关于自然语言处理的对话
——冯志伟教授访谈录
2022-06-30冯志伟
自然语言处理(Natural Language Processing)是一门融语言学、计算机科学、数学于一体的学科,它以语言为对象,利用计算机技术来分析、理解和处理自然语言。可以说,语言文本和对话在各个层面上所广泛存在的歧义性或多义性(ambiguity),给自然语言处理带来了很大的困难。冯志伟先生是我国计算语言学的开拓者之一,出版、发表了一系列与自然语言处理相关的论著。他的《计算语言学基础》
、《数学与语言》
、《自然语言处理综论》
、《自然语言处理简明教程》
、《中文信息处理与汉语研究》
等专(译)著,在语言学界产生了深远影响,有力地推动了国内自然语言处理的发展。我们从学术之路、知识图谱、智能化、自动切词、发展方向等方面,就自然语言处理的几个关键性问题,对冯先生进行了专门访谈。
一、学术之路:走自己的路
徐琴(以下简称“徐”):冯先生,您好!首先非常感谢您接受我们的采访。您作为我国计算语言学和自然语言处理研究的开拓者之一,是世界上第一个“汉语到多种外语机器翻译系统”的研制者。那么,当初是由于什么原因让您弃理从文,毅然决定转向语言学的呢?您认为语言学最让您着迷的是什么?
冯志伟(以下简称“冯”):今天是2022年4月15日,恰好是我83岁生日。我从事计算语言学和自然语言处理的研究已经有60多年了。
1957年高中毕业时,同班同学送给我一本书:苏联科学院院士、著名地球化学家费尔斯曼的《趣味地球化学》
,书中描述了费尔斯曼使用地球化学方法在可拉半岛找到钾盐矿,从而解决了苏联社会主义建设的燃眉之急的事迹,给了我很大的鼓舞。当时地球化学是国家急需的尖端学科,我看了这本书,对地球化学产生了浓厚的兴趣,决心学习费尔斯曼,为祖国找到社会主义建设所需要的矿藏。于是我毅然报考了北京大学地球化学专业。后来,果然以优异成绩考入北京大学地球化学专业学习。
在地球化学专业,我学习了高等数学、普通物理学、普通化学、矿物学、结晶学等课程,打好了自然科学的基础。我特别喜欢做数学题,思考复杂的数学问题。我在一首诗里写道:
数学就像磁石一样,
吸引我走进逻辑的殿堂,
7.有穷多级列举法。这种方法把现代汉语中的全部词分为两大类:一类是开放词,如名词、动词、形容词等,它们的成员几乎是无穷的;另一类是闭锁词,如连词、助词、叹词等,它们的成员是可以一一枚举的。切词的时候,先切出具有特殊标志的字符串,如阿拉伯数字、拉丁字母等,再切出可枚举的闭锁词,最后再逐级切出开放词。这是一种完全立足于语言学的切词方法,在计算机上实现起来还有很大难度。
我似乎看到了自己思想的光芒。
我自幼就初通英语,能阅读英语的书籍,在北大图书馆的英文版《无线电工程师协会会刊:信息论》(I.R.E.Transaction of Information Theory)杂志上,我读到乔姆斯基(Noam Chomsky)在1956年发表的论文《语言描写的三个模型》(Three models for the description of language)。这篇文章是研究语言的,可是却使用了马尔可夫链(Markov Chain)这样的数学方法,乔姆斯基运用数学方法,为自然语言建立了有限状态模型、短语结构模型和转换模型三个不同的模型,并且分析了这些模型对于自然语言的描述能力和解释能力。
乔姆斯基使用的这种数学方法激发了我的好奇心,使我对语言学中的形式化方法产生了浓厚兴趣,萌发了强烈的探索愿望。接着,我又怀着兴奋的心情通读了乔姆斯基在1957年发表的《句法结构》英文本,对语言学的兴趣愈发浓厚了。于是我向学校教务处诚恳地表达了自己想改行学习语言学的志向。1959年9月,经北大教务处批准,我弃理学文,转入北京大学语言学专业(07591班)学习,从一年级学起,学号是5705006。这样,我就从理科的大学三年级转到文科的一年级,降了两级,成为了一个文科生。
当然,理科不管是在科研经费上,还是在就业前景上,都要比文科好得多。但是我当时根本没有考虑这些功利方面的问题,完全是出于用数学方法研究语言的兴趣,被强烈的兴趣所驱动。可以说,弃理学文是我人生的重要转折。这样的转折完全是出于对语言研究的好奇心,并没有任何的功利目的,可谓是好奇之心战胜了功利之心。
但是,在当时的条件下,这样的转折需要面对很多问题。
