概念整合视角下多模态隐喻的意义构建
2022-06-27侯小珍
侯小珍
(甘肃民族师范学院 外语系, 甘肃 合作 747000)
多模态隐喻不仅是反映现代社会人类的一种群体认知语言表达方式,而且还广泛体现在一种群体语言中,如各种人体图像、音乐、声音和各种视觉体姿等以及人类的各种精神交流模态中。越来越多的国外学者已经开始将其科学研究重点逐渐转向现代电视广告、卡通、动漫、电影等多种传播媒介及各种多模态群体形象隐喻。本文以纪录片《共筑未来》为语料,基于Fauconnier和Turner概念整合理论,分析并探讨其中有关多模态隐喻的意义认知构建。
1 理论基础
1.1 概念整合理论
Fauconnier和Turner基于空间心理学和空间整合理论提出了在概念上的整合空间理论,其认为隐喻是源域和目标域跨域映射的结果,可以应用于常规隐喻的解释,但是对非常规新颖的隐喻解释力相对较弱[1]。Fauconnier在其数学专著《思维和语言中的映现》中对整合论的理论基础进行了详细而系统的理论描述,并提出一种意义建构的在线模型,概念论的整合哲学理论以其哲学动态性特点弥补了传统概念论和隐喻整合理论的不足。整合理论的哲学核心是以四种不同心理逻辑空间构成其理论核心,以四种心理空间为基础,构建认知机制的基本原理,解释了人从获得信息到信息筛选再到新信息构成的过程。四种心理空间分别为输入空间Ⅰ、输入空间Ⅱ、类属空间和合成空间。通常来说,输入空间Ⅰ与输入空间Ⅱ代表原域和目标域,类属空间中包含输入空间Ⅰ与输入空间Ⅱ共同享有成分,输入空间中的信息在此进行筛选,筛选所获信息在合成空间进行信息整合重组,即人的认知过程。董桂荣认为两个整合输入类属空间的抽象元素根据一个类属输入空间所需要限定的空间范围将合适的抽象元素分别投射出来到新的一个整合输入空间中,从而动态地开发层创结构[2]。创建的结构本身并非只是两个类的输入输出空间直接相互映射的一个集合,是在整合空间里经过了组合、完善以及拓展所产生的最终合成成果。
1.2 多模态隐喻
早期语言隐喻局限于哲学概念上,是隐喻在中国语言哲学层面的一种体现,而近年来多模态隐喻作品获得了越来越多的读者关注。多模态隐喻(Multimodal Metaphor)包括模态和隐喻。模态一般认为是与人的感官所联系的,包括视觉、听觉、嗅觉等多种感官。隐喻简单地说就是用一组词形象地表示一个物体的本质,从而表明所用词与物体之间具有相似之处,通常被理解为从一个具体的概念域向一个抽象的概念域的系统映射。其中隐喻涉及两个概念域——源域和目标域。源域是我们常说的喻体,而目标域是本体[3]。Forceville认为模态是“利用具体的感知过程和阐释的符号系统”,如图像符号、书面符号、手势、声音、触觉等,这些符号模态可共同参与意义构建[4]。在实际的操作过程中,多模态隐喻也存在着狭义和广义之分,其中由二个或多个模态所共同构成的隐喻可以被看作是广义的多模态隐喻,具备了动态叙事性、鲜活性和普遍性等特征[5]。近年来,国内外多模态隐喻研究涉及的语言类型正表现出新的发展趋势。
2 研究的设计
2.1 研究的问题
① 从多模态隐喻视角出发,在《共筑未来》中存在哪些隐喻?② 从概念整合视角出发,这些文字、图像、音乐等不同模态如何共同构建隐喻意义?不同模态间如何互为补充?③ 通过多模态隐喻的意义构建,对“一带一路”的传播发展有何启示?
