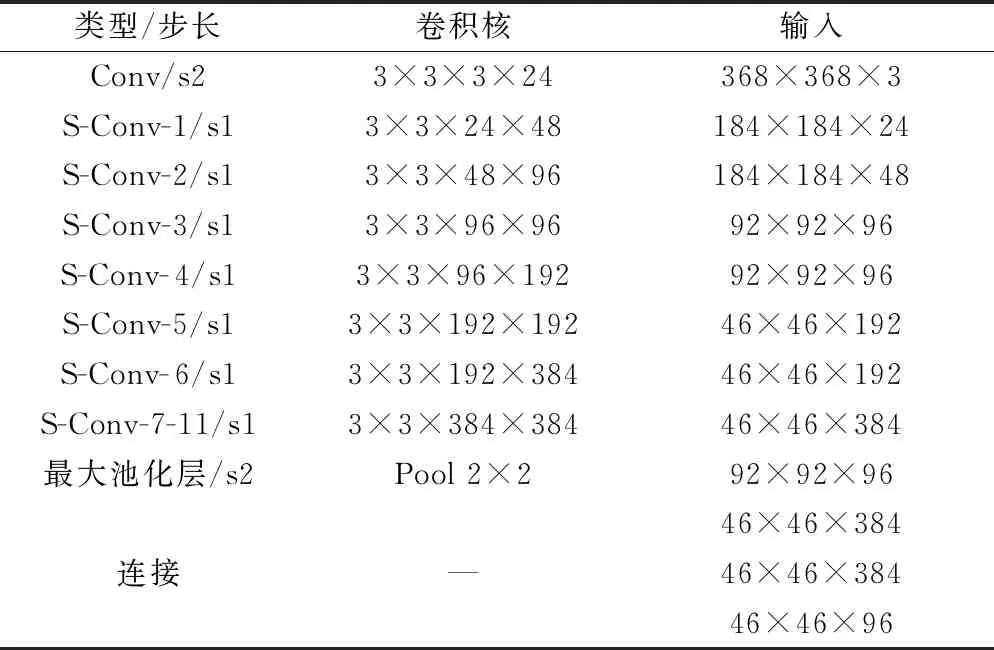
表5 特征提取网络架构[70]
3.2 深度可分离卷积
深度可分离卷积作为MobileNet的核心,被广泛用于基于网络结构设计的轻量化中。由于深度可分离卷积与标准卷积相比,参数量将减少1/9左右。利用深度可分离卷积替换标准卷积,Gao等[71]在Stacked Hourglass的基础上进行了改进,提出了一个轻量化的网络模型。首先利用深度可分离卷积替换其中一部分标准卷积,然后在金字塔残差模块中加入了通道分离模块和通道混合模块,用来加强特征融合,改变特征图的通道维数。这项工作有效降低了网络的训练参数和计算量,参数量减少了50%。轻量化金字塔残差模块可表示为

(1)
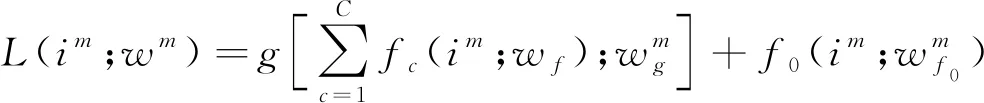
(2)
式中:im为第m层的输入;⊗表示级联;wm为第m层的滤波器;L(im;wm)为特征金字塔;g为滤波器;c为个数;C为金字塔多尺度的个数;fc为第c个金字塔特征变换;wf为滤波器f;wg为过滤器g;f0为首个金字塔特征变换;wf0m为首个金字塔特征变换中的第m个滤波器。
段俊臣等[72]对 OpenPose网络模型进行了改进,利用深度可分离卷积替换部位亲和网络中的标准卷积,同时为了加速收敛在每个深度可分离卷积与点卷积之后均加入了一个ReLU函数。肖文福等[73]同样是利用深度可分离卷积的代替标准卷积的方式来减少参数量。该方法主要是对PAF模块和Heatmap模块内部结构进行改进,将卷积块中的3×3标准卷积替换成深度可分离卷积,改进后的模块内部结构,如图9[73]所示。
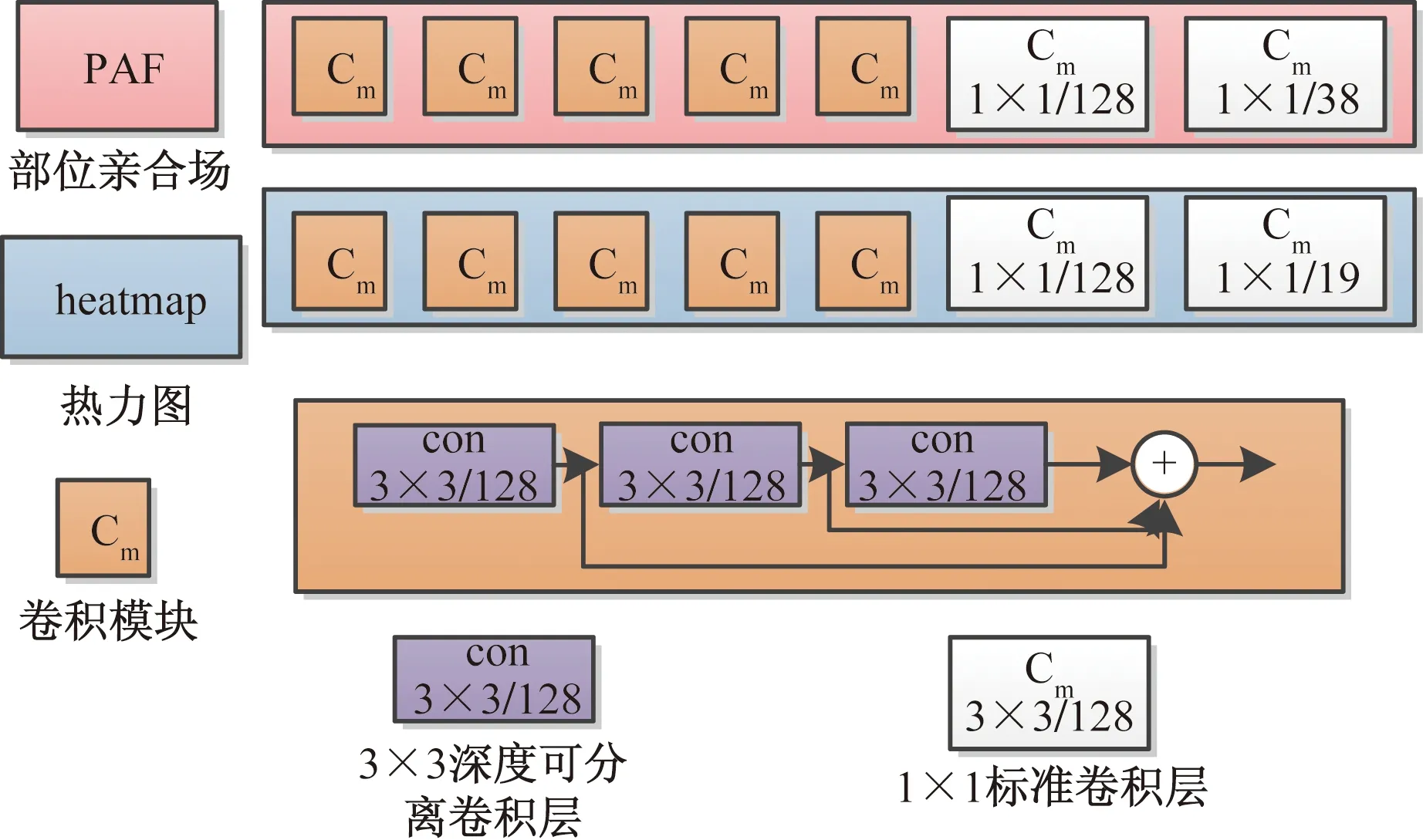
Cm为卷积模块;con为卷积层
Li等[74]提出了一个轻量级HRNet模型,模型以HRNet作为主干网络,但是由于HRNet利用多个分辨率分支,整个过程特征图始终保持高分辨率,这使得HRNet网络过于复杂,无法部署在移动设备上。于是受MobileNet的启发,利用深度可隔离网络代替HRNet中的标准卷积,同时采用了空洞卷积来提高特征提取能力。该模型的体系结构比原始的HRNet中的参数和计算量都要少,而且仍然保持着出色的表示能力。蔡敏敏等[75]提出了一种对运动视频提取特定运动帧的方法,采用HRNet作为骨干网络,但该模型过大、无法满足实际运用需求,于是对HRNet进行了轻量化处理,首先将3×3的标准卷积替换成深度可分离卷积,然后减少了HRNet并行的子网数量。
