结合坐标注意力与自适应残差连接的logo 检测①
2022-06-27范亚臣
王 林, 范亚臣
(西安理工大学 自动化与信息工程学院, 西安 710048)
Logo 是指徽标或商标, 通常由图形、文字或者图形和文字的组合构成. Logo 被用于各种物体表面对物体进行标识. Logo 检测的任务是定位和识别图像中的logo, 它在知识产权保护、产品品牌识别、智能交通车辆标识检测、社交媒体产品品牌管理等领域有很多应用. Logo 检测虽然可以被视作目标检测的一种特殊类型, 但是由于大小、旋转、光照、遮挡和形变等因素的影响, 检测自然场景图像中的logo 是具有挑战性的.
自然图像中的logo 检测方法大致分为传统方法和基于深度学习的方法. 传统方法依赖于手工设计的特征和轮廓, 通过特征和轮廓匹配来识别和分类, 常见特征有尺度不变特征变换(scale invariant feature transform,SIFT)[1]特征、加速稳健特征(speeded up robust feature,SURF)和方向梯度直方图(histograms of oriented gradients,HoG)[2]特征. 在过去的2007-2014 年间, 手工设计的特征是大多数logo 检测和识别方法的核心. Kleban 等人[3]提出了一种基于数据挖掘的方案, 将每幅图像视为一个事务, 在多分辨率下寻找关联规则, 以找到与logo 对应的局部SIFT 特征的频繁空间配置. Gao 等人[4]提出通过空间光谱显著性来发现logo 区域, 对查询图像中使用的这些区域提取SURF 特征, 然后根据提取的SURF 特征发现数据集图像与查询图像之间的相似度.Zhang 等人[5]提出将图像随机分割并从中提取混合特征, 包括纹理特征、形状特征、梯度方向直方图特征、HoG 特征、SIFT特征和SURF 特征, 然后应用随机森林分类器进行logo 检测.
近年来, 深度学习方法在计算机视觉的各个领域得到了广泛的应用, 随着深度学习的发展, 很多使用CNNs 的logo 检测模型被提出. Iandola 等人[6]首次将Faster R-CNN[7]应用于logo 检测, 在GoogLeNet结构中每个初始化层之后添加全局平均池化来辅助分类. Paleček 等人[8]研究了优化算法、批量大小和学习率调度的具体设计对最终检测性能的影响. 同时, 对4 种不同主干网的3 种主要类型的探测器进行了实证评价. 通过实验观察到Faster R-CNN 通常比Mask RCNN[9]和以RetinaNet[10]为代表的single shot 检测器表现得更好. 黄明珠等人[11]考虑到logo 的低分辨率导致的检测性能难以进一步提升, 在Faster R-CNN 框架中结合了生成对抗模型, 利用网络先将分辨率较低的logo 特征映射成高分辨率的表达能力更强的特征, 再送入完全连接层进行分类和回归, 从而提高检测的性能. 2020 年, Alsheikhy 等人[12]将传递学习技术应用于深度卷积神经网络模型DenseNet[13], 在较少的参数以及较小的计算开销下进行logo 识别. Wang 等人[14]引入最大的全标注logo 检测数据集LogoDet-3K, 并提出了一个强大的基线方法Logo-Yolo, 它将focal loss 和CIoU 损失合并到最先进的YOLOv3 (you only look once version 3)框架[15]中, 用于大规模的logo 检测.
上述研究虽然在一定程度上提高了logo 检测性能, 但仍存在一些不足. 目前存在的logo 检测算法对小尺寸的logo 检测不准, 并且对图像中的logo 定位精度低, 无法在图像中准确地框出logo 的位置, 因此本文基于YOLOv4 算法[16]提出了一种融合坐标注意力和自适应残差连接的logo 检测方法, 可以提高logo 定位精度和小尺寸logo 的检测性能. 主要的改进包括两个方面: 一是使用设计的自适应残差块替换5 个连续卷积层, 增强特征利用, 同时优化网络训练. 二是引入坐标注意力机制[17], 使用通道重要性和空间位置重要性来增强对于检测更有用的信息, 剔除冗余信息. 对logo 检测数据集使用聚类算法获得最佳的先验框尺寸. 通过FlickrLogos-32 数据集[18]和FlickrSportLogos-10 数据集进行训练和验证, 并在相同的环境下与YOLOv3、YOLOv4 等检测算法进行比较, 验证改进算法的性能.
