农作物冠层光谱信息的施肥管理分区研究
2022-07-06王新忠狄小冬
陈 浩,王 熙*,张 伟,王新忠,狄小冬,王 畅
1. 黑龙江八一农垦大学工程学院,黑龙江 大庆 163319 2. 黑龙江八一农垦大学理学院,黑龙江 大庆 163319
引 言
黑龙江省是中国的重要商品粮食种植基地,种植了大量的玉米和大豆,从国家官方媒体公布的数据显示,2020年黑龙江省粮食总产量已经达到了7 541万吨,玉米和大豆的种植产量连续数年位居全国前列。 随着玉米、 大豆等农作物的产量逐年攀升,出现了不同程度的化肥滥用情况,化肥的滥用不仅造成了一定的经济损失,也对种植土壤造成了不可逆的损害,施肥管理分区概念的引入,正是应对化肥利用率下降的有效方法。 基于管理分区可以进行有针对性的变量施肥,通过划分管理分区,能够快速辨别各个分区的作物长势、 土壤养分情况等差别,根据分区间的差异精准管理,提高肥料利用率,减少因滥用化肥导致的生态环境破坏[1]。 施肥管理分区的划分多以土壤养分的含量、 作物的产量及农作物冠层光谱特征作为信息源,利用k-均值(k-means)算法、 模糊c-均值(fuzzy c-means,FCM)算法、 层次聚类(hierarchical clustering)算法以及衍生出的相关优化算法进行分区计算。 在各种划分算法中,FCM算法的应用最为广泛。 朱昌达[2]基于农作物土壤的特性,利用FCM算法计算并划分管理分区,划分的管理分区与农作物的土壤特性具有较高的相关性,可利用划分的管理分区进行差异管理。 陈世超[3]基于种植农作物的地形、 土壤、 电导率等因素,使用FCM算法划分了管理分区,验证了可以根据各区域的不同特点划分管理分区。
随着光谱技术的发展,比值植被指数、 增强型植被指数、 归一化植被指数(normalized difference vegetation index,NDVI)等多种光谱植被指数被提出,依据植被指数来反映农作物的生长特性的研究也越来越多,其中NDVI的研究最多[4]。 利用光谱传感器测定植物冠层对红光和近红外光的反射率可以得到NDVI数据,从而反映植株的氮素营养情况并表征农作物长势[5]。 植物冠层光谱传感器有无光源传感器和有光源传感器,其中无光源传感器以日光作为光源生成光谱图像估计作物生长参数,传感器以光谱参数及像素准确描述植物生长状态。 卫星和飞机基于图像光谱传感器以这种方式工作,但卫星易受到云层及大气因素干扰,无人机虽无此问题,但续航时间较短。 有源传感器自带光源照射作物表面,对反射回来的信号进行测量并进行相应计算,受外界因素干扰小,工作稳定,时效性强。 Greenseeker作为农作物冠层光谱信息采集传感器,在各个国家的应用都较为广泛,比如美国约翰迪尔公司开发的的绿色之星变量喷施系统就使用Greenseeker传感器实时检测反映农作物长势信息的光谱数据,并利用光谱数据划分施肥管理分区进行精准施肥,Greenseeker广泛应用于指导变量施肥,具有良好的研究基础和应用前景。
本工作使用有光源的地面遥感植物光谱检测仪Greenseeker获取大豆及玉米的NDVI数据,再利用基于FCM算法提出的基于模型的模糊c-均值算法(model-based fuzzy c-means,MFCM)对NDVI数据进行划分计算,实现施肥管理分区的划分,利用管理分区划分效果评价指标轮廓系数和调整兰德系数对MFCM算法结果进行了评价。
