NOMA下行信道总速率最大化算法研究
2022-06-29邹金妤张足生高佳曼吴超超
邹金妤 张足生 高佳曼 吴超超
(东莞理工学院 网络空间安全学院,广东东莞 523808)
在过去的二十多年中,随着移动通信技术标准的不断发展,基于正交频分多址接入(Orthogonal Frequency Division Multiple Access,OFDMA)技术的第四代移动通信技术(4G),已达到每秒数十兆比特的数据传输率,这适应了当时移动通信的发展需求。然而,随着智能终端设备的广泛使用,移动通讯的需求持续增长[1],4G的传输速率已不能满足当下移动通信的发展需求,对无线传输速率提出了更高的要求。
按照IMT-2020(5G)推进组发布的《5G愿景与需求白皮书》,第五代移动通信技术(5G)定位于频谱效率更高、速率更快、容量更大的无线网络,其频谱效率与4G相比可以提高5~15倍[2]。NOMA已被纳入5G标准,能够带来高速的数据传输和较低的系统延迟,并实现相对较高的频谱利用率。
NOMA技术可以同时为多个用户提供服务,通过叠加编码(Superposition Coding,SC)技术,在发送端将多个用户的叠加信号分配到同一时频资源上;然后,利用串行干扰消除(Successive Interference Cancellation,SIC)技术,在接收端对用户间存在的干扰进行消减,从而完成基站到用户的下行NOMA通信系统的数据传输[3]。因此,NOMA技术能够为未来的无线通信系统获得更高的吞吐量[4]。
通过NOMA技术,基站能同时与多个用户进行通信,也就是在下行信道上同时向多个用户传输不同的数据流,但是如果将所有的用户都叠加到同一信道上,这既不符合实际系统约束,还会造成数据的错误传输以及系统的解码时延。在这种情况下,以最大化系统总速率为目标,基站应该如何选择一个用户子集来进行数据传输,这还有待研究。
为此,本文研究NOMA下行信道的用户选择问题,以基站的发射功率和单个信道叠加的用户数为约束条件来优化系统的总速率。