1 相关工作
1.1 YOLOv4 网络
YOLOv4 目标检测器的网络架构如图1 所示, 主要包括输入(input)、骨干网络(backbone)、颈部(neck)和预测模块(prediction) 4 个部分. 骨干网络是在ImageNet 上进行预训练, 而颈部用于收集各个阶段的特征图, 预测模块用于预测物体的类别、置信度和边界框. 图1 中, CBM 单元包含卷积层(convolutional,CONV)、批归一化层(BatchNormalization, BN) 和Mish 激活函数; CBL 单元包含CONV 层、BN 层和LeakyReLU 激活函数; Res_unit 单元由两个CBL 单元进行残差操作, 通过引入BN 层和残差单元可以加快网络训练, 防止随着网络加深而出现的梯度消失以及网络退化问题; 3 个CBL 单元和X个Res_unit 进行残差操作构成CSPX 单元; SPP 单元由4 个尺寸分别为1×1、 5 ×5、 9 ×9和 1 3×13的卷积核对输入进行最大池化(MaxPool)操作, 然后拼接(concat) 4 个分支的结果;图中的*代表连续多个模块. YOLOv4 算法是一种端到端的目标检测算法, 相比于YOLOv3 算法, 主要有以下4 个方面的改进.
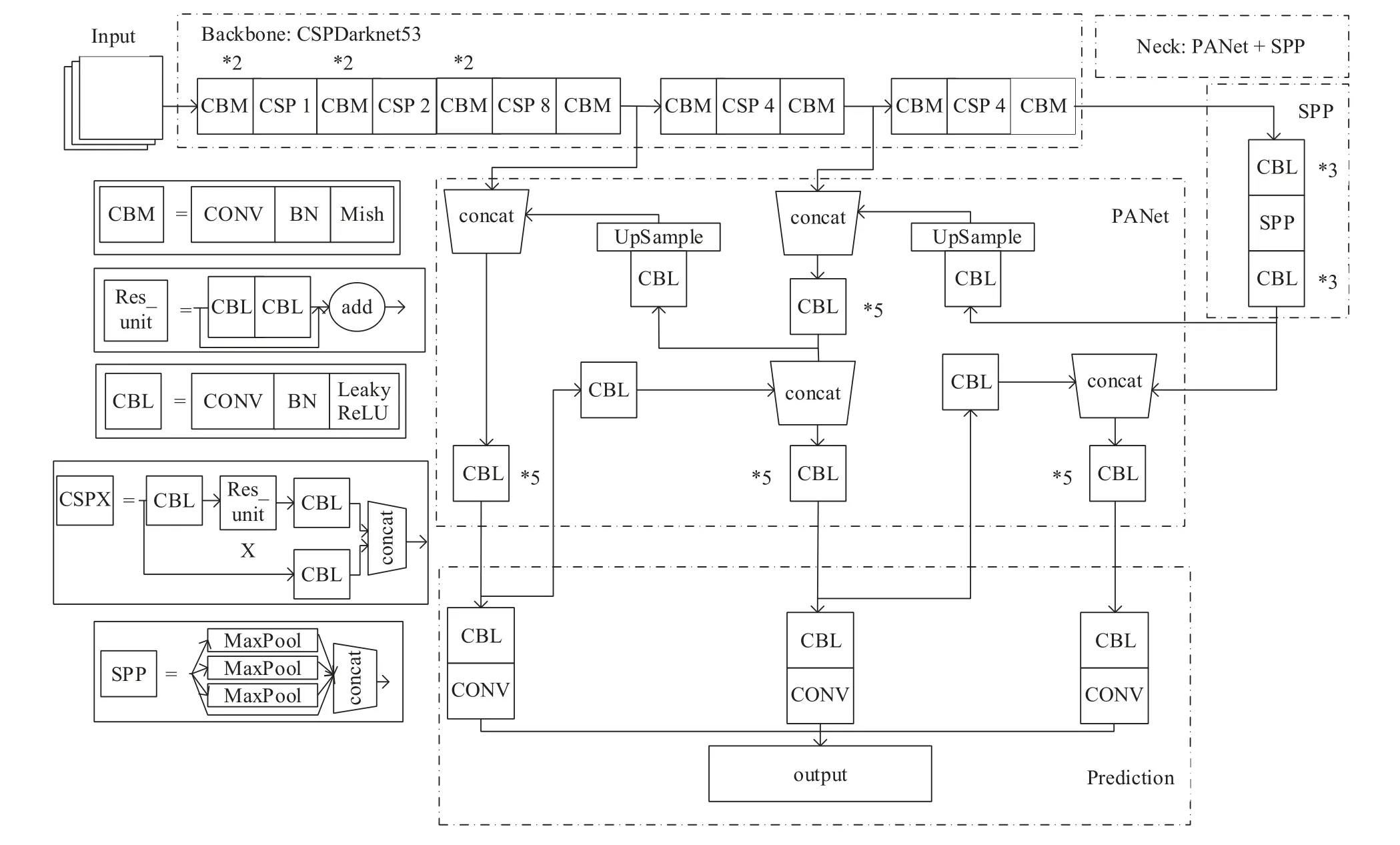
图1 YOLOv4 网络架构图
(1) Input: 对输入数据进行Mosaic 数据增强. 通过随机选取4 张输入图像进行随机裁剪、拼接和排布从而丰富数据集, 一方面多样化目标可能出现的背景, 另一方面增加了小目标的数量. 这种数据增强方式扩充了数据集, 提高了模型的鲁棒性和对小目标的检测能力.
