智能鱼类信息共享平台的构建
2022-07-11李然杨玉婷张志强刘鹰黄健隆李浩淼
李然,杨玉婷,张志强,刘鹰,3*,黄健隆,李浩淼
(1.大连海洋大学 信息工程学院,辽宁 大连 116023;2.设施渔业教育部重点实验室(大连海洋大学),辽宁 大连 116023;3.浙江大学 生物系统工程与食品科学学院,浙江 杭州 310058)
随着经济的高速发展,各行业对科学数据的需求日益迫切,许多国家和国际组织都开展了一系列基于新技术的科学数据共享研究和实践,在世界范围内进行科学数据共享工作。自20世纪80年代起,中国在多个领域开始推动科学数据共享平台的构建与运用,经过40多年的发展,中国已建成的综合性科学信息服务系统,为国家重大战略、科研计划等提供了重要的信息服务支持。随着互联网新技术的发展,各领域对信息共享技术的需求达到了一个新的高度。就渔业科学数据而言,由于涉及多个领域或学科的相关知识和原始数据,尤其需要把以往分散的数据按一定标准重新整理形成共享平台[1]。
随着中国海洋经济的高速增长,对鱼类信息的需求也日益增大,数据库技术的发展,使得海量信息资源的高效存储和检索成为可能。传统的数据库基于集中式存储和关系数据库体系结构,无法满足海量数据存储和高并发查询的需求,存储效率低,查询响应慢,且数据信息种类、归属和溯源也存在一些问题[2]。因此,现有的鱼类数据库管理系统已难以满足海量鱼类信息存储和快速响应的需要。
中国现有的鱼类信息数据库主要有6个:①“水库渔业数据库”,始建于20世纪80年代末,由中国科学院水生生物研究所建立,该数据库包含中国主要水库鱼类的生物学信息,并提供检索和查询功能[3];②“我国水产种质资源信息系统”,2002年由中国水产科学研究院构建,采用Access软件,通过ODBC链接,综合了2 771个物种的生物学信息、养殖信息和分布信息等;③“渔业科学数据共享平台”,2009年由中国水产科学研究院承担建设,采用SQL Server 2000关系数据库管理系统存储数据,该平台集成了渔业生态环境野外调查数据、渔业生物资源野外调查数据、渔业水资源与生态特征数据及渔业物种资源与生物基础数据等9类渔业科学数据;④“渔业科学数据库”,由中国水产科学研究院淡水渔业研究中心建立,涵盖了食物成分数据库、水生生物数据库、水产价格行情数据库、水产英文期刊数据库和渔业法律法规数据库等19个子数据库;⑤“中国台湾地区鱼类数据库”,该数据库实现了中国台湾地区本土鱼类和贝类(鱼类和贝类标本)的数字化,并可与国际鱼类和贝类数据库或相关网站进行互通,在鱼类分类数据和GIS应用方面也取得了一定的进展[4-5];⑥世界鱼类数据库“FishBase”,这是所有鱼类数据库中规模最大、开发最广泛的全球鱼类物种数据库,由欧盟等机构资助,全球有9个国际机构管理(其中包括中国水产科学研究院),也是世界上访问频率最高的鱼类数据库,MySQL被用作该数据库管理系统的支撑软件[6]。
上述鱼类信息数据库虽然解决了鱼类信息存储和查询的问题,但仍存在诸多局限性:①数据库信息在归类上科学性欠缺,降低了用户查询有效信息的效率;②数据库存取方式无法满足海量数据存储和高并发查询的需求,导致存储效率低、查询响应慢;③信息检索方式单一,只提供文字检索,不支持图片、地图检索的功能;④鱼类信息数据来源缺乏可追溯性,不能方便快捷地追踪信息来源以确定信息的准确度;⑤大多数的数据库只是作为查询展示的窗口,数据主要来自政府、科研单位和高校等。这在一定程度上影响了网站的开放性,不能做到优质、丰富的鱼类资源共享。
