基于卷积神经网络的音符级钢琴音乐转录方法研究
2022-07-07胡丽敏杜佶峻汤健雄陈开一
胡丽敏 桂 浩 杜佶峻 汤健雄 陈开一
1(武汉音乐学院 湖北 武汉 430060)2(武汉大学 湖北 武汉 430072)
0 引 言
自动音乐转录(Automatic Music Transcription, AMT)是将声学音乐信号转换为音乐符号的过程[7]。AMT 作为音乐领域内的一项新兴技术,不仅可以直接用于实现音频到音乐符号表示的转换,还能在乐曲匹配、哼唱识别等领域提供重要的技术支撑。AMT最直接的应用就是让科学家完整地记录下来即兴演奏的音符以便能够再现它。即使对于专业音乐家来说,转录多音音乐(Polyphonic Music)也是一项十分困难的任务,虽然单声道信号的自动音高估计问题已经解决,但是目前的多音音乐转录仍然存在着许多重大挑战。
AMT 问题可以分为几个子任务,包括:多音级检测、音符开始/结束检测、响度估计和量化、乐器识别、节奏信息提取和时间量化。自动转录中核心问题是估计时间帧中的多音音高,也被称为多音级检测或多F0检测。图1所示为钢琴自动转谱的过程。近几年,音高的检测问题已经在深度学习发展的基础上取得了重大突破,而音符的时值检测问题仍处于探索阶段,因此本文的核心关注点也从音乐中音高和时值的识别展开。

图1 自动转谱过程
本文综合应用了基本乐理、声学模型、深度学习和多标签多分类相关知识,针对当下基于深度学习方法的自动转录技术进行了深入的研究和探讨,并提出了音符级自动音乐转录算法。此算法很好地利用了音符起止点处显著的频谱特征,捕获钢琴音乐在时间结构和空间结构上的特点,在识别上达到了优越的性能。在这种优化的自动转录技术上,提出了一种后处理方案,用以进行音符级自动时间对齐,并应用到现场演奏的钢琴辅助练习中,取得了较好的效果。
1 相关理论基础
1.1 声学特征提取
常数Q变换(Constant Q Transform, CQT)是将数字音乐信号处理为基于频谱的技术。该变换非常适合于音乐数据,与快速傅里叶变换相比,其输出在对数频率下能有效地计算出与音乐频率相关的振幅,因此可以使用更少的频率区间来有效地覆盖音乐频率范围,并且这在频率跨越几个八度音程的情况下被证明是有用的。
除此之外,该变换表现出的频率分辨率随着较高的频率而降低,这反映了人的听觉系统在较低的频率下光谱分辨率更好,在较高的频率下时间分辨率更好。由此可知,在处理钢琴音频的时候,常数Q变换是最为理想的。
但是,相对于傅里叶变换和梅尔频谱,CQT的实现更加棘手。这是因为在计算每个频率格时使用的样本数量不同,这会影响所实现窗口函数的长度。下面是CQT的具体实现。
CQT本质上可以看作是一系列对数间隔的滤波器,其中第k个滤波器的频谱宽度为δfk,δfk与前一个滤波器之间的有着倍数关系:
(1)
式中:δfk是第k个滤波器的带宽;fmin是最小滤波器上滤波带的中心频率;n指的是每个钢琴八度上滤波器数。
(2)

(3)
接下来,在处理截取信号时间片段的问题上,一般会进行周期延拓,做法是使用窗口函数。在上面定义的基础上构建等效的汉明窗口如下:
(4)

