基于BiLSTM 改进聚类的空气质量监测点位优化①
2022-06-29马元婧
李 幔, 马元婧
1(中国科学院 沈阳计算技术研究所, 沈阳 110168)
2(中国科学院大学, 北京 100049)
随着我国经济水平的提高, 交通运输业的飞速发展以及工业现代化进程的不断加快, 空气质量水平作为可持续发展的重要组成部分, 也越来越受到人们的关注. 为及时精准地了解空气质量问题时空分布状况,提高动态反应空气质量的能力, 空气质量监测应运而生. 根据多年来的实验表明, 环境监测在采样过程中产生的误差是总体误差的重要组成部分[1]. 因此, 保证采样过程中监测点位选择的准确度就成为了空气质量监测与表征空气污染程度的关键[2]. 而监测点位的优化准确度依赖于空气质量监测微子站(以下简称为微子站)的监测数据的有效完整性, 但在微子站监测过程中, 常常由于各种突发因素导致一段时间内的数据缺失. 因此, 在根据微子站监测数据进行点位优化前, 进行缺失数据处理成为了不可或缺的一部分.
近年来, 随着空气质量监测点位优化问题研究的不断深入, 已有众多发达国家与地区对于空气质量监测点位优选提出了一系列的优化方法, 如相关性分析法、聚类分析法以及多目标优化等数学与统计学方法[3].我国对于空气质量监测点位优化的研究也在逐步发展,如徐明德等人提出的凝聚层次物元法[4]、杜增荣采用的凝聚层次聚类法[5]、姜林等人提出的BP 分析法[6]应用于空气质量监测点位优化. 这些方法各有特色, 可以很好地代表空气质量的准确性与代表性. 与此同时,随着对缺失数据处理问题的关注度不断提高, 大多被提出的数据填充方案大概分为以下两种填充思想, 第一种是对缺失数据邻近数据进行特征分析, 利用均值, 众数和聚类的方法表现数据特征进行填补的算法. 如李董等人提出的基于SMOTE 和KNN 的数据缺失填充算法[7]、袁兆祥等人提出的基于DBSCAN 聚类的数据补充算法[8]、杨挺等人提出的基于FSOM 神经网络的数据补充方案[9], 另一种缺失数据的填补方式是利用神经网络对数据整体特征进行分析与补充, 例如使用RNN来对缺失的数据进行填补操作. 如柯昊等人提出的BP 神经网络补差法[10]、宋维等人提出的基于LSTM的活立木茎干水分缺失数据填补方法[11], 对于数据缺失问题都有很好的表现. 因此, 本文首先选取在空气质量、水质、地质预测领域应用广泛, 原理简单, 计算量小的凝聚层次聚类法进行空气质量监测点位优化. 鉴于凝聚层次聚类法易受到初始聚类中心以及缺失数据的影响, 单独使用凝聚层次聚类法的聚类效果不理想.为了能够在空气质量监测点位监测数据缺失的情况下,拥有更好的聚类效果, 本文首先选取适用于具有时序特征缺失数据补充且能够反映空气质量监测数据双向特征的BiLSTM 神经网络对缺失数据进行填补, 然后应用凝聚层次聚类法对修复后的数据进行聚类分析,实现对空气质量监测点位的优化, 获取更加真实、精准的数据, 用以分析空气污染成因. 同时, 为环境质量监测有关部门制定点位优化标准提供有利的技术支撑.
