蒙汉机器翻译校正数据集
2022-07-03申影利包乌格德勒赵小兵
申影利,包乌格德勒,赵小兵
1.中央民族大学中国少数民族语言文学学院,北京 100081
2.呼和浩特民族学院,呼和浩特 010051
3.中央民族大学信息工程学院,北京 100081
4.国家语言资源监测与研究少数民族语言中心,北京 100081
引 言
传统蒙古文(又称回鹘式蒙古文)是一种黏着型拼音文字,包含“名义字符”和“变形显现字符”。名义字符是蒙古文字符的独立体存在形式,显现字符则是字符居于词首、词中、词尾时由于变形而产生的不同显示形态[1]。蒙古文Unicode字符编码“以音编码”,其文本存在“形同音异”的现象,因而造成以国际标准编码存储的传统蒙古文文本常常错误地录入形状相同,但读音不同的变形显现字符。从字形上看,该单词是完全相同的,但其内部编码却是不同的,这种文本拼写错误对蒙古文信息处理研究造成重大障碍[2]。
蒙古文的文本校对工作是蒙古文信息处理的基础性工作之一。早期的校正工作依赖于人工校对,准确性高,但耗时耗力,效率低下。很多学者针对传统蒙古文的自动校对问题提出了可行的方案。华沙宝[3]依据蒙古文正字法规则开发MHAHP校对系统,受限于词典规模,该系统对动词构形附加成分、格附加成分之外的错误校对效果欠佳。苏传捷[4]等人利用机器翻译模型来构建拼写校对模型,在小规模文本上纠错后正确词比例达到97.55%。蔡祝元[5]通过建立音节与真词混淆集,实现了对蒙古文非词错误与真词错误的查错与纠错。
本文以第十七届全国机器翻译大会(The 17th China Conference on Machine Translation,CCMT 2021,网址见http://sc.cipsc.org.cn/mt/conference/2021/)蒙汉双语翻译项目公开评测数据集作为原始语料。根据分析,评测中提供的未经处理的蒙文语料存在诸多文本错误,这将严重影响机器翻译的性能。因此,本文开展蒙文自动校正工作,构建面向机器翻译任务的高质量蒙汉双语数据集。
1 数据采集和处理方法
1.1 原始语料数据收集
原始数据来自第十七届全国机器翻译大会机器翻译评测任务(CCMT 2021 MT Evaluation),CCMT 2021蒙汉双语翻译任务的评测训练、开发语料数据的情况见表1。

表1 CCMT 2021蒙汉双语翻译任务数据情况Table 1 Data of CCMT 2021 Mongolian and Chinese bilingual translation task
1.2 数据处理
1.2.1 噪声数据清洗
在对蒙古文进行文本校正工作之前,我们发现原始评测集中蒙汉平行语料,存在源端、目标端语言混杂的情况。例如,在 IMU-CWMT2015文件夹中在源语言训练语料中存在大量的目标端语言句子,反之亦然,如图1所示。另外,训练数据中的重复句子会增加模型的负担,影响翻译效果,因此在对蒙汉双语句对中的蒙古文文本进行校正前,首先需要进行清洗、过滤蒙汉平行句对中的“噪声”数据。这样不但可以降低文本校正工作量,还能缓解低质量语料引起的翻译性能下降问题。针对以上情况,分别利用语种检测技术删除混杂语种、重复语句及空行,由实验最初设定的262,458句对训练语料得到经过清洗后的248,438句对,共删除14,020句对。
1.2.2 蒙文文本校正
(一)数字、英文、中文符号、蒙古文非Unicode字符的转换处理
CCMT2021提供的蒙古文语料为Unicode编码语料,因此,首先将蒙文语料中的数字、英文、符号及蒙古文非 Unicode 字符进行转换处理。
(二)文本校对
(1)通过正则表达式对部分字符进行修正
连续的变形控制符(u180B,u180C,u180D)只保留第一个;对分写的附加成分进行统一处理;对u182C(ᠬ)和u182D(ᠭ)字符进行修正;对混用的阳性元音和阴性元音进行修正;对u1836(ᠶ)字符进行修正。以上操作结束后把蒙古文语料转换为拉丁转写形式,对拉丁转写语料进行校对。
