基于子词嵌入和相对注意力的材料实体识别
2022-07-05韩玉民郝晓燕
韩玉民,郝晓燕
基于子词嵌入和相对注意力的材料实体识别
韩玉民,郝晓燕*
(太原理工大学 信息与计算机学院,太原 030600)(*通信作者电子邮箱haoxiaoyan@tyut.edu.cn)
准确识别命名实体有助于构建专业知识图谱、问答系统等。基于深度学习的命名实体识别(NER)技术已广泛应用于多种专业领域,然而面向材料领域的NER研究相对较少。针对材料领域NER中可用于监督学习的数据集规模小、实体词复杂度高等问题,使用大规模非结构化的材料领域文献数据来训练基于一元语言模型(ULM)的子词嵌入分词模型,并充分利用单词结构蕴含的信息来增强模型鲁棒性;提出以BiLSTM-CRF模型(双向长短时记忆网络与条件随机场结合的模型)为基础并结合能够感知方向和距离的相对多头注意力机制(RMHA)的实体识别模型,以提高对关键词的敏感程度。得到的BiLSTM-RMHA-CRF模型结合ULM子词嵌入方法,相比BiLSTM-CNNs-CRF和SciBERT等模型,在固体氧化物燃料电池(SOFC)NER数据集上的宏平均F1值(Macro F1值)提高了2~4个百分点,在SOFC细粒度实体识别数据集上的Macro F1值提高了3~8个百分点。实验结果表明,基于子词嵌入和相对注意力的识别模型能够有效提高材料领域实体的识别准确率。
命名实体识别;子词嵌入;相对注意力;深度学习;材料领域
0 引言
命名实体识别(Named Entity Recognition, NER)的目标是在非结构化的文本中按照预先定义的类别信息,提取并分类出具有特定意义的命名实体信息,如人名、机构、地点等。NER技术可以用于如知识图谱构建、问答系统、机器翻译等自然语言处理(Natural Language Processing , NLP)任务。专业领域的NER对于机器阅读理解专业领域文献和构建专业知识图谱具有重要作用,精准地进行专业领域的命名实体识别有助于减少科研工作量,提高查阅效率,并能够辅助提高专业领域机器翻译、自动问答等上游NLP系统的水平。
近几年对于命名实体识别的研究大多基于深度学习,目前适用于命名实体识别的常用深度学习模型与方法有条件随机场(Conditional Random Field, CRF)[1]、卷积神经网络(Convolutional Neural Network, CNN)[2]、长短期记忆(Long-Short Term Memory, LSTM)神经网络[3]、门控循环单元(Gate Recurrent Unit, GRU)[4]以及自注意力机制[5]等。Ma等[6]结合双向长短期记忆(Bi-directional Long-Short Term Memory, BiLSTM)神经网络、CNN与CRF提出了端到端的序列标注模型BiLSTM-CNNs-CRF,在CoNLL-2003数据集上取得了91.21%的F1值;Chiu等[7]提出使用BiLSTM和CNN编码层进行命名实体识别,在CoNLL-2003和OntoNotes数据集上的F1值分别达到了91.62%和86.28%;Liu等[8]提出使用LM-LSTM-CRF(Language Model+LSTM+CRF)模型将CoNLL-2003数据集的F1值提高到了91.71%;Dhrisya等[9]使用双向GRU结合自注意力机制在OntoNotes细粒度实体识别任务上也取得了较好的结果。
