涤纶长丝丝锭质量信息关联规则分析
2022-06-27宫瑞哲王丽丽
宫瑞哲,饶 丰,任 楠,王丽丽,魏 星
(1.北京机械工业自动化研究所,北京 100120;2.北自所(北京)科技发展有限公司,北京 100120)
0 引言
涤纶长丝于二十世纪五十年代在全球范围内快速发展。二十世纪七十年代,全球涤纶长丝的产量已经超过其他种类的纤维产品。此时,中国涤纶工业开始起步。经过八十年代、九十年代的发展,中国已成为全球涤纶长丝产量最大的国家。
目前,涤纶长丝质量信息处理方式简单:系统收集到了大量的产品质量信息,数据没有得到有效应用,对这些数据的处理也只是简单地统计一下降等产品的数量。先进的数据处理方式应运用到其中,从大数据中获取有价值的信息。
针对上述问题,本文将建立一个关联规则分析模型,通过实时地数据采集、处理、建模,来分析生产质量,及时有效反馈生产。
1 相关流程与定义
1.1 丝锭成型后流程
丝锭成型后的流程包括以下三个主要环节。
1)落丝
落丝环节是将络筒机上加工成符合一定要求的丝锭转至丝车,通过丝车运送至外检环节。
在整个流程中,系统都会对丝锭的信息进行记录。在卷绕头开始加工丝锭时,系统记录开始卷绕时间、生产线号以及纺位号等。丝锭加工完毕后,系统记录满卷时间、卷绕时长、批次号、规格信息、锭重、管色和落次等信息。转运过程中,系统记录丝锭的锭位信息如丝车号、丝车的位置信息。
2)外检
外检环节分为:剥丝、外检、织袜和称重。剥丝的目的是去除丝锭外层的杂丝、废丝。外检主要分为人工外检、自动外检。外检的目的是对丝车上的丝锭判定外观质量等级,对有问题的丝锭进行降等。织袜是将丝锭通过织袜机织成袜带,工作人员对其进行染色处理,对不满足染色判定标准的丝锭进行染色降等。称重是将丝车上的丝锭称重,对重量不在规定范围内的丝锭进行重量降等。
系统在此环节记录是否降等、降等原因、质量等级和丝锭重量等信息。
3)包装
包装环节首先将完成外检的,符合质量等级要求的丝锭码垛、包装,对降等的丝锭进行剔除。
系统在此环节会记录丝锭在托盘上的位置信息、置纱盘号等。
综上所述,丝锭从落丝到包装,经过的各个环节都会有详细的信息记录。这些数据的完善记录也为数据挖掘、关联分析提供数据支撑。
1.2 丝锭质量信息定义
在大多数涤纶长丝企业,通常丝锭的质量等级有AAA、AA、A、B和C(AAA为最优等级,C为最差等级)。
丝锭质量降等原因的判定主要包括以下几种:
1)前道降等:问题发生在落丝环节前,人工很难观察到的问题,比如飘错丝(飘多或飘少)、少油(含油量不足)等。此类降等信息是由其他系统通过接口传来的。
2)外检降等:外观降等是人工通过对丝锭观察来判定降等。此类降等原因有毛丝、僵点、紧点、断头、绊丝、碰伤、分层、凸肩、油污丝、尾巴丝、网络、成型、色泽和纸管等。
3)染色降等:人工对织成的袜带进行染色(分为普染、敏染和阳离子染,区别为织物与染料的配比的不同)并观察。降等情况有:主色不均匀、个别深浅色、普遍隐条和间断性条纹。
4)重量降等:对丝锭进行称重,对重量不在规定范围内的丝锭进行重量降等。
2 数据采集及处理
2.1 数据采集
为了分析出降等原因与丝锭流程中的某些环节存在关联关系,需要采集相关设备的数据,在转运过程中的转运设备数据,以及班次和生产批号等数据。
质量降等信息的采集主要在外检环节。采集方式分为以下几种:通过系统录入(WMS、PDA程序进行降等数据的录入)、机器自动外检(自动外检设备采集到信息,通过接口传给上位机)、设备采集(设备记录实时数据,通过接口传给上位机)和其他系统(如:MES)。
采集得到的数据,特征属性较多,通过对数据的分析,选取重要特征。
2.2 数据表结构设计
为了采集人工外检降等时丝锭的降等信息,设计外检信息表。主要通过手持传入的数据,该表的信息会经过存储过程外检数据分析存储过程进行过滤,将信息检验并添加到降等信息表中。主要字段有:产品索引号、运载设备二、运载设备二位置、降等原因、降等等级和生产日期等。
为了采集降等丝锭的详细信息,设计丝锭降等信息表。该表主要字段有:产品索引号、降等原因、降等等级、生产线号、位置号一、位置号二和顺序号等。
2.3 数据预处理
获取到关于丝锭质量的数据有很多,但数据通常是不一致的、极易受到噪声的影响,需要先对数据进行预处理。数据预处理包括数据格式变换和数据归一化。
1)数据格式变换
获取到的数据含有大量的非数值数据,比如班组号、生产线号和运载设备一等。这些非数值数据是有价值的,但是无法直接使用,需要对其进行规范化处理。对生产线号、运载设备二进行数值映射:{数值}{F(非数值)},其中F为映射函数。对于离群点、噪声和重复出现的数据,使用Kmeans算法进行数据清洗。
2)数据的归一化
地理环境各要素并不是彼此孤立的,而是作为整体的一部分,与其他要素相互联系和相互作用,在特征上保持协调一致,并与总体特征相统一。在地理教学过程中要以知识的点、线、面为网络,抓住知识主干,围绕重点、难点进行学习,重在构筑一个完整的知识框架体系。但现在有种错误的时髦倾向,将知识树当思维导图,然而知识结构不等于思维导图,在某一地理要素起变化时,会给其他要素带来哪些影响,这才是我们所从事的地理学的整体性的具体体现。同时,知识迁移不等同于复制,教学中要有意识地教学生迁移知识,理解概念,在教学中要多次重复,让学生耳熟能详,在不断的在重复中形成深刻的印记。
由于数据的取值区间不一致,比如生产线号的取值为[1,2,…,20],而运载设备一的取值为[1,2,…,1000]。进行向量运算时,运载设备一取值对结果的影响要远大于生产线号,因此首先要对数据进行归一化处理。这里使用线性归一化,如式(1)所示(X为某一特征中需要进行归一化的特征值,Xmin为该特征的最小值,Xmax为该特征的最大值)[1]:

将整理完的数据存于Data矩阵中。

3 模型的搭建
3.1 算法原理
为了构建丝锭质量信息关联规则分析模型,所用到的预备知识有信息熵、Gini系数和卡方验证。
3.1.1 信息熵
信息熵可以度量信息量,也可以表达不确定程度、混乱程度。信息熵越大时,不确定性就越强;反之,确定性就越强。当信息熵等于0时,信息即为绝对可信。熵值法是根据各特征数值的变异程度来确定特征权重,是一种客观赋权法,避免了人为因素带来的偏差[2]。信息熵的计算如式(3)所示。

pij表示特征j在第i条记录中占的比例,目的是计算该特征的变异程度。

通过信息熵计算各权重指标:

计算综合评价结果:

3.1.2 Gini系数
Gini系数最小原则是CART算法的分裂方式,是用来衡量特征属性重要度的方式。在保持信息熵模型优点的基础之上,对模型进行简化,减少大量的指数运算。使用Gini系数代替信息增益率,Gini系数可以衡量模型的纯洁度,Gini系数越小,其纯洁度越高,特征越好[3]。Gini系数计算如式(7)所示:pk表示一个特征的第k个类别的概率。

3.1.3 卡方验证
卡方检验是一种过滤式的特征选择方法,使用统计学方法,对每个特征评分并进行选择。其优点是,计算速度较快,不需要依赖于具体的模型。缺点是,不考虑特征之间的相互影响。
卡方验证是一种计数资料的假设检验方法,用于两个分类变量的关联分析或用于比较两个及两个以上的样本率构成比,即检验理论频数和实际频数之间的拟合程度。
卡方检验的基本公式为:
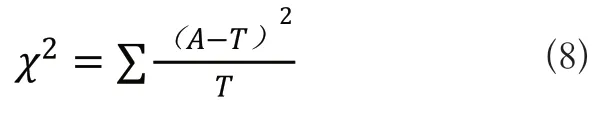
其中,A为实际频数,T为理论频数,x2为卡方值。
卡方分析先假设两个变量是相互独立的,在此假设成立条件下,计算每一变量的理论频数与实际频数。比较这两个数值,差值越大表示差距越大,原假设不成立;两个数值差距小,则卡方检验结果明显,原假设成立。通过Pearsonx2统计量来计算数据的关联程度。根据统计学假设检验理论来进行考察是否有关联,算出统计量R2后查x2(k)分布表的分数位x1-α2(k)。若R2<x1-a2(k),则关联的置信度为1-α,反之,独立。
为了获得对丝锭降等原因关联度较高的几个特征,需综合考量卡方检验、信息熵和Gini系数三者的运算结果。
3.2 模型搭建
本文搭建了一种针对涤纶长丝丝锭质量信息的关联规则分析模型。算法流程及其详细描述如下。
3.2.1 算法流程
丝锭质量信息关联规则分析的算法流程包括以下环节。
1)选择需要进行关联分析的降等原因,通过式(5)计算各特征值信息熵、通过式(7)计算各特征值Gini系数、通过式(8)计算各特征的卡方检验值。
2)对三个结果进行索引倒序排序。
3)排序号越小的评分最高,以次递减。
4)结合三个结果的评分,对总分进行索引倒序排序。
