基于改进强化学习的无人机规避决策控制算法
2022-07-08TajmihirIslamTeethi卞志昂
Tajmihir Islam Teethi,卢 虎,闵 欢,卞志昂
(空军工程大学信息与导航学院,陕西 西安 710077)
0 引言
无人机自主飞行、自主导航是提高无人系统智能化水平的重要基础。在与真实世界的交互过程中,避障是无人机应当具有的最基本的功能之一。目前,很多无人机厂商,如中国的大疆、法国的PARROT等公司也都将自主避障能力作为其无人机产品的一项重要技术指标。当前,无人机的自主避障主要是通过机载传感器获取障碍物的距离、位置、速度等有效信息,再根据障碍物信息自主规划出合理的路径,从而保证其在运行的过程中避开障碍[1-2]。
传统的无人机自主避障技术主要由障碍感知与避障规划两大功能模块组成。障碍感知是指无人机通过机载传感器实时获取周边障碍物的信息。避障所常用的传感器主要包括超声波传感器、激光雷达、双目视觉传感器等。SLAM(simultaneous localization and mapping)技术可以为避障提供更加丰富全面的地图环境信息,因此在近几年的研究中,SLAM技术被广泛应用于移动机器人自主导航避障[3-4]。但基于SLAM的避障方法仍需要手动调试大量的构图模型参数以达到良好的建图效果和可靠的路径规划,且在一架无人机上调试好的一套构图参数,由于平台、传感器载荷等的性能差异并不完全适用于另一架无人机。
当前,人工智能正在飞速发展,基于强化学习的避障方法通过训练深度神经网络进行端到端动作决策,使得无人机避障无须“额外”的建图过程,取而代之的是一种即时自主的行为,并且避免了复杂的建模和大量的参数调整,而且因其不需要建图的特性,此类基于学习的避障方法也能更好地适应于未知无图的应用场景[5-6]。
1 强化学习的马尔可夫决策表示
强化学习作为机器学习的一大分支[7],其基本思想是,智能体在完成某项任务时,通过动作与环境进行交互,环境在动作的作用下会返回新的状态和奖励值,奖励值越高说明该动作越好,反之则说明该动作应该被舍弃,经过数次迭代之后,智能体最终会学到完成某项任务的最优策略。强化学习基本的原理框架如图1所示。
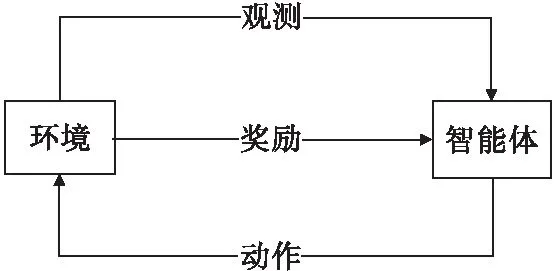
图1 强化学习基本原理框架Fig.1 The principle framework of reinforcement learning
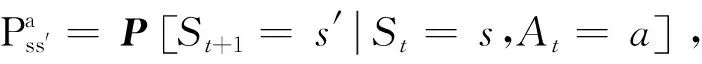
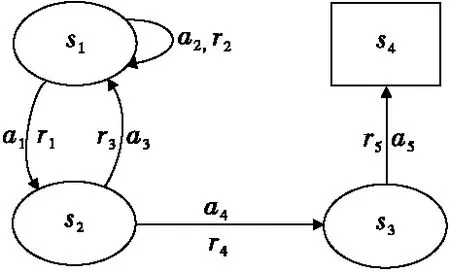
图2 马尔可夫决策过程示例Fig.2 An example of Markov decision process
在强化学习中,从初始状态S1到终止状态的序列过程S1,S2,…,ST,被称为一个片段,一个片段的累积奖励定义为式(1),式中,rτ为智能体在τ时刻从环境获得的即时奖励值,T为智能体达到终止状态时的时刻