1 实验部分
1.1 地点
实验地点位于中国黑龙江省赵光农场的第4管理区中的17作业站11号和12-2号地块,如图1所示。 赵光农场位于黑龙江省大兴安岭东侧,小兴安岭北侧,整个地区群山起伏,海拔240~330 m。 该地区的气候类型是寒温带大陆性季风气候,种植农作物的主要土壤类型是黑土,其天然条件有利于农作物冠层光谱信息采集实验的开展。 玉米的NDVI数

图1 赵光农场第4管理区17作业站11号地与12-2号地Fig.1 No.11 and No.12-2 of No.17 operation stationin No.4 management area of Zhaoguang farm
据采集地块为11号地,地块面积为618亩,采集的时间为2019年6月18日; 大豆的NDVI数据采集地块为12-2号地,地块的面积为700亩,采集的时间为2019年6月22日。
1.2 数据采集
通过搭建的农作物冠层光谱信息采集平台进行大豆及玉米的NDVI数据采集,采集平台由6个Greenseeker植物冠层光谱检测仪、 配备10英寸显示屏一体机、 天宝公司生产的AG332型卫星定位系统、 NDVI数据记录器以及国产运动控制器组成,如图2所示。 Greenseeker植物冠层光谱检测仪由美国天宝公司生产,自带两个窄带LED主动光源,可发射650 nm(误差为10 nm)的红光和770 nm(误差为10nm)近红外光,利用NTech公司的第二代光学传感器作为检测传感器获取两波段下植物冠层光谱反射率信息[6]。 Greenseeker植物冠层光谱检测仪检测过程中不需要外界辅助光源,不受云层遮挡和土壤反射光的影响,可以全天候进行植物冠层光谱信息的采集作业,还具有检测速度快、 数据较为准确的特点,可以实时反映植物的生长状况,从而有效地指导依据作物长势的变量施肥[7-8]。 如图3所示,实验中将农作物冠层光谱信息采集平台安装到凯斯2254型拖拉机上,在中耕期进行大豆及玉米的NDVI数据采集,利用NDVI数据进行施肥管理分区的划分,根据分区结果进行有针对性的施肥。

图2 农作物冠层光谱信息采集平台Fig.2 Spectral information collection platform for crop canopy

图3 农作物冠层光谱信息采集现场Fig.3 Field of spectral information collection of crop canopy
1.3 划分施肥管理分区方法
1.3.1 FCM算法
1969年Ruspini在模糊集合理论的基础上提出了一种模糊划分的概念。 1974年Dunn又依据Ruspini所提出的模糊划分概念,把硬c-均值算法推广到了模糊划分方向,形成了最初步的FCM算法,后续又有众多学者对FCM算法进行了不断的优化和改进。 FCM算法属于柔性的数据划分算法,在所有模糊划分算法中的应用位居前列。 FCM算法在优化目标函数的基础上可以获得每个数据在所有类别中的隶属度,从而可以决定数据的归属。 对于数据集合X=[x1, …,xn],划分中心个数为c,模糊权重指数为m,FCM算法在硬c-均值的基础上,引入了模糊隶属度矩阵U,矩阵中包含隶属度uij(0≤uij≤1;i=1,2,…,c;j=1,2,…,n),uij的值代表某一个数据到某一个划分的程度,划分中心为V=[v1,v2, …,vc],该算法的目标函数为