为突破前述数据库的局限性,本研究中设计并构建了智能鱼类信息共享平台,提出了基于MongoDB的分布式鱼类信息数据库操作策略,数据库设计充分考虑了鱼类信息数据来源的科学性、可追溯性和实用性,可提供基于人工智能的图片检索等多种查询途径。实践表明,该平台实现了鱼类信息的高效存储和多重并发访问需求,有效地解决了海量数据存储和高并发访问问题,同时,该平台提供了文本、图片、地图等多种信息检索方式,可实现优质资源共享,并能为鱼类的准确识别及鱼类种类归属、溯源等鱼类数据库管理提供科学参考。
1 智能鱼类信息共享平台关键技术
1.1 系统架构
平台设计使用了SpringBoot结构的Java一体式框架,采用模块设计方法,按功能分类,将不同的功能在不同的模块中进行开发设计,较好地降低了平台架构的耦合度,利于模块间的调用,同时也提高了代码的可维护性。
平台的模块架构目录如图1所示。平台分为Common公共模块和Web前端交互模块。Common公共模块负责开发各个模块中均可能被调用到的业务;Web模块负责开发与前端进行交互的相关功能。平台将各个功能拆分成不同的模块,并把这些模块部署到Docker容器下,在分离各个功能的同时,不会因为这样的设计添加额外的配置,从而实现了后端的微服务架构。

图1 模块架构目录Fig.1 Module architecture directory
在Common模块中,实现了上传鱼类信息图片的FTP功能、用户中心的密码加密功能;在Web模块中主要是业务逻辑功能的代码,将其放在mainjava之中,将MVC设计模式中的用户个人中心板块定义在Web模块中的mainview包之中。总体上体现了各司其职,减少耦合。
平台前端采用Bootstrap框架,通过该框架的栅格特性,解决了不同浏览器间的兼容性问题,使网页无论在台式机、平板电脑和移动设备上均能获得较好地体验。
平台使用Vue组织与简化Web开发。Vue所关注的核心是MVC模式中的视图层,同时也能方便获取数据更新,并通过组件内部特定的方法实现视图与模型的交互。对于从后端传来的Json数据,运用Vue的for循环输出数据,实现视图与模型的交互,更加适应平台对于信息的展示[7]。平台信息展示流程如图2所示。

图2 平台信息展示流程图Fig.2 Flow chart of platform information display
智能鱼类信息共享平台系统架构如图3所示。其中,接入层展示平台的受众群体,包括用户、科研人员(合作者)和开发维护人员;展示层为前端的Web界面;应用层是后端的一些接口,完成信息的上传、审核和用户管理;服务层中包含与MongoDB、MySQL操作的接口;系统层包含平台运行的硬件和软件,软件使用SpringBoot内置的Tomcat 9、MongoDB 4.4和MySQL 8.0。

图3 智能鱼类信息共享平台系统架构图Fig.3 System architecture of fish information sharing platform
