基于小波特征与注意力机制结合的卷积网络车辆重识别
2022-07-05廖光锴张正宋治国
廖光锴,张正,宋治国
基于小波特征与注意力机制结合的卷积网络车辆重识别
廖光锴1,张正1,宋治国2*
(1.吉首大学 信息科学与工程学院,湖南 吉首 416000; 2.吉首大学 物理与机电工程学院,湖南 吉首 416000)(*通信作者电子邮箱zhiguos@126.com)
针对现有的基于卷积神经网络(CNN)的车辆重识别方法所提取的特征表达力不足的问题,提出一种基于小波特征与注意力机制相结合的车辆重识别方法。首先,将单层小波模块嵌入到卷积模块中代替池化层进行下采样,减少细粒度特征的丢失;其次,结合通道注意力(CA)机制和像素注意力(PA)机制提出一种新的局部注意力模块——特征提取模块(FEM)嵌入到卷积网络中,对关键信息进行加权强化。在VeRi数据集上与基准残差网络ResNet-50、ResNet-101进行对比。实验结果表明,在ResNet-50中增加小波变换层数能提高平均精度均值(mAP);在消融实验中,虽然ResNet-50+离散小波变换(DWT)比ResNet-101的mAP降低了0.25个百分点,但是其参数量和计算复杂度都比ResNet-101低,且mAP、Rank-1和Rank-5均比单独的ResNet-50高,说明该模型在车辆重识别中能够有效提高车辆检索精度。
车辆重识别;通道注意力;像素注意力;小波变换;卷积神经网络
0 引言
近年来,随着城市智能交通系统与公安系统的快速发展,视频监控在交通控制和安全方面发挥着越来越重要的作用。在计算机视觉领域中,车辆分类[1]、车辆跟踪[2]、车辆检测[3]已经取得了很大的进展,但关于车辆重识别的研究进展却相对较慢。车辆重识别可以应用在许多场景,如视频监控、城市交通、目标跟踪等。车辆重识别的目的是从多个不同位置的摄像机获取图像或者视频序列,从中检索出特定的车辆,即给定一个查询车辆的图像,找到图库中由不同的摄像头在不同场景下拍摄的车辆图像进行匹配。与其他图像检索任务相比,车辆重识别难度更高,主要原因有:首先,由于摄像头位置不同,导致同一车辆在光照或视角变化影响下的外观差异较大;其次,由于背景环境杂乱、遮挡、分辨率低等因素影响,使不同类型的车辆外观有较大的相似性。
为了解决上述两个问题,传统的车辆重识别方法主要通过设计有效的手工特征来表示车辆的外观,如尺度不变特征变换(Scale-Invariant Feature Transform, SIFT)[4]、局部最大特征表示(Local Maximal Occurrence Representation, LOMO)[5]、词袋颜色模型(Bag Of Words-Color Name, BOW-CN)[6]和词袋尺度不变特征变换(Bag Of Words-Scale Invariant Feature Transform, BOW-SIFT)[7]等。但手工设计的特征辨识力有限,无法满足复杂场景下车辆重识别任务的要求。随着深度学习技术的发展及VeRi[8]、VehicleID[9]等大型数据集的出现,推动了基于深度神经网络的车辆重识别技术的发展。利用卷积神经网络(Convolutional Neural Network, CNN)来学习深层特征,能显著地提高表示目标的能力,从而能有效地建立车辆的外观模型。现有的研究大多集中于学习车辆不同属性的全局外观特征,包括模型类型、车牌、空间信息、方向等。一些知名的深度卷积神经网络,如VGGNet[10]、GoogLeNet[11]和ResNet[12],已经表现出了优于手工特征方法的性能。
