基于价值差异学习的多小区mMTC接入算法
2022-07-07李昕孙君
李昕,孙君,2
研究与开发
基于价值差异学习的多小区mMTC接入算法
李昕1,孙君1,2
(1. 南京邮电大学通信与信息工程学院,江苏 南京 210003;2. 江苏省无线通信重点实验室,江苏 南京 210003)
在5G大连接物联网场景下,针对大连接物联网设备(massive machine type communication device,mMTCD)的接入拥塞现象,提出了基于价值差异探索的双重深度Q网络(double deep Q network with value-difference based exploration,VDBE-DDQN)算法。该算法着重解决了在多小区网络环境下mMTCD接入基站的问题,并将该深度强化算法的状态转移过程建模为马尔可夫决策过程。该算法使用双重深度Q网络来拟合目标状态—动作值函数,并采用基于价值差异的探索策略,可以同时利用当前条件和预期的未来需求来应对环境变化,每个mMTCD根据当前值函数与网络估计的下一时刻值函数的差异来更新探索概率,而不是使用统一的标准,从而为mMTCD选择最佳基站。仿真结果表明,所提算法可有效提高系统的接入成功率。
大连接物联网;随机接入;强化学习;基站选择
0 引言
5G移动通信及未来移动网络(包括物联网)的部署正在推动先进物联网的发展[1–3],将人与人之间通信拓展到人与物、物与物之间通信,开启万物互联时代[4]。大连接物联网(massive machine-type communication,mMTC)系统的主要挑战是在上行链路中为大量设备设计稳定高效的随机接入方案[5]。特别是,随着5G移动通信的发展和大规模物联网场景的出现,数以百计的大连接物联网设备(massive machine type communication device,mMTCD)被连接起来[6]。据Statista统计,到2030年,全球预计将使用500亿台物联网设备[7],为未来的蜂窝网络设想一个真正的大连接物联网场景。但是,mMTCD的快速增长为随机接入(random access,RA)带来各方面的挑战[8]。
为了解决蜂窝物联网中的RA拥塞问题,3GPP提出了几种解决方案,包括访问等级限制及其变体、特定于mMTC的退避方法、时隙RA、RA资源分离和分页RA方法[9]。此外,文献[10]中还研究了其他方案,如优先级RA、基于分组的RA和码扩展的RA。然而,大多数现有的方法适用于集中式系统,并且是被动的,而不是具有高度动态特性的mMTCD所需的。因此,目前的研究倾向于强化学习(reinforcement learning,RL)辅助的接入控制方案,因为它更适应于学习系统变化和参数不确定的环境。
在RL中,Q-学习因其无模型和分布式特性,更适合mMTC场景。文献[11]提出了一种基于协同Q-学习的拥塞避免方法,该方法利用每个时隙的拥塞水平来设置奖励函数。文献[12]中,每个mMTCD通过Q-学习选择其传输的时隙和传输功率来提高系统吞吐量。文献[13]提出结合NOMA和Q-学习方法,以便在前导分离域中显著分开区域中的设备,既可以重用前导码而不会发生冲突,减少连接尝试。文献[14]提出双Q-学习算法,该算法可以动态地适应ACB机制的接入限制参数。双Q-学习的实现可以降低传统Q-学习过高估计Q值的风险,避免导致次优性能。文献[15]提出了基于多智能体的智能前导码选择机制,将神经网络与RL结合,有效提高了mMTCD接入的性能。同时为解决mMTCD的接入问题提供了思路。