基于联邦学习的人脸检测研究
2022-07-01兰博钧陶青川
兰博钧,陶青川
(四川大学电子信息学院,成都 610065)
0 引言
在互联网与人工智能高速发展的今天,数据逐步成为了企业生产中不可或缺的生产要素,在企业业务发展愈发倚重数据的同时,政府和用户也愈发重视隐私数据的保护与合理利用。《2020年人脸识别行业研究报告》指出,人脸在日常生活中暴露度比较高,相较于其他人体生物特征更易于被动采集。这意味着人脸的信息更易于泄露,对个人可能会带来财产损失,对国家可能引发国家安全问题。对于此类问题,我国于2021年11月1日正式施行《中华人民共和国个人信息保护法》,以保护个人的数据信息权益。随着监管力度的不断加强,个人数据将慢慢形成一个个的数据孤岛,企业如果想利用大量数据来创造新的价值将面临更多阻碍。因此,如何平衡好数据利用与数据隐私保护两方面是企业当前亟待解决的一个难点。
谷歌的McMahan 等于2016年首次提出了联邦学习的概念,他们采用边缘服务器架构,先利用边缘的移动设备对本地数据进行计算,再将各个边缘节点计算的模型参数上传至服务器进行聚合,最后再将聚合的模型参数更新至用户的移动设备。这种方式既保护了个人隐私,又让割裂成一块块的孤岛数据得到了充分的利用。为了解决人脸数据隐私问题以及数据孤岛问题,本文采用联邦学习策略展开对人脸检测的研究,在训练过程中使用Fedavg 算法来进行模型参数的聚合,数据传输过程中通过Paillier算法来进行数据加密,同时对YOLOv5网络进行改进:引入卷积块的注意力模块(convolutional block attention module,CBAM)与快速非极大值抑制(fast non-maximum suppression,Fast-NMS)以提升神经网络模型对人脸检测的准确度和效率。
1 联邦学习
根据应用场景的不同,联邦学习的架构可以分为需要聚合服务器的网络与对等网络(P2P)的形式,本文采用需要聚合服务器的服务器-客户端架构模式,其架构模型如图1所示。根据数据类型的不同,联邦学习又分为:横向联邦学习(horizontal federated learning,HFL)、纵向联邦学习(vertical federated learning,VFL)和联邦迁移 学习(federated transfer learning,FTL),由于本文在不同客户端上的人脸数据的数据特征与标签是一致的,即数据特征在参与训练的客户端之间是对齐的,故采用HFL。HFL 的训练过程通常包括以下5步:

图1 联邦学习架构模型
(1)各个客户端接收服务器分发的初始化模型参数。
(2)各个客户端使用自己的本地数据集进行模型计算,计算后将其模型参数信息- ω使用同态加密、差分隐私等手段进行掩饰,再发送给服务器。
(3)服务器将收到的数据进行聚合。
(4)把服务器聚合后的结果下发给各个客户端。
(5)各个客户将收到的梯度进行解密,然后更新自身的网络信息进行新的训练。
1.1 联邦学习中的Fedavg
数据聚合过程中采用的Fedavg,分为梯度平均与模型平均两种。设ω为当前参数模型,为固定学习率,为训练数据的数量,表示第个客户端,为客户端数量,g为第个客户端在ω参数模型下进行本地训练得到的平均梯度。如果个客户端之间的数据满足独立同分布(IID),且满足的分布式梯度下降的前提。
如公式(1)与公式(2)所示,若服务器将新的模型参数ω或聚合各方梯度得到的加权平均梯度ˉ下发给客户端,那么称这种Fedavg 为梯度平均。
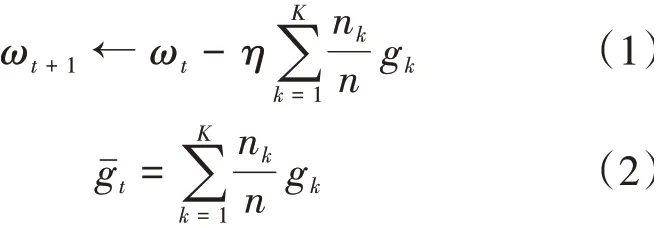
如公式(3)与公式(4)所示,如果客户端先在本地得到新的模型参数ω后,服务器再将这些模型参数进行加权平均得到新的平均模型参数ˉ并将其下发给客户端,那么称这种Fedavg为模型平均。在进行YOLOv5人脸检测的训练中便是采用了模型平均的方案。