考虑到不同视角的差异性,Wang等[13]提出了一个方向不变性的特征嵌入模块和一个时空正则化模块,通过方向不变性的特征嵌入模块得到20个关键点位置来提取不同方向的局部区域特征,然后根据时空正则化模型来改善查询结果。Zhou等[14]针对车辆视觉的不确定性,提出了两种端到端的深度神经网络模型:长短期记忆卷积神经网络(Convolutional Neural Network-Long Short Term Memory, CNN-LSTM),将从不同视点获取的特征融合到一个多视点特征中,以解决不同视点之间视觉模式差异较大的问题。Zhou等[15]利用注意力机制和对抗模型将单视点特征转化为多视点特征,能获得输入视点和目标视点之间的重叠区域,实现有效的多视角特征推断。
上述方法主要研究从不同的视觉角度来提取车辆的特征,但当相同类型的车辆出现时,这些特征并不能提供良好的辨别能力,因此,研究者开始关注获取细节特征来解决这个问题。为了能够学习更多细节的特征,Shen等[16]尝试使用附加的属性,如车辆类型、颜色、时空信息等来提取车辆的细节特征。Liu等[8]提出了一种基于外观的方法,称为属性和颜色融合(Fusion of Attributes and Color feaTures, FACT)模型,它使用基于颜色和纹理的手工特征与深度学习特征进行融合,得到了更多具有辨识力的车辆特征。Liu等[17]提出了一种基于深度孪生网络的方法,称为渐进式车辆重识别(PROgressive Vehicle re-IDentification, PROVID)模型。该方法先粗略地提取车辆外观特征,然后用孪生网络对车牌号进行验证,从而准确地判断车辆;但很多时候由于光线、天气、视角的原因,并不能准确拍到车辆的车牌。Tang等[18]提出了一种把深度学习特征和手工特征进行融合的多模态度量学习网络,为车辆重识别提供了更具有鲁棒性和判别性的特征表示。
注意力机制具有仿人的视觉注意力模式,每次关注与当前任务相关的区域,在数据特征处理方面有极强的能力,已被成功应用于一些目标重识别任务。例如,Zhao等[19]设计了一个定位局部信息的卷积网络,然后利用这些局部特征对行人进行重识别;Li等[20]设计了具有新的空间约束的空间变换网络(Spatial Transformer Network, STN)模型来学习和定位行人的姿态。这些网络结构采用的是硬注意力机制,硬注意力是一个随机的预测过程,更强调动态变化,它不能微分,也无法进行反向传播,因此会影响注意力精度。软注意力对图像的每个像素点进行加权,高相关性的区域乘较大权重,低相关就乘较小权重,软像素级注意力可以抑制噪声像素,增强关注区域的像素,并且它能微分。
大多数基于注意力机制的深度神经网络模型只片面考虑通道间特征的影响或像素间特征的影响。针对此问题,本文结合这两类注意力模块设计了新的局部注意力模块——特征提取模块(Feature Extraction Module, FEM),该模块不仅给每个通道赋予权值,还增强了重点区域像素,能加强任务相关特征表达能力,减弱背景和噪声的影响。传统的CNN模型通常使用池化层扩大感受野,但它同时也会缩小特征图,从而降低分辨率,导致学习获得的特征图往往会丢失细粒度特征信息。为了解决此问题,本文提出一种单层小波模块来代替池化层,从而减少信息缺失。本文的主要工作有:
1)将注意力模型嵌入到残差结构(ResNet-50)框架中,进一步挖掘识别特征。实验结果表明,网络仅使用单层结构就在VeRi和VehicleID数据集上取得了性能的提升。
2)将小波模块嵌入到卷积网络中,采用二维离散小波变换(Discrete Wavelet Transform, DWT)作为下采样层,在不改变主架构的情况下代替池化操作,以增强特征的辨识能力。
3)使用交叉熵损失函数和困难样本三元损失函数(TriHard)对特征向量进行联合训练,使卷积网络能较好地提取同种类型车辆的相似特征,显著扩大不同类型车辆的特征差异。
1 小波特征与注意力机制结合的卷积网络
本文提出的基于小波特征与注意力机制结合的卷积网络如图1所示:将车辆图片的尺寸调整为224像素×224像素,依次输入到设计的网络中,每经过一个阶段,特征图的尺寸就缩小为原来的一半,经过4个特征提取阶段后,通过全局平均池化(Global Average Pooling, GAP)得到大小为1×1×2 048的特征向量,最后通过归一化指数函数(softmax)进行分类。为了更好地区分同类型车辆之间的差异和不同类型车辆之间的差异,本文将交叉熵损失函数与困难样本三元损失函数进行联合用于训练网络模型。
