基于可穿戴设备的FDCN模型在大学生情绪变化检测中的应用
2022-07-01陈宇邵军赖文天
陈宇,邵军,赖文天
(1 湖北第二师范学院 计算机学院 & 湖北省教育云服务工程技术研究中心,武汉430205;2 湖北水利水电职业技术学院,武汉430071)
近年来,随着社会压力增大,大学生情绪、心理方面的问题逐步增多,每年出现情绪障碍甚至罹患抑郁症的大学生人数大幅增长.学生多因情绪管理意识不足或个人因素不愿主动寻求帮助,为高校的学生管理工作带来了较大的阻碍.日渐严重的高校学生心理健康问题,引起了人们的广泛关注.高校目前主要采用量表法对学生进行普查,但该方法具有被动性和滞后性等缺点,反馈性差.如何及时发现学生情绪变化,分析原因并尽早干预,防止学生情绪、心理问题恶化,是当前高校学生管理部门迫切需要解决的问题.
1 相关工作
目前,高校应对大学生情绪变化引起心理健康问题的措施逐渐由事后处理转变为预防和筛查,比如通过量表筛查校园内特定人物的心理问题,提前介入和干预.我国学者周晶晶通过设置问卷和量表的形式对北京大学生进行了抑郁症筛查,达到了一定的效果[1].但通过量表进行筛查存在以下问题:首先,诊断过程中对情绪的测量主要依靠检查者的观察和自我评估的心理测试,存在很大的主观性;其次,受检者被要求主动配合检查者的诊断,这需要受检者有一定的配合性;再次,这种方式需要大量的专业人员,但高校普遍缺乏相关人员,通常只在新生入学时或者每学年筛查一次;最后,该方式仅能反映出受检者的心理状况结果,无法提供更多的信息以帮助分析产生情绪变化的原因,不能给后期治疗和高校管理者改善管理方式提供更多的帮助.由此可见,量表法具有数据质量差、准确度低、延时长等缺点,难以进行预防治疗,对高校管理者帮助有限.因此,高校急需一种准确率较高,且随时能感知学生在学业、生活、感情等方面真实情绪变化的方法,便于学校及时察觉学生心理问题,并提前介入干预.
近年来,随着脑神经科学的发展,人们开始尝试使用头戴式监测系统检测脑电信号感知受检者的情绪、压力等,例如,PATIL 等人将采集的脑电信号做高阶交叉作为特征,优于其他统计特征对情绪进行分类[2],IBRAHIM 采用堆栈自动编码器(SAE)和长-短时记忆/循环神经网络(LSTM/RNN)分类方法对情绪脑电图(EEG)特征进行了分类.该方法降低了模型的复杂度,显著提高了分类器的性能[3].虽然脑电在情绪检测领域的应用取得了很大的进展,其检查的准确度明显优于量表的方式,但由于其使用成本昂贵,且需要受检者在特定的时间地点参与,无法做到伴随式数据采集,故多用于为临床治疗提供重要补充数据.随着移动计算的大力发展,研究者开始尝试通过可穿戴设备结合手机伴随式采集受检者数字生物信号、环境信息,挖掘感知数据和日常情绪的关联,在日常生活中自动检测情绪状态和转变.部分研究者通过实验证明这是一种监测个人情绪和压力行之有效的方法,MA 等人提出了一种日常情绪评估工具,该工具利用手机传感器数据,例如位置、音频、文本消息、加速度计和光线来对情绪进行分类[4].AKANE等人利用Fitbit 运动手环收集大学生的行为数据监测大学生的心理健康,其研究发现饮食习惯对学生的压力、睡眠、运动均有影响[5].ASARE 利用手机和可穿戴传感器搜集环境信息进行抑郁症的检测[6].HELBICH 通过采集实验者的地理数据、环境数据发现人们的心理健康与他们居住的社区、去过的地方以及所经历的环境有关[7].在上述的研究中,研究者将手机采集的数据转化为结构化的表格数据形式,然后采用传统的树模型如XGBOOST、随机森林等对数据进行处理,取得了较好的效果.由于手机采集的数据具有维度多、量大、稀疏等特点,因此如何通过特征处理获取特征间的相互关系,对特征进行有效融合,是提高预测精度的关键.传统的树型模型大多基于一阶特征进行线性加权,无法提取隐式的高阶特征组合.随着深度学习理论的不断成熟,能够提取隐含非线性相关特征的深度学习神经网络(DNN)受到了广泛的关注.TAYLOR[8]采用基于神经网络的深度学习方法,研究大学生的心理压力.SUHARA[9]等人开发了一种基于长-短期记忆(LSTM)递归神经网络的大学生减压预测模型.然而,DNN 的解释性很差,且其结果过分关注高阶特征组合及非线性关系,忽视了低阶特征交叉对结果的影响.
近年来,研究人员开始尝试采用因子分解机、深度交叉网络等模型学习特征间的低阶高阶特征,以期提高模型的表现力.如RENDLE[10]提出了基于因子分解机(FM)模型,用于帮助解决在推荐系统中稀疏数据的特征组合问题.该模型具有参数较少,自动组合特征的优点,但由于其只能解决二阶特征之间交叉,无法解决高阶特征组合,近年来的研究多用于与其他模型组合.Google 于2016 年提出的宽深度(wide&deep)模型是由具有记忆功能的融合浅层宽度(wide)模型和深层(deep)模型进行联合训练的框架,利用了深层模型的泛化能力和浅层模型的记忆能力,比传统的线性模型或深度模型获得了更好的效果[11].但由于其对浅层特征选择需要手工操作,依赖于经验,所以在此基础上,Google 提出了deep & cross network 模型,该模型通过引入cross 网络,显式自动的进行特征交叉,且cross 网络可以和deep网络并行或者串行训练[12].与wide&deep模型相比,deep&cross network 模型以更小的开销学习到更多的高阶有效特征组合表达,从而获得更好的预测效果,但其容易忽略低阶特征交叉对特征组合的影响.因此,为了兼顾特征之间的高阶和低阶交互,必须研究如何使用机器学习算法自动提取最有效的特征组合,以充分挖掘智能手机感知数据与大学生情绪之间的关系,从而获得最佳的情绪变化检测模型.
