基于边缘计算的实时目标检测系统的研究与实现
2022-07-10朱亚东洋李心超魏文豪李婧莹高梦楠于沛
朱亚东洋,李心超,魏文豪,李婧莹,高梦楠,于沛
(1.北京石油化工学院信息工程学院,北京 102617; 2. 北方自动控制技术研究所,山西 太原 030006;3.中国消防救援学院,北京 102202)
目标检测是对图像或视频中的目标进行分类和定位,广泛应用于城市安防、工业质检、智慧工厂、机器人、卫星遥感、自动驾驶等领域[1-2]。应用目标检测技术可有效替代人工进行检测,将工作人员的时间和精力从简单的重复性劳动中释放出来。近年来随着机器学习技术特别是深度学习技术的不断发展,卷积神经网络在目标检测中得到广泛应用,使得目标检测的准确性得到了极大地提升[3]。但视频监控面临的场景千差万别,不同设备的景深、角度、现场的光照等条件均存在着不确定性的变化。目标检测任务目前在很多领域和应用方向上仍然是一项具有挑战性的任务,有着很大的研究空间和发展潜力[4-5]。
近年来,随着芯片技术的发展,以深度学习为代表的人工智能技术摆脱了服务器、GPU等高性能计算设备的限制,在FPGA[6]、ASIC[7]等嵌入式边缘设备上运行。将边缘计算应用到目标检测系统中,依托边缘计算平台,承接部分服务器端数据处理和检测能力[8-10]。通过边缘侧的数据处理,在图像采集端将检测目标识别出来,一方面可有效减少中间数据的传输;另一方面可摆脱对大型服务器、GPU集群的依赖限制,便于目标检测系统的灵活布设,满足小场景中特定目标检测的使用需求[11]。
针对在小场景中灵活布设目标检测系统的需求,提出基于边缘计算的实时目标检测系统。介绍了如何应用边缘计算平台配合云端平台进行目标检测,以及在该构架下边缘计算平台和云平台所需要实现的功能。介绍了系统所应用的SSD目标检测算法及边缘计算平台。应用MobileNet模型对SSD目标检测算法进行优化,使其更适合应用在边缘计算平台上。并对搭建的基于边缘计算的目标检测系统进行了实验及测试。