3.3 Dense连接机制
Dense连接机制[76]包括:①为了提高各层之间的信息交流,Dense模块中的每一层都与前几层进行连接;②把网络的每一层设计的很窄,减小卷积的输出通道数。DenseNet连接机制提高了网络参数的共享性,其参数量和计算量约为ResNet的1/2。ResNet残差网络加上跳跃连接,其非线性映射关系可表示为:Xl=Hl(Xl-1)+Xl-1,其中,下标l表示层,Xl表示l层的输出,Hl表示一个非线性变换。DenseNet改善了不同层之间的信息交流问题,将所有输入连接到输出层,非映射关系表示为:Xl=Hl([X0,X1,X2,…,Xl-1])。DenseNet不仅提高了特征利用率,使不同层次的特征进行融合,还可以避免梯度消失的问题,降低了网络成本。
汪检兵等[77]提出了OpenPose-slim模型。该模型在OpenPose网络模型的基础上将并行结构改成串行结构,并将其中的卷积模块替换成具有Dense连接及时的卷积模块。Yang等[78]提出了密集连接残差模块(densely connected residual module, DCRM),并将其引入HRNet骨干部分,有效减少网络中的参数量。DCRM在原始密集层上增加了一个1×1的卷积层和3×3的卷积短连接,有效减少了网络参数量。每个DCRM由一个以上的密集层组成,如图10[78]所示,每个密集层之间都有一个密集连接,每个层都把前面的所有特征图作为输入。渠涵冰等[79]提出了一个轻量级高分辨率骨骼关键点检测模型。在HRNet的基础上,引入改进后DenseNet卷积网络,替换主干网络中使用的残差模块。针对DenseNet卷积结构的改进是首先在3×3的卷积前添加一个1×1的卷积,然后在每个dense单元中添加一个3×3 的卷积。改进后的网络参数比HRNet减少了63.8%。
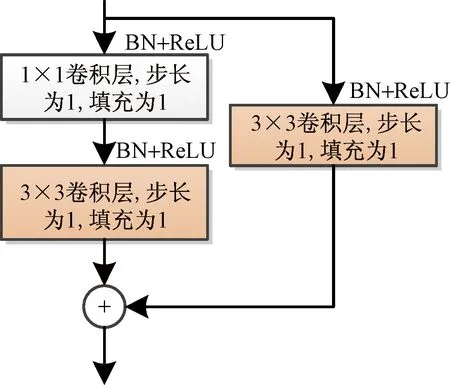