通用领域命名实体识别的准确率已达到较高水准,目前命名实体识别方向的研究大多基于专业领域。杨维等[10]提出基于CRF的命名实体识别算法,在电力服务数据集上具有较高准确率;李博等[11]采用Transformer-CRF、张华丽等[12]采用BiLSTM-CRF模型对中文电子病历进行实体识别,能够准确识别症状、治疗等五类实体;张心怡等[13]提出了联合深度注意力网络,在煤矿领域命名实体识别精准度和识别效率都有较大的提升;许力等[14]结合CNN、BiLSTM、图卷积神经网络(Graph Convolution Neural Network, GCNN),并融合词向量和依存句法分析特征进行生物医学实体识别,在多个数据集上表现出色。
材料领域的自然语言处理研究相对贫乏,其中与本文研究相关的有:Mysore等[15-16]提出了自动提取材料科学文献结构化信息的系统,并且发布了大规模材料领域语料库; Mrdjenovich等[17]构建了材料科学领域的知识图谱propnet;Friedrich等[18]发布了固体氧化物燃料电池(Solid Oxide Fuel Cell, SOFC)命名实体识别数据集,并使用SciBERT(Scientific BERT)模型取得了81.5%的Macro F1值(宏平均F1值)。
识别未登录词(Out-Of-Vocabulary, OOV)是命名实体识别任务的关键,字符嵌入一般用于解决传统词嵌入,如word2vec,存在的OOV问题,同时还能反映出单词字符序列蕴含的形态学信息。Gajendran等[19]将词表示和字符表示作为输入,使用三重BiLSTM-DRNN模型进行命名实体识别。Cho等[20]同时使用BiLSTM和CNN对单词字符进行编码,得到字符嵌入并与词嵌入向量结合作为模型输入,在生物医学命名实体识别中达到了较高水平。字符嵌入能够有效提高命名实体识别模型的识别准度,但缺点也较为明显:1)需要额外的字符级编码层;2)使用CNN作为编码层时对相邻字符的感受野相对固定,而使用BiLSTM编码层又不能充分挖掘单词词缀之间的关联信息。因此,本文考虑采用子词嵌入代替字符嵌入,同时使用大规模材料领域数据,对子词划分模型进行预训练,将得到的子词分词结果再进行词向量训练,同word2vec结合作为命名实体识别模型的输入。
自注意力机制常用于多种NLP任务,命名实体识别中加入自注意力机制能够提高模型的特征提取能力和上下文信息的关注程度;但Transformer结构由于在注意力计算时使用了归一化处理,且其位置编码不具备方向性,在命名实体识别任务上的表现不佳[21]。本文采用相对多头注意力机制代替传统的自注意力机制,作为命名实体识别模型的编码层。
本文的主要工作包括:
1)使用大量非结构化材料领域文献数据,训练基于一元语言模型(Unigram Language Model, ULM)的分词模型,并进一步训练出适用于材料领域数据的子词嵌入用于材料领域命名实体识别任务。
2)在BiLSTM-CRF模型的基础上,使用能够感知单词方向和距离的相对多头注意力机制(Relative Multi-Head Attention, RMHA),以增强模型对关键词的感知能力。
3)在SOFC数据集的命名实体识别和细粒度实体识别任务中,使用常用模型与BiLSTM-RMHA-CRF模型进行多组对比实验,验证ULM子词嵌入和基于RMHA的深度学习模型有助于提高材料领域命名实体识别的精准度。
1 子词嵌入和RMHA实体识别网络
