基于奖励预测误差的内在好奇心方法
2022-07-05谭庆李辉吴昊霖王壮邓书超
谭庆,李辉,吴昊霖,王壮,邓书超
基于奖励预测误差的内在好奇心方法
谭庆1,李辉1,2*,吴昊霖1,王壮1,邓书超1
(1.四川大学 计算机学院(软件学院),成都 610065; 2.视觉合成图形图像技术国家级重点实验室(四川大学),成都 610065)(*通信作者电子邮箱lihuib@scu.edu.cn)
针对状态预测误差直接作为内在好奇心奖励,在状态新颖性与奖励相关度低的任务中强化学习智能体不能有效探索环境的问题,提出一种基于奖励预测误差的内在好奇心模块(RPE-ICM)。RPE-ICM利用奖励预测误差网络(RPE-Network)学习并修正状态预测误差奖励,并将奖励预测误差(RPE)模型的输出作为一种内在奖励信号去平衡探索过度与探索不足,使得智能体能够更有效地探索环境并利用奖励去学习技能,从而达到更好的学习效果。在不同的MuJoCo环境中使用RPE-ICM、内在好奇心模块(ICM)、随机蒸馏网络(RND)以及传统的深度确定性策略梯度(DDPG)算法进行对比实验。结果表明,相较于传统DDPG、ICM-DDPG以及RND-DDPG,基于RPE-ICM的DDPG算法的平均性能在Hopper环境中分别提高了13.85%、13.34%和20.80%。
强化学习;探索;内在好奇心奖励;状态新颖性;深度确定性策略梯度
0 引言
强化学习(Reinforcement Learning, RL)是一种智能体通过与环境交互的同时最大化环境返回的奖励值来学习最优策略的机器学习方法[1]。在许多RL场景中,智能体的外在奖励稀疏,难以正确地更新其策略。人类可以在奖励稀少的情况下对环境进行探索,其动机主要源于人类内在的好奇心。类似地,可以将这种好奇心赋予智能体,使智能体在外在奖励稀疏时增加探索。
目前内在好奇心奖励的设计方法主要分为两种:第一种是基于状态新颖性,例如访问状态计数[2],这种方法可以对以前访问过的状态进行统计,并给予访问新状态的智能体额外的奖励;另一种方法是基于神经网络模型预测的下一状态与实际的下一状态之间的误差。使用状态预测误差作为好奇心奖励可以理解为将没有经历过的状态作为一种奖励信号去触发智能体的好奇心。例如内在好奇心模块(Intrinsic Curiosity Module, ICM)[3]和基于随机网络蒸馏(Random Network Distillation, RND)方法[4],两者利用状态新颖性作为内在好奇心奖励,能够让智能体更好地探索到之前没有经历过的状态。
但基于访问计数的方法难以应用在具有高维度的状态空间的场景;而状态预测误差过度关注于智能体对最新状态的探索,导致智能体在状态与外在奖励低相关的任务中出现过度探索[5],从而不能有效利用内在奖励去解决问题。
本文提出的基于奖励预测误差的内在好奇心奖励模块(Intrinsic Curiosity Module with Reward Prediction Error, RPE-ICM)将状态预测误差奖励作为奖励预测误差网络(Reward Prediction Error Network, RPE-Network)的输入,通过训练奖励预测误差网络去学习修正状态误差奖励,将最终网络输出的奖励作为内在好奇心奖励以引导智能体探索环境。