1.1 小波卷积网络整体结构
1.1.1 图像的小波变换
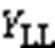
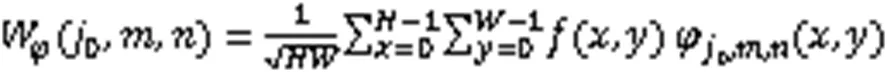
图1 网络整体框架
Fig. 1 Network overall framework

图2 二维离散小波变换
1.1.2 残差网络
CNN在图像识别中被广泛应用,它的最大特点是局部感知与全局共享,可以自动提取原始图像的本质特征进行精确分类,同时降低网络模型的复杂度,从而缩短模型训练时间。最近几年,研究人员提出了大量的CNN,网络越来越深、越来越复杂,但是效果却并非越来越好,因为仅简单地增加网络深度会出现梯度消失或者梯度爆炸问题。针对这个问题,He等[12]提出了残差学习框架(如图3),即使网络结构加深,依然能有很好的特征表现能力,能抑制梯度消失和梯度爆炸问题。残差单元每层输出表示为:

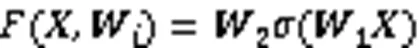
本文基于ResNet-50深度网络模型学习车辆图像的表示特征,采用ResNet-50网络结构stage1、stage2、stage3、stage4阶段来提取输入图片的特征图。其中:在stage1阶段舍掉最大池化层,因为最大池化层会丢弃掉一部分细节特征,从而影响后续卷积层提取车辆特征;其次在每个阶段前添加离散小波变换(DWT)模块,因为DWT作为下采样层能得到更多的特征图;为了更好地利用通道信息和每一阶段图片尺度像素信息,加入特征提取模块(Feature Extraction Module, FEM)对特征图的通道信息进行聚合,从而凸显具有辨识度的特征。
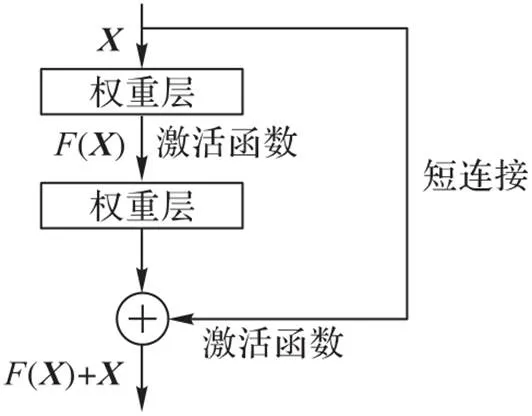
图3 残差单元
整体网络最前端是独立的卷积层Conv1,后面的卷积层则通过残差块堆积而成。网络的基本结构和各模块对应参数配置如表1所示。其中,为了提高训练速度和增强模型的泛化能力,采用批量标准化(Batch Normalization, BN)对批量车辆图片进行归一化处理;Conv1和残差块用于特征提取,非线性激活单元(Rectified Linear Unit, ReLU)作为激活函数。
1.2 双注意力机制模块
1.2.1 通道注意力模块
通道注意力(Channel Attention, CA)机制是对每个通道实现差异化处理,可以增大对目标任务有利的特征通道权重,降低无用特征通道权重,有助于生成有效特征,减少无关区域的干扰。Woo等[22]提出了通道注意力模块,通过平均池化层来压缩通道特征和最大池化层来提取难分辨区域的特征,然后经过多层感知机(Multi-Layer Perceptron, MLP)后对特征求和,进行非线性特征变换,得到通道的注意力权重。该网络结构如图4所示。
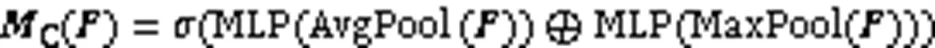
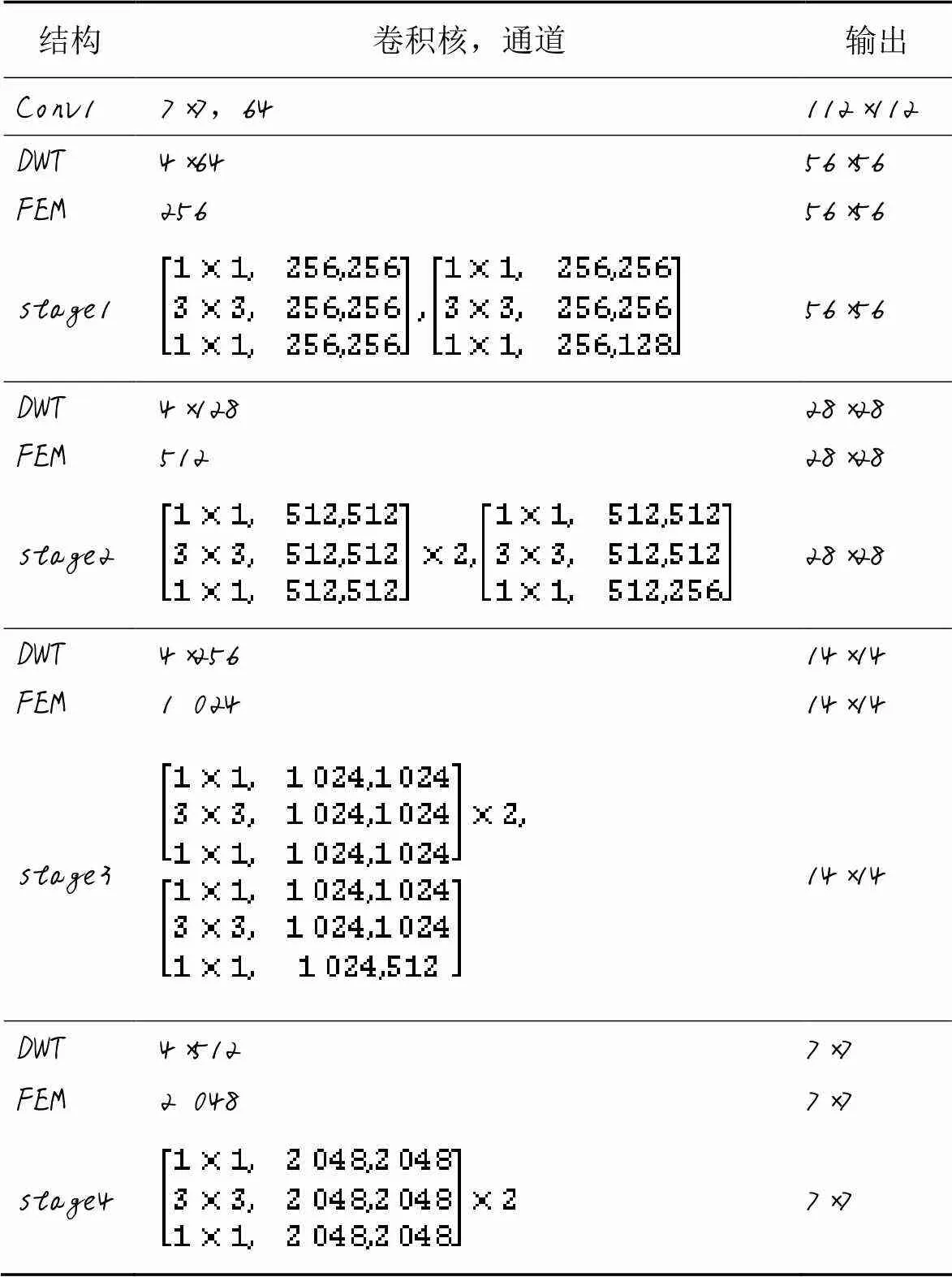
表1 本文网络的基本结构和各模块对应参数

图4 CA模块
1.2.2 像素注意力模块
在车辆重识别中,由于各种环境因素的影响,如光线、天气、投拍摄角度等,通常会导致同类车辆在不同的区域图像上像素分布不平衡。受文献[23]中工作的启发,像素注意力(Pixel Attention, PA)模块给图像的每个像素点赋予相应的权重,能为处理不同类型的信息提供额外的灵活性,改善主网络的特征提取能力。PA模块如图5所示,公式表示为:

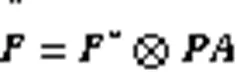
1.2.3 特征提取模块