1.2 MongoDB数据库关键技术
由于平台框架采用SpringBoot,故使用Spring提供的MongoTemplate服务进行MongoDB的数据库操作。数据库基本操作增、删、改、查(CURD)使用Springframework包中的MongoTemplate数据库交互API完成,包括结构化Query查询操作类、结构化Criteria类、Update类和DeleteResult类[8-10]。
使用DBRefs完成文档的引用,保证数据库中的数据正确、有效,使数据库表间的引用清晰规范,方便数据库后期的维护。
采用阿里云提供的云服务器平台,以及Nginx反向代理和SpringBoot内置的Tomcat服务器组合完成网站部署。
1)服务器代码处理方法。在服务器的配置上,使用Nginx反向代理Tomcat的端口服务实现IP地址与域名的解析和映射功能,用户可以直接通过DNS域名解析的方式访问Web界面。
IDEA首先把后端Java代码通过Gradle配置及SpringBoot Application定义SpringBoot启动类入口,执行Gradle的BootJar命令进行Jar包打包处理。
2)云服务器上的部署。Linux通过FTP服务把可执行Jar包上传到服务器中,通过执行下列命令完成:
java -jar yulib-web-1.0.5.jar
把后端Jar包以java原生方式运行在8080端口。一旦退出命令行,8080端口也随之关闭,为把Jar包持久化运行在服务器上,通过执行下列语句达成持久化操作:
nohup java -jar yulib-web-1.0.5.jar >log.out &
3)后端接口的安全策略。Linux为了提高安全性和可访问性,在使用HTTPS协议时,要求前端JS代码不可以通过IP地址的形式访问后端,本平台通过Nginx反向代理端口实现域名的转发跳转操作,在Nginx进行8080端口配置。
1.3 检索方式与入口
鱼类信息平台的一级检索包括专题、类群、鱼汛。二级检索包括纲目、海水、淡水、形态、汛期、濒危、毒性和有无鳞片等。
专题检索按照鱼纲、地域和形态等对鱼类进行分类,平台采用鱼类学中以鱼的形态结构作为分类鉴定的主流分类方法,按纲目对鱼进行划分,使用了拉斯分类系统作为其中的一种分类方式,使检索更清晰;按照鱼所生活的水体环境,又将鱼分为了海水鱼、淡水鱼,目的是使用户可以通过鱼的生活区域,快速了解到鱼的信息;对于生活在中国不同海域的鱼类做了进一步分类,分为黄海、渤海、东海和南海4个海域,对淡水鱼按照北方区、华西区、宁蒙区、华东区和华南区进行了划分,以更好地为渔业生产提供信息服务。平台能根据区域查找指定鱼类信息,如查询黄花鱼在渤海海域中的汛期,则在“渤海”中检索,缩小了检索的范围。针对形态特征、鱼汛等情况,加入了形态、汛期、濒危和毒性等检索入口,方便用户对该类信息的检索[11-12]。
对类群的划分,侧重经济价值和实用性,将鱼分为有鳞片和无鳞片,以更好地了解鱼的经济价值、营养价值,有无毒性等,为渔业生产和人民生活提供服务。
平台还提供了图片、地图检索的功能,系统可根据用户上传的鱼的图片显示该鱼的相关信息;地图检索则是根据鱼所处的位置在地图中进行搜索,提供了直观的检索途径;另外,平台还设置了通过鱼的学名、中文名、高级检索进行查询,方便用户进行综合信息分析。系统检索主界面如图4所示。