这时,那些少男少女也喝得差不多了,吉尔金娜显得有些扫兴,端着一杯酒说:“江,你太不给面子了,跑到哪里了?今天为我做了这么多好食品,我得好好敬你一杯。”江大亮说:“我出去有点事儿。”吉尔金娜不依不饶,江大亮只好一饮而尽,将那高脚杯的酒全都喝光了。柯察金也端着一杯酒过来了,舌头有些僵硬地说:“江,你太神奇了,过去吉尔金娜说你很有魅力,我还表示怀疑,今天我是亲眼见到了,你真的好神奇,很有魅力。”江大亮被俄罗斯那些少男少女团团围住,狂轰烂炸,没过一会的工夫就喝得有些晕晕乎乎。
矿区内侵入岩不发育,在矿区中部见有一辉绿岩脉,岩脉长度为700m,厚度为4m,产状354°~15°∠55°~70°,被F3、F4错断。本次工作在Ⅰ号矿体PD3050中段穿脉中发现绿泥石化阳起石化闪长玢岩脉(图4)。
第一,我从理科转到文科,目的是在于用数学方法研究语言,用数学的逻辑之美来揭示语言的结构之妙。这在当时看来是非常奇特的想法,创新性太强了,难以得到别人的理解,必定会遇到重重的阻力和冷漠的白眼,容易被人误解为“有资产阶级名利思想”。
第二,我在中文系学习中文的同时还学习数学,必定要比别人花更多的时间,难以腾出时间来关心政治,容易被人误解为“走白专道路”。
第三,为了了解国外用数学方法研究语言的信息,我在中文系学习中文的同时还要学习外文,需要经常阅读各种外文书,容易被人误解为“崇洋媚外”。
这些问题,开始转到中文系时我并没有想到,只是凭着用数学方法研究语言的好奇心努力学习,但是随着时间的推移,这些问题愈演愈烈,时时困扰着我。中文系的同学们不理解我,受到了同学们的鄙夷和白眼,日子越来越难过。我陷入了茕茕孑立、形影相吊的困境。
我曾经想打退堂鼓,回到理科去,但是,我想起意大利诗人但丁(Dante Alighieri)的话:“走你自己的路,不要管他人的毁誉!”这句话给了我无穷的力量,鼓舞着我,让我在众人的白眼中坚持下去。转入中文系之后,我除了学好学校规定的中文系各门课程之外,还进一步苦练英语,大量阅读外文的文学作品。
[8]兰平:《汉学“典范大转移”与“新汉学”的来龙去脉——陈珏教授访谈录》,《文艺研究》2014年第10期。
这个时期,我师从王力、朱德熙、林焘、高名凯、岑麒祥、周有光等著名语言学家,学习了语言学的基础知识。王力讲授“古代汉语”“汉语史”“中国语言学史”,朱德熙讲授“现代汉语研究”,林焘讲授“语音学研究”,高名凯讲授“普通语言学”,岑麒祥讲授“西方语言学史”,周有光讲授“汉字改革概论”。我认真学习这些语言学课程,学习成绩优异。我试图把自己由一个理科学生转变为一个会用人文科学方法来思考的文科学生,把人文科学的知识与自然科学的知识结合起来。
为了运用数学方法研究语言,我除了学习语言专业的课程之外,同时也学习数学分析、集合论、数理逻辑、实变函数、复变函数、微分方程等数学系的课程。我在课余做完了苏联数学家吉米多维奇《数学分析习题集》
中的4000多道数学题,练就了解决复杂数学问题的能力。我的这些表现不合时俗,在同学中颇有微词。
同时学习文科、理科和多门外语几乎占据了我的全部时间,体育锻炼也要用去一定时间。我实在没有更多的时间来关心政治了,这在当时是很严重的问题,受到了很多指摘和批评。有人指摘我是“孔子学生妄图继承牛顿事业”,有人批评我“走白专道路”,“有资产阶级名利思想”,“崇洋媚外”。实际上,我只是出于科学的好奇心才这样专心致志,并没有像别人想得那么恶劣。我根本就没有功利的动机!但是,在当时的气氛下,我是有口难辩,只好忍气吞声,夹着尾巴过日子。
1964年,我考取了岑麒祥教授的研究生,学号是6407903,终于可以名正言顺地用数学方法来研究语言了,岑麒祥教授也同意我的研究生毕业论文为“数学方法在语言学中的应用”。可是,1966年5月爆发了“文化大革命”,我不可能再继续进行这样的科学研究了。1968年,我被北京大学扫地出门,先是到天津河东区教初中,后来回到了故乡昆明教中学。昆明地处边陲,在那里,北大老师们教给我的那些高大上的语言学知识基本上没有什么用处,我只好改行当了一名物理教师,聊以维持生计。我彻底地离开了语言学的队伍。
NELL还可以使用知识图谱进行简单的逻辑推理。例如,从知识图谱中知道,“Maple Leafs”球队所在的城市(home town)是多伦多,而多伦多所在的国家(country)是加拿大,因此,可以推论出这个球队所在的国家也是加拿大。其逻辑推理过程如下:
家访是教师、家长、学生之间的纽带,是学校、家庭、社会之间的桥梁,在学校教育中发挥着不可替代的作用。事实证明,家庭访视是有效的教育措施。随着时代的变迁,一种新的家庭交流方式出现了。它不仅是家访的辅助手段,而且是家访的补充。它已经成为学校、家庭和社会三结合教育的一种新方式。学校认识到家长在监督、理解、宣传和协调学校日常管理中的作用,本校因势利导地响应家长需求,开放校园,鼓励并欢迎家长的参与学校学习和生活,本校采取教师主动家访与请家长到学校来校访的方式,加强了家校沟通,优化了教育方式。
知识图谱用结点(vertex)表示语义符号,用边(edge)表示符号与符号之间的语义关系,由此构成了一种通用的语义知识形式化描述框架。知识图谱中的三元组用(h,r,t)表示,其中,h表示“头实体(head)”,r表示“关系(relation)”,t表示“尾实体(tail)”。知识图谱的三元组结构其实非常简单,可以表示为:(head,relation,tail);用首字母表示就是:(h,r,t)。这种表示方法简单、明确、有效。
二、知识图谱:自然语言处理的宝库
徐:您的学术之路确实是走得无比坎坷,但也真是非同寻常。在那样艰辛的环境中,您仍然保持一颗向学之心,能静下心来从事学术研究,真是令人钦佩!您无疑是我们年轻人学习的楷模!在现代社会,技术飞速发展,网络媒体已经渗透到我们生活的方方面面。人类进入了大数据时代,让计算机在这些庞杂的大数据中有效提取信息,建立知识库,为用户提供精准的信息服务,已成为信息服务的核心目标。可以说,知识图谱(knowledge graph)的出现,有助于计算机实现这一目标。不过,在我们的汉语中却有很多深层的语义关系,仅仅依靠知识图谱中传统的知识元素(实体、关系、属性)抽取技术和方法是远远不够的。那么,您认为,在知识抽取中,对于这些隐含关系的抽取,计算机应如何实现呢?
冯:早在50年前,1972年的文献中就出现了“知识图谱(knowledge graph)”这个术语。2012年5月,谷歌公司(Google)明确提出了知识图谱的概念,并构建了一个大规模的知识图谱,开启了知识图谱研究之先河。
我这一生过得很辛苦,由理科转到文科,又从文科转到理科,最后又从理科转回到文科。岁月蹉跎,青春难再,一生中的很多宝贵时间,都在苦苦的挣扎中煎熬。刚入北京大学的时候,我还是一个18岁的幼稚青年,而今我已经是83岁的垂垂老者,只能发挥余热了。现在你们年轻人处于开明盛世,不会再重蹈我的覆辙了。我真羡慕你们!
在计算机中,结点和边这样的符号,都可以通过“符号具化(symbol grounding)”的方式,来表征物理世界和认知世界中的对象,并作为不同个体对认知世界中信息、知识进行描述和交换的桥梁。知识图谱这种使用统一形式的知识描述框架,便于知识的分享和学习,因此,受到了自然语言处理研究者的普遍欢迎。
综上所述,建筑行业随着我国的经济发展,也得到了很大程度上的发展,并且企业之间的竞争越来越激烈,因此,为了不断地促进建筑行业的发展,要不断完善其中的应用技术,保障施工工作的顺利进行。
例如,美国卡内基梅隆大学基于“Read the Web”项目研制出NELL知识图谱,NELL的英文含义就是“Never-Ending Language Learning”(永无止境的语言学习)。NELL每天不间断地执行两项任务:自动阅读(Reading)和自动学习(Learning)。自动阅读任务是从Web文本中获取知识,并把阅读到的知识添加到NELL的内部知识库中;自动学习任务是使用机器学习算法获取新的知识,巩固和扩展对于知识的理解。NELL可以抽取大量的三元组,并标注出所抽取的迭代轮数、时间和置信度,还可以进行人工校验。NELL系统从2010年开始机器自动学习,经过半年的学习之后,总共抽取了35万条实体关系三元组。经过人工标注和校正之后,进一步抽取更多的事实,知识抽取的正确率可以达到87%。这里不妨以图1为例加以说明:
在OPNET Modeler仿真环境下,对科文学院现有校园网在开通视频点播系统前后分别从网络时延、数据库应用和HTTP应用的响应时间、主干链路排队时延、主干链路吞吐量及利用率等多个网络性能指标进行了分析比较,得出主干链路速率是科文学院现有校园网性能的“瓶颈”,为拟定网络升级改造方案提供了客观的定量依据.根据科文学院校园网的实际情况,提出了采用链路聚合为主要手段的校园网升级改造方案,仿真结果显示校园网的性能有了较大的提升.由此得出结论:方案切实可行,能够达到校园网升级改造的预期目标.
