DTFBNet:一种面向智能终端的轻量级人脸识别新方法
2022-07-01叶继华江爱文
叶继华,郭 凤,黎 欣,江 蕗,江爱文
(江西师范大学计算机信息工程学院,江西 南昌 330022)
0 引言
人脸识别是一种重要的身份认证技术,已经应用于越来越多的智能终端,如设备解锁、应用登录、移动支付等.一些配备了人脸验证技术的移动应用程序(如智能手机解锁),需要离线运行.为了在有限的计算资源下实现用户友好性,智能终端本地部署的人脸识别模型不仅要准确,而且要小而快.然而,现代高精度人脸识别模型建立在深度和大卷积神经网络(CNN)上,在训练阶段由损失函数监督.由于需要大量计算资源的大型CNN模型并不适用于许多移动和嵌入式应用程序,因此,在嵌入式领域受计算能力和高吞吐量要求限制的环境下,部署基于深度学习的人脸识别模型仍然具有挑战性[1-2].
最近,通过利用计算机视觉任务而设计的轻量级深度学习模型架构,在设计高效的人脸识别解决方案方面取得了较大的进展,如MobileNetV2[3]、ShuffleNet[4]、VarGNet[5]等.MobileFaceNet[6]是最早提出的高效人脸识别模型,具有大约1 M参数和439 M FLOPs.MobileNetV2的架构是基于反向残差结构和深度可分离卷积[7].AirFace[8]、ShuffleFaceNet[9]和VarGFaceNet[10-11]模型架构分别由MobileNetV2、ShuffleNetV2和VarGNet来构建,使用具有大约1 G FLOPs计算复杂度的紧凑模型并且达到较高准确度.ShuffleNetV2利用ShuffleNetV1提出的通道Shuffle操作,在准确性和计算效率之间进行折中处理.VarGNet建议固定在每个组卷积中的输入通道数量,而不是固定总组数,以平衡卷积块内部的计算强度.LFR的deepglint-light轨道通过1 G FLOPs的计算复杂度和20 M的内存占用(约5 M的可训练参数)来实现在环境约束的条件下的人脸识别.CondenseNet[12]将密集连接与学习组卷积相结合,以促进特征重用,同时消除了冗余连接.Sun Ke等[13]提出了在参数和计算方面都较为有效的交错组卷积,而文献[14]引入了移位操作来取代昂贵的空间卷积.VarGFaceNet考虑了不同组数对提取有效特征的影响,MobileNetV2考虑了深度可分离卷积.在深度可分离卷积中的深度卷积和点卷积相当于2次卷积的过程,并且与输入通道和输出通道、卷积核大小相同的传统卷积相比,深度可分离卷积的参数量会少于传统卷积的参数量.深度卷积是特殊的group convolution,深度卷积的输入通道数、输出通道数、组数相同,这表明通过深度卷积计算后的特征会有信息损失,从而导致需要更多的参数才能学习到具有正确分类能力的特征.
基于以上问题,本文在MobileFaceNet的基础上将深度可分离模块替换成DTFBlock模块.该模块考虑了深度卷积无法提取含有更多细节的低级特征的问题.DTFBlock模块对损失的信息进行补偿,可以提取到含有更多细节的低级特征.DTFBlock模块将深度卷积提取的特征和2个系统模块提取的特征进行融合,从而得到含有更多细节的低级特征,这样有利于DTFBNet网络提取更具有识别性的特征.
在LFW[15]测试数据集上进行实验,实验结果表明本文改进的方法提升了模型的准确性.
1 相关工作
传统卷积同批次输入的特征会一次处理成所需输出特征,但深度可分离卷积并不是对输入的特征一次处理成所需输出特征,而是将传统卷积过程分解成深度卷积和点卷积(见图1).深度卷积计算每个输入的特征,输出中间特征,所有的中间特征通过点卷积得到最终的输出特征.这样不仅计算了图像的空间维度,还计算了图像深度维度.输入的特征x∈RCin×h×w,卷积核的大小为k×k,输出的通道数为Cout.标准卷积的参数量为
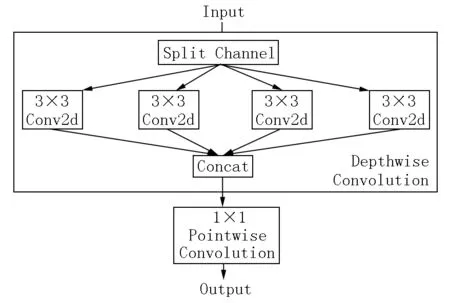
图1 深度可分离卷积
Nsc=k×k×Cout×Cin,
(1)
深度卷积运算的参数量为
Ndc=Cin×k×k,
(2)
点卷积运算的参数量为
Npc=Cin×Cout,
(3)
通过深度可分离卷积的总参数量为
Ndsc=Ndc+Npc.