(2)通过词典和规则的方法对文本进行校正
采用基于词典和规则的方式对蒙古文进行自动校正,使用国家语言资源监测与研究少数民族语言中心(https://nmlr.muc.edu.cn/)构建整理的20万蒙古文的单词词典和构形附加成分词典。校正流程如图2所示。
蒙文文本校正示例如表2所示。表2通过举例说明CCMT 2021蒙汉评测数据中原始蒙文文本的错误形式以及经过蒙文文本校正后的正确蒙文形式。从字形上看,错误蒙文文本、校正蒙文文本基本相同,但通过将二者进行相应的拉丁转写,就可以发现其内部编码的不同之处。在表2的例子中,我们将错误蒙文文本中的格错误部分进行标红,该类型是指蒙古文单词在连写附加成分时由于阴阳性或者其他构词方面的语法原因导致的错误;紫色及蓝色标记单词分别表示单音字、多音字错误。

表2 CCMT 2021蒙文文本错误及校正示例Table 2 Samples of CCMT 2021 Mongolian text errors and correction
2 数据样本描述
本数据集为蒙汉机器翻译双语平行句对,共包含两部分:5万句校正后蒙文文本,文件名称为:mn_correct.txt;5万句中文文本,文件名称为:zh.txt。如下图3所示。
3 数据质量控制和评估
为验证上述蒙文文本校正工作是否对下游机器翻译质量有提升作用,我们使用全部经过蒙文校正的CCMT2021蒙汉评测集及原始蒙汉评测集,在当前主流的神经机器翻译框架Transformer[6]上进行对比实验,使用BLEU[7]作为评测指标。由于CCMT2021主办方未提供蒙汉双语测试数据,我们选取CWMT2017提供的蒙汉双语测试集共1001句对。实验结果如表3所示,其中2021_dev、2017_test分别表示CCMT2021验证集和CWMT2017测试集。
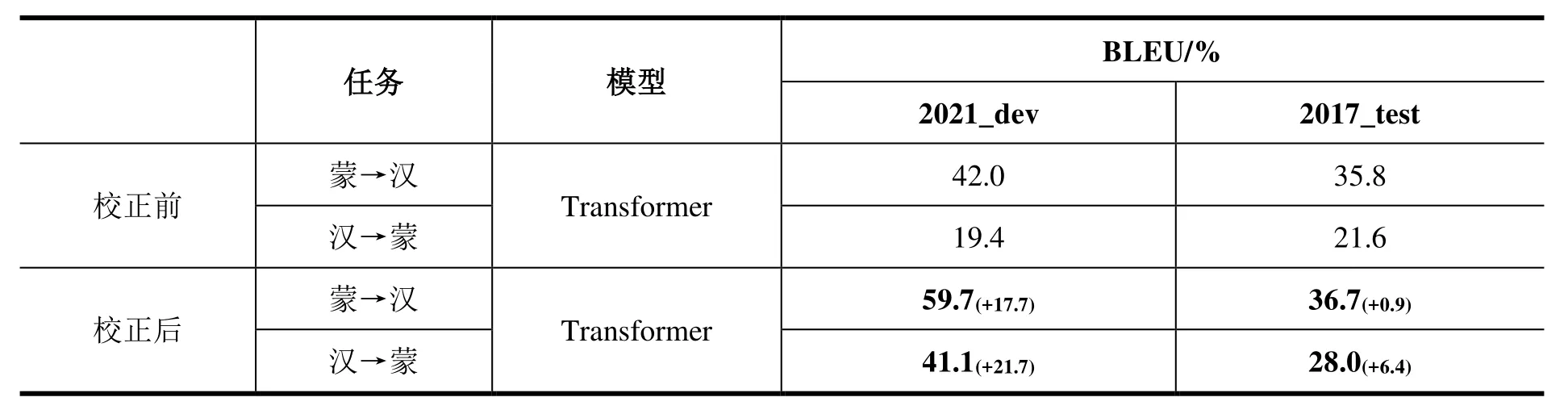
表3 蒙汉双向翻译模型测试结果Table 3 Test results of Mongolian-Chinese bidirectional translation model
从表3中的实验结果可以看出:经过蒙文校正后的语料在蒙汉双向翻译任务中都获得了最优性能。在蒙语→汉语翻译任务中,与校正前的蒙汉双语数据在2021_dev验证集和2017_test测试集上的BLEU值相比,分别提升了17.7和0.9个百分点。另一方面,汉语→蒙语翻译BLEU提升均优于蒙语→汉语翻译任务,校正后分别提升了21.7%、6.4%。这是因为蒙语相比于汉语构词形态更加复杂,当翻译为蒙语时,解码端很难避免语法错误,所以高质量蒙汉双语数据训练的模型对汉语→蒙语方向翻译效果的提升优于蒙语→汉语翻译方向。实验结果发现,使用蒙文文字校正后的蒙汉语料在双向翻译任务上均能够显著提升翻译效果。
4 数据使用价值
数据稀疏是低资源语言神经机器翻译面临的主要问题,针对蒙古文信息处理研究,蒙古文高质量语料的获取一直是亟待解决的难题。本文在蒙汉机器翻译评测数据集的基础上,进行蒙古文文本校正工作,实验验证发现,经过文本校正后的蒙汉双语数据集,在下游机器翻译任务中的翻译质量有明显提升。本数据集除机器翻译任务外,还可用于文本校正、命名实体识别、信息检索等蒙古文自然语言处理工作。
致 谢
感谢全国机器翻译大会主办机构提供的宝贵原始数据资源,感谢对本数据集进行蒙文校正工作的蒙语研究专家。
数据作者分工职责
申影利(1994—),女,安徽亳州人,在读博士研究生,研究方向为自然语言处理、机器翻译。主要承担工作:数据筛选、处理、加工,数据集生成,论文的撰写。
包乌格德勒(1979—),男,内蒙古兴安盟人,博士,副教授,研究方向为计算语言学、蒙古文信息处理。主要承担工作:数据集设计和整理,数据校准。
赵小兵(1967—),女,内蒙古呼和浩特人,博士,博士生导师,研究方向为自然语言处理、舆情分析等。主要承担工作:研究思路设计与论文撰写指导。