1 基于BilSTM 改进聚类的点位优化模型
1.1 模型整体框架
针对空气质量监测点位优化的最终目的, 构建的基于BiLSTM 改进聚类的空气质量监测点位优化模型, 如图1 所示. 首先, 利用BiLSTM 数据补充模型进行数据补充解决监测数据缺失问题, 对于BiLSTM 中的正向LSTM 网络和逆向LSTM 网络具备相同的结构, LSTML部分是通过学习缺失数据之前时序的空气质量数据的数据特征规律来产生缺失数据的候选补充结果; LSTMR是通过学习缺失数据之后时序的空气质量数据进行同样的操作, 产生另一候选补充结果. BiLSTM神经网络通过使用缺失监测数据的前后m组数据对当前缺失的n组数据进行补充, 公式如下:
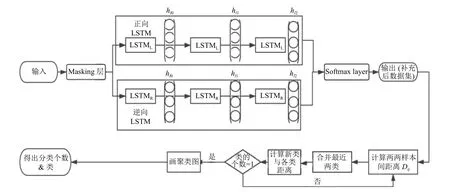
图1 基于BiLSTM 改进聚类模型
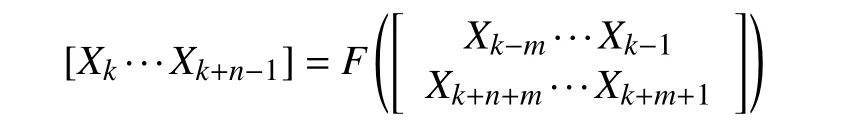
其中,F为基于BiLSTM 的数据补充模型, [Xk···Xk+n−1]表示缺失的n组数据.
最后使用一个Softmax layer 来综合正向LSTM和逆向LSTM 的候选结果并产生最终的缺失数据补充结果. 得到最终的输出结果传递给层次聚类部分, 输出聚类结果.
1.2 BiLSTM 模块
LSTM 神经网络是一种循环神经网络(RNN)的特殊变体. 在标准的RNN 中, 重复部分的模块表现为只有单个tanh 层的简单结构, 如图2 所示. LSTM 的基本结构与基础ANN 保持一致, 但是重复部分模块包含具有4 个网络层的特殊结构, 并且利用一种新的方式与其他部分实现交互[12]. 因此, 解决了RNN 的长期依赖以及梯度消失问题[13].
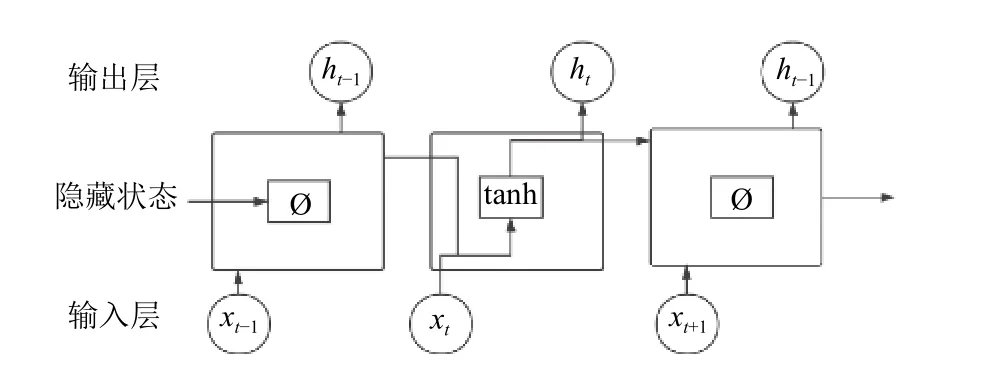
图2 标准RNN 结构图
LSTM 的网络结构如图3 所示, 其中包含输入门、遗忘门、输出门3 个逻辑单元, 输入门控制记忆单元中当前输入的状态; 遗忘门对前一个记忆单元处理结果进行筛选保留; 输出门控制记忆单元的输出状态[14].
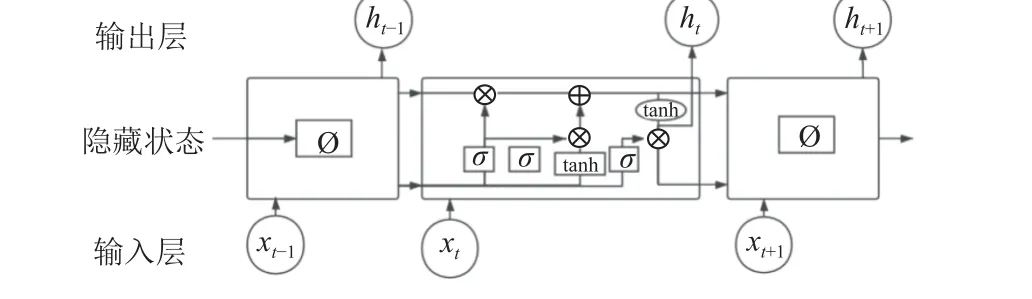
图3 LSTM 神经网络结构图
LSTM 的初始步骤在于判断细胞状态中信息的去留. 这一判断由遗忘门层进行.