(2) Backbone: 使用更好的骨干网络CSPDarknet53[19]来提取输入的特征, 相比于YOLOv3 的Darknet53 多了5 个CSP 模块, 在骨干网络中使用Mish 激活函数[20],并使用Dropblock 正则化方式来防止网络发生过拟合.
(3) Neck: 在Backbone 和最后的预测模块之间添加了SPP 模块和PANet 模块[21], SPP 用于增大感受野,PANet 用于特征整合.
(4) Prediction: 训练时使用CIOU 损失[22]代替MSE 损失, 在边界框回归问题上有更好的回归速度和准确率, 在测试阶段使用DIOU 非极大值抑制策略.
1.2 注意力机制
人类的视觉系统会将有限的注意力放在重点信息上, 自动忽略不重要的信息, 注意力机制(attention model, AM)类似于人类的视觉系统, 它的核心思想是从关注全部到关注重点, 从而节约资源, 快速准确地获取最有效的信息. 注意力机制最初被应用于机器翻译任务中, 现在已被广泛应用在自然语言处理、统计学习、语音识别和计算机视觉任务中. 注意力模型能够显著提高神经网络性能和可解释性. 计算机视觉任务中注意力机制通常分为空间注意力、通道注意力和混合注意力, 如SENet (squeeze-and-excitation network)[23]和CBAM (convolutional block attention module)[24]等.2021 年, Hou 等人[17]考虑到SENet 只考虑通道之间的信息而忽略了位置信息, 但是位置信息对于生成空间选择性注意力图非常重要, 因此作者引入了一种新的坐标注意块(coordinate attention, CA), 它不仅仅考虑了通道间的关系还考虑了特征空间的位置信息.
2 YOLOv4-RCA 模型
为了获得更高的检测精度, 对YOLOv4 网络的特征增强部分进行了改进, 提出了YOLOv4-RCA 网络.
2.1 YOLOv4-RCA 网络架构
(1)自适应残差块代替连续卷积
在网络中为了获得更大的感受野和更丰富的上下文信息, 通常会使用卷积来进行下采样操作, 但是下采样操作会导致原特征图中细节信息丢失. 残差单元[25]以跳层连接的形式实现, 将单元的输入直接与单元输出加在一起, 然后再激活. 残差连接可以将浅层特征送入深层网络, 在不增加过多成本的条件下融合了更多的特征信息, 增强了网络的特征表达能力, 同时很好地解决了深度神经网络的退化问题. 残差连接在一定程度上起到了细节补充的作用, 但是同时也带来了很多冗余信息, 因此本文设计了一种自适应残差连接的方式, 在融合浅层和深层特征来减少原特征图中细节信息丢失的同时能够减少冗余信息.
本文中的自适应残差(adaptive residual)连接方式首先对输入特征使用坐标注意力进行加权, 进一步提取出输入中的有用特征, 然后再与输出以通道相加的方式进行融合. 如图3 所示, 对于YOLOv4 网络PANet中5 个连续卷积CBL 块, 前两个CBL 模块进行自适应残差连接, 第3 和第4 个CBL 模块进行自适应残差连接, 这样构成设计的残差块AR, 图4 是AR 的结构,图中的CA 代表对输入特征图通过坐标注意力进行加权, and 代表输入特征矩阵和输出特征矩阵通过逐元素相加来进行特征融合. 在图2 中用Res2C 模块替换了原网络架构中的5 个连续卷积, 这样能有侧重地将输入的特征与输出特征进行融合, 增强浅层和深层的特征利用, 减少原特征图的细节信息丢失.