(1)
式(1)中,‖xj-vi‖2为第j个数据到第i个划分中心vi的欧式距离,通常1.5≤m≤2.5。 隶属度矩阵U满足
(2)
FCM算法的目标函数达到最小值的条件是
(3)
和
(4)
FCM算法就是基于上述目标函数(1),不断寻找该函数最小值的方法。 FCM算法的具体步骤为: 首先设置划分中心个数c、 停止阈值ε、 模糊权重系数m,随机选取初始划分中心; 然后根据欧氏距离,更新划分隶属度矩阵U; 再更新划分中心V; 最后判断划分中心变化是否小于停止阈值ε,如小于停止阈值ε,则停止划分程序,输出U和V,否则再次更新划分隶属度矩阵U。 该算法迭代终止后,模糊隶属度矩阵U对应为样本数据的模糊划分。
1.3.2 肘部法则
在数据划分分析中一般使用肘部法则来估计划分数c,具体方法是利用设置好的划分数c来计算代价函数的函数值,对比由每个划分数c的值计算出的代价函数值曲线的畸变程度来确定划分数c的值。 其中,代价函数选取的是误差平方和(sum of squares of errors,SSE),SSE是指每个样本点到样本点所在划分中心的距离之和,计算公式如式(5)
(5)
式(5)中,c为划分数,Ci为第i分区数据集,xj为第i分区某个数据,vi为Ci的分区中心。
1.3.2 MFCM算法
MFCM算法是在FCM算法的基础上引入了分区计算模型,在一定数据量范围内不使用FCM算法进行迭代划分数据,而是使用分区计算模型进行数据划分,该方法在满足基本精度的前提下,可有效降低计算耗时,随着数据量的增加,效果更加明显。 具体算法为: 首先按照用户提供的分区数随机设置划分中心,然后利用FCM算法进行2 000个数据量的划分计算并建立分区计算模型,最后以2 000个数据量为分界点,利用分区计算模型划分接下来的数据,算法流程如图4所示。 使用Python函数库中的Scikit-Fuzzy模糊逻辑算法编写FCM算法和MFCM算法,分别对玉米和大豆的NDVI数据进行分区计算。 具体使用到Scikit-fuzzy工具箱中的cmeans工具,将Greenseeker传感器获取的NDVI数据作为程序的输入数据,分区数量设置为4个,隶属度指数设置为2,当隶属度的变化小于0.005时提前结束迭代,最大迭代次数设置为1 000。

图4 MFCM算法流程图Fig.4 Flow chart of model-based fuzzy c-means algorithm
1.4 施肥管理分区划分结果评价方法
1.4.1 轮廓系数
1986年,Rousseeuw提出轮廓系数(silhouette coefficient,SC)的概念,利用轮廓系数可以评价数据划分结果的好坏,也可以评价各种算法对同一组数据划分的优劣效果,轮廓系数主要是利用数据间的结合聚合程度和分离程度两种因素来进行评价计算[9-10]。 轮廓系数的计算公式为
(6)
具体有
(7)
轮廓系数SC(i)的值在[-1, 1]区间内变化,当轮廓系数的值接近1的时候,表明数据间的结合聚合程度和分离程度都比较好,此时的划分效果最好。
1.4.2 调整兰德系数
