少数民族语言分词技术评测数据集MLWS2021
2022-07-03赵小兵高璐高定国包乌格徳勒米尔阿迪力江麦麦提刘洋才智杰孙媛
赵小兵,高璐,高定国,包乌格徳勒,米尔阿迪力江·麦麦提,刘洋,才智杰,孙媛*
1.中央民族大学,北京 100081
2.国家语言资源监测与研究少数民族语言中心,北京 100081
3.西藏大学,拉萨 850013
4.呼和浩特民族学院,呼和浩特 015501
5.清华大学,北京 100084
6.青海师范大学,西宁 810016
7.藏语智能信息处理及应用国家重点实验室,西宁 810016
引 言
少数民族语言信息处理技术起步较晚,目前还处于初中级阶段,要解决人与计算机交互、系统问答等顶层问题,首先要从能够独立表义的最小单位即词汇开始研究。由于各少数民族语言分词标准的不统一以及语料的不开放性,极大地限制了少数民族语言信息处理发展的进程。因此,迫切需要运用评测语料库的科学计算方法进行公开、公正的评测,建构适用于自动分词评测的规范标准,从而推动少数民族语言分词的规范与统一。
本数据集从计算机的角度出发,考虑蒙古文、藏文、维吾尔文分词的规范原则,依据蒙古文、藏文和维吾尔文词汇的构词规律和特点,制定适合计算机信息处理的蒙古文、藏文和维吾尔文分词评测标准,设计三个语种的分词评测分析软件,构建蒙古文、藏文和维吾尔文的分词语料,形成标准评测数据集,为解决自动分词、词性标注、信息检索、语料库构建等研究课题提供依据。
1 数据采集和处理方法
1.1 制定分词评测标准
藏文分词评测标准的制定借鉴了《信息处理用现代汉语分词规范》(GB/T 13715-1992)[5]、《信息处理用藏文分词规范》(GB/T 36452-2018)[3]、《信息处理用藏语词类标记集》(GB/T 36337-2018),对每一词类制定详细的切分细则。
蒙古文按照特定的规范,把词表示为词干和构形词缀的形式。蒙古文分词评测标准的制定主要依据《信息处理用现代汉语分词规范》(GB/T 13715-1992)[5]和《信息处理用蒙古文词语标记》(GB/T 26235-2010)[5]确定大类词类,并对每个词类制定详细的切分规则。
维吾尔文的分词是词干提取的过程,其制定主要依据《信息处理用现代维吾尔语词类标注标记规范集》。规范集对词形变化丰富的名词、动词、形容词进行了详细的规则介绍,并举例说明。
1.2 语料媒体来源
蒙、藏、维3个语种的语料均来源于由新闻、经济、法律、娱乐等各领域组成的综合语料,因此语料爬取的媒体来源广泛,表1展示了部分新闻媒体渠道。

表1 部分新闻媒体来源Table 1 Part of news media sources
1.3 数据采集及预处理
1.3.1 数据爬取
每个语种团队的技术小组负责数据爬取及预处理工作。通过构建并行分布式爬虫框架,按照之前整理的蒙、藏、维各领域媒体渠道,采用合适的机制对网页数据进行爬取并保存在本地。爬取过程中,我们对网页的具体内容并不处理,以提升爬取的速度和效率。爬取结束后使用相应的预处理解析模块,提取需要保存的内容。