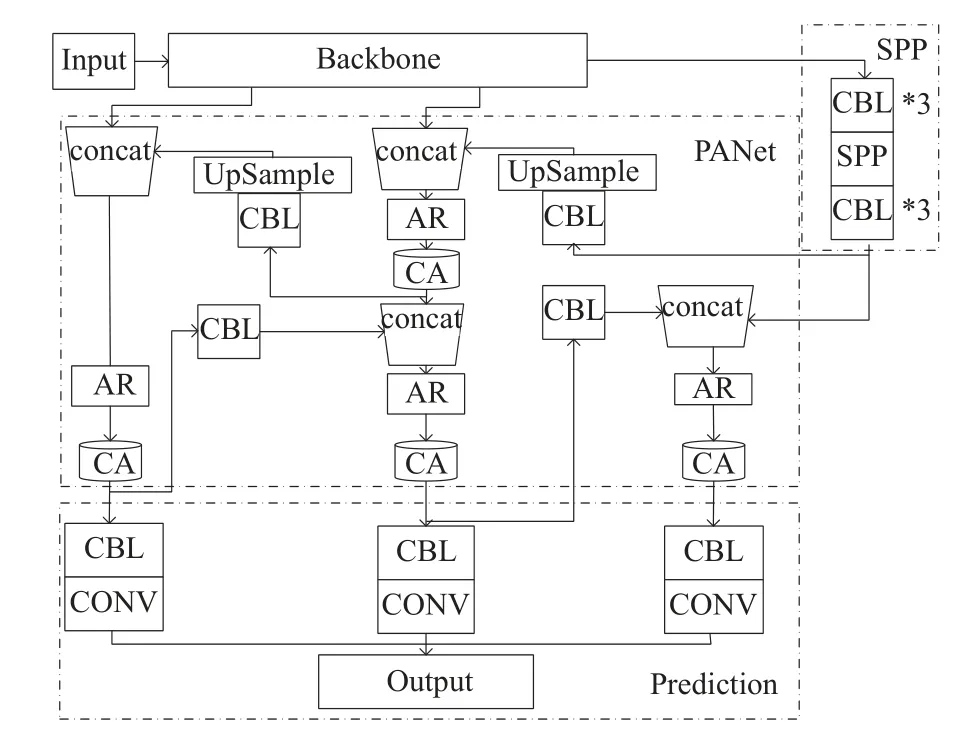
图2 YOLOv4-RCA 架构
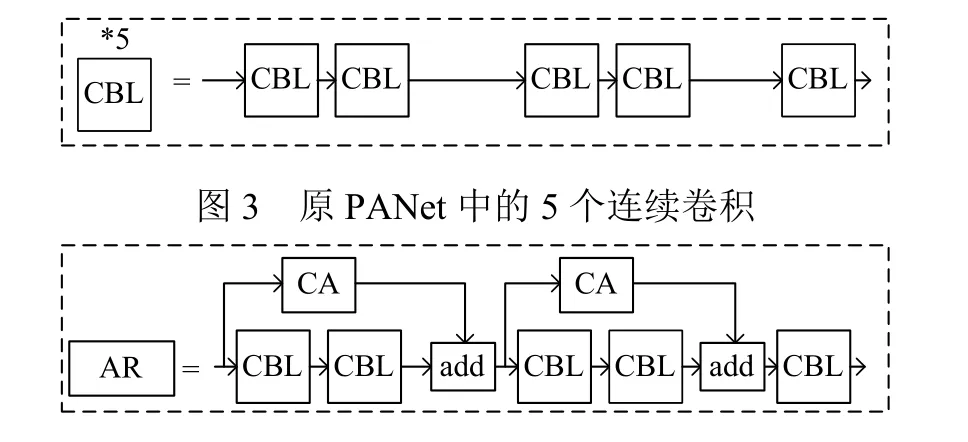
图4 设计的自适应残差块AR 的结构图
(2)引入坐标注意力机制
坐标注意块给通道注意力中嵌入位置信息, 在重新权衡不同通道重要性的同时, 也考虑对空间信息进行编码. 这种编码方式可以使坐标注意力更准确地定位感兴趣对象的准确位置, 从而帮助整个模型更好地定位和识别. 如图2 所示, 在PANet 中4 处Res2C 模块之后添加坐标注意力CA 模块. 这样可以从融合的特征中过滤和增强有用的特征, 同时抑制无用的特征, 将增强的特征送给预测部分来进行分类和定位. CA 模块不添加在主干网络中是为了不改变骨干网络CSPDarknet53的结构, 以使用在ImageNet 上预训练的权重, 而无需从头开始训练网络. 添加CA 模块可以在基本不增加计算量的同时, 提高模型区分背景和前景的能力.
2.2 YOLOv4-RCA 中的注意力模块
在通道注意力中通常使用全局池化来编码全局空间信息, 这种方式将全局空间信息压缩到单个通道描述符中, 因此很难保存通道中对象的空间位置信息.CA 注意力的核心思想是通过精确的位置信息对通道关系和长期依赖性进行编码, 如图5 所示, 具体操作可分为坐标信息嵌入和坐标注意力生成两个步骤.