使用BiLSTM-CRF模型结合RMHA对材料领域数据进行命名实体识别,同时使用预训练词嵌入和子词嵌入提高模型对于未登录词问题的辨识能力,完整模型结构见图1。
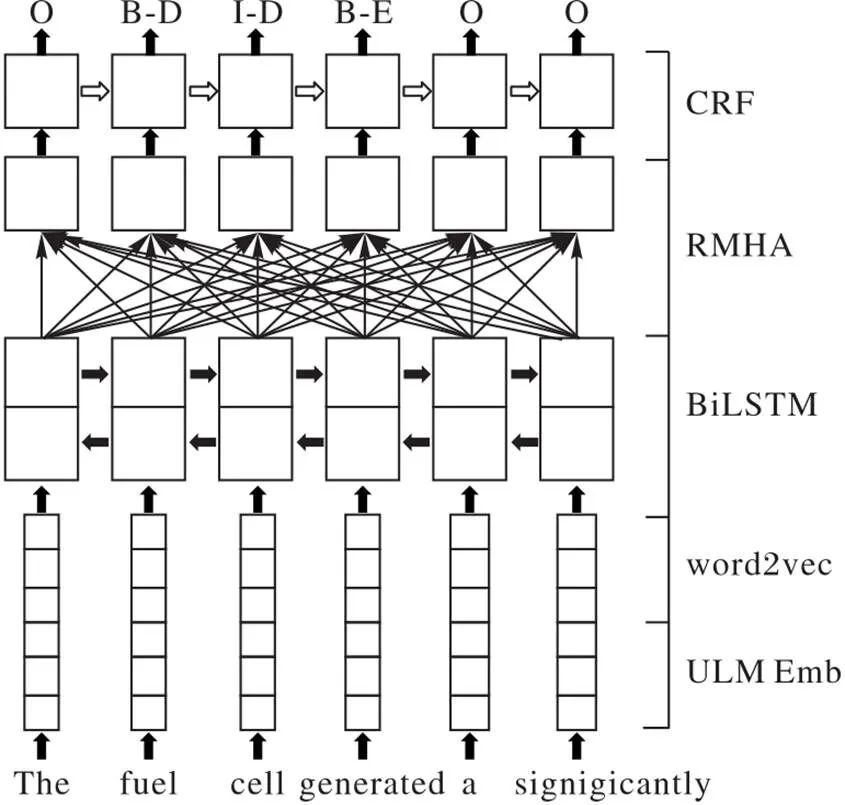
图1 BiLSTM-RMHA-CRF模型结构
1.1 BiLSTM-CRF模型
BiLSTM后接CRF解码层是序列标注任务的常用模型:BiLSTM通过整合前向和后向传递的信息,保证每个隐层都接收到来自其他隐层的信息;CRF解码层可以通过状态转移矩阵来实现相邻标签的约束。本文使用BiLSTM-CRF模型为基本实验模型,在其基础上加入ULM子词嵌入作为输入,并进一步使用基于相对位置编码的相对多头注意力机制作为材料领域命名实体识别模型的编码层,以提高模型对于关键词和相关实体的关注程度。
1.2 基于概率模型的子词嵌入
1.2.1 字符嵌入和子词嵌入
材料领域数据集中存在大量单频词和低频词,传统的词向量表示方法,如word2vec[22],无法很好地处理专业名词、化学式等未知或者罕见词汇,导致其命名实体识别难度较高。目前常用CNN编码层获得单词的字符级表示后,将其与预训练好的词嵌入进行组合参与训练。
子词嵌入把单词划分为长度不一的字符串后对其进行向量表示,相较于字符表示蕴含了更加丰富的形态信息,并可以使用大规模数据集进行预训练词向量。BPEmb[23]利用字节对编码(Byte Pair Encoding, BPE)数据压缩算法构建子词词表,使分词粒度在单词和字符之间,从而更高效率地解决未登录问题。BPEmb划分的子词只能是单一结果,而且对于子词序列的划分结果没有量化的评判标准[24]。
1.2.2 ULM子词嵌入



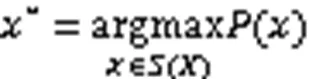

相比BPEmb只能生成固定的子词序列,ULM可以依据概率生成多种不同的分词结果,同时还提出使用不同的分词结果作为噪声输入,有利于提高模型鲁棒性,ULM子词嵌入词表建立流程见图2。
图2 ULM子词嵌入词表建立流程
Fig. 2 Word list construction flow of ULM subword embedding
本文从网络收集大量材料领域文献数据用于ULM子词分词模型训练及词向量训练。首先使用ULM模型分词方法建立词表,并对所有数据进行分词处理,使用概率最大的分词结果训练词向量。在后续命名实体识别的训练中,使用ULM子词嵌入对训练数据,取前3个分词结果对输入数据进行向量表示,而对测试数据仍取概率最大的分词结果。数据处理流程见图3。
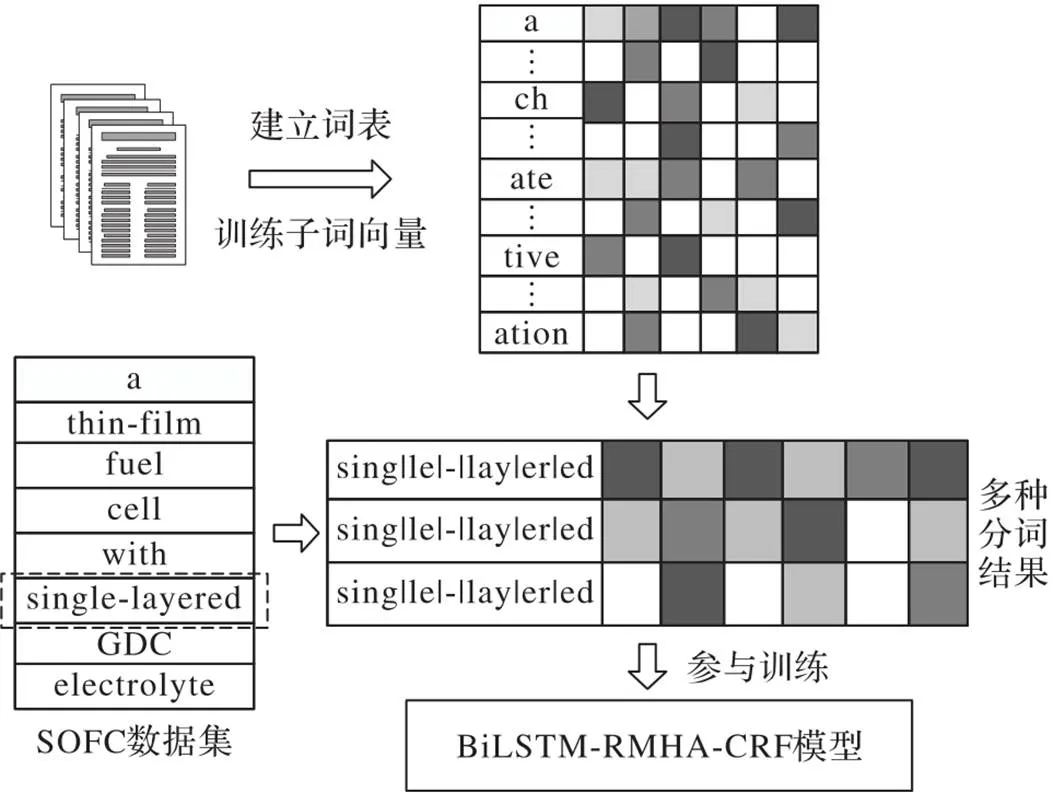
图3 数据处理流程
1.3 相对多头注意力机制
1.3.1 自注意力
自注意力机制能够有效提高模型对于关键词的识别能力,基于多头自注意力机制的Transformer编码器已广泛应用于多种NLP任务,其多头注意力计算见式(5)~(7)。
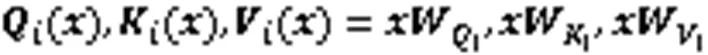
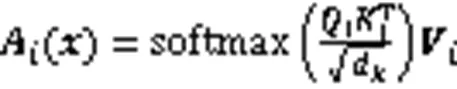
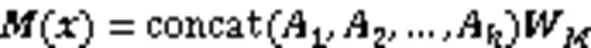
1.3.2 相对多头注意力
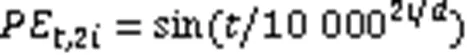

相对多头注意力在多头自注意力机制基础上做出改进,使其能够感知方向和距离特征,其注意力与相对位置编码计算见式(10)~(13)。
