基于Xception模型的遥感影像场景变化检测
2022-06-27李长城何海清章李乐
李长城,何海清*,章李乐,涂 明
(1. 东华理工大学测绘工程学院,330000,南昌;2. 南昌市水利规划服务中心,330000,南昌)
0 引言
场景变化检测是在场景语义的层次上,在同一地区从不同时间的遥感影像中对一定范围区域的土地利用属性变化情况进行检测和分析,识别地表场景类型的转变和空间分布的变化[1],广泛应用于城市发展化检测[2]、灾害评估和环境检测[3]等领域。土地利用场景类型的精确分类是变化检测的基础,影像场景分类是根据影像内容使用不同分类方法对抽象特征分类,从不同场景影像中提取有用信息。随着对地观测技术和遥感技术的发展,亚米级、甚至厘米级高分辨率遥感影像被广泛应用在各行各业,高分辨率影像不仅包含丰富的纹理、空间信息等细节特征,还具有高级的场景语义信息。因此,对高分辨率遥感影像场景分类已经从低层特征的像素级分类到深层抽象特征的高级语义分类[4],场景分类目标具有地物信息的复杂性和特征的多样性。由于同一场景存在内容差异较大、不同场景内容相似的情况,影像场景分类已成为一项非常有挑战性的任务,如何有效地对影像场景分类已成为该领域的一个研究热点[5]。
近年来,以Hinton[6]等提出的深度学习为代表的人工智能算法发展迅速,特别是卷积神经网络(Convolutional Neural Network, CNN),在计算机视觉领域取得了很大的成功,如在影像分类与识别、目标检测等领域。CNN分类模型通过卷积层提取影像的深层语义特征,并通过反向传播算法自动学习和调整参数,最后连接分类器对目标分类。研究结果表明,越深的网络对影像的分类能力越强,但同时学习参数的数量也在快速增加,使得模型学习变得困难,计算复杂度提高,易出现梯度弥散问题,难以优化模型。一些学者提出不同结构的模型来解决因增加模型深度而出现的上述问题,如Szegedy[7]等首次在GoogLeNet中引入了Inception模块,后续又在Inception模块上做了多种改进[8-9]。He[10]等提出残差结构,通过应用剩余学习的思想,在特征提取网络中添加跳转链接。Huang[11]等提出密集链接网络的概念,进一步提高模型分类精度。
基于深度学习的分类算法在场景识别中取得较好的效果,但一般都是使用固定大小的多个滑动窗口进行识别。因此,在场景定位中存在场景类别间差异小,即类间可分离性低,出现场景误分类等问题。针对上述问题,结合简单线性迭代聚类(Simple Linear Iterative Clustering, SLIC)算法,实现不同场景边界化精细化检测,进一步提高场景变化检测的准确性。该方法利用迁移学习方法构建深度卷积神经网络Xception模型,从多时相高分辨率遥感影像中提取语义特征并基于softmax分类器识别场景斑块。在上述分类结果的基础上提取地物场景类别在不同时相的变化信息。