(1)
除此之外,强化学习还在马尔可夫决策过程的基础上,定义了智能体的策略π(a|s),策略π表示的是智能体在状态s下的动作的概率分布,其定义为:
π(a|s)=P[At=a|St=s]。
(2)
强化学习的目的就是通过不断试错来改善智能体的策略π(a|s),以最大化其获得的累积奖励,因此引入了值函数来评价某个策略获得的累积奖励。一般来说值函数分为两种:状态值函数(V函数)和状态动作值函数(Q函数)。V函数的定义是,从状态s开始,使用策略π得到的期望奖励值,其定义式
Vπ(s)=E[Gt|St=s]。
(3)
Q函数的定义为,从状态s开始,执行动作a,然后使用策略π得到的期望奖励值,其定义式
Qπ(s,a)=Ε[Gt|St=s,At=a,π]。
(4)
最终得到V函数的贝尔曼期望方程
Vπ(s)=E[rt+γVπ(St+1)|St=s]。
(5)
贝尔曼期望方程将V函数的求取分为了两部分,一部分是当前的即时奖励rt,另一部分是后继状态St+1的V值。同理,也可以推导出Q函数的贝尔曼期望方程
Qπ(s,a)=E[rt+γQπ(St+1,At+1)|St=s,At=a,π]。
(6)
定义最优值函数为所有策略中最大的值函数,即
V*(s)=maxπVπ(s),
(7)
Q*(s,a)=maxπQπ(s,a)。
(8)
2 基于改进强化学习的无人机规避决策控制算法
2.1 无人机视觉避障的马尔可夫决策模型
无人机视觉避障的强化学习问题可以表述为无人机通过视觉传感器与环境交互的马尔可夫决策过程:无人机获取当前时刻t的视觉图像st,根据策略π(a|s)执行动作at,观测环境反馈的奖励值rt,然后转移到后继状态st+1,其中t∈(0,T],at∈A,A为智能体的动作集,T为每个交互片段的终止时刻。
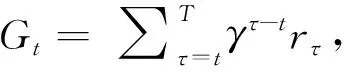
Qπ(st,at)=E[Gt|st,at,π]。
(9)
根据贝尔曼期望方程,当前Q值可以进一步通过当前奖励和后继状态的Q值求出:
Qπ(st,at)=E[rt+γQπ(st+1,at+1)|st,at,π]。
(10)
智能体的动作决策依据是每个动作的最优Q值:
Q*(st,at)=maxπQπ(st,at)=maxπE[Gt|st,at,π]。
(11)
因此,将Q函数的贝尔曼期望方程进一步转化为贝尔曼最优方程的形式,即当前的最优Q值可以通过当前奖励和后继状态的最优Q值中的最大值求出:
(12)
在求得每个状态动作对(st,at)的最优Q值之后,智能体便可以在不同的输入状态下进行最优动作决策,从而生成最优策略π*(a|s),其决策的核心思想是贪婪思想,即选择输入状态下最大的最优Q值所对应的动作作为最优动作:
(13)
2.2 深度Q网络的改进方法
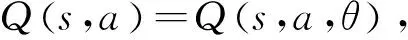
