基于多头注意力机制的端到端语音情感识别
2022-07-05杨磊赵红东于快快
杨磊,赵红东*,于快快
基于多头注意力机制的端到端语音情感识别
杨磊1,赵红东1*,于快快2
(1.河北工业大学 电子信息工程学院,天津 300401; 2.光电信息控制和安全技术重点实验室,天津 300308)(*通信作者电子邮箱zhaohd@hebut.edu.cn)
针对语音情感数据集规模小且数据维度高的特点,为解决传统循环神经网络(RNN)长程依赖消失和卷积神经网络(CNN)关注局部信息导致输入序列内部各帧之间潜在关系没有被充分挖掘的问题,提出一个基于多头注意力(MHA)和支持向量机(SVM)的神经网络MHA-SVM用于语音情感识别(SER)。首先将原始音频数据输入MHA网络来训练MHA的参数并得到MHA的分类结果;然后将原始音频数据再次输入到预训练好的MHA中用于提取特征;最后通过全连接层后使用SVM对得到的特征进行分类获得MHA-SVM的分类结果。充分评估MHA模块中头数和层数对实验结果的影响后,发现MHA-SVM在IEMOCAP数据集上的识别准确率最高达到69.6%。实验结果表明同基于RNN和CNN的模型相比,基于MHA机制的端到端模型更适合处理SER任务。
语音情感识别;多头注意力;卷积神经网络;支持向量机;端到端
0 引言
近年来,语音情感识别(Speech Emotion Recognition,SER)作为人机交互的重要媒介,引起越来越多国内外研究人员的关注。人类的情感在人类交流中一直扮演着重要角色,SER是指对隐藏在人类对话中的情感变化进行分析,通过提取语音的相关特征并将其输入神经网络中进行分类,从而识别说话者可能的情感变化。现实中SER有着广泛的应用场景,如客服人员在与客户电话沟通过程中,通过SER系统实时跟踪客户的情绪变化,以便更加主动地提供优质服务。由于情感的表达依赖于诸多因素,如说话者的性别、年龄、方言等,所以研究人员面临的一个主要挑战是如何更好地提取具有区别性、鲁棒性和显著影响力的特征,以提高模型的识别能力。目前,特征提取方式主要分为两类:一类是从音频信号中手动提取相关的短期特征,如梅尔频谱倒谱系数、音高和能量等,然后将短期特征应用于传统分类器,如高斯混合模型、矩阵分解和隐马尔可夫模型等;另一类是使用神经网络自动提取特征,如卷积神经网络(Convolutional Neural Network, CNN)、自动编码器、循环神经网络(Recurrent Neural Network, RNN)、长短时记忆(Long Short-Term Memory, LSTM)模型、CNN+LSTM的组合等,文献[1-2]的研究表明,这些方法在语音分类任务中都取得了很好的效果。
随着人工智能和硬件计算能力的提高,深度学习方法在音频分类上的应用越来越广泛。深度学习具有优秀的学习和泛化能力,能够从大量训练样本中提取与任务相关的分层特征表示,在自动语音识别和音乐信息检索[3-4]领域的研究工作中取得了巨大成功。文献[5]中首先使用CNN学习语音情感显著特征,并在几个基准数据集上展示了CNN的优异性能。文献[6]中使用一维CNN对音频样本进行预处理,目的是降低噪声并强调音频文件的特定区域。由于音频信号可以在时域中传递上下文信息,即当前时刻的音频信息与前一时刻的信息相关,因此在SER任务中可以应用RNN和LSTM捕捉与时间相关的特征表示。