融合BERT 和图注意力网络的多标签文本分类①
2022-06-29裘杭萍
郝 超, 裘杭萍, 孙 毅
(陆军工程大学 指挥控制工程学院, 南京 210007)
在全球信息化大潮的推动下, 大数据得到了快速的发展, 人们处在一个海量数据的世界, 每时每刻都有新的数据信息产生, 这些数据不仅数量大并且还具有多样性, 这也使得人们用传统手段统计此类数据的时候变得困难[1]. 如何高效地处理这些数据是一个很有研究意义的问题, 这也推动着自动分类技术的发展.传统的文本分类问题中每个样本只对应一个标签类别, 属于单标签文本分类. 但在现实生活中, 样本信息往往不够理想, 一个样本可能拥有更加复杂的语义和内容[2]. Schapire 等人[3]提出了多标签学习, 与单标签文本分类不同, 多标签学习指的是从标签集中为每个样本分配最相关的标签子集的过程, 从而能够更加准确地、有效地表示单标签文本分类中不能表达复杂语义和内容. 比如题为“打造特色体育教学, 推进阳光体育运动”的新闻可能被同时认为与“体育”和“教育”两者相关, 一条微博可能同时与“新冠”“疫苗”和“医疗”有关等等.
1 相关工作
目前, 有关多标签文本分类已经提出很多方法, 这些方法主要可以分为3 大类: 问题转换方法、算法自适应方法和基于深度学习方法.
问题转换方法是最经典的方法, 通过将多标签分类问题转化为多个单标签分类问题来解决, 代表性的方法包括二元相关(binary relevance, BR)[4]、标签幂集分解(label powerset, LP)[5]和分类器链(classifier chain,CC)[6]. BR 方法将多标签分类问题分解为多个二分类问题来进行处理; LP 方法通过将标签组合看成分类类别, 将多标签分类问题转化为多分类问题来处理;CC 方法将多标签分类任务转化为二进制分类问题链,后续的二进制分类器链基于前面的进行预测.
算法自适应方法通过扩展相应的机器学习方法来直接处理多标签分类问题, 代表性的方法包括ML-DT(multi-label decision tree)、排名支持向量机(ranking support vector machine, Rank-SVM)和多标签K 最近邻(multi-label K-nearest-neighborhood, ML-KNN). MLDT 方法通过构造决策树来执行分类操作; Rank-SVM方法通过支持向量机(support vector machine, SVM)来处理多标签分类问题; ML-KNN 方法通过改进KNN方法以实现通过K 近邻来处理多标签数据.
随着深度学习的发展许多基于深度学习的多标签文本分类方法被提出, 代表性的方法包括TextCNN[7]、XML-CNN[8]、CNN-RNN[9]、SGM[10]和MAGNET[11].TextCNN 首次将CNN 应用于文本分类; XML-CNN 方法是对TextCNN 方法的改进, 采用了动态池化和二元交叉熵损失函数; CNN-RNN 方法通过将CNN 和RNN进行融合来实现多标签分类; SGM 方法采用Seq2Seq结构, 首次将序列生成的思想应用到多标签文本分类中; MAGNET 方法利用Bi-LSTM 提取文本的特征, 用图神经网络构建各标签之间的内在联系.
现有的方法没能充分考虑标签之间的相关性, 从而影响了分类效果. 针对此问题, 本文提出了一种基于BERT 和图注意力网络(graph attention network, GAT)的模型, 主要利用BERT 模型获得文本的上下文表示,通过Bi-LSTM 和胶囊网络分别提取全局特征和局部特征, 利用GAT 捕获标签之间的相关性, 从而来提升分类的性能.
2 模型构建
多标签文本分类(multi-label text classification,MLTC)的主要任务是通过若干类别标签对文本样本进行标注分类, 可形式化描述:d维的实例空间X=Rd,q个标签组成的标签空间Y={y1,y2,y3,···,yq}, 训练集为D={(xi,Yi)|1 ≤i≤m}, 模型通过从实例空间到标签空间学习一个映射:h:X→2Y多标签文本分类任务.其中, 在每个实例(xi,Yi)中,xi∈X是d维特征向量,Yi⊆Y是实例xi的标签集合, 测试样本通过映射h便可得到相应的标签集合[12].
本文提出的模型主要包括BERT 模块、特征提取与融合模块、GAT 分类器模块3 个部分, 具体的框架如图1 所示.