1 系统概述
应用边缘计算配合云平台进行目标检测的总体结构框图如图1所示。
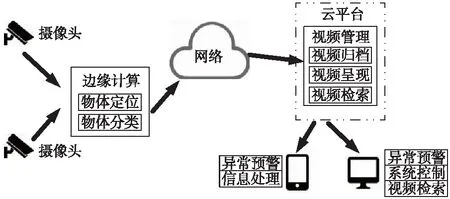
图1 基于边缘计算和云平台的目标检测系统总体框图
将摄像头架设在固定位置或机器人等移动平台上,采集被检测的人或物体的图像数据。通过边缘计算平台上搭载的视频智能分析算法进行目标检测,将识别的图像和识别结果通过有线或无线网络传输至云端平台。在云端平台对采集的图像进行归档、存储等操作;将分析结果实时推送至手持客户端,实现异常情况的预警;也可在云端控制中心进行可视化展示,有助于管理人员对异常情况的实时监管。研究针对边缘计算平台上的视频智能分析展开。
2 模型的构建及优化
2.1 SSD目标检测模型
SSD是一阶目标检测模型,其主干网络是在ImageNet上针对图像分类预训练后的VGG-16模型[12]。SSD模型的提出者对其进行了一些微调,使其能用于检测任务,其中包括使用卷积层替换全连接层、移除dropout层、使用扩张卷积替换最后的最大池化层[13],如图2所示。
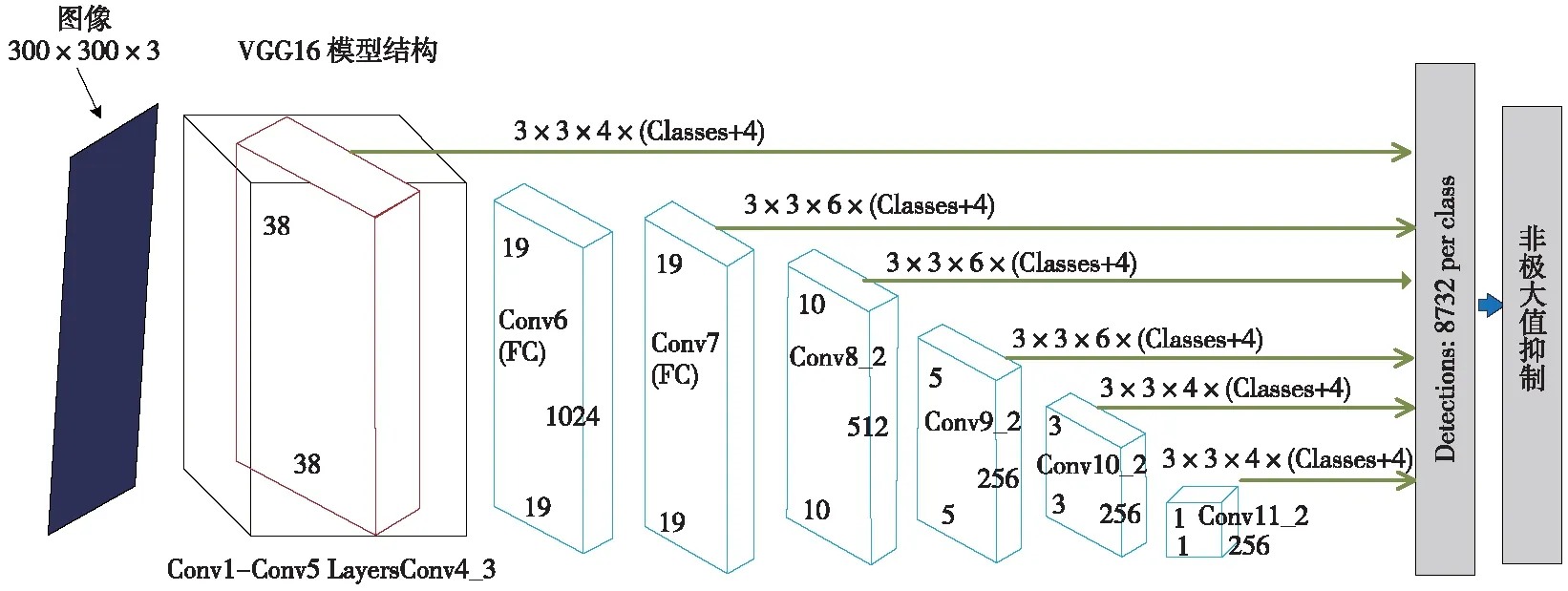
图2 应用VGG-16主干网络的SSD模型
SSD模型没有使用K均值聚类来发现宽高比,而是人工定义了一个宽高比集合,用于每个网格单元位置的B个边界框。对于每个边界框,都会预测其在边界框坐标(x和y)以及尺寸(w和h)上离锚框的偏移量。在计算损失时,会将有最高交并比的每个基本真值框与锚框进行匹配,并将该框定义为负责做出预测的框。也会将基本真值框与交并比超过某个定义阈值(0.5)的任何其他锚框进行匹配,从而不因为这些锚框并不是最佳的而惩罚这些优良预测。为了能进行多个尺度的预测,SSD输出模块会逐步对卷积特征图进行下采样,间歇性地得到边界框预测。
2.2 Jetson Nano嵌入式平台
英伟达Jetson Nano是一款嵌入式计算设备,如图3所示。