(4)
从式(1)~(4)可以得出,用深度可分离卷积来代替传统卷积,参数减少数量为
F=Ndsc/Nsc=1/Cout+1/k2.
(5)
由式(5)可知:相比于传统卷积,深度可分离卷积减少参数量,具有计算成本优势.
MobileNetV2和Xception[16]等模型均采用了深度可分离卷积,用于智能终端以减少模型的参数量,从而降低模型的复杂度.
2 DTFBNet模型
在MobileFaceNet网络中使用了深度卷积,利用深度卷积降低模型参数量.但深度卷积相对于传统卷积提取的特征信息不够丰富,会阻碍网络的优化.针对深度卷积提取的特征存在信息损失的问题,借鉴恒等映射的思想和在MobileFaceNet中轻量级人脸识别网络设计原则,该文提出了DTFBNet.DTFBNet模型主要分为4个部分:(i)网络的架构设计;(ii)针对深度卷积提取特征存在信息损失的问题提出了DTFBlock(depthwise convolution and traditional convolution fusion Block);(iii)特征融合,讨论最佳特征融合方式;(iv)损失函数,在DTFBNet模型中使用ArcFace损失函数和融合损失函数,其中融合损失函数是针对DTFBlock模块在特征融合过程中出现信息损失的问题引入的.下面将从网络架构、DTFBlock模块、特征融合和损失函数4个方面来介绍DTFBNet模型.
2.1 网络架构
在轻量级人脸识别中,MobileFaceNet是经典的轻量级架构之一,因此,本文选用MobileFaceNet架构作为本文模型改进的基础模型来构建DTFBNet,用于人脸识别的轻量级CNN,具体的网络结构如图2所示,网络中的DTFBlock如图3所示.DTFBlock是由3×3、3×3、3×3、1×1的卷积核和一个将2个输出特征进行融合的结构组成,其中1×1卷积核的输出通道数量是输入通道数量的2倍,其余3×3卷积核的输出通道数量和输入通道数量相同.网络中的bottleneck是倒置的残差结构,它从MobileNetV2中引入了线性约束,但是扩展因子比MobileNetV2的更小.倒置的残差结构是由1×1、3×3、1×1的卷积核和1个将输入特征和输出特征进行融合的结构组成.在该结构中,通道数量的变化和结构与残差结构的相反,因此被称为倒残差结构.此外,使用PReLU作为激活函数,并在批量训练时进行批量归一化处理.在网络中的Conv 1×1是由1×1的卷积核构成,该结构将bottleneck输出特征进行融合并提取高级语义特征.在网络中的Linear GDConv 7×6是由7×6的卷积核构成,该卷积核偏执设置为false.该结构的作用是将特征进行下采样,下采样后的特征大小为1×1.在网络中最后一层Linear Conv 1×1是由1×1的卷积核构成,该卷积核的偏执设置为false.