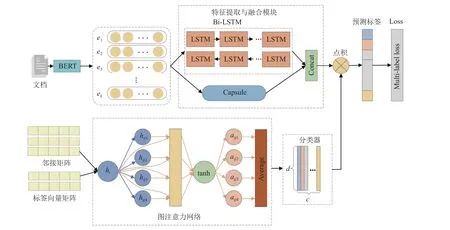
图1 模型框架
2.1 BERT 模块
文本信息对于人而言是可以直观理解的, 但是对于计算机而言无法直接处理, 因此需要将文本转化为计算机能够处理的数据. 传统的文本表示包括one-hot和矩阵分解, 但是在表示的时候会产生维度灾难、花费代价高等缺点, 随着神经网络的发展, 词嵌入(word embedding)作为一种新的词表示方式出现, 使用一个连续、低维、稠密的向量来表示单词, 简称为词向量.Word2Vec[13]和Glove[14]是一种静态的词向量表示方式, 对于任意一个词, 其向量是恒定的, 不随其上下文的变化而变化. 比如“apple”一词在“APPLE Inc”和“apple tree”中有同样的词向量, 但是这两处的意思是明显不一样的, 一个代表的是苹果科技公司, 一个代表苹果树, 静态词向量无法解决一词多义的问题.
为了更好的文本, 本文采用了预训练模型BERT[15]来计算每个单词的上下文表示, 依据不同的上下文对同一个单词有不同的表示, BERT 模型由多层Transformer构成, 接受512 个词的序列输入, 并输出该序列的表示,流程如图2 所示. 对于由k个词组成的文档作为输入W=[w1,w2,···,wk], 经过BERT 模型得到相对应的词向量E=[e1,e2,···,ek].
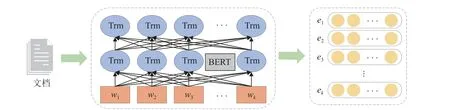
图2 BERT 模块
2.2 GAT 分类器
在图卷积网络(graph convolutional network, GCN)中, 一个节点的相邻节点具有相同的权重, 然而在图结构中相邻节点的重要性存在一定差异. 在GAT 中引入“注意力机制”[16]对此缺点进行改进, 通过计算当前节点和相邻节点的“注意力系数”, 在聚合相邻节点时进行加权, 使得当前节点更加关注重要的节点. 因此, 本文采用了GAT[17], 利用图注意力训练得到的结果作为该模型的分类器, 以便更好地挖掘标签之间的相关性.结构如图3 所示.
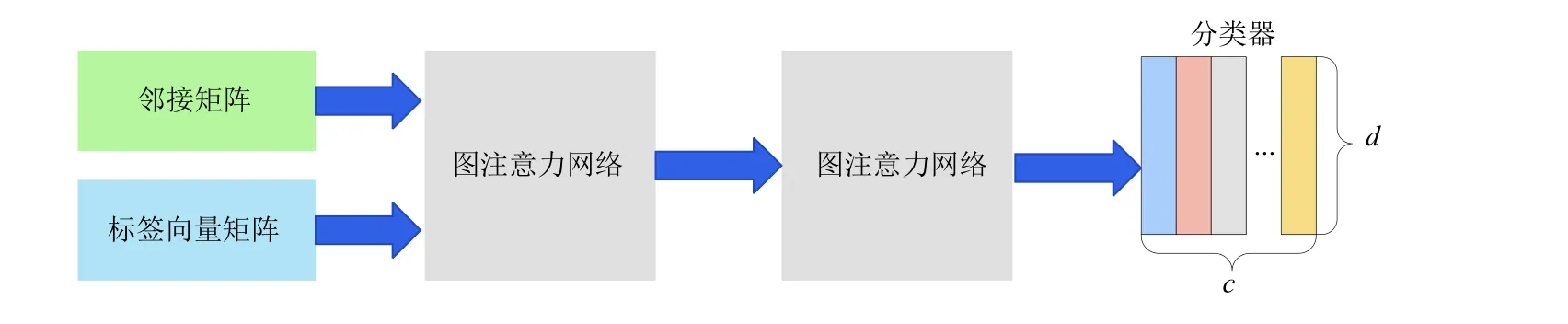
图3 GAT 分类器
在此模块中, 将标签向量矩阵和邻接矩阵作为GAT 输入, 经过两层的GAT 得到最终的分类器. 标签向量采用Stanford 官方预训练好的Glove 词向量, 其中包括有50 维、100 维和300 维3 种, 为了使标签包含更多的语义信息, 本文采用300 维的Glove 词向量作为GAT 的输入. 通过数据驱动[18]的方式建立邻接矩阵, 首先获得训练数据集中的标签共现矩阵M∈Rc×c,频率向量F∈Rc,Fi表示的就是标签i在训练集中出现的频率, 其中,c代表的是标签数量. 通过以下计算能够获得初始邻接矩阵A:

用如下公式更新l层的每个节点i的向量表示, 其中W是一个训练参数:

其中, ‖代表连接操作.
