融合LDA和TF-IWF的健康科普文章混合推荐方法研究*
2022-07-06张培颖
周 欢,张培颖
(湖南工业大学商学院,湖南 株洲 412007)
1 引言
习近平总书记在全国卫生与健康大会上的讲话中提到“要倡导健康文明的生活方式,树立大卫生、大健康的观念,建立健全健康教育体系,提升全民健康素养,推动全民健身和全民健康深度融合。健康中国就是看病更方便,更容易”[1]。2018年,国务院办公厅印发的《关于促进“互联网+医疗健康”发展的意见》[2]中提出要健全“互联网+医疗健康”服务体系,完善“互联网+医疗健康”支撑体系。2021年第48次《中国互联网络发展状况统计报告》[3]显示,截至2021年6月,我国的网民规模高达10.11 亿,其中,在线医疗用户规模达到了2.39亿。这意味着随着互联网技术的不断发展,国家对在线健康领域关注度在不断提升,在线医疗健康行业的发展规模也在不断扩大。
在线健康社区是用户搜集和交流健康信息的平台,其科普文章板块是用科普的方式,以文字或视频的形式将健康领域的科学知识、科学方法、科学思想和科学精神传播给用户,从而培养和提高公众健康素养。对在线健康社区的用户实现个性化科普文章的推荐,可以减少医疗资源的浪费、消除患者的就医误区,为医患沟通建立起良好的桥梁,减少疾病的发生,从而提高个人的卫生素质、提升整体国民身体素质。但是科普文章的数量是海量的,如何从这些海量的科普文章中找到对用户有用的信息,是亟待解决的一个问题。目前,还未有研究对此方面展开分析,因此,本文以“好大夫在线”为例,运用Latent Dirichlet Allocation(LDA)主题模型、Term Frequency-Inverse Word Frequency(TF-IWF)词频统计方法、Collaborative Filtering Recommendation(CF)以及Content-Based Recom⁃mendations(CB)等方法,从“好大夫在线”经典问答板块中的用户提问文本分析用户需求,再从“好大夫在线”所提供的科普文章分析文章所表达的主题,进而为用户生成个性化科普文章推荐。
本文的主要贡献如下:(1)从融合用户观点和科普文章内容的新视角出发展开研究,避免了从单一视角进行研究的局限;(2)使用LDA 主题模型,从文本中挖掘隐含主题,并结合基于TF-IDF算法改进的TF-IWF算法,降低了同一类型的文本数据影响词语及主题权重的比重,更精确、合理地判断词语及主题在文档中的重要程度;(3)提出的科普文章推荐算法,拓宽了在线健康社区领域及推荐领域的研究范围。
2 相关研究
通过梳理在线健康社区、健康科普文章及主题提取的相关文献,对其进行综合和分析,并进行简要评述。
2.1 在线健康社区相关研究
在线健康社区是用户搜集和交流健康信息的平台。随着人们生活水平的提高,健康问题成为社会关注的重点,这推动了在线健康社区的发展,也吸引了众多专家对此展开研究的目光。目前,在线健康社区的研究主要集中在以下几个方面:在用户参与行为的研究方面,刘萌萌和邓朝华[4]认为用户参与行为包括社会支持和网络社交行为,例如医患交互和情感支持属于社会支持的行为,而用户的浏览、评论、点赞或收藏等此类行为则归于网络社交行为;Mark和Debra[5]表示用户之所以会加入到在线健康社区中,是因为他们可以在社区中获得社会支持,也可以从其他成员那里得到动力及建议;许云红等[6]进一步将用户行为划分为三个级别,利用增长模型对其参与行为进行研究,研究结果发现用户积分、活跃度、好友平均隐私数、好友平均发帖数等变量对于三个级别的用户在增长模型的类别产生的影响的显著性和影响程度均有差异。