1.2 Paillier算法加密
联邦学习是为了在保护数据隐私的情况下解决数据孤岛问题,除了需要训练数据本地化、私有化,同时要通过一些数据加密的手段来保护客户端与服务器之间传递的参数信息,因为这些参数的泄露也可能会导致训练数据或模型数据的泄露。常用的保护手段有同态加密与差分隐私,差分隐私可能会对训练数据造成噪声干扰,故本文采用同态加密的保护手段。
根据计算类型的不同,同态加密又可分为:部分同态加密(partially homomorphic encryption,PHE)、些许同态加密(somewhat homomorphic encryption,SHE)与全同态加密(fully homomorphic encryption,FHE)。其中PHE 是指只支持乘法或加法一种运算的加密算法;SWHE 是指可以同时支持乘法运算和加法运算,但是计算次数有限的加密算法;FHE 是指同时支持乘法运算和加法运算且计算次数无限的加密算法。基于达到减少加解密时间损耗的目的,采用了PHE中的加法同态加密算法Paillier。
Paillier 是1999年提出的一种可证的安全加密算法,在现代网络安全中有着广泛的应用。Paillier算法通常分为3步:
(1)生成公钥(,)与私钥(,),如公式(5)、公式(6)、公式(7)所示。其中、为随机生成的大素数,表示整数。

(2)对数据进行加密,得到密文,如公式(8)所示。
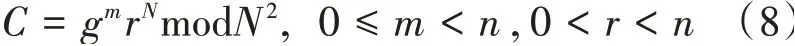
(3)对密文进行解密,得到明文,如公式(9)所示。
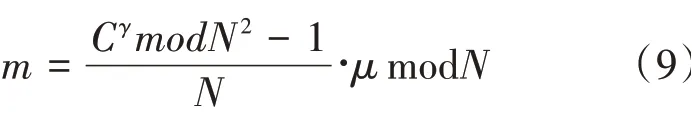
2 YOLOv5人脸检测算法改进
目标检测算法大致可以划分成两类,一类是以R-CNN 系列为代表的算法,它们一般需要两步,先采用Selective Search 或RPN 得到候选区域,再在候选区域中完成回归任务与分类任务;另一类则是以YOLO 系列为代表的算法,这类算法仅需要一次CNN 运算便可以找到目标的位置与类别。而YOLOv5 作为YOLO 系列最新的网络模型, 有着更为优异的性能。YOLOv5s 5.0 版本网络模型如图2 所示,主要由两个组件所构成:Head 和BackBone(Head 部分包括了以往YOLO 模型的Neck 和Head 两部分,YOLOv5代码上并没有将二者进行区分)。其中:BackBone 先获取人眼视觉对目标图像不能提取的深层信息,再由Neck 将这些不同层次的特征信息加工、融合,从而增加神经网络的表达能力,最后再通过Head 使用这些信息将图像上的目标种类及其位置预测出来。