在强化学习问题中,状态是智能体选择动作的重要依据,状态的设置可以是智能体对环境的观测,也可以是智能体的自身状态。在无人机避障过程中,无人机需要感知与障碍物之间的距离,因此选择无人机视觉传感器采集的深度图作为无人机的状态。
为了能使无人机更好地做出合理的决策,设计无人机的状态为连续抓取深度图组成的深度图堆,如图3所示。这样设计的好处在于使状态中既包含了深度信息又隐含了无人机的运动信息,考虑到无人机运行时的实时性,最终决定以连续抓取4帧深度图来组成一个深度图堆。
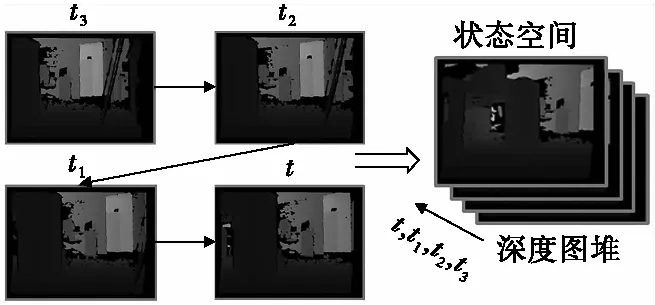
图3 无人机状态空间设置Fig.3 State space configuration of drone
动作空间是无人机能够执行的具体动作,为了使网络经过训练能得到更加可靠的避障策略,需要以无人机能及时规避障碍为目标,合理地设计无人机的动作空间。本文所设计的离散动作空间如图4所示,分为前进和转向两大动作组。前进动作组控制无人机的前进速度,其中包含快速前进和慢速前进2个动作:v∈(4,2)m/s。转向动作组控制无人机偏航角速率,其包含快速左转、左转、停止转向、右转、快速右转5个动作:yawrate∈(π/6,π/12,0,-π/12,-π/6)rad/s。动作空间总共包含7个动作,通过前进动作和转向动作的组合共能生成10种动作指令,基本包含了无人机常见的机动方式。

图4 无人机离散动作空间Fig.4 Discrete action space of drone
为了提高训练过程的稳定性和学习效率,本节结合double Q-learning[10]和dueling network[11]方法,设计了用于无人机视觉避障的D3QN(dueling double DQN)网络,如图5所示。
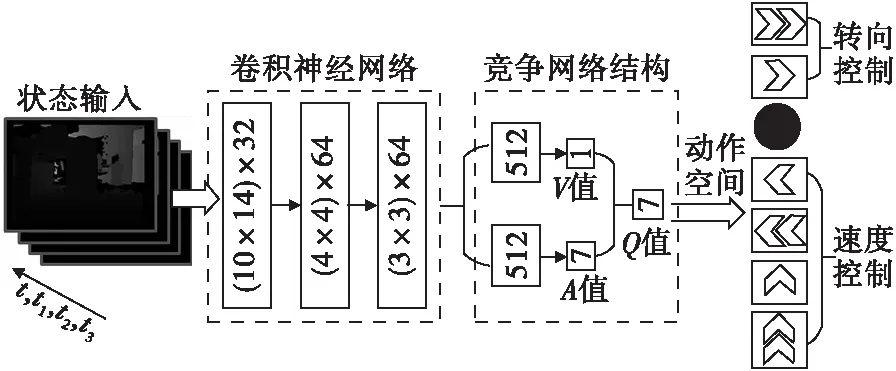
图5 无人机视觉避障D3QN网络结构Fig.5 D3QN network structure for drone visual obstacle avoidance
本文所设计的D3QN网络的输入是连续4帧的深度图,尺寸为160×128×4,经过3层卷积神经网络提取特征后,按照dueling network分为两个数据流,再通过两层全连接层,网络的最终输出是动作空间内各个动作的Q值。网络的损失函数为:
(14)
网络规避训练算法如下:
1:初始化在线网络权重参数θ,初始化目标网络权重参数θ-=θ;
2:初始化记忆回放单元D;
3:For episode=1,Mdo;
4:读取初始状态st;
5:Fort=1,Tdo;
6:计算当前状态下所有动作的Q值Q(st,a,θ),a∈A;
7:根据小概率ε选择随机动作at∈A,否则选择动作at=argmaxa∈AQ(st,a,θ);
8:无人机执行动作a,观测奖励值和后继状态rt和后继状态st+1;
9:将五元组{st,at,rt,st+1,reset}存入D,reset用于判断st+1是否终止状态;
10:状态转移st=st+1;