1 方法
本文方法流程图如图1所示。在分割阶段,使用SLIC算法将两幅不同时相的遥感影像分别分割,得到地面场景对象的初始分割轮廓,按照边界轮廓提取超像素,得到超像素场景斑块。场景分类阶段,利用改进的Xception模型构建影像场景分类网络,添加softmax分类器对超像素斑块进行分类预测,得到分类结果。变化检测阶段,基于不同时相分类后结果提取地物场景变化信息。
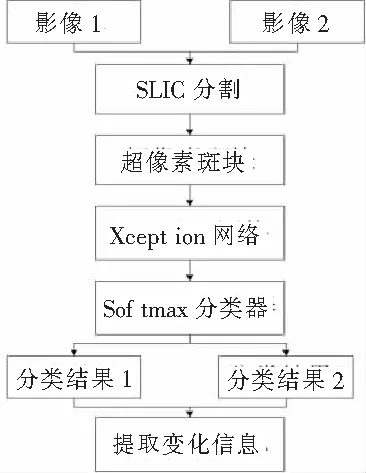
图1 实验流程图
1.1 SLIC分割
SLIC是一种超像素分割算法,由Achanta提出[12]。超像素是由一系列位置相邻且颜色、亮度、纹理等特征相似的像素点组成的小区域,这些小区域大多保留了进一步进行影像分割的有效信息,且一般不会破坏影像中物体的边界信息[13]。其是一种思想简单、易于实现的分割算法,将RGB影像转化为CLELAB颜色空间和XY坐标下的5维特征向量,即[l,a,b,x,y],其中[l,a,b]是由CLELAB颜色空间定义的像素的特征向量表示,[x,y]表示像素坐标。SLIC算法优势有:生成的超像素紧凑整齐、特征易表达、需要设置参数较少、运行速度快、更好地获取边界。
1.2 基于迁移学习的Xception网络模型
Xception模型是由Francos[14]等在2017年提出的,是基于Inception V3模型结构并结合残差网络发展起来的,同时兼顾两者的优点。Xception主体结构如图2所示,包含36层可分离卷积层,其中A-G为卷积块,每个卷积块包含若干个卷积层、池化层、激活层、BN层等。其中Conv为卷积网络,s为卷积滑动窗口步长,SepConv为可分离卷积结构,Relu为激活函数,MaxPool与GlobalAveragePool分别为最大池化层与全局平均池化层。Xception模型引入了深度可分离卷积操作代替常规卷积操作,在基本上不增加网络复杂度的前提下提高了模型精度。深度可分离卷积与常规卷积运算类似,都能用来提取特征,但其参数数量和运算成本较低。假设一张三通道彩色影像,卷积核大小为3×3,输出通道为32,则常规卷积运算的参数为896个,深度可分离卷积运算参数为155个,由此可见,深度可分离卷积大大减少了参数数量,提高了计算效率。
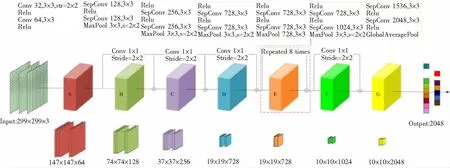
图2 Xception模型结构
迁移学习即通过将一个大型数据集上学到的知识转移到小数据集中,通过模型与参数迁移的方式解决少量标记样本的训练问题,提高模型学习效率。迁移对象之间必须有相似的特征,一个对象才能学习另一个对象的知识。在计算机视觉领域,ImageNet数据集是最大、应用最为广泛的影像数据集之一,其包含了大约1 500万张被人工标记的、2.2万个类别的影像,被广泛用于影像分类,目标检测等。本文中,将Xception模型在ImageNet数据集上学习的模型参数迁移到自定义的小型数据集上再应用到分类任务中,通过迁移学习能快速训练出较为准确的模型,比不使用迁移学习训练的模型精度有很大提高。