BN为批量归一化;ReLU为激活函数
3.4 Lightweight瓶颈结构
瓶颈结构(Bottleneck)是一种特殊的残差结构,是ResNet的核心内容之一。瓶颈结构能够降低大卷积层的计算量,即在计算比较大的卷积层之前,先用一个1×1卷积来压缩大卷积层输入特征图的通道数目,以减少计算量。在大卷积完成计算之后,根据实际需,有时候会再次使用一个1×1卷积来将大卷积层输出特征图的通道数目复原。图11(a)为普通的残差结构,图11(b)为一般的瓶颈结构,依次是小通道的1×1卷积层、一个较大的卷积层、大通道数的1×1卷积层,在增加网络层数的同时特征提取能力也会得到提升。
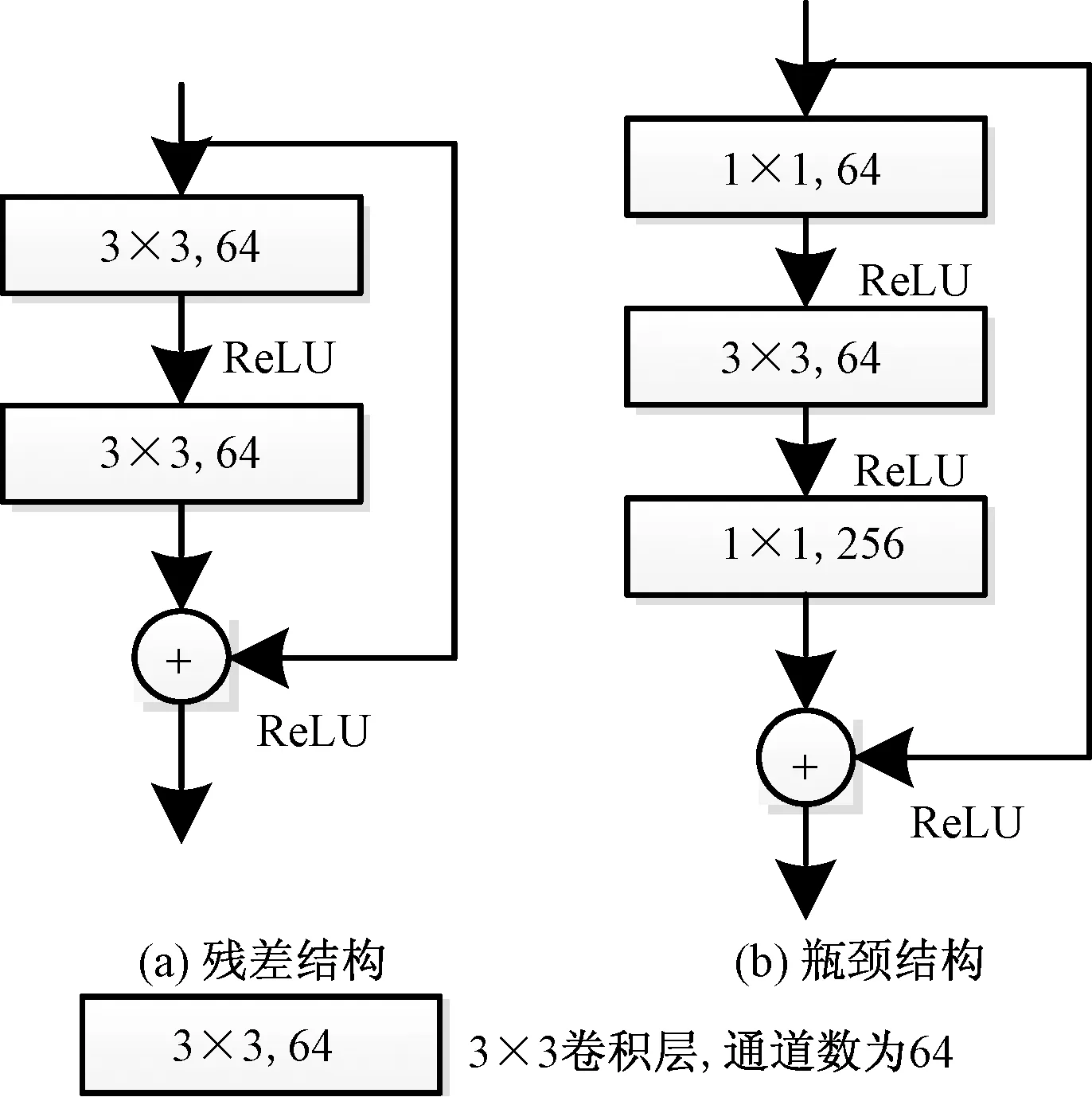
ReLU为激活函数
对HRNet网络模型的轻量化大都利用轻量化瓶颈结构替换原高分辨率网络中的基础模块,以达到网络轻量化的目的。罗梦诗等[80]将注意力特征融合模块(attentional feature fusion,AFF)与GhostNet的瓶颈结构相结合,提出了线性变换注意力特征融合的Gaff模块,Gaff模块包括Gaffblock模块和Gaffneck模块,利用AFF模块替换瓶颈结构中结果相加部分。将HRNet网络中的瓶颈模块和基础模块替换成Gaff模块,Gaff模块有效降低了网络的参数量和网络模型的复杂度。Zhang等[81]和孙琪翔等[82]利用改进的Ghost瓶颈结构替换HRNet中的基础模块,从而降低网络模型参数量。Yu等[83]提出了一个人体骨骼关键点检测的有效高分辨率网络LiteHRNet。首先对HRNet进行了改进,将Shuffle Block与HRNet进行了简单融合,采用Shuffle Block替换HRNet中的第二个3×3的卷积,并替换网络中所有的残差模块,提出了一个Naive Lite-HRNet模型。然后,因为Naive Lite-HRNet中存在大量的1×1卷积操作成为计算瓶颈,于是引入了一个轻量级的单元-有条件的通道加权(conditional channel weighting),用来替换shuffle block中的1×1点卷积,信道加权的复杂度与信道数成线性关系,并且低于1×1逐点卷积的时间复杂度,此网络模型命名为Lite-HRNet。