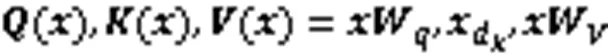
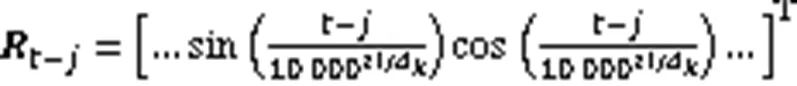
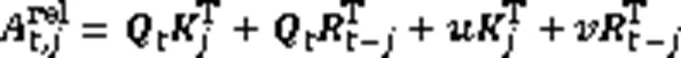
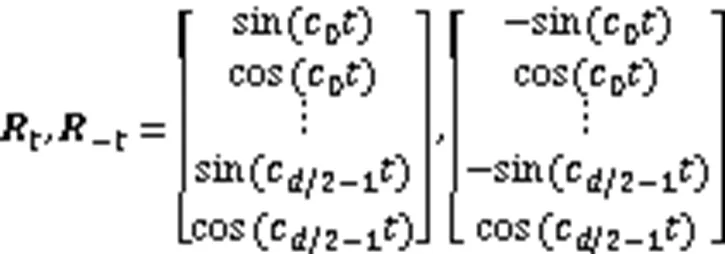
同时多头自注意力中的归一化参数会导致模型注意力分布过于平滑,不利于命名实体识别任务,因此相对多头注意力还取消了归一化因子,使注意力分布更加尖锐,更具区分度。
2 实验设置
2.1 数据集
ULM子词嵌入概率分词模型和预训练子词向量使用网络采集的14万条原始材料领域文献数据;命名实体识别实验采用SOFC命名实体识别数据集(以下简记为SOFC)和SOFC细粒度实体识别数据集(以下简记为SOFC Fine-grained),示例见图4[18]。
SOFC包含MATERIAL、VALUE、DEVICE和EXPERIMENT四种类型的实体标签,采用BIO标注方式。其中MATERIAL类除了材料名外还包括诸如“La0.75Sr0.25Cr0.5Mn0.5O3”的化学式;VALUE类包括实验参数的数值和范围符号,另外还包含描述程度的副词,如“above 750℃”,进一步提高了识别命名实体的复杂度;EXPERIMENT类为标志实验行为的动词,数据集标签分布及标签样例见表1。SOFC细粒度实体识别数据集将四类实体进一步细分为19个子类别。具体实体类别见表2。

图4 SOFC命名实体识别数据集样例
该数据集相较于通用领域数据集,未登录词、单频词和低频词较多,实体形态复杂多样;且不同于通用领域命名实体识别数据集中人名、地名、组织名等本身蕴含的形态学信息较少,实体词之间的关系模糊,材料领域数据集中的实体间存在较大的形态学关联性,如化学式之间的关联信息。
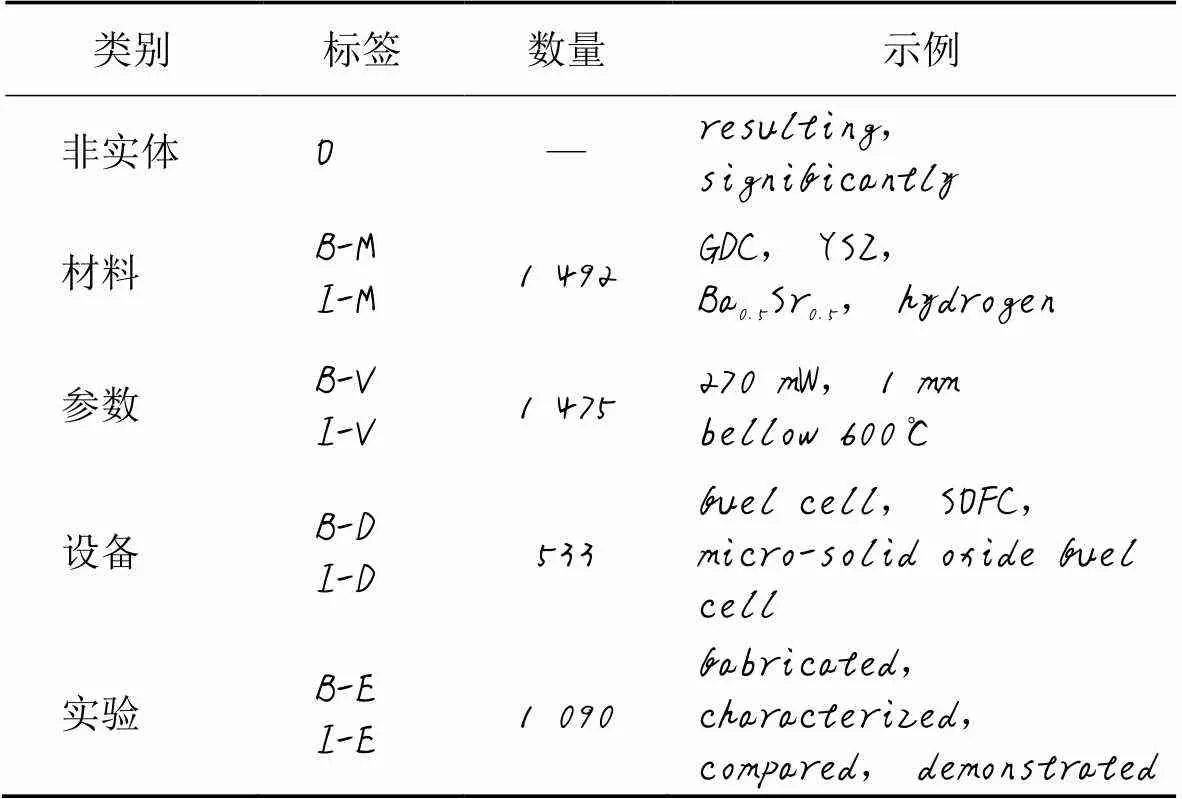
表1 SOFC命名实体识别数据集标签分布

表2 SOFC细粒度实体识别标签类别
2.2 数据预处理
本文使用基于正则模板的数据增强[25],将大量正则模板应用于模型训练,旨在让模型学习到更多上下文信息和模糊实体对于特定上下文的依赖关系,达到提高识别未登录词和低频词的精准度的目的。本文涉及的所有实验均采用正则模板的数据增强方法对训练集数据进行预处理后作为输入。正则模板数据增强见图5。
2.3 模型参数
实验均采用300维word2vec预训练词向量作为基本输入。字符嵌入对字符向量随机初始化后,使用CNN模型进行特征编码得到300维词向量,并参与命名实体识别训练;BPEmb子词嵌入和ULM子词嵌入均使用非结构的大规模材料领域数据进行分词模型的训练,并进一步得到300维预训练词向量作为模型输入。

图5 基于正则模板的数据增强
BiLSTM-RMHA-CRF命名实体识别模型使用Adam优化算法对模型进行参数调整,最大迭代次数为1 440,实验结果选取其中最优结果。本文实验均于PyTorch-1.6.0及GPU环境下完成,详细模型参数设置见表3。

表3 模型参数设置
2.4 评价指标
采用F1值作为模型性能的评价指标,计算平均F1值时采用基于样本分类加权的微平均F1值(Micro F1值)和宏平均F1值(Macro F1),其中Macro F1对于不均衡样本的评估更加敏感,具体计算过程见式(15)~(19):
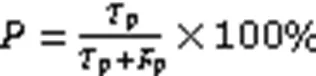
