基于图卷积网络的客服对话情感分析①
2022-06-27张倩宜
孟 洁, 李 妍, 赵 迪, 张倩宜, 刘 赫
1(国网天津市电力公司 信息通信公司, 天津 300010)
2(天津市能源大数据仿真企业重点实验室, 天津 300010)
电力行业[1]是关系到国计民生的基础性行业. 电力业务运营过程产生了海量的多种形态的自然语言数据, 但是海量的数据会造成信息过载, 导致关键信息淹没在大量的其他数据中, 增加了工作人员筛选、获取有效信息的难度, 导致对已有数据缺乏有效的处理和利用, 造成信息资源的浪费. 在我们相关的研究中, 已实现针对电力业务语音数据设计自然语言识别模型,智能化地提取语音信息中的重要特征并根据语音数据自动生成对应文字内容; 进一步地, 由于电力行业专业性较强, 通过基于自然语言理解技术将非结构数据结构化, 实现电力业务知识库地自动构建. 而在本文的研究中, 针对对话信息进行有效的分析和理解, 改进了传统的繁杂、费时费力且重复性较高的客服电话质检工作, 有利于电力系统高效而稳定的运行, 将工作人员从繁杂的记录工作中解脱出来, 极大地提升数据的利用率及信息服务的自动化、智能化. 客服的话务质量关系着用户的满意度, 是服务中的一项重要指标. 在社交网络平台以及在客服服务等情境中, 都会出现大量的对话文本, 随着开源会话数据集的增加, 会话中的数据挖掘也得到了越来越多研究者的关注[2,3], 目前在客服对话领域数据挖掘工作主要是从对话系统的设计[4,5]以及在商业领域的客户购物预测[6]进行的, 而在客服对话的情感分析领域的研究也有越来越多的工作, 如胡若云等[7]提出基于双向传播框架, 首先从外部语料中获取情感词和评价属性并对其进行扩展, 然后使用基于词向量的语料相似度计算方法识别长尾词, 最后挖掘出客服对话文本的情感词和评价属性. 王建成[8]通过长短时记忆网络和注意力机制挖掘对话历史中的相关信息, 融入句子的语义表示; 在解码器中将已解码句子的情感类别的概率分布融入当前句子的情感分类过程中实现客服对话情感分析. Wang 等[9]提出基于主题感知的多任务学习方法, 该方法通过捕捉各种主题信息来学习客服对话中主题丰富的话语表达. 对话情感识别是识别对话中说话人所说语句的情绪, 本质上也可以归纳为文本分类问题.
传统的情感分析(又称观点挖掘)是从文本中分析人们的观点和情感, 是自然语言处理中一个活跃的研究领域[10]. 现有的基于文本的情感分类研究, 作为情感分析的一个重要组成部分, 可以分为基于句法分析、基于词典分析与基于机器学习分析3 大类. 基于句法分析的情感分析主要采用句法知识对文本进行分析,从而确定文本情感类别; 基于词典的情感分析方法通常将文本看成词的集合, 通过统计文本中的关键词再使用相关算法对文本情感进行评分, 从而判断情感类别; 基于机器学习的情感分类方法主要基于Pang 等[11]的工作, 将文本情感分类看作文本分类问题, 利用从情感词选取的大量嘈杂的标签文本作为训练集直接构建分类器(朴素贝叶斯、支持向量机等). 近年来, 随着深度学习技术的发展, 人们提出了各种神经网络模型, 并在文本情感分类方面取得了显著的效果.
Kim[12]首次将神经网络用于情感分类, 该方法是卷积神经网络(convolutional neural networks, CNN)的直接应用, 具有预先训练好的词嵌入功能. Kalchbrenner等[13]提出了一个动态CNN 方法, 用于句子语义建模,来处理长度不同的输入句子, 并在句子上生成一个特征图.这种模型能明确地捕捉短期和长期的关系; Xu 等[14]提出了一个缓存的长短期记忆网络(long-short term memory, LSTM)模型来捕获长文本中的整体语义信息;Zhou 等[15]设计了由两个基于注意力的LSTM 模型用于跨语言情感分类; 宋曙光等[16]提出基于注意力机制的特定目标情感分析方法; Wang 等[17]提出利用CNNLSTM 组合模型预测文本情感极性. Poria 等[18]使用双向门控循环单元(bi-directional gated recurrent unit, Bi-GRU)提取对话句子表征, 指出对话中的信息主要依赖于话语中的序列上下文信息; 王伟等[19]将Bi-GRU模型与注意力机制相结合, 并成功提成了情感分类效果. 孟仕林等[20]提出利用情感词的情感信息构造出情感向量, 与语言模型生成的向量相结合来表示文本, 并使用双向LSTM模型作为分类器进行情感分析. 邱宁佳等[21]提出融合语法规则构建双通道中文情感模型,首先设计语法规则对文本进行预处理, 然后使用CNN和BiLSTM 模型提取局部情感特征并挖掘到文本时间跨度更大时的语义依赖关系. Shen 等[22]和Wang 等[23]利用双向注意网络捕捉单轮问答对话中的语义匹配信息. 以上对话情感分析研究主要集中在话语间语境联系的建模上, 而没有考虑对话的整体特征, 也没有考虑特定说话人的特征. Majumder 等[24]提出采用注意机制, 将每个目标话语的全部或部分对话信息集中起来.然而, 这种聚合机制没有考虑说话人的话语之间信息以及其他话语与目标话语的相对位置关系.