2.2 研究对象选择
本研究的语料均来自网络资源,纪录片《共筑未来》来自CCTV节目官网(https://tv.cctv.com/)。原料选择原则:首先,《共筑未来》是中央广播电视总台摄制的三集“一带一路”主题纪录片,内容面向海内外,展现自2016年“一带一路”倡议的提出到2019年期间 “一带一路”周边国家三年来的发展巨变;其次,内容具有较强的时效性,反应当下和平发展的时代潮流;最后,纪录片本身制作精良,从图像、语言、文字等展现“一带一路”经济发展下的蓬勃活力,具有代表性。
2.3 研究方法
选取《共筑未来》PC端播出的版本共同导入片段为语料,通过截图软件对该片进行截图,并作为案例进行分析,解读其中蕴含的多模态隐喻,为其中的多模态隐喻进行概念整合模型构建,并分析该片建构多模态隐喻时的模态配置以及该片如何通过多模态隐喻展现以“和平共处”“共建共享”“包容互鉴”为核心原则的人类命运共同体的核心理念。
3 研究结果及讨论
3.1 《共筑未来》中多模态隐喻构建类型
本研究基于《共筑未来》共归纳出四种多模态隐喻构建类型,分别是文字-图像隐喻、方位-图像隐喻、情境隐喻以及音乐-图像隐喻。全片以方位与图像隐喻为主,其中音乐-图像隐喻以视频整体作为研究对象,其次是情境隐喻与事件隐喻。本研究从多模态隐喻类型解读分析出发,在此基础上构建概念整合模型对其中的源域和目标域进行模型整合,得出“合成空间”即人的认知。
1) 文字-图像隐喻。
该类型的隐喻诗具有两种主要表征表达形式,即文字图形-抽象图像、文字图像-抽象文字。因此,如果离开其中的某一种要素,隐喻的其中一域即消失,该隐喻也就失去了意义,即所有源域与一个目标域同时可以直接参与一个隐喻的实例构建,而不是仅仅直接参与一个源域或者对目标域的隐喻表征[6]。这种隐喻的本质特征在于一旦取掉其中某一部分时,则表示该词的隐喻也将不复存在。

图1 共筑未来
视频以图1“共筑未来”缓缓上升最后停在了地球上方开头,图像部分宇宙背景的整幅画面由四周到中间逐渐由暗转亮,而“共筑未来”四个字则是整幅画面中最亮的部分。由此映射出“一带一路”经济带正在蓬勃发展,在全球的共同努力下由中国领头,我们即使身处未知的黑暗,同样可以在黑暗中前进,迎接未来的光明。