图4 系统检索主界面Fig.4 Main interface of system retrieval
2 AI图片识鱼
平台应用人工智能技术实现了智能识鱼功能。针对用户使用图片进行查询鱼类信息的需求,平台集成了AI识鱼模块。用户上传需要查询的鱼的图片,系统将会出现该鱼的详细信息。该功能使用Python语言,通过卷积神经网络进行训练,为用户查询提供了一种方便有效的检索渠道。
2.1 数据的预处理
系统数据收集的图片主要来自实地拍照、书籍和互联网等,并对清晰度不足的图片进行了增强处理。本平台数据集包含中华鲟、海豚、鲨鱼、海龟和小丑鱼5种水生生物,每种生物图片200余张,共1 000余张图片。按照80%与20%的比例,分为训练集和验证集。
数据标注通过预先定义labels数组完成,通过append方法追加标签,设置label[index]的初始值为1.0,通过程序对图片进行自动标注,并通过标签完成对图像的分类。
在图片预处理过程中,主要使用的是OpenCV(open source computer vision library)技术,先通过cv2.imread()读取图片,由于输入的图片大小不一且像素较高,需将图像调整到某一尺寸,系统中将图片调整为64×64像素大小。通过调用shuffle函数,将读取到的数据集中的图片打乱顺序,避免由于识别单一图片而造成的数据不准确[13]。
2.2 算法模型
平台中使用的算法是人工神经网络中的卷积神经网络。
1)数据集的输入。数据训练中因为输入的是彩色图片,以RGB 3种颜色为基础,设置num_channels通道数为3。
2)卷积层的建立。定义3个卷积层,其中,每一个卷积层中卷积核大小规定为3×3,将卷积后的结果映射成1 024维的特征。构造一个权重参数,并将其进行随机初始化。构造一个biases参数,将biases参数的值规定为0.05。
3)对输出结果进行调优。调用dropout函数,进一步解决过拟合的问题,将keep_prob的值设为0.7,避免过度拟合。将学习率设为1×10-4,定义total_iterations=0,规定迭代从0开始。调整num_iteration的值,指定迭代次数,当规定的迭代次数完成以后,结束训练。可根据设备性能、图片大小及复杂程度设置迭代次数,从而使训练结果达到最优[14-15]。
4)输出结果的保存。通过调用Saver模块,将训练好的模型进行保存和读取,达到占用较小内存空间的目的。
5)试验结果。通过分析在训练过程中的输出结果可知,随着迭代次数的增加,训练集的准确率不断提高,虽然验证集的准确率在训练过程中有起伏,但总体呈现上升趋势。在现有的数据集训练下,模型的准确率达到92.67%。
本平台在对图像数据集处理中,鉴于图片数量有限,训练集的识别率略低于验证集。随着平台数据的积累,训练结果的准确率将逐步提升。由于所需的图像样本目前并无公开的数据集,未来随着本平台数据的积累,样本匮乏问题将得到有效解决,同时考虑对图像数据集采用数据增强、迁移学习等方法进一步丰富样本。
3 数据库结构
3.1 数据库表