文献[7]中提出了一种框架级语音特征结合注意力和LSTM的SER方法,该方法可以从波形中提取帧级语音特征来代替传统的统计特征,从而通过帧序达到保持原始语音内部时序关系的目的。文献[8-9]中将CNN和LSTM相结合挖掘输入序列的时空特征,这也是语音情感分类任务中常见的一类处理方式。文献[10]中进一步提出了基于注意力机制的卷积循环神经网络,并以梅尔谱图(Mel-spectrogram)作为输入,有效提高了模型的识别能力。文献[11]中采用基于注意力的双向长短时记忆(Bi-directional LSTM, Bi-LSTM)模型与基于注意力的CNN并行组合的排列方式搭建网络,用来学习特征,并结合VGG16进行梅尔谱图的预处理,实现了较高的识别准确率,但模型规模相对较大,增加了训练难度。这些模型的提出表明了注意力机制与神经网络结合的有效性。
注意力机制是近年来序列-序列领域的一个热门话题。作为一种注意力机制,自注意力通过学习输入序列中帧与帧之间的潜在关系,捕捉整个输入序列的内部结构特征。Transformer[12]是一种完全基于自注意力机制的序列模型,它在许多自然语言处理任务中表现出优异性能。与传统的RNN相比,Transformer可以同时应用多个自注意力机制并行处理输入序列上的所有帧,然后通过一定变换,最终映射成能代表整个输入序列的注意力值。一些基于Transformer架构的方法,如预训练语言模型[13-14]和端到端语音识别方法[15]证明了Transformer识别性能优于LSTM。支持向量机(Support Vector Machine, SVM)是一种监督学习方法,擅长处理具有小规模样本、非线性和高维模式识别等特点的分类任务,它通过非线性映射将原始样本从低维特征空间变换到高维特征空间甚至无限维特征空间(希尔伯特空间),利用径向核函数构造高维空间的最优超平面,实现样本的线性分离。受上述分析的启发,针对语音情感数据集规模小、维度高的特点,本文提出了一种基于多头注意力(Multi-Headed Attention, MHA)融合SVM的模型MHA-SVM来实现语音情感分类任务。为说明SVM适合处理语音情感分类任务,本文还给出了最邻近法(-Nearest Neighbor,NN)和逻辑回归法(Logistic Regression, LR)分类器的实验结果。NN的思想是将个最近样本中频率最高的类别分配给该样本;LR是在训练数据的基础上建立决策边界的回归方程,然后将回归方程映射到分类函数来实现分类目的。实验结果表明,相比NN和LR,本文提出的MHA-SVM在IEMOCAP数据集上可以进一步提升多头注意力机制的分类效果。
本文的主要工作有:
1)使用Transformer模型的编码模块搭建一个基于MHA的情感分类模型,利用并行处理结构来高效地学习分类特征,模型的分类性能优于以往的RNN模型。
2)针对语音情感数据集的特点,尝试以MHA为特征提取器,SVM为任务分类器,二者的融合可以将MHA的分类效果提升1.9个百分点。为说明SVM的适用性,本文将SVM和其他两个分类器NN和LR进行对比实验,实验结果表明基于多头注意力机制和SVM的端到端模型非常适合处理SER问题,可以提高模型识别性能。
1 相关研究
