激光雷达技术和摄影测量方法在无人机数字测图中的精度对比分析
2022-07-05胡东升廉旭刚吕俊沛
李 涛,常 江,胡东升,廉旭刚,吕俊沛
(1.华阳新材料科技集团有限公司,山西 阳泉 045000;2.太原理工大学 矿业工程学院,太原 030024)
目前,无人机搭载激光雷达模块采集点云数据,获取地表高精度三维坐标,相比数码航空摄影测量有独特优势[1]。首先,激光雷达直接获取地物表面高精度三维坐标,不受山体、建筑物阴影的影响,单纯数码航空摄影测量在阴影区域判读困难。其次,激光雷达的多次回波对植被具有较好的穿透性,而植被覆盖一直是数码航空摄影不能解决的问题。最后,摄影测量提高精度需经过后差分技术[2-3]和SFM技术[4-5],即通过设计控制点的增多与布设位置的调整,通过拍摄多视角照片结合特征匹配算法,DEM精度可以达到±9 cm,而原始激光点云即可达到±10 cm的高程精度。同时,有多篇文章提出Lidar获取高精度DEM的关键技术,大致可以分为两类,即通过设计改进滤波算法和通过调整采集方案。例如,提出过绿减过红指数提取植被[6-7]、距离限制滤波提取地面点[8]等改进算法;提出从设备选择、点云密度设计、植被覆盖密集山区数据获取方法、点云数据分类组合算法、空白区处理等方面[9-10]进行探讨,并提出改进方法。
目前,对一种点云数据(Lidar点云或者摄影测量点云)精度研究比较多,但是缺乏Lidar点云和摄影测量点云对同一片地区DEM的对比误差研究,定量化描述Lidar点云和摄影测量点云的误差缺乏方法也缺乏实际应用案例。本文提出一种点云对比方法,并结合某地区的实际数据进行案例演示,为后续此类型研究提供参考方案。
1 研究区概况和数据准备
1.1 研究区概况
研究区位于吕梁市孝义市驿马乡下荆封村的某个厂区。地形表面复杂,沟谷纵横,属大陆性半干旱气候。研究区大部分地区植被茂密,除了一条山路和厂区外,只有少量地表裸露,可以满足不同地貌条件之间高程数据的对比。
地理位置东经111.604 2°—111.608 1°,北纬36.957 2°—36.960 0°之间,高程最低947 m,最高992 m,研究区面积大约0.055 km2。如图1所示。

图1 研究区概况
1.2 数据准备
数据采集使用飞马D2000无人机航测平台,一次飞行搭载D-LIDAR2000激光雷达模块,重叠度设置为25%。另一次飞行搭载索尼 A6000相机,有效像素2 430万,航向和旁向重叠分别为80%和60%,采用网络RTK/PPK高精度融合POS+免像控方案。数据采集时间是2021年9月20日,搭载索尼 A6000相机采集的数据,可满足高精度1∶500地形图精度需求。搭载D-LIDAR2000激光雷达模块采集的数据可以直接用于本次的研究。雷达模块参数如表1所示。航测模块参数如表2所示。

表1 D-LIDAR2000激光雷达模块的参数

表2 SONY a6000航测模块的参数
2 点云数据处理
2.1 数据修正
在本次研究中,首先需要清除数据在采集过程中或者使用相关软件处理过程中产生的异常点、孤立点[11]。使用相关滤波算法时,要注意清除低点(不是正常的低矮地物)。使用点云分类工具,设置相关参数分离低点和孤立点,为了保证清除完整,可以多次执行该命令。特殊噪点需要手动清除,使用分类工具classify above line,从侧视图中观察发现噪点。
2.2 数据分层
对已经清除噪点的两份点云数据进行点云分类,两份数据分别划分为植被层、建筑物层、地面层(地面层生成DEM),主要使用点云分类工具,设置不同的参数,保存对应层的数据。两份数据提取相同层的时候尽量保证参数一致,使得两份数据相同层的点云在数量和质量上保持一致。每层数据的保存需要规定格式,方便后续的分析处理。
1)摄影测量点云提取植被层。使用点云分类工具的by vegetation index功能,因为摄影测量点云是带有颜色(RGB值)的,其原理[6]主要是通过过绿减过红指数(EG-ER)把RGB值当参数,通过计算结果和阈值来判断是否是绿色,再将密度值和高程差值作为输入特征变量[7],使用支持向量机(SVM)算法做点云分类,来识别是否是植被。设置的min value和max value含义是规定绿色的范围,目标找到这范围内的绿色点。如图2所示。
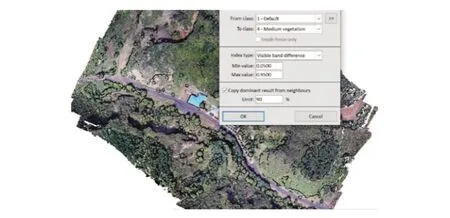
(a)植被提取前
EG-ER作为一种改进的颜色指数通过将EG指数图像与ER指数图像相减,发现基于阈值的EG-ER指数可以较好地将植被与背景分离,计算公式如下:
EG-ER=3g-2.4r-b.