11:从记忆回放单元随机采样n个样本数据{st,at,rt,st+1,reset}i,i=1,…,n;
12:计算YtDDQN=
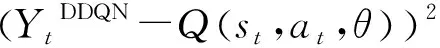
14:每C步更新目标网络参数θ-=θ。
3 实验验证与分析
3.1 仿真平台搭建
为了验证本文所提出的视觉自主避障算法的可行性与有效性,在AirSim仿真平台[12]上开展了无人机避障仿真实验。
无人机视觉自主避障的训练环境,为40 m×40 m×30 m的方盒世界,如图6所示,其全局坐标系位于方盒的中心,无人机的初始位置设置于坐标系的原点,然后在其中布置了三种不同形状的障碍物,在训练环境中以算法训练无人机感知障碍、规避障碍的能力。随后搭建了如图7所示的泛化测试环境,测试场景1在训练环境的基础上,对原来的3个柱形障碍物进行了移动,测试场景2则是在方盒世界中加入了更多的障碍物。
图6 无人机避障训练环境 Fig.6 UAV obstacle avoidance training environment

图7 泛化测试场景Fig.7 Generalization test scenario
为了测试基于D3QN的无人机导航避障算法能力,搭建了如图8所示的未知测试场景:无人机按照从初始位置→目标位置的路径执行多航点任务,导航途中面临多个障碍物,以模拟复杂城市低空复杂场景。
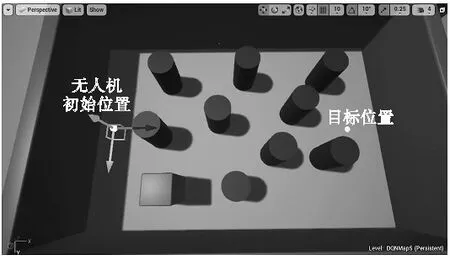
图8 未知测试场景Fig.8 Unknown test scenario
3.2 网络性能对比
首先,为了分析所设计的D3QN网络的优势,分别采用了D3QN、DDQN、DQN三种不同网络在训练环境中进行训练,网络训练的硬件条件为CPU:2.70 GHz×8,GPU:RTX2080ti 11 GB,三种网络训练的总片段数均设置为1 000,每次从记忆回放单元采样32个样本数据进行梯度下降,训练过程中的奖励值曲线如图9所示。
可以看出,D3QN模型最先开始收敛(约600片段),DDQN和DQN收敛较慢(约800片段),D3QN的训练速度相比DDQN和DQN提升了约25%,并且平均每个片段的累积奖励高于DDQN和DQN模型;DDQN相比于DQN,两者的收敛速度相差不大,但DDQN的平均奖励水平高于DQN。这可能是由于D3QN和DDQN模型都运用了Double Q-learning,改善了DQN的过估计问题,给予智能体更多的探索机会,使其能够获得更高的奖励值。综合对比来看,D3QN模型的训练效率最高,达到了预期的改进效果。
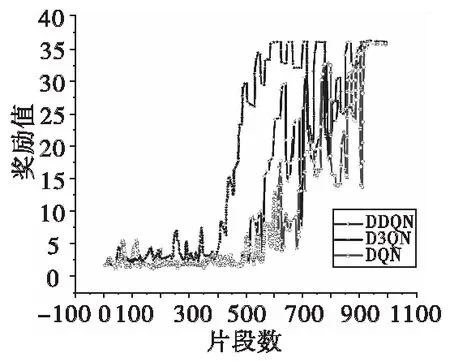
图9 不同网络训练奖励曲线对比Fig.9 Comparison of reward curves for different network training
3.3 规避决策控制算法泛化测试