在SER系统中,特征输入、特征提取和融合网络是模型获得更好性能的重要保证,因此本文将回顾与上述过程相关的一些关键概念和技术。
1.1 卷积层
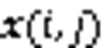
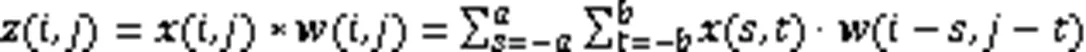
1.2 注意力机制
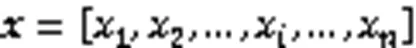
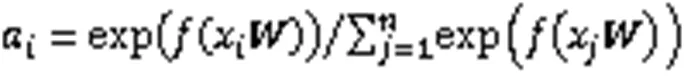
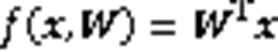
然后计算出输入序列的加权平均和,从而取得整个序列注意力值,数学表达为
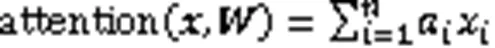
这种计算注意力的方式也被称为软注意力机制。
1.3 多头注意力机制


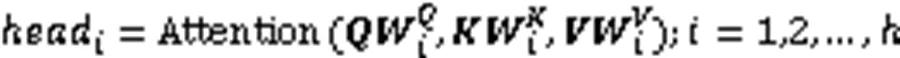
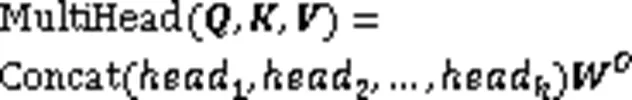

图1 放缩点积注意力结构
1.4 位置编码
音频的信息表达依赖于音频序列中帧的位置,所以位置编码对于音频序列至关重要。在RNN中,位置信息可以被自动记录在网络隐藏层中,而Transformer由于未采用循环结构,为保留输入序列的顺序信息,需要对输入序列内的每一帧进行位置编码,计算过程见式(8)、(9)。
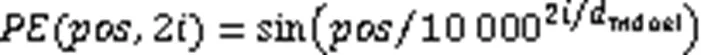
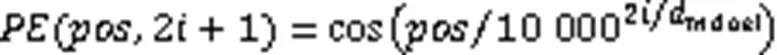
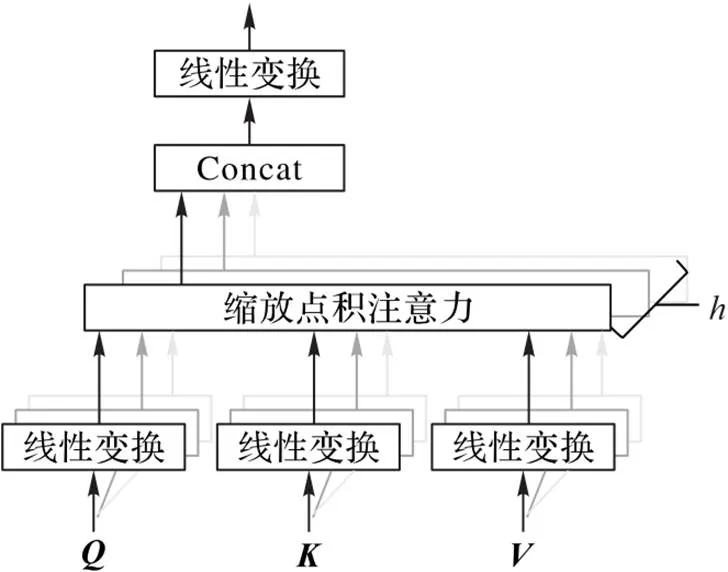
图2 多头注意力结构
1.5 支持向量机
为解决低维度空间线性不可分的问题,SVM使用核函数将数据从低维度的样本空间映射到高维度的特征空间中,然后在特征空间中寻找一个超平面实现样本线性可分[16]。非线性可分的SVM优化问题可描述为

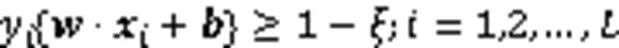
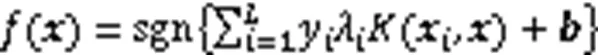
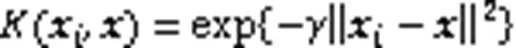
2 模型构建
2.1 数据集
IEMOCAP数据集由10个专业演员(5名女性和5名男性)进行12 h的音频和视频录制,并在两个不同性别的演员之间以演奏剧本或即兴表演的方式进行5次对话。这些收集到的录音被划分为长度在3~15 s的短语句,每个语句被标注为10种情绪之一(中性、快乐、悲伤、愤怒、惊讶、恐惧、厌恶、沮丧、兴奋和其他)。本文实验只使用音频数据,为与前人的作品[17-19]进行一致的比较,将所有标有“兴奋”的话语与标有“高兴”的话语合并为“高兴”类别,且只考虑四种情绪类别(中性、高兴、悲伤、生气)。由表1可以看出类别间数据分布不平衡。

表1 IEMOCAP数据集类别情况
音频信号的采样率直接影响输入样本的维数,并最终影响模型的计算量。本文实验以11 025 Hz的采样率对输入的原始语音信号进行采样[20],以160个采样点为一帧将每个样本依序截取成277帧。考虑到数据集中样本长短不一致,采用补零和截断策略,将样本的一维信号统一变换成大小为(277,160)的二维信号,取样过程见图3。