受注意力机制在行人重识别应用中的启发,本文基于CA机制和PA机制提出了一种新的局部注意力模块FEM,如图6所示。该模块不仅提取特征图的通道信息,还融合了特征图的像素信息,可以自适应地学习每个部分的重要性,从而将更多的注意力放在最具有辨识力的语义和位置信息,抑制信息含量较低的部分,以有效地区分语义特征的特征表示。通过训练一个紧凑的注意力模块来预测目标权重,使卷积网络提取到更具有代表性的特征。
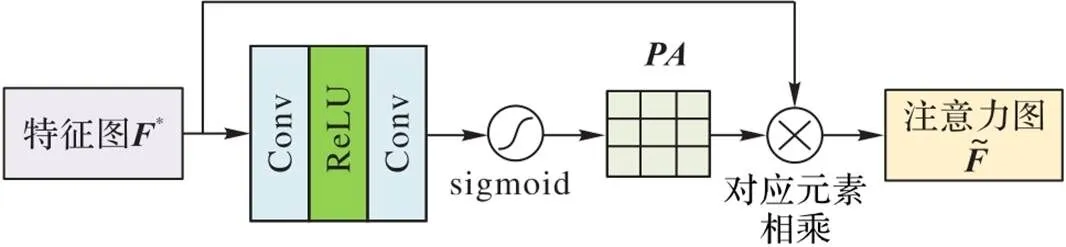
图5 PA模块
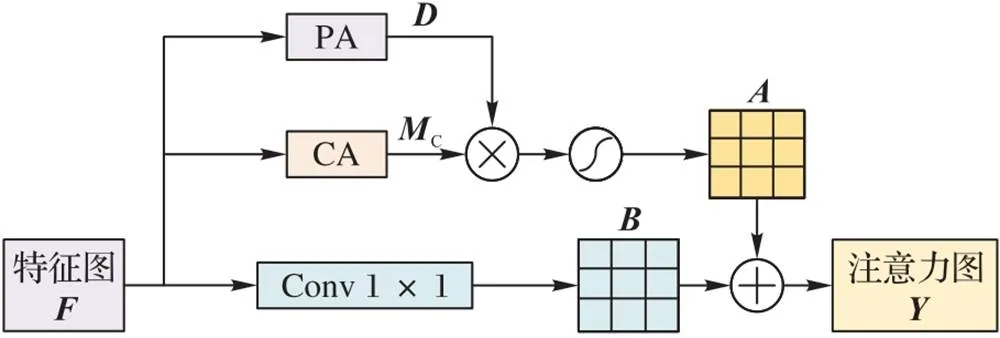
图6 特征提取模块

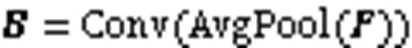
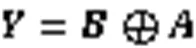
1.3 联合监督学习
由于车辆的属性(身份、模型、颜色)不是绝对互斥的,多属性预测本质上就是一个多标签分类问题。在实验中基于本文提出的模型,在模型的平均池化层之后,对训练的图像进行多标记。为了使本文设计的网络提取到更具有辨识力的特征,采用交叉熵损失函数和困难样本三元损失函数[24]对模型进行联合训练。其中:交叉熵损失函数用于多分类任务,困难样本三元组损失函数用于度量学习任务。特征层用2 048个神经单元来预测车辆特征,分类层用个神经元单元来预测类。针对车辆的身份标签分类部分,本文在特征向量后面增加一层全连接层用于得到每个类的预测概率。本文采用基于softmax激活函数的交叉熵损失训练分类器,softmax激活函数表示为:
交叉熵损失函数公式如下所示:
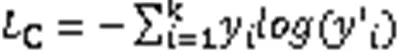
另外,在车辆模型训练中,本文采用困难样本三元损失函数,目的是减小相同类别车辆间的欧氏距离,增大不同类别车辆间的欧氏距离。三元损失函数由锚框(Anchor)、正样本(Positive)和负样本(Negative)组成。在困难样本三元损失函数中,从训练集中随机选择一张图片作为Anchor,然后在相同批次的正样本中选取与Anchor相似度最远的样本作为Positive,同时在相同批次的负样本中选取与Anchor相似度最近的样本作为Negative。

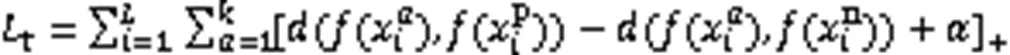

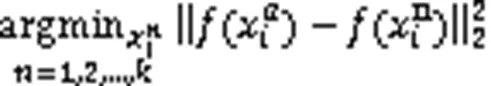

2 实验与分析
2.1 实验数据集及评价指标
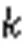
VeRi数据集是大型城市监控车辆数据集,该数据集由20个摄像头为776辆汽车拍摄了50 000多张图片,将其中576辆车的37 781张图像作为一个训练集,200辆车的11 579张图像作为一个测试集,测试集中划分1 678张图像作为查询集。该数据集中包含了每辆车在不同的视觉角度、光照、遮挡和分辨率下的多张图片,同时标注每一辆车的颜色、车辆类型、相机拍摄的地理位置、拍摄图像时间。根据VeRi数据集设定,采用Rank-1、Rank-5以及mAP作为在VeRi数据集上的性能评价指标。
VehicleID数据集采集自中国一个城市道路上监控摄像头白天所拍摄的车辆图片。整个数据集中包含了26 267辆车共221 763张图片,每张车辆图片根据车牌号标注相应的ID。该数据集包含训练集和三种不同大小的测试集:训练集由13 134辆车的110 178张车辆图片组成;Test800测试集包含800张查询车辆图像库和6 532候选图片;Test1600测试集包含1 600张查询车辆图像库和11 395张候选图片;Test2400测试集包含2 400张查询车辆图像库和17 638张查询图片。在后面的实验中会在三个不同的测试集上进行验证,利用Rank-1和Rank-5来作为本文方法在VehicleID数据集上的性能评价指标。
