利用时效规则恢复实验室嵌入式系统日志数据
2022-06-25谢容丽
谢容丽
(福建船政交通职业学院,福州 350000)
实验室嵌入式系统是当前比较热门的科学技术之一,主要用于管理和规划实验室。由于该系统具有成本低、可靠性高、系统内核小、专用性较强等优点,已经被广泛应用于多个领域中,例如工业控制、医疗仪器、通信等,并且在各大高校成立了专门的学科[1]。实验室嵌入式系统在运行一段时间后会存储大量的日志数据,由于其内核比较小,大量的囤积数据会影响实验室嵌入式系统的运行效果,出现系统延迟、卡顿现象[2]。该系统在设计开发时考虑到这一问题,为了保证系统能够长期有效运行,定期会对系统日志数据进行自动删除和销毁[3]。这样虽然可以确保实验室嵌入式系统运行质量,但是由于系统日志存有一些有价值和有用的数据,当实验室嵌入式系统用户没有及时对日志数据进行备份,系统将原有数据进行了删除,从而使系统日志有效数据丢失,该问题成为实验室嵌入式系统用户一大难题[4]。针对该问题,相关学者对实验室嵌入式系统日志数据恢复方法进行研究,并取得了一定的研究成果。目前,现有的方法虽然可以保证实验室嵌入式系统日志数据的时效性,但在实际应用中恢复的数据量较少,无法实现100%数据恢复。传统方法已经无法满足实验室嵌入式系统日志数据恢复需求,为此,提出基于时效规则的实验室嵌入式系统日志数据恢复方法。
1 实验室嵌入式系统日志数据恢复现状
目前用于实验室嵌入式系统日志数据恢复的方法主要有两大类:一类是基于机器学习的实验室嵌入式系统日志数据恢复方法,该方法利用机器学习算法对系统日志数据集进行聚类分析学习,并使用K邻近值算法为每一个自动删除的系统日志数据找到与其距离最近的邻居类,最后根据邻居类相关属性对系统自动删除的日志数据属性值进行替换,从而恢复实验室嵌入式系统日志数据[5]。基于机器学习的方法对日志数据的恢复是以相邻数据属性为根据,但是相邻数据与缺失数据的属性在本质上还是有区别的,因此,该方法所恢复的数据大部分与原有数据不同,且随着实验室嵌入式系统日志数据缺失率的增加,机器学习算法系统进行大规模的训练和学习,在数据恢复过程中难免会存在恢复误差,同时还会影响系统日志数据恢复速度,并不适用于大规模的实验室嵌入式系统日志数据恢复问题。第二类是基于人工智能的实验室嵌入式系统日志数据恢复方法,该方法主要应用人工智能算法将丢失的数据以矩阵的形式表示,利用矩阵对丢失数据进行计算,随机生成若干个初始解;然后采用关联算法通过交叉、变异等操作从初始解中寻找出最优解,从而得到一个实验室嵌入式系统日志数据相似的恢复数据集[6]。该方法虽然在计算过程上进行了精进,但是由于实验室嵌入式系统日志数据属性之间存在着复杂的非线性相关关系,人工智能算法在实际应用中难以寻找到最合适的目标函数,所以也很难恢复实验室嵌入式系统日志数据,且在实际应用中恢复的数据量与丢失的数据量不对等,无法实现最大比例的丢失日志数据恢复。
2 基于时效规则的实验室嵌入式系统日志数据恢复方法设计
2.1 实验室嵌入式系统日志数据定位
在对实验室嵌入式系统日志数据恢复之前,首先需要对丢失的数据进行定位,确定数据恢复对象,数据定位这一过程中主要完成的任务如下。
将实验室嵌入式系统日志物理地址编号进行排序,建立数据组blo存储各个日志物理地址编号,按照编号对建立的数据组从小到大排序。在此基础上再建立jsd数据组和dsm数据组用于存储实验室嵌入式系统日志对象头和页面编号[7]。内存映射管理器拦截来自上层应用程序的分配/解除分配请求,并通过连续块的预分配为其提供服务,每个块托管不同的二次幂大小的块。为每个模拟对象保留一个名为 malloc_area 的元数据表,用于识别已预先分配的内存块的虚拟地址,服务来自该对象的分配请求,并通过简洁的位图表示维护块内每个块的状态(忙或空闲),包括元数据表和预分配块的数量/大小的动态扩展机制。内存映射管理器通过将所有分配的块打包在一个连续的日志缓冲区中,以及在对象恢复的情况下将记录的块放回原位。为了启用增量日志记录,内存映射管理器已连续与编译/链接时检测工具(已针对 IA-32/x86-64 体系结构和 ELF 量身定制)集成,从而允许透明集成轻量级的更新操作跟踪机制。内存映射管理器仅将当前正在使用的注册模块打包在日志缓冲区中,并记录数据状态恢复时使用的元数据。
建立完成数据组之后,对实验室嵌入式系统日志数据进行正序遍历,从第一物理块开始遍历,读取每一个物理块中的日志对象头页面。当读取完一个物理块中日志对象头页面后,在所对应的数据组中记录日志对象头页面的文件名、创建时间以及更新时间等信息。当所有数据组遍历完成之后,再按照上述程序进行遍历[8]。当再次读取数据组信息时,如果发现读取的信息与上一次信息相同,则对该数据组跳过,不再进行信息记录。如果发现读取的信息与上一次信息不一致,则将该实验室嵌入式系统日志数据定义为丢失数据。通过读取的数据组信息之间的映射关系可以计算出丢失日志数据所对应的物理地址,其公式为
(1)
式中:s表示丢失的实验室嵌入式系统日志数据物理地址;k表示读取到的数据组中日志页面所在的逻辑地址号;a表示物理块内的页面数量;co表示日志页面所在的物理地址在物理块内的偏移量[9]。利用式(1)计算丢失的系统日志数据物理地址,并设置一个指针pdde,利用该指针对丢失日志数据物理地址进行拷贝,用于后续数据恢复。
2.2 提取实验室嵌入式系统日志数据状态时效规则
当定位到实验室嵌入式系统日志待恢复数据后,对丢失数据状态时效规则进行提取。数据的时效规则是指相同的一个实体在不同时间阶段内记录的数据属性会随着时间的推移表现出有规律性的特征,该特征为数据的时效规则。文中需要提取丢失数据的状态时效规则,假设关系数据库模式为T,表示为
T=(EID,A1,…,Ai).