图3 分帧图
2.2 Transformer层
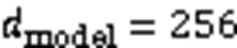

图4 Transformer层结构
2.3 MHA-SVM模型
本文提出的端到端架构可以直接从原始音频信号中学习特征表示,并在不同的语音上取得良好的分类性能,模型结构如图5所示。
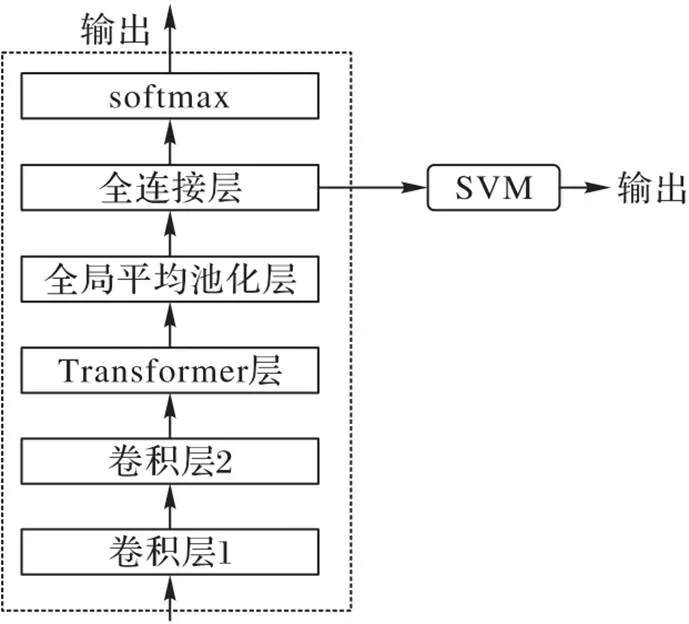
图5 MHA-SVM结构
首先,对输入原始波形应用两个具有小滤波器尺寸的卷积层,以便提取局部特征;然后进入Transformer层,通过全连接层和softmax层得到MHA的分类结果和模型参数设置;最后将已训练的MHA作为预训练模型,原始波形输入MHA中用于提取特征并训练SVM分类器,得到SVM的分类结果。MHA的参数见表2。
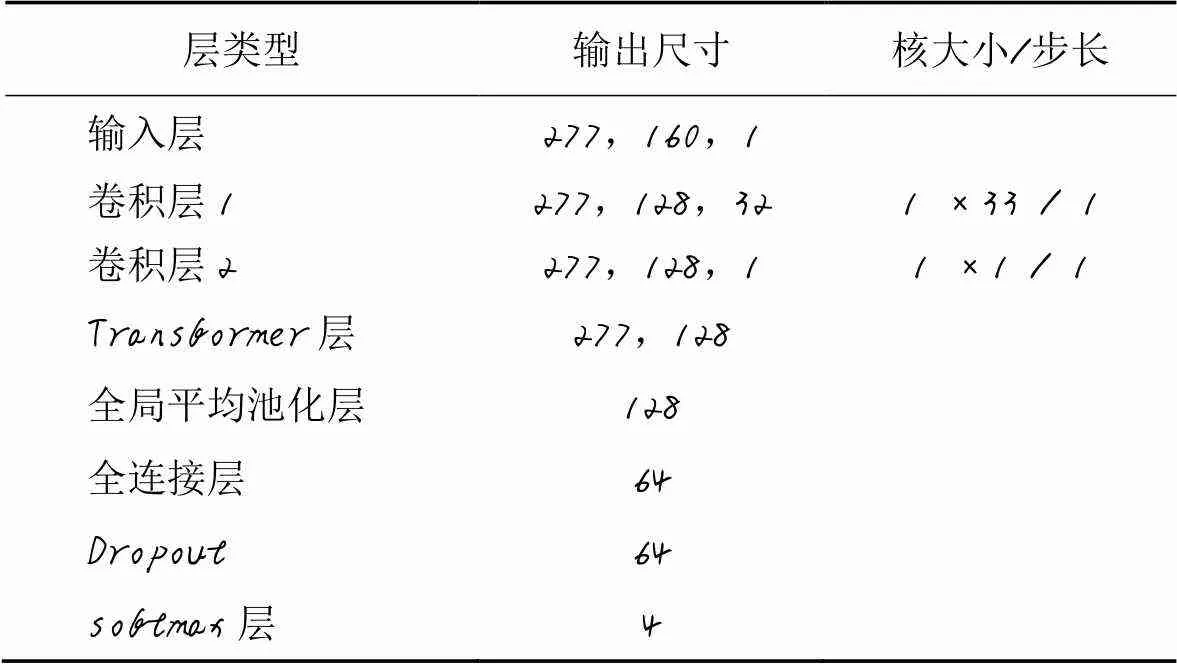
表2 MHA参数
3 模型的验证
3.1 实验环境与参数设置
在内存为16 GB的英伟达TITAN Xp GPU上验证本文提出的语音情感识别方法。实验超参数设置如下:10倍交叉验证,按8∶1∶1的比例随机划分训练集、测试集和验证集;训练集使用批量大小为64的200次迭代;Dropout参数为0.5;以ReLU为激活函数,利用Adam优化器将预测和真实类型标签之间的分类损失函数最小化,选择交叉熵作为损失函数,如式(12)所示。
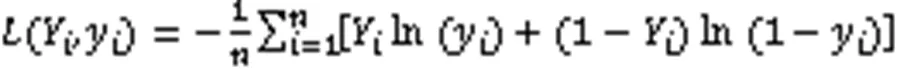
3.2 实验评价指标
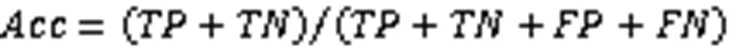

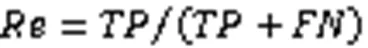
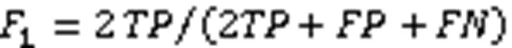
其中:(True Positive)代表真实值为正且预测为正的样本数量;(False Positive)代表真实值为负且预测为正的样本数量;(False Negative)代表真实值为正且预测为负的样本数量;(True Negative)为真实值为负且预测为负的样本数量。
3.3 实验结果与讨论
为验证模型效果,先进行消融实验,去除Transformer层,仅使用卷积网络进行分类实验,识别准确率为47.2%(图6(a));其次,对比自注意力与多头注意力对分类的影响,将Transformer层用LSTM层和注意力层替换,其中LSTM层的输出维度为128,其他设置不变,识别准确率为60.1%(图6(b))。
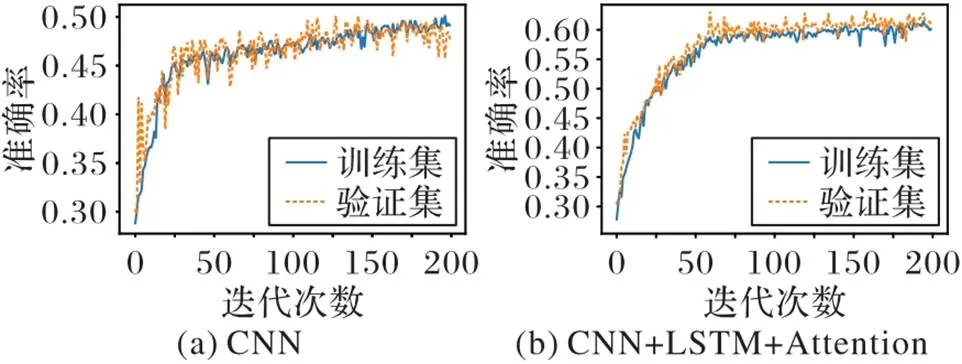
图6 消融实验中训练集和验证集的准确率曲线
其次,使用LR和NN进行对比实验,与SVM设置相同,LR和NN都是连接在MHA的全连接层后面。考虑到模型复杂度与数据量相对有限的数据集,设置模型头数为2、4、8,设置层数为1、2。表3是在不同头数和层数下MHA、MHA-SVM、MHA-LR和MHA-NN的识别准确率结果。可以看出,在“头”数量较少时,隐藏向量的表达能力不足,模型准确率相对较低,增加“头”数量后可以提升模型对细节的表示能力,设置“头”数量为8时,准确率达到最高。