遗忘门的状态更新公式为:
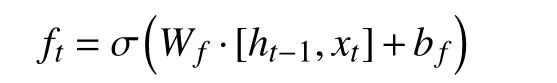
它接收ht–1和xt, 对于细胞状态Ct–1中的每部分的输出值都限制在0 到1 之间. 接受程度跟随0 到1 数值大小递增, 0 表示完全不接受, 1 表示完全接受.
下一步的目的在于判断细胞状态中需要更新的信息并建立新信息. 通过输入门层决定需要被更新的数据. 然后, 通过一个 tanh形网络层创建一个新的备选值向量Ct, 可以用来添加到细胞状态.
输入门状态更新公式:
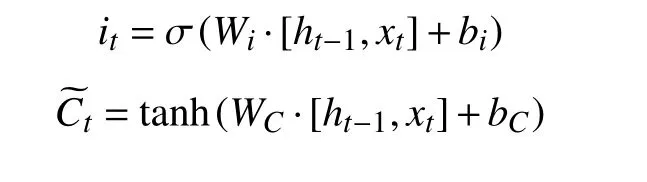
通过下述公式对细胞状态的更新:
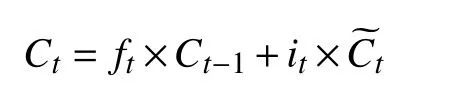
最后, 确定输出值. 首先, 确定细胞状态中的输出部分. 然后, 我们把细胞状态输入tanh 与s 形网络层的输出值相乘, 实现输出.
输出门状态更新公式如下:
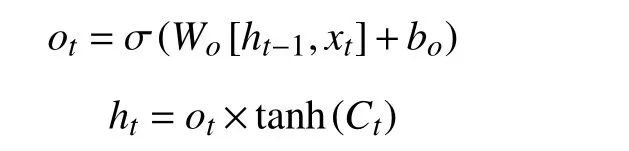
对于LSTM 来说, 只能学习数据对之前数据的依赖性, 无法充分考虑对之后数据的依赖性[15]. 在面对数据缺失问题时, 需要结合数据缺失前后数据来共同决定当前缺失数据补充. 图3 为BiLSTM 模型图.
BiLSTM 可以通过双向计算, 不仅能考虑到缺失数据之前的监测数据记录, 还能捕捉到后续监测数据.将前向LSTM 模型和后向LSTM 模型构成BiLSTM模型来学习双向监测数据信息.
1.3 聚类分析模块
本文采用聚类中的适用于少量特征、少量点位的凝聚层次聚类法(以下简称为层次聚类法)对没有预先处理的微子站点位监测数据进行分类[16–19]. 如图4 所示, 每个样本先自成一类, 然后按距离准则逐步合并,减少类数. 首先, 将微子站分为n类(每个微子站为一类), 计算类间距离, 将类间距最为接近的两类合并为一类, 循环计算n–1 类之间的间距, 不断合并各个微子站, 直到所有类都完成归类, 聚类结束[20]. 聚类分析根据类间距离的计算方法不同, 层次聚类法也不同. 本文采用最为常用的最小距离法计算类间距离.
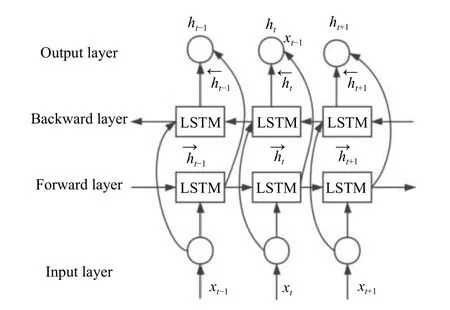
图4 BiLSTM 神经网络结构图
最小距离公式:
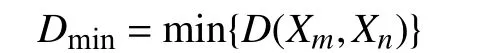
其中,D(Xm,Xn)为M类中的某个样本Xm和N类中的某个样本Xn之间的欧式距离.