可以把数据划分过程看成一系列决策的过程,列举数据集中的每一对数据,判断每一对数据是否应该分到同一个簇中,兰德指数(Rand index,RI)衡量了其中正确决策的比例[11]。 假设U为理想划分结果集合,V为待评价的划分结果集合。 假设存在4个统计量:a为在集合U和集合V中都是同一划分的数据对数;b为在集合U中是同一划分,但是在集合V中却不是同一划分的数据对数;c为在集合U中是同一划分,但在集合V中却不是同一划分的数据对数;d为在集合U和集合V中都不是同一划分的数据对数。 则RI的表达式如式(8)
(8)
式(8)中,0≤RI≤1,当待评价的划分结果与理想划分结果完美匹配时,RI的值为1,当待评价的划分结果与理想划分结果完全不匹配时,RI的值为0。 但是RI不能保证随机划分结果的值接近0,调整兰德指数(adjusted Rand index,ARI)可以解决这个问题[12]。 ARI的值越大说明待评价的划分结果与理想划分结果越相似,ARI的定义如式(9)
(9)
式(9)中,E[RI]为RI的期望值,max(RI)为RI的最大值。
2 结果与讨论
2.1 肘部法则计算施肥管理分区数
利用Python编写基于FCM算法的肘部法则计算程序,通过程序计算大豆及玉米的NDVI数据在不同分区数下的SSE值,并绘制成SSE变化曲线图,如图5所示。 对于大豆的NDVI数据,当分区数大于2时,SSE的值不再有明显的下降趋势,后续曲线也比较平滑,说明大豆的施肥管理分区数在2以上均是合理的。 对于玉米的NDVI数据,当分区数大于3时,SSE值没有明显的下降趋势,曲线也变得较为平滑,说明玉米的施肥管理分区数为3以上是合理的。 施肥管理分区的数量将直接影响施肥作业的难度,分区数的增加也相应伴随着作业成本的增加; 本工作综合考虑农作物施肥场地的条件和农场以往的施肥经验确定施肥管理分区数为4。
2.2 施肥管理分区划分结果评价
SC是常用的施肥管理分区划分效果内部评价指标,反映了数据点与所在划分中心的密集程度,以及与其他划分中心疏远的程度,一个好的划分计算,分区内部的数据要足够的聚集,不同分区的数据应该足够疏远,文献[13-14]利用SC评价了不同聚类的质量,取得了良好的效果。 通过计算不
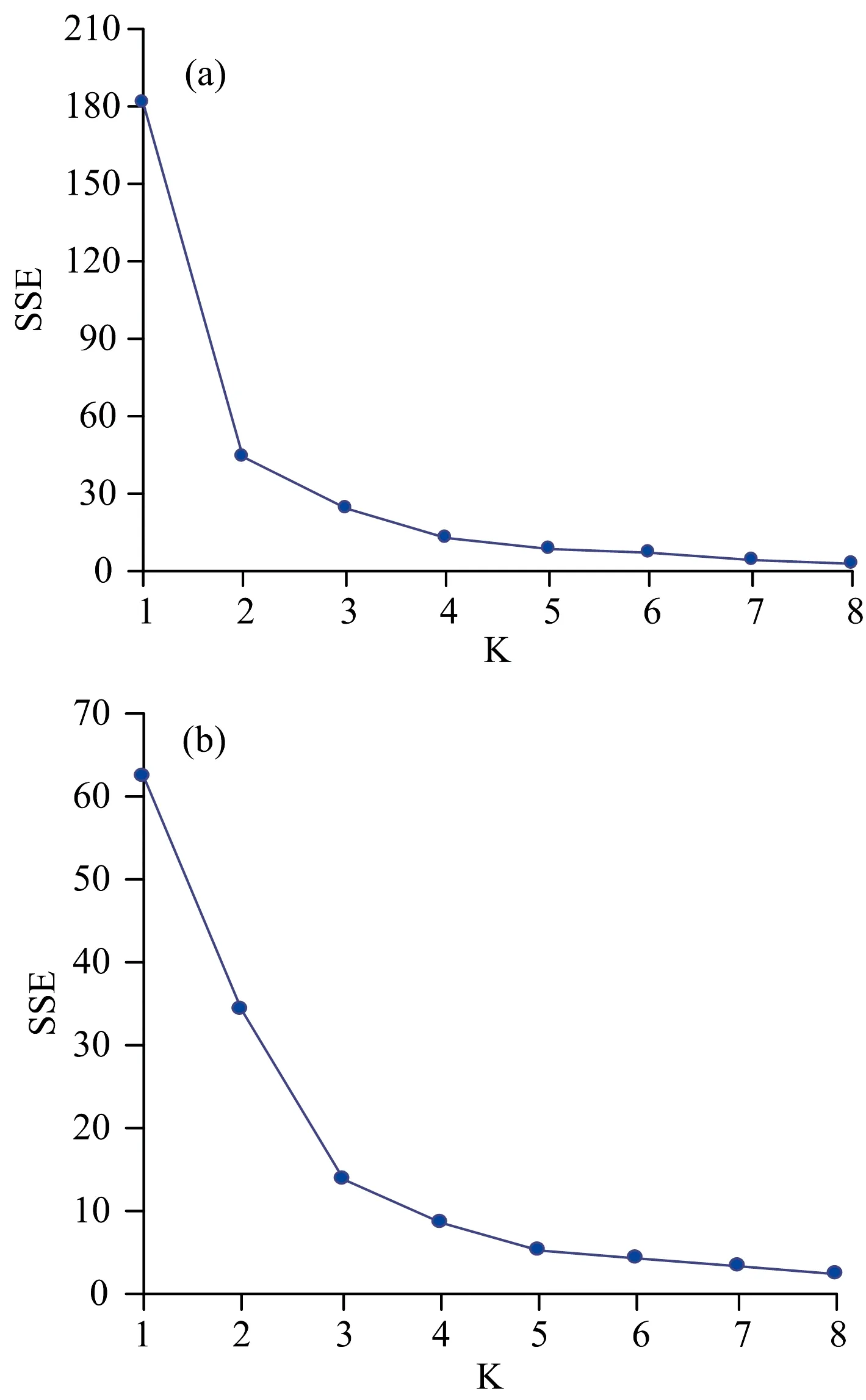
图5 NDVI数据在不同分区数下的SSE变化曲线(a): 大豆; (b): 玉米Fig.5 SSE change curves of NDVI data under differentpartition numbers(a): Soybean; (b): Maize
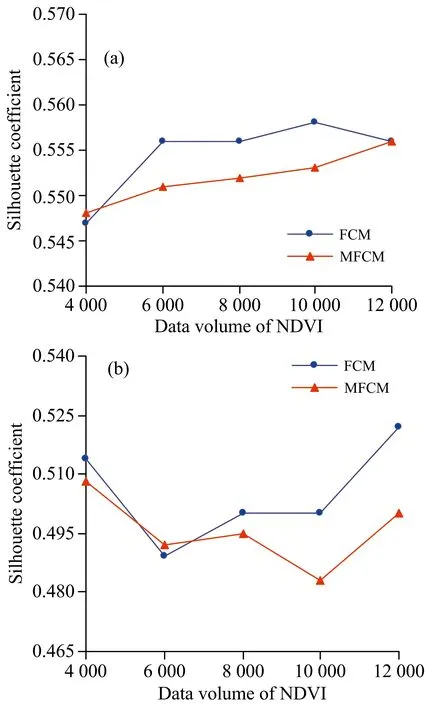
图6 不同NDVI数据量的轮廓系数(a): 大豆; (b): 玉米Fig.6 Silhouette coefficients of different NDVI data volumes(a): Soybean; (b): Maize
同NDVI数据量下的大豆和玉米施肥管理分区划分评价指标SC,得到SC在不同NDVI数据量下的变化曲线,如图6所示。 从图中可以看出,对于大豆NDVI数据,两种算法相差最多为0.005; 对于玉米NDVI数据,两种算法相差最多0.022。 总体来看,无论对于大豆还是玉米,两种算法划分施肥管理分区的效果均相差不大。