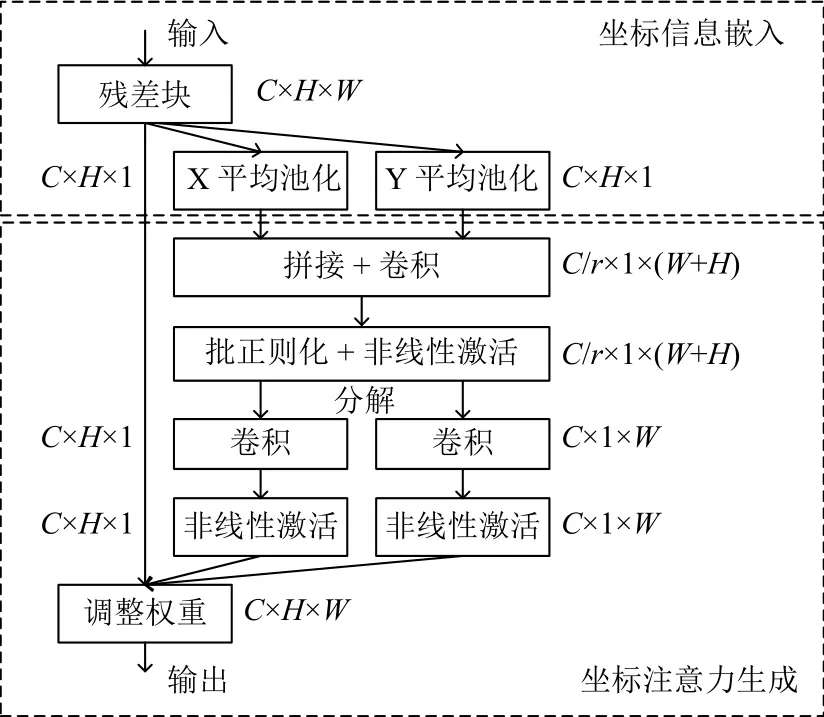
图5 坐标注意力机制的操作过程

这两种转换保证注意力模块捕捉到沿着一个空间方向特征的长期依赖关系, 并保存沿着另一个空间方向特征的精确位置信息, 这有助于网络更准确地定位感兴趣的信息.
(2)坐标注意力生成
将两个方向的坐标信息嵌入进行拼接, 然后进行卷积、批正则化和非线性激活的操作, 如式(4)所示.

2.3 先验框尺寸
从YOLOv2 开始, YOLO 系列算法引入了先验框(anchor box)的概念, 根据标注的真实框(ground truth)使用K-means 聚类算法[26]来获得K个anchor box, 用来提高检测的速度和准确率. YOLOv4 算法中先验框的尺寸是由COCO (common objects in context)数据集通过聚类算法得到的, 但是COCO 数据集中包含了80 个类别, 宽高比的差别较大, 检测对象的尺寸也较大, 而对于logo 检测任务, 图像中logo 的尺寸偏小, 同时logo的宽高比变化相对较少, 因此, 对于logo 检测任务, 需要通过重新聚类来选取适合logo 数据集的先验框尺寸.
本文选择K-means++聚类算法对数据集中的标注框进行聚类获得9 个先验框, 并为每个特征检测尺度分配3 个检测框. 对FlickrLogos-32 和FLickrSportLogos-10数据集先验框聚类和分配结果如表1 所示. 相比于YOLOv4 最初的先验框, 根据logo 检测数据集通过聚类得到的先验框尺寸更符合训练集中logo 的宽高比,使用重新聚类获得的先验框对网络进行训练能够使得检测更加准确高效.

表1 先验框聚类和分配结果
2.4 损失函数
总的损失包括类别损失、置信度损失和边界框回归损失3 部分, 类别损失和置信度损失用二元交叉熵损失来计算, 对于边界框回归使用CIOU 损失来代替MSE 损失, 总损失的计算方法如式(8)所示.


3 实验结果和分析
3.1 实验设置
实验在以下配置的计算机上进行: 处理器: Inter(R)Xeon(R) CPU E5-2640 v4 @2.4 GHz; 显卡: NVIDIA 1080Ti GPU, 显存11 GB; 系统类型: 64 位CentOS Linux 7 操作系统. 算法用深度学习框架PyTorch1.4.0实现, Anaconda 集成开发环境, Python 3.7 编程语言.关于网络参数设置, 设置批训练量batch_size 为8, 图像在训练前尺寸调整为608×608, 对骨干网络CSPDarknet53使用大型分类数据集ImageNet 进行预训练, 获得参数初始化, 除此之外, 网络中其他结构均采用normal 方法进行参数初始化; 优化算法使用Adam 算法; 学习率使用余弦退火学习率衰减方法; 总共训练100 个epoch,其中前50 个epoch 冻结骨干网络部分的权重; 使用YOLOv4 系列算法时在训练阶段使用Mosaic 数据增强.