2 实验结果与分析
为验证本文方法的可行性,本文使用公开的Multi-temp Scene Wuhan(MtS-WH)数据集[15]训练模型,主要包括2张由IKONOS传感器获得的、大小为7 200×6 000的大尺寸高分辨率遥感影像,覆盖范围为中国武汉市汉阳区(图3)。影像分别获取于2002年2月和2009年6月,训练集和测试集的场景图片共划分为8个类别:停车场、水体、稀疏房屋、稠密房屋、居民区、空置地、农田、工业区。重新通过选择典型区域来产生训练集样本,训练集每个时相均包含400张影像,每类50张,大小为150×150,但不同时相的训练样本并不对应相同位置,训练集影像部分如图4所示。测试集是对大尺寸影像通过大小为150×150互不重叠的网格划分产生测试集样本,每个时相可以获得1 920(48×40)张场景图片,目视解译为以上几个类别。为提高模型的稳健性、增强场景分类识别的准确率,采用常见的数据增强方式来扩充数据集,本文用到的数据增强方式有:影像随机旋转、左右翻转、上下翻转、随机裁剪、添加椒盐噪声、直方图均衡化。如图5所示。

(a)2002年2月 (b)2009年6月

图4 部分影像示例图

(a)原始影像;(b)随机旋转;(c)左右翻转;(d)水平翻转;(e)随机剪切;(f)增加椒盐噪声;(g)直方图均衡化
2.1 SLIC分割结果
图6显示的是使用SLIC算法对2002年和2009年2幅影像分割结果。分别获得946个、903个超像素块,每个超像素斑块对应一个地物类型,从影像分割图的完整分割区域中截取相应的场景并对其分类,按照分割结果将每一个超像素块提取出来输入到神经网络模型并对其进行预测分类。这些超像素斑块基本上是由同种地物像元组成,避免了混合像元造成不同地物之间可分离性低、分类精度不高的问题。

(a)2002年2月 (b)2009年6月
2.2 基于Xception网络模型训练结果
本文实验以Tensorflow为后端的keras作为深度学习框架,模型的基本参数包括:训练集、测试集、验证集的比例为8:1:1,学习率为0.1~0.001之间动态变化,采用Adam优化方法,训练轮次200个epochs。借助迁移学习方法,将Xception模型在ImageNet数据集上学习到的参数向量迁移到新数据集上,使得只需少量的样本数据即可实现高精度的场景分类。目前,在keras框架中,已经存在在ImageNet数据集训练好的Xception模型,较容易就能实现学习参数的迁移,省去了在ImageNet数据集上再次训练的麻烦。本文实验平台环境:联想笔记本电脑,GPU:NVIDIA GeForce GTX 1660 Ti,CPU:intel(R) Core(TM) i7-10750 @2.60GHz,RAM:16.0GB。