在本文模型中, 采用了Vaswani 等人[16]提到的多头注意力, 通过不同的注意力来获得更多的标签间的关系. 此操作将被复制K次, 每一次的参数都是不相同的, 最终将K次结果求均值得到最终的输出, 其计算公式如下:

2.3 特征提取与融合模块
将BERT 模块得到词向量分别作为Bi-LSTM 和胶囊网络的输入, 之后进行特征提取. 在特征提取时采用Bi-LSTM 来提取全局特征, 并通过胶囊网络来兼顾局部特征, 最后通过特征融合的方式得到最终的特征向量. 这样能够充分利用上下文信息, 减少特征的丢失,从而带来更好的分类效果.
(1)胶囊网络
通过对卷积神经网络进行改进形成了胶囊网络,在传统的卷积神经网络中, 池化步骤往往采用的是最大池化或者平均池化, 此过程中会造成特征信息大量丢失. 针对这一问题, Hinton 提出的胶囊网络[19]用神经元向量代替卷积神经网络中的单个神经元节点, 能够确保保存更多的特征信息, 提取到局部特征.
动态路由是胶囊网络的核心机制, 通过动态路由来训练神经网络, 能够获取文本序列中的单词位置信息并捕获文本的局部空间特征, 动态路由的过程如图4所示.
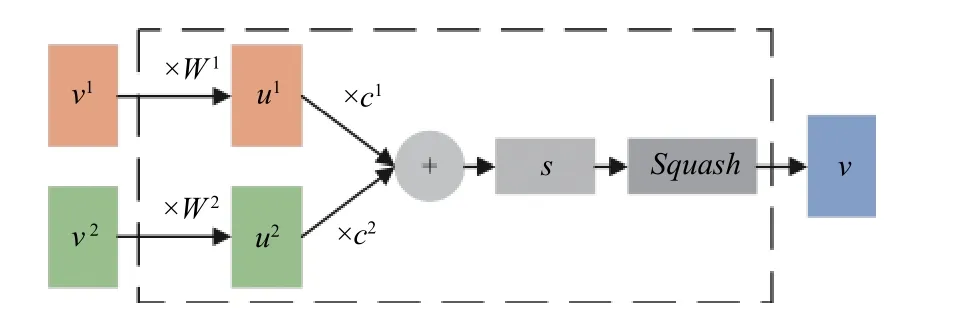
图4 胶囊网络
在胶囊网络中, 底层胶囊ui将输入向量传递到高层胶囊uˆj|i的过程称为路由, 高层胶囊和底层胶囊的权重通过动态路由获得, 过程如下:
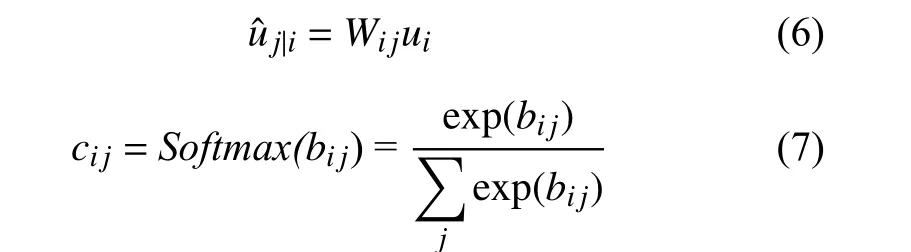
其中,Wij为权重矩阵;cij为耦合系数.
cij用来预测上一层胶囊和下一层胶囊的相似性,其通过动态路由的过程来决定, 并且输入层和输出层之间所有cij值和为1;bij的初始值设置为0, 通过迭代更新.