深度确定性策略梯度(Deep Deterministic Policy Gradient, DDPG)算法[6]是一个确定性动作算法,存在探索不足的问题。本文首先将RPE-ICM(前向模型与RPE-Network)和ICM模块(前向模型与逆向模型)分别与DDPG算法结合,在四种MuJoCo(Multi-Joint dynamics with Contact)环境中进行对比实验,结果表明:ICM对传统DDPG的性能有所提升,但是存在探索过度,方差较大的情况;而RPE-ICM能够平衡探索不足与探索过度,在稳定性与得分有更好的表现。然后比较了仅使用前向模型的DDPG智能体与RPE模块与前向模型结合的DDPG智能体,实验结果表明在前向模型基础之上加入奖励预测误差(Reward Prediction Error, RPE)模型对其性能提升有重要作用。
1 相关研究
1.1 强化学习
RL是机器学习方法的一大分支,是研究智能体在外在环境中进行交互和学习的理论与方法。RL模型的定义如图1所示。智能体根据自身的策略与环境进行交互,环境进入下一状态并将奖励信号反馈给智能体。

图1 强化学习智能体与环境交互
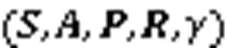
1.2 DDPG算法
传统的RL方法如Q学习(Q-learning)[7]等表格类方法都无法处理复杂的状态和动作维度。针对这类问题,RL和深度学习[8]结合而成的深度强化学习方法应运而生,例如采用神经网络估计值函数的深度Q学习网络(Deep Q-learning Network, DQN)[9]算法。在后续研究中,许多DQN的改进算法以及使用神经网络的策略梯度算法迅速发展。DDPG算法是确定性策略梯度(Deterministic Policy Gradient, DPG)[10]算法的改进算法,同时结合了行动器-评判器(Actor-Critic, AC)算法[11-12]、目标网络和经验池的优点。
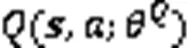
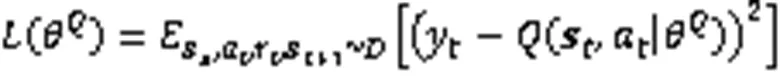
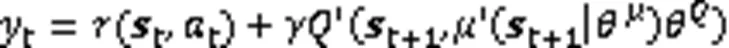
Actor网络根据策略梯度更新网络参数,即式(3):
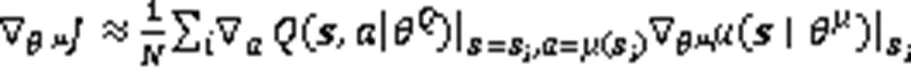
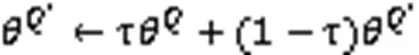

2 内在好奇心奖励模块
RL的外在动机是智能体需要最大化与环境交互过程中出现的外在奖励,例如Atari视频游戏中的分数。在外在奖励稀疏的情况下,智能体单纯依靠外在动机无法有效学习。而内在动机或者好奇心可以促使智能体在没有明确外在奖励的情况下进行好奇心驱动的探索,这种内在驱动或者好奇心有利于提高智能体在外在奖励稀疏环境中解决任务、学习技能和提高任务泛化的能力,因此内在奖励或者好奇心驱动能解决稀疏奖励问题带来的稀疏性和不可靠性问题[13]。
奖励稀疏性问题在三维视频游戏场景中较为突出,智能体在三维视频游戏场景中可能在持续较长的时间序列内都难以获得环境奖励反馈[14]。在这类三维场景中,深度强化学习算法需要依据包含奖励值信号的数据元组样本进行智能体行动策略的迭代和更新,缺乏奖励信号将导致智能体难以学习到有效的行动策略。而好奇心驱动是一类使用内在奖励引导智能体探索环境的方法,高效的探索能够更快地获得外在奖励[15],同时能够降低环境的奖励和状态转移的不确定性,平衡探索与利用[16]。
