基于DBSCAN改进的SMOTE算法
2022-06-30邱灿华吴杰
邱灿华 吴杰
摘要:针对传统的合成少数类过采样技术(Synthetic Minority Oversampling Technique,SMOTE)中存在的忽略类间不平衡、类内不平衡、无法控制合成样本的噪声等问题,结合DBSCAN聚类算法,提出了一种基于DBSCAN改进的SMOTE算法:使用DBSCAN算法对少数类样本进行聚类,计算少数类密度系数和采用权重为每个簇分配采样数量,将每个簇中样本点按照到簇质心的距离分为2类,对每类中的样本点分配不同的随机系数进行过采样,得到新的较为平衡的数据集。根据获取的数据集进行实验表明,改进的算法可以很好地改善分类器的分类性能。
关键词:SMOTE算法;DBSCAN算法;不平衡数据集;过采样
中图分类号:TP181文献标志码:A文章编号:1008-1739(2022)07-62-5

0引言
旅游在線评论是文本情感分析的一种重要的信息来源,对游客选择旅游目的地以及帮助旅游地改善其旅游产品或服务都有非常好的现实意义[1]。然而在实际研究中,评论数据集大多是不平衡的。不平衡数据是指类分布不平均的数据,样本数目多的类被称为多数类,数目少的被称为少数类[2]。在分类算法中,数据集的不平衡会导致传统分类器的准确率偏向于多数类,而在不平衡类中,少数类包含更多有用的信息,对分析结果会产生更大影响[3]。在现实中,少数类样本的预测结果往往才是人们关注的重点,如旅游评论分析中,少数的差评比多数的好评更有研究意义[4]。
为了解决数据集不平衡问题,Chawla[5]于2022年提出少数类过采样技术(Synthetic Minority Oversampling Technique,SMOTE),通过在数据集中增加人工合成的少数类样本,使数据集趋于平衡,同时减少了过拟合的可能性,有效地平衡了数据集。近些年,很多学者也在SMOTE算法的基础上进行改进,Han[6]提出的Borderline-SMOTE算法将数据集的少数类分成3类,选择其中一类样本作为根样本进行过采样,确保了新合成的样本不会成为噪声。古平[7]提出AdaBoost-SVM-MSA算法,将分类错误的样本分成3类,对每一类样本采用不同的方式进行处理,实验表明算法能有效地提高少数类的分类准确率。Barua[8]将聚类算法与SMOTE结合,采用聚类算法从加权的少数类样本中合成样本,保证生成的新样本位于少数类区域内。Douzas[9]将K-means聚类算法同SMOTE相结合,实验证明该方法能有效避免噪声的生成,改善了SMOTE造成的类间不平衡问题。
针对SMOTE算法存在的一些问题,本文将DBSCAN聚类算法同改进的SMOTE算法相结合,提出DBS-DTCSMOTE算法。使用DBSCAN算法进行聚类,有效剔除噪声样本,改善传统SMOTE算法无法控制样本噪声的问题。根据本文提出的类不平衡率和采样权重,对于聚类产生的不同的簇合成不同数量的新样本,很好地改善传统SMOTE算法存在的类间不平衡问题;改进的SMOTE算法按照簇内样本到质心的距离设置不同的随机系数,使合成后的簇内部分布更加合理,一定程度上缓解了传统SMOTE算法造成的类内不平衡问题。
1基本原理
1.1 SMOTE算法
SMOTE是一种基于特征空间的过采样方法,通过在少数类样本及其近邻样本之间采用线性插值的方法合成新的少数类样本,通过人工合成新样本有效缓解了随机复制少数类样本引起的过拟合问题,是目前主要的应用于不平衡问题的数据预处理技术。SMOTE基本原理如图1所示。
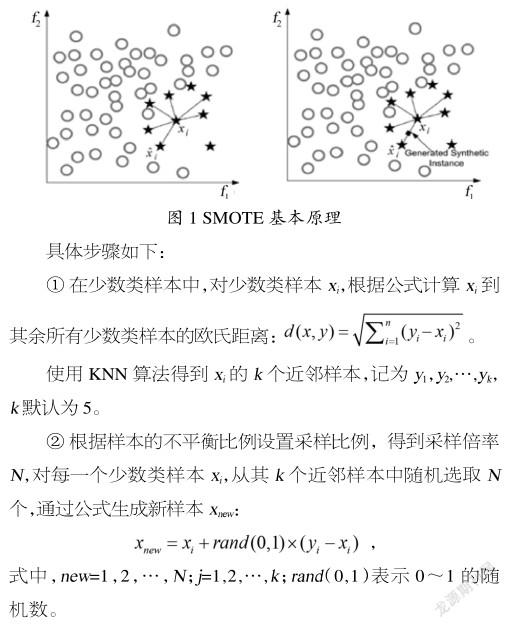
③将生成的新样本加入原始的数据集中,增加少数类样本数量,降低数据集的不平衡性。
