应用梯度提升树的小区域无线网络多标签流量预测*
2022-06-28杜施默陈国军周海骄
杜施默,陈国军,陆 敏,张 晨,周海骄
(中国移动通信集团浙江有限公司杭州分公司,杭州 310015)
0 引 言
随着科学技术的进步以及互联网内容的延伸发展,网络早已从一种先进的传播方法发展成为人们一种不可或缺的生活方式。根据思科对网络发展的预测,用户数与无线流量不断攀升,移动流量将以每年42%的速度增长[1],然而重要城区内基站密度已趋于饱和,无线承载网络面临巨大的压力。因此,收集各项历史信息发掘基站流量变化规律以对链路流量进行准确的预测极为必要[2]。合适的网络流量预测方法一方面能够指导网络管理与调度,提高整个网络的数据传送效率[3-4];另一方面针对流量预测结果优化资源配置,防止流量拥塞,提高用户体验质量[5]。
当前研究多是探寻历史流量间的关联关系从而进行预测,然而考虑到无线基站流量与其覆盖范围内用户数及用户流量使用行为息息相关,上述方法存在一定局限性,即预测样本较为单一,并未将基站周边多维度环境因素考虑进来。因此,有学者将目光转向基于环境因素的无线网络流量预测[2,6-7]。然而,当前无线通信一个重要的特点是与用户聚集性和聚集群体的偏好强相关,上述几种方法均是将相对平稳的外界信息源作为预测模型的输入,并未将此类突发性纳入考虑。
因此,本文以指导无线网络临时性活动保障前软硬件扩容为目的,将有效捕获影响临时性流量的波动特征,并在该特征的基础上实现对临时性流量预测作为本文研究思路的核心,提出基于梯度提升树(Gradient Boosting Decision Tree,GBDT)的多标签无线网络流量预测方法。本文以无线网络中忙时流量预测为框架,以“天”为采集时间间隔,以“小时”为采集样本粒度,研究适合小区域突发性流量的预测方法(每天最大单小时流量),以指导临时性活动前的资源分配。
对于小区域内的网络资源投入,由于缺乏准确有效的流量预测方法,当前的网络资源主要根据活动类型,依靠优化人员经验测算此区域在后续时间段内的流量最大值,从而计算资源投入量。本文从电力负荷预测中环境因素的相关概念方法中得到启示,将外部环境考量用于小区域的网络流量预测,以应对现网用户区域性聚集及流量突发性增长。
1 小区域无线网络流量特征分析
1.1 日常无线网络流量趋势分析
鉴于无线网络流量是由该基站覆盖区域内的用户行为信息汇聚而成,流量预测本质上说就是将用户行为引发的流量变动趋势挖掘出来。从图1可以发现,大区域流量由于范围扩大模糊了小区域流量中用户聚集带来的突发性,其自相关性明显增强,大区域流量预测方法不再适用于小区域。

(a)小区域流量变动趋势
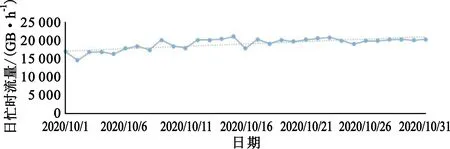
(a)大区域流量变动趋势图1 无线网络忙时流量变动趋势
因此,针对突发性明显的无线网流量序列,仅利用历史数据中包含的信息不足以形成精确预测。因此,本文进行反向思考,从影响用户行为的外部因素入手,量化外部因素的贡献度,从而实现预测流量。
1.2 外部各因素影响分析
考虑引起用户聚散、流量突增或陡降的原因,大体可分为天气因素、覆盖场景、日类型、活动事件类型等,小区域内主要影响因素的选择直接影响到预测精度。为选取合适的外部影响因素,衡量对于流量变动的贡献,本文以信息增益分析。
1.2.1 天气对流量影响分析
天气因素对当日流量大小有着较大影响,例如发生高温、降雨等。由于天气因素对于当日流量的影响具有“隐含性”,即天气因素对于流量的贡献度隐含于历史流量序列中,当天气因素无明显变动时仅使用平稳时间序列预测便有可能利用隐含天气信息得出较准确的预测结果;但当天气因素明显改变时,其信息无法从历史流量序列中体现出来,必须另作考量。参照基本成熟的电力负荷预测领域[8],流量预测相关天气特征提取如表1所示。