以上方案只关注在单小区接入过程中的拥塞问题,很少关注在基站侧的影响。即使mMTCD完成了随机接入过程,也会出现过载和资源分配失败。因此需要设计高效稳定的eNB选择方案,以适应mMTC的特性,减少网络拥塞和过载。文献[16]中Q-学习用于选择最佳可用基站,使用吞吐量和时延作为QoS测量和奖励。文献[17]在时隙多小区随机接入的场景下,提出了一种基于指数权重探索与开发的RL算法,用于选择关联的接入点。但是文献[16-17]不能处理网络密度的增长,因此过载仍然是一个问题。虽然Q-学习因其分布式和无模型特性而被广泛使用,但是在mMTC场景下,其并不能解决网络密度增长带来的挑战,可能会使其Q表过大并且增加查表难度导致函数难收敛。因此,本文引入神经网络拟合Q表来优化传统用于随机接入的RL算法,并使用双重网络提高算法精度。同时,提出一种探索策略,进一步提高算法性能,与现有的基于多小区随机接入的算法相比,本文算法降低了选择eNB的随机性,更能选择最优的eNB。
因此,本文提出了基于价值差异的双重深度Q网络(double deep Q network with value-difference based exploration,VDBE-DDQN)算法来解决多小区网络环境下的eNB选择问题。通过双重深度Q网络(double deep Q network,DDQN)来学习mMTCD到eNB的直接映射,同时,当网络参数未知时,引入价值差异探索(value-difference based exploration,VDBE)的研究方法,根据每个mMTCD自身学习的情况更新探索概率,使学习过程更符合每个mMTCD的需求。在学习过程中,知道的信息越多,越有可能在所知的eNB中选择最优eNB,而不是随机选择。本文所提方法与其他多小区网络选择基站的随机接入方法相比,能够允许大量mMTCD的接入,并有效提高系统中mMTCD的接入成功率。
1 系统模型
系统模型如图1所示,系统模型由位于小区原点的eNB和随机分布在其周围的个mMTCD组成。本文只考虑mMTCD与eNB之间的上行链路传输,其中mMTCD以信号和数据的形式向eNB发送接入请求,eNB充当数据集中器,并向其覆盖区域的设备广播控制消息。考虑个小区,每个小区由位于其原点的基站所覆盖。区域1的mMTCD仅由eNB1服务,3个小区重叠区域的设备可以选择3个eNB中的任一个通信。如果多个集中器可用,那么每个mMTCD每次只能选其中一个通信。
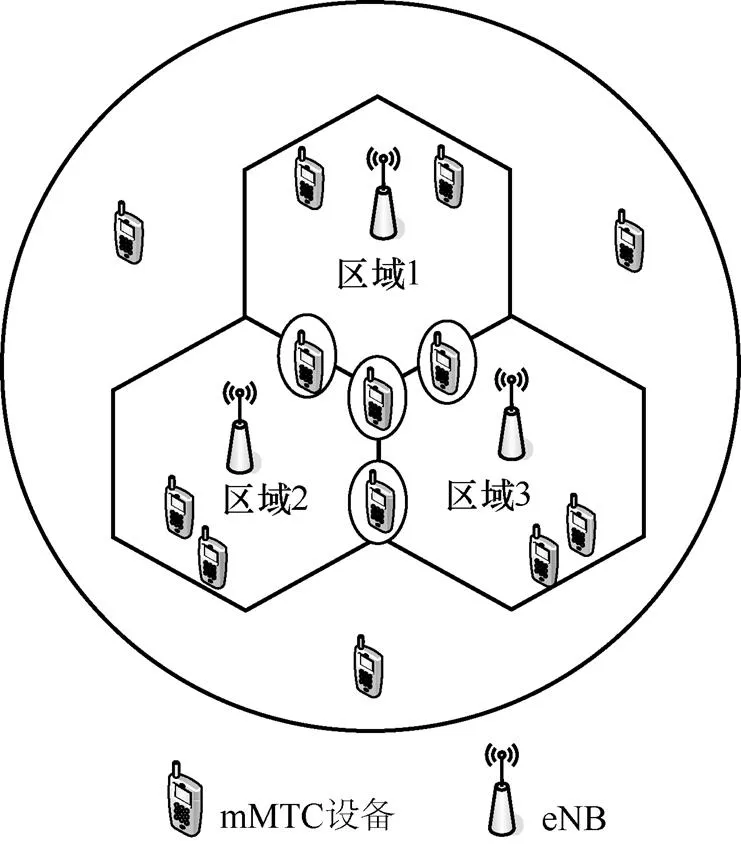
图1 系统模型
在随机接入之前,设备需要等待前导码来传输分组,前导码被定义为向eNB发送数据包的传输机会[18]。如果多个设备同时选择相同的前导码,那么会发生前导码碰撞,使设备无法分配到前导码,无法向eNB传输数据包。所以重叠区域的mMTCD在发送数据包之前必须选择一个eNB进行传输,那么拥塞较少的eNB将有更大的可能将前导码分配给mMTCD,增加成功接入的可能。除此之外,接入失败的设备可以在下一时隙重新请求接入。为了评估在多小区网络下系统的性能,将接入成功率作为性能指标:
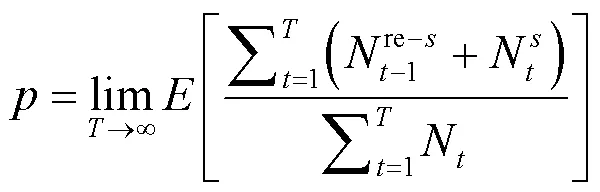
2 算法描述
2.1 RL算法描述
在RL中,智能体通过试错来学习。智能体与环境交互的学习过程可以被视为马尔可夫决策过程(Markov decision process,MDP),其被定义为一个四元组[],分别表示状态集、动作集、状态转移和奖励。RL框架与MDP如图2所示,为RL中智能体与环境的交互过程以及将其状态转移描述为MDP。

