基于DeepLab v3+模型的高分辨率影像养殖用海信息提取
2022-07-09何显锦蒙方鑫北部湾环境演变与资源利用教育部重点实验室南宁师范大学广西南宁50001广西地表过程与智能模拟重点实验室广西南宁50001南宁师范大学地理科学与规划学院广西南宁50001
何显锦,蒙方鑫 (1.北部湾环境演变与资源利用教育部重点实验室(南宁师范大学),广西南宁 50001;2.广西地表过程与智能模拟重点实验室,广西南宁 50001;.南宁师范大学地理科学与规划学院,广西南宁 50001)
广西壮族自治区北部湾经济区是继珠江三角经济区、长江三角经济区、环渤海经济区之后的又一个具有重大发展意义的国际区域经济合作区。随着北部湾经济区的快速发展,海域使用也发生了翻天覆地的变化,在获取经济效益的同时,也将对周围的生态环境安全产生重要影响。及时、准确发现获取海域使用动态变化信息,不但直接影响海域管理部门对海域使用的有效执法监察和行政管理,也为海域资源的可持续利用与发展提供决策支持。然而,由于整个经济区的海域范围广、面积大,人工解译获取信息速度慢,而传统的机器学习方法由于不能自动提取原始特征信息,导致获取信息精度不够高,无法更好地为沿海开发利用提供技术支撑与服务。
近年来,随着科技的迅速发展,深度学习在影像识别、人工智能等方面发挥着越来越重要的作用。深度学习作为机器学习中的一个新兴领域,可通过逐层特征提取的方法、逐层学习输入数据的方式,使得数据分类或预测的问题更加容易实现,并且可以从少数样本中集中学习数据集的本质特征,还可以通过学习深层非线性的网络结构,实现对复杂函数的逼近。深度学习从大类上可以归入神经网络,通常由多层神经网络构成。其中,卷积神经网络(Convolutional Neural Network,CNN)是目前深度学习技术领域中最具有代表性的神经网络之一,可以通过一系列方法,成功将数据量庞大的图像识别问题不断降维,最终使其能够被训练。CNN能够自动获取特征信息,具备更强的泛化能力,相对传统机器学习方法能够处理更复杂的分类问题,极大地提高了分类精度;另一种深度学习方法全卷积神经网络(Fully Convolutional Networks,FCN),则是通过去除CNN的全连接层,将传统CNN中的全连接层转化成一个个的卷积层以及添加上采样操作恢复影像尺寸的方式,在减轻网络复杂度的同时实现了影像的像素级分类。但为了得到更深层次的语义信息,FCN分类方法采用池化层扩大感受野,不可避免地造成空间信息的损失。基于此,众多更先进的深度学习网络模型应运而生,如SegNet、U-Net、DeepLab系列。DeepLab v3因其清晰的网络结构和利用并行空洞卷积所捕获多尺度信息的特点,在影像信息解译提取方面得到了广泛应用。