传统的神经网络中, 多数情况下会使用Sigmoid、tanh 和ReLU 等激活函数, 但在胶囊网络中创建了一个新的激活函数Squash, 只会改变向量的长度, 不会改变向量的方向. 其中,sj通过耦合系数cij和uˆj|i加权求和来得到, 作为Squash函数的输入.

通过胶囊网络动态路由的迭代, 可以获得局部特征Hc=(v1,v2,v3,···,vk).
(2) Bi-LSTM
长短时记忆网络(long short-term memory, LSTM)[20]能够有效缓解梯度消失问题, 但RNN 和LSTM 都只能依据前一时刻的信息来预测下一时刻的输出. 在有些问题中, 当前时刻的输出除了与之前的状态有关外, 还可能和未来的状态有一定的联系. 比如在对缺失单词进行预测时, 往往需要将其上下文同时考虑才能获得最准确的结果.
双向长短时记忆网络(bi-directional long short-term memory, Bi-LSTM)[21]有效地改善了这一问题. 一个前向的LSTM 和一个后向的LSTM 组合成Bi-LSTM. 通过前向和后向的特征提取, 能够更好地建立上下文之间的关系, 从而捕获全局文本特征. Bi-LSTM 结构如图5 所示, 计算公式如下:
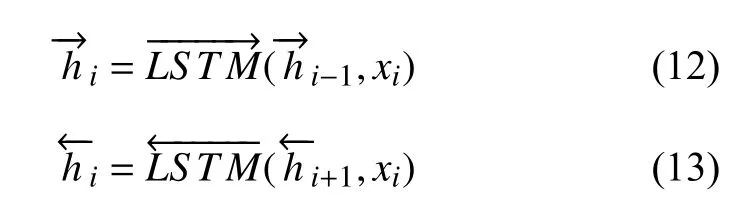
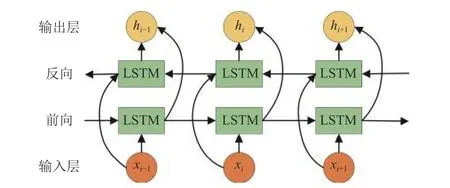
图5 Bi-LSTM 结构

(3)特征融合
传统的模式识别通常运用的是人工设计的特征,经过特征提取算法得到特征数据; 神经网络相比与传统模式识别, 具有自动提取特征的特点和更好的特征提取效果, 特征的优劣影响分类结果的好坏. 因此, 需要提取较优的特征. 胶囊网络作为对卷积神经网络的改进, 在提取局部特征的时候有着不错的效果; Bi-LSTM通过前向和后向的传播, 能够较好关联上下文信息, 提取全局特征.
在本文模型中, 充分的发挥两者的优势, 分别采用胶囊网络和Bi-LSTM 来提取文本的局部和全局的特征, 通过特征融合的方式将两者特征提取结果进行信息的融合连接. 融合连接有两种常用方式: 第一种是相加融合, 通过直接将对应维度的数据进行相加实现, 这种方式不会改变特征向量的维度, 能够避免维数灾难;另一种是拼接融合, 通过将维度进行拼接来实现, 这种方式会是将两种特征向量拼接后, 维度会变大[22]. 由于拼接融合会导致维度增大, 可能会造成维度灾难, 因此,本文选择相加融合的方式.
胶囊网络提取的特征可以用Hc=(v1,v2,v3,···,vk)来表示, Bi-LSTM 提取的特征可以用HL=(h1,h2,h3, ···,hk)来表示, 通过相加融合的方式, 可以得到新的特征H, 从而提升模型的效果.
通过分类器训练获得的每个标签向量和胶囊网络以及Bi-LSTM 获得的融合特征向量相乘就可以得到标签最终的得分, 得到最终的结果. 计算公式如下:

2.4 损失函数
在实验中, 损失函数选择二元交叉熵(binary cross entropy loss), 它广泛应用于神经网络分类训练任务中.假设文本的真实值是y∈Rc,yi={0,1}表示标签i是否属于该文本, ^yc表示的是模型的预测值. 具体的计算公式如下:
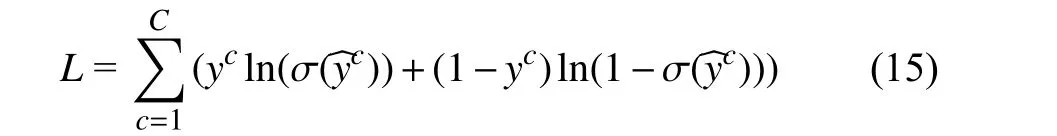
其中, σ(·)代表的是Sigmoid 函数.