(1)
其中ER为过红指数,计算方法如下:
ER=1.4r-g.
(2)
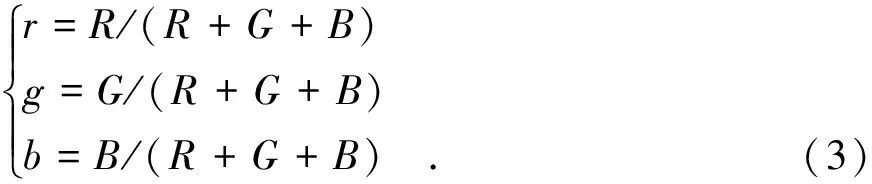
上式的R,G,B值是归一化后的值,即0~255归一到0~1之间。
2)点云提取地面点层制作DEM。使用点云分类工具的ground功能,该功能的原理是发现点云之间的距离和角度的关系[12]。因为不同地物构建的三角网在角度、边长、高度上有差异,通过设置相关参数,排除地表的植被和建筑,只留下地面点。分离地面点的原理有两个,距离限制滤波[8]分类地面点和非地面点,角度滤波去除地物的侧面信息。然后依据局部地形设置动态阈值,以表面拟合区域生长算法扩充地面种子点,循环迭代逐渐逼近真实地面[13]。
滤除起伏突然比较大的点,比如建筑物点,植被点等,使用角度滤除,一般计算θ值的大小,计算公式如下:
获得地面种子点之后,便可以进行表面拟合区域生长算法扩充地面种子点,其流程可以描述为:
a.利用地面种子点构建TIN;
b.选择一个未分类点,寻找该点所在的三角形;
c.计算该点到三角形平面的距离S和该点与三角形3个角点的夹角,并选出最大角度,其几何意义如图3所示;
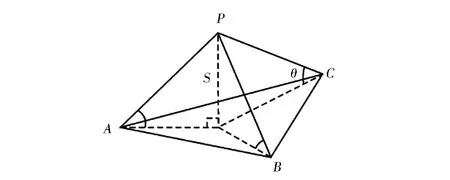
图3 S和θ的几何意义
d.根据人工设置的最大距离阈值Smax和最大角度阈值θmax,再规定区间,将该点加入地面点;
e.重复步骤b~d直到所有未分类的点全部判断完毕。