本文根据智能手机和传感器收集的大学生行为、环境数据开展了情绪变化检测的研究,提出了一种基于因子分解机的深度交叉网络(FDCN)情绪变化检测模型,该模型利用因子分解机(Factorization Machines,FM)学习采集信号的低阶特征组合,交叉网络(Cross model)学习高阶特征之间的关联,深度模型(deep model)则通过学习可以找到隐藏的非线性关系.将三者结合起来,即通过FM 模型、Cross 模型利用特征交叉在历史数据中挖掘特征关联,又通过Deep模型自动学习特征的非线性关联,提高对大学生情绪变化检测的精度,反映环境、行为数据对大学生情绪变化的影响,以帮助高校管理者更好地改进管理方式.
2 数据集及情感等级
2.1 数据集
本文采用的数据来源于公开数据集Extrasensor,数据集由圣地亚哥加利福尼亚大学(UCSD)的研究人员收集于2015至2016年,共包含60名UCSD的学生的数据[13].数据是使用 extrasense 移动应用程序收集的,该应用程序每分钟自动执行20 秒的“录音会话”.每次记录过程中,该应用程序从手机的传感器或手表收集测量数据,包括:手机的加速度计、陀螺仪和磁力计(采样频率为40 Hz)、音频(采样频率为22 kHz,然后处理为MFCC 特征表示)、位置、手表的加速度计,数据集采集的数据均来源于实验者的真实生活,通过实验者的智能手机和智能手表上传感器采集相关的物理的信号进行自动上下文标记.这个数据集还包含不同的时间间隔内实验者选择性自我报告的离散情绪.实验者共有49种不同的离散情绪(如活跃、平静、快乐、困倦等),间隔时间从1分钟到几天不等.研究人员通过结合各种信息源(如位置和其他标签)对自我报告的数据进行处理,以使其可靠.
传感器的测量记录为每分钟20秒,数据收集周期为每个人3 到9 天不等.各实验者的样本数量从1164 到6263 不等.数据集包含二元变量和连续变量.总的来说,这些特征可以分为以下几类:
(1)运动数据:包含了3 个智能手机传感器(一个加速计、一个陀螺仪和一个磁强计)和2个智能手表传感器(一个加速计和一个指南针)的原始测量值计算出的138个特征.这些是连续变量;
(2)声音数据:包含了28 个原始特征,计算为13个Mel频率倒谱系数的平均值和标准差.
(3)位置数据:包含了根据每分钟人员的相对位置和运动变化测量的17个位置特征.
(4)手机数据:包含了28 个指示手机感知状态的二进制功能,例如应用程序状态、电池插入、电池状态、铃声模式、手机上、Wi-Fi 状态、屏幕亮度和电池电量.
(5)环境数据:包含了6 个环境变量,例如光、压力、湿度和温度.但是存在许多缺失值,因为并非所有手机都具有所有传感器.
(6)时空数据:从记录的时间戳中设计了5 个变量来表达情绪状态和转换的时间模式.由于数据集非常稀疏,我们计算了分钟变量的时间差,以测量自上次记录以来经过的分钟数.其余4 个变量是分类变量.
(7)上下文数据:包含了51 个二元上下文标签,如室内,室外,饮食,和在车里,可以帮助识别主导情绪.
(8)情绪数据:包含了49 个标签,如活跃、恐惧、警惕、愤怒等.
2.2 情感模型
情绪识别领域通常使用离散的情感模型和多维的情感模型来有效的对情感进行度量.离散情感模型使用诸如快乐、恐惧、愤怒、悲伤等标签来表示独立的情感.该模型特点简单直观,但表示的情感范围有限,同时由于情感类别之间存有相似性,其难以进行表达及度量.为了解决上诉问题,研究者建立了多维的情感模型,利用多个维度的连续数值来描述情感的状态,ORTORY 等人提出的OCC(Ortory-Clore-Collins)模 型[14]和 MEHRABIAN 和RUSSELL 提出的 PAD 模型[15]是目前使用最广泛的模型.其中PAD 可以连续的描述情感,本文采用的是PAD模型.
PAD 模型开发于1974年,用于评估个人对环境感知和体验的心理反应.人的情绪状态可以从三个基本维度来感知:愉悦、唤醒和支配.快乐是积极或消极情绪的维度.唤醒代表心理反应状态.支配是受影响或控制的感觉的知觉认知维度[16].本文研究包括情绪状态的所有3 个维度.基本能够区分日常生活中的所有情感.
2.3 数据处理
2.3.1 数据准备及清洗
数据集中有18 名实验者的样本含有情绪数据超过1000 个,缺失数据不到90%.因此,本文研究中以该18个实验者的数据构成情绪转化数据集,数据集中共有49个离散的情绪标签,使用英语单词情感规范(ANEW)将49 个离散的情绪标签映射到PAD模型的愉悦(P)、兴奋(A)和支配(D)3 个维度 .ANEW 是由情绪和注意力研究中心开发的为研究情绪和注意力的研究者提供的标准.最新的数据库包含了近14000 个英语单词的情感含义,由1827 名参与者评分,他们的年龄、职业和教育程度各不相同.数据集中每个语言情感标签被转换成3 个维度的连续值,取值范围在1 到9 内,其中1 和9 分别表示在相应的PAD 维度中的最低和最高强度[17].通过分别计算三个维度的绝对值最大值来决定一个人在任何时间点的主要情绪维度,然后,根据绝对值最大值的正负性考虑将愉悦分为不和谐、高兴2 种情绪状态,兴奋分为劝阻、唤醒、2 种情绪状态,支配分为顺从和支配2种情绪状态.按{1,2,3,4,5,6}赋值,并设置为特征属性“emotion”,完成将文本的情绪标签映射为数值.
同时,删除了数据集中缺失数据达到80%的特征,以及地理位置数据.缺失值都被一个大的负数代替以表示缺失,并通过去除均值和缩放到单位方差来标准化特征.最后原始数据共有104个特征,其中标签类数据为19个.
2.3.2 重采样
由于数据稀疏,目标变量过于不平衡.在原始数据中,每5 分钟间隔的样本数从0 到5 不等.本文的研究旨在检测较小时间间隔内的情绪转变和状态.因此,我们以每5分钟采样一次的频率重新采样所有数据.在重采样过程中,本文通过取5分钟的间隔内所有连续特征的平均值、所有二元特征的总和以及有顺序特征值的最大值来作为样本.
2.3.3 情绪变化处理
对于情绪转换检测,我们考虑了前一个窗口的特征变化 .因此,任意时刻 t 的特征集 Tt,k计算如公式(1):