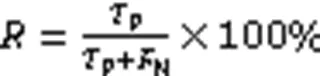
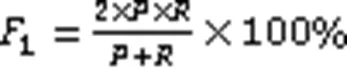
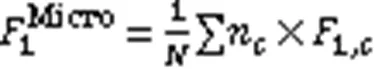
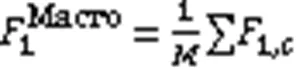
3 实验结果与分析
3.1 综合实验结果
实验使用加入ULM子词嵌入的BiLSTM-RMHA-CRF模型与现有模型在SOFC与SOFC Fine-grained上进行对比,对比模型包括BiLSTM-CNNs-CRF模型[6]、LM-LSTM-CRF模型[8]、BiGRU-SelfAttn模型[9]、SciBERT模型[18]、Char-Level CNN-LSTM模型[20],实验结果见表4。由表4可以看出,相较于其他模型,基于相对多头注意力机制和ULM子词嵌入的模型能够提高对命名实体的辨别能力。
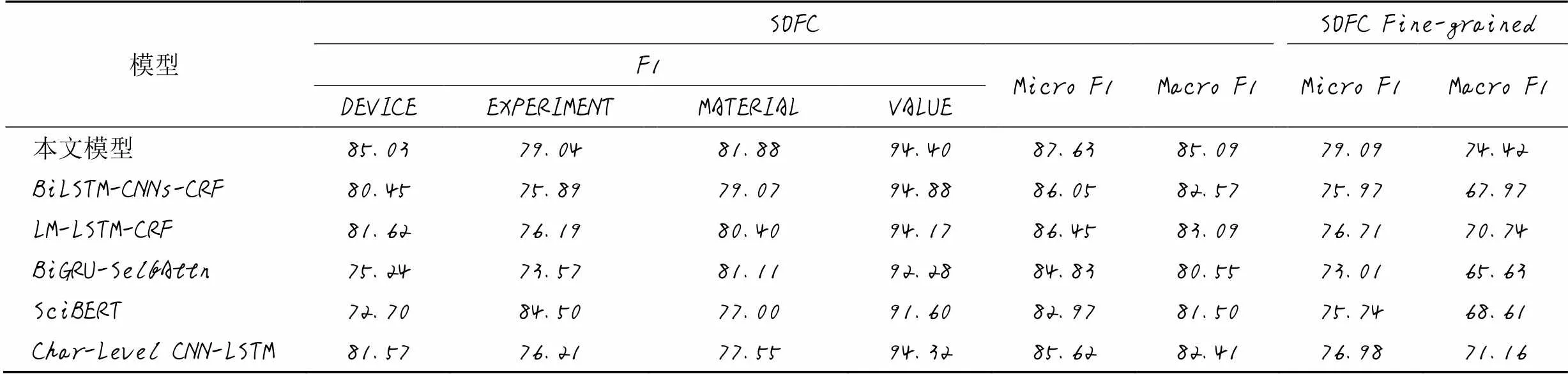
表4 SOFC命名实体识别数据集上不同模型的实验结果 单位: %
BiLSTM-CNNs-CRF模型使用字符级CNN对输入进行编码,得到字符嵌入,再将其输入BiLSTM-CRF模型进行序列标注,其卷积操作在一定程度上相当于能够提取固定宽度的子词信息。LM-LSTM-CRF模型使用字符级LSTM作为字符嵌入模型,将字符序列编码为词向量用于命名实体识别训练。Char-Level CNN-LSTM模型结合了上述两个模型的字符嵌入方法。基于字符嵌入的词嵌入算法在SOFC与SOFC Fine-grained表现尚佳,但由于字符嵌入词表规模过小且蕴含信息有限,无法进行预训练,对于不同的单词输入,即使拥有相同的子词特征也不能保证得到相近的向量表示;而预训练子词嵌入可以确保具有相同子词特征的单词,其词嵌入获得的信息量相同。BiGRU-SelfAttn模型使用了结构更加简单的GRU作为特征编码层,并结合自注意力机制作为命名实体识别模型,并直接将单词作为输入进行训练,其效果相对于其他模型表现有限。SciBERT模型使用了大规模科学领域文献预训练的BERT模型作为编码层,并结合BPEmb子词嵌入作为输入,但使用预训练模型进行微调,并不能充分利用子词嵌入提供的辅助信息。模型对比实验结果表明,基于ULM预训练子词嵌入和相对多头注意力的命名实体识别模型相较于其他模型,在材料领域命名实体识别任务中表现更加出色。
3.2 消融实验
本文针对BiLSTM-RMHA-CRF模型中的RMHA特征编码层以及ULM词嵌入特征进行消融实验,以度量ULM词嵌入方法以及相对多头注意力机制对于材料领域命名实体识别准度的提升作用,实验结果见表5。可以看出BiLSTM-RMHA-CRF模型中,相对多头注意力机制和ULM子词嵌入对材料领域命名实体识别都有不同程度的提升作用。
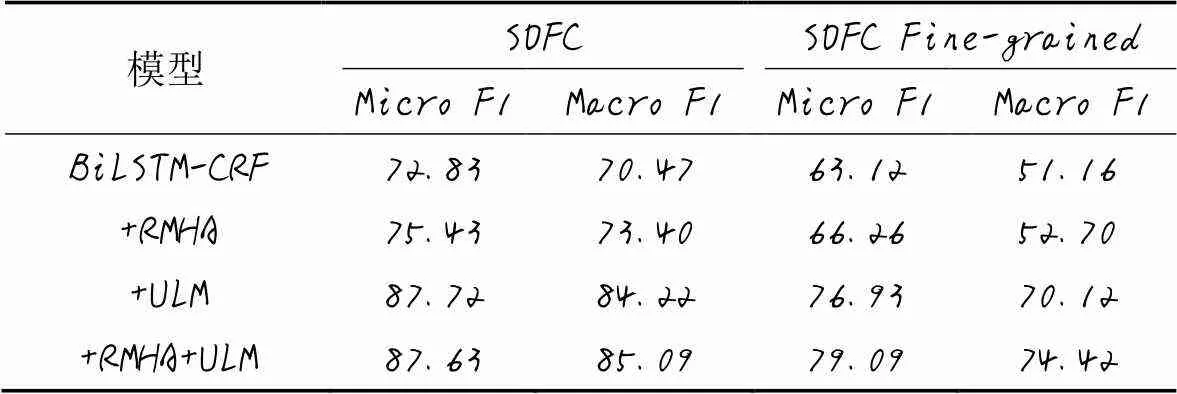
表5 消融实验结果 单位: %
在仅使用BiLSTM-CRF模型时,由于其模型特征编码性能有限,且从词嵌入获取到的信息较少,而材料领域文献中的未登录词较多,导致模型的识别性能不佳;加入相对多头注意力机制后,提高了模型对于关键词的关注度,命名实体识别性能有一定程度的提升;加入ULM子词嵌入,使模型能够获取到单词的形态学信息,并能够辨别单词之间的关联作用,其性能有较大提升,表明基于概率模型的子词嵌入确实能够有效解决未登录词问题,并能提高模型对于材料领域词汇间关联关系的辨识性能。