例如,司海飞等提出一种新的轻量化网络结构MobileNetV2结构,它替代了DeepLab v3原有的特征提取器,改进的DeepLab v3网络模型综合性能更强,更适合对分割性能要求较高的快速分割网络;韩玲等利用DeepLab v3提取高分辨率遥感影像道路,结果显示该模型能够较好地提取高分辨率遥感影像中的道路边缘特征,相比其他道路提取方法具有更高的提取精度和更加完整的道路信息,正确率可达到93%以上;何红术等提出改进的U-Net网络语义分割方法,借鉴经典U-Net网络的解编码结构对网络进行改进,改进后的U-Net网络结构在mIoU、精准率和Kappa系数指标上均高于SegNet和经典U-Net网络;蔡博文等利用深度卷积神经网络对影像特征进行提取,并根据其邻域关系构建概率图学习模型,进一步引入高阶语义信息对特征进行优化,实现不透水面的精确提取。
尽管深度学习在各个领域的应用不断深入,但是对于用海信息提取的研究较少,且提取的对象多为均质地物。鉴于此,笔者利用深度学习模型,对养殖用海中的网箱、浮筏等非均质地物进行提取,阐明深度学习方法在海域信息提取应用过程,并通过对传统机器学习方法,说明深度学习方法所具有的优势,为高精度监测北部湾海域使用状况提供一套科学有效的方法。
1 材料与方法
钦州湾位于北部湾顶部,广西沿岸中段,东邻钦州市钦州港区,西邻防城港市企沙半岛,北与钦州市钦南区接壤,南临北部湾,湾口门宽约为29 km,纵深约为39 km,海湾面积约为380 km。钦州湾是广西的传统大蚝养殖基地,近年来养殖区域面积不断扩大,大蚝养殖也得到爆炸式增长。钦州湾顶部为茅尾海,是以钦江、茅岭江为主要入湾径流的河口海滨区。东南部为三娘湾海域,有大风江淡水汇入,其特点是岛屿棋布、浅滩众多,创造了适宜多种海洋生物生存的不同环境。由于有钦江、茅岭江淡水汇入,因此饵料充足、鱼类资源丰富,并且钦州湾年均水温21.3 ℃,处于最适合生蚝生长的水温(15~25 ℃)范围内。同时,湾内自然灾害较少,贴合生蚝养殖要求的无台风、无污染条件。
该研究所用数据主要为影像数据,通过谷歌地球引擎平台获取了2期空间分辨率为0.5 m的钦州湾海域遥感影像。其中,2011年影像为同一时相影像,2019年影像则由多个时相影像拼接而成(图1)。另外,该研究利用与影像相匹配的钦州湾海域矢量数据,裁剪出钦州湾海域,这样可以减少其他地物对目标地物信息提取的干扰。

图1 钦州湾影像Fig.1 Images of Qinzhou Bay
基于DeepLab v3+模型的影像语义分割
模型介绍。Deeplab语义分割网络在2015年被提出,该模型是给输入的图像在像素级别进行语义标签的分配。目前,Deeplab经历了v1、v2、v3以及v3+的不断发展,其性能更是得到了不断地完善。DeepLab v3+最大的特征就是引入了空洞卷积,在不损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。同时,模型为了融合多尺度信息,引入了语义分割常用的encoder-decoder形式。DeepLab v3+结合了空洞空间金字塔池化(ASPP)和多比例的带孔卷积级联或并行来捕获多尺度背景两者的优点,在没有添加任何后端处理的情况下在PASCAL VOC 2012数据集上验证可达到89% mIoU。该研究采用最新的DeepLab v3+模型进行钦州湾海域使用状况的信息提取,模型架构如图2所示。