1 相关研究
NOMA技术允许多个用户共享同一时频域资源,由此引入的用户间干扰将会降低系统的性能,而通过合理的用户选择和功率分配可以减小这种干扰,所以关于这两个问题的讨论成了NOMA研究中的热点。
1.1 NOMA用户选择算法
在NOMA系统中,同一信道上所叠加的用户数量受实际系统的约束,为了减少用户间的干扰,降低解码时延,规避严重的错误传播[5],已有学者对于用户选择问题进行了研究,以提高系统总的吞吐量。用户选择算法主要有随机选择、基于信道差异选择和基于遍历搜索的用户选择。
随机用户选择算法[6]不依赖其他的限制条件,在用户集合中,随机地选择叠加用户。虽然复杂度很低,但是由于叠加用户之间是随机匹配的,没有考虑用户之间的叠加干扰,因此,不能保证用户接入的公平性。
基于用户信道差异的用户选择算法[7],根据用户叠加原理,当叠加用户之间的信道差异较大时,在功率分配过程中可以获得较大的功率差异,便于接收端分离用户的信息。由于考虑了叠加用户之间的信道状况,性能相对于随机选择有了很大提高,但当信道差异较小时将会影响叠加组合的传输性能。
遍历搜索的用户选择算法[8]基于比例公平调度(Proportional Fairness Scheduling,PF)准则,通过对随机的用户组合进行PF准则值的计算和比较,找到在用户容量与系统容量之间达到良好折中的叠加用户组合。虽然性能优势明显,但该算法的用户迭代的复杂度较高。
1.2 NOMA功率分配算法
在NOMA系统中,基站会为服务的用户分配功率,其中,用户所分配功率的大小不仅决定着自身吞吐量的性能,还影响着叠加信号中的其他用户的性能,进而影响系统的总吞吐量。此外,由于在接收端需要根据用户的发射功率进行串行干扰消除,功率分配算法还会直接影响到后续的用户信号检测。因此,在NOMA系统中,为使基站可以更好地权衡用户速率与系统整体容量性能之间的关系,给用户合理地分配功率相当关键。