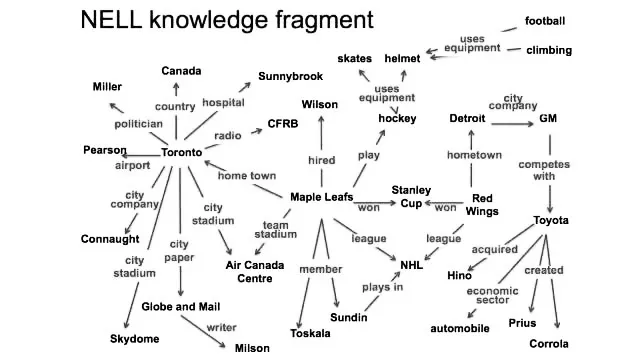
图1是NELL抽取的有关“Maple Leafs(枫叶)”球队的知识片段,该片段由很多三元组构成。例如:
(Maple Leafs,play,hockey)
(Maple Leafs,won,Stanley Cup)
(Maple Leafs,hired,Wilson)
(Maple Leafs,member,Toskals)
Boosting算法问题在于更多关注不能正确分类样本数据,对于边界样本会导致权重失衡,产生“退化问题”。在Boosting基础上使用指数权重产生用于二值分类的AdaBoost算法[28,29]。
(Maple Leafs,member,Sundin)
阅读推广视角下的品牌品质是指阅读推广的活动质量。品牌认知的评估首先要设计品质评估要素,比如活动设计的形式是否具有创意性、阅读内容是否吸引读者、活动是否让读者有所获等。然后通过问卷等不同的评估方式和多样的评估渠道进行读者评估。值得注意的是,会存在一些因素因读者个体的个性、爱好、自身素养程度等不同对品质的感受不同,所以品质认知评估结果只是一个方向性的评估成果。
(Maple Leafs,home town,Toronto)
(Toronto,country,Canada)
从这些三元组中可以知道,“Maple Leafs”这个球队是打(play)曲棍球(hockey)的;这个球队曾经获奖(won),得过Stanley奖杯(Stanley Cup);这个球队的雇主(hired)是威尔森(Wilson);这个球队的成员(member)有托斯卡尔思(Toskals)和孙定(Sundin);这个球队所在的城市(home town)是多伦多(Toronto);而多伦多所在的国家(country)是加拿大(Canada)。这就构成了一个非常复杂的知识系统。
粉碎“四人帮”后,我有机会于1978年考入中国科学技术大学研究生院学习理科;接着,又公派到法国格勒诺布尔理科医科大学应用数学研究所留学。我在法国研制了世界上第一个把汉语自动地翻译成法语、英语、日语、俄语和德语五种外语的机器翻译系统。可以说,国家改革开放政策的实施,使得我有机会回到科学研究岗位,成为一名软件工程师。1985年,由于国家的需要,我被调入语言文字应用研究所,继续从事语言学研究。
在智能对话系统中,当用户提问:“冯志伟出生的时候,乔姆斯基的年龄有多大?”对于这样的问题,仅仅依靠直接查询知识图谱中的三元组,是很难回答的,它属于隐含的知识,必须进行逻辑推理才可能获得。
→(Maple Leafs,country,Canada)在上面的逻辑推理式子中,“∩”是逻辑合取符号,表示“和”的意思。
NELL通过机器学习的方式以构建知识图谱,从而可以持续不断地从网络上获取资源来发现事实并总结规则,其中,就涉及到命名实体识别、同名排歧、智能推荐等自然语言处理的技术。
如果我们具有了数以亿计的这样的知识图谱的三元组知识,还可以使用它们进行逻辑推理,从而获得一些隐含的知识。例如,如果我们有了关于冯志伟和乔姆斯基出生年代的三元组:
(冯志伟,出生年代,1939)
(乔姆斯基,出生年代,1928)
(Maple Leafs,home town,Toronto)∩(Toronto,country,Canada)
如果有了知识图谱的上述三元组信息,根据冯志伟出生时乔姆斯基的年龄应当等于冯志伟的出生年代减去乔姆斯基的出生年代这样的数学规律,即:1939-1928=11,我们就可以根据知识图谱推论出:冯志伟出生时乔姆斯基的年龄应当是11岁。这样,我们就可以从知识图谱中存储的旧知识中推论出新的、隐含的知识,从而回答“冯志伟出生的时候,乔姆斯基的年龄有多大?”这样很难直接在知识图谱中查询的问题。由此可见,知识图谱的三元组结构化信息不仅能够存储知识,还可以进行逻辑推理,从而产生出新的、隐含的知识,它确实是人类知识的宝库,是人工智能发展的阶梯,是非常有价值的。
目前,知识图谱仍处于初级阶段,如何自动地使用知识图谱的方法来获取自然语言中隐含的各种语法、语义、语用知识,还需要我们进一步探讨。
三、智能化:实现由直觉到理性的转变
徐:也就是说,知识图谱是一种描述知识的图,从不同模态(语音、图片、文本)的自然语言(人类使用的语言)中,抽取出有意义的知识,并转换成计算机理解的形式,从而使计算机具备一定的推理能力。不得不令人感叹,当代社会的技术发展如此迅速,自然语言处理也迈向了新的征程。那么,您认为,在将来的自然语言处理中,计算机能否像人类一样发展出逻辑推理能力?如果可以做到的话,您认为需要我们做哪些方面的努力?