3 实验与结果分析
3.1 数据集介绍
本文采用了多标签文本分类领域常用的数据集.包括Reuters-21578 和AAPD, 表1 为数据集详细信息.

表1 数据集简介
Reuters-21578: 该数据集是由路透社新闻组成的,收集了10788 条来自路透社的新闻, 包括7769 条训练集和3019 条测试集组成, 一共包含90 个类别.
AAPD[9]: 该数据集是由Yang 等人提供. 是从网络上收集了55840 篇论文的摘要和相应学科类别, 一篇学术论文属于一个或者多个学科, 总共由54 个学科组成.
3.2 实验参数设置
本实验利用了GAT 来捕获标签之间的关系, 在进行实验时, 主要采用了两层带有多头注意力的GAT 层.在对句子和标签进行表示时候, 均采用了BERT 向量获得其表示. 对于Reuters-21578 和AAPD 数据集, 模型的批处理大小Batch Size 均设置为250, 训练过程中使用了Adam 优化器来使目标函数最小化, 学习率大小Learning Rate 设置为0.001, 并且在模型中添加了Dropout 层来防止过拟合, Dropout 的值取0.5, 多头注意力机制头的个数K=8. 表2 为实验参数的汇总.

表2 网络参数说明表
3.3 实验评价指标
在本文的实验中, 使用Micro-precision、Microrecall、Micro-F1[23]和汉明损失[3]作为评价指标, 其中,将Micro-F1 作为主要的评价指标, 各个指标的具体计算公式如下:

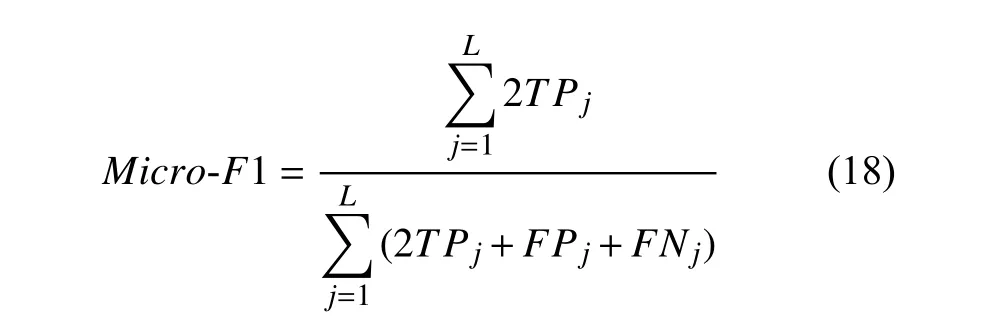
其中,L代表类别标签数量,TP代表原来是正样本被预测为正的数量,FP代表原来是正样本被预测为负的数量,FN代表原来是负样本被预测为正的数量.
汉明损失指的是被错分的标签的比例大小, 也就是两个标签集合的差别占比. 其计算公式如下:

其中, |S|是样本的数量, |L|是标签的总数,xi表示标签,yi表示真实标签, XOR 是异或运算.
3.4 实验结果与分析
3.4.1 实验对比
为了验证本文提出模型的有效性, 选择与现有的多标签文本分类方法: BR[4]、CC[6]、ML-KNN[24]、CNN[7]、CNN-RNN[9]、S2S+Attn[25]、MAGNET[11]进行对比实验.
本文提出的方法在Reuters-21578 和AAPD 数据集的结果如表3 和表4. 在正确率(P)、召回率(R)、F1 值和汉明损失(HL) 4 个常用的评价指标上与其他模型进行了对比, P、R 和F1 中的“+”代表该值越高,模型的效果越好, HL 这一列中的“–”代表该值越小, 模型的效果越好. 其中实验的最佳结果由加粗黑体表示.