在医生推荐方面,熊回香等[7]利用word2vec模型、TF-IDF算法、余弦相似度和文本相似度分别计算患者和医生的相似度关系,形成基于患者的医生推荐集和基于医生的医生推荐集,然后融合两个推荐集进行医生推荐;潘有能和倪秀丽[8]基于Labeled-LDA 模型挖掘健康问题的潜在主题,进而明确医生的专长,达到精准医疗专家推荐的目的;Mondal 等[9]没有从关系型数据模型进行研究,而是通过建立一个比关系型数据模型更加有效的多层图数据模型,并在实验过程中引入信任因子,实现更加精准的医生推荐。
当前对在线健康社区的研究,主要是通过研究用户的参与行为,明确用户使用在线健康社区的目的,并以用户参与行为所产生的数据为基础,对医生推荐进行研究,帮助用户快速、高效地获得自己想要的信息及资源。
2.2 科普文章相关研究
健康科普是以科普的方式将健康领域的科学知识、方法、思想和精神传播给公众,旨在培养和提高公众健康素养的长期性活动。健康科普文章则是以文字进行健康信息传播的一种健康科普形式。目前,有关健康科普文章的研究还比较少,对健康科普展开研究的学者有:梁海柱[10]就如何充分利用文章素材,将专家的表述和作者的提问巧妙地连接在一起,形成一篇逻辑清晰、结构合理的文章,对文章写作方法进行了研究;贾建敏等[11]分析了高校医学期刊开展健康科普的意义,新媒体在推动健康科普中的优势以及提出了高效医学期刊实施健康科普的策略;还有部分学者对健康科普在微信公众号中的传播领域展开研究,如高菲等[12]探究了肿瘤专科医院微信公众号健康科普内容及传播规律、朱秋艳和韦婉[13]对全国6所三甲精神专科医院微信公众号健康科普传播现状进行了分析。
目前,已有的对健康科普的研究大多集中在健康科普的内容及其写作、实施健康科普的意义方面,而未将研究的重点放在用户规模在不断增大的在线健康社区及社区中健康科普文章推荐方面。
2.3 主题提取相关研究
主题模型是通过将高维单词空间映射到低维目标主题空间,以使读者能更好地理解文档集合所讨论的主题信息,早期的主题模型主要有La⁃tent Semantic Analysis(LSA)和Probabilistic Latent Semantic Analysis(PLSA)。然而,LSA 模型面临着“一词多义”和“多词一义”等问题,PLSA模型对特定文档中的主题的混合比例权重没有做任何假设,在实际训练中会出现过拟合的情况[14]。针对早期这两种模型的缺点,Blei 等[15]提出了LDA 主题模型这种无监督机器学习技术,其通过一个概率生成模型将所有文档参数联系起来,进而揭示文档的主题信息。LDA 主题模型提出之后,大量的专家学者对此模型展开了更为深入的研究,同时也将此模型应用于众多领域。如:李莉等[16]基于LDA模型,以客服聊天记录为例,对交互式文本主题挖掘进行了研究,其研究表明,LDA模型有较好的主题挖掘效果;王珠美等[17]利用LDA 主题模型对农产品在线评论进行情感分析;杨磊等[18]通过构建Q-LDA 模型对在线健康社区的主题进行挖掘;李振鹏等[19]利用LDA主题模型,基于天涯杂谈2015 年全年帖子,对其标题进行文本挖掘。此外,TF-IWF 词频统计方法常用于词项权重计算,其是由IF-IDF 词频-逆文档频率演化而来的,IFIDF 方法通过单词在整个文档语料库中的反比来确定特定文档中单词的相对频率[20],但这种方法存在特征词提取不准确、特征词权重方差较小的问题,导致文本之间区分度低、分类效果不佳。因此,李昌兵等人[21]提出使用IF-IWF方法扩大特征词权重值的范围,增加文本集权重值的方差,在一定程度上解决了短文本内容稀疏的问题,提高了短文本分类的性能。