8.联想—回溯法(Association—Backtracking Method,简称“AB法”)。这种方法要求建立三个知识库:特征词词库、实词词库和规则库。首先,将待切分的汉字字符串序列按特征词词库分割为若干子串,子串可以是词,也可以是由几个词组合而成的词群;然后,利用实词词库和规则库,将词群再细分为词。在切词时,需要运用一定的语法知识,建立联想机制和回溯机制。联想机制由联想网络和联想推理构成,其中,联想网络描述每个虚词的构词能力,联想推理利用相应的联想网络来判定所描述的虚词究竟是单独成词还是作为其他词中的构词成分。回溯机制则主要用于处理歧义句子的切分。联想—回溯法虽然增加了算法的时间复杂度和空间复杂度,但是这种方法的切词正确率较高,是一种行之有效的方法。
①大量的观测数据表明,全球气候正在发生以全球变暖为主要特征的变化;这种变化除了气候系统的本身自然周期变化外,人类活动排放的大量温室气体是气候变化的重要原因。
花桥板栗:于2016年9月采收于湘潭市雨湖区云湖桥镇金湖良种板栗示范推广基地,要求外观品质均一、成熟度适中、无病虫害。
目前,基于神经网络和深度学习的自然语言处理,基本上还是在系统1的基础上进行的,主要依靠大规模或者超大规模的数据来支持,有的自然语言处理系统的数据参数已经到达数千亿之多,这样的自然语言处理系统具有很强大的处理能力。例如,根据最近WMT(国际机器翻译评测会议)的评测结果,英汉神经机器翻译系统对于一般文本的翻译正确率已经达到83%以上,基本上可以满足普通用户的要求了。可惜的是,系统1的效率虽然较高,但是它的可解释性很差,基本上还是一个黑箱(black box)。我们对于系统1的研究,还处于“知其然而不知其所以然”的水平。
今后,自然语言处理研究需要从系统1的深度学习发展到系统2的深度学习,实现系统2的逻辑分析和推理功能。这除了需要大规模数据(big data)的支持之外,更需要丰富知识(rich knowledge)的支持,这些知识不仅包括语言学知识(linguistic knowledge),还包括日常生活中的普通常识(common knowledge)。系统2的知识如何融入系统1中,是一个相当复杂的问题,目前还没有找到有效的途径,上文中所提到的知识图谱这一形式化的方法,是我们目前正在探索的一个可行的途径。可以说,语言学家有必要学习知识图谱,更新自己的知识观念,把知识图谱应用到语言的研究中,或许会有所突破。
四、自动切词:多种方法并存
徐:这样看来,如果说语言是人类学习、思维的一个工具,那么,知识图谱则是计算机学习的工具。在自然语言信息处理中,不仅仅包括对于信息的抽取,自动分词也是重要的组成部分:语言信息处理必须以词为基本单位,然后才能进行句法、语义分析。英语等西方语言的词与词之间在书面上是用空格分开的,一般不存在分词问题。不过,由于汉语自身的独特性,在机器自动分词上存在着很大的困难。在汉语中有这样一类现象:字段AB,组合起来是词,分开也是词。比如,“她将来想当老师”中的“将来”是一个词,不能切分;在“她将来北京”中,“将来”却应该切分为“将/来”。那么,您认为,在语言信息处理时,可以采取哪些措施来解决这种有歧义的切分字段?在中文信息处理领域,关于自动分词技术还有哪些可以采用的方法呢?