从理论上分析, RNN、LSTM、GRU 等网络模型,可以传播长期的上下文信息, 然而在实际应用中, 这些方法过度依赖于对话上下文和序列信息, 容易忽略对话中的上下文情感动态建模, 并且由于缺乏标准数据集对文本的有效标记, 难以实现对文本的意图、个性以及主题等方面的建模.
近年来, 图卷积神经网络(graph convolutional networks, GCN)受到越来越多的关注. 在最近对相关自然语言处理任务的研究中, Yao 等[25]提出在整个语料库上构建一个异构图来进行文本级分类. Wu 等[26]反复消除GCN 层之间的非线性, 并将函数折叠成线性变换, 以降低GCN 的复杂性. Zhang 等[27]将句法依赖树引入到GCN 中对句法结构进行编码, 并将新的GCN 结构用于句子和体层的情感分析. 陈佳伟等[28]提出基于自注意力门控图卷积网络的特定目标情感分析模型, 并将预训练BERT 应用到该任务中实现情感极性的分析.
由于图神经网络在文本分类[25,29]、链接预测[30]、文档摘要[31]和关系分类[32]等方面取得了成功, 受以上研究的启发, 本文将图网络应用于客服对话的情感识别问题.
首先, 在对话过程中, 词语是构成语句的主要成分,词语在决定句子的情感极性方面起着最重要的作用,词语的出现、排列和定位以及文档不同组成部分之间的关系对于理解文档是必要的和有价值的. 另外, 在双方对话的交互语句进行建模时, 说话人信息是建模说话人之间依赖的必要条件, 即模型能够理解说话人是如何影响其他说话人的情感状态; 同样地, 对说话人自身话语的建模有助于模型理解说话人个体的情感状态变化. 此外, 在对话过程中, 上下文话语的相对位置决定了过去话语会对未来话语产生影响.
基于以上因素, 本文提出了一种新的基于异构图卷积网络的对话情感识别模型(conversation sentiment analysis based on graph convolution network, CS-GCN).
在该模型中, 首先, 根据词共现关系构建词语关系图,对整个语句进行非连续长距离的语义建模; 其次使用Bi-GRU 模型来捕捉连续顺序语句之间的上下文信息,并根据对话双方语句信息建立顺序语句的自我上下文依赖关系和交互语句上下文依赖关系, 并通过邻居语句特征聚合进而得到每个语句的特征. 最后通过以上图模型的建立, 将词结构嵌入表示、语句上下文之间的自我顺序依赖和交互依赖关系得到的语句嵌入表示聚合得到文本信息的最终嵌入表示, 实现对话情感状态检测.
1 基于图卷积网络的对话情感识别
1.1 模型设计
在大数据时代, 文本是存储数据和元数据最普遍的形式之一, 数据表示是数据挖掘中特征提取阶段的关键步骤. 因此, 如何构建一个合适的文本表示模型,能够更好地描述文本数据的固有特征, 仍然是一个挑战. 本文从词共现关系、语句的自依赖关系和互依赖关系两方面构建分别构建词图模型和有向语句图模型,并采用图卷积网络提取文本特征, 进一步得到文本最终的嵌入表示用于识别对话情感状态. 该模型主要由4 部分组成: 字图编码结构、顺序上下文语句编码结构、交互上下文语句编码结构和情感分类器. 所提出框架的总体架构如图1 所示.
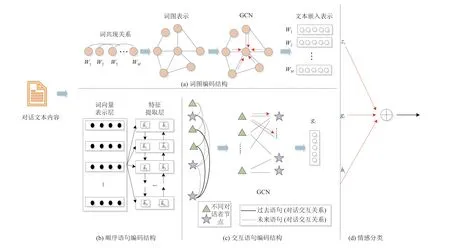
图1 基于图卷积网络的客服对话情感分析框架
1.2 字图编码
1.2.1 词共现图构建
词语是构成语句的主要成分, 词语在决定句子的情感极性方面起着最重要的作用, 词语的出现、排列和定位以及文档不同组成部分之间的关系对于理解文档是必要的和有价值的. 对话情感识别的第一个关键问题是对对话语句词语进行建模并提取特征, 尽管有各种基于图形的文档表示模型, 但词共现图是表示社交媒体内容中一个词和另一个词之间关系的有效方法. 在文献[33] 的启发下, 本文构建窗口大小为3 的词图. 图2 给出了一个示例句子的图, 当两个节点在一个最大长度为3 的窗口内时, 则认为两节点之间具有连边.
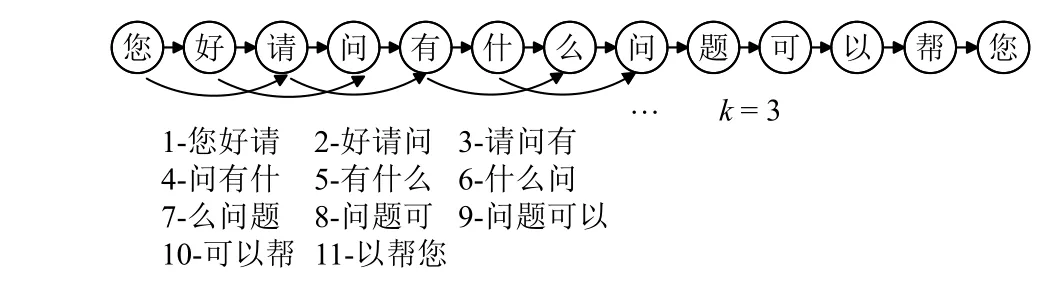
图2 窗口为3 的示例词图
1.2.2 字图编码结构