3.3 词嵌入对比实验
为验证使用大规模材料数据预训练子词嵌入对于模型的提升效用,以BiLSTM-RMHA-CRF模型为基本模型,分别使用CNN字符嵌入、BPEmb子词嵌入和ULM子词嵌入结合word2vec作为输入,实验结果见表6。可以看出,使用预训练词向量的BPEmb和ULM子词嵌入相对于字符嵌入,对于命名实体识别的提升较大,表明预训练词向量能够充分利用非结构化的文献数据,使模型能够解析其蕴涵的词缀信息;使用概率模型的ULM子词嵌入相较于BPEmb有所提升,表明基于概率模型的分词方式和噪声输入确实有助于提高模型的鲁棒性。
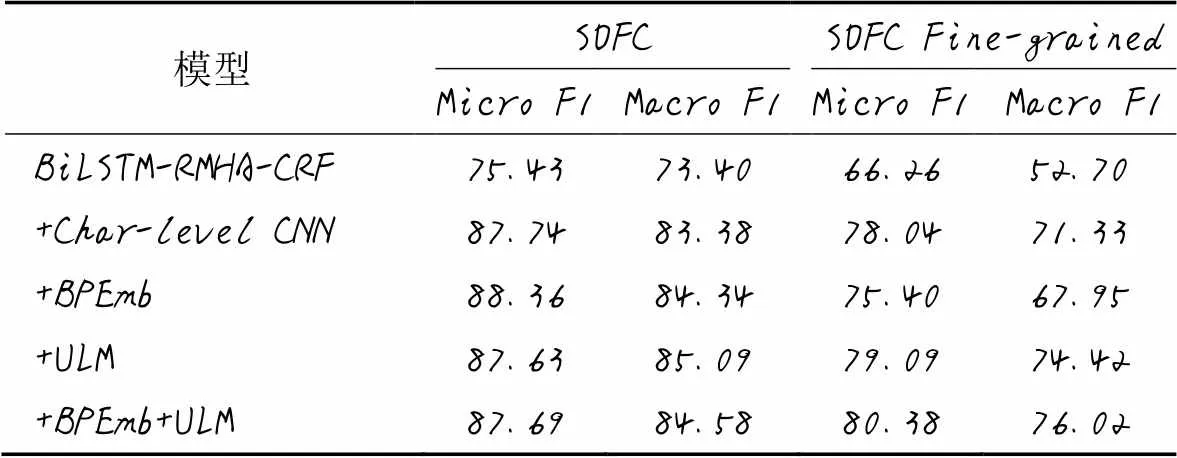
表6 词嵌入实验结果 单位: %
3.4 特征编码对比实验
统一使用ULM词嵌入作为输入,在BiLSTM-CRF模型基础上加入命名实体识别常用的卷积神经网络、自注意力机制(Self-Attention, SA)、多头注意力机制(Multi-Head Attention, MHA)和相对多头注意力机制(RMHA),用以验证相对多头注意力机制对于模型的提升效用,实验结果见表7。可以看出,相对于其他特征编码模型,相对多头注意力机制能更有效地提升模型对于实体与实体、实体与上下文关系的辨别能力,提高注意力的锐化程度,从而提高模型的识别水平。
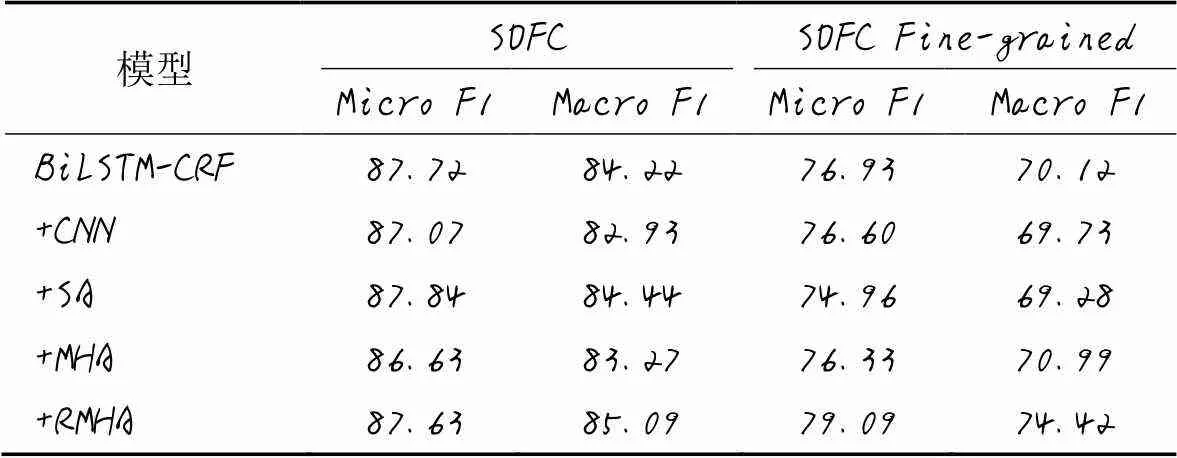
表7 特征编码器实验结果 单位: %
4 结语
本文针对材料领域命名实体识别数据规模小、识别难度高等问题,提出了BiLSTM-RMHA-CRF模型方法,同时使用基于概率模型的ULM子词嵌入作为模型输入,以提高模型对于材料领域命名实体的辨别能力。通过在多种适用于命名实体识别的模型上进行对比实验,证明该方法可以有效提高模型的普适性和鲁棒性,在Micro F1、Macro F1两种评价指标上都有较大的提高。通过特征编码层对照和词嵌入对照实验,验证了相对多头注意力机制和预训练ULM子词嵌入对于命名实体识别模型的提高效用,表明相对多头注意力机制和ULM子词嵌入对于材料领域命名实体识别确有较大的提升作用。但本文算法并没有解决样本分布不均带来的模型偏侧性问题,不同类别的实体,其识别准度差异较大,检测能力也有待提升,可以将其作为进一步的研究方向。
[1] LAFFERTY J D, McCALLUM A, PEREIRA F C N. Conditional random fields: probabilistic models for segmenting and labeling sequence data[C]// Proceedings of the 18th International Conference on Machine Learning. San Francisco: Morgan Kaufmann Publishers Inc., 2001: 282-289.
[2] KIM Y. Convolutional neural networks for sentence classification[C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2014: 1746 - 1751.
[3] HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8):1735-1780.