文献[9]提出了全空间搜索功率分配(Full Search Power Allocation,FSPA)算法,通过遍历各种可能的用户配对组合和功率分配方式,以获得最佳的系统性能。但是,随着用户规模的增加,对于实际系统来说,功率搜索在计算上变得过于复杂。文献[10]以最大化系统的几何平均吞吐量为目标,通过遗传算法联合优化用户分组和功率分配问题,虽然相较FSPA复杂度有所降低,但对两个问题进行联合优化本身就有着极高的计算难度和挑战。文献[11]使用Karush-Kuhn-Tucker(KKT)条件解决了在最大功率约束下最大化加权和速率的优化问题。
从最大化多用户比例公平的角度,文献[12]提出一种基于瞬时用户吞吐量加权和最大化的功率分配方案,其目标函数在理论上是最佳的,因此NOMA系统能够达到理论上的最佳性能。但是,该方法不易扩展到采用调制和编码的实际系统中。为此,有学者提出了两种简化的次优方案,分别为固定功率分配算法 (Fixed Power Allocation,FPA)[13]和分数阶功率分配算法(Fractional Transmit Power Allocation,FTPA)[14]。尽管这两种简化的方法具有非常低的计算复杂度,并且可以应用于实际系统,但是它们的性能受到相对简单的功率分配标准的限制,本文认为可以通过增加功率约束加以改进。
综上所述,在具有大量用户的NOMA下行系统中,用户选择算法研究已取得了一些成果。但是本文所关注的以基站发射功率为约束条件,选择一个用户子集,使得系统总速率最大是尚待研究的关键问题。
2 系统概述及问题建模
2.1 系统概述
1)叠加编码技术。在NOMA系统中,发送端利用叠加编码技术[15]将多个用户的信号叠加在同一时频域上,使得一个子信道可以同时接入多个用户。假设系统中有两个用户和一个包含两个点对点编码器的发射机,用户的输入信息被两个编码器分别映射成两个复信号,通过叠加编码技术将这两个复信号进行叠加,图1给出了两个用户信号在星座图上的叠加过程,由图可以看出,基站端发送的叠加信号是通过把具有较大功率的用户1的正交相移键控(Quadrature Phase Shift Keying,QPSK)星座图和具有小功率的用户2的QPSK星座图叠加起来得到的。