同时,1层的模型就可以获得较好效果,层数对模型的影响相对不太敏感,而且由于层数增加,导致模型复杂度提升,对于训练数据量较小的数据集,容易导致过拟合,从而影响模型的泛化能力。从表3中还可以看出,SVM分类器可以进一步提升MHA的分类效果,而LR和NN则对MHA的影响较小。当头数为8且层数为1时,MHA和MHA-SVM的识别准确率都达到最高,分别为67.7%和69.6%。图7分别是准确率曲线、混淆矩阵和t分布-随机邻近嵌入(T-distribution Stochastic Neighbour Embedding, t-SNE)图。
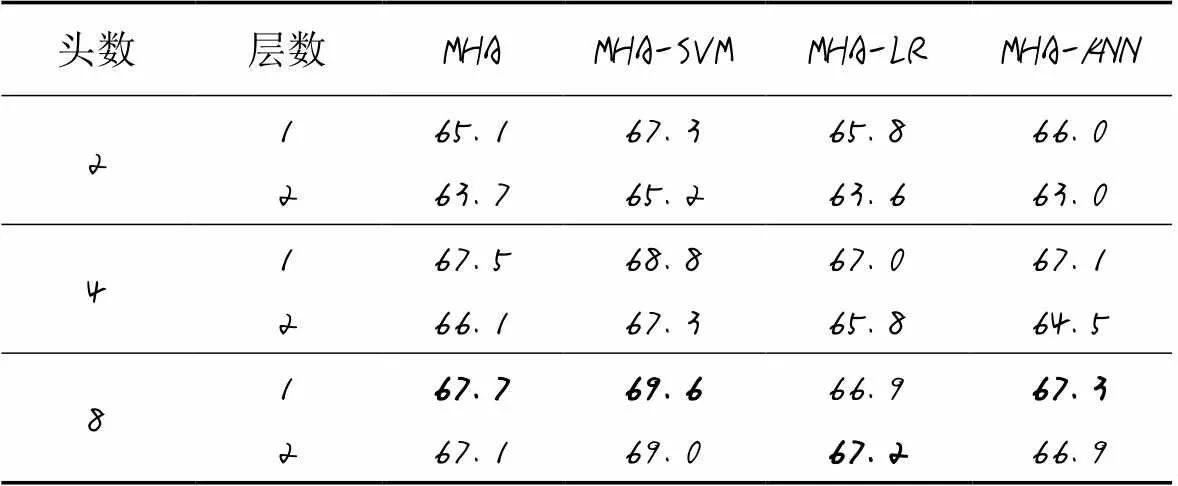
表3 不同头数和层数下模型的识别准确率比较 单位: %
由表4可以看出,除“悲伤”类别外,其余三个类别的精准率都在70%以上。由于训练集中“悲伤”类别的训练样本数相对较少,模型只能从有限的样本中学习特征,从而容易将测试集中的“悲伤”样本错误地分类到“中性”或“高兴”类别。从总体上看,所有模型的F1分数都达到70%,这表明MHA-SVM在不平衡数据集上具有很好的识别性能。
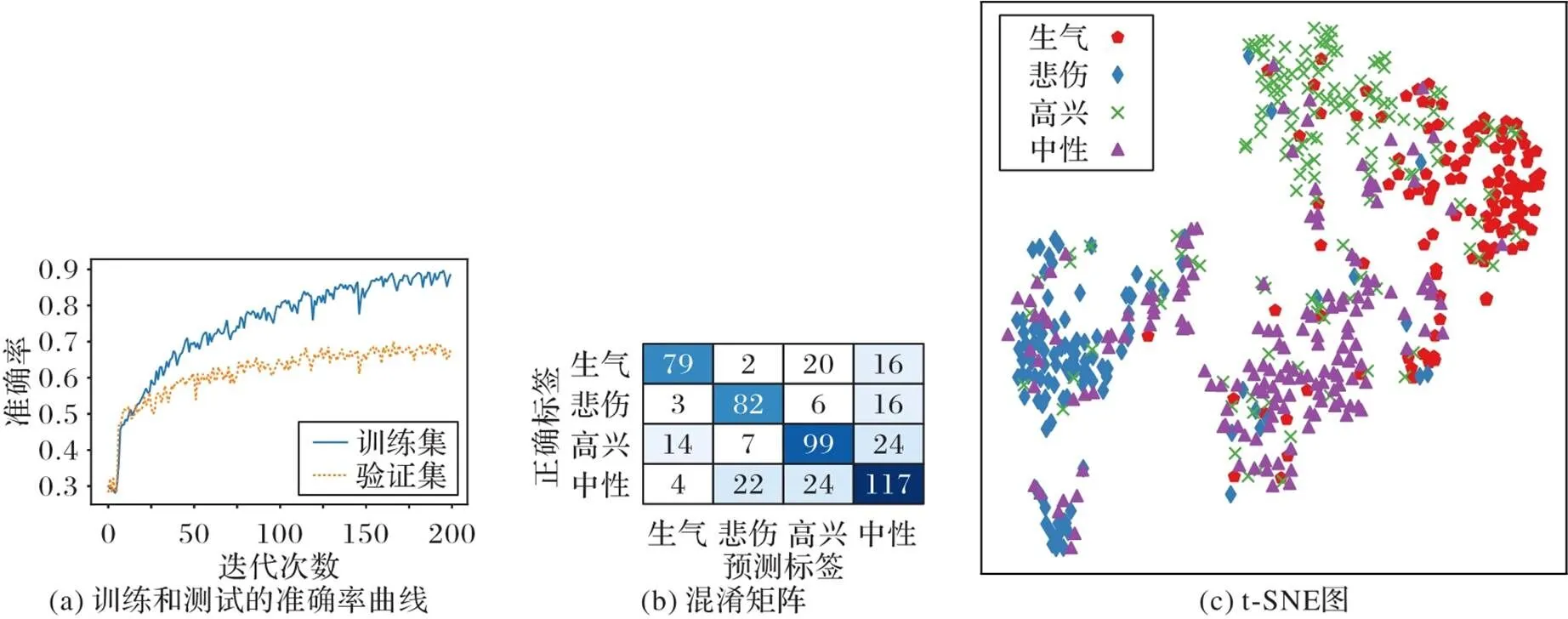
图7 实验结果
最后,表5给出了SER领域近年的研究成果及其研究方法。这些研究工作的准确率都不高于70%,这主要是由IEMOCAP数据内部结构特点决定[23]。IEMOCAP数据集采集过程使用两个麦克风分别独立采集男演员声音和女演员声音,两类演员在对话表演中会相互打断,话语会相交,这个交集时间占整个对话时间的9%,由于麦克风放置位置相对接近对方,这会导致单一麦克风同时记录两个声音,从而增加音频片段内容的判断难度和数据类型的非平衡性。另外,数据标注质量进一步降低了IMMOCAP数据集的识别准确率,根据标注规则,对音频片段所含情绪类别的判断需取得半数以上专家一致评价时,才能对该片段进行标注,数据集中约有25%的音频片段无法被分配到情绪标签,而标注片段中能取得所有专家一致评价的占比不到50%,这进一步说明人类情绪表达的复杂性和情绪评估的主观性。由表5可以看出,与其他对比方法相比,在IEMOCAP数据集上本文模型的识别性能最优。传统机器学习方法SVM[24-25]的识别性能要弱于神经网络,其中文献[24]中以低水平特征集为输入使用单一SVM获得57.5%准确率;文献[25]中将原始音频输入以SVM为内部节点的决策树中,逐步识别各情绪类别。以原始音频为输入的端到端CNN-BLSTM[8]中,从原始音频提取潜在关系的能力都远逊于基于MHA的模型,而且网络深度增加带来的运算效率的降低不利于其在移动终端的部署实施。以手工提取的梅尔谱图等声音特征作为输入的模型[10-11]虽然网络结构较前面模型简洁,但受限于人为选择声音特征的偏差和样本数据维度高、规模小的问题,无法针对具体语音情感数据集的特点,自主挖掘声音序列的内部潜在特征,模型的泛化能力弱于基于MHA的模型。实验结果说明基于MHA的模型可以有效地捕捉原始声音序列中的内部时空关系,而SVM作为分类器对高维小规模样本的声音特征分类有积极的促进作用。
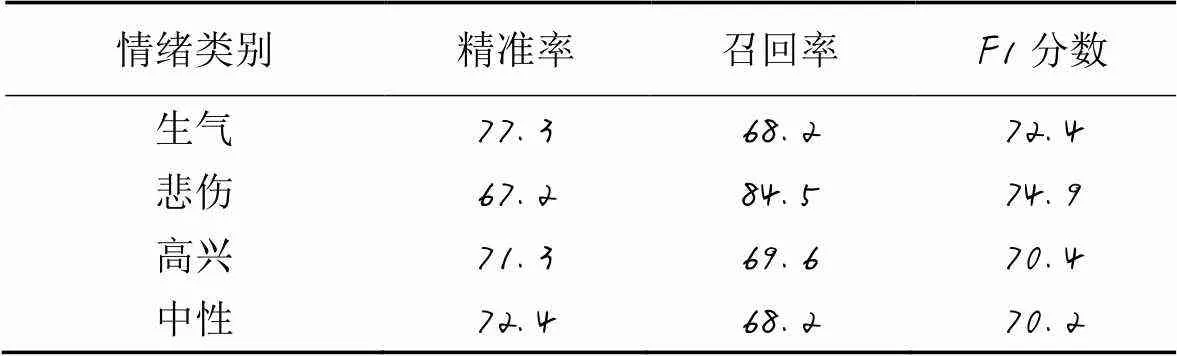
表4 MHA-SVM在IEMOCAP数据集上四个情绪类别的性能比较 单位: %
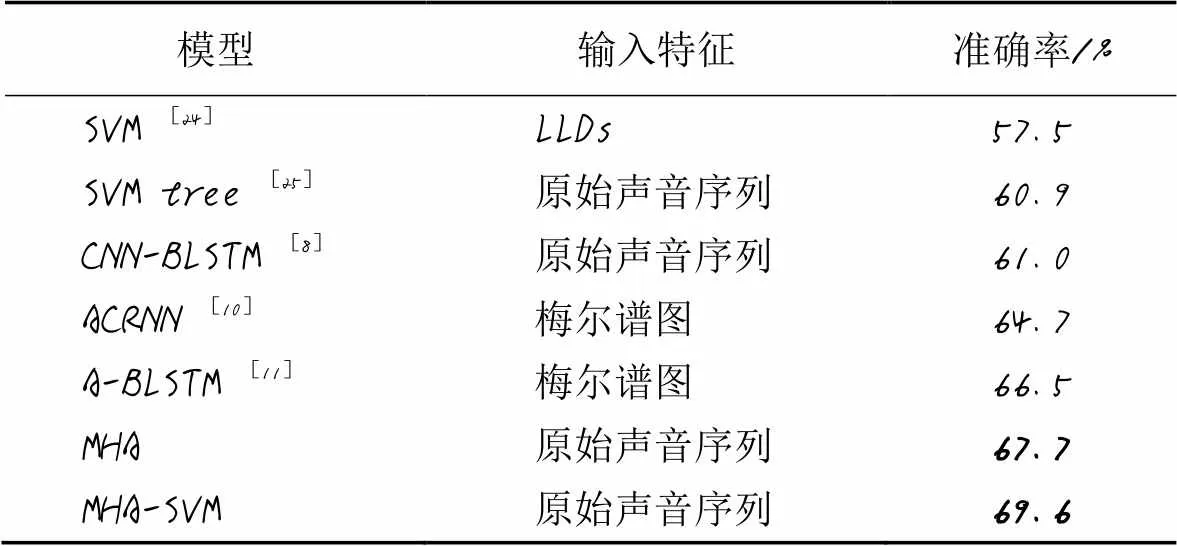