2.2 实验参数设置

2.3 实验结果分析
2.3.1 与基线方法对比
从表2的数据可以看出,在VeRi数据集上:基线网络(ResNet-50)的Rank-1和mAP表现得非常出色;本文方法与基线网络的方法相比,Rank-1提高了5.21个百分点,mAP提高了11.02个百分点。本文提出的小波残差注意力网络在基准网络基础上仅增加了一个轻量级注意力模块,效果就得到了提升,表明本文提出的局部注意力模块FEM可以让卷积网络关注到更多细节特征,取得更好的车辆重识别效果。

表2 在VeRi数据集上与ResNet-50的比较 单位: %
从表3的数据可以看出,在VehicleID数据集上,本文方法在Test800、Test1600、Test2400三个测试数据集上的Rank-1分别提高了2.03、5.29、8.82个百分点。

表3 在VehicleID数据集上的Rank-1比较 单位: %
2.3.2 消融实验
为了进一步验证本文方法中小波模块和注意力模块及损失优化带来的效果,对比了ResNet-50+FEM、ResNet-50+DWT和局部困难样本三元损失函数以及本文方法,如表4。可以看出,ResNet-50+DWT是去掉FEM注意力通道层,仅利用了小波变换层(DWT),相比ResNet-50,在mAP上提升了2.62个百分点;此外,困难三元损失函数加入训练后,相比仅采用交叉熵损失函数,在mAP指标上提高了1.1个百分点。可以看出,DWT嵌入到残差网络中结果有明显的提升,困难样本三元损失函数加入训练也有效地提升了精度。

表4 在VeRi数据集上本文方法的消融实验结果 单位: %
2.3.3 本文方法与其他方法对比
表5列出了本文方法与近年来性能较优的其他算法和模型在VehicleID车辆数据集上的对比结果,比较对象包括:BOW-SIFT[7]、LOMO[5]、BOW-CN[6]、GoogLeNet[11]、FACT[8]、零空间的颜色和属性特征融合模型NuFACT(Null space based Fusion of Attributes and Color feaTures)[17]、MLL+MLSR(Multi-Label Learning+Multi-Label Smoothing Regularization)[25]、视点感知和关注的多视图推理(Viewpoint-aware Attentive Multi-view Inference, VAMI)模型[26]、嵌入对抗的学习网络(Embedding Adversarial Learning Network, EALN)[27]。
NuFACT采用了多层特征融合,不仅从不同角度学习车辆特征,还能减少特征的冗余,可以显著提高基于外观检索的准确率。MLL+MLSR在同时学习三个标签的基础上进行正则化处理,能有效提高车辆重识别的性能。VAMI模型只需要单个视觉信息即可解决多视图车辆识别问题。EALN是一种新颖的端到端嵌入对抗学习网络,它能够生成嵌入空间内的局部样本,从而避免了在训练集中选择大量硬负样本的困难,可以大幅提高网络识别相似车辆的能力。
由表5可以看到,本文方法除了在Test800的Rank-5略差于VAMI,其他指标均取得了最好结果。其中:LOMO、BOW-CN和FACT等方法采用的是手工特征方法,准确率不高;深度学习方法VAMI是将每张输入图像先提取单视图特征,再用单个角度特征生成多角度特征,最终得到全局多视图特征,但是生成的多角度特征与实际特征有较大差异,因此整体效果要比本文方法差。
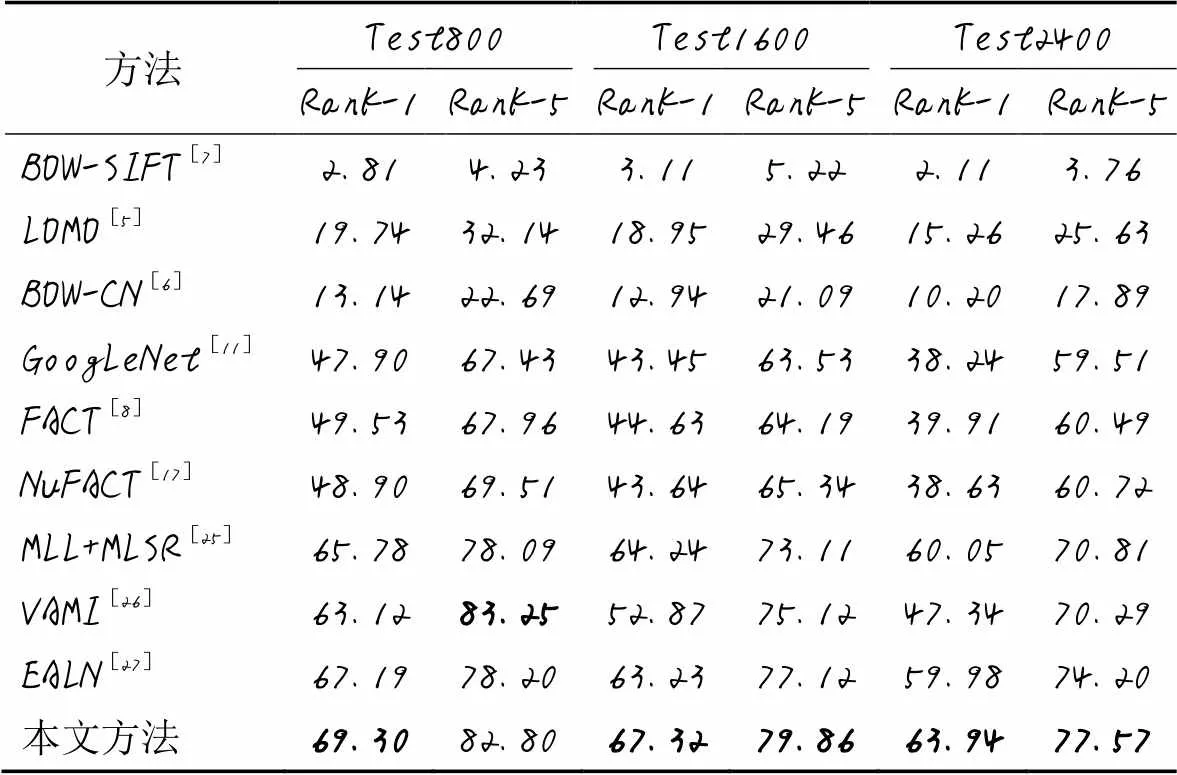
表5 VehicleID数据集上不同方法的对比 单位: %