上述原理在提取过程中体现为设置不同的参数,Max building size设置需要根据实地情况填写,必须大于当地的最大建筑面积。Iteration angle和Iteration distance两个参数是三角网的参数,代表角度和距离。城区设置一般偏小,比如4°和0.6 m;山区设置一般偏大,比如6°和1.4 m。如果得到过滤点云密度太低,需要选择加密点云ground层,因为ground层的点云密度越大,使用Export lattice Model工具插值得到规则格网DEM越精确。
2.3 DEM点云数据处理
按照2.2描述进行数据分层,一共得到6个文件,分别是Lidar点云的building.txt,tree.txt,DEM.txt和摄影测量点云的building.txt,tree.txt,DEM.txt。然后主要使用python语言,写代码实现数据的分析处理。
主要思想是,由于两份数据的坐标系相同,同一地区范围得到的同一种地物类型的点云,必定存在相同坐标点,两幅点云的相同坐标点的高程差应该是差异较小。但是由于数据获取方式不同、数据处理方式不同和数据类型不同,两幅点云的高程存在不容忽视的差异,所以需要通过以下方法量化分析二者差异。如图4所示。
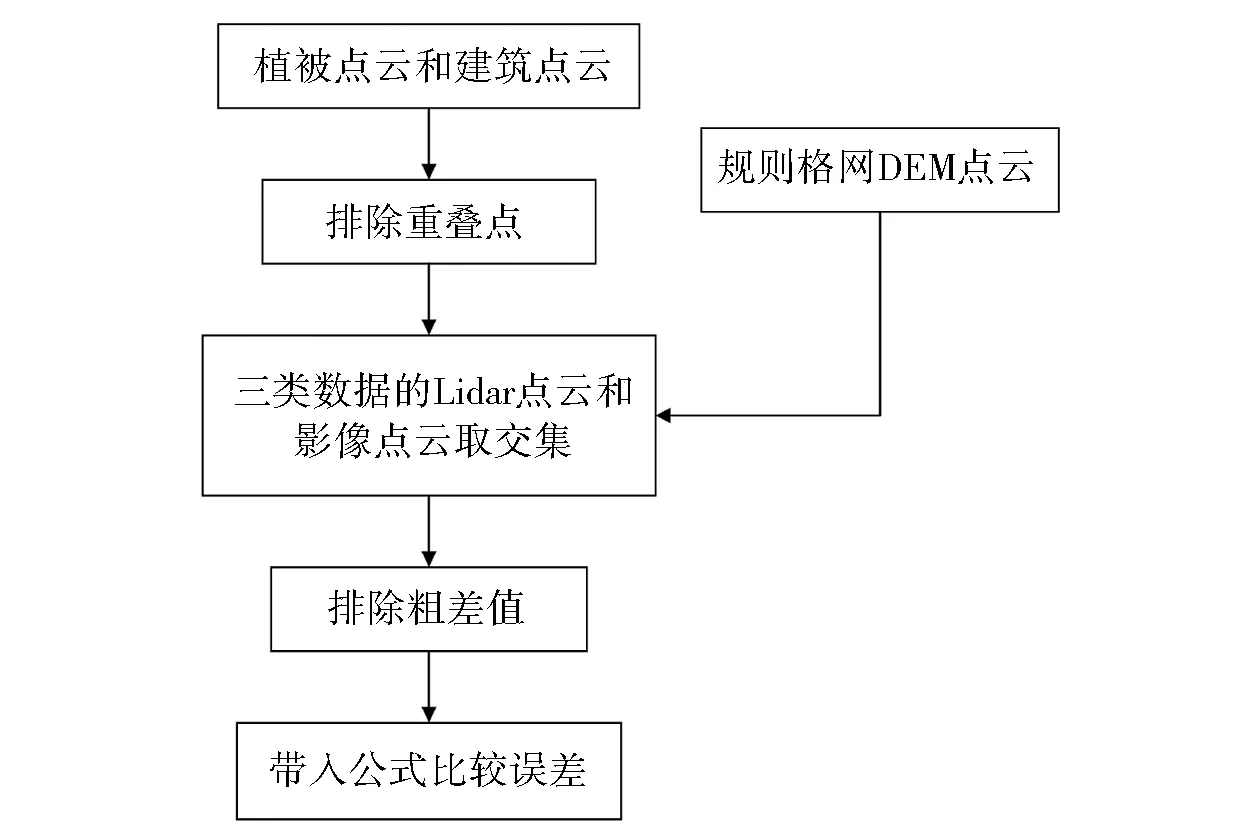
图4 算法实现方法图
使用Lidar点云和影像点云的DEM.txt来举例:通过上述处理,得到Lidar点云大约20万个点,摄影测量点云17万个点,使用python的pandas库可以实现找相同坐标点的操作,并且可以最大程度保留原始数据[14-15]。经过上述操作,保留大约16万对相同坐标点,是原始数据Lidar点云数量的80%,是原始数据摄影测量点云的95%。然后对新表的列名重新命名,进而计算Lidar点云高程减去摄影测量点云高程的差值。如表3所示。