3.2 数据集
为了验证我们提出的YOLOv4-RCA 算法的性能,我们在FlickrLogos-32 数据集和FlickrSportLogos-10 数据集上分别实验. 数据集包含的logo 如图6 所示.FlickrLogos-32 数据集包含了Adidas、Aldi、Apple、Becks、Bmw 等32 个logo 类别, 每个类别有70 张图像, 将官方提供的数据集标注的格式转换成PASCAL VOC 数据集格式用来训练. FlickrSportLogos-10 数据集是一个包含361、Adidas、Anta、Erke 和Kappa 等10 种体育运动品牌的数据集, 共有2 038 张图片.

图6 FlickrLogos-32 和FlickrSportLogos-10 数据集
3.3 评估指标
为了评估所提出的算法对logo 检测的有效性, 本文使用COCO 评估指标,AP,AP50,AP75,APS,APM和APL, 其中,AP为 0.50-0.95 之间10 个不同IOU设置下平均准确率的平均值, 该指标能描述模型对感兴趣对象的定位精度;AP50是IOU为0.5 时各个类别的平均准确度;AP75更 严格一些, 是IOU为0.75 时各个类别的平均准确度;APS,APM和APL分别描述的是小、中和大目标的平均准确度. 同时, 使用PASCAL 指标来评估算法在每个logo 类别上的检测精度, 即每个类别上的AP和所有类别的平均检测精度mAP. 考虑在推理阶段的FPS来衡量模型的推理速度, 本实验中FPS是在单张NVIDIA GTX1080ti GPU 上计算的.
3.4 实验过程
在FlickrLogos-32 数据集和FlickrSportLogos-10数据集上分别实验, 使用COCO 和PASCAL 指标来评估引入自适应残差块Res2C 和坐标注意力CA 的YOLOv4-RCA 算法的性能, 并将其与YOLOv3 算法和YOLOv4算法进行比较.
在FlickrLogos-32 数据集上的COCO 评估结果如表2 所示. 根据表2 的结果, 可以发现相比于YOLOv3算法, YOLOv4-RCA 算法在每一项指标上都有改进;而相比于YOLOv4 算法, YOLOv4-RCA 算法在牺牲1.78%FPS的情况下, 除了指标AP75, 在其余所有指标上都有不同程度的提高. 重点关注AP和APS这两个指标, 发现相比于YOLOv4 算法, YOLOv4-RCA 算法的AP指标提高了0.94, 说明YOLOv4-RCA 算法提高了logo 定位精度;APS指标提高了7.76%, 表明YOLOv4-RCA 算法在小尺寸logo 的检测性能有了显著改善. 通过分析表3, 可以在FlickrSportLogos-10 数据集上得到类似的结论.
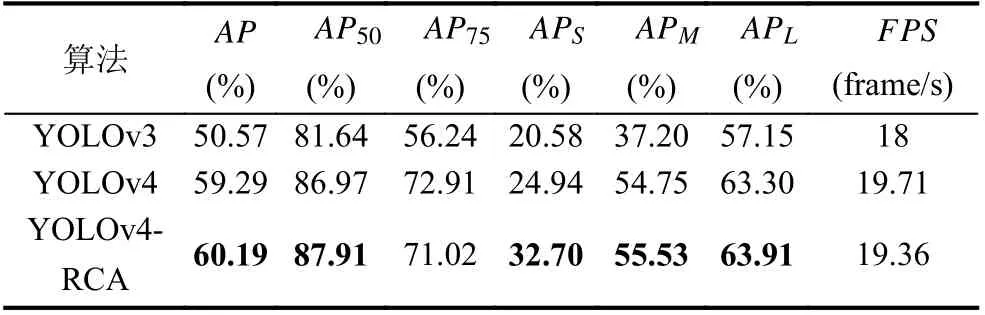
表2 FlickrLogos-32 数据集上的比较
在FlickrLogos-32 上的PASCAL 评估结果如表4所示, 表4 中展示了3 种算法在每个类别上的准确度和在32 个类别上的平均准确度. 从表3 可以看出, 提出的YOLOv4-RCA 算法在“Apple”“Dhl”和“Guiness”等15 个logo 类别上准确度达到最高; 32 个类别上的平均准确度mAP相比YOLOv3 算法提高了5.37%, 相比YOLOv4 算法提高了0.91. 通过分析表5 也可以在FlickrSportLogos-10 数据集上得到类似的结论.