冯:这里首先需要申明的是,我并不喜欢使用“自动分词”这个术语,而更愿意使用“自动切词”这个术语。因为“分词”容易与英语中的“participle”这个术语混淆,而participle是英语中非定式动词的一种形式。participle既有动词的作用,又可起形容词的作用,如“现在分词(present participle)”“ 过 去 分 词(past participle)”等,与我们所讨论的“自动切词(automatic word segmentation)”是完全不同的概念。
你所说的“将来”这个字段,属于多义组合型歧义切分字段,这种歧义切分字段是由词与词之间的串联组合产生的。从形式上说,在字段S=a
…a
b
…b
中,由于a
…a
、b
…b
和S三者都能分别成词,字串a
…a
与字串b
…b
形成了串联组合,就会产生歧义切分。“将来”“将”“来”三者都可以分别成词,因而产生歧义。对于这样的多义组合型歧义切分字段,可以根据句法知识进行切分。例如,在“她将来想当老师”这个句子中,动词“想当”是中心动词,因此,前面的“将来”应当是表示时间的时间词,不能切分。而在句子“她将来北京”中,中心动词是“来”,前面的“将”是表示时态的副词,因此,应当切分为“将/来”。根据这些句法知识,不难进行正确的判定。此外,如“马上”这个字段可以切分为“马上”“马”“上”,三者都可以分别成词,也是一种多义组合型歧义切分字段,同样会产生切分歧义。至于在语言信息处理时,如何解决这种有歧义的切分字段,可参看我所撰写的《自然语言处理中的歧义消解方法》
一文。
从上世纪80年代开始,我国学者就对汉语书面文本的自动切词进行了深入探讨。关于这一问题,可参看奉国和、郑伟的《国内中文自动分词技术研究综述》
。归纳起来看,国内学者提出的方法主要有以下几种:
1.最大匹配法(Maximum Matching Method,简称“MM法”)。在计算机中存放一个已知的词表,这个词表称为“底表”;从被切分的语料中,按照给定的方向顺序截取一个定长的字符串,通常为6至8个汉字,这个字符串的长度称为“最大词长”。把这个具有最大词长的字符串与底表中的词相匹配,如果匹配成功,就可以确定这个字符串为词,计算机程序的指针向后移动,与给定最大词长相应个数的汉字继续进行匹配;否则,则把该字符串逐次减一,再与底表中的词进行匹配,直到成功为止。MM法的原理简单,易于在计算机上实现,时间复杂度也比较低。不过,最大词长的长度较难确定,如果定得太长,则匹配时花费的时间就多,算法的时间复杂度明显提高;如果定得太短,则不能切分长度超过它的词,导致切分正确率降低。
2.逆向最大匹配法(Reverse Maximum Matching Method,简称“RMM法”)。这种方法的基本原理与MM法相同,不同的是切词时的扫描方向。如果说MM法的扫描方向是从左到右取字符串进行匹配,RMM法的扫描方向则是从右到左取字符串进行匹配。实验表明,RMM法的切词正确率比MM法更高一些。但是,RMM法要求配置逆序的切词词典,这样的词典与人们的语言习惯不相符合,修改和维护都不太方便。
3.逐词遍历匹配法。这种方法是把词典中存放的词按由长到短的顺序,逐个与待切词的语料进行匹配,直到把语料中的所有的词都切分出来为止。由于这种方法要把在词典中的每一个词都匹配一遍,需要花费很多时间,算法的时间复杂度相应增加,因此,切词的速度较慢,切词的效率不高。
4.双向扫描法。分别采用MM法和RMM法进行正向和逆向的扫描与初步的切分,并将用MM法初步切分的结果与用RMM法初步切分的结果进行比较。如果两种结果一致,则判定切分正确;如果两种结果不一致,则判定为疑点。这时,或者结合上下文有关的信息,或者进行人工干预,选取一种切分作为正确的切分。不过,这种方法也存在一定问题:一是要进行双向扫描,时间复杂度增加;二是切词词典要同时支持正向和逆向两种顺序的匹配与搜索,词典的结构比一般的切词词典要复杂得多。