(5)
CQT的计算将线性频谱转为以2为底的log频谱,充分利用了音符频率的数值规律。CQT目前作为音乐信号处理最主流的方法,被大量使用于音乐声学模型和前期音乐信号的特征处理中,在文献[1,3,7,12]中,CQT将音乐信号转换为频谱图,为后续机器学习方法和数值分析方法提供了优质的音谱特征。
1.2 当前音符级转录的不足
近年来主流的AMT研究中,识别结果的重点主要强调了起音点和音高,对于音符止音点、响度和音色的问题并没有给予太多的关注。而当前音符级转录最重要的问题在于无法完全预估整个音符的时值信息以及多音级估计问题上无法得到提升。如果只是识别音符的起音点,并将起音点处的音高当成两个起音点之间聚合而成音符音高的话,会造成音符时值估计不准的问题。同时多音级识别如果仅仅考虑当前时刻上下文的音符频谱,而不考虑音符序列全文中的上下文信息,多音级识别问题的性能将不能得到提升。
如图2所示,可以看到图中a处,由于图中的音符在持续过程中有新的音符出现,于是转录会直接将旧音符进行截断。图中b处,其中一个音符的停止时间应该提前,但是由于下一个音符出现时间较晚,因此这里音符的停止时间将会延后。如此一来,当出现种种限制时,当前音符级的自动音乐转录根本无法判断准确的音符时值。此外,图中显示的多音转录结果也并不是十分完美,错音和漏音出现的频率仍旧不低。针对此问题,提出了针对音符起止点的自动转录方法,帮助解决当前无法准确判别音符时值和多音级估计瓶颈的问题。
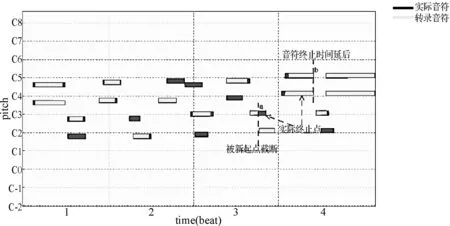
图2 识别方法中存在的问题
2 基于CNN和CRNN的转录方法
2.1 基于CNN的转录方法
基于CNN的转录方法提出一种单独识别音符起止点和音高的模型,解决了文献[12]不能完整预估时值的问题。钢琴发声的敲击和衰减阶段(对应音符的起点和止点)在频谱图上特性会非常明显,CNN具有良好的平移不变性,能够处理频谱图中多个方位的起止点特征。基于CNN的转录模型如图3所示。

图3 基于CNN的转录方法模型
模型首先接受一个输入音乐信号,在预处理过程中通过CQT提取时频域信息。参与训练的有三个神经网络,模型中起点识别和止点识别都使用两个单独的卷积神经网络进行,再利用一个额外的多音级识别网络识别起点和止点附近的音级。分开处理起点和止点问题能够让模型专注解决一个问题,使训练效果达到最优。
(1) 数据预处理。
为了将音频转换为计算机能够理解的形式进行训练,数据预处理包括两个阶段:音频预处理和MIDI标注预处理。
音频预处理即利用常数Q变换,将频谱映射到log2的线性空间,使用的采样频率为44 100 Hz,窗口长1 024。网络模型的输入是一幅高确定、长不确定的频谱图,为频谱图中每帧划定一个264频带×9帧的滑动窗口,固定该帧前后延伸4帧(在开始和结束部分补0),在多音级识别中,在起止点附近选择同样大小的窗口,作为多音级识别的输入。多音级频谱窗如图4所示。

图4 多音级识别的频谱窗口
MIDI标注预处理是将MIDI文件转换为计算机能理解的格式。MIDI是一个二进制文件,由头文件块和音轨块组成[3]。利用MIDI元信息就可以获取到MIDI的音符序列,将音符序列表示成三元组(NoteNum, Start, Duration)的形式,将多音轨合并到单音轨之后以Start作为排序键排序。之后需要将Start和Duration代表的MIDI内部事件转换成现实事件,计算出现实时间后利用音频预处理中的时频域变换法将时间变换到时间帧中,与频谱图对应。变换后的三元序列为(NoteNumber, StartFrame, EndFrame)。
(2) 起止点与多音级识别。
基于CNN的转录方法第一阶段是进行起止点识别,起止点识别是一个二分类问题,模型的输入是2.1(1)节中的频谱窗在每个时间帧上的264×9的切片。若输入音频恰好为起/止点则标注为1,否则为0。无差别起止点识别采用的是文献[12]提出的结构。最终得到的是无差别起点序列(式(6))和无差别止点序列(式(7)),其中T为音乐总时间帧数。
S=(s1,s2,…,sT)si∈{0,1}
(6)
E=(e1,e2,…,eT)ei∈{0,1}
(7)
针对音乐图像信息的时序特征,设计了一种专用于提取频谱音级特征的网络结构来识别多音级。第一层使用了标准的3×3的卷积核来提取空间和时间特征,然后使用了m×n的卷积核来卷积频谱。m×n的卷积核能够同时学习频率和时间信息。这些滤波器可以根据m和n的设置方式学习不同的音乐元素,并且打击乐乐器的特征在于频率的时间演变不会很长,因此卷积核可以捕捉到小时间尺度内的声音特质。之后使用2×2的最大池化层进行特征压缩,再使用11×1的频域卷积核卷积空间信息,继续池化拉平后通过两层全连接层,经Sigmoid激活函数激活神经元后输出在88个音级上的概率,采用Cross-entropy进行损失计算,如图5所示。