表5 IEMOCAP数据集上7种模型的准确率对比
4 结语
本文提出了以原始音频为输入的基于多头注意力的端到端语音情感识别模型。模型中的卷积层能够有效提取语音信号的低维特征,多头注意机制可以减小序列信息的长度,充分挖掘语音信号的时空结构信息,并结合SVM进一步提高语音情感分类的识别准确率。实验结果表明该模型比基于梅尔谱图的模型具有更大的优势,由于输入为原始波形,且无需手工特征提取步骤,这给模型部署在移动端带来了便利。未来的工作中,我们将继续优化模型,提高模型识别准确率,使模型在移动端具有开发应用前景。
[1] SALAMON J, BELLO J P. Deep convolutional neural networks and data augmentation for environmental sound classification[J]. IEEE Signal Processing Letters, 2017, 24(3): 279-283.
[2] LIM W, JANG D, LEE T. Speech emotion recognition using convolutional and recurrent neural networks[C]// Proceedings of the 2016 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference. Piscataway: IEEE, 2016: 1-4.
[3] HINTON G, DENG L, YU D, et al. Deep neural networks for acoustic modeling in speech recognition: the shared views of four research groups[J]. IEEE Signal Processing Magazine, 2012, 29(6): 82-97.
[4] SCHEDL M, GÓMEZ E, URBANO J. Music information retrieval: recent developments and applications[J]. Foundations and Trends in Information Retrieval, 2014, 8(2/3): 127-261.
[5] MAO Q R, DONG M, HUANG Z W, et al. Learning salient features for speech emotion recognition using convolutional neural networks[J]. IEEE Transactions on Multimedia, 2014, 16(8): 2203-2213.
[6] ISSA D, DEMIRCI M F, YAZICI A. Speech emotion recognition with deep convolutional neural networks[J]. Biomedical Signal Processing Control, 2020, 59: No.101894.