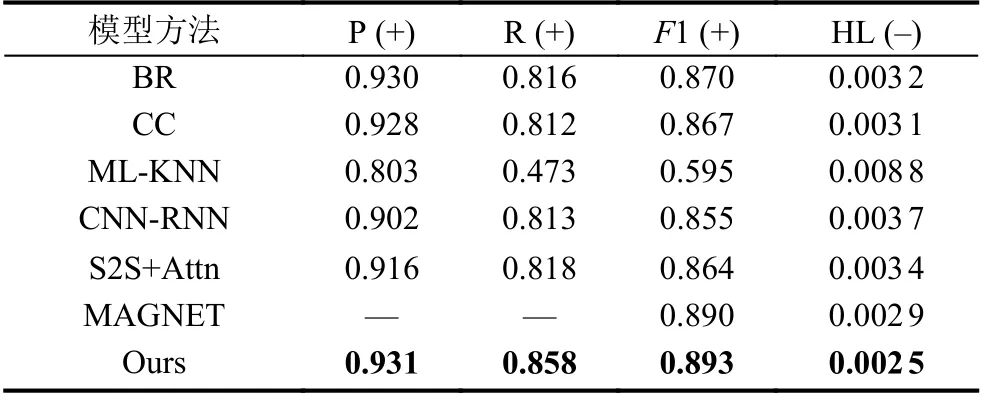
表3 Reuters-21578 数据集上结果对比
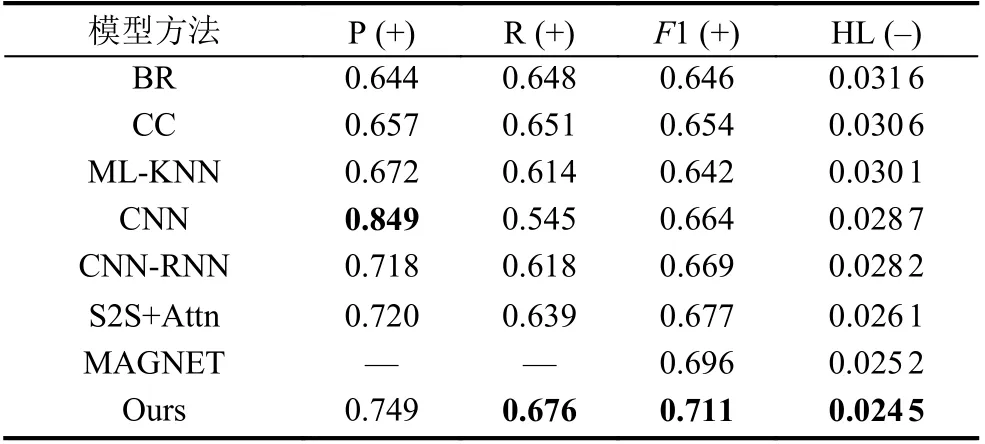
表4 AAPD 数据集上结果对比
从表3 和表4 的实验结果可以看出, 本文提出的模型在Reuters-21578和AAPD 数据集上大部分评价指标上都展示了最好的结果. 在Reuters-21578 数据集上, 与CNN-RNN 相比在F1 值上面提升了接近4%, 汉明损失的值也取得了最优的结果; 在AAPD 数据集上,本文模型在召回率、F1 值和HL 值上相比于其他模型均达到了最佳效果, 其中F1 值比最优模型MAGNET提升了约1.5%. 在准确率指标上, 传统的CNN 表现最佳, 本文模型次之. 主要原因在于CNN 是基于字符级别的模型, 利用网络特点细粒度地抓取标签与字符文本之间的关联, 从而提高模型的准确率, 另外, 在实验训练方面, CNN 在分类任务上超参数调整较小, 也是其在准确率上取得最佳表现的原因之一. 综合4 类评价指标的实验结果来看, 本文提出的模型比其他模型更具适用性, 在有效提升F1 值、召回率和减少汉明损失的同时, 兼顾了多标签文本分类的准确率.
从实验结果看, 深度学习方法普遍要比传统机器学习方法(包括BR、CC、LP 等方法)表现更好. 这主要是由于传统机器学习方法处理此类问题的时候是利用人来提取特征, 往往会带来一些误差, 并且在一些复杂情况下, 有更多的局限性. 而深度学习方法最大的进步就是能够自动提取特征, 从而比传统机器学习方法有更好的效果, 在特征提取上, 深度学习领域也涌现出了很多方法, 本文提出的方法采用了Bi-LSTM 和胶囊网络的方法, 比只采用了Bi-LSTM 的模型MAGNET有着更好的效果, 证明了胶囊网络的有效性.
