英特尔推出锐炫A系列移动端独立显卡
2022-06-30谢列琴
谢列琴
近日,英特尔宣布推出面向笔记本电脑的英特尔锐炫A独立显卡系列。这是英特尔锐炫A系列显卡产品组合中率先发布的独立显卡。所有搭载英特尔锐炫A系列独立显卡的产品均基于英特尔全新Xe HPG微架构而打造,专为游戏玩家和内容创作者量身设计。此外,英特尔公司也表示将于今年发布面向台式机和工作站的产品。
此次推出的英特尔锐炫A系列独立显卡将应用于广泛的移动设备中,其中多款搭载锐炫3系列显卡的首批机型还将通过英特尔Evo平台认证,并采用英特尔最新第12代酷睿处理器,包括针对超薄本设计的A350M以及为兼顾性能和轻薄而设计的A370M,同时还兼具WiFi 6、即时响应和超长续航等特性。
英特尔公司副总裁兼显卡与游戏团队总经理Roger Chandler表示:“数十年来,英特尔一直致力于推动PC平台的创新。通过推出历代CPU处理器,我们为全球数十亿用户提供了强大的计算能力。我们通过USB、Thunderbolt和WiFi等特性不断推动连接技术的演进,并与PC生态系统合作开发突破性的PCI架构、推出英特尔Evo平台,不断拓展移动设备的更多可能性。英特尔在推动PC平台创新方面拥有得天独厚的优势,旨在满足全球商用用户、消费者、游戏玩家和内容创作者对于算力日益增长的需求。”
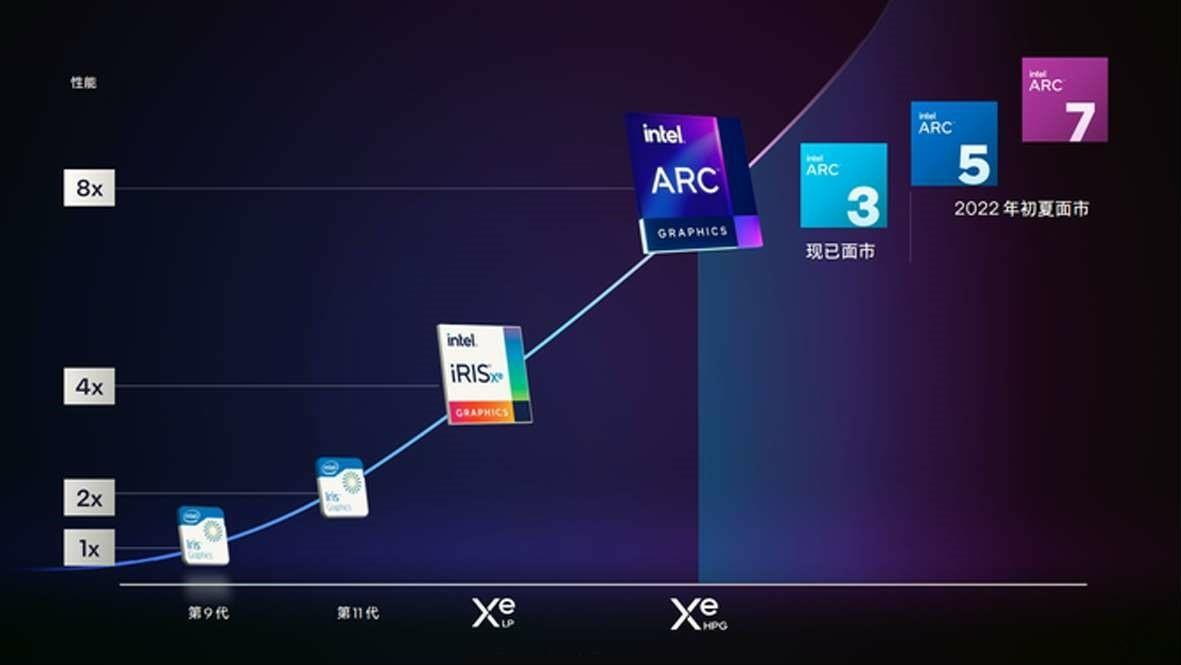
据英特尔表示,此次推出的英特尔锐炫3系列独立显卡能够提供1 080 p主流游戏和内容创作体验。在运行多款热门游戏时,搭载锐炫A370M的笔记本电脑可以提供1 080 p 60 fps以上的画质。英特尔锐炫5系列和锐炫7系列均可提供领先的内容创建性能,以及更强大的图形与计算性能。与锐炫3系列相比,锐炫5系列和锐炫7系列内置更多Xe内核、更多光线追踪单元和更高GDDR6显存。
据悉,首款搭载英特尔锐炫3系列独显的笔记本电脑———三星Galaxy Book2 Pro已于海外市场上市,搭载锐炫5和锐炫7系列显卡的笔记本以及面向台式机的英特尔锐炫A系列显卡的产品,预计在2022年夏天上市。
基于Xe HPG微架構设计
搭载英特尔锐炫A系列独立显卡的产品均基于英特尔全新Xe HPG微架构而打造,提供了出色的性能、能效和可扩展性。Xe HPG微架构包括了强大的AI引擎和支持下一代编解码器标准的增强媒体引擎。除此以外,还有下一代Xe显示引擎和新的图形管线,用来处理各种不同的显示任务。
在Xe HPG微架构里,每4个Xe内核组成了一个渲染切片(Rendering Slice)。每一个Xe内核中都配备了数量可观的运算单元,比如矢量引擎XVE,矩阵引擎XMX。此外Xe HPG也集成了其他主流的图形技术,比如网格着色,采样器反馈等。Xe HPG架构最大的特点就是灵活性,通过叠加渲染切片来构建不同的SoC,最小两个,最大八个。这样的结构最主要的特点就是可扩展性很强,根据渲染切片数量的不同,可以打造更丰富的产品线,为用户提供更多选择。