图5 基于频谱特征的网络结构
由于多音级识别和起止点识别是两个独立训练的过程,因此多音级识别的训练数据是在标注的音符起止时间帧挑选出来的。在预测阶段此方法首先会预测音符起止时间帧,然后再通过选取起止时间帧上的频谱切片进行多音级估计。
最后一步是进行起止点对齐,它并不参与到网络训练当中。对齐即将式(6)和式(7)的序列进行匹配,并生成对应的三元序列与标准MIDI进行比对。在测试阶段,得到无差别起止点序列S和E之后,标记其在频谱上的时间帧位置得到起止点帧序列。音级识别基于起止点帧序列,最后得到多音级矩阵D来表达整首音乐的所有音符起止点:
(8)
遍历D得到最后的音符三元组Note序列,并且过滤掉损坏的三元组,如式(9)所示。匹配Dp,t′=0对于任何的ts Note={(p,ts,te)∨Dp,ts=1,Dp,te=-1} (9) 式中:p为音级,代表88个钢琴键,满足0 2.1节中提出的CNN的转录方法没有考虑起止点处多音级向量的时间关联性,因此对齐效果不佳;并且丢失了原本音乐的时序性特征,忽略了多音级估计的音符内与音符序列的上下文信息,因此多音级识别上效果不是十分显著。针对以上问题,本文提出了一种基于卷积循环神经网络的转录方法,将CNN和RNN进行结合,并添加了一层自注意力层形成CRNN网络,最后输出与标注同样个数的单元数,同样采用Cross-Entropy进行损失函数的计算。这种网络结构可以同时从时间和空间维度上学习音乐特征,实现端到端的音符起止点识别。见图6。 图6 基于CRNN的音符自动转录方法 与基于CNN的方法不同,该方法需要将频谱图按块切分输入网络中,块是n帧频谱中的聚合态,互相不重叠。第一步仍是利用CNN进行特征提取,得到一个p×step的步长向量,p为特征高,step为时间步长。之后被切分为step个p×1的向量输出到LSTM中,经过自注意力层后全链接输出n维向量,转录完成后同样进行起止点对齐生成音符序列。 (1) 数据预处理。 识别的预处理工作仍包含两部分:音频预处理和标注预处理。 基于CNN的转录方法在进行音频预处理的时候是由单个帧为中心划分窗口截取而成的,并且帧与帧之间还有重叠部分。本节中模型需要识别频谱切片的内部的时间结构和音级结构,所以这种小时间切片不能满足要求。除此之外还必须保证完整的上下文关系,针对以上要求,音频预处理需要分为两部分。第一步,选择音频时间切片长度。选取的音频时间切片长度不应过长,也不应过短。过长会影响整体训练速度,导致LSTM整体性能下降;过短则没有包含太多有意义的信息。因此在切片上选取了2 s、4 s和8 s的长度分别进行了实验。第二步,消除无上下文的音频片段。无上下文的音频片段指的是在音频切片中有来自上一个切片的音频,或者未完全结束的音频。为了不影响训练和识别的质量,因此在频谱上对这些音频进行了平滑处理。 与2.1节中的方法不同的是,本节提出的网络模型将起止点与音级三者一并进行识别,因此采用了一种新编码来表示音高和起止点信息。MIDI中的声音状态分为音符激活态和音符非激活态,而音符的开始和结束状态都是一种特殊的状态,于是该方法将音符的状态分为三种,起状态、止状态和非起非止状态。每个音级的三种状态需要一个二维向量进行编码: (1,0)表示这个音符的起状态,这种状态的条件是该音符前一帧处于未激活状态而当前帧处于激活状态; (0,1)表示这个音符的止状态,这种状态的条件是该音符当前帧处于激活状态而后一帧处于非激活状态; (0,0)表示这个音符的非起非止状态,这种状态的条件是该音符的前后帧都属于激活或者非激活状态。 对每个音级进行这样的编码,则需要88×2=176维的向量。利用2.1节方法中的三元组(NoteNumber, StartFrame, EndFrame)就可以构建一个标注矩阵Mtrue,矩阵的高P=176,宽为输入频谱切片的时间帧数T。 (2) 基于CRNN的起止点识别模型。 本节的模型如图7所示,首先使用CNN提取频谱特征,然后将特征切片输入到后续的序列识别层中,这个序列识别层在每个时间步上的输出也会输入到自注意力层,自注意力层主要可以通过寻找音符序列的内部依赖性提高识别准确率。经过自注意力层的向量会通过一层全连接,使用Sigmoid激活函数输出176维的概率真值,表示起止点在当帧的激活情况,并同样使用Cross-entropy计算损失函数。在预测阶段会选择一个阈值,将每一维输出值分类为0或者1,表达音符起止点中的信息。