目前,关于主题提取的研究,主要集中于LDA主题模型及TF-IWF 词频统计方法方面。基于LDA 主题模型的研究涉及很多领域,如农产品领域和论坛领域。TF-IWF主要用于文本分类,然而应用LDA 主题模型及TF-IWF 于在线健康社区领域的研究数量很少,而利用这种模型对在线健康社区中的科普文章板块进行分析的研究则是更为少见。
健康科普文章提供的健康医疗信息可以帮助在线医疗用户提高健康素养,养成良好卫生习惯,还能帮助用户进行健康自测,并有针对性地就医问诊,减少医疗资源的浪费,提高就医问诊的效率,而LDA 主题模型和TF-IWF 可以清楚地表达出科普文章的主题信息。因此,本文提出基于LDA和TF-IWF的健康科普文章推荐方法,旨在更加有效地利用在线健康社区中的科普文章主题信息,从而为社区中用户自动推荐满足其需求的科普文章,实现个性化推荐。
3 基于LDA和TF-IWF的健康科普文章混合推荐模型构建
3.1 推荐框架
本研究基于python获取在线健康社区中医患问答文本及科普文章文本并进行分析,其中用户提问文本研究分两部分进行:第一部分涉及的是用户提问文本中的其中一个主体即患者,本文拟从患者所患疾病类型、可能患有的疾病类型及患者需求意向3个维度进行分析;第二部分涉及的是用户提问文本内容,具体是获取患者提问的主题特征和意向特征,采用LDA 主题模型、TF-IWF 词频统计等方法进行主题揭示,并通过CF推荐算法生成基于用户的推荐列表。对科普文章的分析同样分两部分进行:第一部分是从文章的类型及所科普疾病的类型2个维度展开;第二部分是对科普文章的特征分析,应用LDA 主题模型、TF-IWF 词频统计等方法进行主题揭示,并通过CB推荐算法生成基于文章的推荐列表。最后,对基于用户的推荐列表和基于文章的推荐列表基于相同主题进行加权混合,生成最终的混合推荐列表。推荐框架如图1所示。
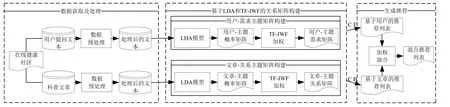
图1 基于LDA和TF-IWF的健康科普文章混合推荐方法框架
3.2 基于LDA和TF-IWF的关系矩阵构建
3.2.1 文档主题聚类
本研究拟从“好大夫在线”平台中的提问文档集和科普文章语料库中提取出各自包含的主题,并基于提取的主题完成用户文章推荐。LDA主题模型常用于文档主题聚类,是一种无监督机器学习技术,其认为每篇文章是由多个主题混合而成的,而每个主题可以由多个词的概率表征。因此,本实验使用LDA主题模型来识别用户提问文档集和健康科普文章语料库中潜在的主题信息。此外,该模型也是典型的词袋模型,认为文档是由互不关联且无先后顺序的词汇组成,因此使用此模型可以将本研究采集的文档,根据词在文中的概率分布来反映用户提问文档及健康科普文章文档中的主题分布。对于语料库中的每篇文档,LDA定义了如下生成过程:
(1)从狄利克雷分布α中取样生成提问文档i1和文章文档i2的主题分布θi;
(2)从主题的多项式分布θi中取样生成提问文档i1和文章文档i2的第j1和j2个词的主题,i jZ;
(3)从狄利克雷分布β中取样生成主题Zi,j对应的词语分布φZi,j;
(4)从词语的多项式分布φZi,j中采样最终生成词语Wi,j。