其中的源域是中国提出的“一带一路”倡议,由“共筑未来”文字表征,地球与宇宙的图像则是目标域,由图像模态来表征。多模态隐喻的构建需要文字和图像的共同参与,并由此构建出人的基本认知。而在概念整合理论下,输入空间Ⅰ与输入空间Ⅱ代表源域和目标域,并在类属空间中进行筛选整合,从而得到合成空间中的新信息,由此构建文字-图像隐喻的概念整合模型如图2所示。
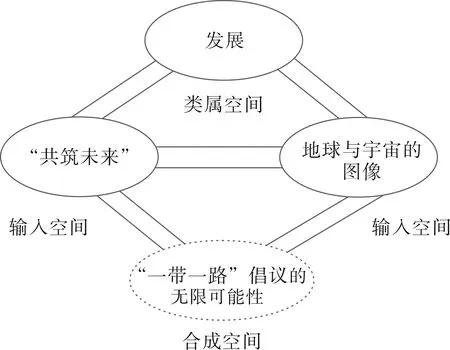
图2 “共筑未来”的整合模型
2) 方位-图像隐喻。
方位-图像隐喻通常表现在视频画面的转换过程中,其中方位变化转换代表了某种趋势的延伸与发展,图像则是方位变化的结果或结论。同文字-图像隐喻类似,作为源域的方位与目标域的图像均是构成该种隐喻不可或缺的一部分。

图3 纳扎尔巴耶夫大学
如图3可见,画面出现在视频开始,以3D动画的呈现方式展现了画面的转换。从路线图中的锦绸丝带路线出发,到达了哈萨克斯坦的纳扎尔巴耶夫大学——“一带一路”倡议中所提出的一个起点,随着丝带的方位变化,画面遍布全世界,图中春天花朵繁盛、阳光明媚的画面隐喻“一带一路”倡议将伴着鲜花与阳光在光明大道上去往全世界。
而在图4中,出现的是丝带在经过“一带一路”经济带沿途国家后又回到了北京雁栖湖的画面,展现的是世界各国人民围绕在“一带一路”logo图案形花坛周围欢呼,而丝带在全世界人们的欢呼声下升向天空。花坛周围欢呼的世界各国人民象征全世界人民,丝带与“一带一路”的logo形花坛隐喻“一带一路”倡议惠及全球各个国家,给全世界人民带来美好与幸福。此部分作为同一隐喻类型进行分析,其共同源域为“一带一路”倡议的发展,由图中的丝带方位变化进行表征,目标域分别为纳扎尔巴耶夫大学和北京雁栖湖欢呼的各国人民,由图像模态表征,由此进行概念整合模型构建如图5所示。

图4 北京雁栖湖
3) 情境隐喻。
所谓情境隐喻,是情境在该类隐喻中搭建起由源域到目标域的映射,一旦脱离情境,隐喻也就不复存在[7]。
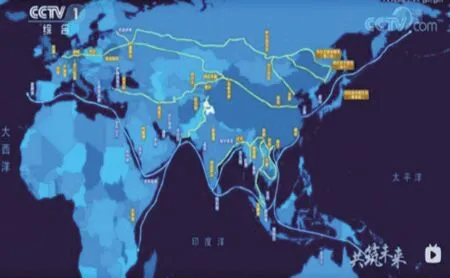
图6 “丝绸之路”路线