[7] XIE Y, LIANG R Y, LIANG Z L, et al. Speech emotion classification using attention-based LSTM[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2019, 27(11): 1675-1685.
[8] 吕惠炼,胡维平. 基于端到端深度神经网络的语言情感识别研究[J].广西师范大学学报(自然科学版), 2021, 39(3): 20-26.(LYU H L, HU W P. Research on speech emotion recognition based on end-to-end deep neural network[J]. Journal of Guangxi Normal University (Natural Science Edition), 2021, 39(3): 20-26.)
[9] LATIF S, RANA R, KHALIFA S, et al. Direct modelling of speech emotion from raw speech[EB/OL]. (2020-07-28)[2021-01-25].https://arxiv.org/pdf/1904.03833.pdf.
[10] CHEN M Y, HE X J, YANG J, et al. 3-D convolutional recurrent neural networks with attention model for speech emotion recognition[J]. IEEE Signal Processing Letters, 2018, 25(10): 1440-1444.
[11] ZHAO Z P, BAO Z T, ZHAO Y Q, et al. Exploring deep spectrum representations via attention-based recurrent and convolutional neural networks for speech emotion recognition[J]. IEEE Access, 2019, 7:97515-97525.
[12] VASWANI A, SHAZEER N, PARMAR J, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 6000-6010.
[13] RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving language understanding by generative pre-training [EB/OL]. [2021-01-25].https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_ understanding_paper.pdf.
[14] DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg, PA: Association for Computational Linguistics, 2019: 4171-4186.