图1 采用QPSK调制的用户1和用户2的叠加编码
2)功率复用技术。在NOMA系统中,由于接收端以用户间所分配的总功率为标准来划分不同用户,为此在发送端,移动通信基站必须对同一时频资源块上的各个叠加用户进行功率分配,以确保用户间的功率各不相同。图2将OFDMA系统和NOMA系统中的功率分配进行对比,功率复用技术[16]使得基站覆盖范围内的用户获得更大的可接入带宽,从而极大地提高了NOMA网络的吞吐量,增加了接入无线通信系统内的用户的公平性。

图2 OFDMA系统和NOMA系统功率分配对比
通过叠加编码和功率复用技术可以得到基站所发送的叠加信号,具体流程如图3所示,利用正交相移键控、正交振幅调制等单载波调制技术,对每个用户的比特流进行调制,将每个调制信号的波形相加后得到基站发送的叠加信号x(t):
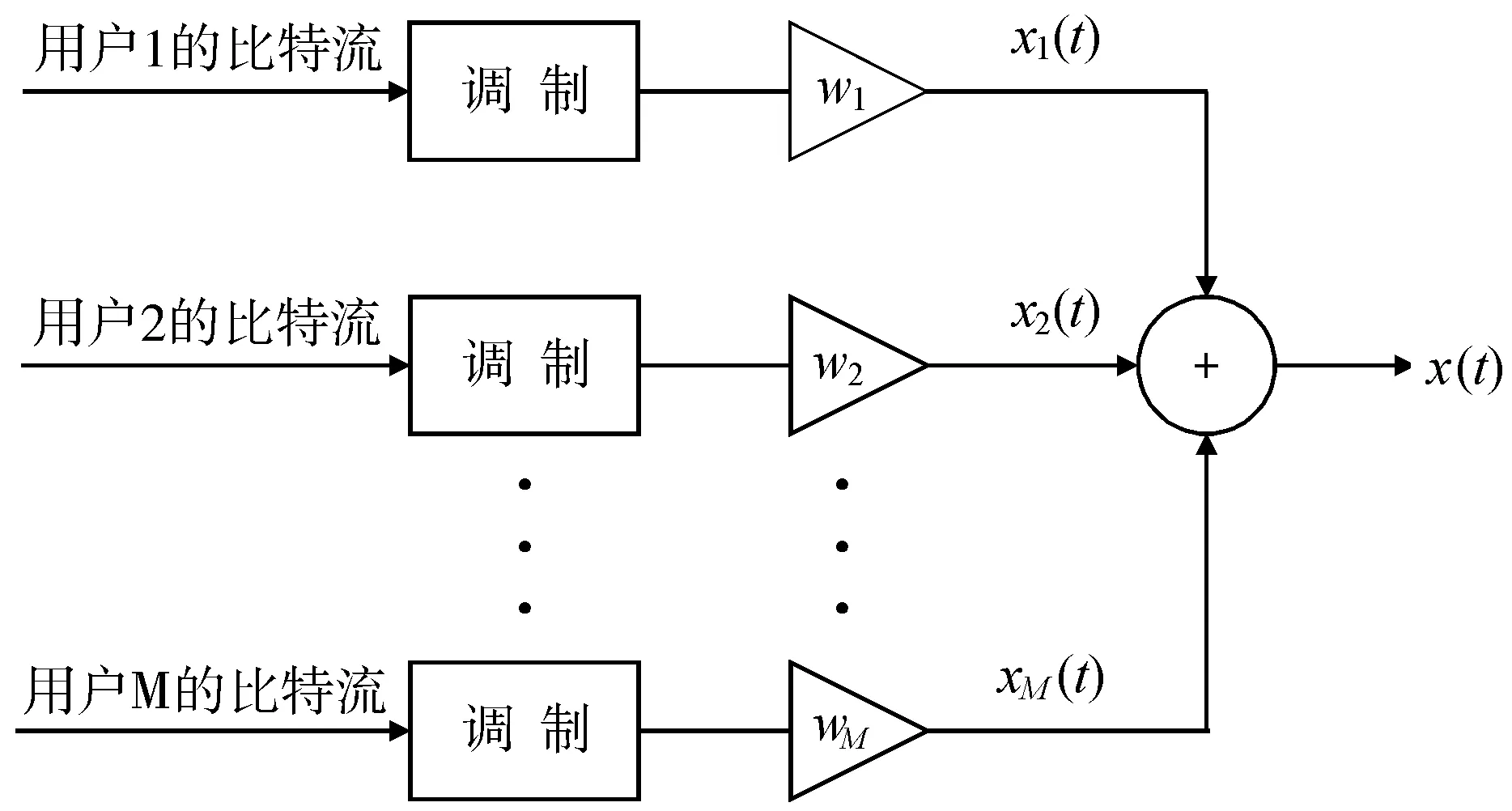
图3 叠加信号的形成过程
(1)
其中,M表示叠加用户的数量,i表示任一叠加用户,wi(i=1,2,…,M)表示用户i的功率分配因子,P表示基站的发射功率,xi(t)表示用户i的信号。
3)下行NOMA系统模型。图4为NOMA系统下行信道发送和接收信号的处理流程,基站作为发射端,在同一时频域上叠加用户U1,U2,…,UM;U1,U2,…,UM作为接收端进行解码、重构以及串行干扰消除。
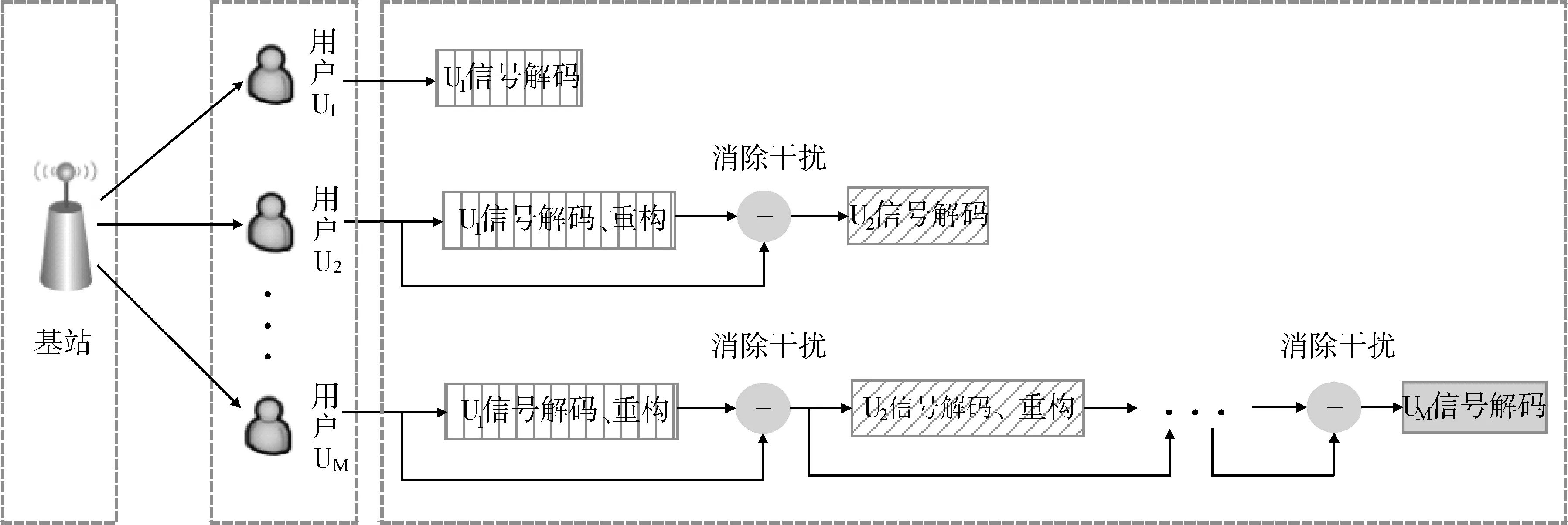
图4 下行NOMA系统模型
对于发射端,假设基站所服务的用户数量为N,通过叠加编码技术可以使多个用户叠加在同一信道上,但是为了减少解码时延与错误传播,每个信道会设定最多可叠加的用户数量阈值,假设为M。本文的目标即为在基站发射功率的约束下,在N个用户中最多选择M个用户,使得下行NOMA系统的总速率最大。