当前,国际标准的话语权已成为全球制造业发展的必争之地,依靠技术标准占领市场成为国际竞争中的首选战略。提升“江苏制造”标准,占领制造业高地,需要借鉴发达国家和地区的有益经验。实施标准化战略是振兴制造业的国际通行做法。
1.3.2 数据预处理
该模块将蒙古文、藏文、维吾尔文的网页数据转换成统一编码。此外,由于少数民族语言字符输入较为复杂,如输入蒙古文时需要考虑分写词缀、分写元音、特殊字符等,部分人员在使用时为了提高输入效率,会尽可能地减少使用这些繁琐的控制符,导致输入文本的后端编码出错,因此在进行文本处理之前势必要进行字符的校对。在数据集构建过程中,按照不同语种文本预处理的需要,应用和开发了相关的加工软件对语料进行预处理。开发的软件包括垃圾信息滤除软件、编码转换软件、语料校对软件等。
1.3.3 自动初步分词
少数民族语言分词技术已经有一定的研究基础,也积累了相应的分词工具,取得了领域内较好的分词结果。为了加快语料的处理,提高分词的准确性,利用清华大学、中央民族大学、西藏大学等依托单位现有的分词工具对各个语种的语料进行了初步分词。由于没有任何分词工具能够达到百分之百的准确性,初步分词的结果需要进一步的人工校对。
1.3.4 人工校对
人工校对工作繁重,需要大量有经验的母语人士参与。蒙古文、藏文、维吾尔文分别由中央民族大学、西藏大学、清华大学负责。每个语种团队分为技术小组、标注小组、校验小组,其中标注小组和校验小组由母语人士构成,负责语料的人工校对工作。标注小组和校验小组通力协作,不断推动着数据集的构建过程。在标注小组与校验小组标注结果达成一致时,该条数据才会成功入库;若有不一致现象产生,则移交相关负责人研判。在所有数据条目构建完成后,按照整体10%的比例,引入第三方机构进行数据集抽检。
为保证标注的一致性及规范性,在标注之前,由相关团队对母语人士进行语言水平测试,筛选有经验的母语人士入组;对母语人士进行标准规范的相关培训,确保标注人员按照同一标准分词;校验小组与标注小组背对背,互不干扰,当二者标注不一致时,提交相关负责人研判,确保标注的准确率。
数据集整体构建流程如图1所示。
2 数据样本描述
MLWS2021包含蒙、藏、维3个语种,评测对象是蒙古文、藏文、维吾尔文三个语种的自动分词核心技术。数据集在MLWS2017的基础上,由之前单一的新闻领域扩充到新闻、经济、法律、娱乐等综合领域;数据规模也由之前的3万句,扩大到目前的15.5万句。MLWS2021数据集中,蒙古文由中央民族大学提供,共计6.5万句;藏文由西藏大学提供,共计2.5万句;维吾尔文由清华大学提供,共计6.5万句。评测数据集概况如表2所示,标注样例见表3。
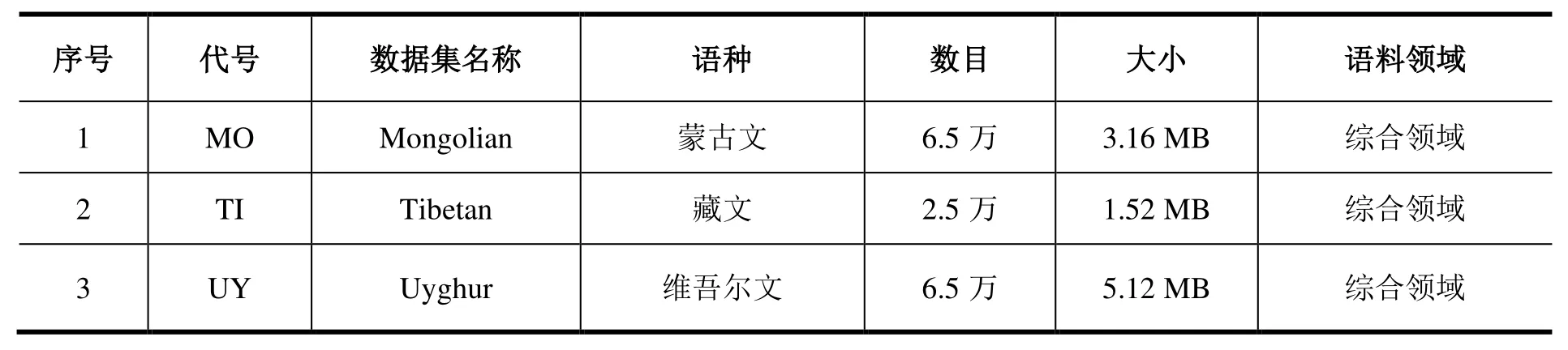
表2 MLWS2021概况Table 2 Overview of MLWS2021

表3 标注样例Table 3 Annotation samples
3 数据质量控制和评估
为保证评测数据集质量的可靠性、稳定性,评测工作委员会启动数据集质量评估工作,成立数据集抽检小组,并进行抽检排期。对于蒙、藏、维3个语种的标注语料,按照10%的比例抽取。其中,藏文以步长为10,均匀抽取10%,共抽取样本2500句;蒙古文和维吾尔文分别将原语料打散,随机抽取10%,分别抽取6500句。将抽取的数据样本(15500句)委托第三方机构进行人工校对。