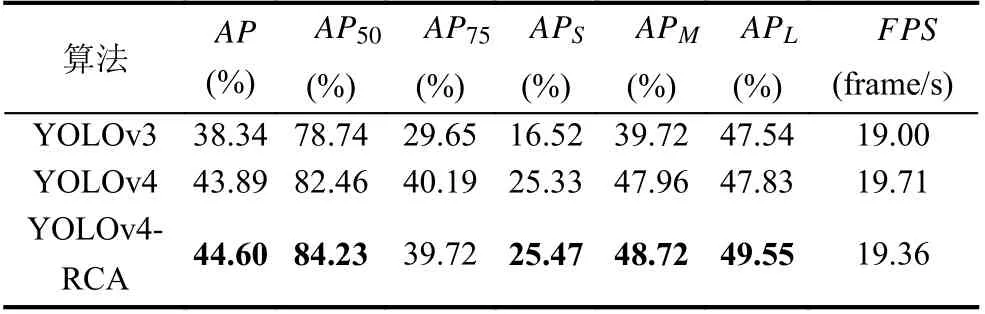
表3 FlickrSportLogos-10 数据集上的比较
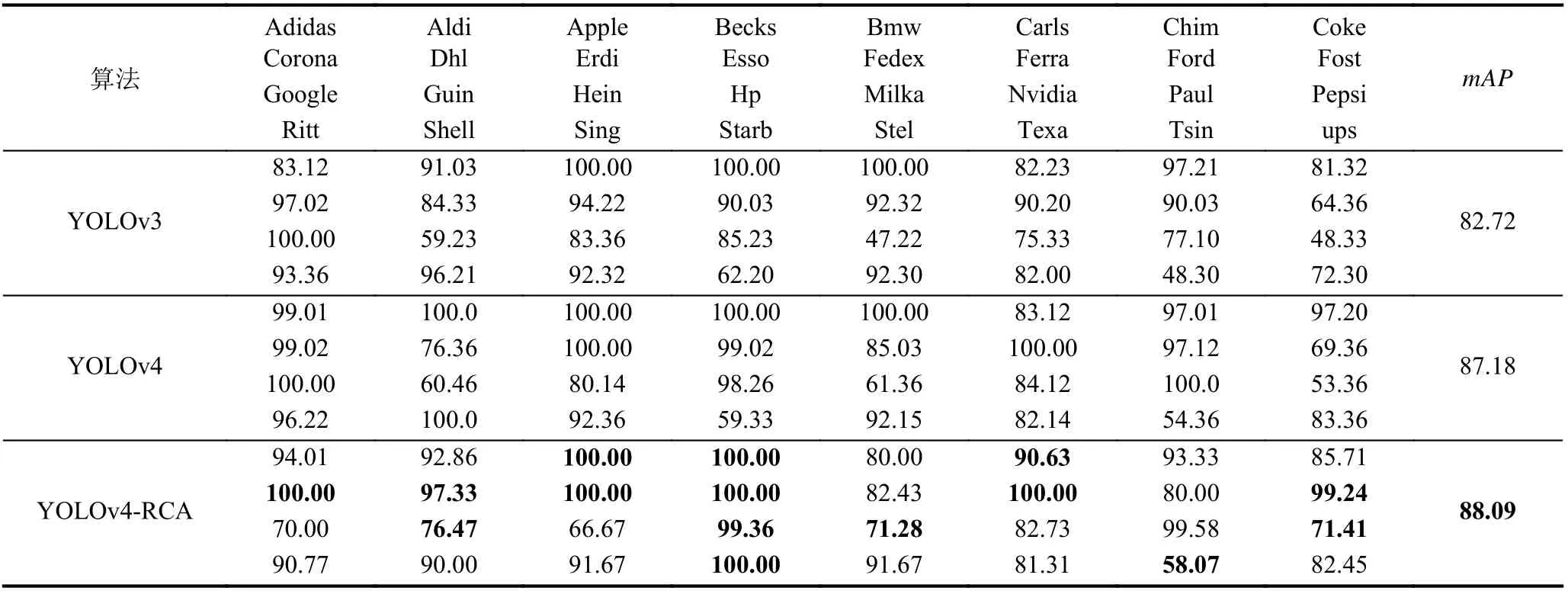
表4 3 种算法在FlickrSportLogos-10 数据集上的比较(PASCAL 评估) (%)

表5 3 种算法在FlickrSportLogos-10 数据集上的比较(PASCAL 评估) (%)
为了更直观地分析3 种算法的检测性能, 从Flickr-Logos-32 数据集中选取3 张具有代表性的图片来对算法进行测试, 检测对比结果如图7 所示. 图7(a)中, 有很多小尺寸的logo, 仅有YOLOv4-RCA 算法可以检测到所有小尺寸logo 目标. 图7(b)中, logo 尺寸中等, 但目标聚集, 多个logo 之间距离接近, 容易产生混淆,YOLOv4-RCA 算法可以避免混淆, 将每个logo 单独检测出来, 并用非常准确的边界框框住. 图7(c)中, 大量logo 被遮挡, YOLOv4-RCA 算法可以检测出图中所有被严重遮挡的logo, 效果明显好于YOLOv3 和YOLOv4.通过对比分析得出结论, 尽管仍然存在一些漏检的情况, YOLOv4-RCA 在处理小目标、目标密集和遮挡等复杂场景时检测性能更好.