[4] CHUNG J, GULCEHRE C, CHO K, et al. Empirical evaluation of gated recurrent neural networks on sequence modeling[EB/OL]. (2014-12-11)[2021-02-13]. https://arxiv.org/pdf/1412.3555.pdf.
[5] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 6000-6010.
[6] MA X Z, HOVY E. End-to-end sequence labeling via bi-directional LSTM-CNNs-CRF[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2016: 1064-1074.
[7] CHIU J P C, NICHOLS E. Named entity recognition with bidirectional LSTM-CNNs[J]. Transactions of the Association for Computational Linguistics, 2016, 4: 357-370.
[8] LIU L Y, SHANG J B, Ren x, et al. Empower sequence labeling with task-aware neural language model[C]// Proceedings of the 32nd AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2018: 5253-5260.
[9] DHRISYA K, REMYA G, MOHAN A. Fine-grained entity type classification using GRU with self-attention[J]. International Journal of Information Technology, 2020, 12(3): 869-878.
[10] 杨维,孙德艳,张晓慧,等. 面向电力智能问答系统的命名实体识别算法[J]. 计算机工程与设计, 2019, 40(12): 3625-3630.(YANG W, SUN D Y, ZHANG X H, et al. Named entity recognition for intelligent answer system in power service[J]. Computer Engineering and Design, 2019, 40(12): 3625-3630.)
[11] 李博,康晓东,张华丽,等. 采用Transformer-CRF的中文电子病历命名实体识别[J]. 计算机工程与应用, 2020, 56(5):153-159.(LI B, KANG X D, ZHANG H L, et al. Named entity recognition in Chinese electronic medical records using Transformer-CRF[J]. Computer Engineering and Applications, 2020, 56(5):153-159.)