5.最佳匹配法(Optimum Matching Method,简称“OM法”)。在切词词典中,按照词的出现频率的大小排列词条,高频率的词排在前,低频率的词排在后,从而缩短查询切词词典的时间,加快切词的速度,使切词达到最佳效果。这种方法对于切词的算法没有什么改进,只是改进了切词词典的排列顺序,它虽然降低了切词的时间复杂度,却没有提高切词的正确率。
6.设立切分标志法。书面汉语中的切分标志主要有两种:一种是自然的切分标志,如标点符号,词不能跨越标点符号而存在,标点符号必定是词的边界之所在;另一种是非自然的切分标志,如只能在词首出现的词首字、只能在词尾出现的词尾字、没有构词能力的单音节单纯词、多音节单纯词、拟声词等,词显然也不能跨越这些标志而存在,它们也必定是词的边界之所在。如果我们搜集了大量的这种切分标志,在切词时,先找出切分标志,就可以把句子切分成一些较短的字段;然后,再采用MM法或RMM法,进一步把词切分出来。使用这种方法切词,不仅要额外消耗时间来扫描切分标志,而且还要花费存贮空间来存放非自然的切分标志,使切词算法的时间复杂度和空间复杂度都大大增加,而切词的正确率却不能提高。因此,采用这种方法的自动切词系统很少。
就像在黑暗中电光一闪,
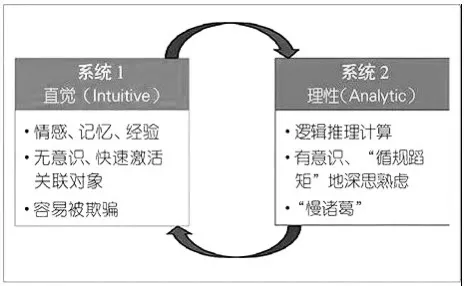
冯:在认知科学(cognitive science)中,有一个著名的“双过程理论”。该理论认为,人类的认知可以分为两个系统:系统1和系统2。其中,系统1是基于直觉的(Intuitive-based)系统,系统2是基于分析的(Analytic-based)系统。系统1进行“快思维”,是建立在直觉基础上的、无知觉的思考系统,其运作依赖于经验和关联。它的基本功能是激活感知、情感、记忆、经验等相关对象,这些都是无意识的、可以快速激活的对象,并把激活的信息构成一个和谐的事件。这将导致系统1很容易被欺骗,只要相关对象是和谐的,系统1就认为是正确的。因此,系统1可以自动地、轻易地、快速地相信任何东西,容易造成误判。而系统2进行“慢思维”,是人类特有的逻辑思维能力。它利用工作系统中的知识,进行慢速而可靠的逻辑推理,需要意识控制,进行循规蹈矩的深思熟虑,是人类高级智能的表现。它的基本功能是数学计算和逻辑推理,进行有意识的判断和推理,就像一个“慢诸葛”。系统2可以改变系统1的工作方式,彼此之间进行协调,从而修正系统1的误判。系统1与系统2的协调关系,可如图2所示(见下页):
STZ 诱导的小鼠糖尿病模型在早期阶段会产生氧自由基,如超氧阴离子自由基(• O2-)、过氧化氢(H2O2)、羟自由基(• OH)等会引起小鼠体内促氧化剂和抗氧化剂失衡导致氧化应激,并与 NO 途径相互作用导致 β 细胞破坏,引起糖代谢紊乱[7]。
9.基于词频统计的切词法。这种方法利用词频统计的结果来帮助在切词过程中处理歧义切分字段。例如,AB是一个词,BC是另一个词,如果词频统计的结果表明BC的出现频率大于AB的出现频率,那么,在处理歧义切分字段ABC时,就把BC作为一个单词,A作为一个单词,而排斥AB作为一个单词的可能性,也就是把ABC切分为A/BC。这种方法的缺点是,由于只考虑词频,出现频率较低的词总是被错误地切分。
10.基于期望的切词法。这种方法认为,当一个词出现时,它后面紧随的词就会有一种期望,根据这种期望,在词表中找出所对应的词,从而完成切分。这种方法增加了切词的空间复杂度,但在一定程度上提高了切词的正确率。
此外,还有基于专家系统的切词法和基于神经网络的切词法,可以说,利用人工智能的方法来进行汉语书面语的自动切分,也取得了较好的成绩。
在上述切词方法中,MM法、RMM法和逐词遍历法是最基本的机械性的切词方法,而其他方法都不是纯粹意义上的机械性的切词方法。在实际的汉语书面语自动切词系统中,一般都是几种方法配合使用,以此达到最理想的切词效果。
五、发展方向:经验主义和理性主义相结合
徐:冯先生,听了您的解释,真是令人茅塞顿开。在进行自然语言处理时,将汉语语法运用到其中,给可能会出现歧义的情况加上限制条件,这样才能使计算机明白应如何进行自动切词。同时,也十分感谢冯先生为我们总结了自动切词技术可以采用的主要方法。接下来,请您谈谈是如何评价自然语言处理领域的研究现状的;您认为,这个领域今后应当朝什么方向继续努力?