LDA的图模型结构如图2所示:

图2 LDA图模型结构
其中,K为主题个数,M为文档总数,N是第m个文档的单词总数。本研究设置K=15,提问文档M=5 000,文章文档M=1 000。
3.2.2 词项权重计算
计算各个词项的权重,可以更为清楚地表示各个主题所包含的词项及这些词项所占的比重,以及每个文档所表示的主题及这些主题在文档中的重要程度。本文采用的词项权重计算方法为TF-IWF 词频统计方法,其中TF 如公式(1)和(2)所示表示的是词频,其中分子nj,i表示词语tj在提问文本i1和文章文本i2中的频数,分母表示文档中所有词汇量之和。如公式(3)和(4)所示,IWF计算的是逆词频,其中分子表示语料库中所有词语的频数之和,分母ntj表示词语tj在提问文本和文章文本语料库中的总频数。

因此,本实验采用TF-IWF 词频统计方法,先计算文档集中每个词语的词频TF,再计算每个词语的逆词频IWF,最后将两者生成的结果对应相乘,其表达式如公式(5)所示:
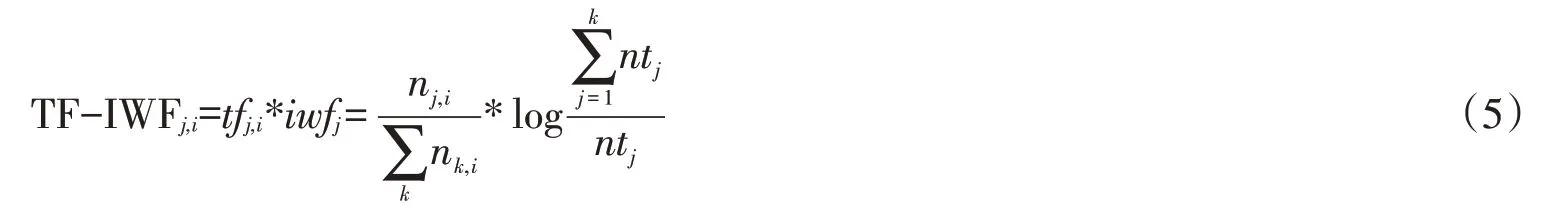
3.2.3 关系矩阵构建
用户-需求主题矩阵建模及主题提取:若只提取某个健康问题的文本,其内容较少,无法获得完整充分的医学主题。因此,本文根据“好大夫在线”平台的经典问答板块提取用户需求所涉及的医学主题,将用户提问文本中的提问标题、疾病描述和用户希望得到的帮助3 个文本集作为建模的训练集,通过TF-IWF 词频统计方法加入权重,得到提问文本主题-词项的概率分布,从而生成用户-需求主题矩阵。
文章-关系主题矩阵建模及主题提取:单独提取某类疾病的科普文章,并不能充分地获取到医学主题,推荐效果也会大打折扣。因此,本文根据医院对“好大夫在线”平台中的“医学科普”类文章进行提取,对文章的标题和文章的科普内容文本集进行分析,将其作为训练集,通过TF-IWF 词频统计方法加入权重,得到科普文章主题-词项分布,进而生成文章-关系主题矩阵。
3.3 科普文章推荐
3.3.1 基于用户或文章的推荐
数据预处理后得到的文本通过运用LDA主题模型和TF-IWF加权计算后会生成用户-需求主题矩阵和文章-关系主题矩阵,研究需要运用相关推荐算法,对上述得到的两个矩阵进行处理,从而为用户推荐符合其需求的健康科普文章。目前,常用于推荐的算法有CF 推荐算法和CB 推荐算法,本文运用基于文章的CF 推荐算法为用户推荐科普文章,具体步骤为:
(1)根据主题和词语计算各篇健康科普文章之间的相似度;
(2)根据各篇文章的相似度和用户的需求数据为用户生成基于文章的推荐列表。
利用CB 推荐算法为用户推荐科普文章的具体步骤为:
(1)根据用户提问文本中的提问标题、疾病描述和意向需求生成用户需求特征表示;
(2)根据健康科普文章文本中的文章标题和文章内容生成文章关系特征表示;
(3)通过比较之前两步生成的用户需求特征和文章关系特征为用户推荐一组相关性最大的科普文章。
3.3.2 加权混合推荐
本文采用加权混合推荐技术对基于用户的推荐列表和基于文章的推荐列表进行混合推荐,利用CF 和CB 推荐算法的推荐结果,通过加权来获得每篇推荐文章的加权得分,根据最终的加权得分来排序。具体加权步骤为:以主题作为连接中介,从用户-需求主题矩阵及文章-关系主题矩阵找到相对应的主题编号,根据主题编号分别在两个矩阵中找到主题关联度即用户-需求主题矩阵中的主题权重和文章-关系主题矩阵中的主题权重,对应的主题关联度相乘后相加,形成最终的用户-文章关联度矩阵,以清楚地表示符合用户需求的文章及其需求程度即权重。