与上一代的Xe LP微架构相比,Xe HPG微架构的每瓦性能提升了1.5倍。此外,渲染切片还支持DX12 Ultimate,其中包括对所有图形固定功能块的改进,当然还有支持微软DXR和Vulkan RT的专用硬件光追单元。每个切片还配备了4个硬件光追加速器,用来支持实时的光线追踪技术,能够显著提升3A大作的游戏画面和光影效果。
Xe Core核心方面,现在Xe内核已经取代了此前集成显卡架构中EU的概念,成为Xe HPG架构中最基础的执行单元。它包括16个256位宽的SIMD矢量引擎,并为传统图形着色器执行大部分的运算。矢量引擎主要负责传统图像处理的计算任务。由于AI的算法核心几乎完全围绕着一系列大型的矩阵乘法和累加算法,在每个Xe内核中构建了专用的矩阵引擎,来进行硬件加速。Xe内核包含16个矩阵引擎,每个引擎都是1 024位宽。矩阵引擎就是为了加速AI运算用的。为了满足矩阵、矢量和光线追踪单元的高带宽需求,在每个Xe内核中构建了一个192 KB的大型本地内存,它可以根据每个工作负载的需要在L1缓存和共享本地内存(SLM)之间动态分配。
其中矩阵引擎的一个主要应用是在实时渲染过程中使用AI。这一算法称为XeSS,它是一种超级采样技术,与传统的高分辨率渲染相比,可在游戏中提供更高的性能。它使用神经网络辅助运动矢量,从低分辨率渲染中生成精美的高分辨率图像。英特尔还展示了14款支持XeSS技术的游戏,并表示未来将继续深化与顶级游戏工作室的合作,以增加对这种强大并开放的AI超分技术得到广泛的使用,为游戏玩家提供更好的游戏体验。
2种不同的芯片设计
英特尔锐炫A系列独立显卡的芯片代号有2个———ACM-G10和ACM-G11。ACM-G10包含多达32个Xe内核和光追单元,16 MB的L2缓存,256位GDDR6接口,16路PCIE4接口;ACM-G11包含多达8个Xe内核和光追单元,4 MBL2缓存,96位显存接口,8路PCIE4,2种芯片设计都包含2个Xe多功能编解码引擎,和4路显示输出引擎。
在芯片设计中,频率是必不可少的一个因素。但是,频率的提升会要求电压的升高,从而带来功耗的增加。通过实时监控独立显卡的性能指标,例如功耗,温度和使用率,并且动态调节时钟频率来与之适配。此外,在显卡运行各种不同负载的时候,或者运行同一个负载但不同阶段的时候,显卡的占用率等指标是不一样的,从而时钟频率会在一个范围内动态调整,而且这个范围的分布也是有规律的,在分布内,一些接近中部的频率出现的概率会高一些。
考虑到这种分布的情况,在制定独立显卡参数配置的时候,先标定一个有代表性的负载,然后在这个负载运行的时候,全程测量并统计时钟频率的分布,最终在整个负载完成后,把平均时钟频率作为参数配置中的定义。当然,对于不同的平台,有着不同的TDP,即基于散热的设计功耗。更宽松的TDP限制下,时钟频率的分布范围也会整体提升。
英特尔锐炫A系列移动端独立显卡
产品方面,英特尔锐炫A系列移动端独立显卡首发2款型号,包括针对超薄本设计的A350M以及为兼顾性能和轻薄而设计的A370M,搭载锐炫5和锐炫7系列的产品,会在2022年夏天面市。