对于接收端,假设U1的信道状态比U2差,U2的信道状态比U3差,以此类推,UM的信道状态最好。其中,信道状态越好的用户所分配的功率越小[3],所以UM具有最小的发射功率。对于接收机来说,最先识别到强用户的信号,若想正确解调出UM的信号,终端要先逐次对U1,U2,…,UM-1的信号解码、重构以及串行干扰消除,最后才能解码出UM的信号。
2.2 问题建模
本节问题建模参考了Wan P J等人的研究成果。在下行NOMA系统中,假设基站的发射功率为P,基站所服务的用户集合为U,其中编号依次为1,2,…,N,共包含N个用户;用户的有效噪声为a,系统容量域包含的速率分配为x,则P满足下式:
(2)
其中,P>0,i表示用户集合U中的任一用户,ai表示第i个用户的有效噪声,ai-1表示第i-1个用户的有效噪声,aN表示第N个用户的有效噪声,并且用户的有效噪声满足a0=0,a1≤a2≤…≤aN。
对于一个非空的用户子集S,集合中所有用户的功率需求为p(S),其表达式如下:
(3)
其中,i表示用户子集S中的任一用户,ri表示用户i的速率需求且ri>0,r(S>i)表示子集S中在用户i后面的所有用户的总速率需求。当子集S不为空时,集合中所有用户的速率需求为r(S),其表达式如下:
r(S)=∑i∈Sri.
(4)
在下行NOMA系统中,假设单个信道最多可叠加的用户数量为M。在不失一般性的前提下,假设每个用户的功率需求最多为P,本文以基站的发射功率和单个信道叠加的用户数量为约束条件来优化系统总速率,具体定义如下。
定义1:当|S|≤M且p(S)≤P时,在用户集合U中选择子集S,使其总速率需求r(S)最大。其中,|S|表示集合S中的用户数量,p(S)表示集合S中所有用户的功率需求。
3 用户选择算法