图3 英伟达 Jetson Nano嵌入式开发板
该设备主要用于开发需要高处理能力的嵌入式系统,用于深度学习、机器学习和图像/视频处理应用。Jetson Nano采用128核CUDA Maxwell GPU、四核ARM A57 CPU 1.43 GHz、4GB LPDDR4内存、472 GFLOPS处理能力。由于Jetson Nano功耗小于5 W,内置GPU内核,与其他嵌入式板相比成本较低。Jetson Nano是业内先进的AI计算平台,使用Linux操作系统,可以快速执行机器学习的算法,并可同时执行多个神经网络。可用于嵌入式物联网应用、入门及网络录像机、家用机器人与完整分析功能的智能网关。
3 优化的MobileNet-SSD目标检测算法
传统的SSD算法使用多尺度特征图进行目标检测,可以提取多尺度特征,减小后续各层的大小,提高检测精度和速度,但实时检测的能力仍然较差。MobileNet[14]算法使用深度可分离卷积层作为基础层网络,其在考虑模型大小的同时优化了延迟,但是对于目标检测而言,准确性仍然很低。因此,提出了2种网络的结合以同时实现实时和高精度检测。笔者应用优化后的MobileNet-SSD模型进行目标检测[15]。
MobileNet模型是谷歌提出的一种非常适合计算能力较低的嵌入式视觉应用的基础架构。MobileNet体系结构使用深度可分离卷积而不是标准卷积。与具有相同深度的普通卷积网络相比,大大减少了参数的数量。MobileNet将激活函数ReLU替换为ReLU6,并在新附加结构的每一层中加入批处理归一化层,以防止梯度消失。MobileNet很容易训练,其训练和推理花费的时间也较少。与VGG-16和其他可用架构相比,这使得网络更加可靠。优化后的MobileNet-SSD主干网络如图4所示。
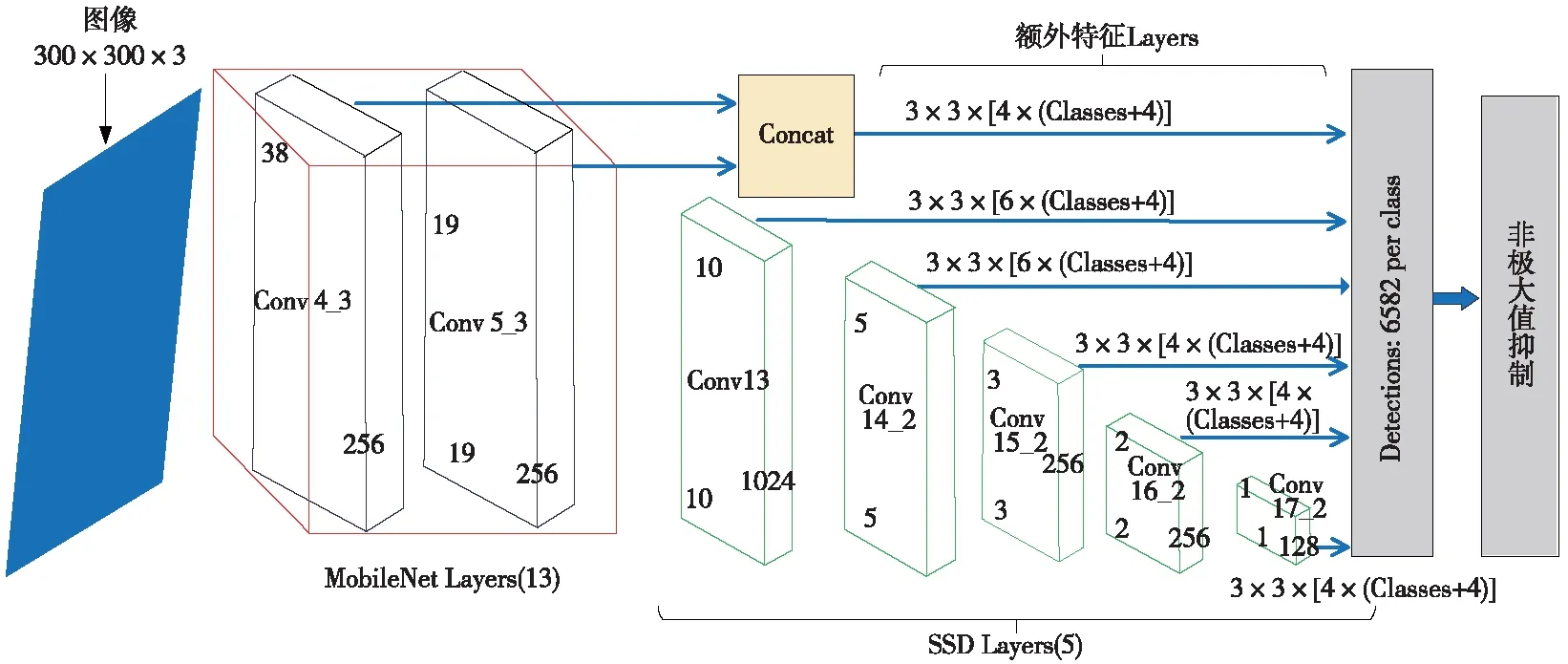
图4 优化后的MobileNet-SSD主干网络