注意力机制目前被广泛应用于图像分类,目标识别和自然语言处理等方面,后来注意力机制被引入人体骨骼关键点检测[84]。注意力机制在人体骨骼关键点检测中取得了不错的效果,但计算成本高。Hu等[85]通对注意力机制近一步改进,提出了SENet(squeeze-and-excitation)。SENet通过对特征通道间依赖关系进行建模,对每个通道的重要性进行预测,按照通道的重要程度提升重要的特征通道抑制不重要的通道特征[86]。Ren等[87]提出了一种快速轻巧的人体骨骼关键点检测方法,在保持精准性的前期下并花费较小的成本。该方法包括两部分:用于人体姿态估计的快速轻量级网络(fast lightweight pose network,FLPN)和用于降低计算量的新型轻量级模块。轻量级模块引入了结构相似性度量(structural similarity measurement,SSIM)和注意力机制,其中SSIM方法来精炼适当的固有特征图比例,以减少模块的尺寸并保持 高精度。郭欣等[88]为了在嵌入式平台通过提取人体骨骼关键点对跌倒行为进行实时检测,设计了一个带有注意力机制的轻量级基本模块,用来搭建特征提取网络。基本模块包含了深度可分离卷积、线性瓶颈逆残差结构和注意力机制。强保华等[89]提出了一种基于CPMs和SqueezeNet的单人人体骨骼关键点检测模型,首先,由于CPMs模型训练时间长、检测速度慢,CPMS-Stage4减少了两个Stage以缩短训练时间、提高检测速度,这样做带来的问题就是检测的准确率降低。然后,针对CPMS-Stage4存在的问题,提出了SqueezeNet15-CPMs-Stage4模型。该模型将SqueezeNet的前15层Fire8替换Stage1中一个卷积池化层,同时在每个Stage中添加了两个卷积层。Stage1中的Fire8和五层卷积提取的特征作为后面每个Stage的输入。改进后模型虽然增加了网络的深度,但是大大缩减了训练时间,提高了检测速度。
