一种基于特征偏移补偿的深度智能化教学评价方法
2022-07-07曲豫宾李梦鳌
李 芳, 曲豫宾, 李 龙, 李梦鳌
(1. 桂林电子科技大学 广西可信软件重点实验室, 广西 桂林 541004; 2. 江苏工程职业技术学院 马克思主义学院, 江苏 南通 226001;3. 江苏工程职业技术学院 信息工程学院, 江苏 南通 226001; 4. 中国船舶工业系统工程研究院, 北京 100094)
慕课(massive open online course, MOOC)能支持线上大规模学习, 因此目前已成为高等教育领域内广泛使用的教学方法之一. 针对MOOC的研究也取得了丰富成果[1-11]. 但目前单一针对MOOC评论的深度语义分析框架与评价机制尚未见文献报道, 因此本文采用卷积神经网络对MOOC评论进行深度语义分析, 设计语义理解框架并基于该框架设计MOOC平台评价机制. 该分析框架具有适应性广、 数据采集成本较低、 评价策略直观等特点. 该面向MOOC评论的深度智能化教学评价框架与自然语言处理领域中的情感分析有一定的相似性. 网络评论中的情感分析是将网络评论内容根据极性的不同分类为积极评论或消极评论. 情感分析是文本处理任务中的一项基本任务[12]. 借鉴文本中情感分析任务的分类标准, 将面向MOOC评论的深度智能化教学评价也划分为积极评价或消极评价. 在本文研究中, 积极评论除包含对课程支持或赞扬的评论外, 还包括对课程的一般性内容评价. 情感分析任务中, 基于机器学习的分析技术被广泛使用[13], 高巍等[14]采用卷积神经网络对Twitter进行情感分析, 取得了较好的效果; 李芳等[15]基于卷积神经网络设计教学评论语义理解框架, 该框架采用了基于浅层卷积神经网络的结构.
对MOOC评论的深度语义分析除考虑采用浅层神经网络学习语义外, 在实证研究中发现MOOC评论数据集中存在较明显的特征偏移现象, 如浅层神经网络学习到的训练数据中的数据分布与测试数据集中的数据分布有较大差异. 在图形图像分类领域, 广泛存在着长尾效应, 即某几种图形图像在训练数据集中有较多的实例, 而其余的大部分图形图像却有较少的实例[16-17], 这是一种典型的类不平衡现象. 采用存在类不平衡现象的数据集训练得到的卷积神经网络在少数类上分类效果不佳[18]. 产生该现象的原因是深度卷积神经网络从训练数据集的多数类损失中学到了特征而对于少数类的损失未重点关注, 从而导致深度卷积神经网络在少数类上的分类效果较差[19-20]. 常见的处理方法包括对少数类进行过采样[18,21]以及采用代价敏感的方式提升少数类训练过程中的损失值[15,20]. 但这些方法存在对少数类过拟合的现象[18-19,22], 而且训练数据集中少数类越少, 预测效果越差. 文献[23]基于训练数据集与测试数据集的特征偏移, 提出了特征偏移补偿的方法, 用于解决类不平衡问题. 在图形分类中, 该方法在常见的类不平衡数据集上达到了较好的分类效果, 但该方法并未考虑二分类问题中多数类与少数类之间的畸形类不平衡率问题, 可能会存在深度神经网络训练过程中损失突变的问题.
本文采用归一法对二分类中的多数类与少数类样例的数目进行处理, 以解决损失突变的问题. 针对MOOC评论智能化评价问题, 本文采用浅层卷积神经网络对MOOC评论进行语义学习, 通过归一化的特征偏移补偿函数对数据集进行训练, 在公开的MOOC评论数据集上进行实证验证, 验证结果表明, 在常见的评价指标上, 如F1,gmean,balance,gmeasure等, 该分类方法能取得较好的分类效果.
1 基于特征偏移补偿的深度语义学习框架
1.1 框架设计
针对MOOC评论中存在的特征偏移问题, 采用浅层卷积神经网络对评论进行语义学习, 用基于归一法的特征偏移补偿函数计算训练数据集中的损失值, 用梯度下降法对损失函数进行优化, 训练MOOC评论语义学习模型. 该深度语义学习框架的整体流程如图1所示.

