布隆过滤器研究综述
2022-07-05华文镝高原吕萌谢平
华文镝,高原,吕萌,谢平*
布隆过滤器研究综述
华文镝1,2,3,4,高原1,2,3,4,吕萌1,2,3,4,谢平1,2,3,4*
(1.青海师范大学 计算机学院,西宁 810016; 2.青海省物联网重点实验室,西宁 810008; 3.省部共建藏语智能信息处理及应用国家重点实验室,西宁 810008; 4.高原科学与可持续发展研究院,西宁 810016)(*通信作者电子邮箱xieping@qhnu.edu.cn)
布隆过滤器(BF)是一种基于哈希策略的二进制向量数据结构,凭借分摊哈希碰撞的思想、存在单向误判性的特点以及极小常数查询时间复杂度,常用于表示集合元素并作为进行集合元素查询操作的“加速器”。作为计算机工程中解决集合元素查询问题最好的数学工具,BF在网络工程、存储系统、数据库、文件系统、分布式系统等领域得到了广泛的应用和发展。近几年来,为了适用于各种硬件环境和应用场景,BF出现了大量基于改变结构、优化算法等思想的变种方案。随着大数据时代的发展,对BF自身特点和操作逻辑进行改进已经成为现有集合元素查询研究的一个重要方向。
布隆过滤器;集合元素查询;近似成员查询结构;哈希策略;误判率
0 引言
集合元素查询,即查询一个元素是否属于某集合,是软件开发中一种非常常见的查询操作[1]。为了避免遍历整个集合、提高查询速度,常见的处理方法是把集合中所有元素的指纹(fingerprint)保存在一个哈希表中,查询时通过哈希映射来判断元素是否属于集合。但由于维护哈希表时不仅要存储元素的指纹,还要保存处理哈希碰撞而引入的其他结构(如使用链地址法需要存储额外若干个指针变量),所以使用哈希表的空间效率较低。当集合数据量较大时,哈希表无法保存在内存中,这就导致查询时需频繁往返于内存和二级存储之间,使得系统执行查询操作的消耗巨大。而在一些使用场景中,对于集合元素查询可以容忍一定的错误,这个特点促使产生了近似成员查询(Approximate Membership Query, AMQ)结构来估计性地回答这种交互式查询(interactive query)问题[2],布隆过滤器(Bloom Filter, BF)就是其中一个典型的代表。
BF使用一个位向量和若干个哈希映射函数,通过对元素指纹的哈希映射bit位置1来间接存储元素,并且不再处理映射过程中发生的哈希碰撞,从而使其能够保存在内存甚至cache中,同时解决了集合元素查询的查询时间和空间开销问题。但BF并不完美,还存在以下问题:
1)BF的位向量大小固定,无法改变,使用时只能对其中存储的元素个数进行预估计;并且一切相关性能参数都针对预估计的位向量,这使得在运行前期,BF对空间的利用并不高效;而且一旦元素个数超出预期就会导致性能大幅下降,甚至出现无法继续使用的情况。
2)虽然BF的空间开销小于哈希表,但一旦存储集合过大或应用场景对查询的准确性有较高要求时,对应的BF就无法完全存在于内存而需迁移至二级存储中,这会大大影响BF的查询效率,无法完全发挥出BF的最高性能。
3)BF本身就是一种牺牲查询准确率来换取空间效率的数据结构,因此在设计BF时需要在空间效率和查询准确率之间进行权衡,而这二者都是影响应用场景的重要因素,对此BF往往无法得到一个完美的解决方案。
4)由于BF使用哈希映射对集合元素进行间接存储表示,所以无法从其中获得查询元素的完整信息;而且有限大小的位向量使哈希映射必然存在碰撞,向量中的一位可能被映射多次,所以BF无法删除已经存储的元素。这样的特点在一定程度上限制了BF的应用场景。
经过研究和发展,目前出现了大量针对上述问题的优化方案和一些BF综述文章[3-4]。本文从了解每个方案的特点、梳理方案之间的关系、明确优化方案的适用场景等角度出发,对现有主流的优化方案进行综述。
1 标准布隆过滤器
1.1 结构组成和基本操作
标准BF的基本操作分为元素查找和元素插入。需要说明的是,在一些方案中除了插入操作外还有过滤器的构建操作,但只有那些不支持在运行途中进行元素插入,只能在集合完全静止的场景中使用元素插入的优化方案才需要区分插入和构建操作,而标准BF可以在系统运行途中进行插入操作,所以对BF的构建可以分为若干个元素的插入操作。为了突出少数优化方案的上述特点和简化标准BF的操作,本文只考虑查找和插入两种操作。

图1 标准BF结构
1.2 结构参数和性能表现
本文中BF及其改进的结构参数分为过滤器位向量大小、集合中的元素个数和哈希函数个数;性能指标包括:
1)元素查询性能:在过滤器中执行集合元素查询等查询操作的时间复杂度。
2)元素插入性能:元素插入到过滤器中的时间复杂度。
3)空间开销:过滤器中所有用于存储集合元素结构的大小总和,通常等于。
4)查询误判率(False Positive Rate, FPR):过滤器对于集合元素查询等查询操作做出错误判断的数量占总判断数量的比率。
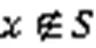
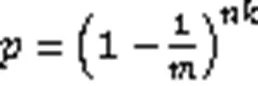

进而得到误判率的公式为


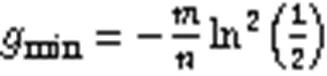
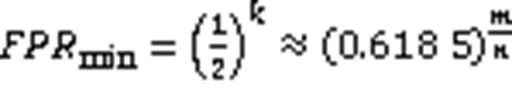
所以当位向量中一个位置为0和1的概率相同时,BF的误判率最低,此时哈希函数的个数是ln2倍位向量大小与集合元素个数的比值。
1.3 应用场景
由于BF使用哈希映射对元素进行存储表示,所以在使用时无需考虑存储元素的种类和大小,这也使得BF能够适用于大量的应用场景,成为计算机工程中解决“元素是否属于集合”问题最好的数学工具。1970年,BF被Bloom提出时用于断字程序(hypenation program),通过在BF中维护一个字典并使用一些简单的规则来实现[1]。在此之后,UNIX拼写检查[6-7]和不安全密码检测[8]中也出现了BF的身影。同时BF也被广泛应用于保存差异文件(Differential File)内容[9-10]和冰山查询(Iceberg Query)[11]等数据库领域,用于提升数据库查找和数据恢复的性能。进入21世纪,随着网络技术的发展和响应要求的提高,BF开始大量应用于网络应用[12]中并且取得了巨大的成功,如帮助重叠网络(Overlap Network)与点对点网络之间的协作[13-14]、对包中的组播转发信息进行编码[15]、在资源路由中使用概率算法来定位资源[16]、加速和简化路由协议来优化数据包路由[17]以及通过在路由器等网络设备中创建数据摘要(data summary)来对其进行评估和管理[18-19]等方面。
数据中心和存储系统也经常使用BF来检索内部数据和删除重复数据[20],如图2中利用BF来减少检索数据时对二级存储的访问。近些年来,一些非计算机工程的应用场景,如生物信息学中对于基因序列的分析[21]也开始使用BF对相关的操作进行优化。

图2 BF在存储系统的查询操作中的应用
2 拆分向量的布隆过滤器
BF最常见的优化思路是优化位向量,本章主要对使用拆分位向量的几种优化方案进行介绍。位向量的常见拆分方式分为分块和分层。由于哈希函数映射是随机的,在最坏的情况下,两个相邻哈希映射的位置距离等于过滤器位向量的大小。如果小于系统cache的大小就没有问题,但对于较大的数据集就需要大于cache的过滤器。随着过滤器的增大,cache的命中率会下降,cache中保存的BF就会频繁地换入换出,使操作成本逐渐增加[22]。虽然无法针对cache进行编程,但通过对过滤器进行拆分,使每次操作最多进行一次cache与内存之间的换入换出,依然可以优化BF的操作性能。
2.1 对向量分块
2.1.1 数据和规则的平等性
标准BF为了适用更多的应用场景,没有考虑数据和规则的平等性问题,而实际应用中,数据失效代价的不平等、数据热度的不平等和哈希映射之间的不平等都会影响过滤器的性能,而这些正是优化的入手点。本节将介绍以上述平等性问题为优化思想的三种优化方案。
在一些实际应用中,查询操作并非仅在过滤器中完成,如键值(Key-Value, KV)存储系统的查询操作,不仅需要在过滤器中判断键(Key)是否存在,对于存在的Key还需要寻找二级存储中保存的对应值(Value),如果查询发生误判,进入二级存储中寻找的操作将会是无效的,这个过程中的查询代价称为失效代价。失效代价甚至有可能大于在过滤器中查询所有集合元素的总开销,这就导致理论公式分析无法完美地体现在实际应用中。文献[23]中提出的分档式BF就以集合元素的不同失效代价为依据将集合划分成若干子集,为每个子集的过滤器分配不同个数的哈希函数,在元素插入和查找操作不变且不影响非误判的查询性能的前提下,失效代价高的数据子集对应的哈希函数相对较多,查询误判率也就较低;而相反情况的哈希函数相对较少,误判率也就较高。总结下来分档式BF能够在总体上降低查询代价达40%,应用在Web缓存和网络监控系统中会有非常好的效果。而对于每个子集具体的哈希函数个数,可以通过类目标函数梯度遗传算法[24]得到,具体细节由于篇幅有限,不再赘述。
文献[25]中提出的弹性BF则与分档式BF一样,同样关注使用BF的读取代价问题。弹性BF被设计用于LevelDB[26]、RocksDB[27]和PebblesDB[28]等KV数据库中,能够在保持写和范围查询性能不变的情况下,提升读取性能。在基于日志结构合并树(Log-Structured Merge-tree, LSM-tree)[29]的KV存储系统中通常存在一个矛盾,为了保证BF的查询误判率尽可能小,就要在内存中给BF分配更多的空间。当过滤器的体积过大而无法存在于内存时,就要将其保存在二级存储中。这样虽然实现了降低误判率的目标,但会带来“读放大”的问题,影响读取性能。而对于上述存储结构,一般认为LSM-tree中低层的数据会比高层的数据访问更加频繁,Monkey[30]也正是基于此给低层对应的BF每个元素分配更大的映射空间,但在实际应用中部分高层的数据要比低层的数据更加频繁地被访问;并且同一个SSTable中数据的热度也可能存在很大的差距,这也反映出Monkey对于每一层中所有过滤器使用相同配置的缺点。
如图3所示,弹性BF将一个SSTable中的数据区(data block)分解成若干分段(segment),针对每个分段分配一个过滤器组(filter group),而一个过滤器组中又包含若干个相互独立的小型过滤器,称为过滤器单元(filter unit)。虽然对每个分段创建的过滤器单元个数是一样的,但在系统运行时,系统会根据分段的热度把若干个对应的过滤器单元加载到内存中用于查询操作,而没有加载到内存的部分,则只在数据插入数据库时将数据映射其中,执行查询操作时并不查询它们,这样就间接地实现了“根据数据的不同热度分配不同大小过滤器”的目标,使其在不增大使用空间的情况下,降低了数据整体的查询误判率。弹性BF使用式(7)对数据热度进行度量:
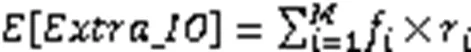