[15] KARITA S, SOPLIN N E Y, WATANABE M, et al. Improving transformer-based end-to-end speech recognition with connectionist temporal classification and language model integration[C]// Proceedings of the 20th Annual Conference of the International Speech Communication Association. [S.l.]: ISCA, 2019: 1408-1412.
[16] 陈闯, RYAD C,邢尹,等. 改进GWO优化SVM的语音情感识别研究[J]. 计算机工程与应用, 2018, 54(16): 113-118.(CHEN C, RYAD C, XING Y, et al. Research on speech emotion recognition based on improved GWO optimized SVM[J]. Computer Engineering and Applications, 2018, 54(16): 113-118.)
[17] 余华,颜丙聪. 基于CTC-RNN的语音情感识别方法[J]. 电子器件, 2020, 43(4): 934-937.(YU H, YAN B C. Speech emotion recognition based on CTC-RNN[J]. Chinese Journal of Electron Devices, 2020, 43(4): 934-937.)
[18] YOON S, BYUN S, JUNG K. Multimodal speech emotion recognition using audio and text[C]// Proceedings of the 2018 IEEE Spoken Language Technology Workshop. Piscataway: IEEE, 2018: 112-118.
[19] CHO J, PAPPAGARI R, KULKARNI P, et al. Deep neural networks for emotion recognition combining audio and transcripts[C]// Proceedings of the 19th Annual Conference of the International Speech Communication Association. [S.l.]: ISCA, 2018: 247-251.
[20] ALDENEH Z, PROVOST E M. Using regional saliency for speech emotion recognition[C]// Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2017: 2741-2745.
[21] WAN M T, McAULEY J. Item recommendation on monotonic behavior chains[C]// Proceedings of the 12th ACM Conference on Recommender Systems. New York: ACM, 2018: 86-94.
[22] XIA Q L, JIANG P, SUN F, et al. Modeling consumer buying decision for recommendation based on multi-task deep learning[C]// Proceedings of the 27th ACM International Conference on Information and Knowledge Management. New York: ACM, 2018: 1703-1706.
[23] CHERNYKH V, PRIKHODKO P. Emotion recognition from speech with recurrent neural networks[EB/OL]. (2018-07-05)[2021-01-25].https://arxiv.org/pdf/1701.08071.pdf.
[24] TIAN L M, MOORE J D, CATHERINE L. Emotion recognition in spontaneous and acted dialogues[C]// Proceedings of the 2015 International Conference on Affective Computing and Intelligent Interaction. Piscataway: IEEE, 2015: 698-704.
[25] ROZGIĆ V, ANANTHAKRISHNAN S, SALEEM S, et al. Ensemble of SVM trees for multimodal emotion recognition[C]// Proceedings of the 2012 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference. Piscataway: IEEE, 2012: 1-4.
End-to-end speech emotion recognition based on multi-head attention
YANG Lei1, ZHAO Hongdong1*, YU Kuaikuai2
(1,,300401,;2,300308,)
Aiming at the characteristics of small size and high data dimensionality of speech emotion datasets, to solve the problem of long-range dependence disappearance in traditional Recurrent Neural Network (RNN) and insufficient excavation of potential relationship between frames within the input sequence because of focus on local information of Convolutional Neural Network (CNN), a new neural network MAH-SVM based on Multi-Head Attention (MHA) and Support Vector Machine (SVM) was proposed for Speech Emotion Recognition (SER). First, the original audio data were input into the MHA network to train the parameters of MHA and obtain the classification results of MHA. Then, the same original audio data were input into the pre-trained MHA again for feature extraction. Finally, these obtained features were fed into SVM after the fully connected layer to obtain classification results of MHA-SVM. After fully evaluating the effect of the heads and layers in the MHA module on the experimental results, it was found that MHA-SVM achieved the highest recognition accuracy of 69.6% on IEMOCAP dataset. Experimental results indicate that the end-to-end model based on MHA mechanism is more suitable for SER tasks compared with models based on RNN and CNN.
Speech Emotion Recognition (SER); Multi-Head Attention (MHA); Convolutional Neural Network (CNN); Support Vector Machine (SVM); end-to-end
This work is partially supported by Fund of Science and Technology on Electro-Optical Information Security Control Laboratory (614210701041705).
YANG Lei, born in 1978, Ph. D. candidate. His research interests include intelligent information processing.
ZHAO Hongdong, born in 1968, Ph. D., professor. His research interests include photoelectric information processing, speech signal processing.
YU Kuaikuai, born in 1988, M. S., engineer. His research interests include electronic information.
TP183
A
1001-9081(2022)06-1869-07
10.11772/j.issn.1001-9081.2021040578
2021⁃04⁃14;
2021⁃07⁃19;
2021⁃07⁃23。
光电信息控制和安全技术重点实验室基金资助项目(614210701041705)。
杨磊(1978—),男,吉林敦化人,博士研究生,CCF会员,主要研究方向:智能信息处理;赵红东(1968—),男,河北沧州人,教授,博士生导师,博士,主要研究方向:光电信息处理及应用、语音信号处理;于快快(1988—),男,天津人,工程师,硕士,主要研究方向:电子信息。