4 实验及结果讨论
本文通过采集真实数据,基于python 平台对所提出的方法进行实验,并对实验得到的结果进行检验和评估。
4.1 数据获取及处理
4.1.1 数据获取
好大夫在线、春雨医生、39健康网、丁香医生、寻医问药等是我国当前较为大型且知名的在线健康社区平台,考虑到“好大夫在线”所收录的医院、医生规模量大,数据较为容易获得以及此平台功能强大等方面的因素,本文选择以“好大夫在线”作为实验的数据来源,利用python爬虫获得“好大夫在线”经典问答板块中的患者提问文本集合和以“好大夫在线”所收录的医院为单位,爬取各单位医生所发布的“医学科普”类健康科普文章集合。截至2021 年9 月15 日,“好大夫在线”平台收录了全国9 759家正规医院863 058位医生以及这些医生累计发表的总数达到1 484 038篇的科普文章,对各类疾病都有很好的指导意义。另外,此平台经典问答板块提供了共9 000 条经典的用户健康提问问题。
本文从1 484 038篇科普文章中选取了11 911篇“医学科普”类文章,考虑到设备运行时间的问题,实验随机抽取了11 911 篇中的1 000 篇文章,以及从9 000 条经典用户健康提问问题中选取了5 000条提问文本,其中用户健康提问问题文本的获取分为3个部分进行:一是用户提问标题;二是用户对于疾病的描述;三是用户希望得到的帮助。科普文章文本的获取从两方面展开:一是科普文章标题文本的获取;二是科普文章内容的获取。本文后续实验皆是基于以上两个文本集的共5个部分的数据来进行的。
4.1.2 数据处理
利用python爬虫获取到的原始文本数据充斥着大量的噪音数据,若直接利用这些文本数据进行分析和主题挖掘,所得到的效果必然不理想。因此,必须要对这些原始文本数据进行降噪处理。在对用户健康提问问题和“医学科普”类文章进行LDA 建模前,需要对其进行分词及停用词过滤等操作,以降低文本的空间维度及提高LDA 建模的效果。
本文采用的是jieba中文分词算法对原始文本数据进行分词,但分词后的文本中还包含着大量的无用词,如方位词、语气助词、代词和介词等,这些无用词不仅对本文的实验分析毫无用处,还会对实验效果产生负面影响。本研究主要通过增加停用词表以及人工添加语料库中的无意义字符,以实现对文本的降噪处理,提高LDA 的建模效果。此外,由于文本数据中会包含一些疾病的英文缩写,对主题的揭示具有一定的作用。因此,不能直接删除文本数据中的英文。本文通过整合百度停用词表、中文停用词表、哈尔滨工业大学停用词表和四川大学机器智能实验室停用词库,形成了一个新的停用词表,并利用这个新的停用词表对文本数据进行处理。
为了验证本研究所采取的数据预处理方法的正确性和有效性,首先将小部分文本数据经过上述预处理后,输入到LDA模型中运算,观察主题与词项的分布,通过人工筛选过滤掉未成功处理掉的不必要的特殊停用词,并将这些停用词添加到本研究所采用的停用词表中,将最终整合的停用词表用于所有数据处理。
4.2 实验结果
本研究将LDA 主题模型设置超参数α=1,β=0.01。令K=15,表示最终获得15 个主题,n=60,表示循环迭代抽样的次数为60次。将用户提问文档中的提问标题、疾病描述和意向需求以及健康科普文章文档中的文章标题和文章内容进行数据清洗后运行LDA 主题模型,得到关于用户提问文本和科普文章文本的15 个主题-词项分布;随后运用TF-IWF词频统计方法使上个步骤得到的主题-词项分布的权重值更加合理化,从而得到结果更加明确清楚的主题-词项分布和文本-主题分布;再以所得到的主题为中介,通过运用CF推荐算法和CB 推荐算法分别生成基于文章的推荐列表和基于用户的推荐列表,并通过对基于文章和基于用户的推荐列表进行加权计算生成最终的混合推荐列表。