表1 天气因素特征提取及说明
1.2.2 覆盖场景对流量影响分析
日常运维发现,基站流量与其覆盖场景强相关,为量化各覆盖场景类型对流量的贡献度,本文采用2020年8~10月OMC上采集的基站流量数据,计算信息增益进行衡量。为突显覆盖场景对于流量影响,本文对同一地市内同类型场景进行流量汇聚,以平衡特殊活动事件带来的影响。
对全网基站忙时流量分布进行统计,得到其概率分布(Probability Density Function,PDF)如图2所示。
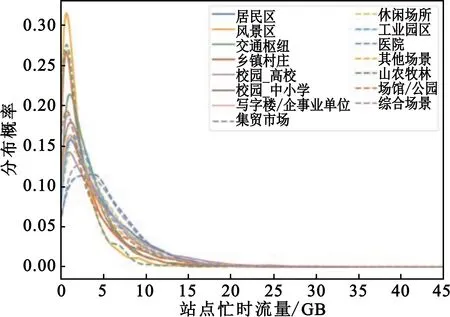
图2 全网基站忙时流量概率分布图
分析图2可知,覆盖场景对于基站忙时流量有着明显的影响。以全网综合流量分别作为对照,忙时流量分布近似于对数正态分布,风景区流量的分布较为集中,医院场景流量的分布较为平均。为进一步量化覆盖场景对于忙时流量的贡献大小,本文以熵为切入点,计算考虑覆盖场景后忙时流量不确定性减少的程度(即信息增益)。
综合场景内的忙时流量可看作是一个连续信源,则不考虑场景时忙时流量的信息熵为
(1)
式中:X代表综合场景下的某站的忙时流量,流量的大小用x表示,p(x)则代表此忙时流量为x的概率,Hc(X)为X的信息熵即事件X出现的不确定性。
当加入X的场景信息Y后,X的不确定性降低至式(2)所示:
(2)
式中:yi(i=1,2,…,n)表示n个场景中的某一种(如y1代表居民区)。如此可得到每类场景对应忙时流量的不确定性减少量,如式(3)所示:
Gaini(X,Y)=Hc(X)-Hc(X|Y=yi)。
(3)
得到各场景下的信息增益如图3所示,其中山农木林由于流量较小,且与现网其他场景流量相比最为明显,其信息增益最大;居民区、集贸市场的流量由于用户活动行为与现网无明显差异,其信息增益较小。根据信息增益筛选贡献明显的覆盖场景作为特征项,选取“风景区、交通枢纽、乡镇村庄、校园(高校)、校园(中小学)、写字楼/企事业单位、休闲娱乐场所、工业园区、医院、山农牧林、大型场馆/广场公园、其他”分别用0~11表示。

图3 覆盖场景信息增益
1.2.3 日类型对流量影响分析
基于电力负荷预测中对于日类型的影响的分析,本文选取相关特征因素如表2所示。

表2 日类型因素特征提取及说明
1.2.4 活动事件对流量影响分析
本文通过整理日常网络运维过程中的舆情上报信息,选取特殊活动事件如表3所示。

表3 活动事件因素特征提取及说明
2 基于GBDT的流量预测方法
基于第1小节中的流量特征分析可以得出,天气、场景及特殊事件对无线网络流量的影响不可忽视。然而,当前对于网络流量的研究成果中并没有考虑此类因素的影响,导致无法精确指导优化维护人员进行网络扩容[9-10]。因此,本文在充分考虑整合移动平均自回归(Autoregressive Integrated Moving Average,ARIMA)模型与日常网络流量自相似性的匹配优势的基础上,结合决策树对多标签样本预测的方法,将日常等比流量预测结果嵌入到决策树中,构建多标签预测模型。
2.1 多标签流量预测模型
考虑到手机已然成为日常生活中不可或缺的社交工具,当前无线流量中承载着丰富的用户行为活动信息,如此流量的波动趋势必然与用户的活动息息相关。进一步,本文在日常流量自相似性模型的基础上,从终端行为考虑用决策树分类方法加以校正。预测模型总体结构如图4所示。

图4 多标签流量预测模型
2.2 基于ARIMA的日常增长等比预测方法
为最大程度上弱化流量的突发性,本文借助宏观上全网大尺度流量变动趋势,模糊场景及特殊事件对局部流量的影响,以观测日常流量增长趋势。本文中以日常等比预测指代。
利用扩展的迪克富勒检验(Augmented Dickey-Fuller,ADF)判断流量序列平稳性,得到p值为0.167,大于判断标准值0.05,说明流量序列为非平稳序列。进一步,对原始流量进行一阶差分得到P值为0.000 013,一阶差分序列满足平稳性要求。图5为对差分后的数据定阶,可以看到自相关和偏相函数均具有拖尾的特点,且都存在明显一阶相关性,即可用ARIMA模型(1,1,1)拟合,如式(4)所示。

(a)自相关函数(ACF)