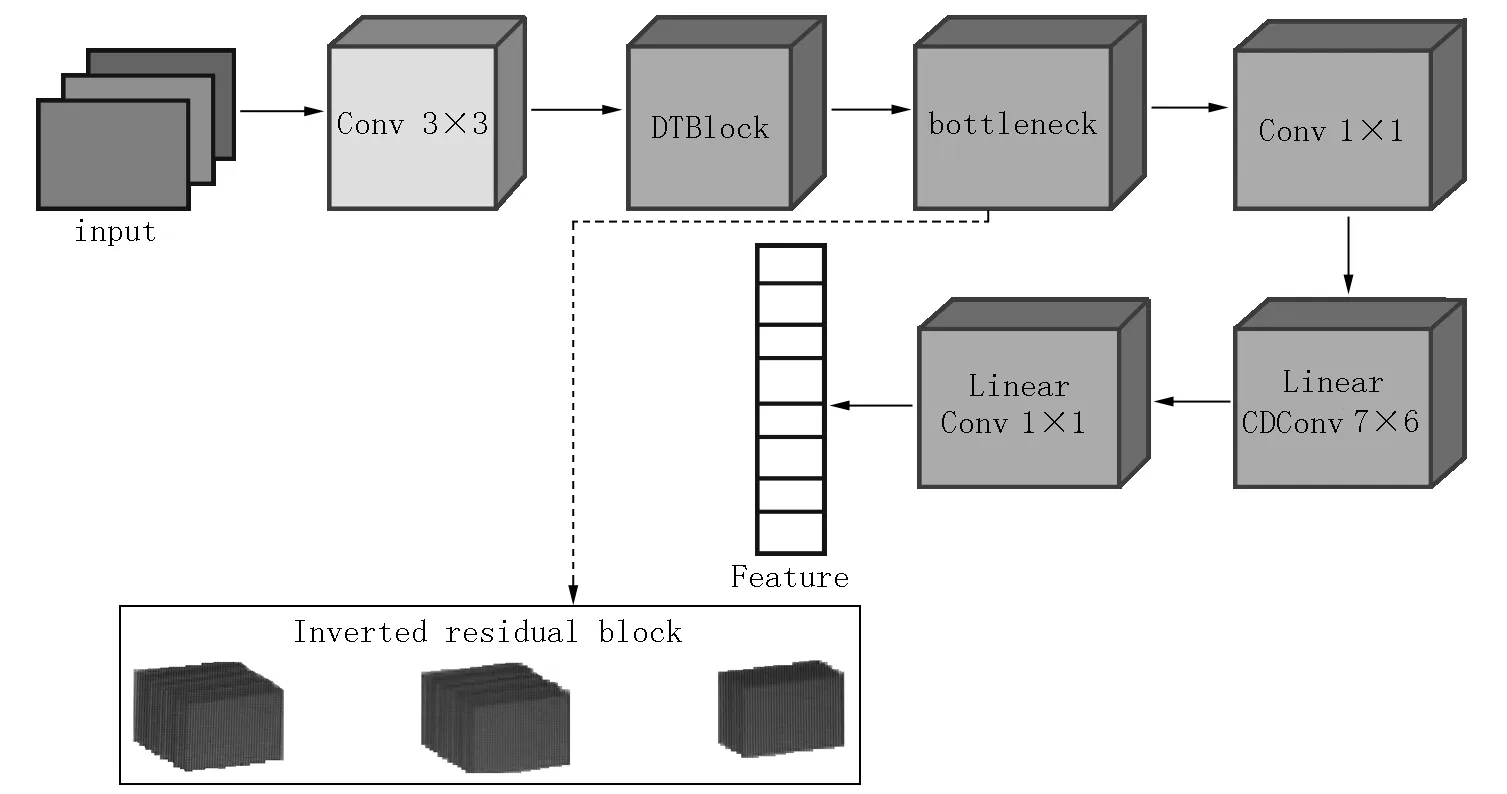
图2 DTFBNet
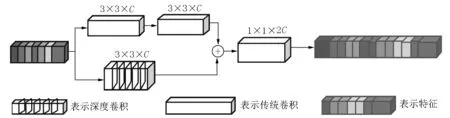
图3 DTFBlock
在网络中的bottleneck可以提取信息丰富的特征,这是由DTFBlock输出的特征输入到bottleneck中所致.在Conv 1×1输出通道数量为输入通道数量的4倍情况下,即输出通道数量为512,会出现特征冗余.实验结果表明:将DTFBlock提取的特征输入bottleneck网络结构中,bottleneck可以提取的特征含有更多细节的信息,这将导致在Conv 1×1中提取的特征出现特征冗余,模型的精确率没有上升,反而有下降的趋势;当将Conv 1×1的输出通道数量设为256时,效果最佳.减少Conv 1×1输出通道数将直接影响Linear GDConv 7×6的输入通道数量,同时减少Conv2输出通道数和Linear GDConv 7×6的输入通道数是本文减少参数量的关键.虽然在本文中DTFBlock模块引入了深度卷积更多的参数量,但是DTFBlock提取的特征相对更加丰富,也更加具有判别力,因此,Conv 1×1的输出通道数和Linear GDConv 7×6的输入通道数减少的参数量比DTFBlock引入的参数量更多,因此,DTFBNet的总参数数量比MobileFaceNet的总参数数量更少.