2.1 状态预测误差内在好奇心模块

图2 ICM原理
2.2 奖励预测误差的内在好奇心模块
ICM在前向模型基础上增加了逆向模型提取对智能体选择动作有影响的特征去更新前向模型,但好奇心奖励仍然是一个状态差异值预测[20],因此同样存在对内在奖励值过高估计的问题。文献[18]的实验结果表明,在很多强化学习环境中,并不是越新的状态和动作对智能体的学习越有效,在状态多样性与奖励低相关的游戏任务中ICM方法与普通强化学习算法相比没有改进,例如MuJoCo环境中的Ant、Walker2d等。
为了解决状态预测误差奖励所存在的好奇心奖励高估问题,本文提出的RPE-ICM方法在前向模型基础上增加了奖励预测网络(RPE-Network)。利用外在奖励和状态预测误差奖励对RPE-Network进行训练,然后用训练的RPE-Network评估状态预测误差奖励,从而不断对前向模型的预测状态误差奖励进行修正。在RPE-Network与前向模型结合的方法中,强化学习智能体能够学到合适的好奇心奖励,因此RPE-ICM能够平衡探索不足与探索过度。
2.2.1 RPE-ICM方法
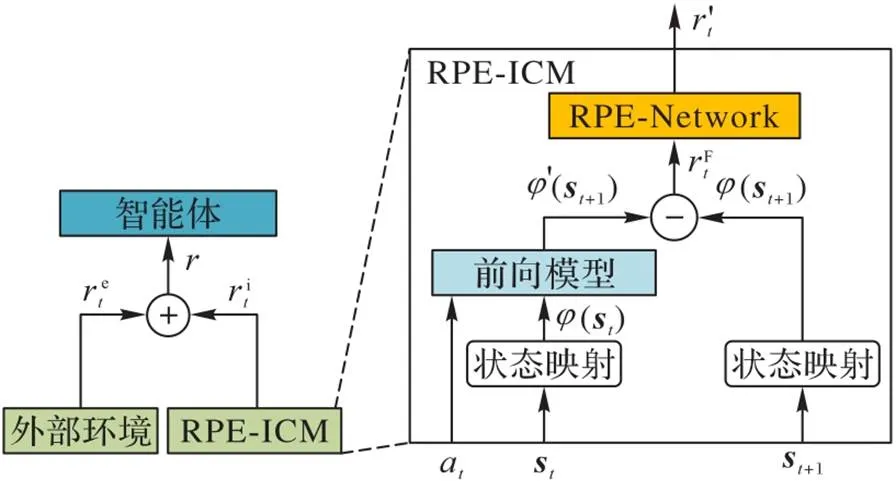
图3 RPE-ICM方法架构
RPE-ICM中前向网络模型定义如式(6):
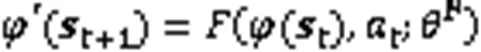
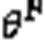


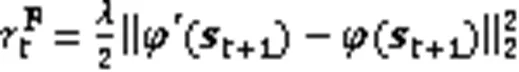
除了前向模型,本文还需要训练一个RPE-Network,计算公式如下:

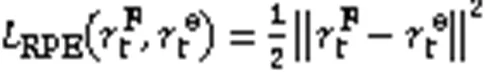
最后通过式(11)最小化RPE-ICM模块中的损失函数。
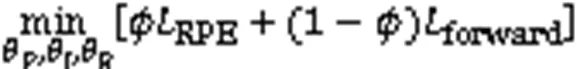
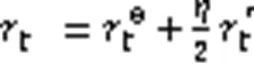
2.2.2 算法流程
综上所述,RPE-ICM-DDPG算法整体流程如下:
3)初始化经验池(Replay Memory, RM);
8) 根据当前策略和探索噪声选择动作
9) End for
16) End for
RPE‑ICM前向网络和RPE‑Network参数;
Critic网络参数;
19) 式(3)使用策略梯度算法更新Actor网络;
20) End for
21) End for
3 实验与结果分析
3.1 实验平台和实验介绍
本文采用OpenAI公司开发的Gym平台MuJoCo中的4个连续控制任务作为实验环境。Gym平台是一个开源强化学习环境,也是一个开发和对比强化学习算法的工具箱。MuJoCo环境是一个物理引擎,意在促进机器人、生物力学、图形和动画以及其他需要快速准确模拟的领域的研究和开发[22]。本文进行实验的4个连续控制任务如下:
1)Walker2d实验环境如图4(a)所示,此任务是使二维两足机器人尽可能地向前行走。
2)Hopper实验环境如图4(b)所示,此任务是让一个三维单腿机器人尽可能地快速向前跳跃。