图1 基于特征偏移补偿的深度语义学习框架Fig.1 Deep semantic learning framework based on compensation for feature deviation

(1)


(2)
MOOC评论通过使用词嵌入的方式获取分布式向量展示, 作为浅层卷积神经网络的的输入. 词向量采用Glove预训练模型进行表示[24], 这是一个基于全局词频统计的词表征工具, 每个单词被表示为一个实数词向量. 单词的语义相似性可通过欧氏距离等计算. 图1所示的深度语义学习框架中, 词向量的语义学习通过含有多个卷积核的浅层卷积神经网络学习得到. 卷积神经网络的输出值作为特征向量分类层的输入, 特征向量分类层是一种线性分类器wc.全连接层将深度神经网络学习到的评论语义特征输入到激活神经元, 对激活神经元做Softmax处理, 最后通过交叉信息熵损失函数计算损失值.
1.2 基于浅层卷积神经网络的MOOC评论语义学习模型
基于浅层卷积神经网络的MOOC评论语义学习模型源于TextCNN[25]模型, 该语义分类模型目前已广泛应用于如智能软件工程中自引入技术债务等问题的语义学习中. 基于TextCNN的深度语义学习模型如图2所示. 该模型由卷积层、 池化层、 全连接层等组成, 该模型中的全连接层与特征向量分类层中的全连接层共享同一层. 卷积神经网络的核心思想是使用多个卷积核获取不同的特征表示, 在MOOC评论语义分析过程中, 采用多种不同尺寸的卷积核组成滑动窗口对分布式词向量进行语义理解. 卷积核的尺寸为filter_size∈{1,2,3,4,5,6}. 多种尺寸的一维卷积核对词向量进行组合筛选, 获得不同层次的语义信息.