欧式距离公式:
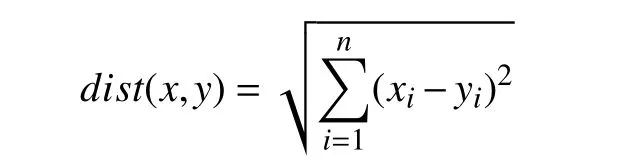
层次聚类法示意图如图5 所示.
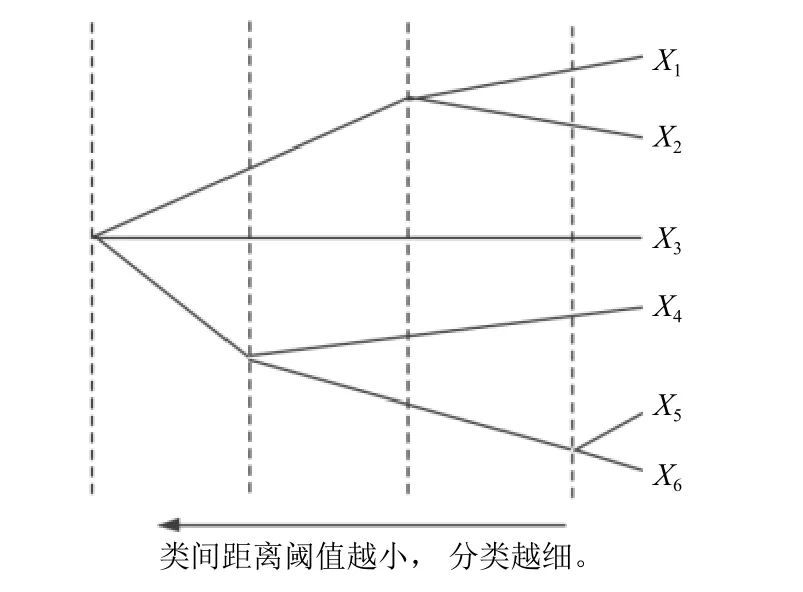
图5 层次聚类示意图
2 实验与结果分析
为验证本文提出的基于BiLSTM 改进的聚类算法的效果, 本实验数据集来源为沈阳市浑南区18 个微子站2020 年1 月–2021 年8 月的SO2、NO2、O3、PM10、PM2.5、CO 六种大气污染物的日均监测数据, 表1 为其中某月各站点6 种污染物日均监测数据.
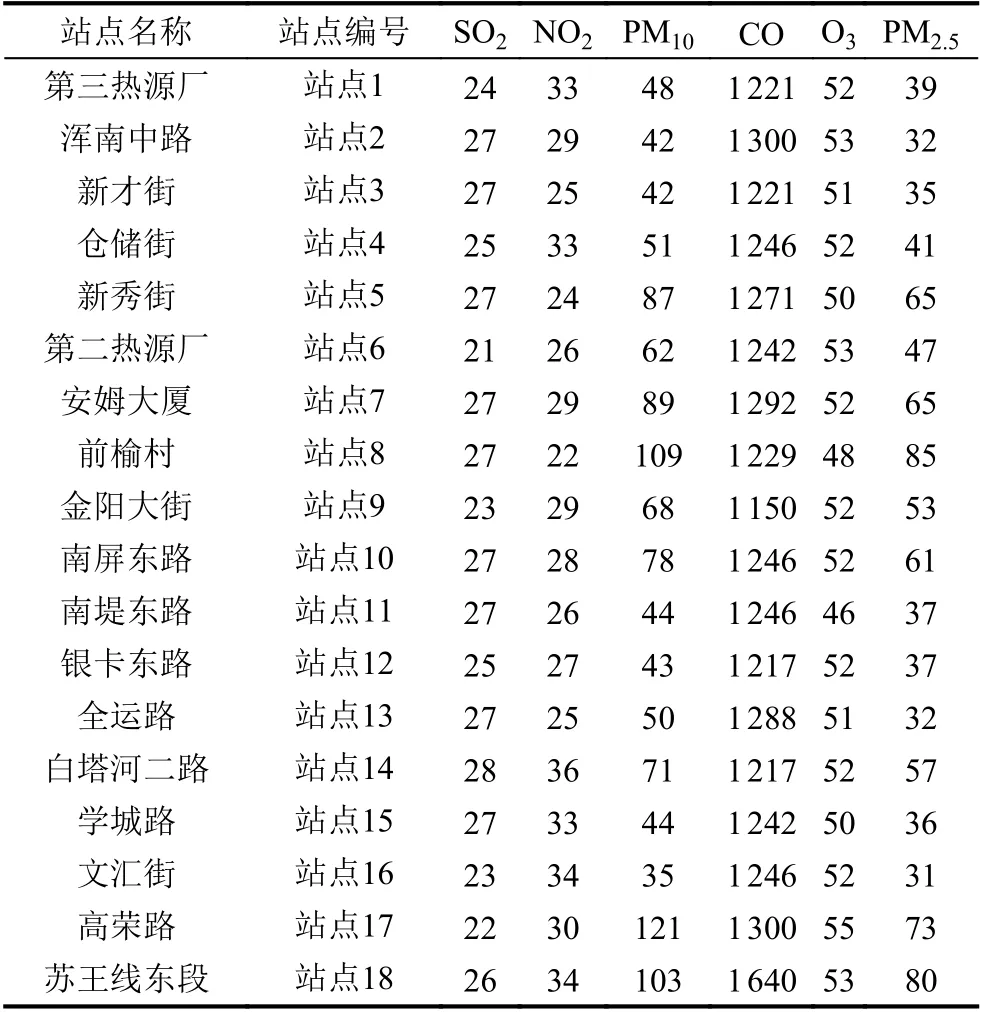
表1 主要污染物浓度监测日均值 (μg/m³)
实验中选取的18 个监测站点位置如图6 所示.
图6 监测站点位置
2.1 原始数据处理
部分原始数据如图7 所示, 在图7 中横轴代表的是部分月份各站点的CO 日均值原始数据组数, 纵轴代表的是CO 原始数据的浓度值. 从图上可以看出部分原始数据存在缺失的情况. 因此, 在使用此数据集进行模型训练和验证之前需要对原始数据进行数据预处理, 补充缺失数据.
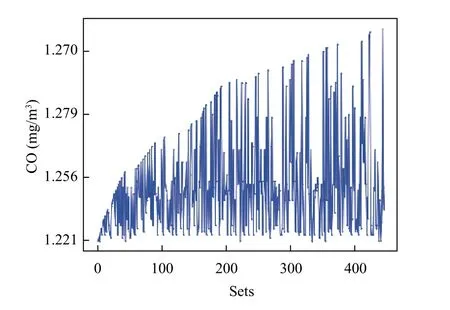
图7 CO 原始数据
同时, 数据的标准化处理是数据处理过程中的至关重要的一环, 将原始观测数据矩阵中的每类元素, 按照某种特定的运算把它变为一个新值, 使其更具有可比性. 因此, 在聚类分析之前, 对数据进行预处理, 将原始数据映射到(0, 1)之间, 即均匀化原始数据公式如下:

2.2 实验环境
本文实验所采用的硬件配置为: Intel(R) Core(TM)i5-1035G1 CPU@1.0 GHz 的处理器, 内存DDR4 (16 GB);软件环境为: 编辑器PyCharm 2019.3.2, Python 3.7,PyTorch 1.5.
2.3 实验过程
实验过程如图5 所示, 首先, 对数据进行标准化、归一化处理. 由于原始监测数据存在缺失, 因此, 对序列缺失处, 补上日期索引并特殊值标记该时间步, 之后,Masking 层接收经过预处理后的序列, 为后续BiLSTM层过滤掉标记为缺失的时间步, 为保证监测数据季节完整性以及客观地展示本文方法的补全效果, 将2020年1–12 月的数据作为训练集, 2021 年1–4 月的数据作为验证集, 输入上述的BiLSTM 网络模型中, 开始训练, 设置误差平方和E=0.001; 学习率 η=0.01. 经过589 次迭代训练网络达到要求. 最后, 将2021 年5–8 月的数据随机选取300 个监测数据, 删除其真实值作为缺失数据, 并将处理后数据作为测试样本输入已训练好的网络中进行估计, 得到缺失数据的估计值. 图8 为部分缺失数据估计值与真实值的误差曲线图, 可以看出BiLSTM 神经网络模型结果与实测值变化趋势基本一致, 由此可得出该神经网络模型训练结果良好.