由图7可知,训练集精度随着网络不断迭代在逐渐增加,精度从迭代0~50次的时候增长最快,因为使用迁移学习使得网络不必再从头学习参数知识,体现了迁移学习的优越性,能够减少训练时间。在150次迭代后,精度逐渐稳定在0.96。训练集损失一直在下降,逐渐稳定在0.18。
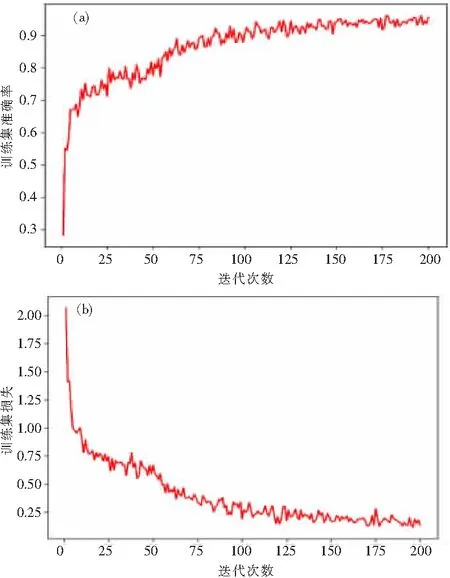
图7 训练精度(a)和损失(b)图
图8显示的是Xception网络在测试集上产生的混淆矩阵。8个类别中有5个类别的分类准确率大于90%,其中,水体和农业用地的分类精度最高,达到98%和99%,因为这2种场景与其它场景类别在颜色、纹理等特征上较容易区分,能达到较高的分类精度。稀疏房屋、稠密房屋和居民区的分类准确率相对较低,为82%、90%和74%,这3种场景相互之间有较大的相似度,可分离性不强,造成分类精度不高。总体而言,证明了Xception模型在分类上的有效性和实用性。

图8 测试集混淆矩阵
2.3 场景分类和变化检测结果
图9显示的是使用本文方法得到的场景分类结果,从中可以看出,大部分的空闲地和少部分的农业用地转变为工业用地和居民区。而表1土地利用类型占比统计中显示,停车场、居民区和工业区的面积增加,其中工业区显著增加,增量达到7.21 km2;水体、稀疏房屋、稠密房屋、空闲地和农业用地占比减少,空闲地减少5.53 km2。这种土地利用类型的变化情况是城市发展过程中的典型扩张模式。
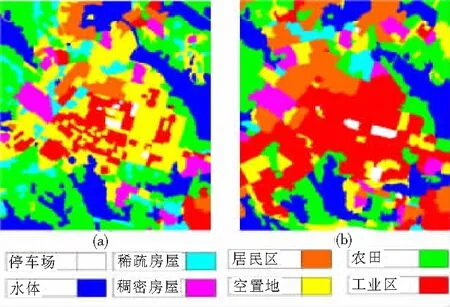
(a)2002年2月 (b)2009年6月
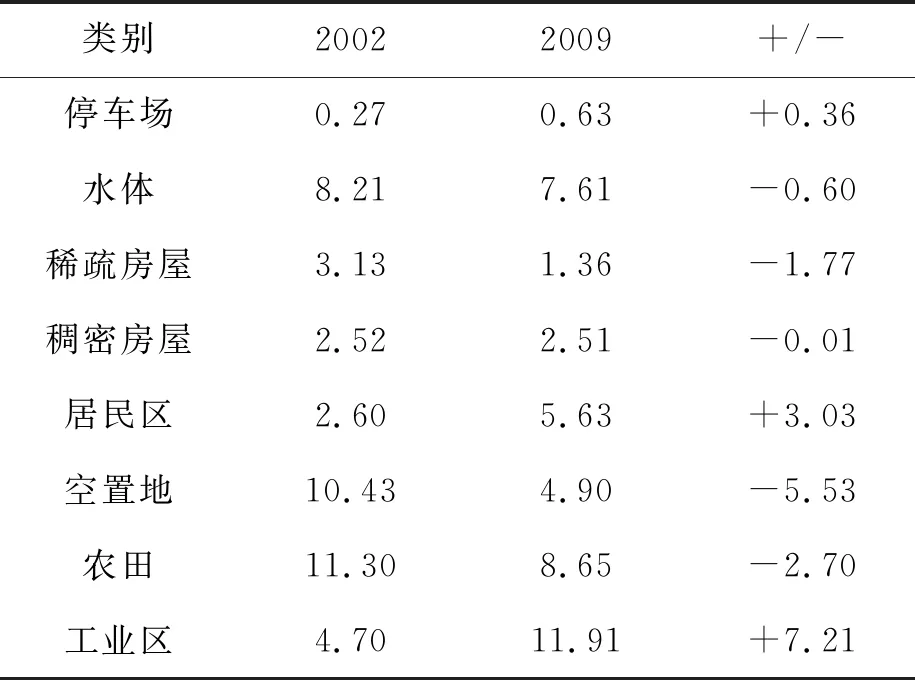
表1 场景类别占比统计/km2
图10显示的是变化检测的参考图和利用本文方法得到的结果图。黄色区域表示已改变的土地利用类型,白色区域表示未更改的土地利用类型,黑色区域表示不确定是否变化的场景。通过对图10(a)和(b)的目视解译,可以得出:图10(b)场景变化检测结果较为准确地表明了土地利用类型变化的区域,比参考图更好地体现了不同地物之间边缘细节特征。本文的方法可用于检测城市的发展并对未来的城市规划提供建议。

··(a)参考结果 (b)本文方法结果
3 结论
多时相场景变化检测在城市发展规划过程中具有重要的意义。本文提出了一种基于改进的Xception模型的遥感场景分类方法用于变化检测。首先对遥感影像使用SLIC分割,得到具有相似颜色、纹理等特征的超像素块;通过迁移学习在Imagenet数据集上学习知识,利用改进的Xception网络模型对超像素块预测分类。基于分类结果提取场景变化信息,统计城区变化区域大小和范围以及不同场景前后变化情况,为城市的发展规划提供参考建议。