(2)
式中:EID表示数据标识符,不同元组的相同数据标识符对应的是同一个数据;Ai表示数据第i个属性,假设数据属性的值域为domAi。在以上设定的关系中,将Ai值域dom中所有不重复值进行集合,定义为有限状态集合,用有向图G(V,E)表示实验室嵌入式系统日志数据时效规则的状态图[10]。在该关系上,属于同一个待恢复数据的两个元组分别有对应的属性值,且该两个元组的状态结点都在有向图G(V,E)上[11]。如果前一个元组比后一个元组新,则在有向图G(V,E)中,新的元组可以到达后一个元组,而后一个元组不可到达新的元组[12]。如果呈现该状态则表示为一条状态时效规则,对其进行提取,如果没有呈现该状态,则自动跳过,如此对实验室嵌入式系统日志数据状态时效规则进行提取。
2.3 基于时效规则的数据时序修复
数据的众多属性中时间属性最为重要,时间作为一个连续值,如果数据中时间属性丢失,则无法对其进行完整修复。因此,在提取到数据的状态时效规则之后,利用时效规则对实验室嵌入式系统日志数据进行恢复。假设实验室嵌入式系统日志数据的实现序列为e(1→2→3→…→n),1~n表示日志数据记录时间索引,按照时间先后顺序排列[13]。在此基础上通过时效规则匹配还原该数据,其过程如下:
第一步:以“1”为起始/终点穷举路径,将得到的路径集中到集合A中。
第二步:以“n”为起始/终点穷举路径,将得到的路径集中到集合B中。
第三步:分别计算出每个路径的支持度。支持度用于表示数据时效规则的强和弱,其计算公式为
(3)
式中:d表示数据时效规则的支持度;u表示满足时效规则的实体集合;x表示实体集合中的实体数量;w表示不满足时效规则的实体数量[14]。对集合A中的多个时效规则进行支持度检查,检查是否存在支持度为1的时效规则[15]。如果存在,将时效规则作为依赖条件的时间索引添加到后继的时效列表中。如果检验发现不存在支持度为1的时效规则,则依赖时效规则的时间索引的后继时效列表为空。
第四步:同样对集合B中的多个时效规则支持度进行检查。如果在该集合中存在强符合时效规则,则将时效规则前件时间索引添加到前驱的时效列表中。如果检验发现不存在支持度为1的时效规则,则时效规则前件时间索引的前驱时效列表为空。
第五步:对上两步中的前驱、后继时效列表进行处理。如果实验室嵌入式系统日志数据的后继时序列表为空,则可以确定该数据属性状态结点出度0是有向图G(V,E)的一个终点;如果实验室嵌入式系统日志数据属性的后继时序列表存在强符合时效规则,则按照状态时效规则的强和弱对数据属性进行排序。按照处理后的时序顺序对实验室嵌入式系统日志数据属性进行恢复,由此可以完成实验室嵌入式系统日志数据恢复,进而实现基于时效规则的实验室嵌入式系统日志数据恢复。