图3 弹性BF的结构组成
Fig. 3 Structure composition of elastic BF

2.1.2 基于固态硬盘的优化方案
BF的设计初衷是让其完全驻留在内存中,但如果系统的数据量过大并需要较低的误判率,且内存空间受限,就不得不把过滤器保存在二级存储介质中。由于磁盘的特征,将过滤器移植其中只会降低其平均运行性能,而不会出现太大的问题。随着固态硬盘(Solid State Disk, SSD)应用的普及,越来越多的二级存储介质选择使用SSD。SSD对页(page)读写和对块(block)擦除等特点使得把过滤器简单地移植到SSD中会造成大量的额外I/O,从而严重影响性能表现,因此出现了许多“分块+缓冲”的优化方案来适配SSD。


图4 缓冲BF结构
缓冲BF对于插入请求进行缓冲,让大量请求连续对一个SSD页进行操作,总体上减少了SSD的访问次数。但对查询操作也进行缓冲,虽然这不会增加过滤器的查询误判率,但会导致响应时间的增加。
文献[33]中的布隆Flash同样按照页的大小对BF进行分块,但在内存中只保存一个缓冲区且只记录元素的插入请求。查询和插入同样先确定对应的子过滤器,查询操作直接执行,而插入操作是以“页号,偏移量”(page_id, offset)且按前者进行分组的形式保存在缓冲区中,当缓冲区数据达到设定阈值时再把其中的数据插入到对应的子过滤器中,一个分组的所有操作全部在一次写操作中完成。执行插入的分组顺序分为两种:
1)最“脏”分组优先原则:优先执行插入请求数量最多的子过滤器,这种“贪心法”能够最小化SSD写操作的总数,但没有考虑按任意页的顺序进行写入可能导致的性能下降。
2)顺序执行原则:按照缓冲区分组中页的逻辑顺序进行插入操作,这种原则的优缺点与前者相反。
布隆Flash解决了缓冲BF查询响应时间过大等问题,且同样使用分块思想,相比标准BF,在SSD中有更高效的查询和插入性能。但布隆Flash的查询误判率为

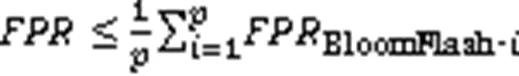
当且仅当每个子过滤器的误判率相等时,等号成立。虽然实验表明子过滤器中最多元素个数和最少元素个数的比值为1.1,但仍然可以说明布隆Flash的查询误判率要略高于标准BF。
上述两种针对SSD的BF优化方案都无法动态改变过滤器的大小,而文献[34]中的链式BF把SSD中的子过滤器使用链表结构相连,在内存中维护一个标准BF而不再是一个缓冲区,处理插入操作时,仍然像标准BF那样对内存中的过滤器进行操作,而当内存中过滤器保存的元素数量达到上限时,将该过滤器转移链接到SSD中的子过滤器链表中,然后在内存中重新构建一个标准BF,继续保存插入的元素。而当查询元素时,先查找位于内存中的过滤器,如果认定“元素属于集合”,则返回该结果;但如果得到的结果是“元素不属于集合”,则在SSD链表结构的每一个子过滤器中继续查找该元素,直到找到该元素或所有子过滤器中都不存在该元素,再返回相应结果。从查询和插入策略中可以看出,链式BF省略了缓冲请求信息的步骤,使得插入操作与标准BF一样高效,但其查找性能会大幅下降,虽然链式BF能够通过动态增加子过滤器让每个子过滤器的查询误判率低于某个设定的阈值,但在最坏的情况下,查询一个元素需要链式地遍历查找每一个子过滤器,并且查找过程中的查询误判率也是线性叠加的,因此链式BF更适合“多插入,少查询”的应用场景。
扩展型BF和快速BF也借助了拆分过滤器的思想,但它们本身还具备其他重要的改进,将分别在2.3节和2.4节中进行详细介绍。
2.2 对向量分层
2.2.1 基于SSD的优化方案
对于SSD作为二级存储介质的系统,虽然2.1节中介绍的对过滤器分块的方法可以很好地解决因SSD自身特点而带来的问题,但这些改进方案都存在同样的问题:由于缓冲区和过滤器之间大小尺寸的差距,这些改进方案在进行插入操作时,仍然会产生较多的页写入和块删除操作。文献[35]中提出的森林结构BF是一种应用于“重复数据删除”的优化方案,能解决上述的问题。重复数据删除的特点是查询操作和插入操作不再独立,如果查询数据不在集合中,则需要将该数据插入集合。对于集合中数据量的变化,森林结构BF可以动态地调节自身过滤器的大小,如果内存空间大小足以容纳表示集合中所有数据的过滤器,则系统直接在内存中维护一个标准BF;但如果集合数据量超出了内存的承受能力,则与其他SSD的优化方案一样,如图5,森林结构BF也将过滤器整体按页大小划分成子过滤器,而为了解决上述其他优化方案的共性问题,该方案把存储在一个数据块中的若干子过滤器认为是一个子过滤器块,并以其为非根节点构造树形结构。此时内存中的过滤器也写入SSD中作为树形结构的根节点,而空闲出的内存空间则当作缓冲区使用,这一点也与2.1节中几种优化方案一致。
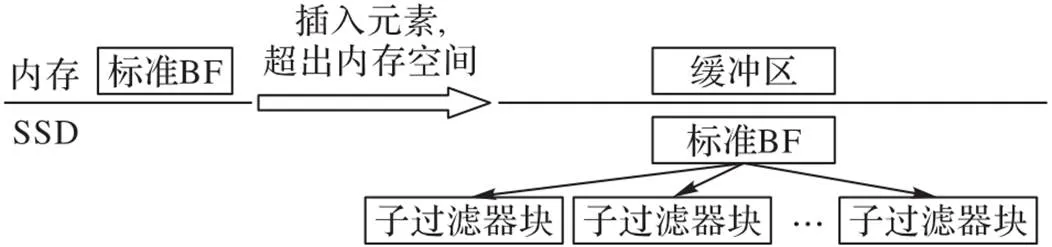
图5 森林结构BF的结构变化
2.2.2 分支路径的唯一性
文献[36]中的布隆树是一棵叉完全树,它的每个节点都是一个标准BF,主要解决多集合成员查询问题。一个系统中存在多个集合,每一个集合都有其自身的过滤器,当请求查询一个Key对应的Value时,检查所有过滤器,如果该Key属于其中一个集合,则返回该集合中该Key所对应的Value,这就是多集合成员查询问题[37]。如数据包的分类与转发,交换机和路由器都维持有转发表,当学习一个新的表项时,转发表会记录新表项中的数据,把目的IP地址和流标签的信息视作Key,而将其转发接口(outgoing interface)视为Key对应的Value存储在对应接口的过滤器中。这样每一个转发接口都对应一个过滤器,当后续数据包到达时,交换机和路由器根据包中信息查找所有过滤器,并按照查到的对应值(转发接口)把包转发出去。布隆树的每一个叶节点都隐含地对应着一个值,值的取值个数就是叶节点数,因此从根节点到不同值的路径也是不同的,每一个节点都对应着个哈希函数集合,每个集合包含若干个独立的哈希函数,树中相同层上每个集合的函数个数相同。而由于叶节点对应过滤器的含义是“该Key是否对应这个叶节点隐含的Value”,所以只需一个哈希函数集合。针对每一个KV,将Key按照Value的路径选取对应的哈希函数集,映射到这个路径经过的每一个BF节点中。查找时,从根节点开始使用每一个哈希函数集合映射检查Key的存在,如果结果返回“真”,则根据返回“真”的对应路径继续寻找,直到根节点过滤器返回结果,如果返回“真”,就可以得到该Key对应的Value,即该根节点的隐含Value;如果根节点过滤器返回“假”或路径中的非叶节点所有哈希函数集合的映射检查结果都为“假”,则说明该Key不属于集合。查询中布隆树可能出现两种误判的情况:
1)对于不属于集合的Key,返回了一个对应的Value,这种误判率与普通BF的查询误判本质相同;
2)对于一个Key(无论是否属于集合),查询出了多个对应的Value,无法确定哪个Value是正确的,这称为分类错误(classification failure)。
由于过滤器自身的树形结构,父节点中产生的误判可能通过在其子节点的判断中纠正过来,所以在实际应用中查询误判率不会增加;而且布隆树能够在相同的空间中比标准BF多存储127%的数据,并将查找性能提升37.5%左右;此外,布隆树还能通过“把路径引入Key中来减少哈希函数个数”“对值进行‘或’运算使映射更加均匀化”和“并行访问来缩短访问时间”的方法对其做进一步的优化。
2.2.3 优化范围查询
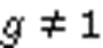
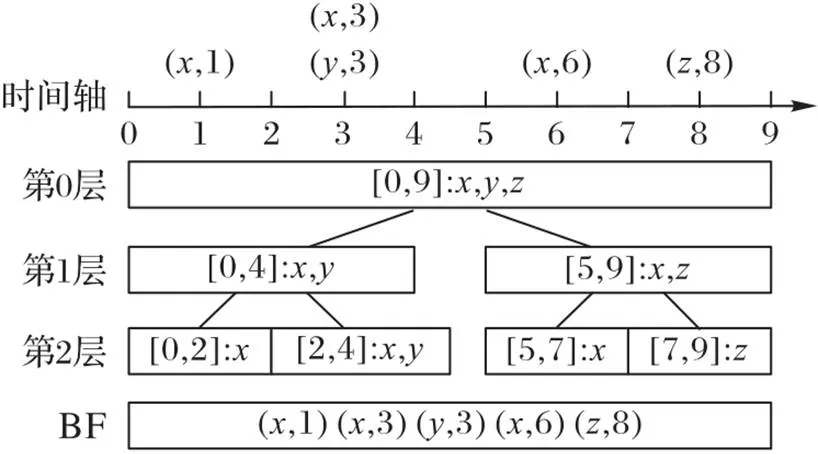
图6 Ⅰ型过滤器结构