图2 RL框架与MDP
Q-学习是RL最常见的一种,通过对智能体与其环境之间的交互进行抽样观察学习值函数。在时隙,先基于当前状态,使用贪婪法按一定概率选择动作,得到奖励,进入新状态。每个状态下的Q值通过以下迭代过程[19]计算:

2.2 VDBE-DDQN算法
设备每隔一段时间检测当前小区的网络状态,并根据当前网络状态决定是否切换小区来达到更好的接入效果。与算法相关的状态、动作和感知奖励定义如下。
状态:状态为mMTC设备,连接它所选择的eNB。
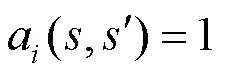
奖励R:奖励是在mMTCD向eNB发送接入请求之后获得,需考虑mMTCD是否在网络覆盖范围。如果不在覆盖范围,设置=0,此时mMTCD向eNB发送任何请求都无效,奖励值为0;如果在覆盖范围,设置=1。此时若eNB接收了mMTCD的接入请求,则发送确认信息;若mMTCD发送数据失败,说明选择同一个eNB的设备发生了碰撞冲突。



此外,算法将深度神经网络(deep neural network,DNN)代替Q表,并将其称为深度Q网络(deep Q network,DQN)。在DQN中,通过DNN对值函数近似,可表示为:


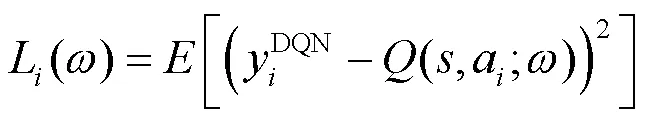
目标值表示为:

其中,表示目标网络的权重。
此外,由于在Q-学习和DQN方法中使用相同的值来选择和评估动作,Q值函数可能过于乐观。因此,使用DDQN[20]通过以下定义的目标值替换(8)的值来缓解上述问题:

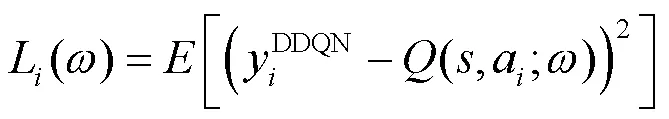



算法1:基于VDBE-DDQN的eNB选择算法描述

for 每个回合数=1,...,
for每个0,...,
每个mMTCD观察状态
根据式(13)更新
end for
end for
3 仿真及结果分析
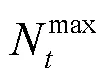

表1 仿真参数设置


图4 不同学习率下的性能
不同优化算法的性能如图5所示,其针对参数更新的不同优化算法的性能。在学习开始时,这3种情况下的训练步数都非常大。随着回合数增加,收敛速度有增加的趋势。RMSProp优化算法的收敛速度最快。因此,选择RMSProp算法更新参数。