图2 基于TextCNN的深度语义学习模型Fig.2 Deep semantic learning model based on TextCNN
对MOOC评论进行补全获得句子长度为n, 通过检索Glove预训练词向量获得分布式词向量的输出为n×k的矩阵, 其中k表示词向量的输出维度.该输出矩阵作为卷积层的输入值.在卷积层中, 采用一维卷积核进行局部特征学习, 与图形图像处理领域中的二维卷积核不同, 一维卷积核的宽度为词向量的维度k.多个不同的卷积核对MOOC评论分布式词向量矩阵窗口进行滑动即可获取多个不同的特征向量. 如filter_size=2, 则一维卷积核为2×k, 在窗口中滑动形成特征向量为w[n-2+1,1], 多个卷积核对窗口进行滑动形成当前评论向量的特征向量集合.然后对该特征向量集合池化处理, 处理方法采用1-max池化方法, 从不同的特征向量中选取值最大的特征作为输入特征. 不同的输出特征拼接作为全连接层的输入. 全连接层中的输入向量值即为学习到的深度语义特征.
1.3 基于归一法的特征偏移补偿损失函数
1.3.1 MOOC评论可视化分析
MOOC评论数据集存在类不平衡问题, 常见解决类不平衡问题的方法(如重采样和代价敏感的方法)可能会导致在深度学习过程中少数类的过拟合现象[18-19]. Ye等[23]通过对图形图像处理中的图像识别问题研究表明, 对于少数类, 训练数据集与测试数据集存在特征偏移问题. 而且训练越少的类别偏移问题越严重, 这种情况下加大少数类的损失补偿会使过拟合更易发生. 采用t-SNE(t-distributed stochastic neighbor embedding)对MOOC评论数据集进行可视化分析.t-SNE是一种高效的针对高维数据的可视化方法, 使用非线性降维算法将高维数据降为二维或者三维数据.
针对MOOC评论数据集的少数类特征偏移可视化展示如图3所示. 通过t-SNE算法将词嵌入后的多维分布式词向量降维为二维向量, 并在二维平面展示. 训练数据集中的积极评论具有最大的数据分布, 该数据分布可以覆盖到测试数据集中积极评论的数据分布, 积极评论在整个数据集中为多数类, 这种数据分布式符合对训练数据集的直观认识. 而训练数据集中消极评论的数据分布与测试数据集中的消极评论数据分布有明显偏移, 表明在训练数据集中学到的少数类特征无法泛化到测试数据集中. 因此在深度语义学习过程中有必要解决存在少数类的特征偏移问题.
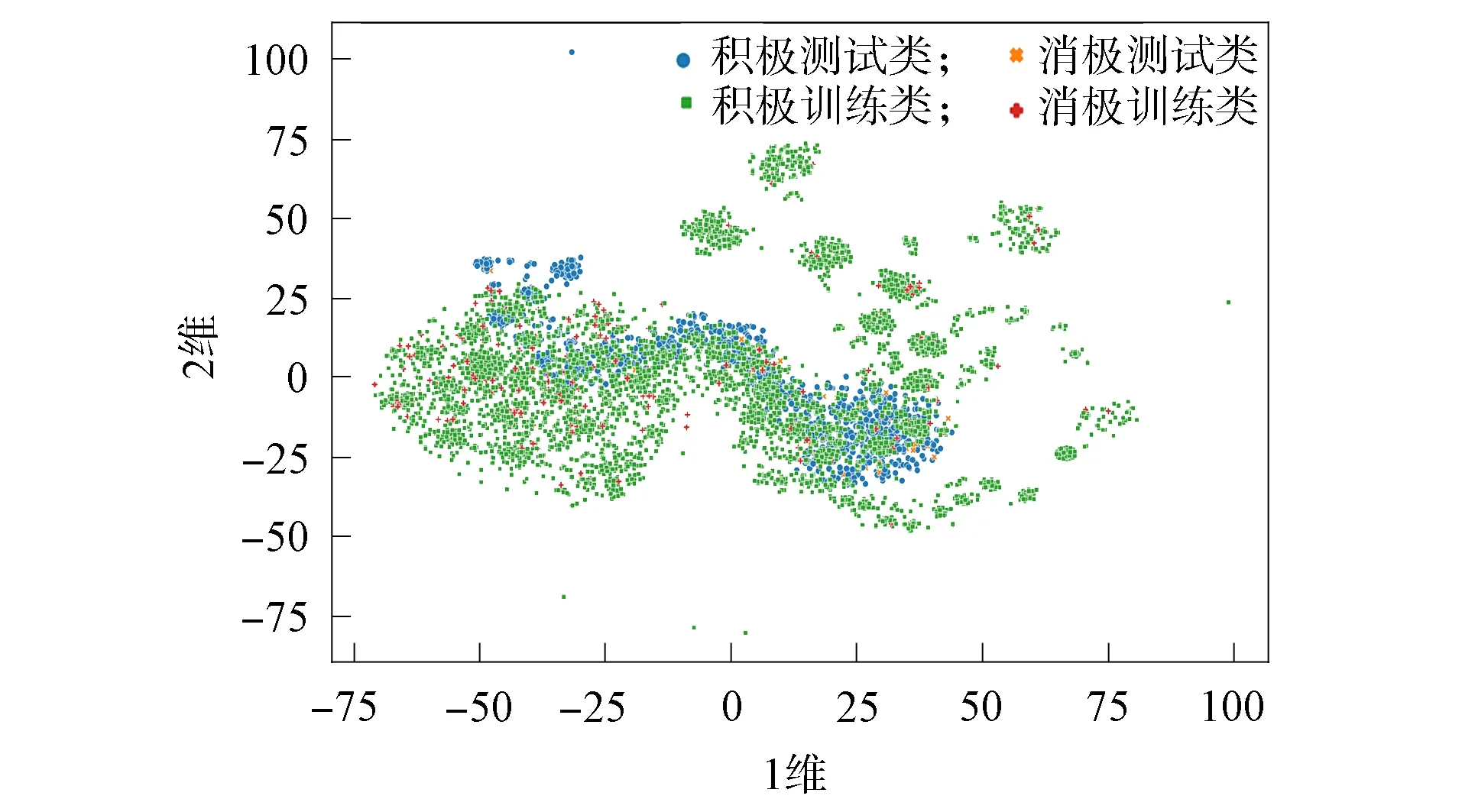
图3 少数类特征偏移可视化展示Fig.3 Visual display of feature deviation for minority class
1.3.2 Class-Dependent Temperatures补偿函数
选取2015年1月~2017年12月吉林市职业病防治院接收的突发性职业中毒患者86例作为研究对象,将其随机分为研究组与对照组,各43例。其中,研究组男25例,女18例,年龄25~59岁,平均年龄(45.2±4.7)岁,中毒类型:三氯乙烯19例,二甲基甲酰胺15例,二氯乙烷9例;对照组男26例,女17例,年龄24~58岁,平均年龄(45.5±4.3)岁,中毒类型:三氯乙烯21例,二甲基甲酰胺14例,二氯乙烷8例。两组患者的性别、年龄及中毒类型等一般资料比较,差异无统计学意义(P>0.05)。
基于特征偏移现象, Ye等[23]提出了在存在类不平衡问题的图形图像训练数据集上采用降低决策边界的方法设计新的损失函数(Class-Dependent Temperatures补偿函数), 表示为

