基于生成对抗网络的照片动漫风格化
2022-06-27周燕玲段金玲谭高斌
周燕玲,段金玲,谭高斌
(江西中医药大学计算机学院,330004,南昌)
0 引言
图像的风格渲染是计算机视觉领域的重要研究方向,在电影产业、动画制作、游戏渲染等诸多领域具有广泛应用[1]。在人工智能时代,深度学习也成为了机器学习领域中重要的研究方向,基于图像处理的深度学习法具有重要作用,能够实现各种高效的图像处理,如图像增强、图像复原、对比度增强、图像分割、无损放大、图像视频自动上色、动漫风格转换以及如今火热的AI换脸技术等[2]。
动漫是现在非常流行的一种艺术表现形式,这种艺术形式广泛地应用于社会的诸多方面,包括广告、游戏、影视作品和摄影等多个方面。希望可以通过电脑将现实世界的图片自动转换为具有动漫风格的图片。同时可以人为地调控其对人像或背景进行风格迁移以满足不同人对图片风格化的要求。
根据近几年来图像风格迁移现状来看,主要是以深度学习进行研究,尽管现阶段能够实现的图像风格转换技术已十分强大,但在图像风格迁移过程中存在许多问题,如风格转化后的图像边缘轮廓不清晰[3]、内容细节处理不当、纹理合成有所失真[4]、笔触形状不清晰以及图像质量欠佳。为解决以上问题,实现更高效的图像风格迁移,改进和优化迁移算法具有重要意义和研究价值。
目前,基于深度学习的图像风格迁移已经取得了相对较好的效果,使得深度学习成为了图像风格转换的常用方法。GAN[5](对抗生成网络)是现阶段最新的方法之一。
本文主要基于Tensorflow[6]对模型进行训练,Tensorflow是一种基于数据流编程的符号数学系统,被广泛用于各类机器学习算法的编程实现。在训练数据后设计并实现了GAN-anime系统,对上传的照片进行动漫风格化,同时实现了在PyTorch上的扩展。
1 相关算法简介
生成对抗网络GAN(Generative Adversarial Network)最初由Ian J.Goodfellow教授及其团队于2014年提出[7],GAN作为一种非监督学习方式。生成对抗网络GAN也是一种概率生成模型,它通过对抗训练的方式促使生成的样本分布服从真实数据分布情况。
深度卷积生成对抗网络DCGAN[8](Deep Convolution Generative Adversarial Networks),由卷积神经网络与生成对抗网络结合而成,是一个无标签的非监督生成模型。通过各类的图像数据训练表明,DCGAN的生成器和鉴别器能够学习从物体部分到场景的表示层次。并且能把学到的特征用于新的任务中,以证明它们可以作为一般图像表征的适用性。
循环生成对抗网络CycleGAN[9](Generative Adversarial Networks)本质上是2个镜像对称的GAN,构成了一个环形网络,它是一种无监督的生成对抗网络,打破了图像风格迁移需要成对数据的难题[10]。
2018年清华大学Chen等人提出Cartton-GAN,用于将图像风格进行动漫化[11]。CartoonGAN实际就是一个用于非成对image训练的GAN,可以说是单向的CycleGAN,它可以用真实景物的照片作为源图片,生成任意风格的漫画。
AnimeGAN[12]是来自武汉大学和湖北工业大学的一项研究,采用的是神经风格迁移与生成对抗网络(GAN)的组合,其视觉效果已超越了CartoonGAN。其在CartoonGAN的基础上,改进了网络结构,由2个卷积神经网络构成:一个是generator G,将照片转化为动画图片;一个是discriminator D,判断输入的图片是real或者fake,更加轻量,具有较少的网络参数,并引入了Gram矩阵来生成更生动的风格图像。为了生成更好的视觉效果的图像,提出了3个损失函数:灰度样式损失、颜色重建损失和灰度对抗损失。在生成网络中,灰度风格损失和颜色重建损失使生成的图像具有更明显的动漫风格,并保留了照片的颜色。识别网络中的灰度对抗损失使生成的图像具有鲜明的色彩。在鉴别器网络中,本文也使用了 CartoonGAN 提出的促进边缘的对抗损失(edge-promoting adversarial loss)来保留清晰的边缘。