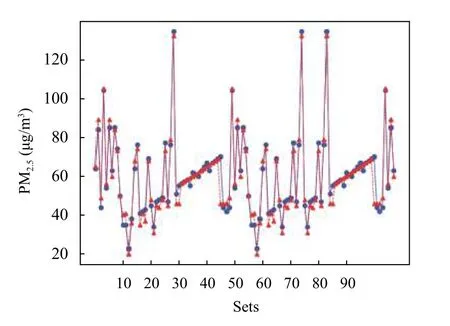
图8 监测数据补充值与真实值对比
为了更好地验证BiLSTM 神经网络模型的监测数据插补方法的效果, 本文将提出的数据缺失补充模型与以往在空气质量数据缺失情况下常用的均值补插法以及使用单向LSTM 神经网络进行对比. 为了评价模型描述实验数据的精确度与反映补充值误差的实际情况, 本文采用计算简便的均方根误差(RMSE) 与具有更强鲁棒性的绝对平均误差(MAE)来共同分析补充结果和真实测量值之间的偏差. 表2 是3 种模型关于部分站点数据补充结果的评价指标的对比, 一般来说当预测值与真实值之间的偏差越小, 也就是说MAE和RMSE 的值越小, 模型的补充效果越好.

表2 不同模型下缺失数据填补实验结果对比
由以上分析可以得出本文提出的模型在空气质量数据缺失的补充效果表现更优. 进而在此基础上, 基于补充数据进行聚类分析, 从18 个采样点中可选出1、2、3、5、6、8、9、10、13、14 共10 个优化点, 如图9 所示.
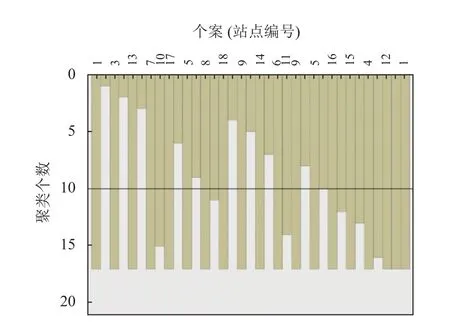
图9 填补数据层次聚类结果图
为验证算法选取的优化点位准确度, 对比单独使用原始数据进行层次聚类法选取的优化结果, 如图10所示, 发现与单独使用聚类分析法选择的1、2、4、3、13、16、8、5、6、10、14、17 等12 个点位基本保持一致.
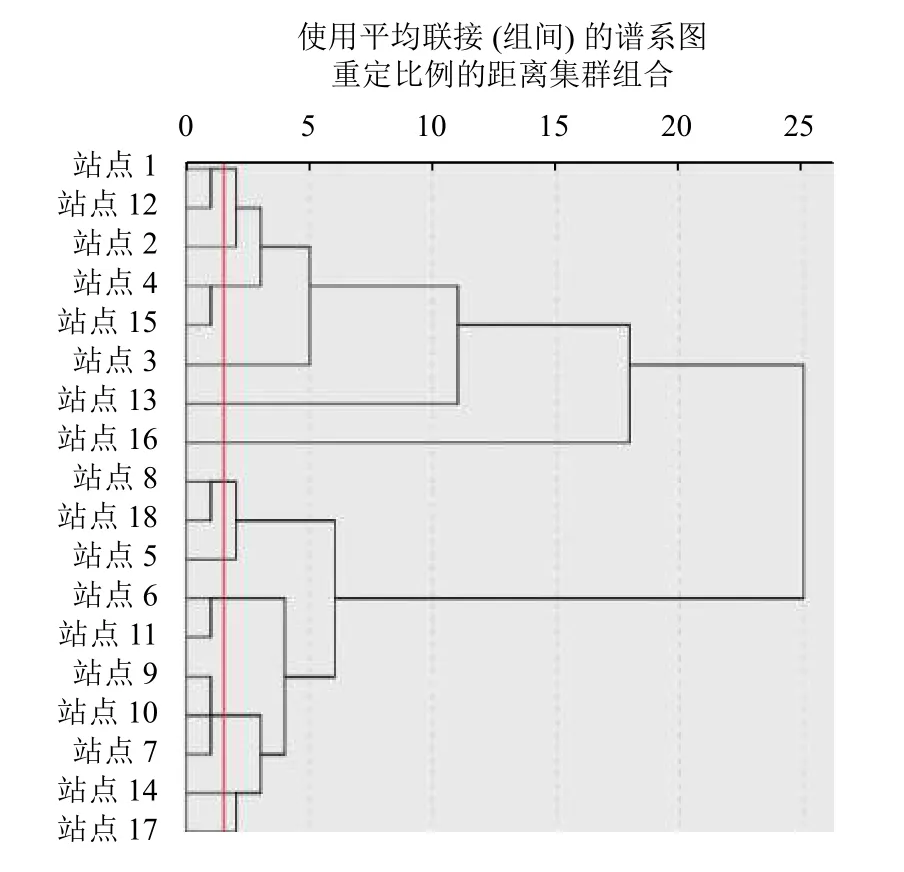
图10 原始数据层次聚类结果图
2.4 优化结果检验