堆叠沙漏网络常作为人体骨骼关键点检测网络的骨干网络,但是由于沙漏堆叠网络存在参数量大和需要较高的计算能力。因此,Seung-Taek等[90]提出了人体骨骼关键点检测的轻量化堆叠沙漏网络,该网络在编码器的前端使用了额外的堆栈间跳跃连接,通过在下一个堆栈中反映编码器提取的相对较低级别的特征。该网络结构加入了跳跃连接,用来提高网络的性能,同时保持网络中的参数量。另外,提出了一个用于增大卷积感受野的残差模块Multidilated Light残差块,通过使用扩张卷积增大感受野,Multidilated Light残差块结构如图12[90]所示。受ResNet和SqueezeNet启发,Zhao等[91]提出了一种多分支HybridBlock,设计了一个精简版沙漏模块,目的是用更少的参数量生成丰富的特征信息,减少参数量。HybridBlock使用不同扩张率的卷积构建多条上下文路径,其结构如图13[91]所示,其中Squeez卷积层使用1×1的卷积核,来减少特征图中的通道数,expand卷积层使用1×1和3×3的卷积核,以及经过1×1卷积的短连接,用来匹配输出维度。
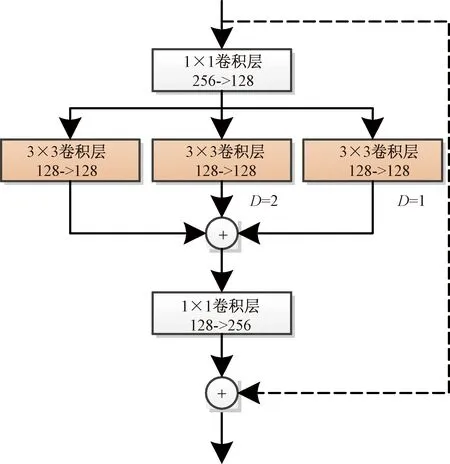
D为扩张率;->表示通道数变化
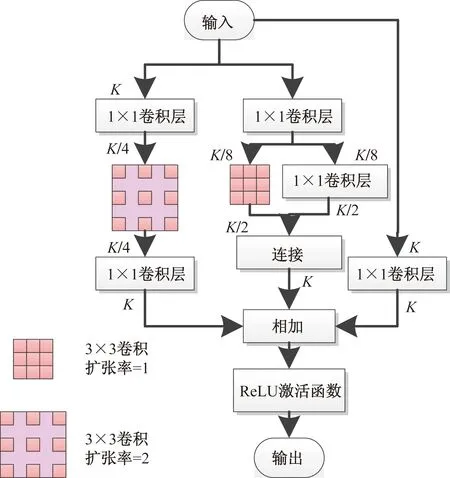
K为卷积核数量
根据SimpleBaseline的设计理念,提出了一个轻量级人体骨骼关键点检测网络(lightweight pose network,LPN)[92],将下采样中的标准卷积替换成轻量级Bottleneck block,上采样中使用一组转置卷积和一个1×1的卷积层替换每个转置卷积。最终实验和SimpleBaseline相比,在模型参数大大减少的情况下性能只下降了一点点。Simple Baseline在人体骨骼关键点检测中取得了出色的性能,但是网络具有大量参数和计算。为了减少计算成本,Zhong等[93]提出了一种低计算成本的深度监督金字塔网络(deep supervision pyramid network,DSPNet)。该网络使用轻量级上采样单元(lightweight up-sampling unit,LUSU)代替Simple Baseline中的转置卷积,LUSU单元集成了可分离转置卷积、channel-wise attention和轻量级自注意力机制,有效降低了参数量。