SMOTE算法依然存在着很多问题,如合成样本的质量问题、类边界模糊的问题以及少数类样本的分布问题等[9]。如果选择的少数类样本或者其近邻样本存在噪声,则合成的样本极有可能成为噪声;如果选择的少数类样本位于边缘地区,那么生成的新样本也大概率位于边缘地区,会造成类边界模糊。由于少数类样本内部分布不均,SMOTE在进行线性插值的过程中,根据近邻原则会在根样本以及辅助样本附近位置生成新样本,这样就会导致少数类中相对密集的区域更密集,相对稀疏的区域更稀疏,分类算法不易识别稀疏区的少数类样本,进而会影响分类的准确性[10]。
1.2 DBSCAN聚类算法
DBSCAN是一种基于密度的空间聚类算法,该算法将具有足够密度的区域划分为簇,可以在具有噪声的数据集中识别出任意形状的簇。与K-means算法不同,它不需要确定聚类的数量,而是基于数据推测聚类的数目,能够针对任意形状产生聚类。
DBSCAN算法存在以下2个关键参数:Epsilon表示在一个点周围邻近区域的半径;MinPts表示邻近区域内至少包含点的个数[11]。
DBSCAN聚类算法与K-means聚类算法相比,最大优势是能够识别任意形状的聚类簇,并且可以在聚类时发现异常点,过滤噪声点,同时聚类结果没有大的偏差,K-means聚类算法的结果与初始值有很大的关系[12]。
2基于DBSCAN改进的SMOTE算法
针对SMOTE过采样算法存在的不足,如无法控制合成样本的质量、容易导致类边界的模糊等问题,本文结合DBSCAN算法良好的聚类性能,对传统的SMOTE算法进行一定的改进,提出一种基于DBSCAN的改进的SMOTE算法。
2.1类不平衡率与采用样重



DTCSMOTE算法主要是将同一聚类簇内的少数类样本按照到质心的距离分为远离质心类与接近质心类,针对远离质心类中的样本,在远离质心的一端合成新的样本;针对接近质心类中的样本,在接近质心的一端合成新的样本,试图以不同的随机数去改善少数类的类间不平衡性。
2.3 DB-DTCSMOTE过采样算法
DB-DTCSMOTE过采样算法由DBSCAN聚类算法以及改进的SMOTE过采样算法组成,算法主要包括DBSCAN聚类、少数类样本密度系数的计算、采样权重的计算和DTCSMOTE算法合成新样本。主要步骤如下:
Input:原始数据集,需要合成的新样本数量,DBSCAN聚类算法参数和。
Output:合成的少数类样本集。

步骤2:计算簇的少数类样本密度系数( )。
步骤3:计算簇的采样权重( ),记为。
步骤4:计算簇需要合成的新样本数量=×。
步骤5:在簇中使用DTCSMOTE算法合成新样本集,并将加入中。
DB-DTCSMOTE与传统的SMOTE算法相比存在很多优势,使用DBSCAN算法对所有数据进行聚类可以有效剔除噪声样本,通过引入少数类样本密度系数以及采样权重,可以有效改善类间不平衡的问题;利用改进的DTCSMOTE算法合成新樣本,对远离质心的样本点与接近质心的样本点分开进行合成,有效改善了SMOTE算法任意合成新样本的弊端。
3实验与分析
为了验证算法的性能,利用从携程旅游网站获取的游客关于古镇的评论作为原始数据集,分别使用Random-OverSampling,SMOTE,Borderline-SMOTE,ADASYN,DB-DTCSMOTE五种算法对原始数据集进行过采样,得到新的较为平衡的数据集,并且使用SVM算法和KNN算法对数据进行分类,以验证不同算法的性能优劣。
3.1原始数据集
本文根据携程旅游网站对于古镇的排名,选择排名前10的古镇,基于Python的爬虫技术获取游客关于古镇景点的评论数据。原始数据集经过去杂去重后,对所有评论内容进行分词处理,分词后的数据利用Google开源的Word2vec算法得到文本的向量表示,基于Tf-idf的文本加权技术将文本数据转换为向量形式。经过前期的数据处理得到原始数据集,共包含32 080条数据,经过DBSCAN聚类后去除噪声样本,剩余数据集包含正样本数29 720条,负样本数2 359条。