从图4可以看出,优化后的MobileNet-SSD网络由21个卷积层组成。用于检测的目标特征层为Conv 4_3、Conv 13、Conv 14_2、Conv 15_2、Conv 16_2和Conv 17_2。该网络增强了新加入的浅卷积层Conv 5_3,以检测更小、更密集的目标。由于Conv 4_3和Conv 5_3 的特征图在尺寸上是不同的,所以为了得到相同的输出尺寸,Conv5_3之后是1个2倍上采样的反卷积层。最后,2种卷积层都是通过应用1×1×256卷积减少维数和特征重组,生成最终的融合特征图,如图5所示。
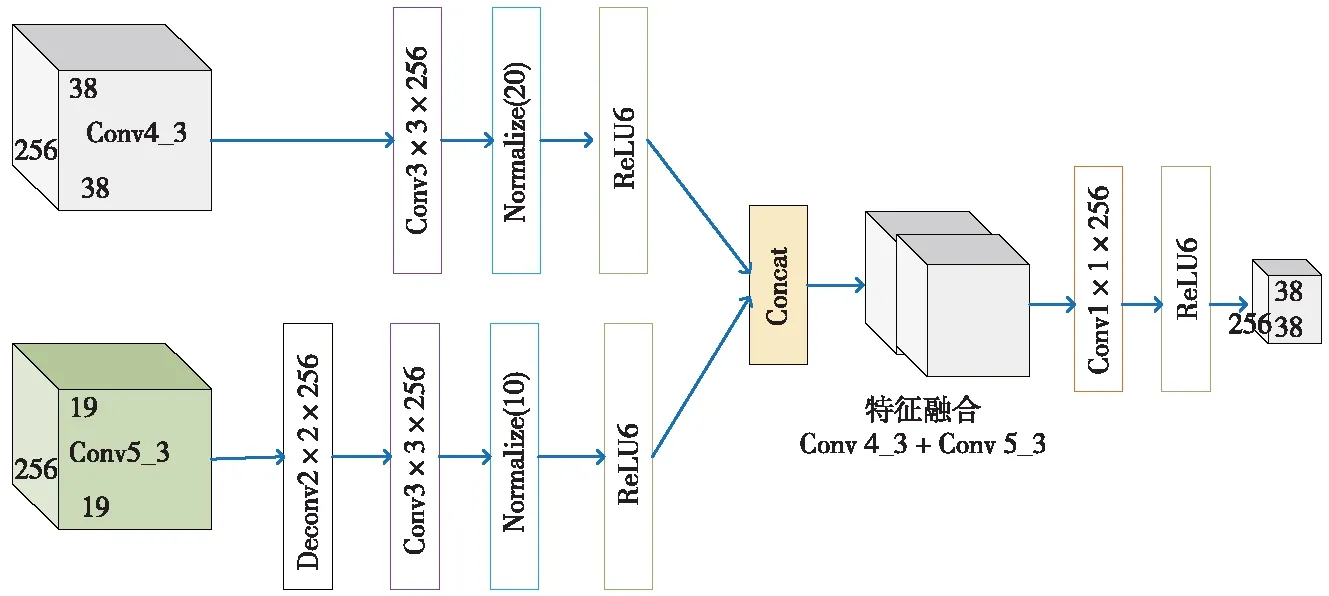
图5 特征融合连接模型
模型引入1个特征融合拼接模块,将上下文信息注入到较浅的Conv 4_3层,是检测小尺度密集目标的重要补充。通过将卷积前向计算中捕获的语义信息返回到较浅的区域,提高了小尺度目标的检测性能。在设计最有效的特征融合拼接模块的同时,探索了不同的特征融合方法。最终,选择Conv 4_3和Conv 5_3浅层进行融合,在小尺度检测时引入较少的背景噪声。Conv 5_3后的层具有较大的接收域,在检测小规模目标时引入更多的背景噪声。
同时进行逐深度卷积和逐点卷积称为深度可分离卷积。MobileNet的标准卷积和深度可分离卷积如图6所示。
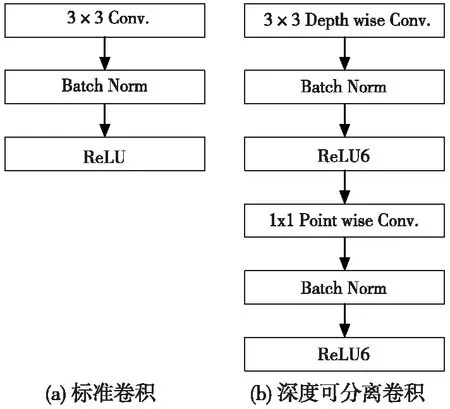
图6 标准卷积和深度可分离卷积
由图6中可以看出,深度可分离的卷积结构由2层组成,即逐深度卷积D和逐点卷积P。逐深度卷积D层使用3×3的核,逐点卷积P层使用1×1的核。每个卷积的结果是通过批处理归一化算法和ReLU6激活处理。
激活函数ReLU6是非线性的,在性能上也优于sigmoid函数。该算法支持数据分布的自动调整。MobileNet极大地降低了复杂性和计算量,还加快了训练过程。ReLU6激活函数表示为:
r(z)=min(max(0,z),6)