(b)偏自相关函数(PACF)图5 流量相关分析
(1-αB)(1-B)×Xt=(1-βB)×εt。
(4)
式中:B为滞后算子,(1-αB)为自回归系数,(1-B)为差分算子,(1-βB)称为滑动平均系数,εt为零均值白噪声。
2.3 基于梯度模型树的流量预测方法
鉴于无线网络流量对于外部因素的敏感性,本文以GBDT引入外部影响因素y参与训练流量序列Xt的预测模型训练提高预测准确性,初始化弱学习器如式(5)所示:
(5)
式中:N为训练样本数量,F0为初始模型,γ为使损失函数L最小的常数值。对于第m次迭代(迭代轮数m=1,2,…,M),以找到损失L最小的弱学习器为目标,更新强学习器。其中m次迭代的第t个值的损失函数负梯度可表示为
(6)
用(yt,rmt)拟合第m颗CART回归树,针对叶子节点区域Rmj(j=1,2,…,J,J为叶子节点个数)计算最佳拟合值:
(7)
即m次迭代后的预测模型Fm为
(8)
式中:I为指示函数,
(9)
得到强学习器:
(10)
3 预测效果验证与分析
3.1 模型预测结果
本文采集2020年10月某小区域的流量样本进行预测效果对比分析。由于本文目的是借助流量预测结果指导资源投放,因此采用每日忙时流量(一小时内最大流量)进行预测效果验证。
首先选取同时段大区域流量进行ARIMA一步预测(即根据10月1~16日数据拟合模型参数)进行对比分析,第2节中已根据自相关与偏自相关函数确定模型阶数为ARIMA(1,1,1),本文使用Python建立ARIMA模型,预测结果如图6所示。
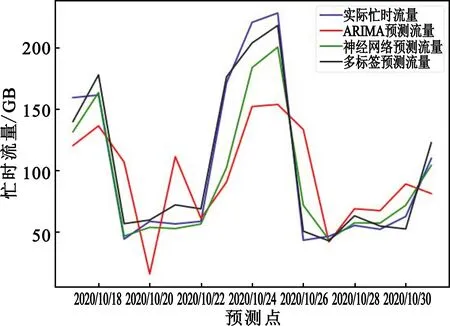
图6 流量预测结果对比
同时,BP神经网络(Back Propagation Neural Network,BPNN)的预测值也在图6中示出,取500个数据用于训练预测模型,鉴于流量序列具有一定的周关联性,输入层节点数为7(即以上一周的流量数据为输入数据),单隐藏层由三个隐藏节点组成,且输入时滞为5、输出层节点数为1(预测一天的数据,即一步预测)。
多标签预测则是首先建立ARIMA(1,1,1)模型,其参数与对比算法相同,后用Python 的机器学习扩展包sklearn 实现,将300组历史数据集用于GBDT训练,输入为第1节中分析的各特征项及ARIMA预测结果。其中参数设置通过网格搜索法选取最佳参数,损失函数采用均方误差。最终模型训练结果为:学习率0.1,决策树最大深度4,决策树个数160。
从图6可以看出,由于汇聚区域较小,实际流量具有很大的突发性,ARIMA模型由于仅依靠历史数据进行训练很难适应外部因素引起的突发趋势;神经网络模型虽然同样依靠历史数据,但部分影响流量的外界因素已隐含在训练序列中,如“工作日”“活动场所”等,其预测准确度相对于ARIMA有所提升;多标签预测则由于尽可能多地将外部影响因素考虑进来,预测结果更加准确,尤其在突发趋势拟合上更具优势。
3.2 预测误差对比
本文以相对均方根误差(Relative Root Mean Square Error,RRMSE)和平均相对误差(Mean Absolute Percentage Error,MAPE)为衡量标准,分别如式(11)和(12)所示:
(11)
(12)
小区域多标签预测模型与ARIMA预测、PBNN预测结果的比较(训练模型与3.1节相同,共选取100个区域参与模拟预测,即N=100),各项预测算法误差在表4中列出。
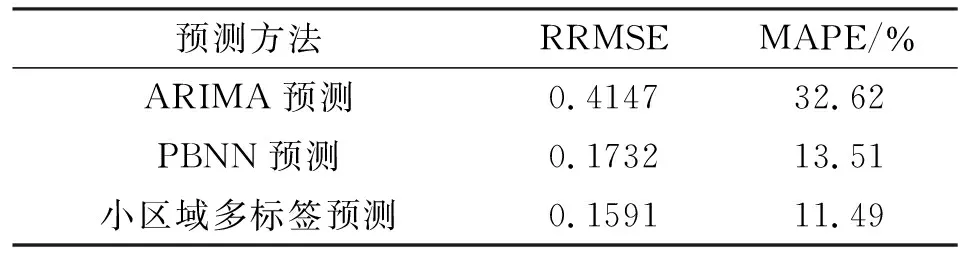
表4 预测结果比较
从表4中的预测结果可以得出,多标签预测在RRMSE、MAPE上表现出明显的优越性;ARIMA预测由于仅依据近期流量本身的信息进行参数拟合,将其用于突发性极强的小区域流量预测会产生较大的误差;神经网络方法虽然在预测领域广为应用,但同样由于未考虑外部影响因素,其预测误差高于多标签预测方法。
4 结 论
本文在充分分析小区域通信网络流量特征之后,利用外部因素对流量的影响程度构建适用于小区域范围内通信网流量的预测算法。仿真结果表明,本文提出的多标签预测算法相对于当前单纯依靠历史数据的流量预测方法能够提供更加准确的预测结果,从而为下一步的网络资源合理分配提供研究基础,实现网络运维工作由被动防御走向主动优化。