特征总数为n,ft,k表示第t个窗口第k个特征的值.情绪转换检测是一个二元分类问题,根据“emotion”字段,本文增设”emotion_change“属性,其中0和1分别表示在过去5 分钟内情绪状态没有变化和变化.”emotion_change“即是本文的预测值.
3 基于FDCN的情绪检测模型
为了充分学习特征间的低阶、高阶交叉、非线性组合,本文提出了基于因子分解机、深度交叉网络的混合情绪变化检测模型FDCN 模型,充分挖掘大学生日常环境、行为等数据特征间的隐形关联,提高大学生情绪变化预测的准确性.
3.1 FDCN情绪变化检测模型框架
FDCN 模型由 embedding 层、FM 层、交叉层、深度网络层组成,其结构图如图1所示.

图1 FDCN模型结构图Fig.1 FDCN model structure diagram
其中FM 层负责低阶特征的交叉;cross 层负责高阶线性特征交叉,deep 层负责学习非线性的特征表达,充分挖掘特征关联,提高预测精度.combination层由各层的输出线性加权而成.
3.2 embedding层
考虑到数据集里的数据除传感器数据外,还含有大量标签类数据,如所在的环境是室内或者室外等.这些数据在数据集里采用的是one-hot 编码方式,在学习时会产生大量高维度的特征向量,为了减少特征的维数采用了embedding 层对这些标签类数据进行处理[18],embedding处理如公式(2)所示:

其中xembed,i是嵌入向量,xi是第i个标签数据的输入,它参数一起进行优化,ne,nv分别是嵌入层大小和词汇字典大小.
嵌入向量经过嵌入层后与经过连续特征归一化后合并形成下一层的输入如公式(3)所示:
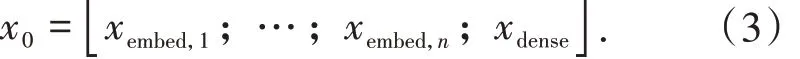
3.3 FM层
FM 层的作用是解决特征数据稀疏如何组合,其通过在线性模型中加入两个互相影响的特征组合,即将逻辑回归模型拓展成二阶特征交互,其预测值公式如公式(4)所示:

FM 模型借鉴了矩阵分解的思想,将二次项系数拆分为两个特征向量相乘的形式,解决特征数据高维度且稀疏的问题.其优化后如公式(5)所示:
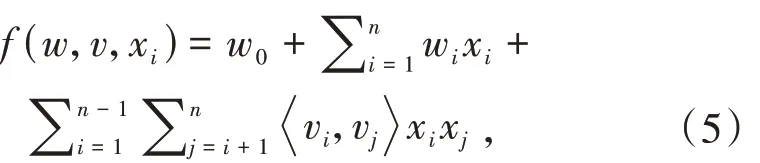
其中 vi,vj∈ Rn×k表示第 i 个和第 j 个特征对应的参数,向量内积公式(6)计算如下:
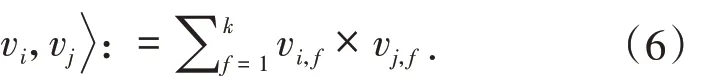
3.4 cross层
cross 层的作用是对特征进行显式交叉,交叉网络分为若干个交叉层,每一层的计算如公式(7)所示:
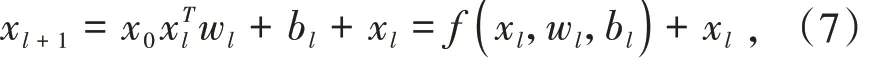
其中 wl,bl∈ Rd是第 L 层交叉网络的权重系数和偏置系数,xl,xl+1是列向量,分别表示第 L 层和第 L+1交叉层的输出.
3.5 deep层
deep 层由多层前馈神经网络叠加组成,负责提取输入特征之间的隐形关联,其每层输出隐变量由公式(8)计算:

其 中 hl为 第 L 层 的 输 出 ,hl∈ Rdl,hl+1∈ Rdl+1,Wl∈ Rdl×dl+1为第L层的权重矩阵,bl∈Rdl+1为第L层的偏执向量,f为激活函数.
3.6 组合输出层
组合输出层主要用于连接FM 层和cross层以及deep 层输出的向量并计算概率值.本文直接将三个网络输出的向量进行线性组合,然后用sigmoid函数计算概率值.在网络训练过程中,使用对数损失和正则化项.组合输出层组合三层的输出向量为公式(9):

预测值为公式(10):

σ 为sigmoid 函数,模型训练的损失函数为公式(11):
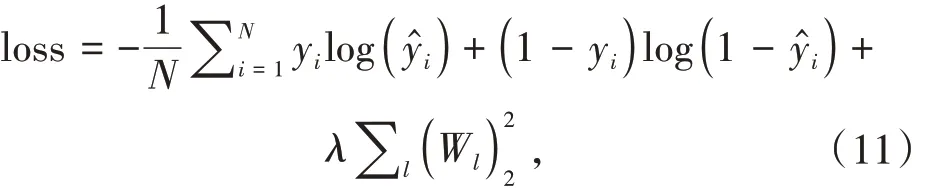
yi为真实值,N 为输入向量个数,λ 为正则化系数.RMES计算公式如公式(12)所示:

3.7 算法流程
算法流程如下所示.