图2 DeepLabv 3+模型框架Fig.2 DeepLab v3+ model
首先,输入的图片经过主干DCNN深度卷积神经网络之后的结果被分为2部分,一部分直接传入Decoder,另一部分经过并行的Atrous Convolution,分别用不同rate的Atrous Convolution进行特征提取、进行合并,再进行1×1卷积压缩特征;其次,对于解码器Decoder部分,其输入有2部分,一部分是DCNN的输出,另外一部分是DCNN经过并行空洞卷积输出后的结果,接着将编码器的输出结果上采样4倍,然后与resnet中下采样前的Conv2特征Concat一起,再进行3×3的卷积,最后上采样4倍使其分辨率和低层级的Feature一致;最后,把获得的特征重新映射到图中的每一个像素点,用于每一个像素点的分类,最终输出Prediction图像。
样本获取。(1)样本影像裁剪。由于该试验的研究区范围较大,影像尺寸达到了50 000像素×50 000像素以上,所以不能直接将研究区作为标注对象,需要将影像进行切片处理。为了提高标注精度,将两景研究区影像切片为621像素×922像素大小的共4 000多张影像,并将其导出为.jpg格式。切成更小尺寸的图像是为了在标注阶段能够更好地识别地物信息,减小错分概率。
(2)样本选取与标注。基于上一步切片得到的影像,还需要通过目视解译的方法将包含目标地物的图像选取出来,经过筛选后,最终得到了共542张图像质量较好、具有较高识别度的图像;随后用Labelme工具进行语义分割样本的标注,将图像标注为养殖排筏与背景2类。这些样本在训练前需要经过镜像翻转、图像旋转等以获取更多的训练样本。
数据处理。训练前,首先将Labelme软件标注生成的json格式文件转换为VOC格式,方便后续进一步转换成DeepLab v3+模型训练所需的灰度图;随后利用build_voc2012_data.py文件将灰度图转换成tfrec7ord格式,同时添加对养殖排筏数据集的描述,最后进行数据集的训练。
训练时,引用预训练模型Xception65_coco_voc_trainval,调整迭代训练次数(training_number_of_steps)为30 000,图片训练尺寸(train_crop_size)为513,训练批数(train_batch_size)为1。另外,面对训练数据不足的情况,可以借鉴苟杰松等训练过程通过增添数据增强模块,即通过随步长随机缩放、镜像翻转、图像旋转、非等比例缩放等多种方式来增加训练数据量,以防止样本不足带来的过拟合,提升模型泛化能力和鲁棒性。训练结束后,导出生成.dp格式预测模型文件。