另外,为了使生成的图像具有原始照片的内容,引入了预先训练好的 VGG19[13]作为感知网络,获得生成的图像和原始照片的深度感知特征的L1丢失。其与 CartoonGAN 使用的方法类似,通过预训练模型可以更好地提取图片的高维信息,这样可以在风格不同的情况之下比较2个照片的差别,2个图像的风格即使不一样,但是高维的语义信息是一样的,不需要像Cycle GAN一样需要同时训练2个模型来保证模型的正常收敛。
AnimeGAN具有的创新点:使用灰阶损失来优化生成图像纹理和线条;使用颜色重构损失来保留原始图像中的色彩信息;使用了色彩损失,避免了使用灰阶损失导致生成灰色图像。
2 实现人脸与风景动漫化
2.1 前期准备
本文使用来自武汉大学与湖北工业大学研究的AnimeGAN,采用的是神经风格迁移和生成对抗网络(GAN)的组合。相比于CartoonGAN,AnimeGAN的模型更小,计算量更小,记忆推理速度更快。提出了3个全新的损失函数用于提升风格化的动漫视觉效果,这3个损失函数分别是灰度风格损失、灰度对抗损失和颜色重建损失。
模型使用的数据集为kaggle网站上搜集的Anime Faces数据集以及Anime Scenery数据集,分为动漫风格图和真实图片,共1 650张动漫图片,包括人物图和风景图,6 656张真实图片。
训练模型之前对风格图片进行了预处理,对动漫图片进行边缘平滑处理,使用OpenCV的Canny算法,对图片进行边缘检测,使用高斯滤波对图片降噪,使图像变得平滑,排除非边缘像素,保留一些较细的线条,在保留原有图像属性的情况下,显著减少图像的数据规模,然后对边缘检测后的图片进行膨胀操作。
2.2 模型训练与测试
采用AnimeGAN模型进行动漫风格化模型训练,其中生成器的总损失函数如式(1)所示。
L(G,D)=ωadvLadv(G,D)+ωconLcon(G,D)+ωgraLgra(G,D)+ωcolLcol(G,D)
(1)
式中:Ladv(G,D)是对抗性loss,影响图像风格迁移部分;Lcon(G,D)是图像内容信息的loss,使生成的图像保留原始图像的内容;Lgra(G,D)是图像灰度风格loss,使生成的图像在线条和纹理上具有清晰的动漫风格;Lcol(G,D)是颜色重构loss使得生成的图像保留原始图像的色彩。
最终的生成器损失函数L(G)如式(2)所示:
L(G)=ωadcEpi~Sdata(p)[(G(pi)-1)2]+ωconLcon(G,D)+ωgraLgra(G,D)+ωcolLcol(G,D)
(2)
鉴别器的损失函数L(D)如式(3)所示:
L(G)=ωadv{Eai~Sdata(a)[(D(ai)-1)2]+Epi-Sdata(p)[(D(G(pi)))2]+Exi-Sdata(x)[(D(xi))2]+0.1Eyi-Sdata(y)[(D)yi))2]}
(3)
权重系数ωadv=333,ωcon=1.5,ωgra=3,ωcol=10。对于Lcon(G,D)和Lgra(G,D)使用了VGG-19作为感知网络来提取高层次的语义特征。判别器的总损失由灰度对抗损失和边界促进的对抗损失组成。
生成器网络(Generator Network)的学习率为0.000 08,判别器网络(Discriminator Network)的学习率为0.000 16,使用Adam优化器,传入总的损失loss值。