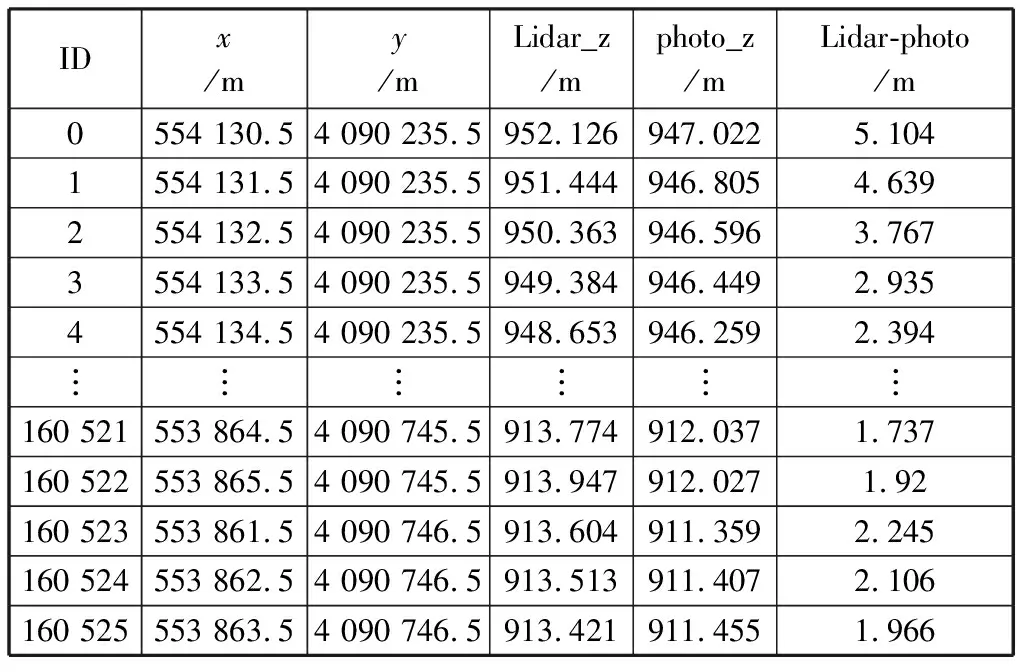
表3 两份DEM的交集数据以及高程差
从Lidar-photo这一列中,可以看到,两份DEM的高程差是普遍存在的。由于软件处理植被点云可能不完整,或者由于无人机飞行初始和结尾状态的不稳定性[9],导致出现的高程差比较大,称之为粗差点,这些点是需要排除的。
选择剔除的方法一般是认为两倍标准差是数据的合理范围,大于两倍标准差的可以认为是粗差,选择剔除。如图5所示。
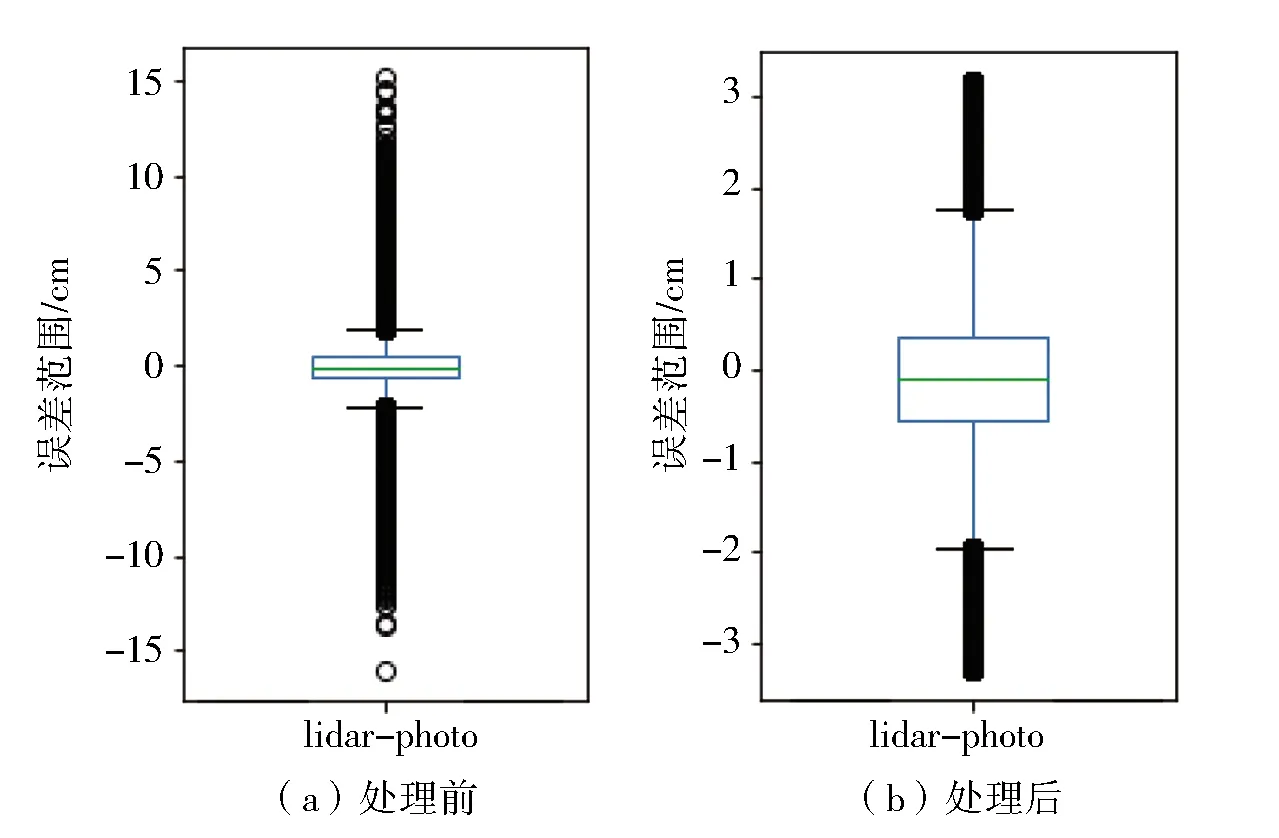
图5 箱型图观察交集DEM排除大于两倍标准差的点云变化
箱型图中黑色圆圈点表示大于1.5倍标准差的数据,矩形方框表示数据的75%集中的区间,绿色的线表示平均值。下表是处理前后的关键统计量的变化,平均值变化较小,进一步说明排除大于两倍标准差的方法是合理的。
经过上述处理,剔除5%的粗差点云,得到的点云数量占原来的95%。如表4所示。
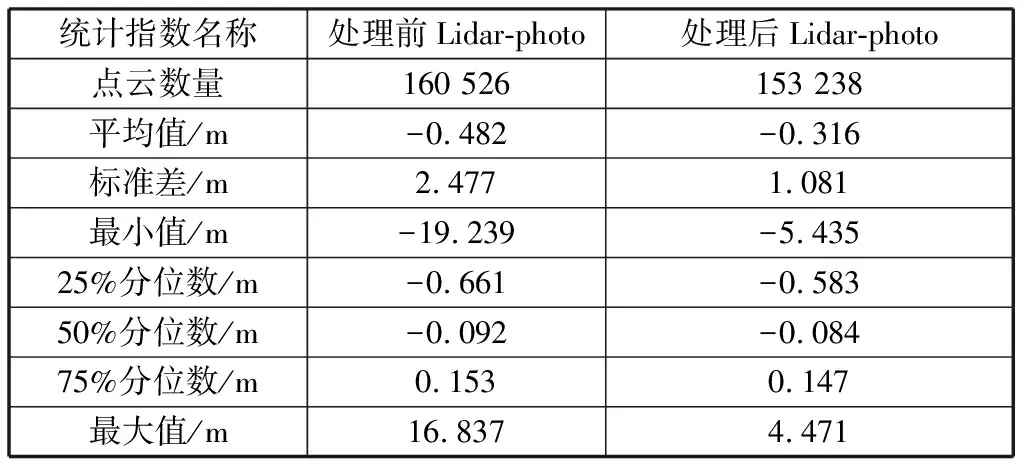
表4 统计量观察交集DEM排除大于两倍标准差的点云变化
从数据中可以看出,已经把处理前最大高差19 m的数据排除,但存在最大高差5 m或者4 m,而选择保留是因为在实际中可能存在5 m或4 m的高差。现在两份DEM高差数据大部分的高差有几十厘米甚至更小,从第一四分位(25%)为-0.583 75 m和第三四分位(75%)为0.147 m可以看出。因此,待研究的数据整体是比较合理的,研究结果是具有参考意义的。