下面详细介绍该模型的各个部分。 图7 基于CRNN的音符起止点识别模型 首先依照2.2(1)节的数据预处理方法,将音频谱图处理成切片,再得到音符起止点标注矩阵,标注矩阵的每一列就对应着一个时间步的标注。模型使用CNN作为频谱切片的特征提取器,再利用后续的RNN来对频谱特征进行识别工作。本方法所采用的CNN网络结构类似于2.1(2)中的网络结构,如图8所示。 图8 特征提取器结构 此网络结构中的卷积核同样含有在2.2节中叙述的卷积核特性。为了方便进行特征压缩,实验将频谱切片的时间轴和频率仓轴进行转置。因此,特征提取器的输入为一个高T帧、长264的频谱仓的特征谱图切片。首先谱图会经过一个3×3的卷积核,提取频谱内部的时间和空间上细节特征。接下来经过一个3×12的卷积核,既可以用于在频谱的频域空间上提取音乐八度范围内的频谱特征,又可以在小范围的时间内提取到频谱的变化特征。再接下来经过一个1×2的最大池化将频谱的频域进行压缩,减少由于卷积操作所导致的频域特征均值偏移。1×11的卷积核主要可以用来提取频域长范围内的空间特征。最后一层1×2的最大池化与之前的原理类似,通过将特征Reshape之后,特征维度将变换为(T,3 712),最后在频域维度上再使用一层全链接层,将维度变换到(T,768),特征抽取工作就完成了。 在序列识别层中,采用RNN来对上文提取的特征进行识别,通常采用LSTM作为序列模型进行识别。由于LSTM只能根据前一时刻的时序信息来预测下一时刻的输出,但音符序列不仅跟前一状态有关,还可能和未来状态有联系。比如预测音符起点时,不仅依赖于之前的状态和当前输入的特征切片,还与未来该音符可能出现的止点状态有关,在预测止点音符时,同时需要依赖之前的起点音状态。因此本模型中引入了双向LSTM(Bidirectional LSTM,BiLSTM)。 LSTM传递的信息会随着时间步主机传递而渐渐失效,因此当音频长度过长,LSTM对这种音乐特征的学习会呈现一定的下降趋势,针对这一问题,继而在网络结构中加入了自注意力机制,通过扁平化的位置计算方式来解决这种线性遗忘的问题。 实验采用的是MAPS(MIDI Aligned Piano Sounds)数据集和MAESTRO(MIDI and Audio Edited for Synchronous TRacks and Organization)数据集。MAPS数据集提供了CD音质(44 kHz采样立体声音频)的钢琴录音和已对齐的MIDI文件作为录音的标注。数据集的大小约为40 GB,MAPS使用了一些自动生成技术,提供了音乐MIDI文件与相对应的音频,提供了大量的声音数据和可靠的标注(音高和起止时间)。在实验当中,本文使用MUS音乐集中70首音乐作为训练集,19首音乐作为测试集。MAESTRO数据集是谷歌与国际钢琴比赛Piano-e-Competition的组织者合作得到的数据集,该数据集中使用的都是比赛中钢琴演奏的原始数据,数据量达到90 GB左右。由于时间关系,本文仅选用了MAESTRO数据集中2017年的比赛曲目进行训练和测试。MAESTRO 2017中有283首钢琴曲目,本文将使用这些钢琴曲中226首乐曲作为训练集,使用57首用作测试。实验采用的硬件环境为Linux 4.15.0-72-generic,Memery220G,物理显卡GeForce GTX 1080Ti,显存11 GB。 基于CNN的音符级钢琴转录方法的总共包含三个实验:无差别起止点识别、多音级识别和起止点对齐。基于CRNN的音符级钢琴转录方法包括两个实验:音符起止点识别和起止点对齐。首先,第一个模型的无差别起止点识别属于二分类问题,使用二分类问题的评价标准。其次,第一个模型的多音级识别和第二个模型的音符起止点识别采用了同一个标准。最后两个模型起止点对齐部分都使用了同一标准。 二分类问题利用精准度(Precision)、召回率(Recall)和F值(F-Measure)值作为评价标准,它们的计算方式如下: (10) (11) (12) 多音级识别是一个多标签多分类问题,文献[1]提出了一种进行多音级分类的评价标准。依照上分预测分类的四种定义,而这里这些量进行了延伸。TP(t)的定义为,统计起止点帧t处预测音级i被分为正类时,实际音级i也为正类的个数。类似地,FP(t)定义为在起止点帧t处预测音级i被分类为负类时,实际属于正类的个数;FN(t)定义为在起止点帧t处音级i被分类为负类时,实际也属于负类的个数。