3.2评价指标
机器学习有很多评价指标,实际上不同的评价指标就是用不同的方法来评价算法的好坏。对于回归问题,通过mae,mse等指标就可以很好地衡量模型的好坏,但针对分类问题,仅仅通过准确率并不能很好地衡量模型的优劣,这时就要引入查准率、查全率、F1值来评价模型的性能[13]。
机器学习的评价指标建立在混淆矩阵之上,在混淆矩阵中有4个数据,其中,TP和TN分别表示正确分类的正类和负类的样本数量;FN和FP分别表示错误分类的正类和负类的样本数量[14]。
①准确率:所有正确预测(正类、负类)占总体的比重,准确率越高说明模型分类效果越好,准确率是衡量模型性能的重要指标。
②精确率(查准率):即正确预测为正的占全部预测为正的比例。
③召回率(查全率):即正确预测为正的占全部实际为正的比例。
④F1值为查准率和查全率的调和平均数,因为精确率和召回率指标有时候会出现矛盾的情况,就需要综合考虑,最常见的方法就是F1-score[15]。
3.3实验结果分析
本文基于Python实现原始数据获取、数据整理、过采样、SVM分类以及KNN分类。训练集与测试集的比例为6:4,随机种子值设为1;DB-DTCSMOTE算法中DBSCAN聚类算法的=3,Min=5;SVM算法的核函数为高斯核函数,Gamma值设置为0.1,惩罚因子设置为0.8;经过数据预处理设置KNN算法的近邻数为20,步长为0.2。通过数据的比较可以得出以下结论:
①使用同一数据集,在SVM分类器得出的结果要优于KNN分类器,这归功于SVM算法中的核函数。核函数的应用使得算法无需知道非线性映射的显式表达式,由于SVM是在高维特征空间中构建的线性学习机,所以与线性模型相比,几乎不增加计算的复杂性,而且在某种程度上避免了“维数灾难”,使得SVM分类器的性能更加优异。
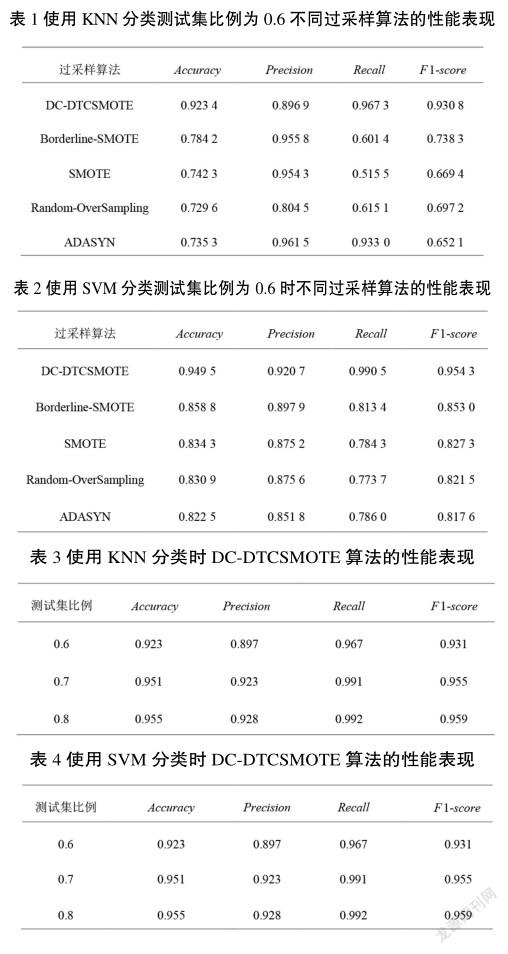
②使用KNN和SVM分类测试集比例为0.6,不同过采样算法的性能表现分别如表1和表2所示,相对于原始数据集来说,应用Random-Oversampling,SMOTE,Borderline-Smote,ADASYN,DC-DTCSMOTE这些过采样算法对数据集进行过采样,可以不同程度地提高分类器对数据集的分类效果。相对于其他4种过采样算法,DC-DTCSMOTE过采样算法对分类器分类效果的提高效果更明显,可以很好地提高分类器分类的各项评估系数。这是因为DC-DTCSMOTE在过采样之前先对原始数据集进行了聚类,可以保证聚类同时去除噪声数据,同时可以对任意形状的稠密数据集进行聚类。按照簇内密度对每一簇分配不同的采样权重,可以很好地克服原始数据集的类间分布不均;同时,改进的SMOTE算法可以一定程度缓解簇内的分布不平衡。
③为了验证测试集比例对分类结果的影响,将测试集比例设为0.6,0.7,0.8,使用KNN和SVM分类DC-DTCSMOTE算法的性能表现分别如表3和表4所示。实验数据显示,对于DC-DTCSMOTE算法,测试集比例越高,无论是KNN还是SVM的分类结果的各项指标都有提升,测试集的比例对最终的分类结果存在一定的影响。
4结束语
本文试图解决SMOTE算法中存在的不足,利用DBSCAN聚类算法的优势,提出了一种基于DBSCAN改进的SMOTE算法。算法首先使用DBSCAN算法对原始数据集中的少数类数据进行聚类;随后按照不同聚类簇的密度分布,为不同簇分配不同的采样权重,根据每个簇的权重确定该簇需合成样本的数量;最后,对SMOTE算法做出改进,将同一簇内样本按照到质心的距离分成两类,对每一类数据设置不同的随机数产生范围,合成新的少数类样本。根据从携程旅游获取的旅游评论数据,经实验验证,本文提出的基于DBSCAN改进的SMOTE算法可以有效缓解传统SMOTE算法存在的类间不平衡与类内不平衡问题,增强分类器的分类性能。