3)Swimmer实验环境如图4(c)所示,是在粘性流体中的三连杆游泳机器人,此任务是通过驱动两个关节使其尽可能快地向前游。
4)Ant实验环境如图4(d)所示,此任务使3D四足蚂蚁形态的机器人学会快速向前走。
3.2 实验参数设置
在深度强化学习算法中参数的设计对网络训练结果有着较大影响。本文DPPG中评判器网络、行动器网络结构参数、ICM和RPE-ICM模块网络中的具体超参数如表1。其中,学习率控制网络中权重更新幅度的大小:学习率太高会导致网络训练过程不稳定,从而导致最终学习效果不好;而学习率太低则会导致学习过程缓慢,需要极长时间才能够收敛。训练批次大小是每一次训练神经网络送入模型的样本数,大批次可以使网络训练速度变快,但批次过大对硬件设备配置要求高,本文实验中批次大小设为64。在每个MuJoCo任务环境中的总步数是400万。Critic网络和Actor网络的网络结构沿用DDPG论文中的设置,RPE-ICM中前向模型与RPE-Network结构如表2。
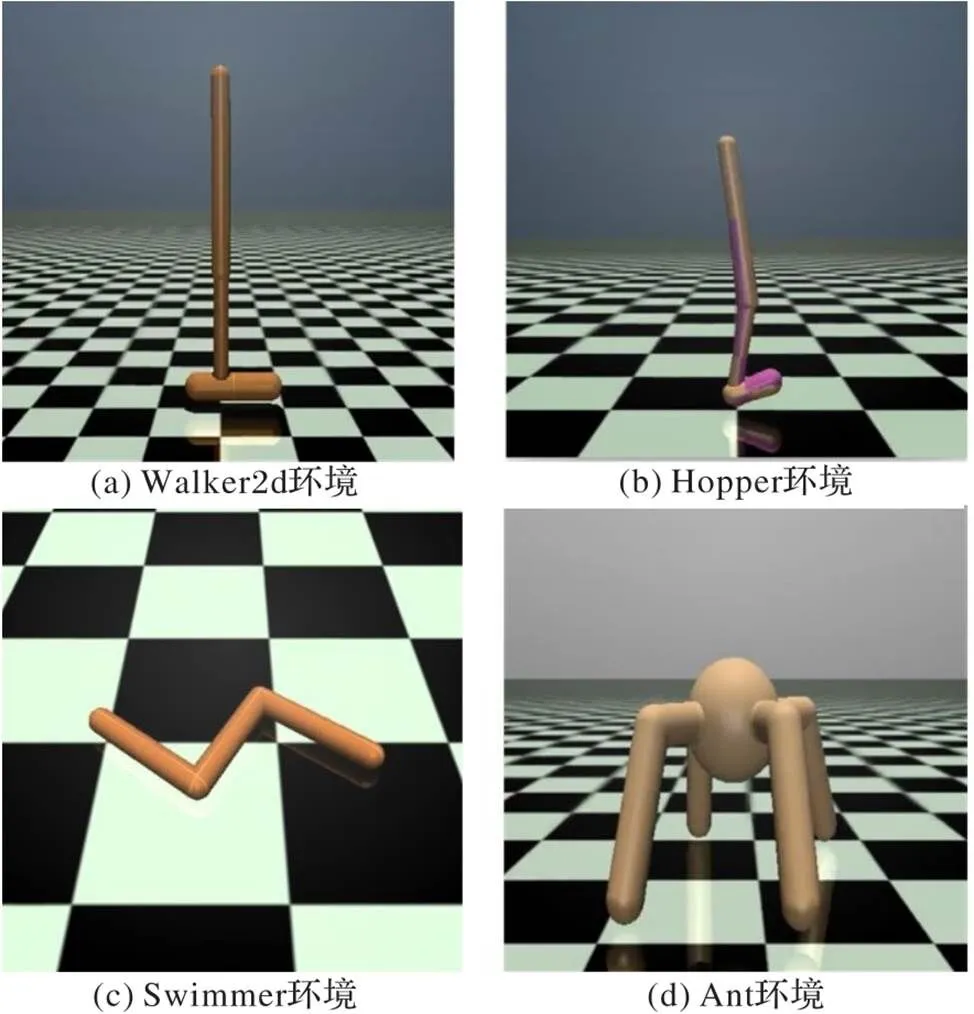
图4 实验环境

表1 实验超参数

表2 RPE-ICM网络结构
3.3 实验结果与分析
深度强化学习中算法效果主要由最终平均奖励决定,网络在设定的迭代次数结束后,平均奖励越大说明该算法性能越好。本文首先比较了RPE-ICM-DDPG、ICM-DDPG、RND-DDPG和传统DDPG在MuJoCo的4个连续任务环境上的性能(平均回报);然后将RPE模型和前向模型结合的方法与仅使用前向模型的方法进行对比,进一步验证在前向模型基础之上加入RPE-Network的作用。
3.3.1 对比不同算法的性能
为了减少随机因素对实验的影响,验证算法有效性,本文对每个环境进行了5次对比实验。实验结果如图5所示,横坐标为实验步数(Steps),纵坐标为平均回报值。图中实线表示多次训练过程回报的平均值,阴影表示方差。
在Walker2d和Swimmer环境中,如图5(a)、5(c)所示,DDPG、ICM-DDPG、RND-DDPG与RPE-ICM-DDPG算法在前100万步时,四种算法的平均回报都处于上升阶段。而在实验进行100万步之后,RPE-ICM-DDPG平均回报优于其他三种算法,在Walker2d环境中,RPE-ICM-DDPG与RND-DDPG相比,性能提升明显。同时RPE-ICM-DDPG的曲线阴影面积相较于另外三种算法要小,这表示其方差更小,即算法更加稳定。在Hopper中,如图5(b)所示,在实验前期,RPE-ICM-DDPG算法的表现略差于DDPG,原因之一是RPE-ICM-DDPG算法增加了神经网络模块,所以学习所需的样本量大于DDPG算法。另外一个更重要的原因是DDPG是确定性动作算法,由于没有好奇心奖励模块,智能体更加偏向于利用而忽略探索。这会使智能体在前期能够获得比较高的奖励值,从而得到一个次优策略,但是在后期由于缺乏探索导致智能体学习效果不佳。本文增加RPE-ICM模块后,虽然前期需要增加训练的样本,但这也使得智能体在陌生的环境中有更多的内在好奇心奖励,从而激励智能体探索环境。智能体在整个学习过程中能够更好地平衡探索与利用,从而得到更好的学习效果。在实验进行50万步之后,DDPG和ICM-DDPG上升趋势趋于平稳甚至有所下降,而RPE-ICM-DDPG算法的表现明显优于其他三种算法。