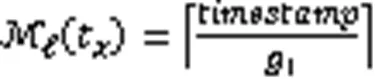
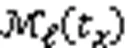

其中:表示Ⅱ型过滤器的层数;FPR表示第层BF的查询误判率。Ⅱ型过滤器的动态策略是当系统时间达到阈值时,重新创建一个BF作为第0层,原有过滤器的层数均加1。这样后续时间的元素就可以继续插入了。
持久型BF成功将时间范围查询减低到了对数级别,并且由于应用场景的特殊性,过滤器无需支持删除操作。而文献[39]中的罗塞塔(Rosetta)则是在不影响普通成员资格查询操作性能的前提下,优化了KV存储系统的范围查询问题,把RocksDB中的范围查询性能提升了近40倍。它使用了目前该问题最先进的前缀BF[38]和SuRF[40]所使用的“前缀技术”,即存储和查询集合元素的前缀来优化解决范围查询问题。但在存储系统的范围查询中,对于较小范围查询的结果有很大的可能为空(范围中根本不存在元素)。当这种情况发生时,上述的两种方法会造成大量的负载,而Rosetta可以很好地解决这个问题。一个Rosetta实例针对LSM‑tree中的一个持久性系列()为集合而创建,其树形结构的层数与集合中元素前缀位数的最大值相同,每一层仍是一个标准BF,系统把集合中所有长度为的前缀通过哈希映射的方式插入到第层的过滤器中,就可以将Rosetta看成一个隐式的线段树。在执行范围查询时,先将查询范围进行划分,在树形结构中找到能正好覆盖它们的前缀节点(这些节点很可能不在同一层中),如查询范围是[12,14],其对应的二进制为1100、1101和1110,前缀110和1110就可以正好覆盖。然后使用标准BF的查询操作在对应层中查询这些前缀,如果查找的前缀节点不在最后一层,且查询结果为“真”,则需要向隐式线段树中其孩子节点继续递归查询,查询途中一旦递归查询结果返回“假”,则说明以该节点表示前缀的元素不存在,只有递归查询一直到最后一层仍为“真”,才说明对应表示的元素属于集合,也就可以说明在总查询范围中存在该元素。而如果找到的范围覆盖在最后一层或不在最后一层但结果为“假”,则无需继续查询。前者的查询结果直接表示对应元素是否存在,而后者直接说明集合中不存在以该节点表示为前缀的元素。这样如果查询的范围为空,则可以很快地在上层节点中被知晓,从而避免过大的负载。而普通的成员资格查询直接在最后一层BF中就可完成,因为最后一层中插入的元素前缀就是元素本身。
由于一个Rosetta只针对一个持久性系列且一个系列中元素Key的取值范围不同,所以导致存储系统中每个Rosetta都不一样,这就使系统可以对每个Rosetta进行“定制”,如根据数据的热度为较热的Rosetta分配更大的空间,以降低其查询误判率,或对于KV范围较小的系列只设定单层BF等操作。并且由于LSM-tree的合并操作,一个Rosetta实例的生命周期不会太长,会因为旧数据的合并而回收并重新构造,这也反过来为Rosetta的定制提供了方便。
总结来说,将过滤器分层更多地是利用层次结构层数是节点个数对数级的特点来对原始方案进行优化,除了上述的这些优化方案,还有许多对过滤器分层的方案,如多层压缩BF,详细介绍见4.1节。
3 改进结构的布隆过滤器
第2章中介绍的优化方案仅仅是对过滤器进行了结构上的拆分,并没有改变过滤器的本质,这导致这些优化方案只是改变了BF的操作逻辑,并没有改变具体操作过滤器的步骤和方法,也就只针对特定的应用场景优化了相关的一些性能参数。本章将介绍5个改进结构的过滤器优化方案,它们从本质上改进了BF的结构,包括过滤器向量类型、过滤器扩展策略和哈希映射范围。
3.1 计数型布隆过滤器
本文在开头中提到,BF无法支持删除的缺点,而在实际应用中存在大量可以使用BF对其查询性能进行优化且同样对删除元素存在需求的应用场景,比如对于数据仓库来说,维持一个数据的滑动窗口(sliding window)需要一种支持删除操作的BF来优化其性能。流数据(streaming data)中通常只使用当前一小时或一天的数据,如果采用支持删除操作的BF,其性能表现将进一步提高[39]。
虽然计数型BF能够对元素计数,但是其向量中的每一个计数器都存在相同的上限,如果集合中相同的元素过多或哈希碰撞频繁就会导致计数器溢出,从而影响查询操作,导致把本属于集合的元素判断成不属于,这就破坏了BF的“单向误判性”。而如果分配向量每一位的位数过多,就会导致空间上的浪费,根据坛子模型(urn model)和对实际应用情况的统计,4 bit是一个适用于大多数使用场景的选择。计数型BF简单地更改了向量的类型就在不降低过滤器操作性能的基础上增加了删除操作,并且由于如负载平衡、缓存、路由和差异化服务等众多应用领域和场景对删除元素的操作存在需求,计数型BF取得了重大的成功,Facebook的分布式存储系统Cassandra[42]、Chrome浏览器[43]以及谷歌公司的数据库系统BigTable[44]等产品中都有计数型BF的身影,它甚至成为了标准BF的替代品和BF改进基础,大量的改进方案都在计数型BF基础上进行。
3.2 谱型布隆过滤器
计数型BF把位向量扩展成了计数器向量从而支持了元素删除操作,但是从计数器中的映射次数还可以挖掘出更多的信息。在一些数据流应用中,需要查询的不是一个元素是否属于集合,而是查询该元素在集中的个数。文献[45]中提出的谱型(spectral)布隆过滤器是一种基于计数型BF的改进方案,通过对计数器中数据进行分析,使其支持查询元素个数的操作。也正是如此,该过滤器能够过滤出某个范围(spectrum)中重复出现的元素,因而得名谱型布隆过滤器(谱型BF)。
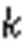
除了支持元素个数的查询,谱型BF还利用索引机制使计数器能够动态伸缩,更加高效地利用空间。谱型BF中所有计数器需要的最少位数为
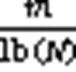
除此之外,谱型BF对元素个数查询还有两个算法上的优化:
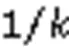
3.3 动态计数型过滤器
如图7,CBFV的每一项都是一个普通的计数型BF的计数器,大小固定为

其中:为起始状态下集合中的元素总数,为起始状态下集合中不同元素的个数。所以
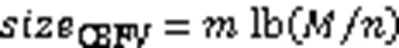
OFV的每一项是一个动态变化且同时变化的计数器,顾名思义用来处理前者对应计数器的溢出,所以映射次数的最大值决定了溢出计数器向量的大小:

元素插入或删除时,先修改CBFV中哈希映射位置对应的计数器,如果计数器之前已经达到最大值或最小值,则会发生上溢或下溢现象,这时先调节CBFV中对应的溢出计数器,再向OFV中的对应计数器进行加1或减1操作即可。如果OFV的对应计数器之前同样达到了最大值或最小值,就先对OFV中的每一个计数器扩展一位(如果删除后,所有计数器的最高位都为0,就缩小一位),再修改这个对应的计数器。这种计数器向量的扩展和缩小称为重建,其开销很大,必须创建一个新OFV,然后把旧OFV的值拷贝到新OFV中,最后释放旧OFV的空间。所以不像插入元素时必须重建,删除操作可以不立即重建,而是等待一定时间或达到一定阈值后再重建,这样既减少了删除操作重建的次数,同时也能避免一些插入时的重建请求。

图7 动态计数型过滤器的结构
3.4 扩展型布隆过滤器
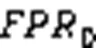

当执行查询操作时,扩展型BF先从最新创建的过滤器开始查找,查找方法与标准BF相同,如果找到元素则返回“元素属于集合”,否则到次新创建的过滤器中继续查找,直到找到该元素并返回“真”,如果查找0仍没找到该元素,则返回“元素不属于集合”。而对于插入操作,首先判断此前最新创建的过滤器其存储能力是否已经达到了上限,如果已经达到上限,则按照规则创建一个新的过滤器,并按照与标准BF相同的方式把元素插入到该过滤器中;但如果该扩展型BF并没有达到存储上限,则直接把元素插入到最新创建的过滤器中即可。