预测时,直接调用.pb格式模型文件对图片进预测。考虑设备限制与数据处理效率,并不能将整幅影像一次性导入进行预测。需将50 000像素×50 000像素的影像切割为500像素×500像素的共10 000张小尺寸图像,再将小尺寸图像放入预测模型中循环遍历,生成的预测图保存在列表中,最后再将预测好的图像进行拼接,最终生成一幅与原图尺寸一致的图像。
基于最大似然法的养殖用海识别
算法选取。在ENVI软件中监督分类常用的方法有最大似然法(Maximum Likelihood Classification,MLC)、最小距离法、马氏距离法、平行六面体法、神经网络法以及支持向量机法等。在影像信息提取研究中,ENVI监督分类利用最大似然法能够实现较高的信息提取精度,应用较为广泛。该分类算法是求出每一个像元对于各类别的归属概率,把该像元划分到归属概率最大的类别中去。它的判别规则是假设某待分类像元X满足如下公式:
=ln()-[0.5 ln(||)-[05(-)()(-)]
(1)
式中,、、分别为加权距离、某一特征类型和像元的测量矢量;、、分别为类别的样本均值、协方差矩阵和待分像元属于类别的概率。
ROI的选取与分离度指标的关系。根据地物在影像上的分布情况,在ENVI中选择绘制感兴趣区域(region of interest,简称ROI),并将地物分为2类,即养殖鱼、蚝等排筏与背景。ROI选择完毕之后还要对其进行分离精度评价,即在ENVI中对每个兴趣区计算Transformed距离和Jef-friesMatusita距离,分离度阈值是0~2。在该试验中,依据可分离值的大小来判断选取ROI样本的精度情况。当分离值大于1.9,说明2类地物样本之间可以很好地被区分开;当分离值小于1.8时说明2类地物样本之间无法很好地区别开,应当修改原样本并重新选择,当可分离值小于1时,说明2类样本几乎无法区分开,应该考虑将2类地物视为同种类型的地物并将其合并。该试验中,将钦州湾2011与2019年2期影像进行养殖用海面积的分类,得到2011年养殖用海与背景的分离度为1.923,具有比较好的分离性;2019年的分离度仅为1.806,达不到很好的分离效果。由此可知,利用最大似然法对影像分类时,拼接影像获取的分离度较非拼接影像更低。
精度评价方法。影像分类精度评价方法主要包括整体精度评价和制图精度评价。整体分类精度评价是对分类精度高低的检验,常用的检验方法有2种:一是在影像上随机选取一定比例的验证样本与分类结果进行对比;二是将分类结果与实际养殖用海的面积进行对比。该研究主要采用第2种,其中采用的分类精度指标包括总体精度(Overall Accuracy)和Kappa系数。制图精度是分类器将整个影像的像元正确分为A类的像元数(对角线值)与A类真实参考总数(混淆矩阵中A类列的总和)的比率。