在Ant环境中,如图5(d)所示,四种算法虽然都在波动上升,但在实验后期,RPE-ICM-DDPG的性能表现始终优于DDPG和ICM-DDPG,最终的平均回报也在较高值。RPE-ICM-DDPG与RND-DDPG算法在Ant环境中的性能差距不明显,但是可以明显看出后者波动相对较大,即方差更大。RPE-ICM对比三种算法性能分数情况如表3所示,其中1、2和3分别表示RPE-ICM-DDPG相对于DDPG、ICM-DDPG和RND-DDPG的性能提升。可以看到,对比传统DDPG算法,RPE-ICM-DDPG在Walker2d环境中提升了9.54%,在Ant环境中提升达到了173.27%;对比ICM-DDPG,在RPE-ICM-DDPG在Walker2d中提升7.05%,在Ant中达到了83.49%;对比RND-DDPG,RPE-ICM-DDPG在Walker2d中提升5.0%,在Hopper中提升了20.8%。
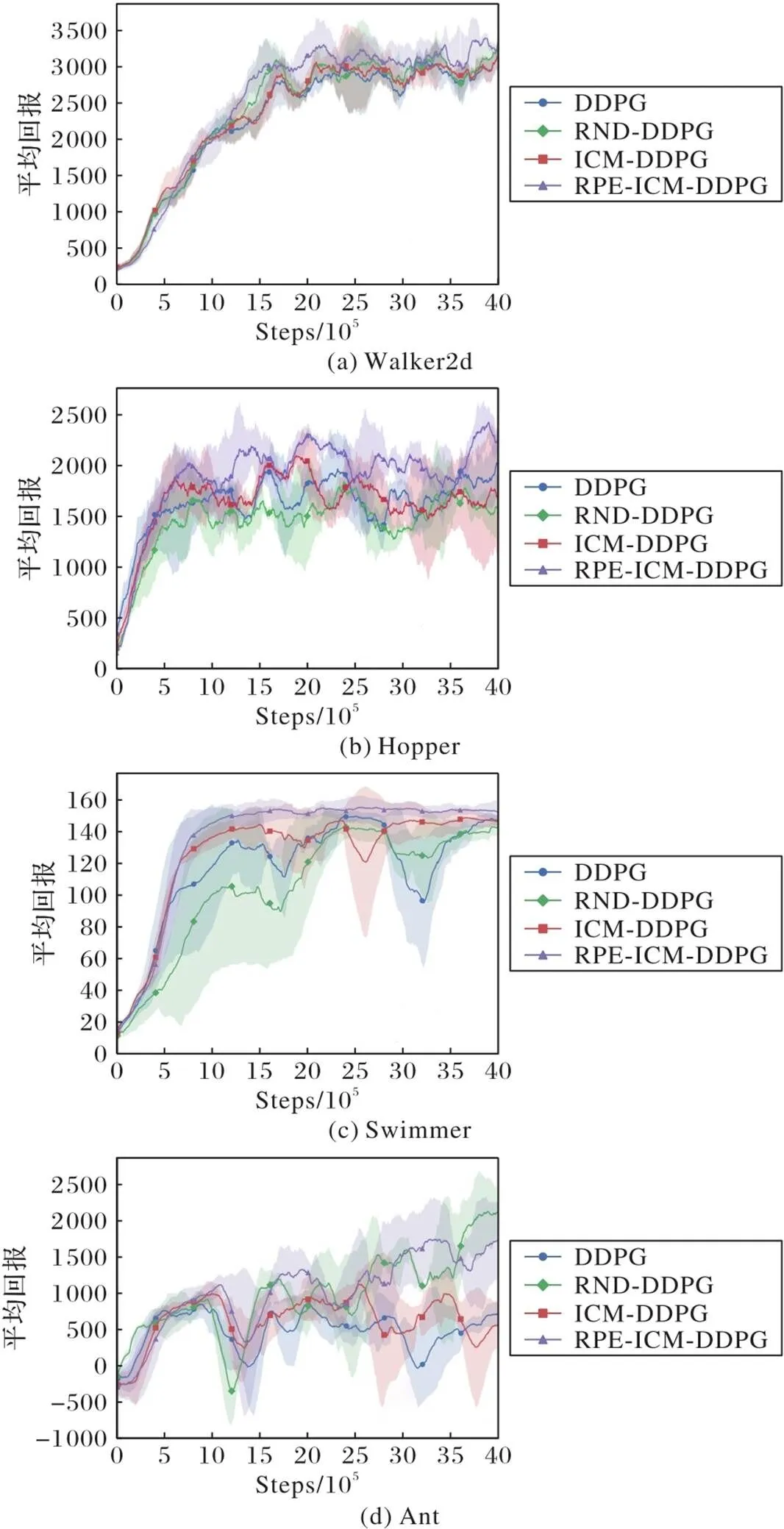
图5 四种算法在不同任务中的性能对比

表3 不同实验环境中算法的性能对比
实验结果表明,由于DDPG的探索策略主要是随机噪声,在三维视频环境中难以学习到有效策略。ICM通过状态预测误差的好奇心奖励驱动智能体获取更多有用的状态,使得在某些环境中探索程度有所提高;但同时,ICM算法会面临好奇心陷阱,即过度探索新状态,这在状态新颖性与奖励低相关环境中不利于智能体神经网络的收敛,因此可以看到ICM算法中方差较大,导致实际性能表现也并不是特别理想。如图5所示,RPE-ICM-DDPG算法方差比其他两者算法更小。在利用好奇心奖励引导智能体探索的同时,奖励误差预测模块也让智能体学会“克制”自己的好奇心,能够平衡智能体的探索不足与探索过度。
3.3.2 RPE-Network与前向模型
为了进一步验证本文提出的RPE-Network对前向模型性能提升的重要作用,本节实验将仅前向模型的方法(Only Forward)与RPE-Network结合前向模型的方法(RPE-ICM)进行了对比。由于在上节实验中,RPE-ICM的性能提升在Hopper和Swimmer两个环境中处于所有环境中的中间水平,故实验环境最终选择Hopper和Swimmer。实验结果分别如图6、7所示,实线表示5次训练过程回报的平均值,阴影部分表示方差。如图6、7所示,在实验前前期,两种方法的平均回报都处于上升趋势;随着训练的进行,Only Forward方法的智能体的平均回报明显要低于RPE-ICM方法的智能体。同时从图中的阴影面积可以看出,在两个任务环境中RPE-ICM智能体在多次实验中得到回报的方差与Only Forward智能体相比要小。实验结果表明RPE与前向模型结合的方法的性能和稳定性比仅使用前向模型的方法更好,这进一步验证了RPE-Network对前向模型的性能与稳定性的提升起着重要作用。
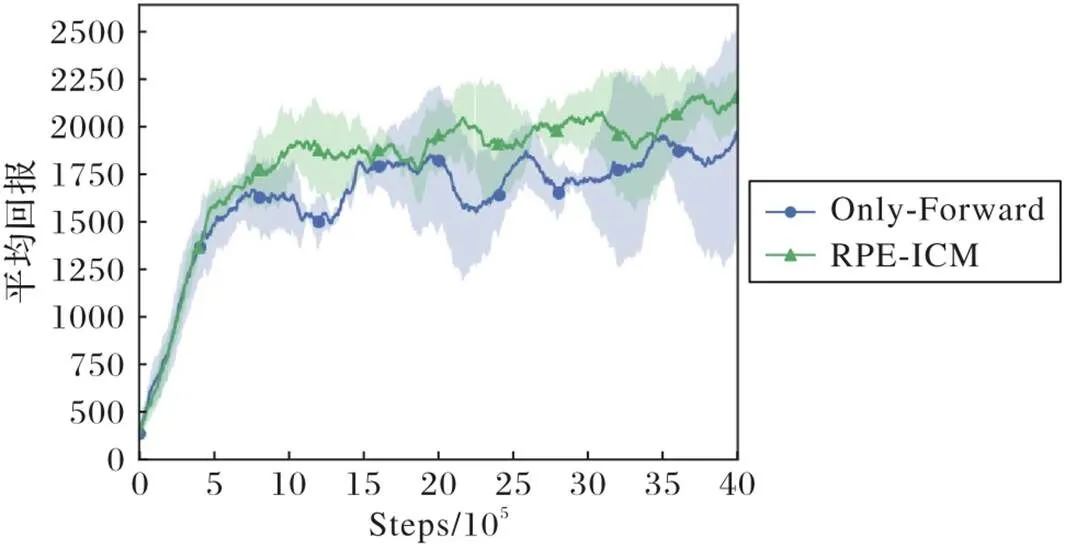
图6 Hopper环境中两种方法的平均回报
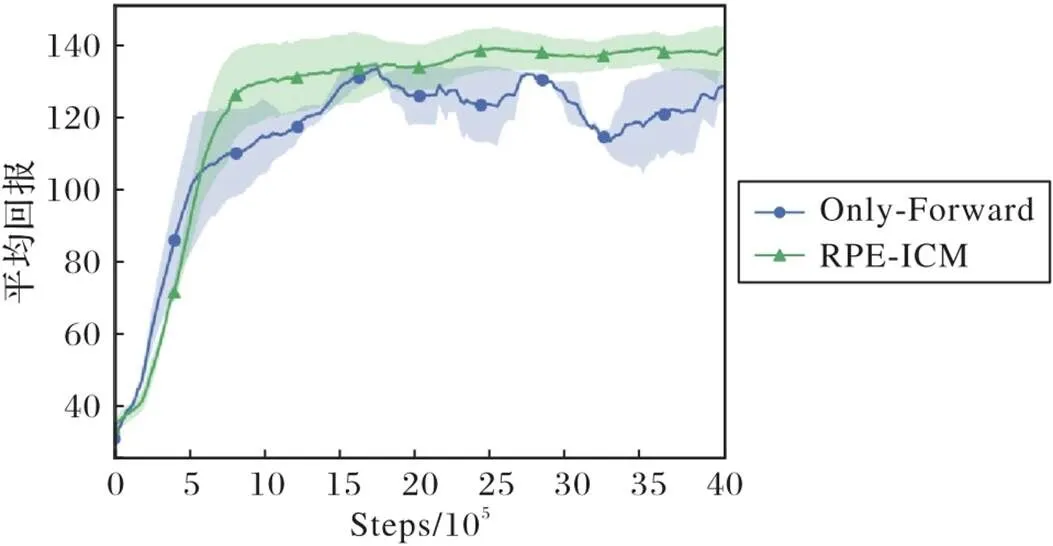
图7 Swimmer环境中两种方法的平均回报
4 结语