MFCM算法在计算施肥管理分区过程中利用少部分数据建立分区模型,肯定会降低计算精度; 为了检验在不同数据量下对计算精度的影响,计算了不同NDVI数据量下的大豆和玉米施肥管理分区划分评价指标ARI。 ARI是对RI进行了改进聚类效果外部评价指标,试图表达怎样聚类才是正确的,通过计算两个不同聚类的相似性来评价聚类的效果好坏。 文献[15]在评估单细胞RNA-sep数据聚类方法中,利用ARI评价方法评估了5种聚类方法的稳定性,取得了良好的效果。 对比数据为FCM算法的施肥管理分区划分,计算结果如图7所示。 通过分析大豆的ARI变化曲线,可以发现当数据量为超过6000后,ARI的值维持在0.8左右,当数据量为超过8 000后,ARI的值维持在0.9左右,说明数据量超过6 000后,两种算法的划分精度几乎接近。 通过分析玉米的ARI变化曲线,可以发现当数据量达到8 000后,ARI的值维持在0.8左右,但是在数据量达到10 000时,ARI的值突降到0.5以下,说明在8 000~10 000的数据的值波动较大,造成MFCM算法此前建立的分区模型不再适应后续2 000个NDVI值,但是此时轮廓系数相差仅为0.017,说明两种算法的划分结果相差较大,但本身的划分效果相差不大,具体原因需后续进行深入研究。
通过计算不同NDVI数据量下的大豆和玉米施肥管理分区划分耗时,得到两种算法在不同NDVI数据量下的耗时变化曲线图,如图8所示。 从图中可以看出,无论对于大豆还是玉米,MFCM耗时均比FCM耗时少,耗时差值最大时达到0.51 s。

图7 不同NDVI数据量的调整兰德指数(a): 大豆; (b): 玉米Fig.7 Adjusted Rand index of different NDVI data volumes(a): Soybean; (b): Maize
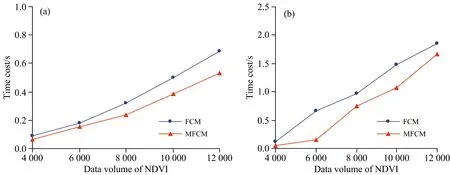
图8 两种算法在不同NDVI数据量下的计算耗时(a): 大豆; (b): 玉米Fig.8 Time costs of two algorithms under different NDVI data volumes(a): Soybean; (b): Maize
2.3 不同算法的大豆施肥管理分区图对比
ArcGIS软件是一款非常优秀的地理信息处理及绘图软件,可以将农作物的NDVI数据基于地理信息(经纬度数据)进行插值计算,绘制出基于农作物NDVI的施肥管理分区图。 当大豆NDVI数据量为4 000时,两种算法的施肥管理分区如图9所示,通过分区图对比两种算法的划分效果。 FCM算法和MFCM算法在施肥管理分区图上的差异较为明显,与施肥管理分区划分评价指标ARI值的变化相符合,主要差别体现在图中的绿色和蓝色分区部分。 出现明显差异的原因是此数据量下的NDVI数据样本较少,说明MFCM算法在作业初期将会出现施肥管理分区划分相对不准确情况,在实际应用中建议早期使用推荐施肥量进行施肥,不需根据长势调整施肥量。