4 实验结果
4.1 数据集及实验环境
应用的优化算法在Pascal VOC数据集上进行预训练,并在安全帽数据集SHWD上进行迁移学习和测试。Pascal VOC是由20个类别组成的数据集。在训练过程中,模型使用Pascal VOC中的5011张图像进行训练。很多优秀的计算机视觉模型如分类、定位、检测、分割、动作识别等都是基于Pascal VOC数据集上训练的。SHWD 提供用于安全帽佩戴和人头检测的数据集。包括7581张图像,其中9044个人体安全帽佩戴标注和111514正常头部标注。
模型的训练在工作站上进行,工作站的配置如表1所示。模型的推理在工作站和Jetson Nano嵌入式平台上进行。在Jetson Nano嵌入式平台上推理的结果如图7所示。
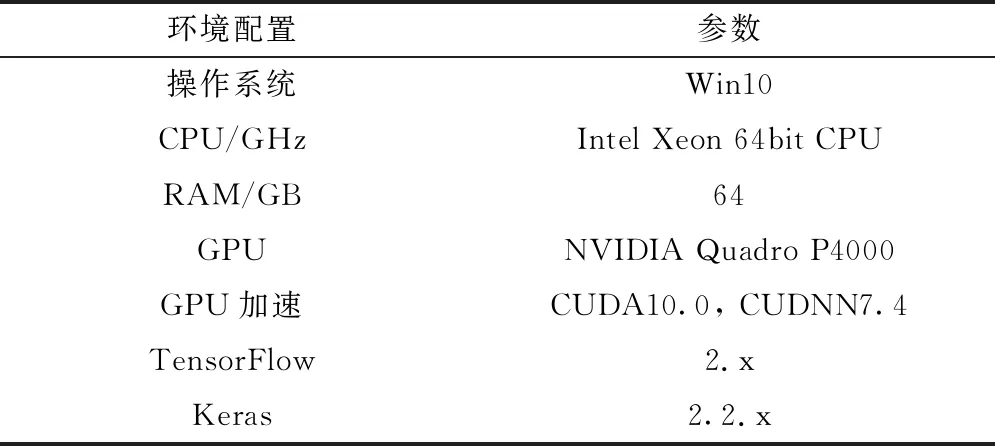
表1 工作站配置

图7 模型在Jetson Nano嵌入式平台上推理
4.2 检测速度对比
为了测试模型在嵌入式平台上的实时检测效果,应用的模型在低成本的边缘设备上进行了测试。模型在Quadro P4000 GPU上进行训练后,在英伟达Jetson Nano评估板上进行推理测试。一般来说,在相同的内存和频率条件下,更多的CUDA核代表更高的计算能力。Jetson Nano的核数为128,仅为Quadro P4000 (1792核) GPU的1/14,但是Jetson Nano消耗的能量更少。
在Pascal VOC测试数据集上测试的模型检测速度(帧/s)的对比结果如图8所示。通过使用相同的视频进行对比验证,应用的模型在Jetson Nano上的运行速度为32 fps,这比SSD 300、Yolov3、Tiny Yolov3和改进的Tiny Yolov3 等模型要高得多。
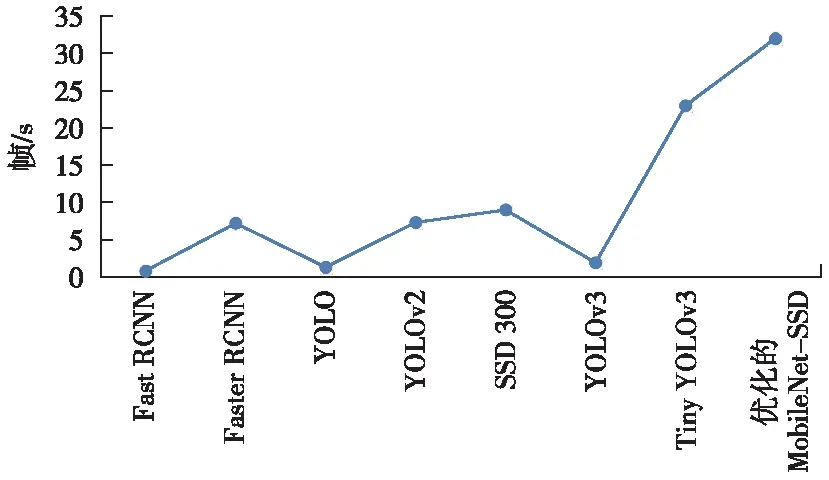
图8 不同模型检测速度的对比(在Jetson Nano嵌入式板上运行)