2.2 DTFBlock
设计一个高效并且参数量较少的模型一般采取的卷积核大小为1×1和3×3,而3×3的卷积核相比1×1的卷积核有更大的感受野.感受野大的卷积核提取的特征含有全局信息,而感受野较小的卷积核提取的特征属于局部信息,DTFBlock提取的低级特征需要包含了全局信息.因此,在DTFBlock中采用卷积核大小为3×3的传统卷积.
本文网络中的深度卷积是一个卷积核大小为3×3、步长为1,输入通道数和输出通道数均为32的卷积.深度卷积的计算特点是每个卷积核对应一个特征通道,因此,深度卷积没有计算输入特征之间的通道关系,通过深度卷积提取到的特征会有信息损失.基于深度卷积的特点,本文设计了DTFBlock.DTFBlock的设计思想来源于残差网络中的恒等映射的思想,该思想主要是:深层的网络不应比浅层的网络表现得更差,因此设计出了残差块.本文借助恒等映射的思想设计了DTFBlock模块,该模块可以提取含有更多细节的低级特征.DTFBlock模块主要由2种卷积运算构成:一种是传统卷积运算,另一种是深度卷积运算.如图4所示,深度卷积运算是将每个通道对应一个卷积核进行卷积.因此,每个通道提取的特征只能体现每个通道的重要性或者特殊性,从而忽略了在输入特征中的空间信息.传统卷积的计算方式如图5所示,传统卷积的计算方式是所有特征图和一个卷积核计算,即所有通道与一个卷积核进行计算,每个通道计算后求和得出每个卷积核提取的特征.传统卷积提取的特征既有通道间的信息又有空间的信息,因此本文借助恒等映射的思想将2种卷积运算进行恒等运算,将这2种卷积提取的特征进行融合,融合后的特征既含有空间信息又突出了每个通道的特殊性.在DTFBlock中选择2个传统卷积,主要原因在于MobileNetV2中的ReLU会破坏低维空间的数据.因此,本文借助该思想选择2个传统卷积提取特征,这样既不会引入太多的参数量又可以提取包含更多的低维信息的特征.

图4 深度卷积运算过程
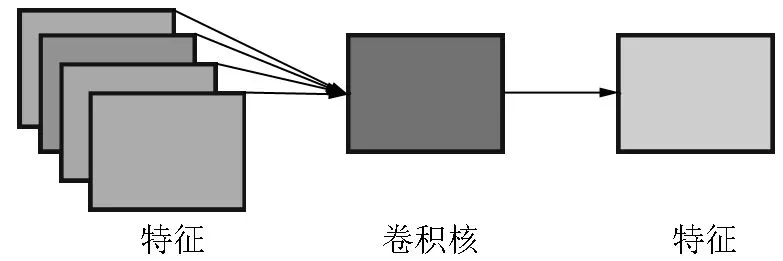
图5 传统卷积运算过程
2.3 特征融合
随着CNN的发展,一系列从低级到高级的特征提取器可以从大规模数据中通过卷积运算的方式自动训练出来.在高级特征中包含了更多高级信息,如语义等.虽然在高级特征中也包含有少量的细节,但在低级特征中包含了更多的细节,如纹理、颜色等.DTFBlock可以提取含有更多细节的低级特征,它通过将深度卷积提取的特征和传统卷积提取的特征进行融合,特征以add和concat方式进行融合.
add融合是将深度卷积提取的特征Xi和传统卷积提取的特征Yi组合而成,组合方法为
add方式融合的特征既包含了先验信息,又在传统卷积提取特征的基础上增强了通道间的信息.
concat融合是将深度卷积提取的特征Xi和传统卷积提取的特征Yi进行拼接,拼接方法为
concat特征融合保留了深度卷积提取的特征和传统卷积提取的特征.