图5 不同优化算法的性能

图6 不同折扣率γ的性能
3种算法性能比较如图7所示,其比较了3种不同探索策略的DRL算法的接入成功率。在学习开始时,3种算法下的接入成功率都很低。随着训练回合数增加,成功率和收敛速度都有增加趋势。其中,本文算法的成功率最高,其次是greedy-RL算法,softmax-RL算法成功率相对最低。此外,由于系统模型分布着不在小区覆盖范围的设备,因此无法接入基站,影响接入成功率。

图7 3种算法性能比较

图8 不同值对3种算法的性能影响
4 结束语
针对大连接物联网场景,本文提出了VDBE- DDQN算法来解决在多小区网络环境下mMTCD选择eNB的问题。首先,本文将此RL算法的状态转移过程建模为MDP,定义了其中的状态、动作和奖励函数,并根据设备之间的协作获得接入失败设备的碰撞级别作为奖励。其次,通过设计的网络来近似值函数,通过不断学习使目标值与值函数无限接近。同时,DDQN也解决了传统算法对值函数高估的问题。然后,通过VDBE方法使每个mMTCD有适合自己的探索概率,而不是统一的标准。此外,该算法还能够感知网络环境的变化,调整探索和利用的比值。仿真结果表明,所提方法在接入成功率方面优于其他方法。
[1] TULLBERG H, POPOVSKI P, LI Z X, et al. The METIS 5G system concept: meeting the 5G requirements[J]. IEEE Communications Magazine, 2016, 54(12): 132-139.
[2] Latva-aho M, Leppänen K, Clazzer F, et al. Key drivers and research challenges for 6G ubiquitous wireless intelligence[J]. 2020.
[3] BI Q. Ten trends in the cellular industry and an outlook on 6G[J]. IEEE Communications Magazine, 2019, 57(12): 31-36.[LinkOut]
[4] 董石磊, 赵婧博. 面向工业场景的 5G 专网解决方案研究[J]. 电信科学, 2021, 37(11): 97-103.
DONG S L, ZHAO J B. Research on 5G private networking schemes for industry[J]. Telecommunications Science, 2021, 37(11): 97-103.
[5] POPLI S, JHA R K, JAIN S. A survey on energy efficient narrowband internet of things (NBIoT): architecture, application and challenges[J]. IEEE Access, 2018(7): 16739-16776.
[6] NAVARRO-ORTIZ J, ROMERO-DIAZ P, SENDRA S, et al. A survey on 5G usage scenarios and traffic models[J]. IEEE Communications Surveys & Tutorials, 2020, 22(2): 905-929.
[7] ANALYTICS S. Number of Internet of things(IoT) connected devices worldwide in 2018, 2025 and 2030(in billions)[J]. Statista Inc, 2020(7): 17.
[8] SHARMA S K, WANG X B. Toward massive machine type communications in ultra-dense cellular IoT networks: current issues and machine learning-assisted solutions[J]. IEEE Communications Surveys & Tutorials, 2020, 22(1): 426-471.
[9] 3GPP. Study on RAN improvements for machine-type communications:TR 37.868[R]. 2011.
[10] ALI M S, HOSSAIN E, KIM D I. LTE/LTE-A random access for massive machine-type communications in smart cities[J]. IEEE Communications Magazine, 2017, 55(1): 76-83.
[11] SHARMA S K, WANG X B. Collaborative distributed Q-learning for RACH congestion minimization in cellular IoT networks[J]. IEEE Communications Letters, 2019, 23(4): 600-603.
[12] DA SILVA M V, SOUZA R D, ALVES H, et al. A NOMA-based Q-learning random access method for machine type communications[J]. IEEE Wireless Communications Letters, 2020, 9(10): 1720-1724.
[13] TSOUKANERI G, WU S B, WANG Y. Probabilistic preamble selection with reinforcement learning for massive machine type communication (MTC) devices[C]//Proceedings of 2019 IEEE 30th Annual International Symposium on Personal, Indoor and Mobile Radio Communications. Piscataway: IEEE Press, 2019: 1-6.
[14] PACHECO-PARAMO D, TELLO-OQUENDO L. Adjustable access control mechanism in cellular MTC networks: a double Q-learning approach[C]//Proceedings of 2019 IEEE Fourth Ecuador Technical Chapters Meeting. Piscataway: IEEE Press, 2019: 1-6.
[15] BAI J N, SONG H, YI Y, et al. Multiagent reinforcement learning meets random access in massive cellular Internet of Things[J]. IEEE Internet of Things Journal, 2021, 8(24): 17417-17428.