本文通过相关性检验, 推断点位优化前后点位的可靠性, 通过选取沈阳市浑南区2021 年4–8 月6 种主要污染物浓度日均实测值进行相关性检验, 判断优选后的微子站能否客观地反映空气质量.
相关系数公式:
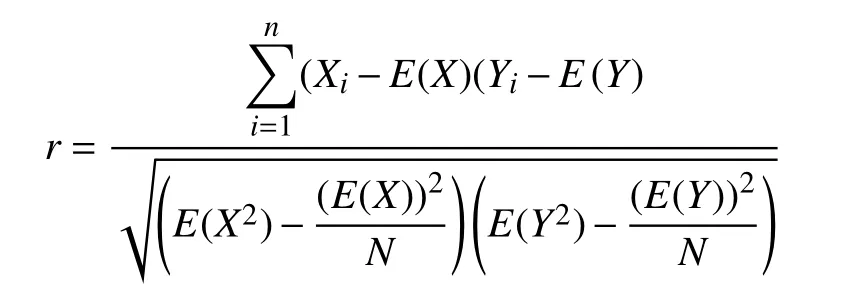
其中,Xi,Yi指优化前后污染物浓度值.
在给定α=0.05 时, 相关性表如表3.

表3 各污染物相关性系数表
根据表1 所示的相关性检验, 表明原点位与优化后点位的各污染物浓度密切相关, 无明显差异性.
为进一步验证优化前后监测数据的一致性, 选取部分监测数据采用方差齐性检验-F 检验法, 对优化前后数据的显著性差异进行检验. 在显著性差异不明显的前提下, 继续进行t检验, 确定两组数据是否具有一致性. 结果如表4 所示, 可以得出优化前后各污染物浓度之间具有一致性. 由此表明优化点位具有较好的代表性, 点位选择较为准确, 表明优化后的点位可以替代原点位.
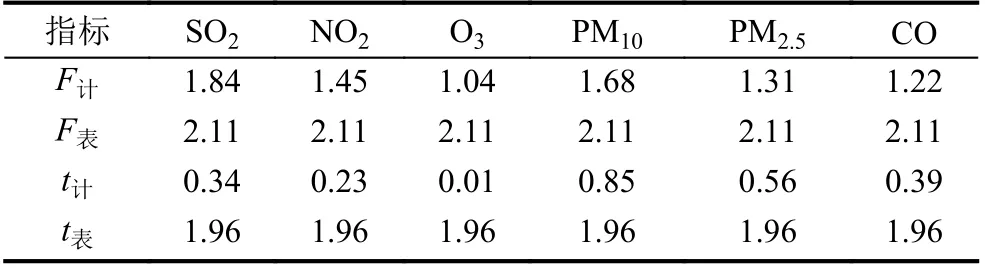
表4 一致性检验结果
2.5 性能评价指标
聚类属于无监督学习中的一种, 原始数据不具有标签, 需要一些定量的指标来进行评估算法的好坏[19,21].根据是否提供样本的标签信息, 相关的指标可以分为外部方法与内部方法, 内部方法指的是不需要数据的标签, 仅仅从聚类效果本身出发, 而制定的一些指标[16].因为点位优化属于无标签数据, 故选择内部方法的2 种评价指标:CH指数(Calinski-Harabaz index,CH)、戴维森堡丁指数(Davies-Bouldin index,DBI)作为评价标准, 对基于补充数据后数据集与基于原始数据集的聚类效果进行评价.