images/BZ_107_237_2326_2242_2383.png输入:上下文环境数据、环境数据、手机数据、位置数据、声音数据、.运动数据、时间数据输出:情绪变化预测值步骤:1、对输入数据进行清洗、预处理、重采样;2、对输入标签类数据进行embedding处理;3、将连续特征和经过embedding处理后的特征拼接;4、将拼接好的特征送入FM层、cross层、deep层;5、对三层的输出进行线性加权;6、训练网络,利用反向传播调整各层的权重系数;7、得到预测值
4 实验结果与分析
4.1 评价指标
为了对以上分类模型进行评价,采用正确率(accuracy)、精度(precision)、召回率(recall)、F1 分数(F1Score)、AUC 进行评估,其计算公式如公式(13)、公式(14)、公式(15)、公式(16)所示:


其中,TP 为被分类器正确划分为正例的个数,FP 为被分类器错误的划分为正例的个数,TN为被分类器正确的划分为负例的个数,FN为被分类器错误的划分为负例的个数.
4.2 模型训练
本文的模型使用python3.6 在深度学习框架tensorflow2.0 上实现,使用的显卡是NVIDIA gtx 1080显卡.
将预处理好的数据作为FM 层、embedding 层的输入特征.模型超参数影响模型性能的主要有正则化、deep 网络层数及神经元的个数.通过表1,分析了超参数对实验结果的影响.

表1 超参数对精度的影响Tab.1 Influence of super parameters on accuracy
由表1 可知,正则化操作有效提高了模型的指标,网络层数和神经元的个数并非越多越好.综上,本文FCDC 模型设定的参数为deep 层网络设为2 层,神经元个数为128 个,层与层之间以全连接形式连接.embedding 层嵌入向量大小设置为4,cross层数为3,每层节点数为64 个,以全连接方式连接.输出层采用relu 激活函数,采用L1 正则化.学习率参数设置为0.001.
4.3 模型对比
为了验证本文提出的FDCN 模型在大学生情绪变化检测的有效性,首先将FDCN 模型与前述的deep&cross模型、FM模型和DCN模型进行比较,验证混合模型的效果.数据集采用交叉验证,将数据集划分为10 份,依次选用9 份作为训练集,余下一份作为测试集,实验10轮,以平均值为最终结果.图2所示是四种模型的损失函数对比图.

图2 各模型损失函数对比图Fig.2 Comparison diagram of loss function of each model
由实验结果可知,四种模型随着训练代数增加,损失函数都呈下降趋势,且都在第6次训练代数损失函数趋于稳定,其中FDCN模型表现最好,DCN次之.
各模型的RMES结果对比如图3所示:

图3 各模型RMES对比图Fig.3 Comparison diagram of RMES of each model
由图3 可知,随着训练迭代次数增加,各模型RMES 的值逐渐收敛,其中FDCN 模型收敛速度最快,DCN次之,FM表现较差.
为了进一步验证FDCN模型的有效性,将FDCN模型和以上模型与近几年在分类算法中应用比较多的树形模型Xgboost 算法和RandomForest(随机森林算法)进行比较.Xgboost 和RandomForest 两种算法均调用Sklearn 库实现,分别采用十折交叉验证方法以及网格搜索法选择两种算法的最佳超参数.对比结果如表2所示:

表2 模型对比Tab.2 Model comparison
实验结果表明,在算法执行时间上,传统的树形模型在中小型数据集上仍有一定优势,FDCN、deep&cross模型、DCN 模型等深度学习模型耗时均有所增加.FDCN 模型相较与单一的FM 模型、deep& cross 模型、DCN 模型在 ACC、Precision、Recall、F1等指标上均有提升,FDCN 模型和Xgboost算法的预测性能相似.由此可见,FDCN 模型通过FM 层获取低阶特征交叉、cross 层提取高阶特征有效的组合,deep 层学习高阶的非线性特征,三者组合具有较好的表现. 所以深度学习模型通过结合FM、embedding、cross 等特征提取机制可以实现更加丰富的类别特征表达,充分挖掘特征关联,在分类算法的精度上可以达到以传统树模型为基础的分类算法水平.
5 结语
大学生的情绪变化检测对高校的学生管理工作具有重要意义,传统的量表筛查反馈性差,脑电检测成本高昂.本文利用机器学习,提出了FDCN 情绪变化检测模型,通过在智能手机和智能手表感知的日常数据上训练,以深度交叉网络为基础,结合因子分解机充分学习特征的低阶组合和高阶组合以及非线性关系,可以及时、主动地检测大学生的情绪状态转换.本研究有助于减少传统筛查中对学生自我报告的依赖,实现对学生日常情绪的无缝跟踪及情绪异常变化的提前感知,具有较好的应用性.