1.3 语句编码
1.3.1 构建对话语句有向图
对话情感识别另一个关键的是对语句上下文进行建模, 语句上下文包括说话者自身语句的上下文以及双方对话形成的上下文. 受Majumder 等[24]的启发, 针对每一句对话本文都通过两种上下文关系进行建模.但考虑到在对上下文语句进行建模时, 情感动态会随之改变, 即对话双方未来语句的情感状态不仅会受到自身过去语句的影响, 还会受到对方过去语句的影响,这种对话语句自身的依赖性和语句交互的依赖性分别称为顺序语句自身依赖和交互语句相互依赖关系. 在本文提出的方法中, 将这两种截然不同但相关的上下文信息(顺序语句编码和交互语句编码)结合起来, 实现增强的上下文表示, 从而更好地理解会话系统中的情绪状态. 如图3 所示为语句自依赖和交互语句依赖关系.

图3 语句自依赖和交互语句依赖关系图
1.3.2 顺序语句编码
对话的本质是一种序列信息, RNN 模型被广泛用于序列信息建模, GRU 是一种与LSTM 相似的递归神经网络, 它也被用来解决反向传播中的长期记忆和梯度问题. GRU 的输入输出结构类似于RNN, 其内在思想类似于LSTM. 与LSTM 相比, GRU 具有更少的“选通”和更少的参数, 但可以实现与LSTM 相同的性能.因此考虑到计算开销, 本文选择Bi-GRU 来捕捉上下文信息. 首先在编码语句时不区分说话人, 对全部对话语句信息进行特征表示. 以前向传播GRU 为例, 每个GRU 单元包含更新门和重置门, 给定状态向量ht∈RF,当前隐藏状态可计算如下:


1.4 情感分类与模型优化


2 实验
在实验中, 首先将所提出的CS-GCN 方法与基线和性能较好的情感分析方法进行了比较, 验证了不同上下文窗口对情感分析准确率以及F1 值的影响, 并且验证了不同聚合函数的性能, 最后设置了消融实验来验证采用词共现关系, 顺序语句编码器和交互语句上下文编码器进行对话情感分析的有效性. 实验环境为:Intel Xeon 2.30 GHz, RAM 256 GB 和Nvidia Quadro P620 GPU; 操作系统和软件平台是Ubuntu 16.04、TensorFlow 1.14 和Python 3.5.
2.1 数据集与评价指标
IEMOCAP: 南加州大学的SAIL 实验室收集的双人对话数据. 该数据集包括151 段对话, 共7 433 句. 该数据集标注了6 类情绪: 中立, 快乐, 悲伤, 愤怒, 沮丧,兴奋, 其中, 非中立情绪占比77%. 为简化实验, 实验中对6 种情绪状态只进行积极、消极以及中立3 种情感分类.
AVEC2012: SEMAINE 数据库收集的多模态对话数据, 由4 个固定形象的机器人与人进行对话, 曾用于AVEC2012 挑战赛使用的数据. 该数据有95 段对话,共5 798 句. 标注了4 个情感维度: Valence, Arousal,Expectancy, Power. Valence 表示情感积极的程度,Arousal 表示兴奋的程度, Expectancy 表示与预期相符的程度, Power 表示情感影响力. 其中, Valence、Arousa和Expectancy 为[-1, 1]范围内的连续值, Power 为大于等于0 的连续值.
为了评价不同模型的情感分析准确率, 采用准确率和F1 值作为评价指标
2.2 情感分析对比
为了全面评估CS-GCN, 将本文提出的模型与以下方法进行比较, 选择串联操作作为聚合函数, 并且在参数设置过程中, 尽量保持4 种文本模型在参数设置上的一致性, 由于模型结构的不同而无法达到一致性时, 采用最优的参数设置. IEMOCAP 和AVEC2012 中没有提供预定义的训练集和验证集分割, 因此使用10%的训练对话作为验证集.
CNN[12]: 基于卷积神经网络的基线模型, 该模型是上下文无关的, 不使用上下文语境中的信息. 该模型中,词向量维度为100, 学习率为0.001, 滤波窗口选择3、4 和5; Dropout 为0.5, 批大小为64.
Memnet[34]: 每一个话语都被反馈到网络中, 与先前话语相对应的记忆以多跳方式不断更新, 最后利用记忆网络的输出进行情感分类. 该模型中, 学习率是0.01, 每25 个epoch 学习率自动减半, 直到100 个epoch.在梯度下降中, 没有采用动量和权重衰减. 矩阵采用Gaussian distribution 随机初始化, 均值为0, 方差为0.1.批大小为是32. 采用L2 正则化.
c-LSTM[35]: 通过使用双向LSTM 网络捕获上下文内容进行建模, 然后进行情感分类, 但是上下文LSTM模型与说话人之间的交互无关, 即不对语句间交互依赖关系建模. 该模型词向量维度为100, Bi-LSTM 隐藏层有64 个神经元, 学习率为0.001, Dropout 为0.5, 同时设置双向LSTM 的层数为128 层.
CMN[36]: CMN 使用两个不同的GRU 模型为两个说话人从对话历史中建模话语语境. 最后, 将当前话语作为查询反馈给两个不同的记忆网络, 得到两个说话人的话语表示. 对于CMN 模型, 卷积层的滤波器大小为3、4 和5, 每个滤波器具有50 个特征映射, 在这些特征图上使用最大池, 池窗口大小为2, 最后使用100 个神经元的完全连接层.
DialogueRNN[24]: 基于说话者、过去话语的上下文和过去话语的情绪, 应用了3 个GRU 来对这3 方面进行建模, 该模型是目前在对话情感分析领域取得最好性能的模型, 因此在本文中选用原文的参数进行实验.
在实验中将所有的实验都独立运行5 次, 并取平均值作为最终实验结果, 如表1 和表2 所示.

表1 IEMOCAP 数据集在不同模型上的情感分类准确率对比(%)