4.2.1 提问文本主题聚类结果
提问文本的数据获取分为3个部分,分别是提问标题、疾病描述和意向需求。对这3个部分数据预处理后分别运用LDA 和TF-IWF 方法进行实验,将每个主题的前10个单词显示出来,由此生成提问文本的提问主题-词项分布和提问-主题分布,其中一条提问文本代表一个用户。
生成的提问主题-词项分布表示提问文本的主题及表示主题的词项,提问-主题分布显示的是用户提问文本及其文本表示的主题信息,其中提问文本所包含的主题数量不一,包含主题数量较多的提问文本较包含主题数量少的提问文本的提问内容更多。提问主题更为分散,这可能是由于以下几种原因造成的:第一,提问的用户自身掌握的医疗专业知识不足、所知道的医学专有名词少,难以用简洁、有效的语言描述自身病情或身体状况;第二,提问用户不了解自身患病情况,在对自身病情的描述中难以集中在某种或某类病状;第三,本文爬取的包含主题较少的用户提问文本,可能在线下或者其他线上就医问诊流程中已经获知自身患病情况,因此在提问板块进行提问时,目标较为明确。
4.2.2 科普文本主题聚类结果
实验从文章标题和文章内容两方面来获取科普文章文本数据,并对预处理后的数据运用LDA和TF-IWF 方法,将每个主题的前10 个单词显示出来,并生成科普主题-词项分布和科普-主题分布。
科普主题-词项分布显示的是文章主题及表示主题的词项,科普-主题分布代表的是文章表达的主题,其中大部分文章包含多个主题,而存在少部分文章却没有包含任何主题,这表明前者文章中的主题丰富,涉及的健康知识偏多,而后者文章的主题并没有被包含在本实验所获得的主题库中。从算法视角来看,这可能是在进行主题聚类计算时,主题数K设置过小或循环次数n过多所导致的。从文本内容来看,这可能是由于当前科普文章内容过少所致。此外,与提问主题-词项分布和提问-主题分布对比,科普主题-词项分布和科普-主题分布的权重值均偏小,这可能是由于在运用TF-IWF计算词项权重时,科普文章文本包含的词语数量比用户提问文本包含的词语数量多得多所而导致的结果。
4.2.3 混合推荐结果
本研究的混合推荐以4.2.1 和4.2.2 所生成的提问-主题分布和科普-主题分布中的主题为连接媒介,提取提问-主题分布中的主题权重与科普-主题分布中的主题权重相乘后相加实现混合加权,定义Rm*n为用户-主题评分矩阵,Hx*n为科普文章-主题评分矩阵,rui为用户u 对主题i 的评分,hai为科普文章a 对主题i 的评分,经加权混合生成最终的主题评分预测矩阵,并以推荐列表的形式显示推荐结果。加权步骤如图3所示。

图3 混合加权步骤
本实验将推荐列表的长度设置为10,即为每位用户推荐混合权重最高的前10 篇科普文章,其结果如表1所示。本实验以5作为阈值,相同文章推荐数超过5篇则表示用户具有相似需求,3号、4号及650 号用户所推荐的10 篇文章均相同,仅排序不同,即文章的权重不同,因此可以判断3号、4号和650号用户是具有相似需求的用户,即这些用户处于同一个相似用户集合中;648号和649号被推荐的文章有8篇是相同的,因此这两位用户也是具有相似需求的用户,处于另一个相似用户集合中。另外,有多篇文章被同时推荐给不同的用户,这既说明被推荐的这些用户具有相似的需求,也说明这些文章所表达的主题是相似的,即这些文章属于相似文章,其处于同一个相似文章集合中,进而实现基于相似用户和相似文章的混合推荐。