CH指数, 综合考虑了簇间距离和簇内距离, 计算公式如下:
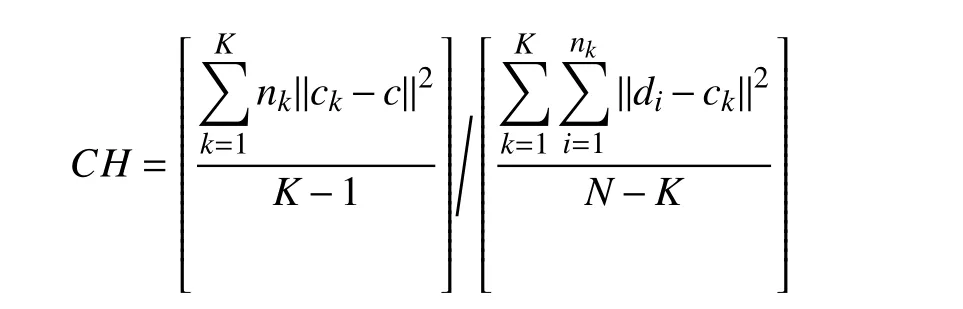
CH的数值大小与簇内距离成负相关, 簇间距离越大, 聚类效果越好.
戴维森堡丁指数, 公式如下:
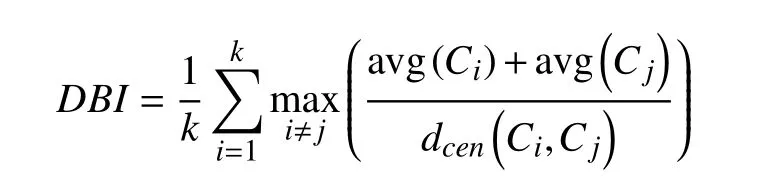
其中, avg(C)表示聚类簇的紧密程度, 公式如下:
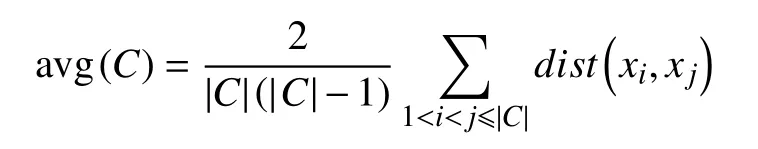
计算该聚类簇内样本点的距离,d表示不同聚类簇中心点之间的距离, 公式如下:

聚类簇间距离越远, 聚类簇内距离越近,DBI指数越小, 聚类算法性能越好.
BiLSTM 神经网络填补监测数据与原始数据两种状态下, 进行层次聚类后, 聚类效果评价指标对比如表5所示, 可以看出相比较于对原始数据进行聚类操作, 本文所采用的基于BiLSTM 改进的聚类算法聚类效果有所提升.

表5 评价指标对比
2.6 结果分析
根据BiLSTM 神经网络补充数据的改进聚类算法从18 个监测点位中选出了10 个监测点位, 与在原始数据上使用层次聚类法选出的12 个点位基本保持一致, 对比单独使用聚类算法选出的12 个监测点位. 此模型选择的点位更少, 并且聚类效果更好, 选择的点位代表性与准确性均得到提升, 为之后监测点位布设与优化提供一个更加高效准确的模型. 由表3 的计算结果可以推断本文提出的方法选择的点位是准确且具有代表性的.
3 结论
本文针对空气质量监测点位优化的最终目的, 通过层次聚类法对BiLSTM 神经网络补充后的微子站监测数据进行聚类处理, 在选择更加少量点位的基础上,提高了点位选择准确度, 提出了一种基于BiLSTM 神经网络改进聚类的点位优化算法.