2.4 损失函数
本文采用ArcFace损失函数和融合损失的方法.ArcFace在训练样本时可以减小同类别样本之间距离和增大不同类别样本之间距离.融合损失可以加快网络寻找到DTFBlock融合后的最优特征,在特征融合过程中一些重要的信息会丢失,因此可以通过融合损失得到最优的特征.
2.4.1 ArcFace 人脸识别是细粒度识别任务,每个人脸和人脸之间的相似度比不同物种之间的相似度更高,因此本文采用了ArcFace损失函数.ArcFace损失函数的核心思想是扩大类间距离、减小类内距离.ArcFace损失函数为
其中yi为第i个样本对应的标签;N为总样本的数量;s和m为超参数,分别表示常数缩放因子和用来控制余弦间隔的常数间隔项;θyi为特征xj,i∈R128×1经过归一化之后和Wj,i∈R128×1经过归一化之后的点乘积,同时也代表特征xi和对应权重Wj,i之间的角度.
cosθyi=xi/‖xi‖×Wj/‖Wj‖,
其中xj,i表示在第j个类中的第i个人脸样本提取到的特征值;Wj,i表示在第j个类中的第i个人脸的权重值;‖xi‖表示归一化之后的特征;‖Wj‖表示归一化之后的权重.
2.4.2 融合损失 在DTFBlock中,深度卷积提取的特征不够丰富,因此需添加一个模块进行信息弥补,本文采用2个3×3的传统卷积组成的模块来提取该特征,从而弥补了深度卷积的通道信息.因此,针对信息弥补定义融合损失,fi表示在输入DTFBlock中的特征,ffu表示融合之后的特征,则图像的融合损失函数为
Lfu=‖fi-ffu‖.
2.4.3 损失函数 综合上述的ArcFace损失和融合损失,本文的总损失函数为
L总=LArcFace+λLfu,
(11)
其中λ(≤1)表示超参数.
3 实验结果与分析
3.1 实验数据集
本文使用CASIA-WebFace数据集进行训练,LFW数据集作为验证数据集.在CASIA-WebFace数据集中包含了10 575个人的494 414 幅图像.
LFW数据集是人脸验证的公共基准数据集,其中包含5 749个人超过13 000幅人脸图像,每1幅人脸都有姓名,大约1 680个人有超过2幅人脸图像.LFW数据集被广泛地用于人脸识别,本文用LFW数据集的标准协议(LFW-pairs)来验证实验结果,LFW标准协议包含了总共6 000对人脸图像,其中3000对属于同一个人2幅人脸照片(正样本对),3 000对属于不同的人每人1幅人脸照片(负样本对).
3.2 数据预处理
在CASIA-WebFace数据集中含有大量的类别,同时每个类别都包含了几十幅图像,但在这些图像中包含了较多的噪声,这些噪声有姿态、光照、多人脸等.这些噪声若不处理则将导致网络学习的特征无法正确分类,因此需要对特征进行预处理.在本次预处理过程中本文主要对多人脸和姿态等问题进行预处理,不对光照等噪声进行预处理.在预处理过程中本文使用MTCNN[17]进行预处理,该方法使用了级联的方式对人脸进行检测,在检测过程中使用了人脸边框回归和面部关键点检测[18-20],将人脸姿态进行矫正和在多个人脸的图像中选用其中一个人脸进行预测.
本文预处理过程将所有的图像裁剪成112×96像素大小的图像.
3.3 实验设置
整个网络的训练和验证都是在pytorch框架下进行的.在训练阶段本文使用SGD优化器对模型进行优化,动量设置为0.9,设置权重衰减参数为4×10-5,最后全局操作(GDConv)权重衰减参数设置为4×10-4.本文将初始的学习率设置为0.1,并且在训练轮次为36、52、58时学习率除以10.本文模型一共训练70轮,用ArcFace损失函数[21]作为目标函数优化整个网络,在ArcFace中的s设置为32,m设置为0.5.
本文实验环境为CPU Inter Core i7-9500,内存为16 G,显卡类型为NVIDIA GeForce GTX 2080SUPER,操作系统为Ubuntu16.04.