Zhang等[94]利用深度可分离卷积和注意力机制设计了一个轻量级瓶颈块,并在此基础上提出了一个单阶段的轻量化网络。其网络结构与SimpleBaseline相似,都是以ResNet为主干,不同的是下采样时使用轻量化瓶颈结构替换主干中的标准瓶颈结构。同时为了减少参数的冗余,将反卷积层替换成一组反卷积层和1×1卷积层的组合。
Guan[95]提出了一种针对资源受限的2D人体姿态估计算法Pose-ShuffleNet。将OpenPose的特征提取骨干网络VGG19替换成由ShuffleNet block组成的多级架构,且分支网络中的7×7卷积可替换成ShuffleNet block,Pose-ShuffleNet网络架构如图14[95]所示,其中的B模块可以是标准卷积模块也可以替换成ShuffleNet block。
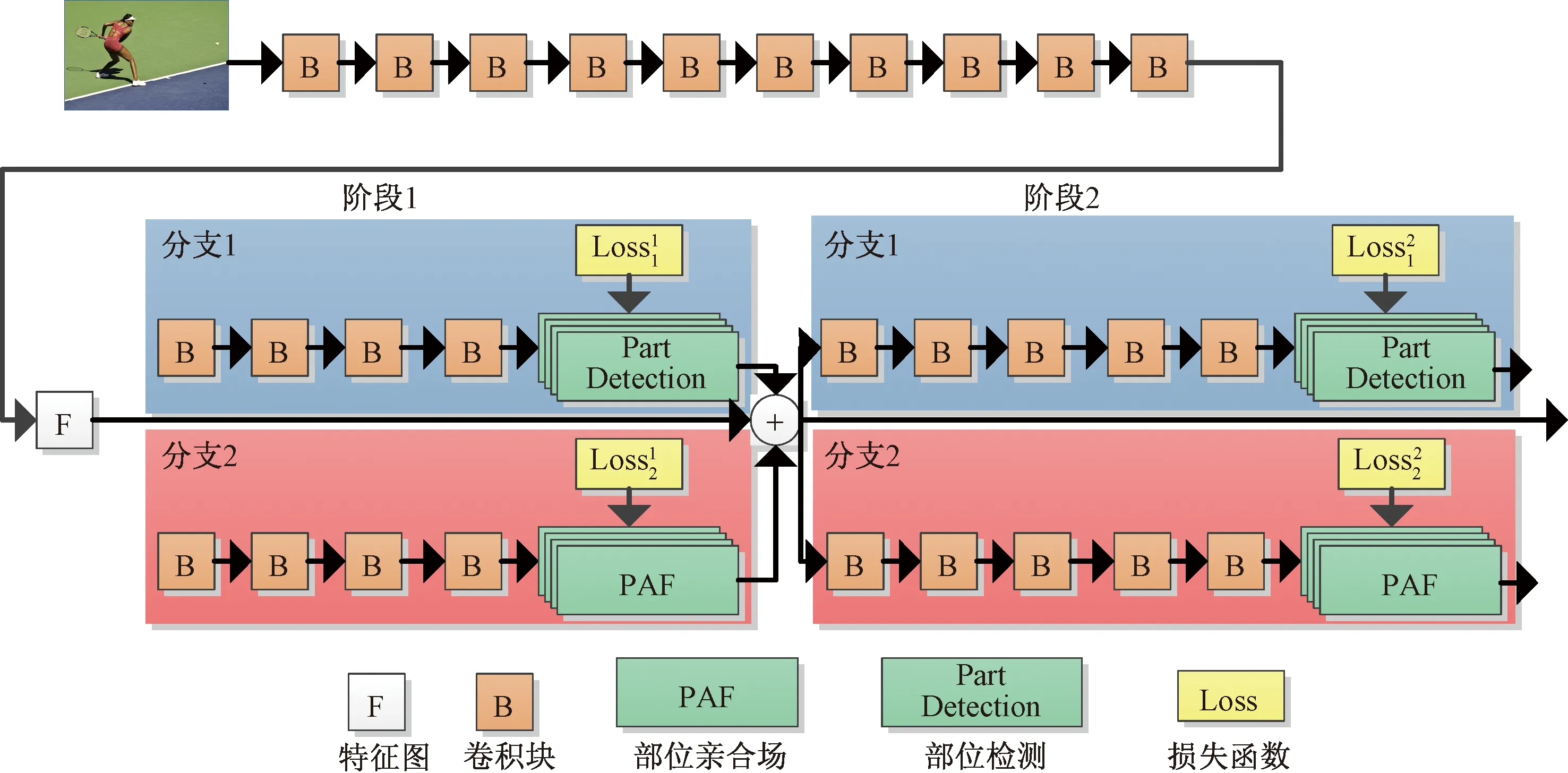
图14 Pose-ShuffleNet网络结构[95]
4 方法评价指标及对比分析
4.1 常用评价指标
精确评估人体骨骼关键点检测的性能是比较困难的,因为有很多特征和因素需要考虑,所以二维的人体骨骼关键点检测的评价指标有很多,下面介绍了常用的人体姿态估计的评价指标。
(1)正确部位的百分比(percentage of correct parts,PCP):最早用于二维的人体骨骼关键点检测的评价指标是PCP,用来反映肢体定位的精准度[96]。如果肢体的两端与真实值的端点在某一阈值内,表示肢体预测正确。但PCP并没有广泛应用到后续的研究当中,主要是因为它会对短肢体进行惩罚。
(2)正确关键点的百分比(percentage of correct keypoints,PCK):PCK被广泛应用于关键点检测,通过衡量预测关键点的位置和真实关键点位置之间的距离来确定检测的关键点的准确性[97]。如果距离在阈值范围内,则表示检测到的关键点的位置正确。PCK值越高,模型性能越好。MPII数据集中以头部长度作为归一化参考,即PCKh,可表示为
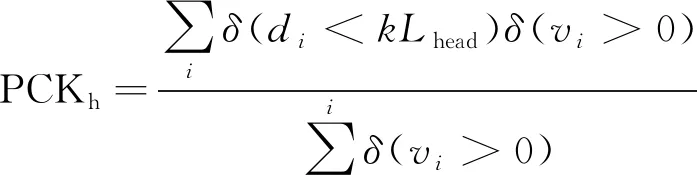
(3)