在VeRi数据集上的对比结果见表6,对比算法包括LOMO[5]、VGGNet[10]、GoogLeNet[11]、FACT[8]、NuFACT+Pate-SNN[17]、PROVID[17]、MLL+MLSR[25]、VAMI[26]、EALN[27]、AAVER(Adaptive Attention VEhicle Re-identifification)[28]和QD-DLF(Quadruple Directional Deep Learning Features)[29]。从表6可以看出,本文方法取得了最好的结果;与AAVER相比,两者的Rank-1值相等,但本文方法的其余指标均优于AAVER,而且AAVER结合了两个分支的特征(包括全局和局部特征),这样会导致网络更加复杂,本文方法仅使用了单层网络结构就取得了较好的性能。
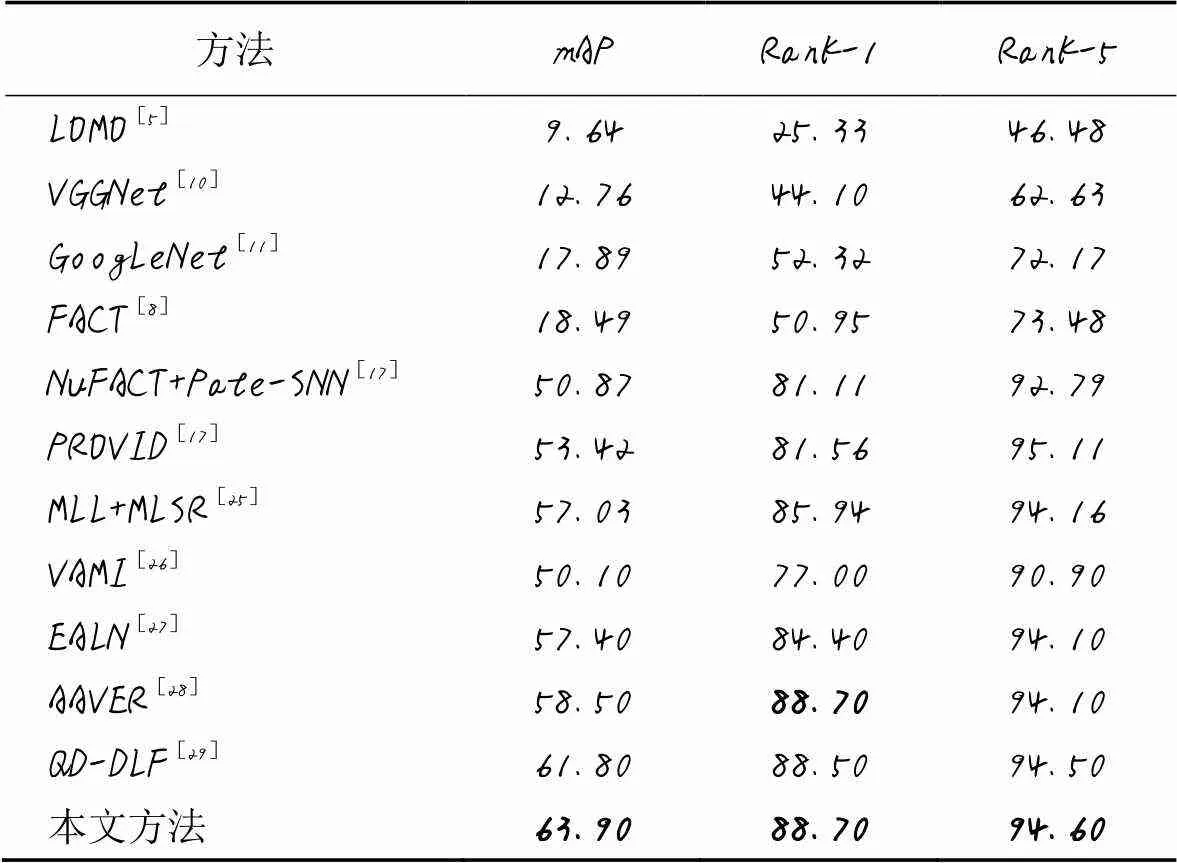
表6 在VeRi数据集上不同方法的对比 单位: %
2.3.4 复杂度分析
从表7可以看出,虽然ResNet-50+DWT的参数量和计算复杂度比ResNet-50要高,但是均比ResNet-101低。从表4可以看出,在数据集VeRi上,ResNet-50+DWT的mAP比ResNet-50高2.62个百分点,但仅比ResNet-101低0.25个百分点。综合模型识别率和复杂度两方面考虑,ResNet-50+DWT具有一定的优势。

表7 复杂度分析
2.3.5 小波层数分析
从表8可以看出,小波变换层(DWT1~DWT4分别代表1~4层小波变换层)嵌入到卷积网络中能取得不错的效果,ResNet50+DWT1效果优于ResNet-50,在VeRi数据集上mAP提升了0.52个百分点。在ResNet-50每个阶段都嵌入小波变换层,mAP的准确精度都有一定的提高。
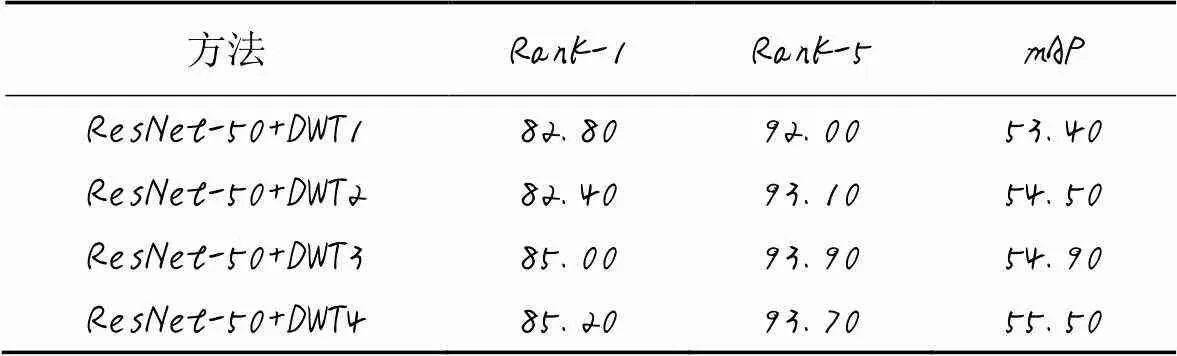
表8 VeRi数据集上小波变换层数对性能的影响 单位: %
最后,随机选取3辆不同的车辆,使用本文方法结合交叉熵损失函数和困难样本三元损失函数进行训练,对车辆重识别结果根据相似度从高到低进行可视化排序,结果如图7所示。从图7可以看出,小车在光照变化和树叶遮挡的情况下,都能很好地被检索出来,说明了本文方法的有效性。

图7 查询可视化Rank-10结果
3 结语
现有的车辆重识别方法为了得到更多的细粒度特征,通常采用池化层来扩大感受域,降低了计算复杂度;但是,池化层可能会导致关键信息丢失,从而影响特征的提取和分析。因此,本文将二维离散小波层嵌入到CNN中以减少特征信息的丢失。另外,为了更好地挖掘细粒度特征信息,设计了一个新的局部注意力模块FEM,并嵌入到小波卷积网络中,结合小波变换层,指导局部特征提取生成,从而使小波卷积网络更好地提取细粒度特征。在VeRi和VehicleID数据集上的实验结果表明,本文方法可以有效改善车辆重识别的性能。
[1] YANG L J, LUO P, LOY C C, et al. A large-scale car dataset for fine-grained categorization and verification[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 3973-3981.
[2] GUO J M, HSIA C H, WONG K, et al. Nighttime vehicle lamp detection and tracking with adaptive mask training[J]. IEEE Transactions on Vehicular Technology, 2016, 65(6): 4023-4032.
[3] CHEN X Y, XIANG S M, LIU C L, et al. Vehicle detection in satellite images by hybrid deep convolutional neural networks[J]. IEEE Geoscience and Remote Sensing Letters, 2014, 11(10): 1797-1801.