2.4 植被和建筑点云数据处理
数据处理办法和2.3一样,但是需要注意因为Lidar点云的穿透性,是存在同一个x、y坐标有多个高程值,所以第一步需要对保存的植被层删除重叠点,保留重叠的多个点的最高值,把最高值认为是植被高度。对于建筑物点云的重叠情况,选择重叠点云的平均值作为建筑物的高程。
可以看到,在处理重叠点后,两次输出的点云数量是不一样的。比如,植被层,第一次输出9 429 398个,第二次输出9 352 880个,重叠率0.81%。
3 数据对比分析
3.1 平均绝对误差(EMA)的比较
平均绝对误差,全称是Mean Absolute Error,EMA的值越小,说明影像高程数据越靠近Lidar高程数据。EMAP[17]是EMA的变形,它是一个百分比值,表示偏离真实值的程度,其值越小则两份数据之间差异越小。把之前数据处理得到的植被的2 040个点、建筑物的205个点、DEM的153 238个点输入下列公式中,计算结果如表5所示。

表5 植被、建筑、DEM的EMA和EMAP的对比表
数据结果说明,不论影像点云还是Lidar点云,建筑物的精度是最高的。植被和DEM差异比较小,但是由于DEM是地面点合成的,从物理的角度来说确实应该比植被的精度要高,所以可以说明这份数据处理过程是合理的,其对比分析具有一定参考价值。
3.2 均方根误差(ERMS)的比较
均方根误差(ERMS)反映测量数据偏离真实值的程度,ERMS越小,表示测量精度越高。把Lidar点云数据当作真值,把影像点云数据当作观测值。同样把之前数据处理得到的植被的2 040个点、建筑物的205个点、DEM的153 238个点输入到上述代码中,得到以下计算结果,如表6所示。