表2 AVEC2012 数据集在不同模型上的情感分类准确率对比(%)
在IEMOCAP 数据集上, CS-GCN 的准确率和F1 值分别为68.34%和71.26%, 相比于DialogueRNN模型的准确率和F1 值分别提高了5%和6%左右. 在AVEC2012 数据集上, CS-GCN 在所有4 个情感维度上的准确率和F1 值也同样都优于其他模型. 与CNN,Memnet, c-LSTM 和CMN 4 个基线模型相比, CSGCN 和DialogueRNN 都对交互语句级别的上下文进行建模, 而其他基线模型都没有对交互语句之间的依赖关系进行编码, 因此其情感分类的准确率优于基线模型. 其次, CS-GCN 和DialogueRNN 都对交互语句级别的上下文进行建模, 但CS-GCN 同时采用了词共现关系对语句进行编码, 其次CS-GCN 通过卷积神经网络对语句的邻域信息进行聚合进而得到该语句的特征表示, 因此相比于DialogueRNN 模型, CS-GCN 模型获得了更好的情感分类性能.
2.3 上下文窗口设置
在实验中分别验证了不同的上下文窗口对情感分类准确率的影响, 分别设置P=10,Q=10;P=8,Q=8;P=4,Q=4;P=0,Q=0四组实验进行对比, 在两个数据集上得到的准确率和F1 值如图4 所示.
由图4 可知, 在两类数据集上, 随着上下文窗口的减小, CS-GCN 模型的情感分类性能也逐步下降, 当上下文窗口大小为P=0,Q=0, CS-GCN 模型只对词共现结构和顺序上下文进行编码, 不再对交互语句之间的依赖关系进行编码, 因此情感分类性能较差.

图4 不同上下文窗口大小情感分类性能对比
2.4 聚合函数测试
为了验证不同聚合函数对情感分类准确率的影响,我们测试了3 种聚合函数在两个数据集上的性能, 实验准确率如表3 所示.

表3 不同聚合函数测试准确度(%)
显然, 串联融合达到了最佳准确度, 而其他两个聚合函数的性能相对较差. 这是因为串联操作在嵌入聚合期间保留比求和和最大池更多的信息, 有助于学习更好的节点信息表示.
2.5 消融实验
为了验证采用词共现关系, 顺序语句编码器和交互语句上下文编码器进行对话情感分析的有效性, 在两个数据集上对几种模型的情感预测性能进行了实验比较. 首先, 将只有顺序语句编码器模型视为对话语句情感分析的基线模型, 记为CS-GCNN. 此外, 为了验证词共现关系和交互语句上下文编码对情感分析的有效性, 在基线模型的基础上加入了词共现编码结构记为CS-GCNW. 为了验证交互语句上下文编码的适用性,在基线模型的基础上增加了交互语句上下文编码结构,记CS-GCNS. 最后, 将词共现关系编码结构和交互语句上下文编码结构嵌入到基线模型之上, 进一步验证组合的优越性. 模型类型如表4 所示, 实验结果如图5所示.

表4 不同模型类型

图5 不同模型类型情感分类性能对比
从图5 可以看出, 随着词共现关系编码器, 交互语句上下文编码器结构的加入, 情感分类的准确率和F1 得到了逐步提高. 在数据集IEMOCAP 上, 与CSGCNN模型相比, CS-GCNW模型的准确率和F1 值分别提高了10.38%和10.05%左右. 与CS-GCNN模型相比, CS-GCNS模型的准确率和F1 值分别提高了13.66%和10.75%. 通过词共现关系编码器, 交互语句上下文编码器结构的加入, 证明了CS-GCNW和CSGCNS模型能够提高情感分类的性能, 具有普遍适用性. 其次, 在CS-GCN 模型中, 实现了3 类编码结构的嵌入和融合用于情感分类, 与CS-GCNN模型相比, CSGCN 模型的准确率和F1 值分别提高了40.98% 和38.06%. 最后, 将CS-GCN 模型与CS-GCNW和CSGCNS模型相比较, 准确率和F1 值同样得到了显著的提高. 综上所述, 这些对比实验充分验证了本文提出的CS-GCN 模型通过引入词共现关系编码器, 交互语句上下文编码器结构, 显著提升了对话情感分析的性能.
3 结论
受异质图卷积网络的启发, 本文提出了一种基于图卷积网络的客服对话情感分析方法. 提出的CSGCN 模型与传统的基于RNN 模型的对话数据情感检测方法不同, CS-GCN 模型将词共现关系, 语句的顺序上下文特征以及不同说话人语句之间的交互依赖关系进行融合编码, 通过图卷积网络实现对文本特征提取与聚合得到最终的文本表示, 进一步实现对对话情感的状态识别. 在实验中, 将CS-GCN 模型与基础CNN,Memnet, c-LSTM, CMN 和DialogueRNN 模型在两个数据集进行情感分类准确率的对比, 验证了CS-GCN模型可有效提高情感识别准确度. 其次, 设计了相关的消融实验验证了融合词共现编码, 顺序语句上下文编码以及交互语句上下文编码3 种结构对于对话情感识别准确率提高的有效性. 在未来的工作中可将多模态信息整合到CS-GCN 网络中, 进一步提高对说话人之间的情感转换检测, 为客服的质检工作提供及时、客观、有效的分析.