为了进一步测试训练好的D3QN网络的泛化性能,接下来分别在泛化测试场景1和2中加载D3QN网络模型,并运行算法进行实际飞行测试,简明起见仅给出场景1的飞行过程中记录的运动轨迹以及无人机的转向控制动作,如图10所示。
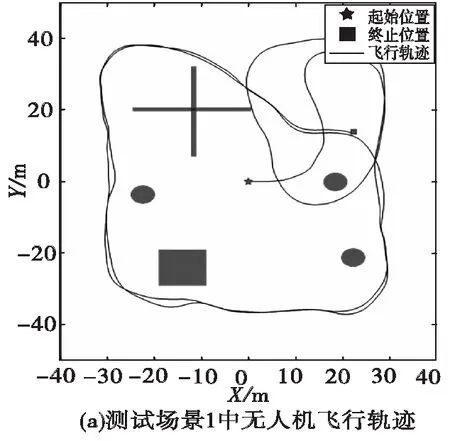
图10 泛化测试结果Fig.10 Generalization test results
在场景1的泛化测试中,无人机没有事先对环境构建全局地图,由记录的运行轨迹可以看出,无人机在未知的新环境下也能进行无碰撞的自主飞行,通过学习得到的规避决策能力具有较好的自适应性,在图10(b)记录的转向控制动作中虽然出现了较多的跳变现象,但是其不影响整体的避障性能。
综上可以看出,本文算法训练出的避障策略,对环境的改变具有较好的自适应能力,训练后的D3QN网络也表现出了较好的泛化性能。
3.4 导航避障算法测试
为了进一步测试把规避决策应用到具体任务中的表现性能,在搭建的图8的未知测试场景中对算法进行了测试,测试结果如图11所示。
从仿真测试结果可以看出,无人机在执行航点导航任务的过程中,能够判断出前方是否存在障碍,并能做出合理决策,及时进行规避,在避开障碍之后继续朝着设置的航点飞行。
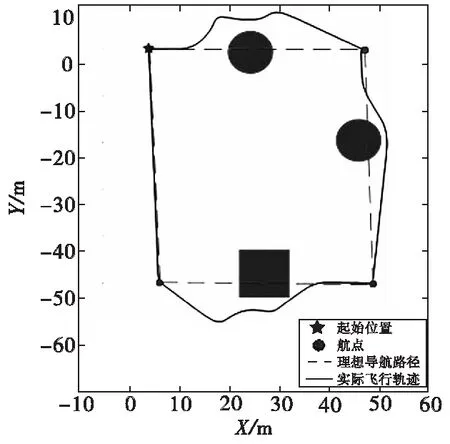
图11 飞行轨迹(多航点任务)导航避障算法测试飞行轨迹Fig.11 Flight trajectory (multi-waypoint task) navigation obstacle avoidance algorithm test flight trajectory
相比于基于地图和规划的避障方法,基于学习的避障方法直接根据图像作出相应决策,其优势在于不依赖地图,能较好地适用于未知无图的环境。但是在建图良好的情况下,基于地图和规划的避障方法可以依据规划好的路径,控制无人机以尽可能快的速度飞行,其动作连续,控制更加精准,最大运行速度可达10 m/s。而在本章的仿真实验中,考虑到图像处理、网络计算量以及动作空间的离散性,无人机自主飞行的最大速度为4 m/s。
4 结论
无人机规避决策的导航控制问题是无人机的核心技术之一,论文研究成果有助于进一步完善无人机智能化、集群化的相关算法与技术,提升无人机中低空飞行的导航控制性能。但本文提出的基于改进强化学习的无人机视觉避障算法,仍有较大性能提升空间。如文中提出的D3QN网络只能输出离散动作空间,且只适用于旋翼无人机,为了进一步提升避障控制的精准程度以及算法的通用性,还应当研究旋翼无人机和固定翼无人机飞行控制的共性与区别,设置维度更大的动作空间来组合形成不同的运动模式,或是改用基于策略梯度的深度强化学习算法学习连续化的避障策略;其次是所提避障算法从仿真到真实环境的泛化问题,在仿真器中训练无人机避障时,仿真器所提供的深度图过于理想,不存在任何噪声,实践中应对其进行加噪声处理,从而使仿真器提供的环境更加逼近真实环境。上述问题都有待进一步的深入研究、技术拓展并逐步完善。