[12] 张华丽,康晓东,李博,等. 结合注意力机制的Bi-LSTM-CRF中文电子病历命名实体识别[J]. 计算机应用, 2020, 40(S1):98-102.(ZHANG H L, KANG X D, LI B, et al. Medical name entity recognition based on Bi-LSTM-CRF and attention mechanism[J]. Journal of Computer Applications, 2020, 40(S1):98-102.)
[13] 张心怡,冯仕民,丁恩杰. 面向煤矿的实体识别与关系抽取模型[J]. 计算机应用, 2020, 40(8):2182-2188.(ZHANG X Y, FENG S M, DING E J. Entity recognition and relation extraction model for coal mine[J]. Journal of Computer Applications, 2020, 40(8):2182-2188.)
[14] 许力,李建华. 基于句法依存分析的图网络生物医学命名实体识别[J]. 计算机应用, 2021, 41(2):357-362.(XU L, LI J H. Biomedical named entity recognition with graph network based on syntactic dependency parsing[J]. Journal of Computer Applications, 2021, 41(2):357-362.)
[15] MYSORE S, KIM E, STRUBELL E, et al. Automatically extracting action graphs from materials science synthesis procedures[EB/OL]. (2017-11-28)[2021-02-13].https://arxiv.org/pdf/1711.06872.pdf.
[16] MYSORE S, JENSEN Z, KIM E, et al. The materials science procedural text corpus: annotating materials synthesis procedures with shallow semantic structures[C]// Proceedings of the 13th Linguistic Annotation Workshop. Stroudsburg, PA: Association for Computational Linguistics, 2019: 56-64.
[17] MRDJENOVICH D, HORTON M K, MONTOYA J H, et al. propnet: a knowledge graph for materials science[J]. Matter, 2020, 2(2): 464-480.
[18] FRIEDRICH A, ADEL H, TOMAZIC F, et al. The SOFC-Exp corpus and neural approaches to information extraction in the materials science domain[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2020: 1255-1268.
[19] GAJENDRAN S, MANJULA D, SUGUMARAN V. Character level and word level embedding with bidirectional LSTM - dynamic recurrent neural network for biomedical named entity recognition from literature[J]. Journal of Biomedical Informatics, 2020, 112: No.103609.
[20] CHO M, HA J, PARK C, et al. Combinatorial feature embedding based on CNN and LSTM for biomedical named entity recognition[J]. Journal of Biomedical Informatics, 2020, 103: No.103381.
[21] YAN H, DENG B C, LI X N, et al. TENER: adapting transformer encoder for named entity recognition[EB/OL]. (2019-12-10)[2021-02-13].https://arxiv.org/pdf/1911.04474.pdf.
[22] MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space[EB/OL]. (2013-09-07)[2021-02-13].https://arxiv.org/pdf/1301.3781.pdf.
[23] HEINZERLING B, STRUBE M. BPEmb: tokenization-free pre-trained subword embeddings in 275 languages[C]// Proceedings of the 11th International Conference on Language Resources and Evaluation . Stroudsburg, PA: Association for Computational Linguistics, 2018: 2989-2993.
[24] KUDO T. Subword regularization: improving neural network translation models with multiple subword candidates[C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2018: 66-75.
[25] LIU Z H, WINATA G I, XU P, et al. Coach: a coarse-to-fine approach for cross-domain slot filling[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2020: 19-25.)
Material entity recognition based on subword embedding and relative attention
HAN Yumin, HAO Xiaoyan*
(,,030600,)
Accurately identifying named entities is helpful to construct professional knowledge graphs and question answering systems. Named Entity Recognition (NER) technology based on deep learning has been widely used in a variety of professional fields. However, there are relatively few researches on NER in the field of materials. Concerning the problem of small scale of datasets and high complexity of entity words for supervised learning in NER of materials field, the large-scale unstructured materials field literature data were used to train the subword embedding word segmentation model based on Unigram Language Model (ULM), and the information contained in the word structure was fully utilized to enhance the robustness of the model. At the same time, the entity recognition model with BiLSTM-CRF (Bi-directional Long-Short Term Memory-Conditional Random Field) model as the basis and combined with the Relative Multi-Head Attention(RMHA)capable of perceiving direction and distance of words was proposed to improve the sensitivity of the model to keywords. Compared with BiLSTM-CNNs-CRF, SciBERT (Scientific BERT) and other models, the obtained BiLSTM-RMHA-CRF model combining with the ULM subword embedding method increased the value of Macro F1 by 2-4 percentage points on Solid Oxide Fuel Cell (SOFC) NER dataset, and 3-8 percentage points on SOFC fine-grained entity recognition dataset. Experimental results show that the recognition model based on subword embedding and relative attention can effectively improve the recognition accuracy of entities in the materials field.
named entity recognition; subword embedding; relative attention; deep learning; material field
This work is partially supported by Soft Science Research Program of Shanxi Province (2019041055-1), Scientific Research and Technology Project of Peking University (203290929-J).
HAN Yumin, born in 1995, M. S. His research interests include natural language processing.
HAO Xiaoyan,born in 1970, Ph. D., associate professor. Her research interests include natural language processing, computer linguistics, artificial intelligence.
TP391
A
1001-9081(2022)06-1862-07
10.11772/j.issn.1001-9081.2021040582
2021⁃04⁃15;
2021⁃07⁃09;
2021⁃07⁃15。
山西省软科学研究计划项目(2019041055-1);京大学科研技术项目(203290929-J)。
韩玉民(1995—),男,山西临汾人,硕士,主要研究方向:自然语言处理;郝晓燕(1970—),女,山西太原人,副教授,博士,主要研究方向:自然语言处理、计算机语言学、人工智能。