(3)
式(3)与式(2)的不同之处在于增加了影响因子αc,αc与训练数据集中特定类别的数量成反比, 训练数据集中数量越少的类别有更大的影响因子值.影响因子αc反映了少数类在训练数据集与测试数据集中存在的特征偏移现象.影响因子αc的计算公式为
αc=(Nmax/Nc)γ,
(4)
其中:Nmax表示训练数据集中多数类的样例数目, 在MOOC评论数据集中则表示积极评论的数目;Nc表示训练数据集中少数类的样例数目, 在MOOC评论数据集中则表示消极评论的数目;γ≥0, 是一个超参数, 为与文献[23]的研究结果保持一致, 本文实验中设定γ=0.3.如果αc=1, 则表示多数类与少数类有同样的偏移补偿效果, 式(3)退化为式(2); 如果αc>1, 则表示多数类拥有较少的偏移补偿效果, 而少数类有较多的偏移补偿效果.
1.3.3 基于归一法的特征偏移补偿损失函数
Class-Dependent Temperatures补偿函数在存在类不平衡问题的图形图像分类问题上分类效果较好, 但针对MOOC评论数据集, 类不平衡率为21.67, 影响因子αc=2.51.在神经网络训练过程中样例要进行随机抽样, 则可能在抽样过程中出现严重的类不平衡率畸变问题, 其结果会导致影响因子针对不同的训练过程出现较大波动, 进而导致损失值也存在较大波动, 因此本文设计一种基于归一法的特征偏移补偿损失函数.归一法的思想是不同类别的影响因子应在某一个固定区间内变化, 不会出现较大波动.针对影响因子αc设计的归一法影响因子为

(5)

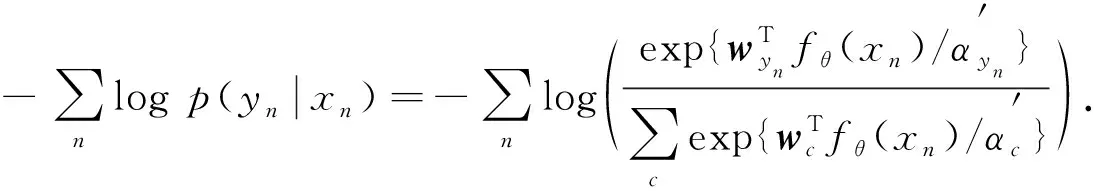
(6)
2 实 验
本文实验在基于Intel Corei7-10700K的CPU与64 GB内存的工作站上完成, 浅层卷积神经网络在NVIDIA GeForce RTX 2070 GPU上训练完成, 操作系统采用Windows 10专业版. 实验中采用的深度神经网络库为Pytorch 1.9稳定版本.
2.1 实验数据集
实验采用的数据集来源于公开的数据集, 该数据集用于针对本科学生的教学研究(https://www.kaggle.com/septa97/100k-courseras-course-reviews-dataset), 数据集中存在的主要问题是类不平衡问题, 其抓取自Coursera网站, 并根据他们的评分预先标记. 对于5星评级, 该评论被标记为非常积极, 4星为积极, 3星为中性, 2星为负面, 1星为非常差. 原始数据集中有2个数据文件, 分别为review.tsv和reviewbycourse.tsv. reviews.tsv文件没有课程分组, 只有课程评论及其相应的标签. 对于reviewbycourse.tsv, 按CourseId列分组. 本文实验重点研究不同MOOC课程评论的分类问题, 因此未使用涉及课程编号的数据集reviewbycourse.tsv. reviews.tsv文件中共有3个字段, Id字段表示评论的唯一标识符, Review字段表示评论的内容, Label字段表示相应课程的评分. 将该评论的分类问题简化为二分类问题, 对数据集进行预处理. 对于评分为3星以上(包括3星)的评论重新标记为积极评论, 对应标记为0; 对于评分为3星以下的评论重新标记为消极评论, 对应标记为1. Coursera学习评论数据集的信息列于表1.