2 结果与分析
图3展示了使用2种方法对2011年单一时相影像与2019年多时相拼接影像的预测结果。从图3可以看出,在非拼接的2011年影像上,基于MLC方法的总体预测质量较好,但在影像中部以及顶部等河网纵横交错、地物分布复杂的区域不能对目标地物实现准确识别(图3a)。对于2019年的拼接影像,研究区右下角、中部、顶部的部分水域被错分为养殖排筏,中部有大部分养殖排筏没有被准确提取,导致了图上的空白(图3b)。然而,DeepLab v3+模型提取的结果与实地养殖分布情况相吻合,总体上明显优于采用MLC方法提取的结果。
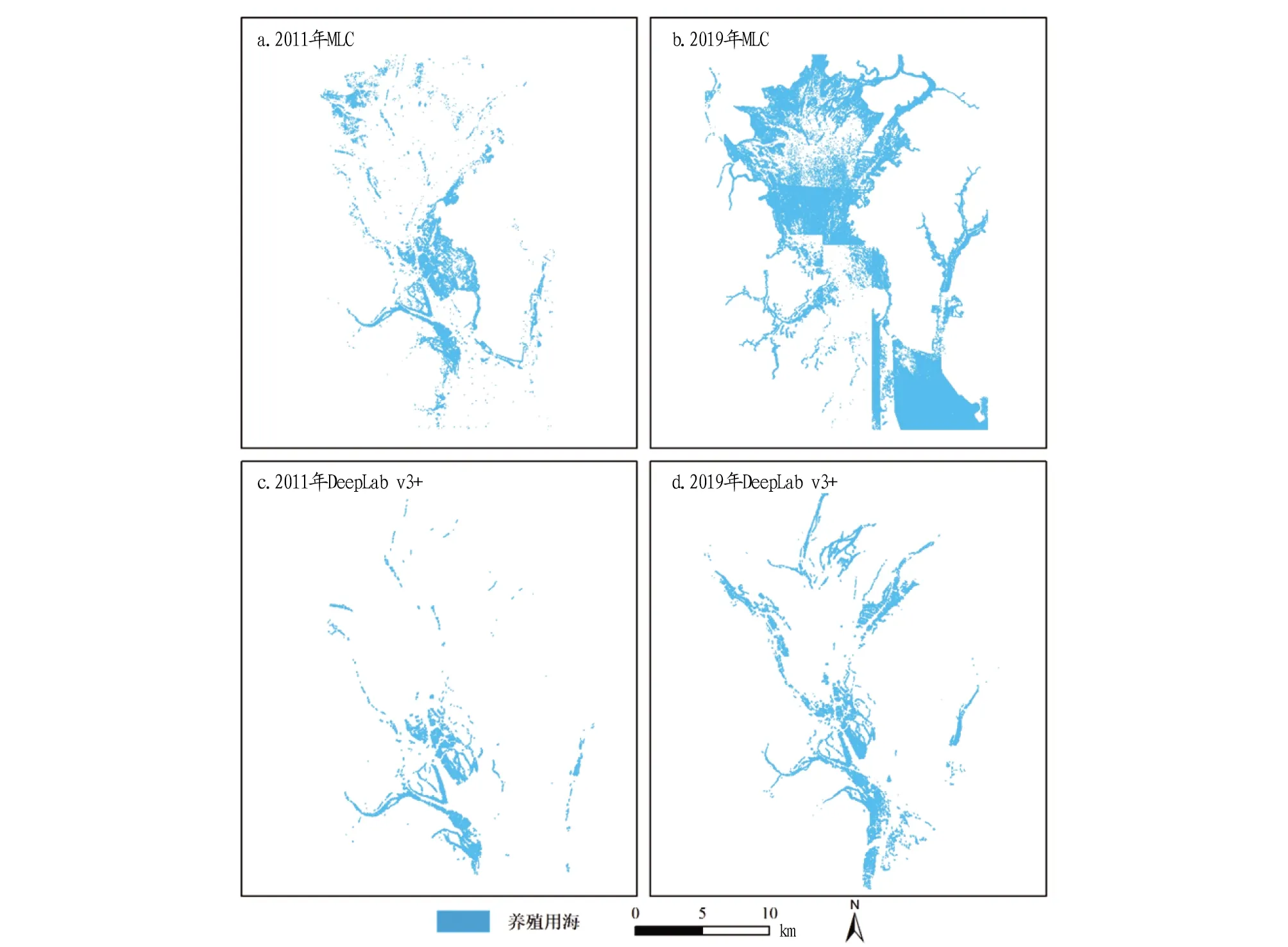
图3 2种方法预测的总体效果对比Fig.3 Comparison of the overall effects of the two methods
图4展示了2种方法在2019年多时相拼接影像上的分类结果部分细节。从图4可以发现,利用MLC方法对2019年的影像进行预测时,图中大部分区域都产生了噪声点,在影像拼接处更是将多种“异物同谱”的目标分为一类,在细节处不能将养殖排筏完整地提取出来,而DeepLab v3+模型提取的结果,边界清晰,地物完整。

图4 2种方法预测结果部分细节对比Fig.4 Comparison of the details of results obtained by the two methods
图5展示了2种方法在养殖排筏细节纹理特征识别上的差异。从图5可以发现,利用MLC方法不能将养殖排筏作为一个整体提取出来,只提取了网格线(图5a),忽略了其中的水域。而DeepLab v3+模型在纹理特征细节处的识别较为准确,能够很好地识别出目标轮廓,并将网格和其中水域作为一个整体提取。

图5 2种方法对地物细微特征的提取Fig.5 The details of aquaculture cages and crafts recognized by the two methods
表1为2种方法提取精度对比。从表1可以看出,DeepLabv3+模型的Kappa系数与总体精度均优于最大似然法。在2011年非拼接影像信息提取中,DeepLab v3+模型比最大似然法的总体精度高0.98%,两者差异较小,而在2019年多时相拼接影像识别上,前者为92.62%,后者仅89.46%,两者相差3.16%。另外,DeepLab v3+模型在制图精度上也优于最大似然法,且在识别复杂拼接影像时依旧能够表现出较高的分类精度。
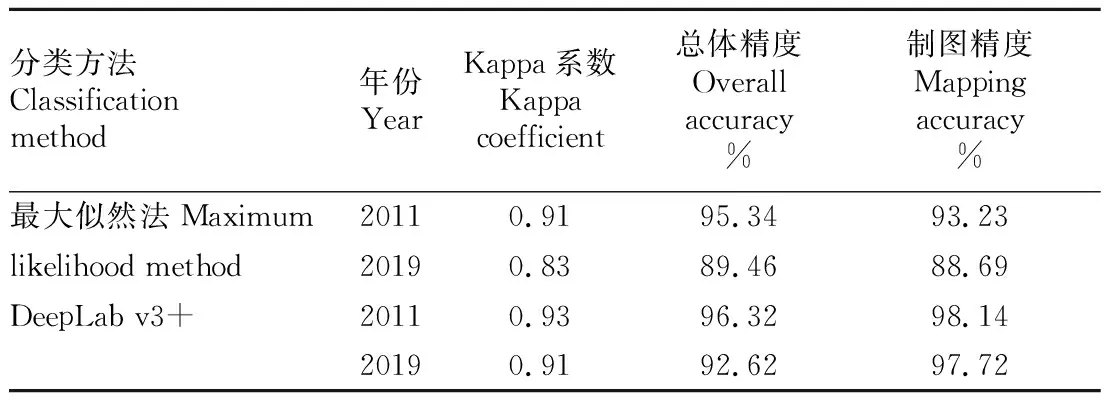
表1 2种方法精度对比Table 1 Comparison of the accuracy of the two methods