如图6可见,该隐喻建立在“海上丝绸之路”“陆上丝绸之路”航线与世界地图上,当目标域世界地图脱离了源域丝绸之路时,该隐喻也将随之消失。该隐喻基于丝绸之路开辟的情境下,用世界地图之广、丝绸之路路线之多暗示了“一带一路”经济带建设的巨大潜力与光明前景,同时也映射出“一带一路”经济带影响范围之广,其对沿线国家的发展助力将是前所未有的。丝绸之路路线以箭头的指向展现了“一带一路”经济带沿途路线,而中国作为这些路线的起点同样展现出了新时代经济发展的蓬勃活力,隐喻出中国正以自身实力影响着世界,推动着世界经济的发展。建立概念整合模型如图7所示。
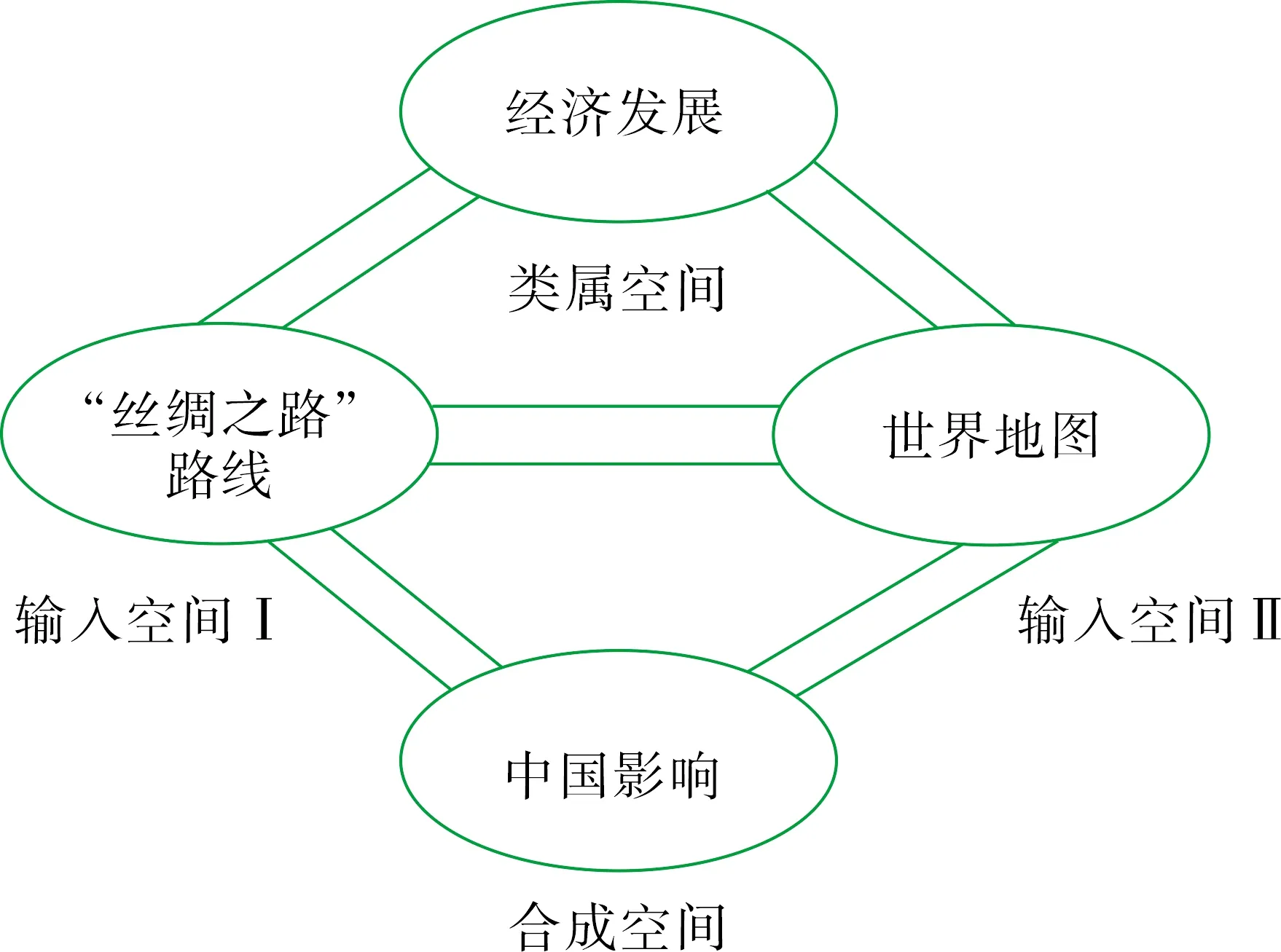
图7 “丝绸之路”展现中国影响的整合模型
4) 音乐-图像隐喻。
区别于文字-图像隐喻,音乐-图像隐喻侧重于在图像之间用音乐来表达视频中的情感,唤起观众的共鸣,其中隐喻表达更偏向于音乐的婉转、轻柔,而文字-图像隐喻则偏向于字里行间的深意,不易外露却同样深刻。作为源域的音乐让目标域图像隐喻表达更加富有感情,也正是如此,使其不同于以上几种多模态隐喻类型,源域与目标域的关系并非缺一不可。音乐-图像隐喻在源域与目标域方面,两者更加相辅相成,但当单独划分出来分析时也并非不可,只是缺失了二者之间的共鸣,从而大大降低了隐喻效果。
此处以视频中的背景音乐为例分析音乐与图像之间相辅相成的隐喻效果。从视频中的整体音乐基调来看,全片处于一种积极向上、充满活力与动力的主旋律当中,辅以视频中阳光、笑颜、繁荣的街道等意象,无时无刻不在给观众一种生活美好的感觉,隐喻在“一带一路”经济带的影响下人们的生活更加美好,经济发展带来的实惠正影响着每一个人,而音乐也在时刻渲染着这份美好。同样具有感染力的是在讲述国外不同国家、地区、民族的发展时,背景音乐会逐渐由主旋律转为带有民族特色、区域特色的本土音乐与所讲述的故事、展现的图像相呼应。隐喻中国的“一带一路”倡议、中国的经济发展尊重当地文化传统,遵循“包容互鉴”的核心理念、与世界各国人民相处恪守“和平共处”的核心准则。
根据以上示例,在刨去音乐之后其仍可作为图像隐喻进行单独分析,却少了在音乐渲染下的那份深刻内涵。建立音乐-图像隐喻概念整合模型如图8所示。
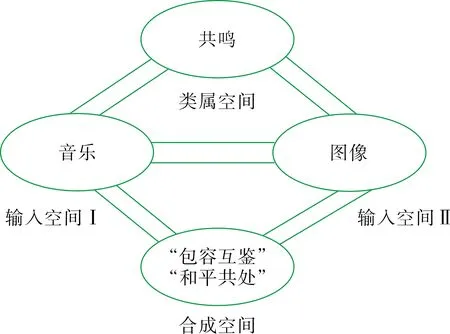
图8 音乐-图像隐喻概念整合模型
3.2 概念整合视角下多模态隐喻的意义构建