通过调研和查阅大量的文献,对现有的鱼类数据库中各种鱼类相关信息进行了系统的归类,最终确定了16张表。每张表的结构相对独立,但信息可以交叉查询,为用户提供了一个科学、严谨、灵活、方便的信息查询环境。
在确定这些表的属性过程中,充分考虑了鱼类信息数据来源的科学性、实用性和可追溯性。该数据库的主表为鱼类基本信息表,通过该表又延伸出与鱼类信息相关的其他15张表(表1)。其中,鱼类的基本信息表是所有数据表的核心,鱼类基本信息表包括学名、俗名、同种异名、纲、目、科、图片、生态学特征、地理区域、形态特征、鱼汛、濒危和毒性等。

表1 鱼类信息共享平台数据库表Tab.1 Database table of fish information sharing platform
在基本信息中确定纲和目为鱼类的分类奠定了基础,使用拉斯系统将鱼类分为软骨鱼纲和硬骨鱼纲,归纳了十几个总目,并对鱼鳍、分解特征、繁殖、鱼卵、形态计量、疾病和参考文献等信息进行了更进一步地描述,涵盖了鱼类的主要信息,满足用户查询信息的需求[6]。
为更好地服务渔业生产和人民生活,平台可通过查找鱼汛信息,准确地掌握汛期,达到最大捕捞量;提供鱼类濒危及毒性等与人类生活息息相关的信息,可为分析鱼类濒危原因及保护措施提供有力依据,并为环境保护和饮食健康提供科学参考。
鱼类基本信息表与其他表间采用一对多的关系,使得各表关系清晰明了;各表均采用ID编号作为各表的主键,方便用户查询信息[16-17]。为了使信息可追溯,在每个表中增加了参考号的属性,方便用户追踪信息来源。
以黄鱼(Larimichthys)为例,在搜索框输入黄鱼,进入黄鱼信息页面,显示包括学名、俗名、
纲目、生物学特征、生活习性、区域和汛期等基本信息(图5)。用户还可根据需要使用其他检索入口查询更多信息。

图5 鱼类基本信息界面Fig.5 Fish basic information interface
3.2 数据采集
智能鱼类信息共享平台的数据库采用边建设边采集数据的方式。在建设数据库的同时,采集、管理数据,做到数据库建设、数据采集同步进行。
智能鱼类信息数据共享平台是一个面向用户免费开放的公益性数据库。平台信息主要来自两个方面:首先,通过向有关的政府部门、科研单位、高等院校等收集信息来完善数据库;其次,平台允许使用者上传鱼类相关信息,或对已有信息提出更改申请,由平台数据库管理员对上传信息进行审核,并更新至数据库中,使用者亦是建设者。鱼类信息数据采集流程如图6所示。
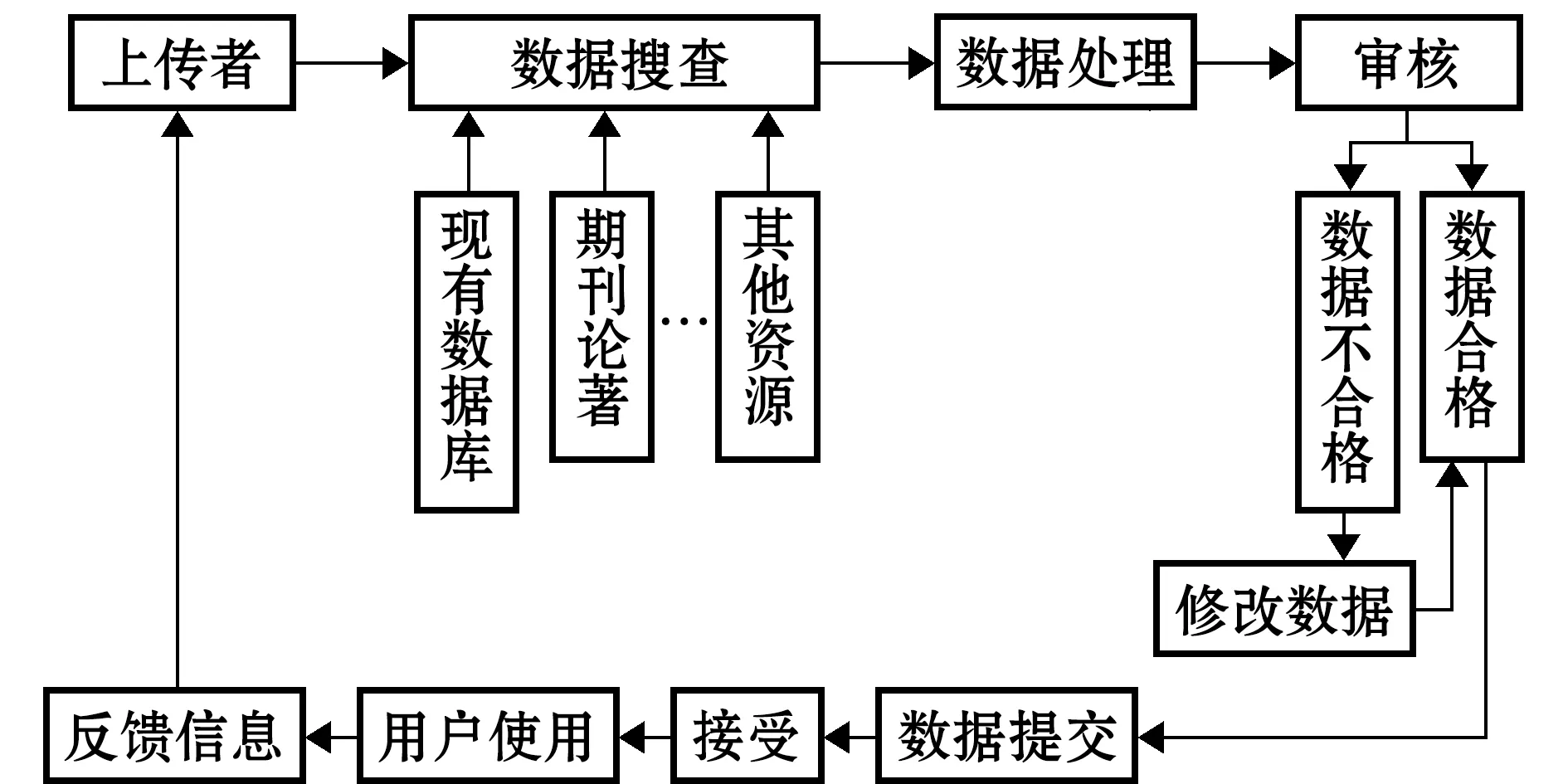
图6 数据采集流程图Fig.6 Flow chart of data acquisition
智能鱼类信息共享平台服务能力与数据库质量密切相关。为使数据库形成一个良好的网络信息环境,平台由专门管理员负责更新数据、监控数据库运行、优化数据查询功能、备份数据和检查数据一致性等工作。在使用者上传鱼类相关信息后,数据库管理员对相关信息进行审核,确保信息正确有效。
4 讨论
4.1 数据库管理系统的选择
随着鱼类信息数据的快速增长,海量信息的高效存储和检索成为渔业领域的一个重要课题。现有的鱼类数据库管理系统已难以满足海量数据存储和快速响应用户查询的需要。其主要原因是传统的数据库主要基于集中式存储和关系数据库体系结构,面对海量数据,在存储和高并发访问上显现出性能低、查询响应慢等问题。