5)得到总分最高的前两个特征。
3.2.2 算法流程描述
完成数据采集及处理后,可以降等原因列表:JD_reason=[“重量降等”,”绊丝”,”夹丝”,”机械毛丝”,”机械成型”,”纸管”,”人为毛丝”,”机械碰毛”,”人为毛丝”,”其他”]。对每种降等原因进行关联规则分析,即遍历JD_reason,对所有元素分别使用3.2.1的方法进行运算。
在算法2、4步中,使用索引排序的目的是为了能够方便得到排序后的结果所对应的特征。特征列表Lable=[“生产线号”,“位置号一”,“顺序号”,“位置号二”,“产品批次号”,“产品规格”,“运载设备一”(运载1),“运载设备一位置”(运1位置),“Area”,“Jtime”,“运载设备二”(运载2),“运载设备二位置”(运2位置),“Itime”,“班组号”]。算法第5步需要通过Lable获取关联系数最高的两个特征。
将算法第1步的卡方检验、信息熵、Gini系数的结果分别存到向量X_res、E_res、G_res中。
将算法第4步最终的结果存到Res中。
算法2~4步的伪代码简化形式如下:

4 案例验证
使用上述模型对近一个月内的丝锭质量信息进行关联规则分析。在全部的降等情况中,“纸管”问题最多,故选取“纸管”降等的数据作为模型的输入数据集。输入数据集=(纸管问题数据,未降等数据),共有739072条数据,数据集如图1所示。
图1 “纸管”数据
使用模型进行计算得到结果,结果如表1所示。

表1 “纸管”结果
图2为模型计算出各特征的卡方检验(X_res)、Gini系数(G_res)和信息熵(E_res)结果:
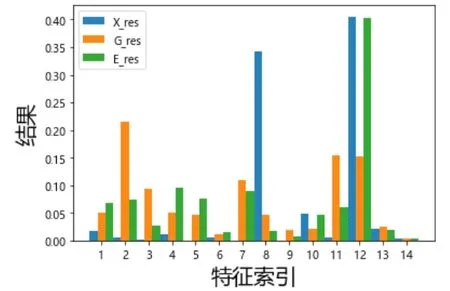
图2 各特征的三个评价指标得分情况
由以上模型的结果可得,运载设备一位置和位置号一为与“纸管”降等情况关联度最高的两个影响因素。分别计算各运载设备一位置和位置号一产生的“纸管”降等数量。
由图3左可以看出,1、9、17、25这些在运载设备一上的位置容易产生纸管问题,这些位置都是边缘位置,需要引起注意。由图3右可以看出29号位出现纸管问题最多,需要人员针对29号位置号一进行检查,是否该位置设备出现问题,导致纸管容易受损。

图3 “纸管”问题的降等数量
依照以上流程对各个的降等情况进行分析,可以分析得到跟当前降等原因关联度最高的几个特征,然后分析该降等原因和关联度最高特征的关系,来判断该时间段这些特征取哪些值时最易降等。
5 结语
本文对化纤行业中的产品质量数据进行了分析处理。通过卡方检验、信息熵和Gini系数结合进行各因素对各种降等因素的关联分析,分析出当前一段时间某种降等情况影响最大的几个关键因素。从海量的化纤行业的数据中,获得有价值的信息,及时的数据反馈,可以了解到当前生产质量的状况,优化生产流程的关键环节,提高产品质量。