表6 植被、建筑、DEM的ERMS的对比表
从ERMS结果中仍然可以看出,建筑物点云的数据精度最高,和其他两种数据的差异是比较大的,植被和DEM比较接近,DEM稍优于植被。所以,再次证明不论Lidar点云还是影像点云,在做精度对比的时候一定要先将地物进行分类。
3.3 Lidar点云和影像点云的DEM验证
可以明显看到在平坦或者规则地区,Lidar的DEM和影像的DEM高度重合,但是在山地或者植被覆盖的地方二者差异还是比较明显的,如图6所示。

(a)硬化地表DEM点云
4 结论
1)当不做点云分类时得到的均方根误差(ERMS)达到724 mm,而做过点云分类之后,植被层的ERMS可以达到1 138 mm,相比不做点云分类的724 mm涨幅57%;但是建筑物层的ERMS计算得到108 mm,降幅达到85%;DEM通过计算为627 mm,降幅13%。可见精度对比分析第一步,必须先分类,再对比分析,使用文中点云数据处理方法,得到相关结论。
2)经过传统摄影测量得到的影像点云,按照文中的分类方法,分类得到的硬化地表地区的点云,其精度是可以认为比较接近Lidar点云,所以在建筑不太密集的城区,可以继续发挥传统摄影测量在成本和效率方面的优势。
3)在实际应用案例中,经过该方法处理后,DEM点云数量损失为5%,而植被和建筑物点云数量损失稍大,可以说明该对比方法的合理性;而且数据处理过程中,在同一坐标系下多次找两份点云数据的相同坐标点,确保对比方法的严密性,得到的结论具有实际参考意义。