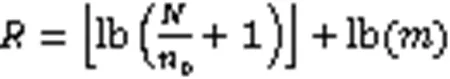

3.5 快速布隆过滤器
现代高端路由器和防火墙主要在硬件上实现它们对于每个数据包的操作,这使其能够在几个时钟周期内转发每个数据包。为了适应如此高的吞吐量,许多涉及数据包处理的网络功能也必须在硬件中实现,而在内存中的BF无法实现这样巨大的吞吐量。文献[49]中的快速BF就是一种优化不同BF访问性能的改进方案。
标准BF的哈希映射是全局的,哈希映射每个元素需要访问内存中的次数不同。机器字是处理器和内存之间的传送单位,快速BF的核心思想是限制一个元素的哈希映射范围为若干个机器字长,使处理器对一个元素的查询更快速地进行。普通BF要映射一个元素,通常需要的数据大小为
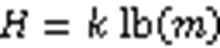

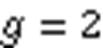
3.6 性能对比及分析
以上5种改进方案都针对过滤器的结构本身进行了改进。谱型BF和动态计数型过滤器都是在计数型BF基础上进行了改进,二者都消除了计数器溢出的问题。计数型BF由于仅把比特位变成计数器,所以只在空间使用上是普通BF的计数器位数倍,其他性能没有改变。而谱型BF和动态计数型过滤器为了动态改变计数器位数进一步增加了空间的使用,在计数器数值普遍不大的情况下,动态计数型过滤器由于不用维护复杂的索引结构,使用空间比谱型BF要少。如果将计数器数值逐渐增大,谱型BF在空间占用上的优势就会越来越明显。在查询性能上,二者都有所下降,动态计数型过滤器比计数型过滤器在查询时多访问一次内存,而谱型BF在普通查询时最多要进行5次内存的访问。在重构方面,由于谱型BF的重构仅仅针对一个计数器,而动态计数型过滤器是针对所有计数器,所以谱型BF的重构频率更高,插入和删除元素的性能也就更差;但谱型BF支持了元素个数的查询操作,并使用改进的算法使其误判率比普通查询的误判率还小。
不同于以上两种方案,扩展型BF和快速BF是针对普通BF的改进方案。前者牺牲查询性能为原来的对数倍而适用于集合元素动态变化的场景,并保持元素插入性能不变;而后者通过限制元素的映射范围提高了查询操作的性能,但在其应用场景中数据集必须是静态的,在一开始就要构建好整个过滤器,并且不能在系统的运行过程中插入元素。扩展型BF和快速BF对于扩展性和限制哈希映射区域的优化在本文前面介绍的几种优化方案中已有所提及,但之前的方案都不是将此作为优化的重点,只是为了优化其他方面而被动地进行扩展和限制映射,所以采用了最简单方便的方法。而3.4节和3.5节中的两个过滤器均采用了动态变化的扩展方案和映射策略,主动对扩展性和映射性能进行优化。另外,这二者的改进思想很容易移植到计数型BF上,从而使其支持元素删除操作,应用到更多的领域中。

表1 几种基于计数型BF改进结构方案的对比

表2 几种基于普通BF改进结构方案的对比
4 优化哈希策略的布隆过滤器
哈希函数作为BF的重要组成部分,使集合元素以存储空间效率极高的方式存储在过滤器中,并且哈希函数还可以统一集合元素的数据类型和长度,无论是长短字符串还是大小数值,通过哈希函数计算都可以变成类型大小相同的数据,从而便于查询和管理。在BF中,哈希函数的输出值通常有两种用途:
1)用作地址:在位向量表中存储一个元素,使用哈希函数生成若干个存储的随机地址。
2)用作元素的指纹:当BF存储的集合元素之间数据类型不一致时,通常先对元素进行一次哈希运算得到该元素的指纹,然后对该元素的指纹再利用上述的第一种用途保存在过滤器中。这既保证了BF存储数据类型的多样性,也实现了存储一致性。
但是没有哈希函数是完全随机的,只要映射范围是有限的,就一定会存在碰撞的可能。并且一个普通哈希函数的输出服从泊松(Poisson)分布,而BF中的个哈希函数之间相互独立,所以依然服从泊松分布[41]。在实际应用中哈希映射的位向量位置是不均匀的,这会使碰撞率变得更大,进而增加误判率,所以就出现了一些针对降低碰撞率和均匀分布的BF改进方案。
4.1 “完美”哈希
文献[50]中提出的Bloomier过滤器使用了一种“完美”哈希(perfect hash)策略,在普通哈希映射之后对映射结果进行统计和调整,让集合中每一个元素的映射位置结果不同,从而实现无碰撞的元素存储。另外,标准BF的查询操作仅仅回答了“元素是否属于集合”,而Bloomier过滤器能存储一个较小值域下的函数值,也就是KV中的Value,可以通过Key快速地找到对应的Value。所以从某种意义上来说,Bloomier过滤器不仅仅是一个过滤器,还是一个存储结构。但由于需要在计算哈希映射之后对映射结果进行统计和调整,Bloomier过滤器仅适用于静态集合,过滤器一旦建立结束就不能再向其中插入或删除元素。
Bloomier过滤器构建操作就是利用“完美”哈希策略插入所有集合元素的过程。它使用贪心思想来对元素映射:分析每个元素所有可能的映射位置,每次找出具有不与任何其他元素存在映射碰撞的元素,并把其独一无二的映射位置作为其插入位置,记录完所有元素的插入位置后,按倒序把值插入到过滤器中。但问题在于元素查询时无法确定哪一个映射位置为该元素的插入位置,所以Bloomier过滤器在元素插入时对值、所有可能映射位置的过滤器值和一个用于降低查询误判率的额外哈希值进行“异或”操作后进行存储,

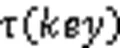

但如果执行的是元素成员资格查询,还需判断反向异或结果是否包含于值函数的值域,如果“包含于”则说明元素属于集合,否则不属于集合。Bloomier过滤器虽然使元素的映射位置不再有碰撞产生,但由于Key与Value之间的映射仍有可能存在碰撞(不属于集合的Key也能映射出合法的Value),所以查询操作依然存在误判率。
虽然不支持插入和删除操作,但Bloomier过滤器通过建立两个过滤器可以允许修改(update)元素的值。二者中的一个过滤器用于存储另一个过滤器中Key对应Value的存储位置:
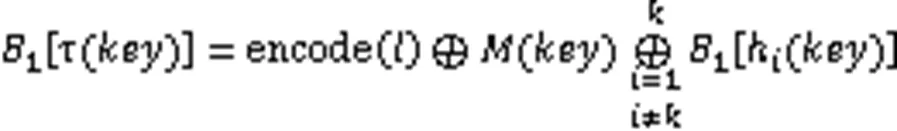
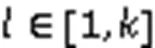

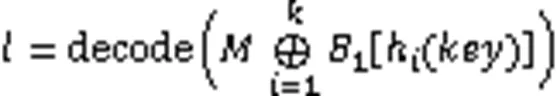
由于Bloomier过滤器直接对值进行存储,所以过滤器不是位向量,而是一个存储值的空间,并且其可以直接获取到Key对应的Value,所以对比标准BF的空间使用也就没有什么意义。因为它存储元素的特性,Bloomier过滤器特别适合作为存储系统中的缓存,让其存在于内存中并存储一些系统中的热数据,在查询它们时无需进入二级存储介质中,直接在内存即可完成,这样能大大缩短了查找时间,但缺点是在删除其中数据时或每隔一段时间需要对过滤器进行一次重构。
4.2 d‑left哈希
对于静态集合来说,“完美”哈希策略无疑是一个不错的选择,可以实现本质上的最佳性能。但一旦集合变为动态,即涉及插入和删除操作,如果仍然使用“完美”哈希策略,就需要对过滤器进行频繁的重构,反而降低了性能。‑left哈希是一种遵循“Always-Go-Left”原则[51]而映射均匀的哈希策略,提升了过滤器的空间使用效率。其根本思想是将哈希表平均分为个子表,对于每一个插入元素使用哈希函数提供其在每一个子表中的相关映射位置(这些位置是相互独立的),选择存储元素个数最少的子表进行插入,如果多个子表都是最少元素则存储在其中最左侧的子表中,从而实现元素的均匀插入。

