一种硬件加速OpenCV 的图像处理方法研究
2022-07-11彭日光彭爽杜琦
彭日光 彭爽 杜琦
(中电长城圣非凡信息系统有限公司湖南计算机研发中心 湖南省长沙市 410000)
在基于OpenCV 的图像处理系统中,图像的处理几乎都是通过调用底层库函数来实现,为了提高系统的性能来满足最终用户的需求,需要提高图像处理库函数的计算性能,可以对图像处理库函数进行硬件加速。硬件加速的首要工作是对软硬件进行分区,软硬件分区的工作可以能会反复迭代,来满足系统的吞吐性能和灵活性要求,而开发人员最关注的部分往往是算法的最终实现和算法模块的优化。这就需要采用一种针对于函数库的硬件加速方法,减少系统设计的软硬件分区工作,而将系统设计的工作专注到算法的优化和软件功能实现上。
1 相关研究
对OpenCV 函数库进行硬件加速,常采用的开发流程:首先进行软硬件分区,来决定将哪些部分用于软件实现,哪些部分放入硬件加速;然后将划分为硬件实现的功能使用RTL(寄存器传输级)代码来开发,或是使用HLS(高层次综合工具)将C/C++代码综合成中可实现的IP;再是搭建DataMover和接口;最后才是进行驱动程序的开发和上层应用软件开发。
对于划分到硬件的库函数硬件加速,实际上是将函数库代码转化为可综合的代码,通常采用两种实现方法:利用FPGA 厂商或者第三方提供的可综合的图像函数库中的IP代替原始的库函数,这些专用的函数库IP 能很好地综合为RTL 代码,进而实现图像处理加速;另外一种方法工程师为实现对应的函数库功能,自己编写函数库对应的代码,通过使用RTL 代码来开发。如果采用第一种方法,有可能需要购买厂商或者第三方提供的专有函数库,并且提供的函数库也可能并不开源,开发人员还需要熟悉硬件函数库功能,以及调用的接口;而采用第二种方式自己编写RTL 代码来改写库函数,又存在不能充分利用原始OpenCV 函数库的计算特性,自己编写的函数的计算效率远低于原有库函数的计算性能,并且底层库函数之间存在调用和依赖关系,如果要将整个调用层次的底层函数都改写成RTL 代码,工作量非常的大。此外,无论是采用厂商或者第三方提供的IP,还是自己编写RTL 代码来综合成IP,这两种方式都需要软硬件开发人员同时参与,并且还需要进行手动软硬件的集成,开发流程比较复杂,开发效率比较低。
针对现有技术的不足,本论文提供了一种基于Xilinx SDSoC 平台,对OpenCV 函数库中图像处理函数进行硬件加速的方法,该方法在保持原有函数库框架不变的基础上,提升了计算性能,而且不需要硬件人员参与,也不需要进行手动软硬件集成,简化了开发流程,提高了开发效率。为了实现对函数库的硬件加速,首要工作就是需要对软硬件进行协同设计。
2 软硬件协同设计
借助Xilinx 提供的SDSoC 开发工具,将需要加速的应用程序函数分配到FPGA 上执行,使之成为硬件加速函数,然后通过工具自动搭建DataMover、软件驱动程序和硬件连接接口,使得软件函数和硬件函数之间通讯工作得到简化,工程师将工作聚焦到C/C++应用层面的算法工作上。基于SDSoC 的OpenCV 库函数软硬件协同设计开发流程如图1所示。

图1:SDSoC 软硬件协同设计流程
首先根据客户需求,定义C/C++的图像处理应用系统;开发应用程序,通过对多个库函数的调用来实现系统功能;在所调用库函数中,选择哪些库函数需要硬件加速,哪些库函数采用现有的软件实现,即进行软硬件分区;库函数硬件加速则是根据软硬件划分的结果,将需要硬件加速的库函数,通过采用本论文提出的库函数硬件加速方法,将库函数移到应用层实现;库函数被移植到应用层之后,再通过Xilinx 提供的SDSoC 工具,将应用层加速函数放入可编程逻辑中加速,该工具还会自动搭建DataMover、配置软件驱动程序、生成软硬件系统连接接口和相关的库,最终生成PL 上可执行的比特流文件和PS 上可执行的ELF 文件;最后将生成的文件下载到嵌入式设备上运行测试,如果测试的性能不达标,可以快速选择不同的硬件加速的功能块,探索不同的软硬件分区方案,或是通过pragma 指示符等手段来指导工具产生不同的系统配置方法来进一步优化系统设计。软硬件协同设计开发流程中的一项关键工作就是将OpenCV 库中需要硬件加速的函数,在保持库框架不变的前提,使之加载到FPGA上执行。
3 库函数硬件加速
在Xilinx 提供的SDSoC 平台基础之上,对库中图像处理函数进行硬件加速,首先需要识别出库中需要进行硬件加速的高强度计算功能的库函数,然后采用特殊的技术处理方式,将库中的需要加速的函数移植到应用代码中去实现,最后再利用FPGA 来对应用程序的高强度功能代码进行硬件加速,库函数加速流程如图2 所示。