目前,国内的鱼类信息数据库多采用关系型数据库管理数据,主流使用的关系型数据库管理系统有MySQL、Microsoft SQL Server、Microsoft Access等,如“我国水产种质资源信息系统”采用Access软件;王立华等[5]构建的“渔业科学数据共享平台”使用SQLServer 2000数据库管理系统;国际上使用较为广泛的FishBase数据库也是采用MySQL作为数据库管理系统的支撑软件[4]。其中,关系型数据库适合可以预先定义逻辑关系的数据,数据结构化是必要的,对于目前海量的非结构化数据管理显得力不从心,当海量数据需要将负载分配到不同的服务器上时,对于基于SQL语言开发的系统也是非常困难的。而非关系型数据库NoSQL适合处理结构松散、不相关、不确定和逐步发展的数据需求,能够更简单或者更快速地开展编程,具备管理大规模数据的功能。
本研究中,智能鱼类信息共享平台的构建,与前述的“我国水产种质资源信息系统”“渔业科学数据共享平台”“FishBase”数据库等系统使用的关系型数据库[18-19]不同,采用非关系型数据库MongoDB。该数据库是基于分布式文件存储的开源非关系型数据库管理系统,平台利用MongoDB的内存映射技术实现了高性能和高可扩展性,获得了较好的高并发访问效率;采用MongoDB的BinaryJSON管理松散的数据结构,使用其自动分片的功能存储海量数据,实现了复杂的数据结构管理,完成了多种查询功能,有效地解决了海量数据存储问题。
4.2 人工智能技术在鱼类图像识别中的应用
现有的鱼类数据库一般只提供文字检索方式,随着大数据及人工智能技术的发展,图像检索、地图检索方式的应用越来越广泛。本研究中构建的鱼类信息共享平台,通过人工智能的图像识别技术实现图像检索,该方式使用卷积神经网络进行训练,模型可根据图片大小及复杂程度设置迭代次数,使训练结果达到最优,准确率达到92.67%。与传统识别算法中复杂的特征提取和数据重建过程相比,卷积神经网络的权值共享网络结构降低了网络模型的复杂度,减少了权值的数量,鱼类图像可以直接作为数据输入,提高了识别的效率及准确率[20]。
本研究中构建的智能鱼类信息共享平台还实现了地图检索功能,通过使用腾讯提供的地图组件实现位置显示,将用户输入的鱼类位置信息存放于云服务器中,程序加载时,取出服务器中位置参数,实现在地图上显示鱼类相关信息。在提高检索效率的设计上,使用机器学习中的推荐算法,通过分析历史记录、高频检索词计算检索结果,并使用基于用户的协同过滤算法进行结果推荐。
综上,本平台通过用户上传的鱼类图片,即可识别该鱼的相关信息,并可在地图中根据鱼所处的位置进行搜索,满足了多样化的检索需求。
5 结论
1)本研究中设计的智能鱼类信息共享平台实现了海量鱼类信息存储和高并发访问需要,在当今数据快速增长情况下,使鱼类信息处理有较好的预期。
2)通过融合人工智能、地图检索等技术,丰富了智能鱼类信息共享平台的检索途径。用户可通过文本、图片、地图多种途径查询鱼的详细信息,更好地满足了使用者的需求。
3)智能鱼类信息共享平台面向所有用户免费开放。用户既可免费浏览所有内容,也可向数据库中添加鱼类信息,使用者亦是建设者,最终实现共享优质鱼类信息资源。