参考文献
[1]郑文英.旅行目的地中文评论的情感分析研究[D].哈尔滨:哈尔滨工业大学,2010.
[2]石洪波,陈雨文,陈鑫.SMOTE过采样及其改进算法研究综述[J].智能系统学报,2019,14(6):1073-1083.
[3]马琳,张莎莎,宋姝雨,等.基于SDN的智能入侵检测系统模型与算法[J].高技术通讯,2020,30(5):533-537.
[4]陈荣荣.基于GAN-XGBoost的信用卡交易欺诈检测模型研究[D].杭州:杭州师范大学,2019.
[5] CHAWLA N V, BOWYER K W, HALL L O, et al. SMOTE: Synthetic Minority Over-sampling Technique[J]. Journal of Artificial Intelligence Research, 2002, 16(1): 321-357
[6] HAN H, WANG W, MAO B. Borderline-SMOTE: A New Over-sampling Method in Imbalanced Data Sets Learning[C]// International Conference on Intelligent Computing. Hefei: Springer, 2005: 878-887.
[7]古平,欧阳源遊.基于混合采样的非平衡数据集分类研究[J].计算机应用研究,2015,32(2):379-381,418.
[8] BARUA S, ISLAM M, YAO X, et al. MWMOTE Majority Weighted Minority Oversampling Technique for Imbalanced Data Set Learning[J]. IEEE Transactions on Knowledge and Data Engineering,2014, 26(2): 405-425.
[9] DOUZAS G, BACAO F, LAST F. Improving Imbalanced Learning through a Heuristic Oversampling Method Based on k-means and SMOTE[J]. Information Sciences, 2018,465:1-20.[10] BLAGUS R, LUSA L. SMOTE for High-dimensional Class-imbalanced Data[J].BMC Bioinformatics, 2013,14(1):106.
[11]于維扬.社交网络中垃圾内容过滤方法研究[D].大连:大连理工大学,2016.
[12] ESTER M, KRIEGEL H P, SANDER J, et al. A Density-based Algorithm for Discovering Clusters in Large Spatial Databases with Noise[C]// 2nd International Conference on Knowledge Discovery and Data Mining. Portland: AAAI, 1996: 226-231.
[13]李阳,马骊,樊锁海.基于动态近邻的DBSCAN算法[J].计算机工程与应用,2016,52(20):80-85.
[14]顾亚祥,丁世飞.支持向量机研究进展[J].计算机科学, 2011,38(2):14-17.
[15]杨扬,李善平.基于实例重要性的SVM解不平衡数据分类[J].模式识别与人工智能,2009,22(6):913-918.