智能体探索一直是深度强化学习的一个重要研究方向,以内在好奇心奖励鼓励智能体探索是重要方法之一。本文针对ICM在实际环境中的过度探索问题,提出了基于预测奖励误差方法,通过RPE-Network修正状态误差奖励,从而使智能体能够更加合理地利用内在好奇心奖励。然后将RPE-ICM-DDPG与传统的DDPG算法、ICM-DDPG算法以及内在好奇心方法RND-DDPG算法进行了实验对比,结果表明RPE-ICM-DDPG方法相较于传统DDPG、ICM-DDPG和RND-DDPG算法有更好的稳定性以及更高的平均奖励回报值。在四个实验任务中,RPE-ICM-DDPG智能体的平均回报对比其他三种算法提升了5%~173%。但本文研究也有一定的不足,奖励误差预测增加了神经网络,这增加了智能体的训练难度。在未来,为了减小网络训练难度,提升奖励预测好奇心模块的效果,可以使用经验池数据对RPE-ICM模型进行预训练,再通过迁移学习等方法将训练的好奇心模型结合深度强化学习算法进行学习。
)
[1] 刘全,翟建伟,章宗长,等. 深度强化学习综述[J]. 计算机学报, 2018, 41(1): 1-27.(LIU Q, ZHAI J W, ZHANG Z Z, et al. A survey on deep reinforcement learning[J]. Chinese Journal of Computers, 2018, 41(1): 1-27.)
[2] BELLEMARE M G, SRINIVASAN S, OSTROVSKI G, et al. Unifying count-based exploration and intrinsic motivation[C]// Proceedings of the 30th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2016: 1479-1487.
[3] PATHAK D, AGRAWAL P, EFROS A A, et al. Curiosity-driven exploration by self-supervised prediction[C]// Proceedings of the 34th International Conference on Machine Learning. New York: JMLR.org, 2017: 2778-2787.
[4] BURDA Y, EDWARDS H, STORKEY A, et al. Exploration by random network distillation[EB/OL]. (2018-10-30)[2021-02-21].https://arxiv.org/pdf/1810.12894.pdf.
[5] AGRAWAL P, NAIR A, ABBEEL P, et al. Learning to poke by poking: experiential learning of intuitive physics[C]// Proceedings of the 30th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2016:5092-5100.
[6] LILLICRAP T P, HUNT J J, PRITZEL A,et al. Continuous control with deep reinforcement learning[EB/OL]. (2019-07-05)[2021-02-21].https://arxiv.org/pdf/1509.02971.pdf.