在搜集了大量各类场景数据集之后,对其进行大量的训练测试,在有关风景动漫化模型的训练过程,共迭代训练100个epoch,每个epoch需要迭代1 109次,每次迭代需要花费近30 s,batch_size为4。需要在GeForce GTX 1080 Ti上跑共花费2个星期左右,最终经过训练后生成的效果图如图1所示。
2.3 系统实现
照片动漫风格化系统页面展示采用PyQt5技术,借助PyCharm平台,设计系统页面布局效果,编写功能和事件代码,进入主功能界面,如图2所示。单击“选择图片”,上传图片文件后有2种实现风格化效果模型,可以进行人脸风格化或场景

图1 动漫化训练结果对比图
风格化,根据不同的选择,进行对应目标图像动漫风格转换效果,效果图像展示在右侧,可以选择“保存图片”将生成后的动漫化效果目标图片保存在本地。如图3所示是人脸动漫化的效果,图4所示是风景动漫化的效果。
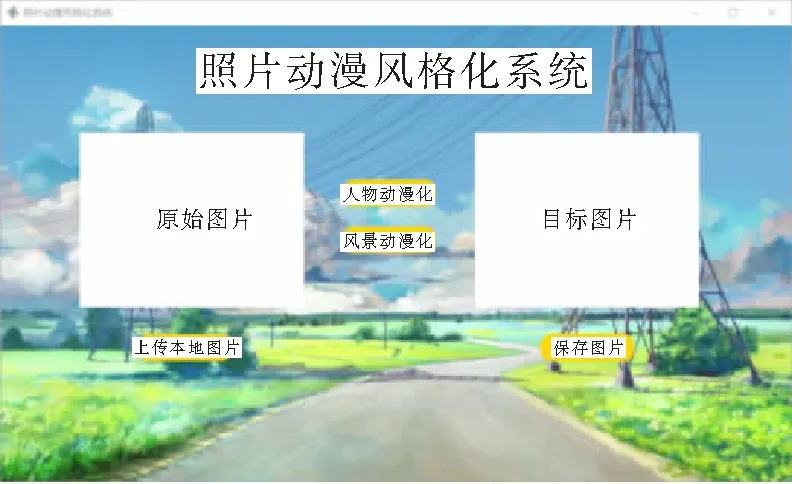
图2 照片动漫风格化系统主界面
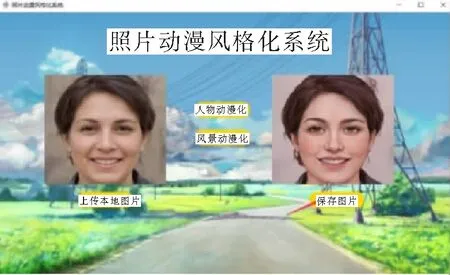
图3 人脸动漫化效果
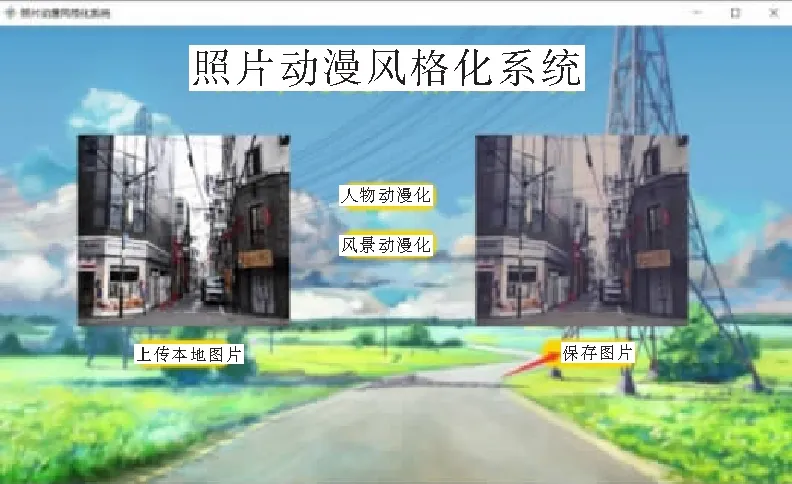
图4 风景动漫化效果
3 总结
经过反复大量多次迭代训练后,生成的人物效果图其面部特征没有很大失真,且能够很好地实现动漫风格转换效果。从眼睛、细纹等细节观察可知,基于AnimeGAN动漫风格人脸风格化实现效果相较于风景风格化实现效果好很多,说明此模型训练较佳。训练完成后根据生成的log文件,利用tensorboard画出的损失函数曲线见图5所示。

图5 损失函数曲线图
Generator_loss是生成器总损失曲线图,是G_gan和G_vgg之和,Discriminator_loss是判别器总损失曲线图,G_vgg是内容损失,灰度风格损失、颜色重建损失之和,G_gan是Least Squares Loss。由图5也可看出,生成器总损失在Epoch 80的时侯曲线开始在固定范围内波动,趋于收敛,且G_gan收敛效果良好,说明图像风格迁移训练有所成效。判别器总损失在Epoch 80的时侯曲线开始在固定范围内波动,趋于收敛,且收敛效果稳定,这说明判别器的训练是成功的,从图5也可以看出来效果是令人满意的。最后本文选取Epoch 80保存的检查点文件对模型的权值系数进行了保存。
照片动漫风格化系统可以实现人脸动漫化和风景动漫化效果,风格化效果的实现是通过调用已经训练好的模型,便能够直接通过点击“人脸动漫化”或“风景动漫化”直接进行风格转换。
调用模型函数的建立是在预测文件的基础上改编的,首先采用if函数判断是否打开图片文件路径为初始赋值'./results/1.jpg',若为初始值则不执行该函数,若不为初始值则读取文件路径。根据文件路径信息用Image.open方法打开图片,再调用deeplab.detect_image函数将打开的图片应用模型处理。处理后获得的图片文件较大不能直接显示在QLabel显示图片窗口,需要通过image.save方法将图片保存在文件夹中,保存过程中图片被自动压缩,再通过setPixmap方法可将图片显示在QLabel窗口中。
4 结束语
针对人脸的动漫化,还存在许多的限制,如照片的分辨率太低导致动漫化的效果不理想,许多边缘化信息模糊不清,在训练的过程中调参不当
会产生模式坍塌。对于基于AnimeGAN的图片动漫风格化模型,由于训练的照片是人物和风景的图片混合在一起,且风景图占多数,在生成效果中可以清晰地感受到模型在对于人脸的生成方面不够细致,专门分开训练人脸的处理,又显得十分冗余。其次是模型的训练还未在pytorch上实现,只能对tensorflow上生成的模型进行转化,期望日后能有所改进。以后将会完善本项目的不足,力求实现清晰度更好,达到更好的动漫风格效果。