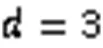
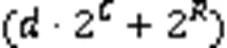
4.3 哈希表
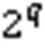
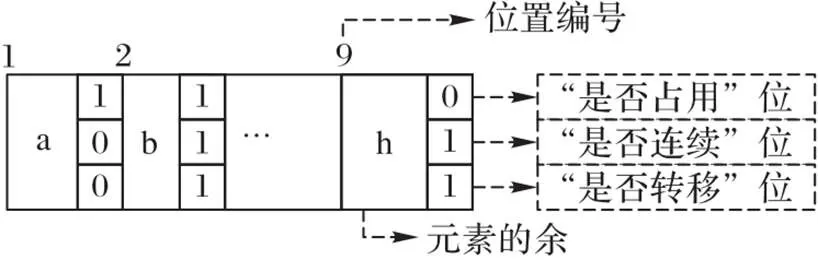
图8 商型过滤器的存储单元
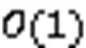
元素插入与查询操作相似,需要说明的是,找到元素所在系列后,商型过滤器按照元素余的大小顺序进行存储,当插入位置已存在元素则按照“插入排序”的规则,把已存在元素及其之后的元素向后移动,再插入元素并调整相关的信息位。不难理解商型过滤器同样支持删除操作,与插入操作相反,元素删除后,将其后面的元素向前移动并调整相关的信息位即可。
商型过滤器仅仅比标准BF的使用空间大20%,但支持删除操作,这远远优于计数型BF,但大量移动元素和修改信息位的操作使元素插入和删除的性能不如计数型BF;并且由于元素是按照大小顺序存储的,所以商型过滤器可以在不需要进行元素重哈希(re-hash)的情况下通过类似于“合并排序”的操作对两个过滤器进行合并,也就间接地使商型过滤器能够动态调节其大小。这种便于合并且自身有序的特点使商型过滤器特别适合用在基于LSM-tree的KV存储系统中,优化存储系统中元素查询的效率。
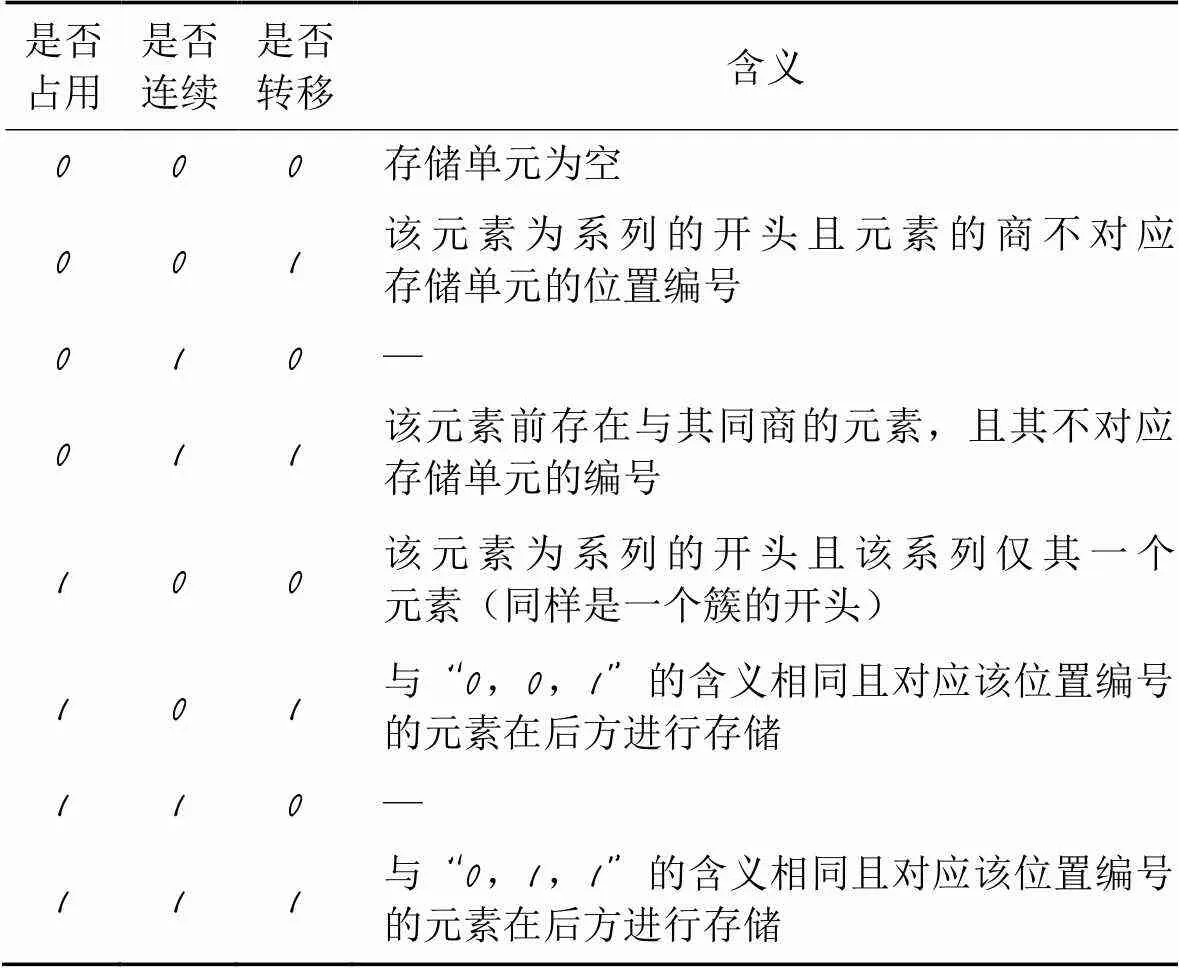
表3 三个信息位所有可能情况的含义
商型过滤器还产生了两种针对SSD优化的变种:缓存型商过滤器和瀑布过滤器。与2.1.2节中对于SSD优化的方案类似,缓存型商过滤器分别在内存和SSD中各创建了一个商型过滤器,当缓存型商过滤器中的元素达到系统设定查询误判率下个数的上限时,将其中的元素依次插入到SSD商型过滤器中,再从缓存型商过滤器中删除它们;而瀑布过滤器则是像瀑布一样,当内存商型过滤器“满”时,将其与SSD商型过滤器合并保存在SSD中,而内存中则再重新创建一个商型过滤器。这两个变种都在不影响查询误判率的情况下,对SSD的特殊结构特点更加友好。
4.4 布谷鸟哈希


图9 Cuckoo哈希的元素插入操作
文献[57]中的布谷鸟过滤器(Cuckoo Filter, CF)则是一种基于布谷鸟哈希的过滤器,它在空间使用、操作性能和实现难易方面都由于大部分的BF改进方案。CF的每一个位置都允许存储固定数量的元素,并且与‑left计数型BF一样存储元素的指纹。但由于使用哈希函数计算元素指纹是一个单向操作,所以无法针对过滤器中的某一指纹计算其对应元素的两个映射位置。CF对此采用的方法是部分关键Cuckoo哈希(partial-key Cuckoo hashing)[58],对于每个指纹仅使用一个哈希函数计算一个映射位置:
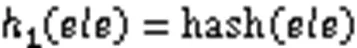
而另一个映射位置通过对式(27)的结果进一步计算得出:
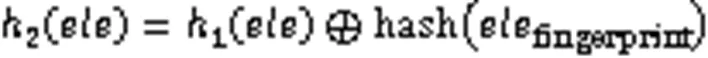
以上三种优化方案,除了都针对哈希策略进行了优化外,还改变了过滤器的存储内容。表4是它们之间存储内容及各项性能指标的对比情况,这些修改方案的过滤器不再存储bit位或是过滤器位置被映射的次数,而是存储插入到该位置元素的指纹(‑left哈希计数型BF存储的是元素指纹和计数器),目的是统一插入元素的数据格式使其适用更多的应用场景。
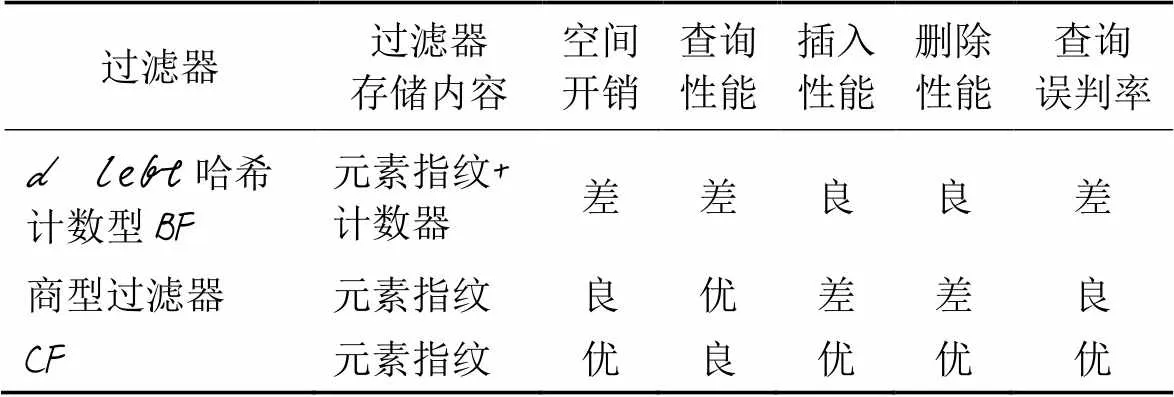
表4 三种优化方案的对比
4.5 可变增量哈希

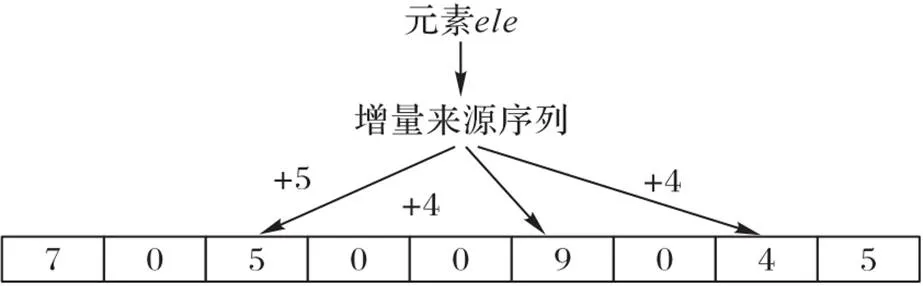
图10 插入元素到可变增量计数型BF中
5 其他改进方案
5.1 结构压缩
对于分布式系统来说,BF常需要作为信息在系统网络中进行传输,其中处理联接(join)是一个重要的应用。布隆联接(Bloomjoin)是一种基于BF应用联接问题的策略[62],设需要通过属性来连接关系和,BF是指把.存储在一个BF中然后传输给关系,再针对这个BF过滤出集合中不关于该联接的部分,并把剩余部分当作结果传回关系来完成联接请求。这样大幅减少了分布式系统中各节点之间通信所传输的信息量。而如果能减少系统中节点之间的交互次数和交互过程中的信息量就可以大幅改善整个系统的运行性能,结构压缩的BF对于这种应用场景无疑是友好的。
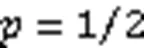

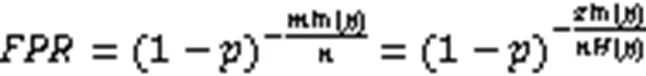
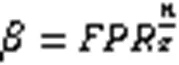
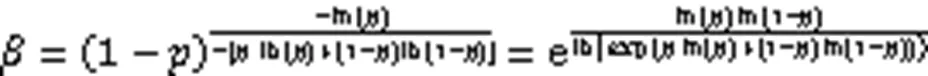