人脸验证常用的模型评价指标是人脸验证的准确率,该准确率的计算方式为准确率=预测正确的样本数/总样本数.
使用10折交叉验证的方法验证本文的模型:首先得到每1折验证部分的准确率,即在该折中预测正确的数量与在该折中所有图像数量的比值,然后将得到的准确率的平均值作为本文的最终评价指标.
3.4 在LFW数据集上的结果与分析
表1显示了MobileNetV1、ShuffleNet、MobileNetV2、MobileFaceNet、MobiFace[22]、AirFace[8]以及本文模型在LFW测试数据集上的识别率.本文将从批量大小、数据集、模型参数量3个方面进行比较.当MobileFaceNet在2个大小为5.8 M的数据集上进行训练(见表1)时,训练模型使用不同批量大小的实验结果表明:使用批量大的训练得到模型效果比使用批量小的训练得到的模型效果更好,但提升效果不明显(约提升了0.03%).
由表1可知:本文使用的训练批量最小,批量大小为128.MobileFaceNet、AirFace、WFaceNet[23]训练的批量大小分别为512、1 024和128,是本文模型训练批量大小的4倍、8倍和1倍,但是本文模型在LFW数据集上测试效果比MobileFaceNet、AirFace和WFaceNet的都更好.因此,在训练批量大小上,本文的模型效果是较优的.从在不同练数据训集上的比较发现:MobileFaceNet在不同数据集上的训练效果相差较大.MobileFaceNet在5.8 M的数据集上的效果为99.55%,而在0.5 M的数据集上的效果为99.28%,虽然在这2个数据集上的批量大小不同,但是从上述对批量大小分析中可知,批量大小对测试结果的影响程度并不是很大.因此,这里忽略批量大小对测试结果带来的影响.MobileFaceNe对这2个不同数据集进行训练,发现在LFW数据集上的测试结果相差0.27%.由此可以看出,相比批次大小对实验结果的影响,训练数据集对模型的测试结果的影响更大;同时这也表明,在使用大的数据集来训练模型的性能方面DTFBNet在0.5 M的数据集上效果为99.40%,MobileFaceNet、MobileNetV2、AirFace、ShuffleNet、WFaceNet在0.5 M的数据集上的效果分别提升了0.12%、0.82%、0.14%、0.70%、0.04%.实验结果表明:DTFBNet在相同的训练数据集上的效果有一定的提升,然而比使用较大训练数据集训练得到的网络性能更差.接下来在模型参数量上进行比较,MobileNet和MobileNetV2都在0.5 M的数据集上进行训练,批量大小也相同,批量为512,MobileNet模型的参数量大小为3.20 M,MobileNetV2模型的参数量大小为2.10 M.MobileNet模型在LFW数据集上的测试效果比MobileNetV2模型在LFW数据集上的测试效果更好,提升了0.05%.MobileNet模型的参数量比MobileNetV2模型的参数量增加了1.1 M.WFaceNet[23]在LFW数据集上的测试效果为99.36%,比MoileNetV2的提高了0.78%,并且参数量也比MobileNetV2的减少了0.94 M.这表明:在模型的参数量较小的情况下,模型的参数量越小,模型提升的性能越有限.DTFBNet模型在LFW数据集上的测试效果为99.40%,参数量大小为0.92 M.在比WFaceNet参数量减少了0.24 M的情况下,DTFBNet模型的网络效果提升了0.04%;在比MobileFaceNet参数量减少了0.07 M的情况下,DTFBNet模型的网络效果提升了0.12%.这些实验表明:DTFBNet在参数量降低的情况下,DTFBNet的性能有一点提升.因此,本文提出的DTFBNet模型无论在训练批量大小、训练数据集上还是在模型参数量大小上都达到了较好的效果.