针对NOMA下行信道上的用户选择问题,利用枚举法可以获得系统的最优解,但该算法具有指数级的时间复杂度,随着用户数量的提高将难以计算,对此,Wan P J等人提出了松弛贪婪算法,可以在降低时间复杂度的前提下获得系统近似最优解,本文将该算法与本文所提算法进行对比分析。首先,提出一种基于贪婪策略的用户选择算法,能够在多项式时间内获得近似最优系统总速率;之后,为了进一步得到最优系统总速率,在此基础上又提出基于分支限界的用户选择算法,从而实现了用户选择优化和算法时间复杂度之间的平衡。
3.1 松弛贪婪算法
松弛贪婪算法是一种多项式时间的用户选择近似算法,基于松弛策略,通过数学建模将用户选择问题转化为优化问题,以最大化系统总速率为目标建立目标函数,在所选用户集满足功率约束的前提下,使得目标函数值达到最大。而松弛策略的主要目的是放松可行解的约束条件,扩大可行域的范围,使得松弛后的优化问题可以在多项式时间内求得,并通过修正的方式将松弛后优化问题的解转化为原问题用户选择的解,从而解决用户选择问题。
3.2 基于贪婪策略的用户选择算法 (GR)
在进行用户选择时,将用户按速率降序排列,通过贪婪策略,总是把当前步骤中满足功率约束的最好的选择作为目标用户子集,具体算法如表1所示。

表1 基于贪婪策略的用户选择算法
3.3 基于分支限界的用户选择算法(BR)
分支限界是以广度为优先的方式对解空间树进行搜索,以便得到最佳解的算法。关于最大化问题,在查找过程中,可以利用限界函数估计所有子结点目标函数的可能取值,从中选取使目标函数取最大值的子结点为扩展结点,然后展开下一个查找,并通过不断调整查找方向来迅速地找出所求问题的最佳解。具体算法如表2所示。

表2 基于分支限界的用户选择算法
其中,目标函数为:arg maxr(S)=∑i∈Sri,下面对于算法中的三个关键问题进行分析:
1)解空间的构造方法。将用户集合U中的速率降序排列,以此作为分支限界解空间结点的生成顺序;
2)约束规则的确定。以p(S)≤P为约束条件,判断结点是否进行分支;
3)目标函数的边界评估方法。目标函数的下界down:如表1所示,通过贪婪法求解用户集合D,将集合D中的用户总速率r(D)作为目标函数的下界。