表1 数据集信息
2.2 模型参数配置
实验采用Glove预训练模型获取MOOC评论的分布式词向量, 每个词向量的维度设为300, 每条评论的长度设为 20. 超过特定长度的句子做截断处理, 对不满足长度的句子进行补零操作, 数据字典大小为20 000. 卷积神经网络的模型参数设置中卷积核的尺寸为filter_size∈{1,2,3,4,5,6}, 每种卷积核的数量为128个, 其他超参数采用默认超参数.
实验中训练数据集与验证数据集、 测试数据集的比例为8∶1∶1, 重复训练次数为10次, 每次都对数据集进行随机分层抽样, 保持数据分布的一致性. 验证过程中, 采用早停法终止神经网络训练过程防止出现过拟合. 基于t-SNE的可视化展示采用sklearn.manifold模块进行非线性降维, 参数采用默认值.
2.3 评价指标
针对类不平衡数据集的常见评价指标包括F1,gmean,balance,gmeasure等. 针对MOOC评论数据集的混淆矩阵如图4所示, 其中TP(true positive)表示消极评论被正确预测为消极评论, FN(false negative)表示消极评论被错误预测为积极评论, FP(false positive)表示积极评论被错误预测为消极评论, TN(true negative)表示积极评论被正确预测为积极评论.

图4 混淆矩阵Fig.4 Confusion matrix
基于混淆矩阵, 定义精确度(precision)和召回率(recall)分别为

(7)
F1和gmean指标分别定义为

(8)
FPR定义为

(9)
balance和gmeasure指标分别定义为

(10)
2.4 损失函数
实验采用3种基线损失函数与本文补偿损失函数进行对比, 分别为常规交叉熵损失函数、 基于不同类别权重的交叉熵损失函数、 Class-Dependent Temperatures补偿函数.
1) 如式(2)所示, 采用交叉信息熵作为损失函数, 未考虑类不平衡问题, 该函数记为normal;
2) 采用交叉信息熵作为损失函数, 将不同类别的评论数量作为影响权重引入损失函数, 该函数记为reweight;
3) 如式(3)所示, 采用Class-Dependent Temperatures补偿函数, 该函数记为CDT;
4) 如式(6)所示, 基于Class-Dependent Temperatures补偿函数, 采用归一法设计面向特征偏移补偿的损失函数, 该函数记为FDC.
3 结果分析
在MOOC评论数据集上重复执行10次实验, 每次实验中采用分层抽样的80%数据作为训练数据集, 10%的数据作为验证数据集, 剩余10%的数据作为测试数据集获取模型的泛化性能. 采用的性能指标包括F1,gmean,balance,gmeasure等, 在不同性能指标上的结果如图5~图8所示. 由图5~图8可见, FDC在多个评价指标上都获得了较大的性能提升. FDC在F1指标上从中位数计算比基类损失函数获取了最多15.39%的性能提升, FDC在gmean指标上从中位数计算比基类损失函数获取了最多7.72%的性能提升, FDC在balance指标上从中位数计算比基类损失函数获取了最多6.28%的性能提升, FDC在gmeasure指标上从中位数计算比基类损失函数获取了最多15.40%的性能提升,F1指标与gmeasure指标都获得了较大的性能提升. 并且FDC与其他损失函数相比, 各性能指标值的中位数都接近最大值, 表明采用该种损失函数有较稳定的性能提升. 此外, 采用CDT损失函数的各性能指标值从中位数上看都处于性能第二佳的位置, 表明采用这种特征偏移的补偿损失函数可潜在解决类不平衡问题. 采用reweight损失函数, 其性能指标表现不佳, 表明采用这种损失函数无法有效解决特征偏移问题. 采用normal损失函数在几个性能指标值上的中位数偏低, 表明此时特征偏移带来的类别不平衡问题影响到了分类函数的分类性能.