[7] WATKINS C J C H. Learning from delayed rewards[D]. Cambridge: University of Cambridge, King’s College, 1989:44-46.
[8] GOODFELLOW I, BENGIO Y, COURVILLE A, et al. Deep Learning[M]. Cambridge: MIT Press, 2016:143-144.
[9] MNIH V, KAVUKCUOGLU K, SILVER D, et al. Playing Atari with deep reinforcement learning[EB/OL]. (2013-12-19)[2021-02-21].https://arxiv.org/pdf/1312.5602.pdf.
[10] SILVER D, LEVER G, HEESS N, et al. Deterministic policy gradient algorithms[C]// Proceedings of the 31st International Conference on Machine Learning. New York: JMLR.org, 2014: 387-395.
[11] SUTTON R S, McALLESTER D, SINGH S P, et al. Policy gradient methods for reinforcement learning with function approximation[C]// Proceedings of the 12th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 1999:1057-1063.
[12] KAKADE S. A natural policy gradient[C]// Proceedings of the 14th International Conference on Neural Information Processing Systems: Natural and Synthetic. Cambridge: MIT Press, 2001:1531-1538.
[13] 时圣苗,刘全. 采用分类经验回放的深度确定性策略梯度方法[J/OL]. 自动化学报. (2019-10-17)[2021-02-21]. https://kns.cnki.net/kcms/detail/detail.aspx?doi=10.16383/j.aas.c190406.(SHI S M, LIU Q. Deep deterministic policy gradient with classified experience replay[J/OL]. Acta Automatica Sinica. (2019-10-17)[2021-02-21]. https://kns.cnki.net/kcms/detail/detail.aspx?doi=10.16383/j.aas.c190406.)