式(3)中:i为关键点编号;di为当前检测第i个关键点与真实值中第i个关键点之间的欧式距离;kLhead为当前人的头部直径作为尺度因子,其中,k为关键点个数,Lhead为头部直径;δ为克罗内克函数;vi为第i个关键点的可见性。
(3)目标关键点相似度(object keypoint similarity,OKS):OKS[98]用于衡量预测关节点与真实关节点的相似度,在目标关节点检测中的作用于IOU非常相似,所以OKS越高,说明预测的关节点与真实关节点之间的重叠度更高。
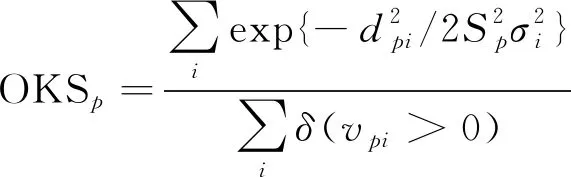
(4)
式(4)中:p为人体检测框编号;dpi为测试是检测关键点位置与数据标书关键点位置的欧式距离;Sp为人体尺度因子;σi为控制各关键点响应衰减程度的超参数;vpi为第p个人的第i个关键点的状态;OKSp为第p个人的关键点的相似度。
(4)平均准确度(average precision,AP):AP是基于计算预测关节点和真实关节点之间的相似度OKS进行评估[44],AP的计算公式为
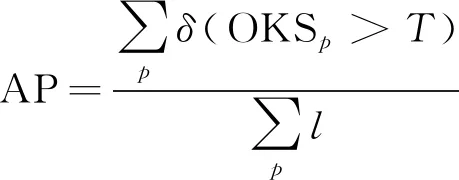
(5)
式(5)中:T为给定的阈值。
(5)平均精度均值(mean average precision,mAP):mAP[44]是常用的检测指标,对所有关节点的AP求均值,获得最终的mAP,其计算公式为
mAP=mean{AP@s(0.50∶0.05∶0.95)}
(6)
式(6)中:mean为计算平均数;s为OKS阈值,在给定的s下,AP为每一关节点在整个测试数据集上检测结果的平均准确率。
GFLOPs(frame rate, number of weights and giga floating-point operations per second):GFLOPS计算性能指标[99]对人体骨骼关键点检测也非常重要。帧率表示输入数据的处理速度,一般用每秒帧数(FPS)或每幅图像秒数(s/image)表示。权重数和GFLOPs显示网络的效率,主要与网络设计和具体使用的GPU/CPU有关。
4.2 方法对比分析