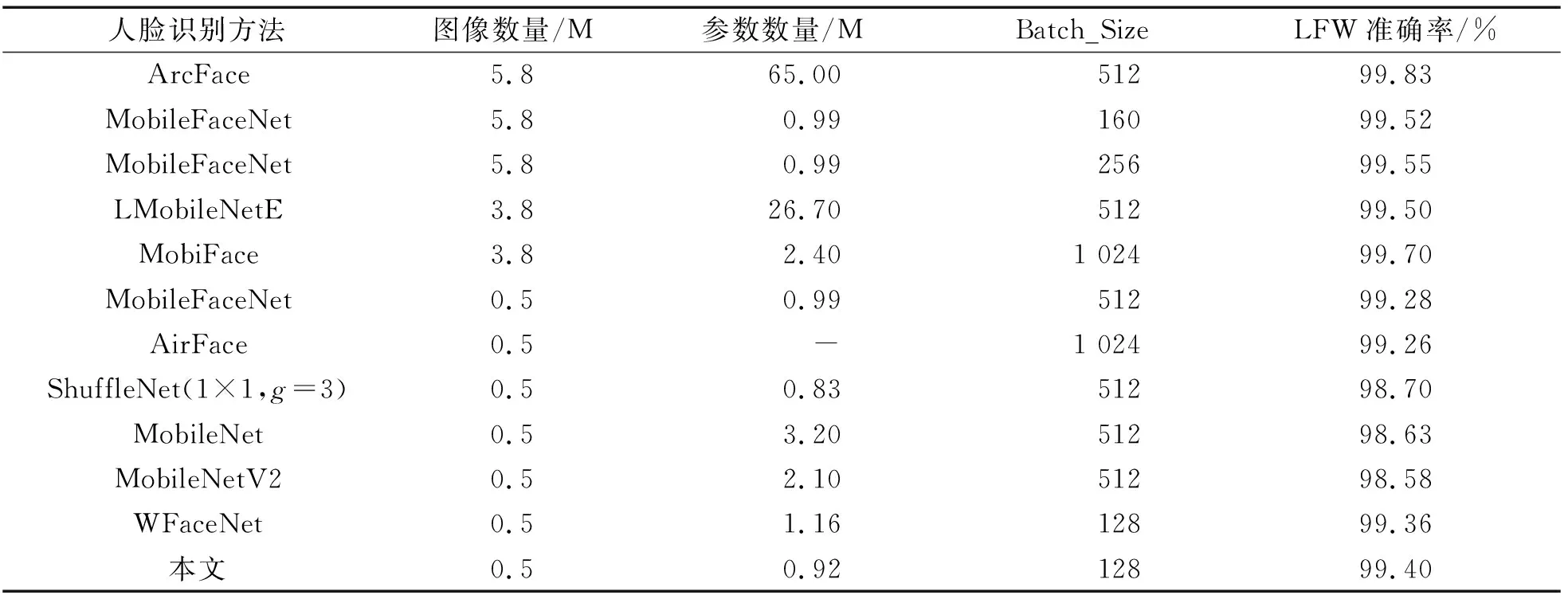
表1 LFW测试结果
3.5 消融实验
3.5.1λ对实验结果的影响分析 对融合损失函数与ArcFace损失函数的参数λ进行了实验,以判断λ的选取对实验结果的影响,本次实验模型有DTFBlock模块,同时Conv 1×1的输出通道数为256.从图6可知:当λ取0.3时实验可以取得最好的效果,若逐渐提升或降低λ的值则实验效果都会较差.这表明融合损失对于模型的提升有局限性.

图6 λ对实验结果的影响分析
3.5.2 DTFBlock模块和损失函数对实验效果的影响分析 本文提出了DTFBlock模块和融合损失函数,为了判断DTFBlock模块和融合损失函数在本文提出模型中的意义,设计了消融实验,实验结果如表2所示.
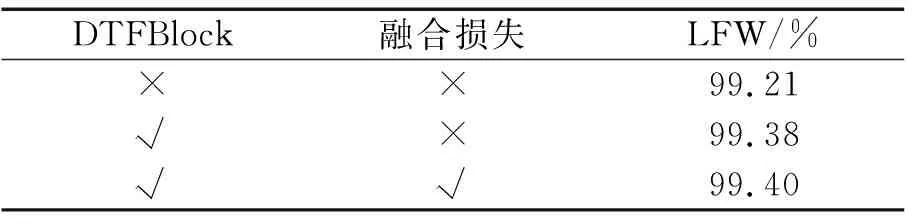
表2 模块比较效果
在表2中,没有DTFBlock和融合损失的基础模型是MobileFaceNet.由表2可知:将深度卷积替换成DTFBlock会带来实验效果的提升,即在LFW数据集上的识别率提升了0.17%.这表明DTFBlock可以提取到含有更多细节的低级特征,即DTFBlock模块更有效.随后,本文使用了融合损失函数(融合损失超参λ设置为0.3),同时也使用DTFBlock,在LFW数据集上的识别率提升了0.02%,有较小幅度的提升.这表明融合损失函数是有效的.