图2:OpenCV 库函数加速流程
如流程图2 所示,对库中图像处理函数进行硬件加速,包括以下步骤:
(1)将库中需要进行硬件加速的图像处理函数的复杂运算代码抽取出来,封装成新的函数,确保新的函数中没有再次对库中的其它函数进行调用,都是基本的算术逻辑运算;
(2)在抽取的硬件加速的图像处理函数所在文件中定义与新抽取的函数对应的函数指针类型,函数指针类型的函数参数应与新抽取的函数的参数保持一致;
(3)在抽取的硬件加速的图像处理函数所在文件中定义函数指针类型对应的静态全局变量(函数指针类型的实例);
(4)针对定义的静态全局变量,定义一个可供应用代码调用的赋值函数,用来给对应的静态全局变量赋值,并且确保赋值函数的函数参数的类型就是静态全局变量对应的函数指针类型,这样应用程序就可以调用库中的赋值函数,对静态全局变量进行赋值;
(5)修改库中步骤(1)确定的需要进行硬件加速的图像处理函数,注释掉其对新抽取的函数的调用,将原有的调用参数传递给步骤(3)中定义的对应的函数指针类型的静态全局变量,从而改成对静态全局变量的函数指针的调用;
(6)重新交叉编译库,生成动态链接库,供应用层代码调用;
(7)在应用代码中,定义需要硬件加速的函数,其函数参数与步骤(2)中定义的函数指针类型的函数参数保持一致,其完成的功能与步骤(1)中抽取出来的函数的功能相同,并且确保其内部不再调用库函数,这样就将原来库中完成的功能,改成应用代码来实现;
(8)应用代码Main 函数在初始化的时候,首先调用动态链接库中的赋值函数,将步骤(7)中定义的硬件加速函数作为参数传给该赋值函数,从而实现对库中对应静态全局变量的赋值,在应用代码对库中图像处理函数进行函数调用时,库中硬件加速函数的内部代码会调用静态全局变量的函数指针,由于此时静态全局变量的函数指针已被赋值函数赋值为应用代码中的硬件加速函数,从而实现对应用代码中的硬件加速函数的调用;
(9)通过Xilinx SDSOC 开发平台工具,将步骤(7)中定义的硬件加速函数改成由FPGA 硬件逻辑来实现。
步骤(1)到(6)在保持OpenCV 低层库框架不变的基础上,通过函数指针调用替换原有功能函数,生成新的动态库;步骤(7)和步骤(8)在应用层完成原有低层库函数的功能;步骤(9)实现对应用层函数的硬件加速。
4 实验验证
使用Xilinx SDSoC 开发环境集成的高层次综合工具Vivado HLS在ZYNQXC7Z020-2CLG400I 平台上对OpenCV 自适应阈值库函数进行硬件加速,并且对实验结果进行分析,来对比本文提出的硬件加速方法与原有软件实现方法,验证本文提出的硬件加速是否能够提高系统的计算性能。
Vivado HLS 工具提供100MHz 的目标时钟频率,对24位深度,每行640 个像素,每列480 个像素的JPG 格式的图片进行均值滤波处理。通过使用工具提供的pragma 指示符来对硬件指令进行优化,使得图片的像素矩阵能够被并行化处理,在计算滤波窗口像素均值时,采用滑动窗口技术,使得硬件函数内执行指令完全达到流水线化(II=1)。
4.1 库函数加速实现
按照库函数硬件加速的流程图,对库中的自适应阈值函数进行硬件加速,具体实施步骤如下:
(1)将adaptiveThreshold 函数内部的复杂运算逻辑功能,抽取出一个新的函数;
int sw_adaptiveThreshold(pix_t gray[][MAX_WIDTH],pix_t in_pix[][MAX_WIDTH], pix_t out_pix[][MAX_WIDTH],short int height, short int width, int _Idelta, int _MaxValue);
(2)定义函数指针类型,其函数参数与新抽取函数的函数参数保持一致;
typedef void (* pfun_adaptiveThreshold)(pix_t gray[][MAX_WIDTH], pix_t in_pix[][MAX_WIDTH], pix_t out_pix[][MAX_WIDTH], short int height, short int width, int _Idelta, int_MaxValue);
(3)定义一个该函数指针类型的静态全局变量;
static pfun_adaptiveThreshold pfun_instance;
(4)定义一个可供应用程序调用的库函数,用来对静态全局变量赋值,并且函数参数类型就是上述定义的函数指针类型;