概念整合理论可以对上述隐喻概念意义的整体构建和转化生成过程给出强有力的推理解释。隐喻整合的整体解决过程离不开概念整合信息网络、层创信息结构、压缩、推理对象投射和生成整体分析目标等多个概念意义整合理论过程。隐喻是传统概念意义整合的重要的具体表现形式,是中外双域概念整合理论运作的重要结果之一[8]。同时,由于传统概念隐喻理论不具备足以系统解释旧概念信息结构产生的新概念意义,许多国外学者已经开始积极尝试综合利用概念整合理论的隐喻心理科学空间结构映射和概念整合网络来系统解释上述隐喻意义的构建生成转化过程,系统地解释了概念隐喻的整体运行机制,有助于对概念隐喻的深入分析理解。该整合理论对隐喻概念意义进行系统分析、过滤,对上述隐喻新概念意义的构建生成过程做出强有力的推理解读,弥补了传统概念隐喻理论的部分缺陷,取得了长足发展。
随着新媒体行业的蓬勃发展,新媒体行业基于视频的传播信息广、易于被人接受等诸多优点已经逐步取代了报纸、广播、书籍等传统媒介,多模态隐喻也已逐步替代单一模态隐喻在视频媒体中得到了更加广泛的开发与运用,视频广告中多模态隐喻的研究也将引起更多学者的关注。综上所述,通过对《共筑未来》中的多模态隐喻实例构建的类型对象进行系统总结分析,基于隐喻概念分析整合建构理论并着重对其中具有代表性的多模态隐喻构建类型结构进行系统分析,构建相应的概念整合隐喻分析建构模型,通过其中的隐喻动态分析建构转化过程, 以期推动多模态隐喻的进一步发展与完善,从概念整合视角发掘多模态隐喻建构的新含义。
4 结语
本研究基于Forceville的理论框架对《共筑未来》进行总结归纳,得到四种隐喻类型。在此基础上通过建立概念整合模型,着重分析了多模态隐喻在视频广告中隐喻意义的映射、整合、生成过程。从动态整合的角度来看,与纯文字隐喻相比,多模态隐喻的构建过程往往更加复杂,因此对多模态隐喻在视频广告中的解读、阐释、评价往往与社会背景、具体情境、文化认知等密不可分。同时发现概念整合理论对广告视频背后广告作品中的多模态意义隐喻的各种动态抽象意义内涵构建过程具有较强烈的阐释力,能够有效帮助观众深入解读广告视频背后观众所要表达的各种抽象意义。本研究不仅可以用于促进多模态意义隐喻在言语理论上的进一步研究与完善,对其他非言语类多模态隐喻的理论研究也有一定的理论启示和借鉴作用。