在卷积神经网络训练过程中,迭代训练次数是一个重要参数,对模型精度有显著影响。图6展示了不同迭代训练次数下模型预测精度情况。从图6可以看出,随着训练次数的不断增加,模型预测精度(mIoU值)也逐渐提高。当训练次数达到30 000次以上时,模型的预测精度趋于平缓,到达50 000次时,模型的精度与30 000次相比仅相差0.60%。由此可知,在样本数一定的情况下,模型的精度超过50 000次后将不会再有明显的提升。分析可知,在不改变初始学习率、train_batch_size以及output_stride时,该模型的预测精度与迭代训练次数成正相关关系。
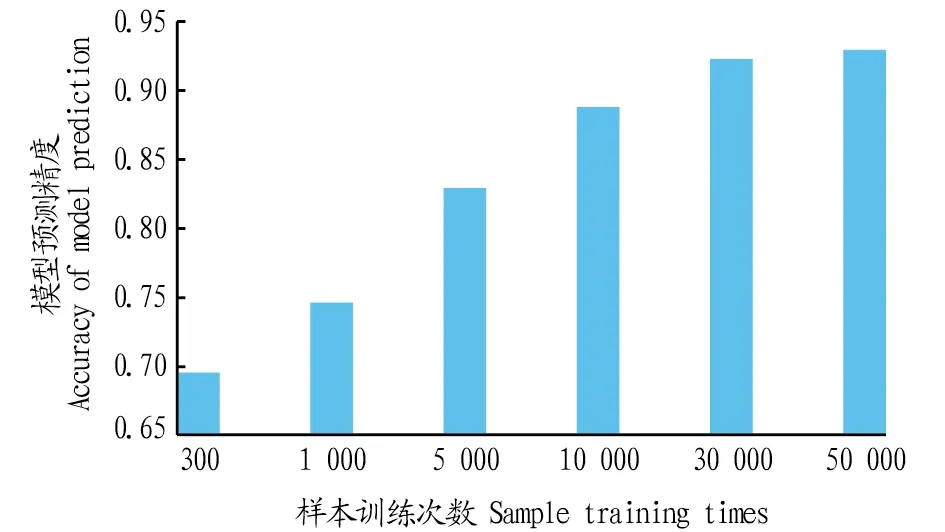
图6 训练次数对预测精度的影响Fig.6 Effects of the training times on DeepLab v3+ model
图7展示了近10年间养殖用海的时空变化分布状况。养殖用海面积在近10年间呈现出爆炸式的增长,养殖用海的分布格局也由起初位于中部的集群分布拓展至整个钦州湾甚至北部的钦江和茅岭江的入海口区域,呈现出了中心扩散的趋势,也从侧面彰显了广西海洋经济在可持续发展“十三五”规划中取得的巨大进步。
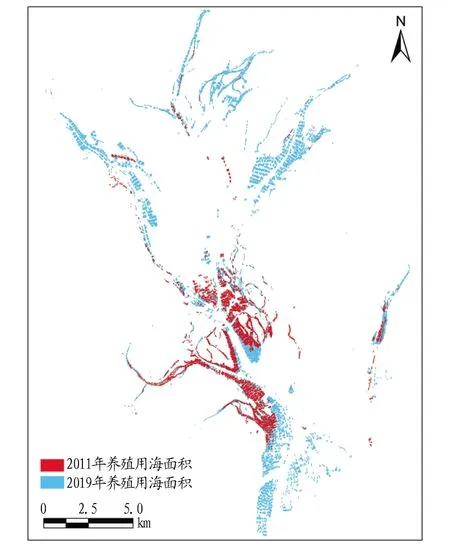
图7 钦州湾近10年间养殖用海分布变化情况Fig.7 Distribution of oyster rafts in Qinzhou Bay in recent ten years
表2统计了基于DeepLab v3+模型的两期影像养殖用海提取面积与实际面积对比。从表2可知,钦州湾养殖用海的净面积由2011年的718 hm增长到了2019年的1 924 hm,是2011年的近2.7倍,相比2011年同比增长了168.23%。随着2011年钦州市委市政府将钦州大蚝列为重点扶持的特色产业,市财政每年在大蚝养殖项目上的扶持经费高达数百万元。另外,随着养殖技术的不断进步,“浮筏吊养”逐渐取代了“滩涂插养”的传统养殖方式,极大提高了钦州大蚝的产量。

表2 基于语义分割的面积比较Table 2 Area comparison based on semanteme division
3 结论
该研究以2期谷歌地球引擎获取的高分辨率影像为数据源,采用了DeepLab v3+模型进行了钦州湾养殖用海信息提取。试验结果表明,该模型在高分辨率、多时相拼接影像上的总体识别精度和纹理特征细节识别方面均显著优于传统机器学习方法。DeepLab v3+模型提取总体精度达到了97%以上,能够很好地识别出养殖网箱、排筏轮廓,可将网格和其中水域作为一个整体提取。另外,通过用海变化分析发现,近10年间,钦州湾海域养殖用海爆发式增长,面积增长接近2倍。该研究可为海域使用监测提供科学技术支持,对海洋开发与管理具有重要意义。