对式(32)求导得:
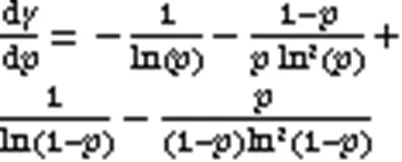
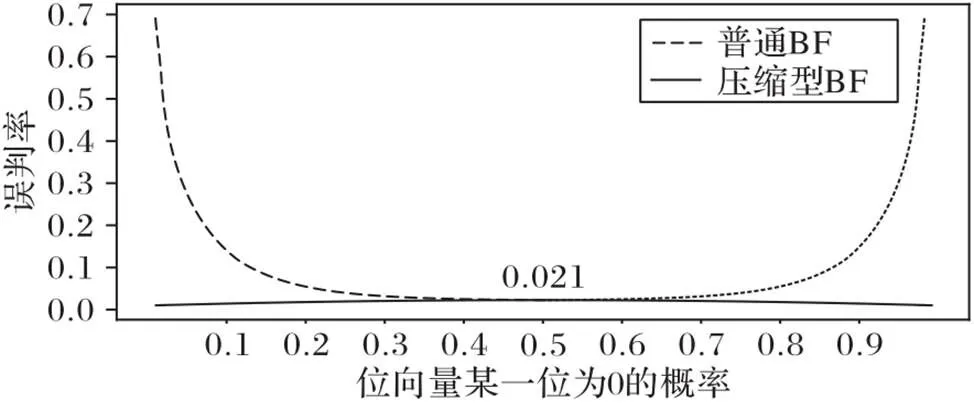
图11 普通BF和压缩型BF的误判率变化
BF的压缩不仅体现在过滤器大小上,对于计数型BF来说,可以对计数器中的数据进行压缩降低溢出的可能性,或在设计上减少计数器的位数,从而减少计数器的空间使用。文献[63]中的哈夫曼编码(Huffman Coding)计数型BF就是对过滤器中内容进行哈夫曼编码的一种优化方案,由于哈夫曼编码能够将集合中元素的编码数据量降到最低,所以相较于计数型BF节省了近50%的内存空间。观察结果表明,如图12,当对计数型BF的计数器数值编码时,一个数值的哈夫曼编码长度等于该数值加1,即
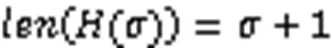
这样的优化方案看似把计数型BF的空间压缩到了最小,但方案中的松弛位和查询表则是从侧面增大了过滤器的使用空间。多层压缩BF[63]在哈夫曼编码计数型BF的基础上使用了多层结构解决了上述的问题。2.2节中介绍的几种对过滤器分层方案虽然把一维的过滤器扩展成了二维结构,但每一层中过滤器依然是一维的;而多层压缩BF把计数器中的数值进行跨层存储,即从最底层开始向上每一层都存储计数器数值中的一位,并且由于存储的是哈夫曼编码,是二进制数,所以每层中保存的只是标准过滤器。当需要计数器具体数值时可以通过一定的规则来获取每层中计数器的对应数据。
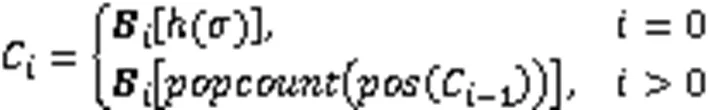
除了上述两种结构压缩方案之外,谱型BF在作为数据进行传输时,也可以使用以利亚加玛码(Elias Gamma Code)对其进行压缩以减少传输数据的大小[45]。
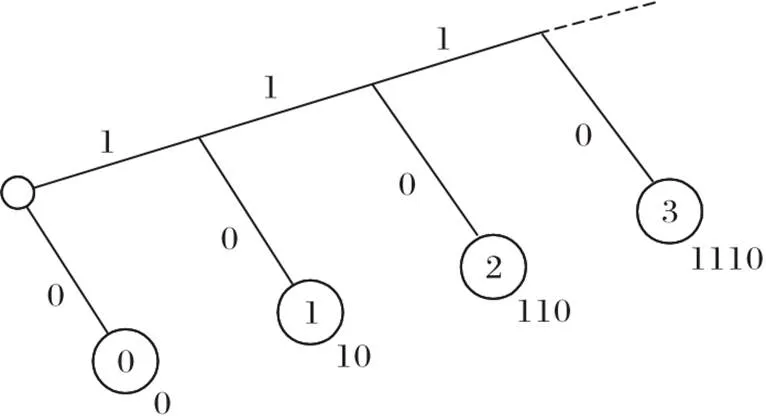
图12 根据计数器值构建的哈夫曼树
5.2 值存储
在一些使用场景中,存储元素的取值范围很小,这就使得可以在BF中直接存储元素的值。4.1节中的Bloomier过滤器就是一种直接将值保存在过滤器中的改进方案,2.2节中的布隆树则是让其树形结构的叶子节点个数与值的种类个数相同,从而间接地用叶子节点来表示元素的值。文献[64]中提出的状态BF顾名思义是针对状态应用场景的BF,这里的状态是指网络中的并发状态机(Concurrent State Machine),将状态BF用作近似并发状态机(Approximate Concurrent State Machine),即近似估计网络中大量数据流的状态,从而用于视频流量控制(video congestion control)和入侵检测(intrusion detection)等方面。
网络中的数据流提供流标签和状态字符串的KV(flow-id, state string)来记录网络中流状态的变化,状态BF类似于计数型BF和Bloomier过滤器的结合,对每个流元素仍然使用个哈希函数映射到过滤器中。过滤器的每一个存储单元包括一个用于存储状态值的空间和一个计数器,这样就可以直接修改存储的状态值,而不必执行“删除旧元素后重新插入新元素”来对元素进行修改。与标准BF不同的是,状态BF不具有单向误判性,有多种误判的可能:
1)查询一个不存在的流时,过滤器返回一个有效的状态值;
2)查询一个存在的流时,过滤器无法找到其对应的状态值;
3)查询一个存在的流时,过滤器返回了一个错误的状态值。
而状态BF此外又引入了一个全新的状态值,当映射位置出现冲突时,对应位置存储的状态值改为“不知道(Don’t Know, DK)”。在必要时,查询结果返回DK,就可以减小上述三种误判产生的不良影响。这样对应的过滤器操作也会发生变化:
1)插入流元素时:如果映射位置的计数器值为0,则写入该元素的状态值,并更新计数器值为1;如果映射位置的状态值为DK或与插入元素的状态值相等,就让计数器的值原地加1;而如果映射位置的状态值不等于插入元素的状态值,则将映射位置的状态值改为DK,并增加计数器的值。
2)修改流元素时:先看映射位置的状态值是否为DK,如果是,则无法修改;否则如果映射位置的计数器值为1,就直接修改其存储状态值,但如果计数器值超过1,则只能把映射位置的状态值改成DK。
3)删除流元素时:如果映射位置的计数器值为1,则将其置为0,并擦除原本保存的状态值;否则在计数器数值减1的基础上,把映射位置的状态值改为DK。
4)对于流元素的查询,需要检查所有映射位置的状态值:如果全部为DK,则返回DK;而如果检查到的状态值有和DK两种结果,则返回;其他情况说明该流元素根本不属于集合。
此外,状态BF通过使用标志位和一个全局的计数器实现了“删除过滤器中超时流元素”的功能,并且还能搭配“存储元素指纹”和“‑left哈希策略”使其适用于Blooimer过滤器无法胜任的动态场景中。
6 改进方案的分析与讨论
BF自1970年提出至今,据不完全统计,已经出现了超过60种的优化和变形[65],近几年还有如堆栈过滤器[66]、Chucky[67]等优化方案不断地出现。表5对本文提到的25种现有典型BF优化方案和标准BF从查询性能、插入性能、空间使用和误判率四个通用性能指标,以及使用场景共5个方面进行了对比分析和总结,其中:√表示对此性能优化,×表示牺牲此性能,—表示此性能没有改变或无法比较。这些改进方案大多数是针对一个特定的应用场景提出的,所以没有最好最坏之分;但有些改进方案如计数型BF是标准BF的通用替代品,‑left哈希计数型BF和CF是计数型BF的标准替代品。所有改进方案中使用一种以上优化思想的有扩展型BF和快速BF,它们在改进过滤器结构的基础上继续对过滤器进行拆分;瀑布过滤器则对多个哈希表进行合并,让商型过滤器对SSD结构更加友好。
对结构进行拆分是本文所介绍的优化思想中最简单的一种,而不管对过滤器是分块还是分层,都有以下两点原因:第一,让过滤器充分考虑或者借助数据或规则的平等性,对不同的集合元素进行“定制化”使其更加适合集合元素的某些特点,从而在整体上提高过滤器的性能;第二,拆分过滤器缩小整个过滤器的尺寸,让其适用于新型存储介质 SSD的结构特点,减少多余的写入和擦除操作。