经第三方机构评估,反馈结果为:藏文正确率为98.27%,蒙古文正确率99.12%,维吾尔文正确率86.39%。由评估结果可知,数据集质量稳定,可满足少数民族语言分词技术评测的要求。同时我们将第三方机构人工校对后的结果收集起来,对原数据集的对应错误进行替换。
目前MLWS数据集已经连续服务两届少数民族语言分词技术评测,在构建过程中形成了一套完整的迭代流程。未来,数据集维护小组会不定时对数据集按比例进行抽取、校验、反馈、优化,同时借助多语种信息处理专委会,成立评测工作组,利用MLWS2021数据集开展相关的评测工作。我们相信,在不断的公开评测及多轮迭代下,数据集会不断完善,推动少数民族语言信息技术的发展。
4 数据价值
目前评测集已成功服务两届少数民族语言分词技术评测,版本也由最初的MLWS2017迭代为MLWS2021,质量和稳定性得到进一步巩固。表4展示了第二届少数民族语言分词技术评测中,藏文分词技术在MLWS2021数据集上的部分参评结果。结果采用准确率(Precision)、召回率(Recall)、F1值作为评测指标,按照F1值进行高低排序并排名。未来该评测数据集将面向社会,提供免费评测服务,逐步构建权威的少数民族语言分词技术评测平台,推动少数民族语言信息处理技术的发展。
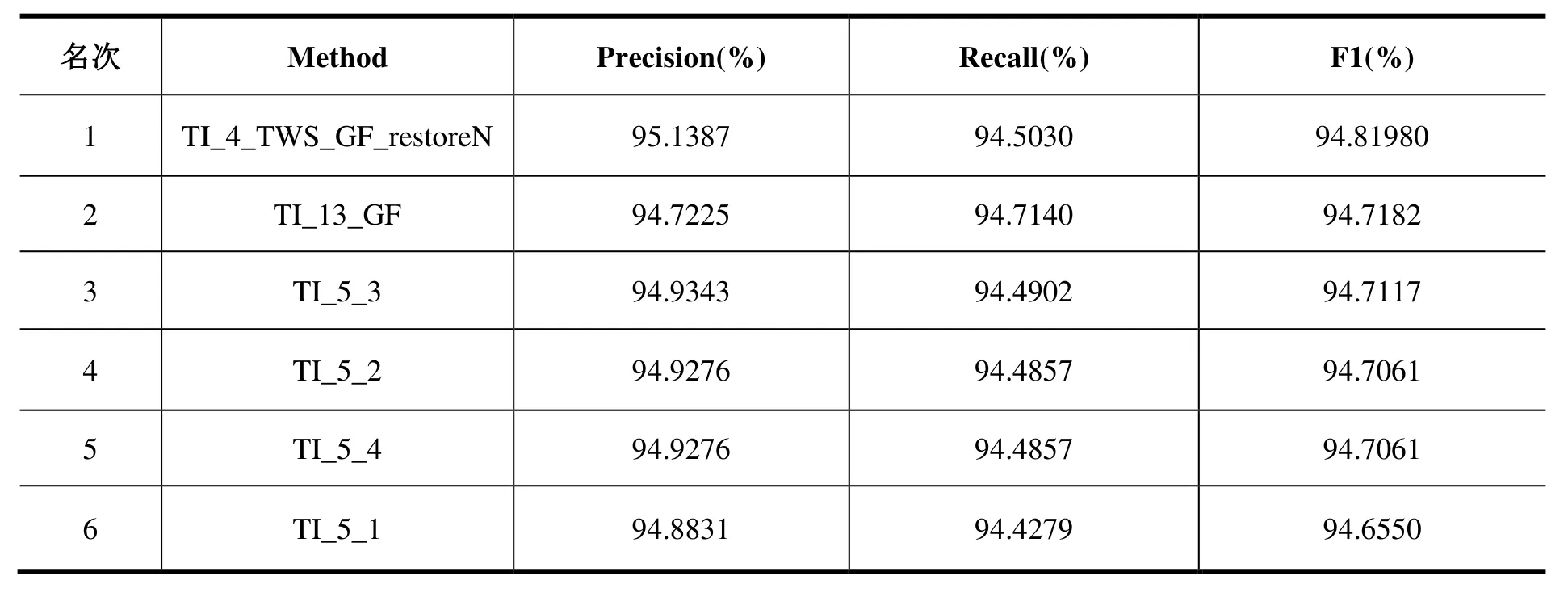
表4 藏文评测部分结果Table 4 Results of Tibetan evaluation
致 谢
感谢中央民族大学硕士生金波搭建第二届少数民族语言分词技术评测平台!感谢中央民族大学博士生特尼格尔、依斯马依力·艾肯木、周毛克等在数据集校验过程中的辛苦付出!
数据作者分工职责
赵小兵(1967—),女,北京市人,博士,教授,研究方向为计算语言学。主要承担工作:评测数据集构建流程的整体把控,人员协调与安排。
高璐(1989—),女,河北省邯郸市人,博士生,讲师,研究方向为计算语言学。主要承担工作:数据集质量监控。
高定国(1972—),男,四川省若尔盖县人,硕士,教授,研究方向为藏文信息处理。主要承担工作:藏文数据集的收集、整理、分词标注、校对工作。
包乌格德勒(1979—),男,内蒙古兴安盟人,博士,副教授,研究方向为自然语言处理、人工智能。主要承担工作:蒙古文评测语料的收集、整理、分词标注、校对工作。
米尔阿迪力江·麦麦提(1989—),男,北京市人,博士,研究方向是:自然语言处理、机器翻译、多语言信息处理。主要承担工作:维吾尔文数据搜集、组织标注团队、清洗数据、分配标注任务。
刘洋(1979—),男,北京市人,博士,教授,研究方向为:自然语言处理、深度学习、机器学习、机器翻译。主要承担工作:维吾尔文数据集整体质量把控。
才智杰(1970—),男,青海乐都人,博士,教授,研究方向为藏语自然语言处理。主要承担工作:藏文训练集和测试集的标注质量校对。
孙媛(1979—),女,北京市人,博士,副教授,研究方向为自然语言处理。主要承担工作:数据集整体流程把控。