[4] ZHAO R, OUYANG W L, WANG X G. Unsupervised salience learning for person re-identification[C]// Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2013: 3586-3593.
[5] LIAO S C, HU Y, ZHU X Y, et al. Person re-identification by local maximal occurrence representation and metric learning[C]// Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 2197-2206.
[6] ZHENG L, SHEN L Y, TIAN L, et al. Scalable person re-identification: a benchmark[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 1116-1124.
[7] ZHENG L, WANG S J, ZHOU W G, et al. Bayes merging of multiple vocabularies for scalable image retrieval[C]// Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2014: 1963-1970.
[8] LIU X C, LIU W, MA H D, et al. Large-scale vehicle re-identification in urban surveillance videos[C]// Proceedings of the 2016 IEEE International Conference on Multimedia and Expo. Piscataway: IEEE, 2016: 1-6.
[9] LIU H Y, TIAN Y H, WANG Y W, et al. Deep relative distance learning: tell the difference between similar vehicles[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 2167-2175.
[10] SIMONYAN K, ZISSERMAN A. Very deep convolution networks for large-scale image recognition[EB/OL]. (2015-04-10)[2021-02-20].https://arxiv.org/pdf/1409.1556.pdf.
[11] SZEGEDY C, LIU W, JIA Y Q, et al. Going deeper with convolutions[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 1-9.
[12] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778.
[13] WANG Z D, TANG L M, LIU X H, et al. Orientation invariant feature embedding and spatial temporal regularization for vehicle re-identification[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 379-387.