3.5.3 Conv 1×1输出通道数对实验结果的影响分析 本文将Conv 1×1模块的输出通道数和Linear GDConv 7×6的输入通道数进行改进.通道数的变化如表3所示,其中模型使用了DTFBlock和融合损失函数.由表3可知:当Conv 1×1中的输出通道数为输入通道数的2倍时网络的性能最好,而当输出通道数为输入通道数的1倍时网络的性能最差.这表明在通道倍数为1时网络提取的特征比在其他通道倍数时网络提取的特征差.通道倍数为2的网络可以提取更加有效的特征,在通道倍数为3和通道倍数为4时的网络性能次于在通道倍数为2时的网络.这表明:在通道倍数为3和通道倍数为4的网络提取的特征中含有冗余特征,从而导致最终网络的性能不能达到最佳.在通道倍数为2的网络中由于DTFBlock提取含有许多细节的特征,所以在Conv 1×1模块中提取更具有分类能力的高级特征.
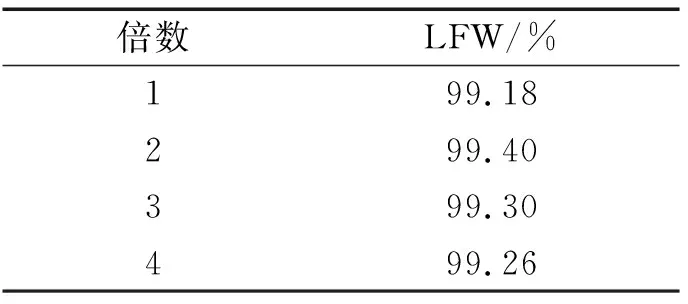
表3 Conv2输出通道数倍数
3.6 可视化
为了展示DTFBlock可以提取含有更多细节的低级特征,本文在LFW数据集上可视化DTFBlock提取的特征.本文从LFW数据集中随机选取了5幅图像进行可视化(见图7).第1层是MobileFaceNet中深度可分离卷积提取出来的特征可视化图,第2层是DTFBNet中DTFBlock提取出来的特征可视化图.从图7可以看出:DTFBlock提取出来的特征可以较为清晰地看出每个人的轮廓和一些纹理.这表明DTFBlock可以提取人脸的含有丰富细节的低级特征.而MobileFaceNet中的深度可分离卷积提取的低级特征含有的细节信息不丰富,看不出完整的纹理结构;提取的特征有一定的信息缺失,这会导致后续网络中判别器会出现较多的预测错误.含有丰富细节的低级特征是提取有判别性高级语义特征的重要前提.因此,本文提出的DTFBlock可以有效地提取含有丰富细节的低级特征.

图7 可视化
4 总结
本文提出了有效的轻量级人脸识别网络模型DTFBNet.DTFBNet是基于MobileFaceNet,将MobileFaceNet中的深度卷积替换成本文提出的DTFBlock.DTFBlock考虑深度卷积提取的特征没有计算通道信息,因此出现了含有细节信息不丰富的现象.DTFBlock将深度卷积提取的特征和2个传统卷积提取的特征进行融合.DTFBNet相比MobileFaceNet在Conv 1×1上减少了输出通道数量,由原来的512减少到128,这导致Linear GDConv 7×6的输入通道数也相应地减少.但是,DTFBlock引入了深度卷积增多的参数量少于Conv 1×1和Linear GDConv 7×6减少的参数量,因此,整个模型的参数量减少,但是整体模型在LFW数据集上的准确率有所提升.这表明DTFBlock模型提取了更丰富的特征,更加有利于分类器进行分类.本文提出的DTFBNet的参数量只有0.92 M,在LFW数据集上的效果也有所提升.这表明本文的模型可以用于在移动设备和嵌入式设备上的实时人脸验证.