图7 3 种算法在FlickrLogos-32 数据集上的检测结果
3.5 消融实验
为了验证每个改进点对网络性能的优化作用, 本文进行了消融实验对比分析. 在FlickrLogos-32 数据集上的实验统计结果如表6 所示, 其中改进点1 和改进点2 分别对应用自适应残差块替代连续卷积和引入坐标注意力模块. 从表中可以看到, 使用残差块代替连续卷积, 仅牺牲了4%的FPS, 将mAP从87.18%提高到87.96%. 坐标注意力的引入仅牺牲了3%的FPS, 却将平均检测精度从87.18%提升到87.71%. 同时增加这两个改进在仅牺牲1.8% 速度的情况下, 将mAP从87.18%提高到88.09%, 取得了最好的效果, 这说明提出的方法在logo 检测中相对可靠. 通过分析表7 也可以在FlickrSportLogos-10 数据集上得到类似的结论.
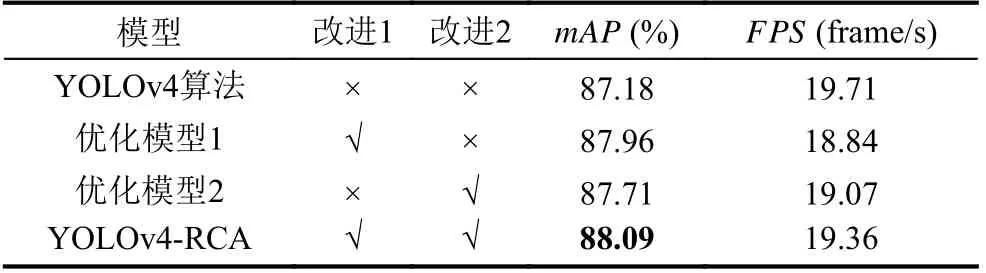
表6 FlickrLogos-32 数据集消融实验
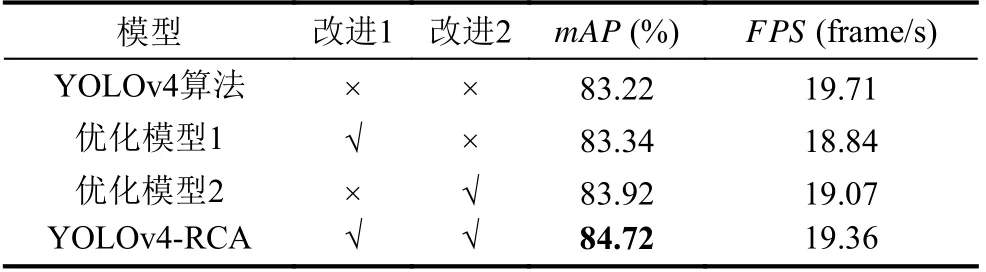
表7 FlickrSportLogos-10 数据集消融实验
4 结论与展望
针对logo 检测对小尺寸logo 检测效果差和对logo定位精度低的问题, 本文基于YOLOv4 提出改进的logo检测算法YOLOv4-RCA, 在特征融合阶段使用设计的自适应残差块替换5 个连续卷积层来有侧重地融合特征, 在增强浅层和深层特征利用的同时避免了特征的冗余, 增强了模型的特征融合和表达能力; 在自适应残差块之后引入坐标注意力机制通过精确的位置信息对通道关系和长期依赖性进行编码, 使用通道重要性和空间位置重要性来增强对于logo 检测更有用的特征;最后使用K-means++聚类算法重新选取对于数据集效果最佳的先验框. 实验结果表明, 改进的YOLOv4-RCA算法满足实时logo 检测的需求, 在FlickrLogos-32 和FlickrSportLogos-10 数据集上的平均精度分别提高了0.91%和1.40%, 同时提高了模型整体的定位精度和小尺度logo 的检测精度.