A370M有8个Xe内核和光追单元,64 bit位宽,时钟频率1550,4 GB显存,功耗设计在35~50 w。A550M的Xe内核数和显存位宽等参数上,基本是A370M的2倍。锐炫7系列有A730M和A770M两款产品,最高可达32Xe内核,16 GB内存,256 bit位宽。
英特尔锐炫A系列独立显卡均全面支持DirectX 12 Ultimate和领先的游戏技术,例如硬件加速的光线追踪和Xe超级采样(XeSS),XeSS将在今夏发布,并有望得到超过20款游戏的支持。为了让业内更多软件和硬件支持该技术,英特尔计划面向所有人开放XeSS SDK和工具包。
性能
首先是与集显对比,相对于第12代酷睿移动处理器搭载的集显,最多可达两倍的性能提升。同时这些游戏都能在1 080 p 60 fps运行,能给用户不错的体验。
对比12代酷睿i7-1280P中集成的96个执行单元、1 450 MHz频率的锐炬Xe核显,综合游戏性能高出一倍左右。
在运行包括《GTA V》、《堡垒之夜》等游戏时,A370M显卡能在1 080 p下达到90帧/秒,而且这是在开了中等或者高画质下测量的结果。
内容创作方面,相比第12代酷睿的集成显卡,搭载A370M独立显卡的平台在视频编解码方面,以Davinci为例,4K H.264转H.265的性能可多达60 %的提升。而在AI相关功能上,例如Adobe PR里的两个应用场景,更是有翻倍的性能提升。
值得注意的是,性能的提升并不仅来自于独立显卡,同样得益于基于整个系统的Deep Link技术的加持。Deep Link涵盖了不同的技术,例如:动态功率共享,超级编码和超级算力。
首先是动态功率共享,该技术能在系统功耗的限制范围内,尽可能最大化释放CPU或GPU的性能。所有搭载英特尔12代酷睿和锐炫的笔记本电脑,都能启用这项技术。
第二个是超级编码技术。在之前的编解码流程里,通常把编码工作放在一个显卡的编解码器上,编码效率成为了整个流程的性能瓶颈;而现在的笔记本系统,例如搭载了12代酷睿处理器和锐炫A系列独立显卡的系统,集成显卡和独立显卡都有硬件编码能力。所以超级编码技术,就是同时运用2个显卡的编解码引擎,来大大提升编解码效率。这种协作是通过OneVPL(一个跨平台的开放性框架)的API接口来实现的。当超级编码开始工作时,一组组解码后的原始帧通过特定的API函数被交给oneVPL,进而按组被分配到不同的多媒体引擎上,拷贝到相应的内存中缓存起来。不论每一组有多少帧,相应的集显或者独显的多媒体引擎会开始按照设定的格式编码。而OneVPL会完成后续的打包工作,把编码后的帧一组组拼接成最终视频来输出。这种并行处理,编码效率比单一显卡提升非常显著。
三是超级算力。每一个搭载英特尔锐炫独立显卡的笔记本,都可以从独立显卡的算力中获益,但是不要忘记,英特尔CPU的集成显卡中同样也提供了计算引擎。为了把负载合理的分配给不同的计算引擎,就设计一个基于机器学习的服务———MLS。
MLS是OpenVino中的一个框架,把负载分配给不同的算力模块。根据当前应用或负载的特征,例如延迟敏感度、吞吐量、性能要求、功率消耗等等。这些因素帮助MLS做出决策,把负载分配给独立显卡,集成显卡,或者CPU。