在处理多标签文本分类问题的时候, 标签之间的相关性是非常重要的信息之一. 传统的机器学习模型在处理多标签文本分类问题上没有考虑标签之间的相关性, 本文提出的方法利用GAT 来捕获标签之间的相关性并建模, 从而来生成分类器, 提升了在多标签文本分类任务上的效果.
综上可知, 本文提出的方法与传统机器学习方法和现有的深度学习方法相比, 取得了具有竞争力的结果.
3.4.2 不同词向量比较
为了验证BERT 在词向量上的表现, 采用了一组对比实验来说明. 采用了目前比较常用的3 种词向量包括Word2Vec 向量、Glove 向量和BERT 向量, 并且在对比实验中加入随机向量(random). 在Reuters-21578数据集上进行比较, 结果如图6 所示.
从图6 可以看出, Word2Vec 向量和Glove 向量的结果接近, 随机向量的结果是最差的, BERT 向量的结果是最好的, 因此, 用BERT 向量能够提升本文方法的准确率.
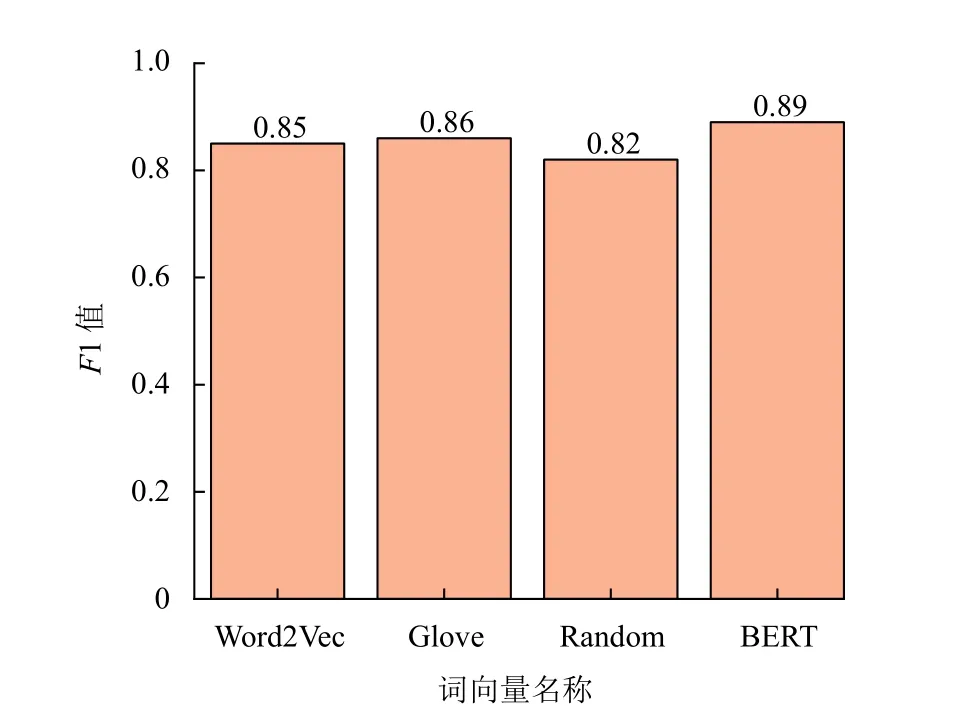
图6 Reuters-21578 数据集词向量比较
4 总结
本文提出了一种基于BERT 和GAT 的模型HBGA来解决多标签文本分类问题, 该模型是一个端到端的结构. 首先, 利用BERT 模型获取文本的上下文向量,通过GAT 来捕获标签之间的注意力依赖结构, 使用特征矩阵和邻接矩阵来探索标签之间的关系, 进行训练后形成一个分类器, 利用Bi-LSTM 和胶囊网络分别提取文本的全局特征和局部特征, 进行特征融合获得文本的特征向量, 最后将分类器和特征向量进行整合得到最终的结果. 实验结果表明, 提出的模型在F1 值上均优于对比模型, 有效地提升了多标签文本分类的性能. 目前模型仅仅在标签集小的数据集下取得不错的效果, 在接下来的工作中, 将探究如何在大规模标签集下的提升性能.