[14] 杨瑞,严江鹏,李秀. 强化学习稀疏奖励算法研究——理论与实验[J].智能系统学报, 2020, 15(5):888-899.(YANG R, YAN J P, LI X. Survey of sparse reward algorithms in reinforcement learning - theory and experiment[J]. CAAI Transactions on Intelligent Systems, 2020, 15(5):888-899.)
[15] ACHIAM J, SASTRY S. Surprise-based intrinsic motivation for deep reinforcement learning[EB/OL]. (2017-03-06)[2021-02-21].https://arxiv.org/pdf/1703.01732.pdf.
[16] SCHMIDHUBER J. Formal theory of creativity, fun, and intrinsic motivation (1990-2010)[J]. IEEE Transactions on Autonomous Mental Development, 2010, 2(3): 230-247.
[17] BURDA Y, EDWARDS H, PATHAK D, et al. Large-scale study of curiosity-driven learning[EB/OL]. (2018-08-13)[2021-02-21].https://arxiv.org/pdf/1808.04355.pdf.
[18] SCHMIDHUBER J. A possibility for implementing curiosity and boredom in model-building neural controllers[C]// Proceedings of the 1st International Conference on Simulation of Adaptive Behavior: From Animals to Animats. Cambridge: MIT Press, 1991: 222-227.
[19] AGRAWAL P, CARREIRA J, MALIK J. Learning to see by moving[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 37-45.
[20] TAÏGA A A, FEDUS W, MACHADO M C, et al. On bonus based exploration methods in the arcade learning environment[EB/OL]. (2021-09-22)[2021-11-21].https://arxiv.org/pdf/2109.11052.pdf.
[21] SCHMIDHUBER J. Formal theory of creativity, fun, and intrinsic motivation [J]. IEEE Transactions on Autonomous Mental Development, 2010, 2(3): 230-247.
[22] TODOROV E, EREZ T, TASSA Y. MuJoCo: a physics engine for model-based control[C]// Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE, 2012: 5026-5033.
Intrinsic curiosity method based on reward prediction error
TAN Qing1, LI Hui1,2*, WU Haolin1, WANG Zhuang1, DENG Shuchao1
(1(),,610065,;2(),610065,)
Concerning the problem that when the state prediction error is directly used as the intrinsic curiosity reward, the reinforcement learning agent cannot effectively explore the environment in the task with low correlation between state novelty and reward, an Intrinsic Curiosity Module with Reward Prediction Error (RPE-ICM) was proposed. In RPE-ICM, the Reward Prediction Error Network (RPE-Network) model was used to learn and correct the state prediction error reward, and the output of the Reward Prediction Error (RPE) model was used as an intrinsic reward signal to balance over-exploration and under-exploration, so that the agent was able to explore the environment more effectively and use the reward to learn skills to achieve better learning effect. In different MuJoCo (Multi-Joint dynamics with Contact) environments, comparative experiments were conducted on RPE-ICM, Intrinsic Curiosity Module (ICM), Random Network Distillation (RND) and traditional Deep Deterministic Strategy Gradient (DDPG) algorithm. The results show that compared with traditional DDPG, ICM-DDPG and RND-DDPG, the DDPG algorithm based on RPE-ICM has the average performance improved by 13.85%, 13.34% and 20.80% respectively in Hopper environment.
reinforcement learning; exploration; intrinsic curiosity reward; state novelty; Deep Deterministic Policy Gradient (DDPG)
This work is partially supported by Army-Wide Equipment Pre-Research Project (31505550302).
TAN Qing, born in 1996, M. S. candidate. His research interests include deep reinforcement learning.
LI Hui, born in 1970, Ph. D., professor. His research interests include computational intelligence, battlefield simulation, virtual reality.
WU Haolin, born in 1990, Ph. D. candidate. His research interests include deep reinforcement learning.
WANG Zhuang, born in 1987, Ph. D. candidate. His research interests include military artificial intelligence, deep reinforcement learning.
DENG Shuchao, born in 1999. His research interests include deep reinforcement learning.
TP181
A
1001-9081(2022)06-1822-07
10.11772/j.issn.1001-9081.2021040552
2021⁃04⁃12;
2021⁃06⁃17;
2021⁃06⁃23。
武器装备预研基金资助项目(31505550302)。
谭庆(1996—),男,重庆人,硕士研究生,主要研究方向:深度强化学习;李辉(1970—),男,四川成都人,教授,博士,主要研究方向:计算智能、战场仿真、虚拟现实;吴昊霖(1990—),男,山东临沂人,博士研究生,主要研究方向:深度强化学习;王壮(1987—),男,吉林白城人,博士研究生,主要研究方向:军事人工智能、深度强化学习;邓书超(1999—),男,贵州绥阳人,主要研究方向:深度强化学习。