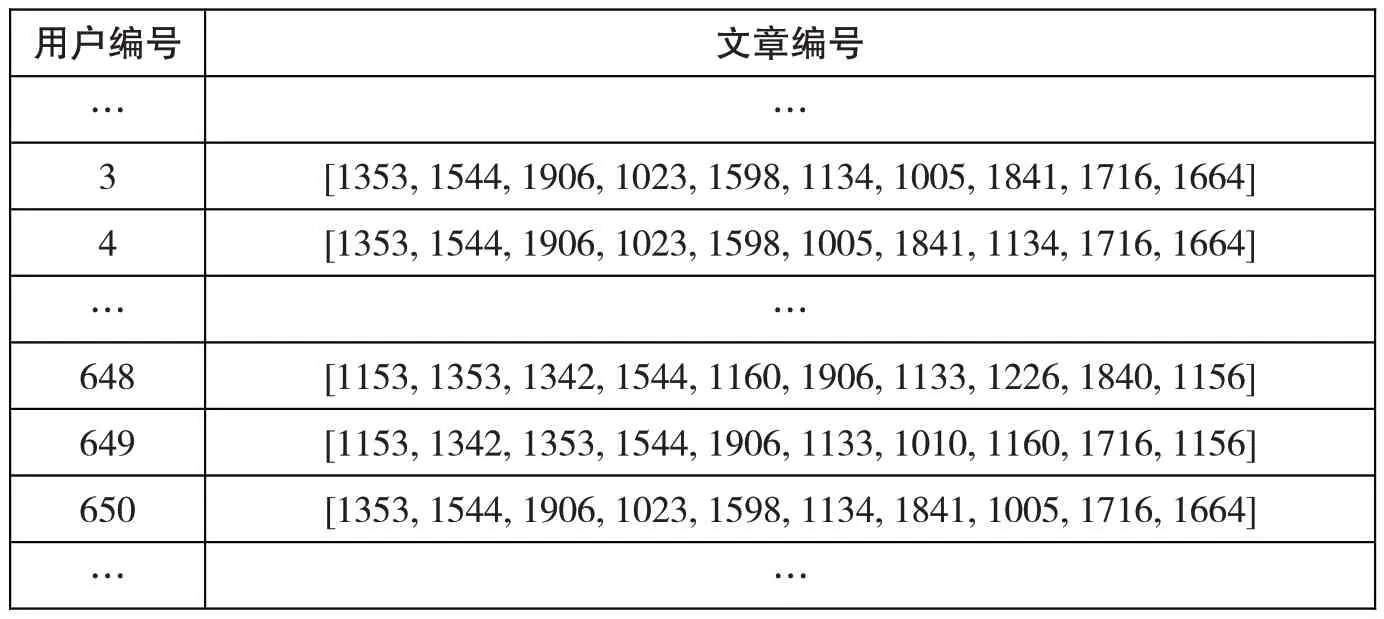
表1 用户-文章推荐列表
实验通过对提问文本聚类和科普文本聚类发现,语料库中权重值位于前15 位的主题和各个主题中所包含的权重值排名前10 的词项,通过词项与主题的关系以及主题与文档的关系,为每位用户推荐与其需求相似度最高的前10 篇科普文章。从实验结果可以看到,所推荐的文章集中有多篇文章同时存在于几个推荐列表中,这说明这些文章所包含的主题是相似的。同时,这些推荐列表也存在于具有相似需求的用户集中。实验结果表明,本文所使用的基于LDA 主题模型和TF-IWF方法,结合基于协同过滤推荐算法和基于内容的推荐算法的混合推荐算法,可以在分别生成相似用户集和相似文章集后,实现混合推荐,找到用户需求主题,并为具有相似需求的用户推荐具有相似主题的健康科普文章,从而实现精准及个性化推荐,提升在线健康社区用户健康素养,并降低用户寻找文章的时间成本,减少医疗资源的浪费。
总的来看,使用本文提出的混合推荐算法具有较好的推荐效果。一方面,能够更加精确地发现和表示用户提问文本及健康科普文章的特征,采用LDA 和TF-IWF 方法对用户提问文本及健康科普文章进行主题聚类,并对两种方法得到的结果进行混合加权,从多个方面考虑了用户提问文本和健康科普文章的主题和特征,增强了推荐结果的可解释性,使得最终的推荐结果更加合理;另一方面,可以基于用户提问文本和健康科普文章的特征相似性,挖掘用户与用户、文章与文章以及用户与文章之间的关联关系,并利用这些关联关系,发现相似用户集合和相似科普文章集合,进一步地通过加权混合方法,为用户推荐与其关联关系最强的前10 篇科普文章,提升了推荐结果的精准性,也有助于实现更好的推荐效果。
5 结语
本文提出了基于LDA 主题模型和TF-IWF 词频统计算法的健康科普文章推荐模型构建过程。首先,对所需要的提问文本及科普文章文本进行采集和预处理。其次,对预处理后的文本数据进行LDA 建模,并对其结果加入TF-IWF 权重,再对加入权重后的结果采用协同过滤和基于内容两种推荐算法生成基于用户的推荐列表和基于文章的推荐列表。最后,对这两个推荐列表以主题为中介进行加权混合,生成最终的混合推荐列表,实现为用户精准推荐符合其需求的健康科普文章的目的。从实验结果看,本研究采用LDA主题模型,可以降低数据维度及计算的复杂度,从而找到用户潜在需求主题及文章主题,结合TF-IWF方法使权重取值更加合理化,帮助用户高效、高质地获取基于自身需求的科普文章推荐结果。
本文所提出的集合LDA 和TF-IWF 算法的优势在于使用此算法可以融合用户观点和科普文章内容,从语义层面为用户推荐更符合其自身需求及潜在需求的科普文章,避免了仅从单一的“提问文本”或“科普文章”出发生成推荐列表的弊端,实现范围更广、更全面,质量更高的个性化推荐,同时使得用户按照主题在平台上查找的时间成本也更低。然而,本研究仍存在不足之处,选取的数据规模小且数据均为文本型数据,类型单一,而对“好大夫在线”平台上所提供的其他类型的数据,如数值型数据和视频数据,并未充分利用。因此,在后续研究中,将考虑选取更大规模的数据,结合“好大夫在线”所提供的其他类型的数据进行实验,以求取效果更好的推荐结果。