目标函数的上界up:在部分解r(G)的基础上,从用户集合U中选择不属于集合G的至多(M-|G|)个用户添加到集合G中,判断每个用户在添加到集合G后是否满足功率约束,筛选满足条件的用户加入集合G,将此时的r(G)作为目标函数的上界。即:限界函数
(5)
其中,r(G)表示集合G中用户的总速率,|G|表示集合G中用户的数量,UG表示属于集合U但不属于集合G的用户。
4 实验
4.1 复杂度分析
对于NOMA下行信道上的用户选择问题,GR算法和松弛贪婪算法取得相对较优系统总速率,而枚举算法[17]和BR算法可得到最大系统总速率。假设基站中的用户数量为N,单个信道可叠加的用户数量为M,为了得到相对较优总速率,GR算法以及松弛贪婪算法的时间复杂度为O(NlogN);为了得到最大总速率,枚举算法的复杂度为O(NM),BR算法为O(2N)。
枚举算法是在功率约束下解决用户选择问题的最优算法,通过理论分析可以看出,随着用户数量的增加,枚举算法具有很高的时间复杂度,可行性较差。本文提出的BR算法也可以得到用户选择问题的最优解,并且在得到最大总速率的前提下,通过有效选择目标函数的上界在一定程度上降低了枚举算法的时间复杂度。而GR算法和松弛贪婪算法是解决用户选择问题的近似算法,本文提出的BR算法与其相比结果更优。
4.2 仿真分析
为了评估GR算法、松弛贪婪算法以及BR算法解决用户选择问题的性能,本节对NOMA下行信道系统进行仿真,并通过Matlab平台对算法的性能进行验证。仿真过程中用到的参数如表3所示。

表3 仿真参数
当叠加用户数M分别为2、4、6时,随着用户数量的增加,GR算法、松弛贪婪算法以及BR算法的性能对比如图5、图6、图7所示。从图中可以看出,GR算法的总速率略高于松弛贪婪算法,性能提升了2.6%左右。这是因为松弛贪婪算法采用松弛策略扩大了可行域的范围,在此基础上得到一个用户集合,通过去除集合内不满足功率约束的用户得到目标用户子集,由于还要进一步去除最后一个满足功率约束的用户,造成一定的误差,导致系统性能降低。因此,GR算法与其相比具有更优的性能。而本文的BR算法选取了较好的目标函数的上界,有效地对解空间树进行剪枝,从而在一定程度上降低了算法时间复杂度,并且达到最大系统总速率,实现了用户选择优化和算法时间复杂度之间的平衡。所以,本文的BR算法与松弛贪婪算法相比,性能提升了6.1%左右,具有较优的总速率。