[16] MOHAMMED A H, KHWAJA A S, ANPALAGAN A, et al. Base Station selection in M2M communication using Q-learning algorithm in LTE-A networks[C]//Proceedings of 2015 IEEE 29th International Conference on Advanced Information Networking and Applications. Piscataway: IEEE Press, 2015: 17-22.
[17] LEE D, ZHAO Y, LEE J. Reinforcement learning for random access in multi-cell networks[C]//Proceedings of 2021 International Conference on Artificial Intelligence in Information and Communication (ICAIIC). Piscataway: IEEE Press, 2021: 335-338.
[18] MOON J, LIM Y. Access control of MTC devices using reinforcement learning approach[C]//Proceedings of 2017 International Conference on Information Networking (ICOIN). Piscataway: IEEE Press, 2017: 641-643.
[19] LIEN S Y, CHEN K C, LIN Y H. Toward ubiquitous massive accesses in 3GPP machine-to-machine communications[J]. IEEE Communications Magazine, 2011, 49(4): 66-74.
[20] VAN HASSELT H, GUEZ A, SILVER D. Deep reinforcement learning with double q-learning[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2016: 2094-2100.
[21] SILVER D, HUANG A, MADDISON C J, et al. Mastering the game of Go with deep neural networks and tree search[J]. Nature, 2016, 529(7587): 484-489.
[22] TIELEMAN T, HINTON G. Lecture 6.5-rmsprop: divide the gradient by a running average of its recent magnitude[J]. COURSERA: Neural networks for machine learning, 2012, 4(2): 26-31.
Value-difference learning based mMTC devices access algorithm in multi-cell network
LI Xin1, SUN Jun1,2
1. College of Telecommunications & Information Engineering, Nanjing University of Posts and Telecommunications, Nanjing 210003, China 2. Jiangsu Key Laboratory of Wireless Communications, Nanjing 210003, China
In the massive machine type communication scenario of 5G, the access congestion problem of massive machine type communication devices (mMTCD) in multi-cell network is very important. A double deep Q network with value-difference based exploration (VDBE-DDQN) algorithm was proposed. The algorithm focused on the solution that could reduce the collision when a number of mMTCDs accessed to eNB in multi-cell network. The state transition process of the deep reinforcement learning algorithm was modeled as Markov decision process. Furthermore, the algorithm used a double deep Q network to fit the target state-action value function, and it employed an exploration strategy based on value-difference to adapt the change of the environment, which could take advantage of both current conditions and expected future needs. Moreover, each mMTCD updated the probability of exploration according to the difference between the current value function and the next value function estimated by the network, rather than using the same standard to select the best base eNB for the mMTCD. Simulation results show that the proposed algorithm can effectively improve the access success rate of the system.
mMTC, RA, reinforcement learning, eNB selection
: The National Natural Science Foundation of China (No.61771255), Provincial and Ministerial Key Laboratory Open Project (No.20190904)
TN929.5
A
10.11959/j.issn.1000−0801.2022152
2022−01−13;
2022−04−06
国家自然科学基金资助项目(No.61771255);省部级重点实验室开放课题项目(No.20190904)
李昕(1997− ),女,南京邮电大学通信与信息工程学院硕士生,主要研究方向为大连接物联网设备的随机接入。

孙君(1980− ),女,南京邮电大学副研究员、硕士生导师,主要研究方向为无线网络、无线资源管理和物联网。