表5 布隆过滤器改进方案对比
对结构进行改进的思想一般是给BF增加功能或在原有改进的基础上继续进行挖掘优化。计数型BF增加了删除元素操作,谱型BF和动态计数型过滤器让计数型BF大小收缩,使其结构更加灵活,并且谱型BF继续挖掘出了更多计数器的含义,进而增加了多重集中查询元素个数的操作。扩展型和快速BF在普通扩展和减少I/O访问方案的基础上对结构改进,进一步优化了扩展和减少I/O的性能。
大多数对BF的改进都是着眼于如何优化过滤器,对于哈希策略的优化是优化BF的另一个方向,其实质是改进BF的操作逻辑。并且大多数的哈希策略不会针对某个特定的应用场景,一旦某个哈希策略能够优化标准BF的性能,就能应用在绝大多数的场景中。在本文提到的哈希策略中,“完美哈希”集合完全避免了哈希碰撞,但需要对元素进行预处理并且无法支持动态的集合;‑left哈希和Cuckoo哈希都是让元素均匀映射在过滤器中,减少过滤器空间的浪费,但‑left需要对删除元素进行特定的操作,而CF虽然在查询和删除操作上的性能出众,但在元素插入时容易由于哈希碰撞而转移大量无关元素的位置,造成性能浪费;可变增量计数型BF借助特殊序列的特殊性质,让过滤器的每个计数器在较小映射次数时不再有查询误判,但一旦映射次数超过特定值,查询误判就会重新存在,并且对计数器每次做不同增量的操作使得计数器更容易溢出。
对于结构压缩和值存储两方面优化,因受具体应用场景的影响很大,所以只有少量的改进方案。作为一个经典的优化方案,压缩BF使用现有的压缩技术对过滤器进行压缩,优化了比较棘手的不同系统间的通信问题,并从理论上证明了这种结构上的压缩不仅可以减少空间的使用,还能降低过滤器的查询误判率。多层压缩BF使用哈夫曼编码和分层思想既减少了计数器值的数据量也从理论上消除了计数器的溢出问题。Bloomier过滤器、布隆树和状态BF直接或间接地在过滤器中对某些元素值进行存储,使它们在各自的应用领域中可以直接使用过滤器查询到元素值,无需再执行其他请求操作。
7 总结与展望
随着数据规模的不断扩大,越来越多的应用场景在执行查询请求时需要设计海量的数据,且场景对于这些请求的性能要求也越来越高,空间紧凑,存在少量查询误判但效率极高的数据结构BF是解决元素成员资格查询的一个常见工具。本文结合不同的应用场景介绍了目前比较主流的几种BF优化方案,并从BF各个性能指标的角度进行了对比和分析,可为以后BF可能的研究方向提供参考。
经过不断的改良和优化,BF的优化方案在“位向量的空间灵活性”“增加空间利用率”“减少查询误判率”和“对元素删除操作的支持”等方面已经有了很大的提高,但由于使用场景繁多、新型存储介质的广泛应用等问题,进一步优化已有的方案使其适用全新场景和新型存储介质将成为一个热点问题。BF未来可能的研究方向展望如下:
1)将删除和查询操作分离。目前讨论过滤器的删除操作都是以“元素一定属于集合”为前提的,当过滤器删除本不属于集合但会产生查询误判的元素时,过滤器会错误地从过滤器中删除该元素,等后续查询到该元素时,查询结果会破坏BF的单向误判性,所以过滤器对请求删除元素是否存在于集合的判断必须是完全正确的。
2)哈希策略的优化是BF的一个非常重要的部分,其映射是否均匀关系到位向量的空间适用效率,在有限空间中的碰撞是BF查询误判率的直接原因。虽然在有限的空间中哈希策略一定存在碰撞的情况,但是对其的进一步探索是未来的一个重要方向。
3)针对二级存储中BF的优化思想单一。当内存大小不足以容纳整个BF而需将其转移到二级存储中时,目前的优化方案都是对过滤器进行分块或分层来减少整体上I/O的次数从而达到优化效果,还没有太多从其他优化思想出发的优化方案。
4)SSD存储设备虽然性能好,但价格高昂,短时间内无法完全替代传统存储设备,因此混合存储系统仍是目前的主流方案,但对于混合存储系统中BF的相关优化方案还很少。
随着大数据时代的发展,BF本身紧凑的空间使用和高效的操作,有着天然的优势,而且它的各部分均可优化,还能够针对特定应用场景进行定制化的改进,因此未来对于高性能查询的研究领域,BF仍然是一个重大课题。
[1] BLOOM B H. Space/time trade-offs in hash coding with allowable errors[J]. Communications of the ACM, 1970, 13(7): 422-426.
[2] CARTER L, FLOYD R W, GILL J, et al. Exact and approximate membership testers[C]// Proceedings of the 10th Annual ACM Symposium on Theory of Computing. New York: ACM, 1978:59-65.
[3] 肖明忠,代亚非. Bloom Filter及其应用综述[J]. 计算机科学, 2004, 31(4):180-183.(XIAO M Z, DAI Y F. A survey on Bloom filters and its applications[J]. Computer Science, 2004, 31(4): 180-183.)
[4] 刘元珍. Bloom Filter及其在网络中的应用综述[J]. 计算机应用与软件, 2013, 30(9):219-220, 249.(LIU Y Z. Survey on Bloom filter and its applications in networks[J]. Computer Applications and Software, 2013, 30(9): 219-220, 249.)
[5] PENG Y Q, GUO J W, LI F F, et al. Persistent Bloom filter: membership testing for the entire history[C]// Proceedings of the 2018 International Conference on Management of Data. New York: ACM, 2018:1037-1052.
[6] MCLLROY M. Development of a spelling list[J]. IEEE Transactions on Communications, 1982, 30(1): 91-99.
[7] MULLIN J K, MARGOLIASH D J. A tale of three spelling checkers[J]. Software: Practice and Experience, 1990, 20(6): 625-630.
[8] SPAFFORD E H. OPUS: preventing weak password choices[J]. Computers and Security, 1992, 11(3): 273-278.
[9] SEVERANCE D G, LOHMAN G M. Differential files: their application to the maintenance of large databases[J]. ACM Transactions on Database Systems, 1976, 1(3): 256-267.
[10] GREMILLION L L. Designing a Bloom filter for differential file access[J]. Communications of the ACM, 1982, 25(9): 600-604.
[11] FANG M, SHIVAKUMAR N, GARCIA-MOLINA H, et al. Computing iceberg queries efficiently[C]// Proceedings of the 24th International Conference on Very Large Data Bases. San Francisco: Morgan Kaufmann Publishers Inc., 1998: 299-310.
[12] BRODER A Z, MITZENMACHER M. Network applications of bloom filters: a survey[J]. Internet Mathematics, 2004, 1(4): 485-509.
[13] STOICA I, MORRIS R, KARGER D, et al. Chord: a scalable peer-to-peer lookup service for internet applications[C]// Proceedings of the 2001 ACM SIGCOMM Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication. New York: ACM, 2001:149-160.
[14] RATNASAMY S, FRANCIS P, HANDLEY M, et al. A scalable content-addressable network[C]// Proceedings of the 2001 ACM SIGCOMM Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication. New York: ACM, 2001:161-172.
[15] JOKELA P, ZAHEMSZKY A, ROTHENBERG C E, et al. LIPSIN: line speed publish/subscribe inter-networking[C]// Proceedings of the 2009 ACM SIGCOMM Conference on Data Communication. New York: ACM, 2009:195-206.
[16] RHEA S C, KUBIATOWICZ J. Probabilistic location and routing[C]// Proceedings of the 21st Annual Joint Conference of the IEEE Computer and Communications Societies. Piscataway: IEEE, 2002:1248-1257.
[17] WHITAKER A, WETHERALL D. Forwarding without loops in Icarus[C]// Proceedings of the 2002 IEEE Conference on Open Architectures and Network Programming. Piscataway: IEEE, 2002:63-75.
[18] FENG W C, SHIN K G, KANDLUR D D, et al. The BLUE active queue management algorithms[J]. IEEE/ACM Transactions on Networking, 2002, 10(4): 513-528.
[19] ESTAN C, VARGHESE G. New directions in traffic measurement and accounting[C]// Proceedings of the 2002 ACM SIGCOMM Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication. New York: ACM, 2002:323-336.
[20] 谢平. 存储系统重复数据删除技术研究综述[J]. 计算机科学, 2014, 41(1):22-30, 42.(XIE P. Survey on data deduplication techniques for storage systems[J]. Computer Science, 2014, 41(1): 22-30, 42.)
[21] MALDE K, O'SULLIVAN B. Using Bloom filters for large scale gene sequence analysis in Haskell[C]// Proceedings of the 2009 International Symposium on Practical Aspects of Declarative Languages, LNPSE 5418. Berlin: Springer, 2009:183-194.
[22] CANIM M, MIHAILA G A, BHATTACHARJEE B, et al. Buffered bloom filters on solid state storage[C/OL]// Proceedings of the 2010 International Workshop on Accelerating Data Management Systems Using Modern Processor and Storage Architectures@Very Large Data Bases Conference. [2021-05-23].https://vldb.org/archives/workshop/2010/proceedings/files/vldb_2010_workshop/ADMS_2010/adms10-canim.pdf.
[23] XIE K, MIN Y H, ZHANG D F, et al. Basket Bloom filters for membership queries[C]// Proceedings of the 2005 IEEE Region 10 Conference. Piscataway: IEEE, 2005:1-6.
[24] 何新贵,梁久祯. 利用目标函数梯度的遗传算法[J]. 软件学报, 2001, 12(7):981-986.(HE X G, LIANG J Z. Genetic algorithms using gradients of object functions[J]. Journal of Software, 2001, 12(7): 981-986.)
[25] LI Y K, TIAN C J, GUO F, et al. ElasticBF: elastic bloom filter with hotness awareness for boosting read performance in large key-value stores[C]// Proceedings of the 2019 USENIX Annual Technical Conference. Berkeley: USENIX Association, 2019:739-752.
[26] Google. LevelDB[DB/OL]. [2021-02-24].https://github.com/google/leveldb.
[27] Meta Open Source. RocksDB[DB/OL]. [2021-05-06].http://rocksdb.org/.
[28] RAJU P, KADEKODI R, CHIDAMBARAM V, et al. PebblesDB: building key-value stores using fragmented log-structured merge trees[C]// Proceedings of the 26th Symposium on Operating Systems Principles. New York: ACM, 2017:497-514.
[29] O’NEIL P E, CHENG E, GAWLICK D, et al. The Log-Structured Merge-tree (LSM-tree)[J]. Acta Informatica, 1996, 33(4): 351-385.
[30] DAYAN N, ATHANASSOULIS M, IDREOS S. Monkey: optimal navigable key-value store[C]// Proceedings of the 2017 ACM International Conference on Management of Data. New York: ACM, 2017:79-94.
[31] ZHOU Y Y, PHILBIN J F, LI K. The multi-queue replacement algorithm for second level buffer caches[C]// Proceedings of the 2001 USENIX Annual Technical Conference. Berkeley: USENIX Association, 2001:91-104.
[32] CHEN Y P, SCHMIDT B, MASSKELL D L. A reconfigurable Bloom filter architecture for BLASTN[C]// Proceedings of the 2009 Architektur von Rechensystemen. Berlin: Springer, 2009:40-49.
[33] DEBNATH B, SENGUPTA S, LI J, et al. BloomFlash: Bloom filter on flash-based storage[C]// Proceedings of the 31st International Conference on Distributed Computing Systems. Piscataway: IEEE, 2011:635-644.
[34] GUO D K, WU J, CHEN H H, et al. Theory and network applications of dynamic Bloom filters[C]// Proceedings of the 25th IEEE International Conference on Computer Communications. Piscataway: IEEE, 2006:1-12.