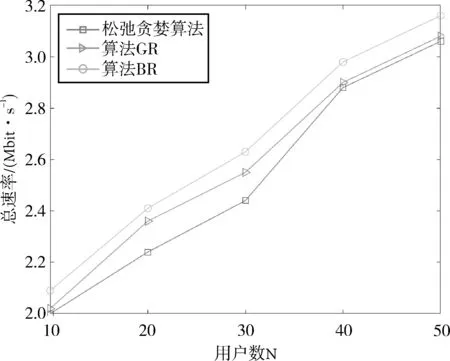
图5 不同用户选择算法下的性能对比(M=2)
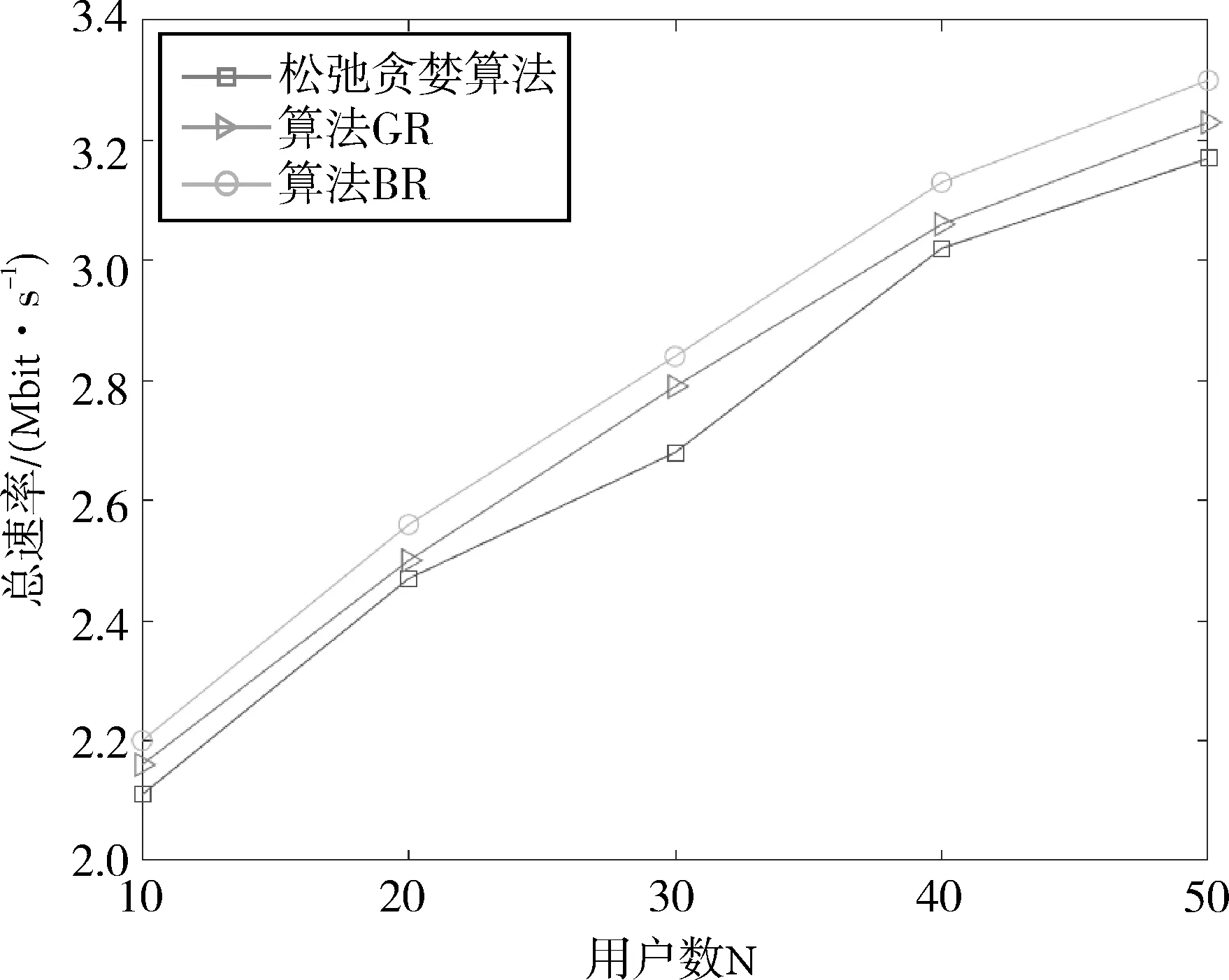
图6 不同用户选择算法下的性能对比(M=4)
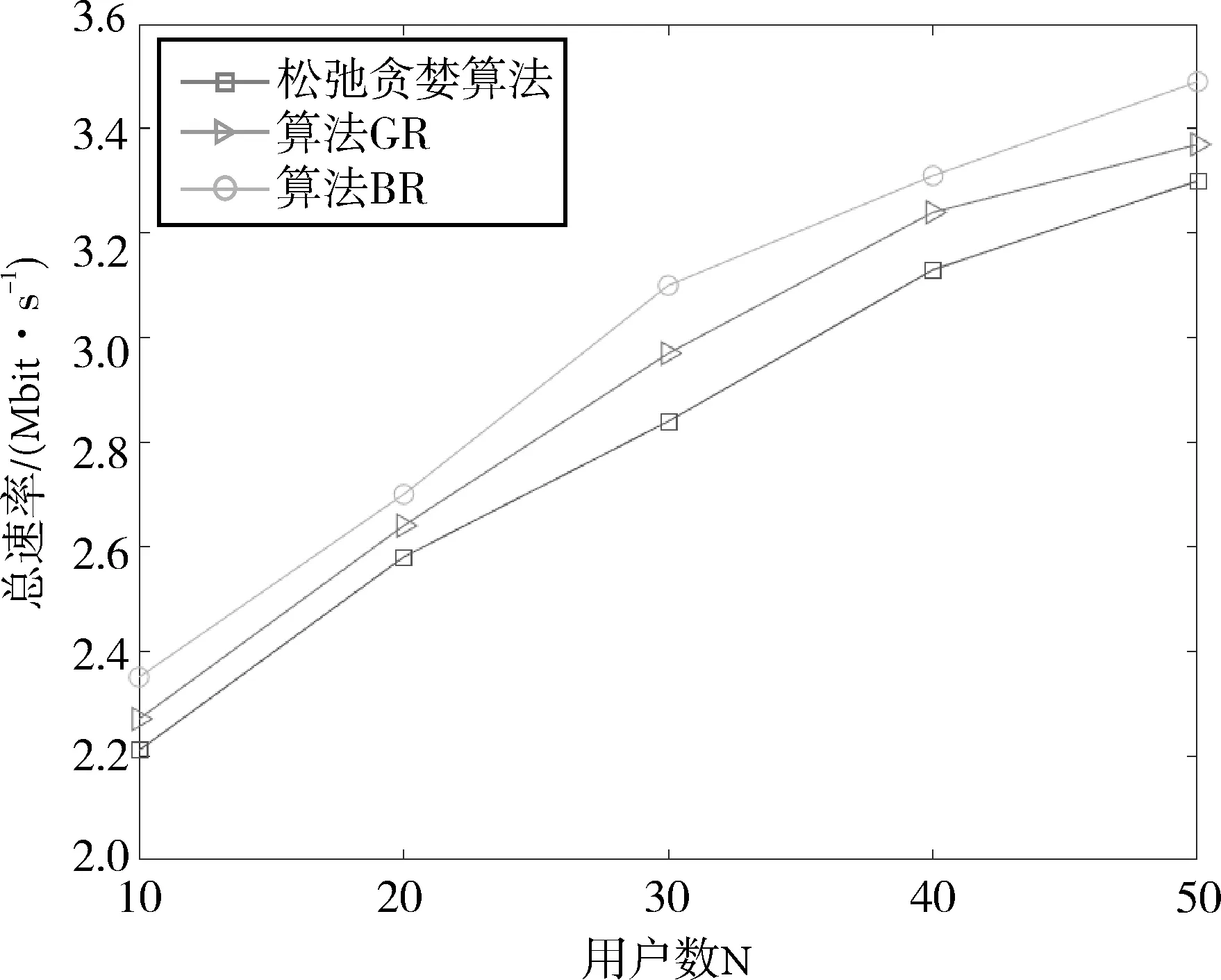
图7 不同用户选择算法下的性能对比(M=6)
当用户数分N别为10、20、30时,随着叠加用户数量的增加,GR算法、松弛贪婪算法以及BR算法的性能对比如图8、图9、图10所示。从图中可以看出,在用户数量不同时,随着叠加用户数量的增加,三个算法的性能相对平稳。其中,本文BR算法与GR算法以及松弛贪婪算法相比,其性能最优,提升了约3.1%、5.9%。BR算法可以得到系统最大总速率,并通过有效平衡最大总速率与算法时间复杂度,使得算法的可行性较强。
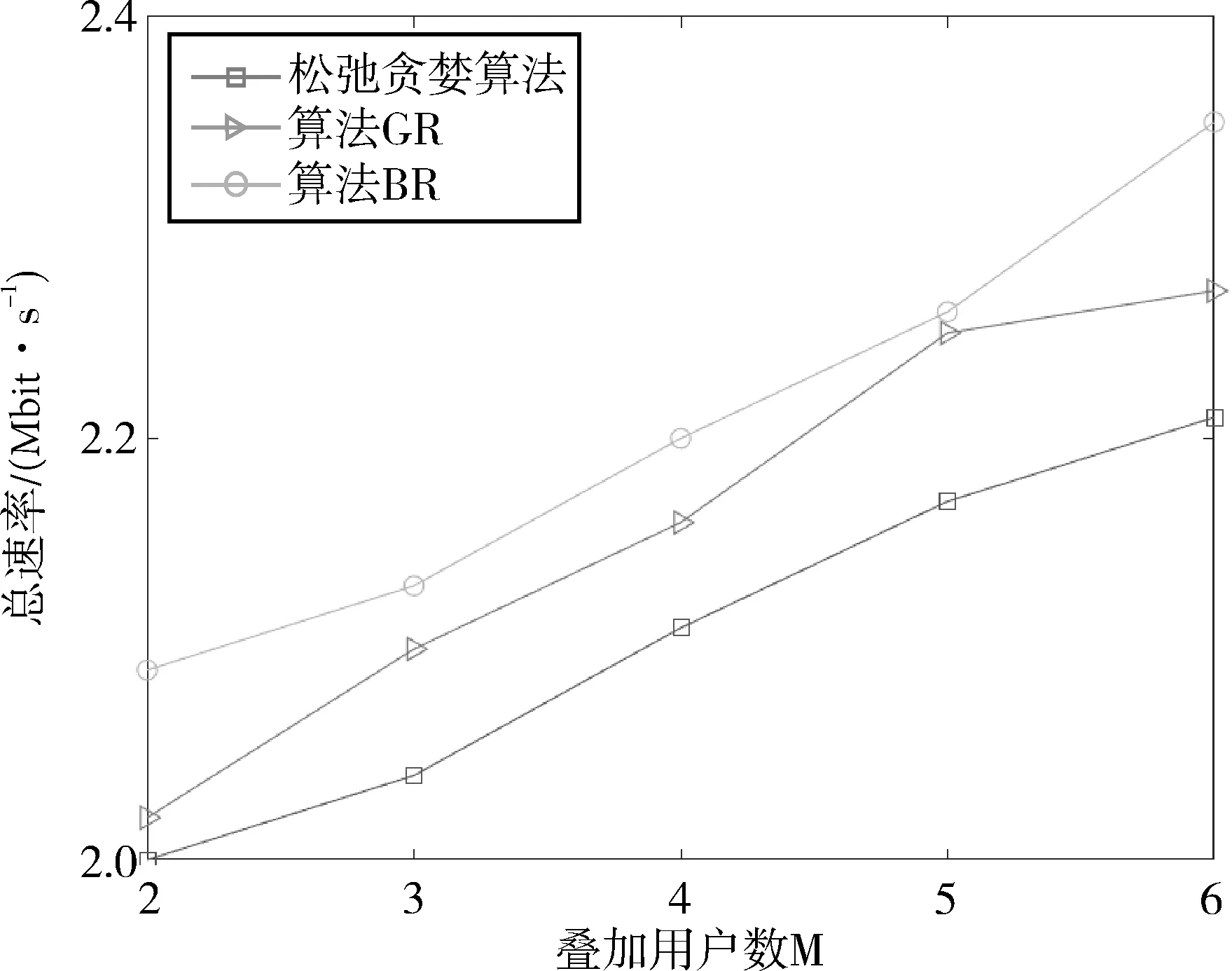
图8 不同用户选择算法下的性能对比(N=10)

图9 不同用户选择算法下的性能对比(N=20)
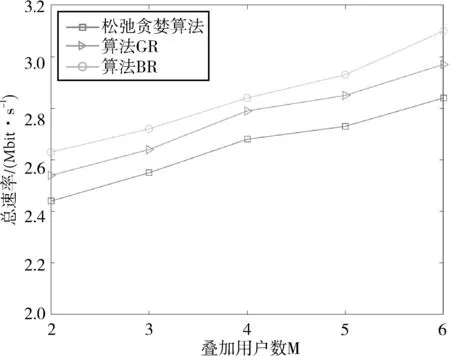
图10 不同用户选择算法下的性能对比(N=30)
5 结语
在下行NOMA系统中,以最大化总速率为目标研究了下行信道的用户选择问题。给定N个下行用户,单个信道最多可以叠加M个用户,在基站发射功率的约束下,提出了基于分支限界的用户选择算法对接入同一子信道的多个用户进行选择,使得系统内的总速率最大。仿真结果表明,本文提出的基于分支限界的用户选择算法与传统算法相比,可以得到下行NOMA系统最优总速率,也极大地降低了算法的时间复杂度。