(5)修改库中需要进行硬件加速的图像处理函数,将其内部改成对静态全局变量函数指针的调用;


(6)重新交叉编译库,生成新的动态链接库,供应用程序调用;
(7)在应用代码中,定义需要硬件加速的函数,函数参数与步骤2 中定义的函数指针类型的函数参数保持一致;


(8)在应用代码中调用动态链接库内的赋值函数,将硬件加速函数作为参数传给该赋值函数,然后调用库中的图像处理函数进行图像处理;

(9)最后在Xilinx SDSOC 开发平台中,将硬件加速函数hw_adaptiveThreshold_impl 改成由FPGA 实现的硬件加速函数。
4.2 应用层实现
库函数被移植到应用层之后,如果针对于特定的应用场景进行加速,则可以对移植后的应用程序进行定制,只需要将上层函数的参数接口和底层库中的函数接口保持一致即可,这样也给应用程序提供了很大的优化空间。自适应阈值应用层硬件加速包括两个硬件函数,一个为根据窗口大小计算窗口像素均值的底层函数,另外一个是顶层函数,通过滑动窗口技术,计算像素矩阵中每一个像素的均值。样例函数如下所示:



4.3 对比分析
在将图片从24 位像素格式转换成8 位像素格式之后,循环10 次进行均值滤波计算,来比较采用本文提出加速方法的均值滤波函数计算时间和原有软件实现的均值滤波函数计算时间。对于均值滤波硬件加速函数,首先可以通过Vivado HLS 性能评估工具,对硬件函数进行时间性能分析,从图3 性能评估结果可以看出,采用本文方法的均值滤波函数,图片所有像素均值计算一共为307200(640*480)个时钟周期,即图片的每一个像素计算其均值只需要一个时钟周期的处理时间。可以看出,虽然需要根据窗口大小来计算像素均值,但计算窗口像素均值都在一个时间周期内完成,对像素矩阵的处理,指令已经达到流水化。
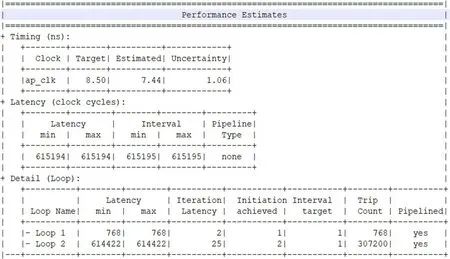
图3:均值滤波硬件函数性能评估
在实际硬件平台上进行性能对比测试,使用原始函数库进行计算,10 次均值滤波计算时间为3S 左右,而采用本文提出的硬件加速函数进行计算,10 次均值滤波的处理时间仅为0.3S 左右。从而可以看出,通过本文的硬件加速方法,计算速度提高了10 倍左右。在处理数据的准确性方面,通过对两种方法生成图片的像素进行比较分析,下图左边为软件均值滤波的处理结果,右边为硬件加速滤波的处理结果,通过对比图4 图像矩阵的像素值,对图片中心区域的处理,硬件加速处理的结果和软件处理的结果几乎完全一致,满足设计时的准确性要求。

图4:均值滤波软硬件函数结果对比
5 结论
本文研究使用基于SDSoC 软硬件协同设计方法结合逻辑可编程FPGA,实现对OpenCV 库函数硬件加速,来解决实时图像处理软件速度性能瓶颈的问题。该研究方法在保持现有库函数框架不变的前提下,通过将库函数实现移植到应用层,再利用工具硬件加速其应用程序,来提高实时图像的处理性能。将该研究方法应用于某手机玻璃厂抓取打磨玻璃的工程项目中,对图像处理的边缘检测功能进行硬件加速,计算速度相比原有的软件实现,性能提高3 倍以上。更重要的是,采用该研究方法,无需硬件工程师参与,软件工程师就能够实现硬件加速功能,并且无需关注软硬件接口,只需要将重点工作专注到算法的优化和软件功能实现上。