图10为大豆NDVI数据量8 000时两种算法的施肥管理分区图,从图中可以看出,两种算法的施肥管理分区图相差不大,与施肥管理分区划分评价指标ARI的变化相符合,当NDVI数据量达到8 000时,ARI的值为0.86,说明当大豆NDVI数据量达到8 000时,两种方法的分区效果相近。

图9 大豆NDVI数据量为4 000时两种算法计算的施肥管理分区图(a): FCM算法; (b): MFCM算法Fig.9 Fertilization management zoning calculated by two algorithms for 4 000 soybean NDVI(a): FCM algorithm; (b): MFCM algorithm

图10 大豆NDVI数据量为8 000时两种算法计算的施肥管理分区图(a): FCM算法; (b): MFCM算法Fig.10 Fertilization management zoning calculated by two algorithms for 8 000 soybean NDVI(a): FCM algorithm; (b): MFCM algorithm
2.4 不同算法的玉米施肥管理分区对比
当玉米NDVI数据量为4 000时,两种算法计算的施肥管理分区如图11所示。 对比两种算法的施肥管理分区图,可以发现,相较于大豆NDVI数据,在4 000数据量时两种算法针对玉米的NDVI数据的施肥管理分区图相差不大,ARI为0.69。 当玉米的NDVI数据量为8 000时,两种方法的施肥管理分区图相差不大,如图12所示。 此时的ARI为0.915,说明此时两种方法的施肥管理分区划分结果高度相似,MFCM能够在节省一定时间的基础上,有一个较好的划分结果。
3 结 论
使用Python编写了FCM算法和MFCM算法,对大豆和玉米两种作物进行了施肥管理分区划分,并利用SC和ARI进行划分效果评价。 从计算结果来看,当NDVI数据量低于4 000时,MFCM算法与FCM算法相比,没有明显优势,但此时涉及的作业面积较小,对整体施肥管理影响不大,建议在此数据量下使用推荐施肥量施肥。 当NDVI数据量大于6 000时,MFCM算法在划分耗时上出现明显优势,

图12 玉米NDVI数据量为8 000时两种算法计算的施肥管理分区图(a): FCM算法; (b): MFCM算法Fig.12 Fertilization management zoning calculated by two algorithms for 8 000 soybean NDVI(a): FCM algorithm; (b): MFCM algorithm
能够在节省计算耗时的基础上保持一定的划分精度; 从SC和ARI的结果也能够体现出来,两种方法的SC相差最多为0.02,ARI能够维持在0.8左右。 通过计算不同NDVI数据量下的大豆和玉米施肥管理分区划分耗时,利用本文提出的MFCM算法可以有效降低划分耗时,随着数据量的增加,这种优势体现的更加明显。 但是MFCM划分算法也有一定的局限性,玉米NDVI数据量在8 000~10 000范围内的数据划分计算发现,此时ARI的值仅为0.475,说明两种算法划分的施肥管理分区结果出现了明显差异,原因是此段数据变化对划分中心的影响较大,MFCM算法应对数据量突变的情况没有很好的适应性,需要继续优化程序,后续将针对此问题进行深入研究。