举个例子,当想对一段视频做处理,例如去噪点、超分、锐化等,导入画面会逐帧传递给MLS框架,每一帧还会拆成若干块,这些块排在工作队列里,MLS启动一个个工作线程,把这些块根据需求自动分配到不同的算力模块中,一部分分配到集显的计算引擎,一部分分配到独显的矩阵引擎。随着显卡完成当前任务,MLS会不断派发新的任务,直到最后完成所有块的处理,打包这些增强后的画面作为输出。
正是因为全新Deep Link技术的加持,在内容创作上,动态功率共享、超级编码、超级算力可以分别带来最多30%,60%,24%的性能提升。
Xe媒体引擎:提供最广泛的编/解码器首发支持AV1
媒体引擎方面,提供了对H.265 / HEVC、H.264 / MPEG-4/ AVC、VP9的支持,以及业界首个对AV1编码和解码的硬件加速支持。
开放媒体联盟主席Matt Frost先生指出,AV1的效率比最常见的编解码器H.264高了50 %,比HEVC高了20 %,能够以更低的带宽和更小的文件大小提供更高的画面质量,而且它是开放的且没有版权费。目前,FFMPEG、Handbrake、Adobe和XSplit都已经集成了对锐炫AV1的支持。
Xe顯示引擎:加入全新Smooth(平滑同步)Sync
在显示方面,Xe已经支持HDMI 2.0b和DP1.4a的规格,游戏玩家可以享受高达1080p360Hz、或者4台具有4k120Hz HDR的显示器连接。
在同步技术方面,英特尔支持VESA标准的Adaptive Sync,可提供流畅的游戏而不会撕裂。此外还有Speed Sync可以适用于任何显示器并解决不同的问题。
此次全新推出的Smooth Sync技术,运用了模糊化2个撕裂帧之间的边界,来减少视觉失真,使图像看起来更加连贯。之后所有锐炫显卡都会支持Smooth Sync功能。
产品上市与相关生态
无疑问,得益于Evo平台更快的处理器速度、超长的续航时间、轻薄便携时尚的外观设计,很多OEM都将优先推出锐炫配置在Evo设计上,在英特尔锐炫显卡的加持下,将让游戏和内容创作在Evo平台上有更好的使用体验。据英特尔介绍,从第二季度开始,采用锐炫3系列的笔记本产品有望国内面市,锐炫5和锐炫7系列的产品有望在今年夏天发布。
在此次英特尔锐炫A系列独立显卡的解析会上,英特尔还发布了新的显卡控制界面———Arc Control英特尔锐炫控制面板。
Arc Control提供了一站式与锐炫显卡相关的设定或者信息接收,包括可以让用户快速升级驱动,及时看到显卡性能的工作负载、虚拟摄像头设定、自动生成游戏高光时刻、还有让每个人都能成为像是专业主播一样的软件设定等。
目前,Arc Control控制面板已经可以下载。需要注意的是,Arc Control控制面板适用于所有英特尔显卡,也因此不只有英特尔的独立显卡能用,英特尔的集成显卡也能用。值得一提的是,Arc Control控制面板不需要登录,这一功能大大提升了用户体验。
英特尔锐炫A系列移动端独立显卡的推出,首先是进一步完善了英特尔移动平台,也为用户和游戏玩家带来更多一项选择。随着相关产品的上市,相信可以缓解目前“一卡难求”的市场局面。对于另外2家显卡厂商,到底是挑战,还是在竞争中创新、进步,那就敬请期待吧。