图5 采用不同损失函数的模型F1指标对比结果Fig.5 Comparison results of F1 indexes of models with different loss functions

图6 采用不同损失函数的模型gmean指标对比结果Fig.6 Comparison results of gmean indexes of models with different loss functions

图7 采用不同损失函数的模型balance指标对比结果Fig.7 Comparison results of balance indexes of models with different loss functions
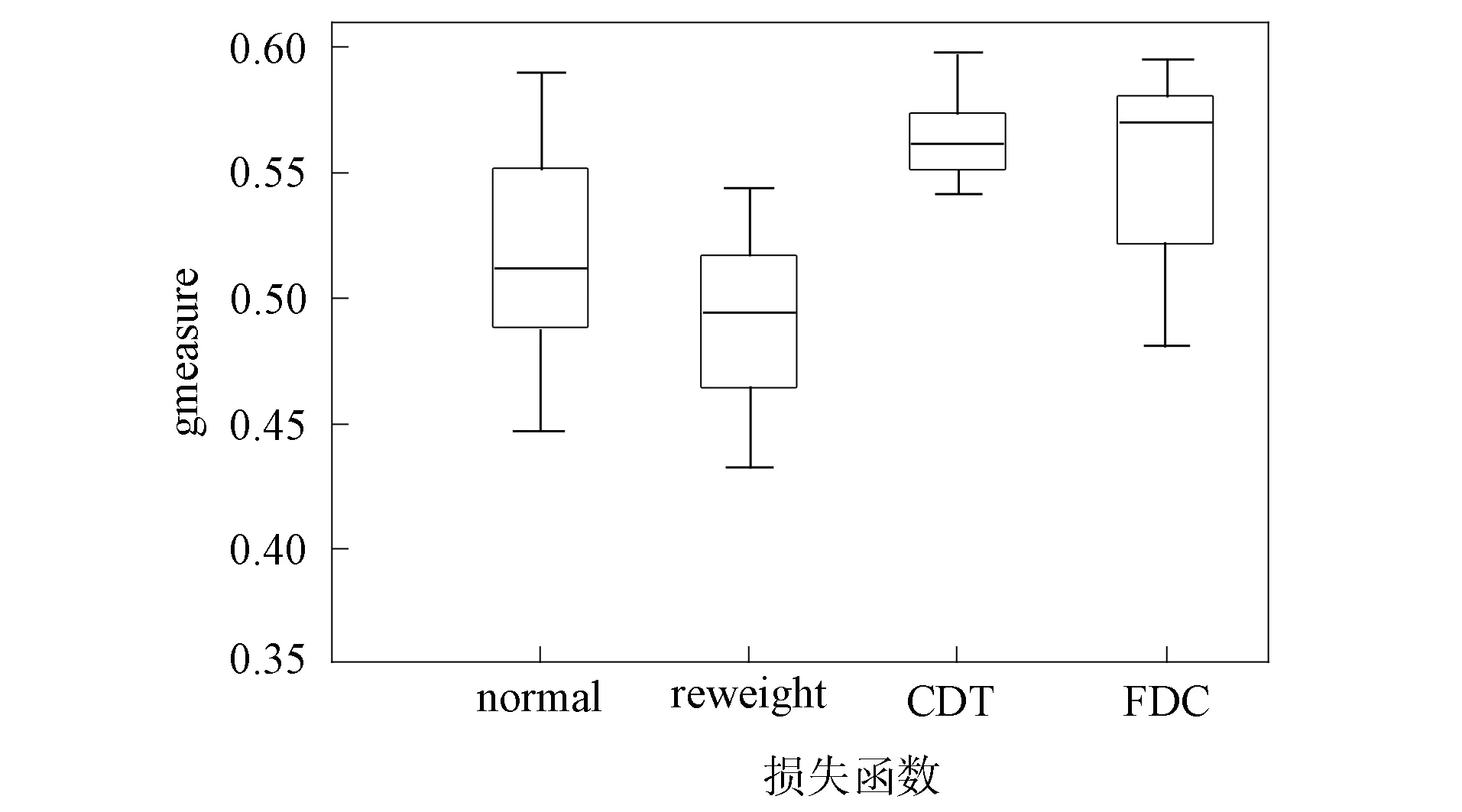
图8 采用不同损失函数的模型gmeasure指标对比结果Fig.8 Comparison results of gmeasure indexes of models with different loss functions
综上所述, 针对MOOC评论数据集中存在的特征偏移问题, 本文设计了一种基于归一法的特征偏移补偿损失函数. 通过与其他常见的损失函数在F1,gmean,balance,gmeasure等评价指标上进行性能对比, 结果表明, 基于归一法的特征偏移补偿损失函数在gmeasure指标上从中位数计算比基类损失函数得到15.40%的性能提升, 并且采用该损失函数的分类模型稳定性较强.