3 实验论证分析
以某实验室嵌入式系统为研究对象,该系统日志数据丢失率为20%~80%,每隔1 h就会自动删除实验室嵌入式系统日志数据。为了收集到系统丢失的数据,将系统日志某个数据项作为ground truth(真值),如果该数据项的MMU数据属性和AMU数据属性的数据记录被实验室嵌入式系统自动移除,则将其作为丢失数据。实验随机收集了500 MB丢失日志数据作为实验数据,利用文中设计方法与传统方法对该数据集进行恢复。本次实验环境为一台计算机,该计算机CPU配置为AMD Ryzen 8 1 500 K@4.25 GHz,计算机内存配置为16 GB,外存配置为128 GB,以Windows2010作为操作系统。实验分别进行单个数据恢复、多个数据恢复、多次修改后的数据恢复以及日志历史数据的恢复。以test名字建立一个文本文件,将恢复后的数据输入到该文件中,并利用LPP软件记录该实验室嵌入式系统日志数据恢复情况,表1为设计方法与传统方法数据恢复统计。
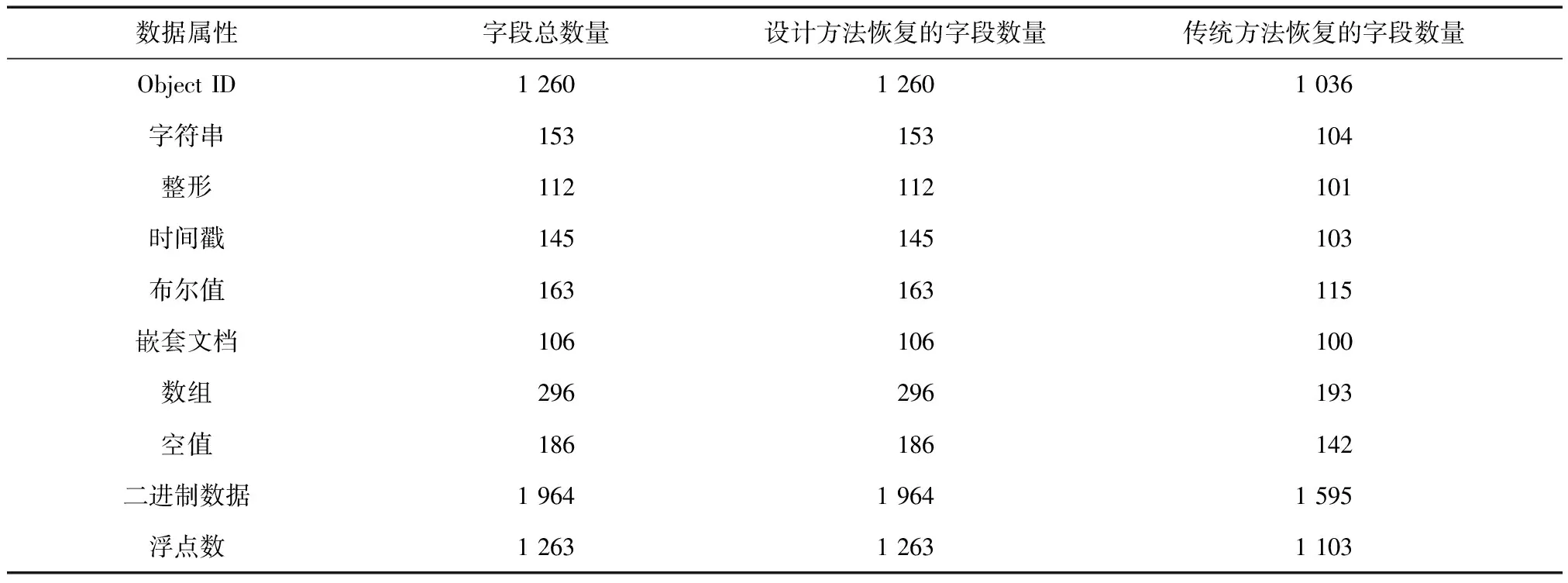
表1 两种方法数据恢复统计 个
实验又对两种方法数据恢复量进行了统计,并将其作为实验结果,如表2所示。

表2 两种方法数据恢复量对比
从表2中数据分析可以得出以下结论:文中设计方法数据恢复量比较大,且数据恢复率比较高,基本都在98%以上,说明设计方法可以基本将实验室嵌入式系统日志数据进行全面恢复。而传统方法随着数据丢失量的增加,数据恢复率呈下降趋势,最低达到62.8%,说明传统方法恢复的数据量有限,相比设计方法数据恢复性能较差。因此,实验证明了本设计方法可以实现实验室嵌入式系统日志数据有效恢复,在恢复量方面更优于传统方法,可以满足实验室嵌入式系统日志数据恢复的需求。
4 结束语
实验室嵌入式系统日志数据丢失问题日益严重,现有的恢复方法无法应对系统日志数据丢失的挑战,并且系统日志数据稀疏性和数据时间属性之间存在着复杂的相关关系。文中结合现有方法的不足,应用时效规则设计了一种面向实验室嵌入式系统日志数据恢复方法。该方法以时效分析确定丢失数据的时间属性,并通过数据重组实现了数据恢复。此次研究为基于时效规则的实验室嵌入式系统日志数据恢复方法实践提供了参考依据,同时也解决了实验室嵌入式系统日志数据丢失问题,对传统方法的优化与完善具有一定的现实意义。由于此次查阅的文献资料有限,设计的方法可能存在一些不足之处,有待今后在基于时效规则的实验室嵌入式系统日志数据恢复方法优化,以及实验室嵌入式系统日志数据恢复模型等方面进行进一步研究,为实验室嵌入式系统日志数据恢复提供理论支持。