4.3 检测结果
为了评价模型的鲁棒性,采用目标检测中常用的评价指标如查全率、查准率、平均精准度(AP)、检测速度(帧/s)和内存占用来对模型进行评价。
在Pascal VOC测试数据集上获得的平均精度与其他模型的比较如表2所示。通过对比发现,应用的模型具有较好的检测性能,在Pascal VOC测试数据集上,AP值达到80.4%,比SSD 300、Yolov3和Tiny Yolov3分别提高了+9%、+2.3%和+11.8%。从评价结果可以看出,Tiny-Yolov3的速度是220 帧/s,而优化的模型只有155 帧/s。同时,优化的模型文件为23.6 MB,比Tiny Yolov3模型文件小得多。总体对比,该模型优于改进的Tiny Yolov3模型。
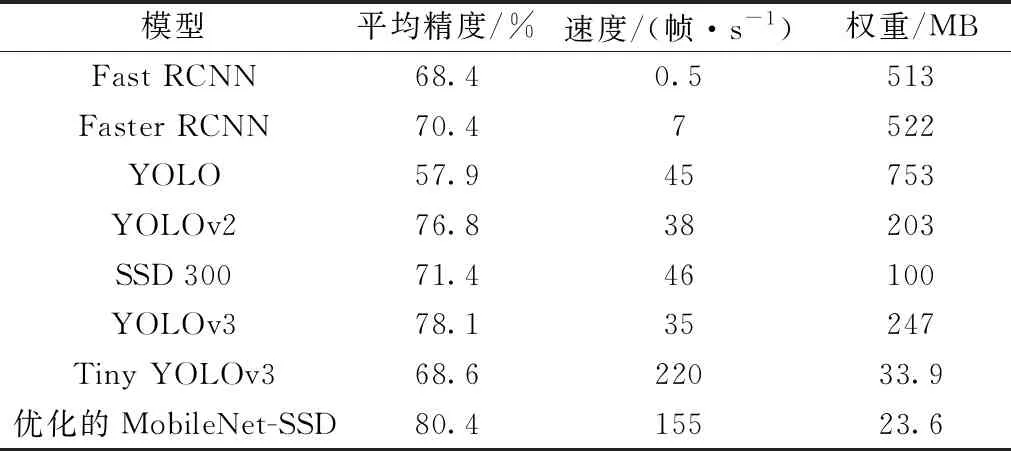
表2 不同模型的精度对比(在工作站上运行)
通过模型针对视频监控环境下工人的安全帽佩戴进行检测。为了更直观地测试算法的有效性,分别采集了施工工地和发电厂的监控视频进行测试,结果图9所示。

图9 SSD模型和优化的MobileNet-SSD模型对比
通过对比可以发现,模型在保证实时性的前提下,检测小尺度和密度较大的目标时能获得更好的效果。
5 结论
由于多尺度目标图像的分辨率和信息有限,在低端边缘设备上进行可靠的目标检测是一项非常具有挑战性的任务。这是因为现有的模型无法在检测准确性和实时性上做好平衡。通过引入特征融合模块,在优化的MobileNet-SSD网络中添加上下文信息,提高了目标检测的实时性。该模型减少了网络参数的数量,而与常用的目标检测模型相比,检测精度也有所提高。通过在Jetson Nano嵌入式板上运行该模型,可有效地实现目标实时检测。实验结果表明,该模型在Pascal VOC测试数据集上的平均精度达到80.4%,在边缘设备Jetson Nano嵌入式板上,能够以32帧/s的速度实时运行。