冯:在自然语言处理领域,我国已经在以大数据驱动的深度学习和神经网络方面取得了可喜的成绩,在语音识别、语音合成、汉字识别、机器翻译等应用领域已经实现了商品化,自然语言处理的研究成果可以造福于人类。这是经验主义方法的成就,值得高兴。但是,我们在以语言学知识驱动的深度学习和神经网络方面还刚刚起步,这是理性主义方法的不足。“道路阻且长”,我们还要继续努力,把理性主义的方法与经验主义的方法进一步结合起来。
国际著名语言学杂志《语言》(Language)2019年第1期刊登了美国学者Pater的文章《生成语言学和神经网络60年:基础、分歧与融合》以及该文的回应文章,重点讨论了基于连接主义方法的深度学习与语言学研究,特别是生成语言学研究之间的对立与融合关系。
陆游的地域书写,比其他作家受时空转换的影响更明显。钱钟书云:“至放翁诗中,居梁益则忆山阴,归山阴又恋梁益,此乃当前不御,过后方思,迁地为良,安居不乐;人之常情,与议论矛盾殊科。”在时间的流逝与空间的转变中,陆游关于梁益的地域书写在内容和情绪等方面都发生了不小的变化,而有些变化因记忆模糊或创作心态改变甚至会前后矛盾,虽非“议论矛盾”,却是许多细节或情绪上的矛盾。
Pater呼吁,应在神经网络研究和语言学之间进行更多的互动。他认为,如果生成语言学继续保持与神经网络和统计学习之间的距离,那么,生成语言学便不可能实现它对语言学习机制进行解释的承诺
。Linzen在他的回应文章中指出,语言学研究与深度学习可以相互促进。一方面,语言学家可以详细描写神经网络模型的语言学习能力,并通过实验加以验证;另一方面,神经网络可以模拟人类加工语言的过程,有助于语言学家研究内在制约条件的必要性
。
第一,时间分布图谱表明,在近10年的时间内,科研成果平稳增长,以政府机构改革为主题的研究主要采取定性为主,辅以定量分析的研究方法,研究成果主要发表在社科类基础研究和政策研究类刊物上。该研究领域现阶段正趋于稳定,多个学科的前沿定量研究方法正被引入,研究深度有加强趋势。
我赞同他们的意见,深度学习应当与语言学研究结合起来,基于语言大数据的经验主义方法应当与基于语言规则的理性主义方法结合起来,相互促进,相得益彰,从而推动自然语言处理的进一步发展。我们这一代学者赶上了基于语言大数据的经验主义盛行的黄金时代,在自然语言处理中,我们可以把唾手可得的那些低枝头上的果实,采用深度学习和神经网络的经验主义方法采摘下来;而我们留给下一代的,则是那些处于高枝头上的最难啃的硬骨头。
因此,我们要告诫下一代的学者,不要过分地迷信目前广为流行的基于语言大数据的经验主义方法,不要轻易地忽视目前受到冷落的基于语言规则的理性主义方法。我们应当让下一代的年轻学者做好创新的准备,把基于语言大数据的经验主义方法和基于语言规则的理性主义方法巧妙地结合起来,把大数据和形式化的知识结合起来,从而把自然语言处理的研究推向深入。
目前流行的深度学习和神经网络的热潮,为基于语言大数据的经验主义方法添了一把火,预计这样的热潮还会继续主导自然语言处理领域很多年,这有可能使我们延宕了向基于语言规则的理性主义方法回归的日程表。不过,我始终认为,在自然语言处理的研究中,基于语言规则的理性主义方法复兴的历史步伐是不会改变的,基于语言数据的经验主义方法一定要与基于语言规则的理性主义方法结合起来,这才是自然语言处理发展的金光大道。
[1]冯志伟.计算语言学基础[M].北京:商务印书馆,2001.
[2]冯志伟.数学与语言[M].北京:世界图书出版公司,2011.
[3][美]Jurafsky,D.& Martin,J.H.自然语言处理综论[M].冯志伟,孙乐译.北京:电子工业出版社,2005.
[4]冯志伟.自然语言处理简明教程[M].上海:上海外语教育出版社,2012.
[5]冯志伟.中文信息处理与汉语研究[M].北京:商务印书馆,1992.
[6][苏]费尔斯曼.趣味地球化学[M].石英,安吉译.北京:中国青年出版社,1956.
[7][苏]吉米多维奇.数学分析习题集[M].李荣涷译.北京:高等教育出版社,1958.
[8]冯志伟.自然语言处理中的歧义消解方法[J].语言文字应用,1996,(1).
[9]奉国和,郑伟.国内中文自动分词技术研究综述[J].图书情报工作,2011,(2).
[10]Pater,J.Generative linguistics and neural networks at 60: Foundation, friction, and fusion[J].Language,2019,(1).
[11]Linzen,T.What can linguistics and deep learning contribute each other?——Response to Joe Pater[J].Language,2019,(1).