图2 YOLOv5s 5.0版本网络模型
YOLOv5网络也有其特点:采用Mosaic 数据增强手段增加数据丰富度、锚定框可基于训练数据自动计算、输入图像放缩至标准尺寸以减少推理时的计算量、采用Focus结构将图像切片以减少FLOPS 和增加速度、借鉴CSPNet网络结构用以增强学习能力,使YOLOv5网络能兼顾轻量化和准确性两方面。
YOLOv5 共有s、l、m、x 四个版本,s 版本网络深度与特征图宽度最小,其他三个版本皆是在其基础上加深扩宽,考虑到需要快速检测以及后期会将网络部署到嵌入式设备上,本文选用s版本用做检测网络模型。
2.1 基于CBAM模块的网络改进
YOLOv5s 的BackBone 相较于其他轻量级网络来说具有网络复杂且深度大的特点,这种特点可能会导致网络提取的图像特征不平衡,因此采用加入CBAM 模块来聚焦重要信息同时抑制不重要的信息。深度学习中的注意力机制与人眼的选择性视觉机制类似,从复杂的信息中选出更为重要的进行关注,根据其关注的域可分为不同类型:层域、通道域、空间域、时间域、混合域,而CBAM 模块则是结合了通道域与空间域。
加入CBAM模块的改进如图3所示。
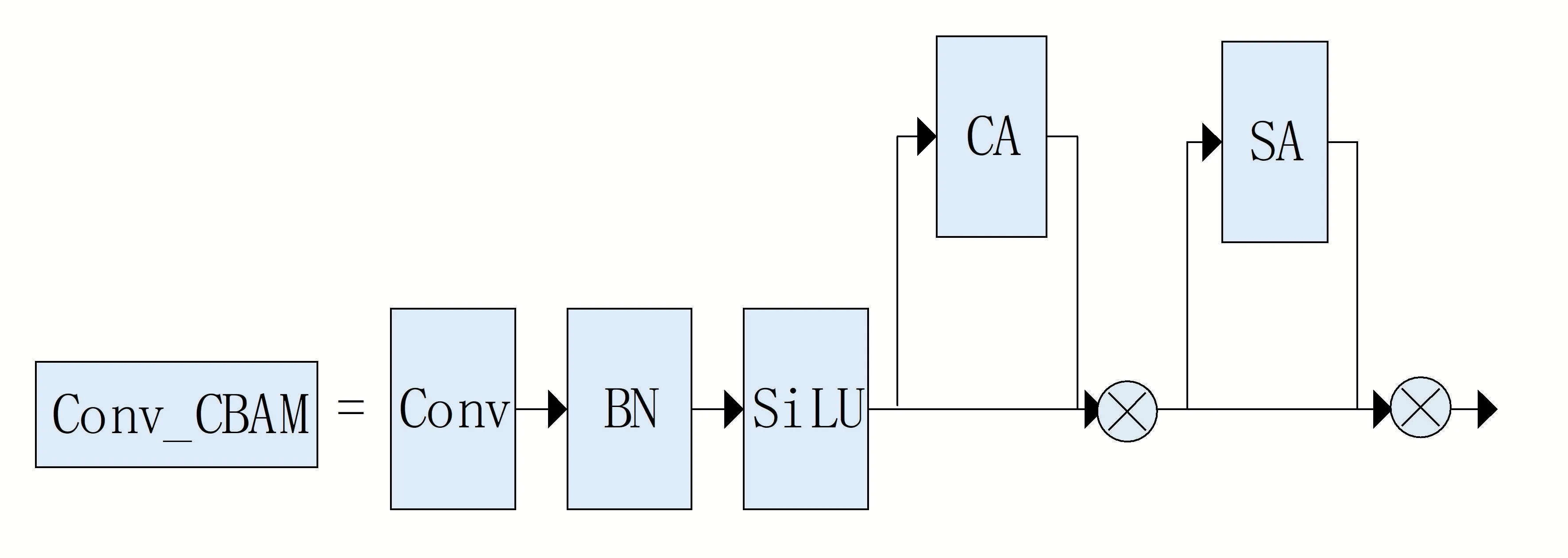
图3 改进后的Conv_CBAM 模块
将改进后的Conv_CBAM 模块去替代Back-Bone 中Focus 后面第一个与SPP 后面第一个CBS模块。CA 是指通道域的注意力机制,其策略如公式(10)所示,表示经过feature map 的输入,首先进行AvgPool 以及MaxPool,从而得到更丰富的高层特征,这里的F与F是经过全局平均池化与全局最大池化后的feature。再通过全连接层和激活函数来构建通道之间的相关性,这里的与是多层感知机模型中的两层参数,而表示sigmoid 激活函数。然后合并两个输出得到各通道的权重信息,最后再把权重与CA 输入的特征图相乘得到输出信息。其目的在于区分出特征图不同通道的重要程度并将其量化成权重的形式,从而聚焦更重要的通道。
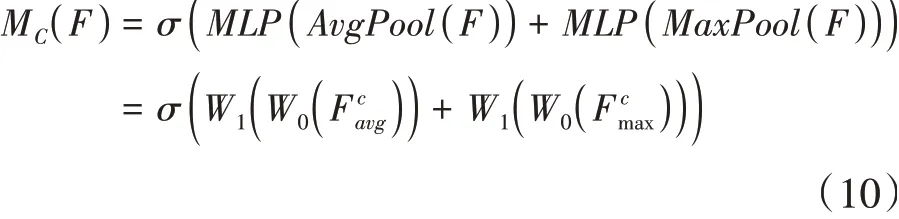
SA 是指空间域的注意力机制,其策略如公式(11)所示,它首先对通道维度进行全局最大池化以及全局平均池化,然后对其输出使用7*7卷积核进行卷积得到空间注意力特征图,最后将其与SA 输入的特征图相乘得到输出信息。其目的在于区分出特征图不同空间位置的有用程度并将其量化成权重的形式,从而聚焦特征图中更主要的空间位置。
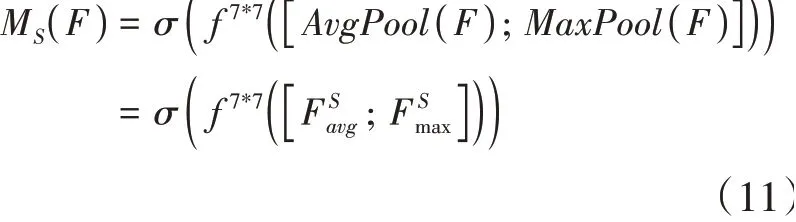
通过将CA 与SA 串行组合便可达到两种注意力机制互补的效果,最终形成CBAM模块。
2.2 基于Fast-NMS模块的网络改进
NMS 对于目标检测来说是一种常用的算法,其目的在于从网络最后输出的候选框中找到最佳的目标框。对于传统的NMS 来说,一般第一步先将候选框按照其分类得分从高到低排序,第二步保留得分最高的候选框,再分别计算其他候选框与保留框之间的,若大于阈值,则删除这个候选框,第三步则是对第二步操作进行迭代直至没有剩余候选框为止。