多音级分类的评价指标如下: (13) (14) (15) 除此之外,为了让转录更直观地体现准确性,实验使用了一种精确匹配率的方式EMR(Exact Match Rate),EMR评价将多标签问题降级到二分类问题上,它认为只有预测标签和真实标签全部匹配才被分为正类,否则就是假类,如式(16)所示。式中:T(t)函数表示当预测帧和实际帧所有音级状态完全匹配时输出1,否则输出0。 (16) 最后,针对起止点识别,通过将能对齐上的起止点数占起止点平均值中的比例来进行计算。对齐率MR如下: (17) (1) 无差别起止点实验。如表1和表2所示,CNN的判别是三种方法中效果最好的。在无差别起点识别中,CNN的F1值比DNN高出0.051 4,比双向BiLSTM高出0.030 2;在无差别止点识别当中,CNN的F1值比DNN要高0.071 7,比LSTM要高0.016 1。 表1 基于MPAS的无差别起止点识别 表2 基于MAESTRO的无差别起止点识别 (2) 多音级识别实验。本文将设计的卷积网络模型分别和DNN、LSTM、Troxel[7]和Sigtia[8]模型进行了对比。在MAPS和MAESTRO数据集上,本文网络在F1值上比DNN要高出0.137 7和0.140 5,比LSTM高出0.112 1和0.113 1,比Sigtia的模型要高出0.053 7和0.067 8,比Troxel的模型要高出0.009 4和0.000 5,在两个数据集上分别达到了最高的80.68%和82.83%。如表3和表4所示。 表3 MAPS ENSTDkCl数据集——起点上多音级识别 表4 MAESTRO 2017数据集——起点上多音级识别 (3) 起止点对齐实验。在得到识别的音符起止点后,再进行起止点对齐,对齐结果见表5。 表5 基于CNN的起止点对齐 (1) 起止点识别实验。如表6和表7所示,音符起止点的识别实验分三种情况进行,分别将频谱切片切为2 s、4 s和10 s,然后将整个频谱切片作为模型输入,预测每一帧的起止点和多音级情况。与基于CNN的转录识别纵向对比,可以看到基于CRNN的音符起止点识别在F1与前者相近时,整精确匹配率上要优于前者。可能因为CRNN对起止点及其音级是逐帧判别的,准确预测空帧的能力给CRNN的精确匹配率上带来了很大的优势。但是仅在F1值上可以看出,使用CRNN端到端地识别起止点,可以给识别率上带来较大的提升。 表6 基于CRNN的音符起止点识别(MPS数据集) 表7 基于CRNN的音符起止点识别(MAESTRO数据集) (2) 起止点对齐实验。基于CRNN的起止点对齐结果如表8所示。可以看出基于CRNN的起止点对齐在对齐率上比基于CNN的起止点对齐要好,其中在MAPS的数据集和MAESTRO数据集比基于CNN的结果要高出0.403 3和0.308 9。可以证明,本文使用的CRNN很大程度上能弥补仅基于CNN的音符起止点在对齐上的劣势。 表8 基于CRNN起止点对齐 如表9所示,音符序列正确性的定义为转录正确音符序列占全部实际音符序列之比。其中Troxel的CNN+音乐语言模型虽然在正确性上要优于两阶段CNN+音乐语言模型,但是两阶段CNN的模型有完整的音符时值估计方法,而CRNN的音符转录方法是高于前两种转录方法的,最后CRNN+自注意力机制的模型又优于仅使用CRNN的模型,并且在长频谱片段中拥有更完美的性能表现。 表9 音符序列正确性结果 本文提出的两种音乐转录办法还是借鉴自传统的机器学习。传统的机器学习对于多分类问题一般采用N元交叉熵函数进行损失计算和反向传播。传统机器学习的标签类别之间呈正交关系(譬如猫狗识别),类与类之间没有明显的内在联系和结构。对于音乐而言,特别是钢琴乐,音与音之间存在特殊的物理联系和逻辑联系,简单地采用交叉熵函数在很大程度上会损失掉钢琴键值之间的数据联系性。尤其是在对和弦类型的音符识别时候,会丢失大部分数据,在反向迭代的过程中不能很好地矫正模型。基于本文,后续希望能够探索一种符合钢琴乐的距离判定方法,从而在优化器进行梯度下降的时候能够更全面地提供平滑准确的梯度来训练参数。2.2 基于CRNN的转录方法



3 实 验
3.1 实验评价标准
3.2 基于CNN的转录实验结果





3.3 基于CRNN的转录实验结果



3.4 转录音符序列实验

4 结 语