针对以上轻量化网络的人体骨骼关键点检测方法,在MPII和MSCOCO上,分别以PCK和AP为评价标准的对比实验进行了总结。结合表2、表3和表6的实验数据可知,虽然轻量化网络的人体骨骼关键点检测算法的精准度与经典人体姿态估计算法的普遍较低,但轻量化检测网络在MPII和COCO数据集上的检测精度分别达到了93.4%和77.7%,且模型参数量和计算复杂度比较小,取得了较好的实验效果,更适部署到嵌入式设备和移动设备上,进行实时检测。
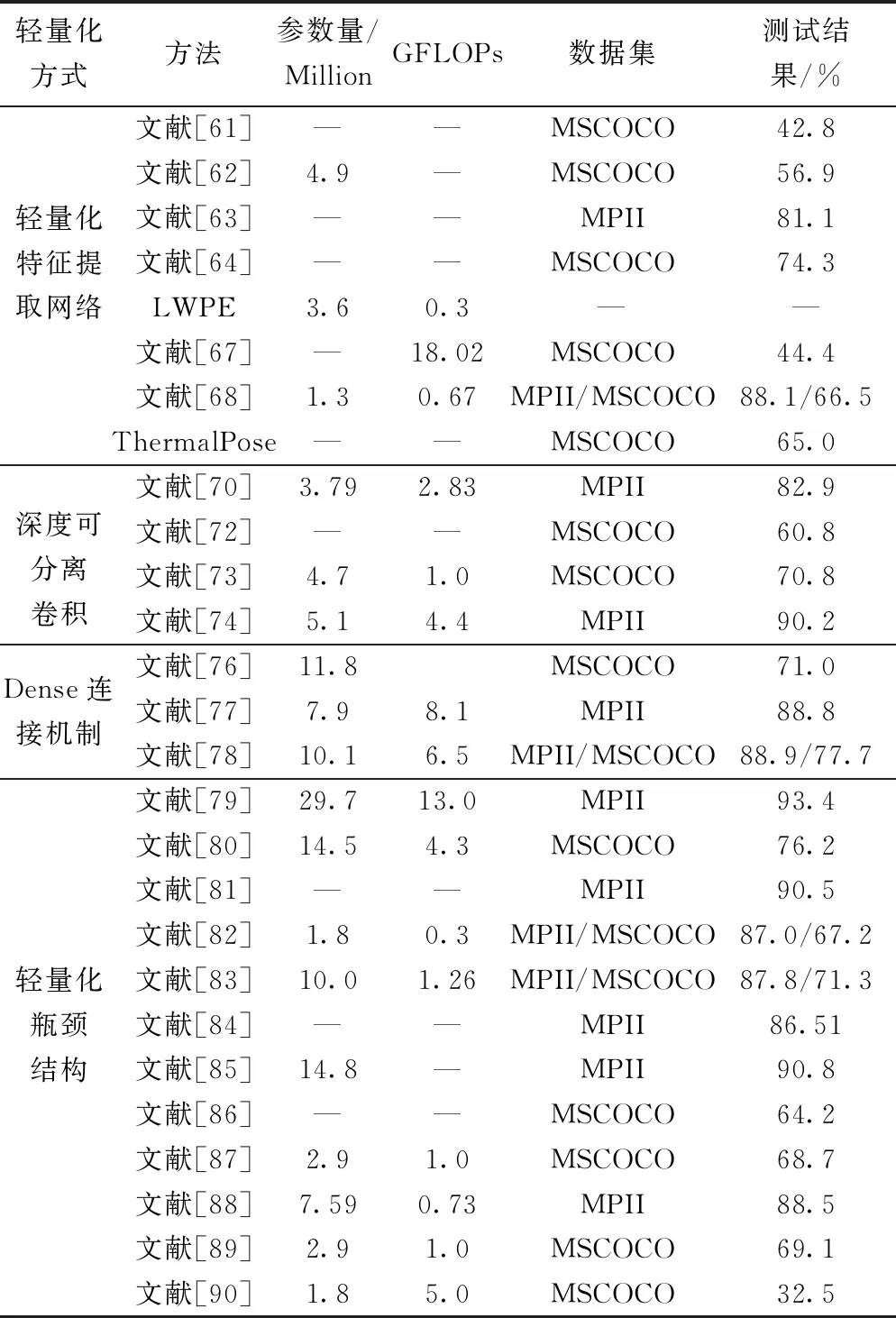
表6 实验结果对比
5 结论与展望
随着移动设备和嵌入式设备的广泛应用,关于轻量化二维的人体骨骼关键点检测的研究受到越来越多研究者的关注,且在许多领域进行了广泛研究。基于近年来关于轻量化骨骼关键点检测的研究,首先介绍了人体骨骼关键点检测中常用数据集、检测方法和轻量级网络模型,然后根据轻量化神经网络的方式对检测方法进行了分类和性能对比。最后对当前的研究存在的问题和发展趋势进行了阐述。
(1)数据集存在问题:目前关于人体骨骼关键点检测研究中常用的数据集包括:MPII、COCO、FLIC 和AI Challenge等,这些数据集中的人体动作主要是一些常规动作,但是随着人体骨骼关键点检测的广泛应用,这些数据集已经无法满足特定的实际应用场景,比如物流行为检测,跌倒检测和安防检测等。还有目前关于人体骨骼关键点检测的方法大多采用有监督的学习方式,这就要求训练数据集包含大量标注信息,这不仅费人力物力还会存在一定的局限性,降低模型的检测精度。所以未来研究者可以对数据种类进行扩充,以适应更多特定应用场景,还可以采用半监督或无监督的训练方法,采用少量带标签数据甚至无标签数据进行训练。
(2)算法检测存在问题:人体骨骼关键点检测效果会受到拍摄角度、光照变化和遮挡情况等的影响,检测结果会出现漏检、错检和误检的问题,降低关键点的检测准确度。其次,目前已有不少关于轻量化人体骨骼关键点检测的研究,但大都采用人工设计的轻量化网络,大多只注重降低网络的参数量和检测实时性,没有对网络进行进一步优化。关于轻量化网络的设计不仅依赖设计者的经验还依赖于资源条件。因此充分利用全局和局部信息,同时加入人体结构约束,以获得先验知识。同时,排除人体因素的干扰,利用自动机器学习技术学习并训练出一个最优的轻量化网络将会是未来的研究方向。