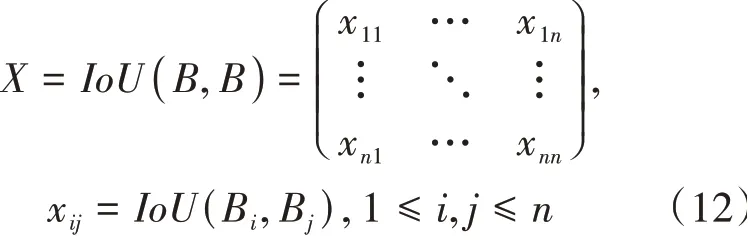
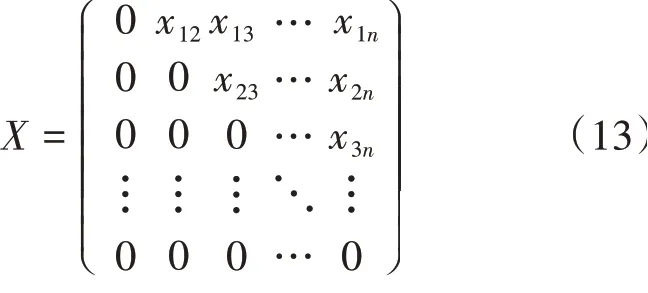
由于是对称矩阵并且不存在候选框与自身进行,故可对进行上三角化,如公式(13)所示。然后对矩阵的每一列取该列最大值,将最大值与设定的阈值进行比较,超过该阈值就将其滤除,最后剩下的便是结果。
3 实验结果与分析
本实验的人脸数据集大小为:训练集11976张,验证集4228 张,测试集3112 张,实验过程中共设置了4个客户端,故将训练集与验证集随机等分成四份并分别放置在4个客户端上,形成训练数据的独立同分布状态。将服务器与客户端的通信轮次设置成200轮,每轮通信时长上限为6 mins,如果服务器不能在规定时长内完成模型收集、模型聚合与模型下发三个步骤,则视为该轮通信失败,下一轮使用的模型参数以上一次参数为准。如图4 所示,在使用联邦学习后,训练的速度有所下降,同时网络模型的性能也略有降低,但是也能较好地趋近于未使用联邦学习策略时的模型性能,保证了YOLOv5人脸检测网络处于联邦学习策略下的可用性。

图4 性能比较
将加入CBAM 模块改进后的YOLOv5与未加的YOLOv5 进行对比,结果如表1 所示。可以看出,加入CBAM 模块后模型对人脸检测的准确率得到了一定的提升。
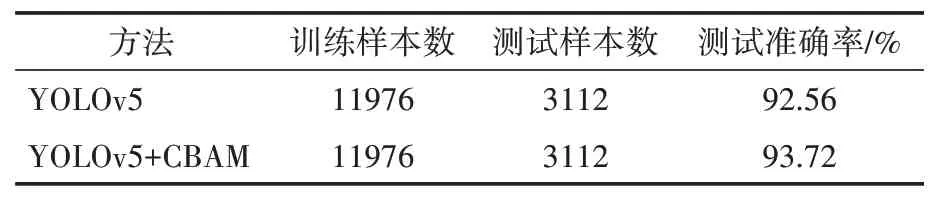
表1 两种模型的准确率比较
当网络将传统的NMS 模块改成Fast-NMS 模块后,模型检测时的总体时长有了一定的减少,可以达到我们预期的效果。测试时,设置成了每个batch 的batchsize 为688,平均每个batch 所耗时间如表2所示,其中torchvision.ops.nms()是官方库的实现,由于底层是用C++实现的,所以效果最好。

表2 测试耗时比较
4 结语
本文采用联邦学习策略来训练YOLOv5的人脸模型,使用Fedavg 算法将模型聚合并通过Paillier 算法把服务器与客户端通信过程中的数据进行加密,同时在YOLOv5 网络中引入CBAM模块与Fast-NMS 模块。实验结果表明,采用联邦学习的策略训练模型,在保证数据隐私安全的情况下有效地解决了数据孤岛问题,同时模型性能的损失在可控范围。而CBAM 模块与Fast-NMS 模块分别使得模型检测的准确度与效率有所提升。