[35] LU G L, DEBNATH B K, DU D H C. A forest-structured Bloom filter with flash memory[C]// Proceedings of the IEEE 27th Symposium on Mass Storage Systems and Technologies. Piscataway: IEEE, 2011:1-6.
[36] YOON M K, SON J, SHIN S H. Bloom tree: a search tree based on Bloom filters for multiple-set membership testing[C]// Proceedings of the 2014 IEEE Conference on Computer Communications. Piscataway: IEEE, 2014:1429-1437.
[37] HAO F, KODIALAM M, LAKSHAM T V, et al. Fast dynamic multiple-set membership testing using combinatorial Bloom filters[J]. IEEE/ACM Transactions on Networking, 2012, 20(1): 295-304.
[38] DHARMAPURIKAR S, KRISHNAMURTHY P, TAYLOR D E. Longest prefix matching using Bloom filters[J]. IEEE/ACM Transactions on Networking, 2006, 14(2): 397-409.
[39] LUO S Q, CHATTERJEE S, KETSETSIDIS R, et al. Rosetta: a robust space-time optimized range filter for key-value stores[C]// Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2020:2071-2086.
[40] ZHANG H C, LIM H, LEIS V, et al. SuRF: practical range query filtering with fast succinct tries[C]// Proceedings of the 2018 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2018:323-336.
[41] FAN L, CAO P, ALMEIDA J, et al. Summary cache: a scalable wide-area web cache sharing protocol[C]// Proceedings of the 1998 ACM SIGCOMM Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication. New York: ACM, 1998:254-265.
[42] LAKSHMAN A, MALIK P. Cassandra: a decentralized structured storage system[J]. ACM SIGOPS Operating Systems Review, 2010, 44(2): 35-40.
[43] The Chromium Projects. Google Chrome safe browsing[EB/OL]. [2021-05-09].http://src.chromium.org/viewvc/chrome/trunk/src/chrome/browser/safe_browsing/.
[44] CHANG F, DEAN J, GHEMAWAT S, et al. Bigtable: a distributed storage system for structured data[C]// Proceedings of the 7th USENIX Symposium on Operating Systems Design and Implementation. Berkeley: USENIX Association, 2006:205-218.
[45] COHEN S, MATIAS Y. Spectral Bloom filters[C]// Proceedings of the 2003 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2003:241-252.
[46] AGUILAR-SABORIT J, TRANCOSO P, MUNTES-MULERO V, et al. Dynamic count filters[J]. ACM SIGMOD Record, 2006, 35(1): 26-32.
[47] XIE K, MIN Y H, ZHANG D F, et al. A scalable Bloom filter for membership queries[C]// Proceedings of the 2007 Global Telecommunications Conference. Piscataway: IEEE, 2007:543-547.
[48] CARTER J L, WEGMAN M N. Universal classes of hash functions[J]. Journal of Computer and System Sciences, 1979, 18(2): 143-154.
[49] QIAO Y, LI T, CHEN S G. Fast Bloom filters and their generalization[J]. IEEE Transactions on Parallel and Distributed Systems, 2014, 25(1): 93-103.
[50] CHAZELLE B, KILIAN J, RUBINFELD R, et al. The Bloomier filter: an efficient data structure for static support lookup tables[C]// Proceedings of the 15th Annual ACM-SIAM Symposium on Discrete Algorithms. Philadelphia, PA: SIAM, 2004:30-39.
[51] VOCKING B. How asymmetry helps load balancing[C]// Proceedings of the 40th Annual Symposium on Foundations of Computer Science. Piscataway: IEEE, 1999:131-141.
[52] BONOMI F, MITZENMACHER M, PANIGRAHY R, et al. An improved construction for counting Bloom filters[C]// Proceedings of the 2006 European Symposium on Algorithms, LNTCS 4168. Berlin: Springer, 2006:684-695.
[53] BENDER M A, FARACH -COLTON M, JOHNSON R, et al. Don’t thrash: how to cache your hash on flash[J]. Proceedings of the VLDB Endowment, 2012, 5(11): 1627-1637.
[54] CLERRY J G. Compact hash tables using bidirectional linear probing[J]. IEEE Transactions on Computers, 1984, C-33(9): 828-834.
[55] Wikipedia. Quotient filter[EB/OL]. [2021-06-13].https://en.wikipedia.org/wiki/Quotient_filter.
[56] PAGH R, RODLER F F. Cuckoo hashing[J]. Journal of Algorithms, 2004, 51(2): 122-144.
[57] FAN B, ANDERSEN D G, KAMINSKY M, et al. Cuckoo filter: practically better than bloom[C]// Proceedings of the 10th ACM International Conference on emerging Networking Experiments and Technologies. New York: ACM, 2014:75-88.
[58] FAN B, ANDERSEN D G, KAMINSKY M. MemC3: compact and concurrent memcache with dumber caching and smarter hashing[C]// Proceedings of the 10th USENIX Symposium on Networked Systems Design and Implementation. Berkeley: USENIX Association, 2013:371-384.
[59] ROTTENSTREICH O, KANIZO Y, KESLASSY I. The variable-increment counting Bloom filter[C]// Proceedings of the 2012 IEEE Conference on Computer Communications. Piscataway: IEEE, 2012:1880-1888.
[60] GRAHAM S. Bhsequences[M]// BERNDT B C, DIAMOND H G, HILDEBRAND A J. Analytic Number Theory, PM 138. Boston: Birkhäuser, 1996: 431-449.
[61] PUTZE F, SANDERS P, SINGLER J. Cache-, hash- and space-efficient Bloom filters[C]// Proceedings of the 2007 nternational Workshop on Experimental and Efficient Algorithms, LNTCS 4525. Berlin: Springer, 2007:108-121.
[62] MACKERT L F, LOHMAN G M. R* optimizer validation and performance evaluation for local queries[C]// Proceedings of the 1986 ACM SIGMOD International Conference on Management of Data. New York: ACM, 1986:84-95.
[63] FICARA D, DI PIETRO A, GIORDANO S, et al. Enhancing counting Bloom filters through Huffman-coded multilayer structures[J]. IEEE/ACM Transactions on Networking, 2010, 18(6): 1977-1987.
[64] BONOMI F, MITZENMACHER M, PANIGRAHY R, et al. Beyond Bloom filters: from approximate membership checks to approximate state machines[C]// Proceedings of the 2006 ACM SIGCOMM Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication. New York: ACM, 2006:315-326.
[65] Wikipedia. Bloom Filter[EB/OL]. [2021-06-13].https://en.wikipedia.org/wiki/Bloom_filter.
[66] DEEDS K, HENTSCHEL B, IDREOS S. Stacked filters: learning to filter by structure[J]. Proceedings of the VLDB Endowment, 2020, 14(4): 600-612.
[67] DAYAN N, TWITTO M. Chucky: a succinct cuckoo filter for LSM-tree[C]// Proceedings of the 2021 International Conference on Management of Data. New York: ACM, 2021:365-378.
Research on Bloom filter: a survey
HUA Wendi1,2,3,4, GAO Yuan1,2,3,4, LYU Meng1,2,3,4, XIE Ping1,2,3,4*
(1,,8100016,;2,810008,;3,810018,;4,810016,)
Bloom Filter (BF) is a binary vector data structure based on hashing strategy. With the idea of sharing hash collisions, the characteristic of one-way misjudgment and the very small time complexity of constant query, BF is often used to represent membership and as an “accelerator” for membership query operations. As the best mathematical tool to solve the membership query problem in computer engineering, BF has been widely used and developed in network engineering, storage system, database, file system, distributed system and some other fields. In the past few years, in order to adapt to various hardware environments and application scenarios, a large number of variant optimization schemes of BF based on the ideas of changing structure and optimizing algorithm appeared. With the development of big data era, it has become an important direction of membership query to improve the characteristics and operation logic of BF.
Bloom Filter (BF); membership query; Approximate Membership Query (AMQ) structure; hashing strategy; False Positive Rate (FPR)
This work is partially supported by National Natural Science Foundation of China (61762075), Natural Science Foundation of Qinghai Province (2020-ZJ-926).
HUA Wendi, born in 1998, M. S. candidate. His research interests include computer architecture, mass storage system, embedded system.
GAO Yuan, born in 1989, M. S. candidate. His research interests include network storage.
LYU Meng, born in 1998, M. S. candidate. Her research interests include network storage.
XIE Ping, born in 1979, Ph. D., professor. His research interests include computer architecture, mass storage system, embedded system.
TP393
A
1001-9081(2022)06-1729-19
10.11772/j.issn.1001-9081.2021061392
2021⁃08⁃04;
2021⁃09⁃29;
2021⁃09⁃30。
国家自然科学基金资助项目(61762075);青海省自然科学基金资助项目(2020‑ZJ‑926)。
华文镝(1998—),男,辽宁抚顺人,硕士研究生,CCF会员,主要研究方向:计算机体系结构、大规模存储系统、嵌入式系统;高原(1989—),男,山东泰安人,硕士研究生,CCF会员,主要研究方向:网络存储;吕萌(1998—),女,山东青岛人,硕士研究生,CCF会员,主要研究方向:网络存储;谢平(1979—),男,四川内江人,教授,博士,CCF会员,主要研究方向:计算机体系结构、大规模存储系统、嵌入式系统。