[14] ZHOU Y, LIU L, SHAO L. Vehicle re-identification by deep hidden multi-view inference[J]. IEEE Transactions on Image Processing, 2018, 27(7): 3275-3287.
[15] ZHOU Y, SHAO L. Aware attentive multi-view inference for vehicle re-identification[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 6489-6498.
[16] SHEN Y T, XIAO T, LI H S, et al. Learning deep neural networks for vehicle re-ID with visual-spatio-temporal path proposals[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 1918-1927.
[17] LIU X C, LIU W, MEI T, et al. PROVID: progressive and multimodal vehicle reidentification for large-scale urban surveillance[J]. IEEE Transactions on Multimedia, 2018, 20(3): 645-658.
[18] TANG Y, WU D, JIN Z, et al. Multi-modal metric learning for vehicle re-identification in traffic surveillance environment[C]// Proceedings of the 2017 IEEE International Conference on Image Processing. Piscataway: IEEE, 2017: 2254-2258.
[19] ZHAO L M, LI X, ZHUANG Y T, et al. Deeply-learned part-aligned representations for person re-identification[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 3239-3248.
[20] LI D W, CHEN X T, ZHANG Z, et al. Learning deep context-aware features over body and latent parts for person re-identification[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 7398-7407.
[21] 邱奕敏,周毅. 基于小波变换的雾霾立体图像增强算法研究[J]. 计算机工程与应用, 2015, 51(9):30-33.(QIU Y M, ZHOU Y. Wavelet transform stereoscopic images enhancement algorithms based on fog and haze[J]. Computer Engineering and Applications, 2015, 51(9):30-33.)
[22] WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C]// Proceedings of the 2018 European Conference on Computer Vision, LNIP 11211. Cham: Springer, 2018: 3-19.
[23] QIN X, WANG Z L, BAI Y C, et al. FFA-Net: feature fusion attention network for single image dehazing[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2020:11908-11915.
[24] HERMANS A, BEYER L, LEIBE B. In defense of the triplet loss for person re-identification[EB/OL]. (2017-11-21)[2021-02-20].https://arxiv.org/pdf/1703.07737.pdf.
[25] HOU J H, ZENG H Q, CAI L, et al. Multi-label learning with multi-label smoothing regularization for vehicle re-identification[J]. Neurocomputing, 2019, 345:15-22.
[26] CHU R H, SUN Y F, LI Y D, et al. Vehicle re-identification with viewpoint-aware metric learning[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 8281-8290.
[27] LOU Y H, BAI Y, LIU J, et al. Embedding adversarial learning for vehicle re-identification[J]. IEEE Transactions on Image Processing, 2019, 28(8):3794-3807.
[28] KHORRAMSHAHI P, KUMAR A, PERI N, et al. A dual-path model with adaptive attention for vehicle re-identification[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 6131-6140.
[29] ZHU J Q, ZENG H Q, HUANG J C, et al. Vehicle re-identification using quadruple directional deep learning features[J]. IEEE Transactions on Intelligent Transportation Systems, 2020, 21(1): 410-420.
Convolutional network-based vehicle re-identification combining wavelet features and attention mechanism
LIAO Guangkai1, ZHANG Zheng1, SONG Zhiguo2*
(1,,416000,;2,,416000,)
Aiming at the problem of insufficient representation ability of features extracted by the existing vehicle re-identification methods based on convolution Neural Network (CNN), a vehicle re-identification method based on the combination of wavelet features and attention mechanism was proposed. Firstly, the single-layer wavelet module was embedded in the convolution module to replace the pooling layer for subsampling, thereby reducing the loss of fine-grained features. Secondly, a new local attention module named Feature Extraction Module (FEM) was put forward by combining Channel Attention (CA) mechanism and Pixel Attention (PA) mechanism, which was embedded into CNN to weight and strengthen the key information. Comparison experiments with the benchmark residual convolutional network ResNet-50 and ResNet-101 were conducted on VeRi dataset. Experimental results show that increasing the number of wavelet decomposition layers in ResNet-50 can improve mean Average Precision (mAP). In the ablation experiment, although ResNet-50+Discrete Wavelet Transform (DWT) has the mAP reduced by 0.25 percentage points compared with ResNet-101, it has the number of parameters and computational complexity lower than those of ResNet-101, and has the mAP, Rank-1 and Rank-5 higher than those of ResNet-50 without DWT, verifying that the proposed model can effectively improve the accuracy of vehicle retrieval in vehicle re-identification.
vehicle re-identification; Channel Attention (CA); Pixel Attention (PA); wavelet transform; Convolutional Neural Network (CNN)
This work is partially supported by National Natural Science Foundation (32060238).
LIAO Guangkai, born in 1993, M. S. candidate. His research interests include vehicle re-identification, image retrieval.
ZHANG Zheng, born in 1981, Ph. D., associate professor. His research interests include matrix computation.
SONG Zhiguo, born in 1984, Ph. D., lecturer. His research interests include target detection, tracking and identification.
TP 391.41
A
1001-9081(2022)06-1876-08
10.11772/j.issn.1001-9081.2021040545
2021⁃04⁃12;
2021⁃07⁃09;
2021⁃07⁃09。
国家自然科学基金资助项目(32060238)。
廖光锴(1993—),男,四川内江人,硕士研究生,主要研究方向:车辆重识别、图像检索;张正(1981—),男,湖南吉首人,副教授,博士,主要研究方向:矩阵计算;宋治国(1984—),男,湖南保靖人,讲师,博士,主要研究方向:目标检测、跟踪和识别。
