高速公路雨天通行安全评估及预警管理分析
2022-06-25刘军
刘 军
(中国电建集团北京勘测设计研究院有限公司,北京 100024)
0 前 言
雨天公路能见度低,驾驶员视野和视距受到影响,湿滑路面摩擦力降低,制动距有所增加,一旦遭遇突发情况,判断、反应和及时刹车控制能力大幅削弱,打滑、侧滑甚至追尾等交通事故极易发生。传统公路安全评估多以事故资料统计分析居多,存在事后评估不及时、预警性不足的弱点。而雨天公路安全状态事前评估,可对雨天行车风险进行预判和预警,及时形成安全管控方案,做出及时有效的交通安全组织,从而降低交通事故发生率,保障高速公路雨天行车安全,减少恶劣事故带来的人员、车辆和财产损失。
1 雨天高速路通行速率L-G预估模型
1.1 最大信息常数MIC特征分析
传统车流速率预估将速率作为单一特征开展预估,换言之就是通过已有的上个时间段速率预估当前或者未来时间段的速率。通过单一速率变量开展预估计算比较简单,但是预估精确度有时存在不理想情况,原因是车辆速率受多种要素共同影响[1-2],如交通事故、时间段及天气等。尤其在降水等恶劣天气的影响下,车辆速率变化波动性相对较大,降水强度等特征变量均会影响车辆速率。所以,对降水天气在高速公路出行的车辆速率开展预估时需考虑将多种影响要素作为模型输入,以增强预估精确度。但是如果把采集的气象、所有车流等数据均作为模型输入,反而会使模型计算变得复杂,并且易出现明显的过拟合现象,虽然在训练数据上能够较好地拟合,但是测试数据上的拟合效果欠佳[3-5]。因此,需选用科学方法获取与速率关联性强的变量作为模型输入特征,增强预估精确度的同时降低过拟合现象。
最大信息常数(以下简称:MIC)能够对非函数依托关系、非线性及变量间线性开展有效度量。速率及其影响要素间的关系不易经过一个单独函数开展表达,一般是多种函数进行叠加。MIC可以捕获各个变量间的关联,不局限于单一函数,所以通过MIC度量速率与其他变量关联性,能够有效获取其重要特征。MIC的计算过程能够简述为:根据数据样本把2个变量间的关系置于二维空间中进行离散,并通过散点图呈现;对散点图开展网络划分,依次求出各个划分尺度下互信息最大值,并对所有划分尺度下对应互信息最大值开展比较,选用最大值作为MIC值。互信息(以下简称:MI)表达2个变量共同具有的信息剂量,能够衡量两个变量间互相依托强弱程度。假设变量取值的集合V={(xi,yi),j=1,2,3,…,m},m是样本数量,MI(X;Y)是随机变量Y及X信息,能够通过式(1)计算获得。
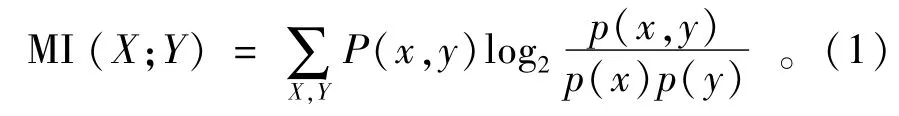
式中:p(x,y)为x、y联合概率密度;p(x)为量x的边缘概率密度;p(y)为y的边缘概率密度。
由网络划分原理以及公式(2)计算随机变量对应最大信息常数MIC(X:Y)。
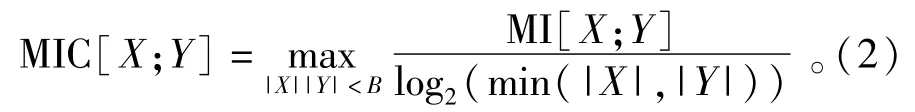
式中:|Y|系为利用网络划分把Y值域划分为|Y|段;|X|系为利用网络划分把变量X值域划分为|X|段;B系为网络划分时|X|×|Y|的上限值,B(m)=m0.6功效最好。
以某公路气象及车流数据为例,运用MIC对降水天气下速率预估模型输入特征开展选。其中,车流数据包含速率及车流量;气象数据包括风速、降水强度、能见度、湿度及温度。基于MIC度量速率与其他特征变量间的关联性,假设样本数据对应特征集合F={f1,f2,f3,…,fi},其中,f1~f6依次代表车流量、温度、湿度、能见度、降水强度及风速。计算任意特征fi以及速率vi对应最大信息常数MIC(fi,vi),取值区域是[0,1]。MIC(fi,vi)越大,显示fi与速率间的关联性越强,越凸显该特征的重要性;MIC(fi,vi)越小,显示fi与速率间的关联性越弱,那么该特征越容易被忽略。其他变量与速率的MIC计算结果及其排序见图1。

图1 特征变量MIC计算成果
结果揭示,降水天气下高速公路某时间段的能见度、降水强度及交通量与该时间段平均行车速率有显著关联性,同其他特征变量关联性相对较弱[6]。所以模型输入特征选取了能见度、降水强度及车流量。
1.2 L-G速率预估模型
为了实现LSTM神经网格以及GRU神经网格优势的综合利用,基于LSTM 及GRU构建预估模型,开展降水天气影响下高速公路行车速率的预估[7]。L-G模型结构见图2。
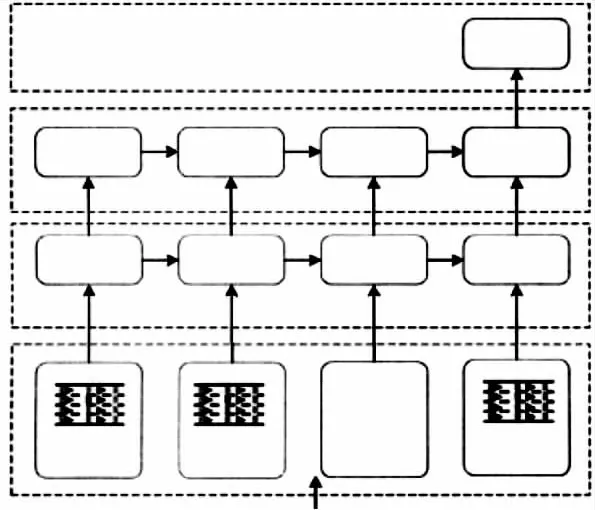
图2 L-G模型结构
该模型由两者深度学习结构结合而成:第一层是LSTM层,能够初步获取输入的特征信息;第二层是GRU层,能够二次获取上一层获取的特征,最终通过全接连层(Dense)开展线性融合获得预估时间段的速率预估值
L-G模型获取的输入变量是预估时间段t的前n个历史时间段的特征,通过输入矩阵可有如下表达:
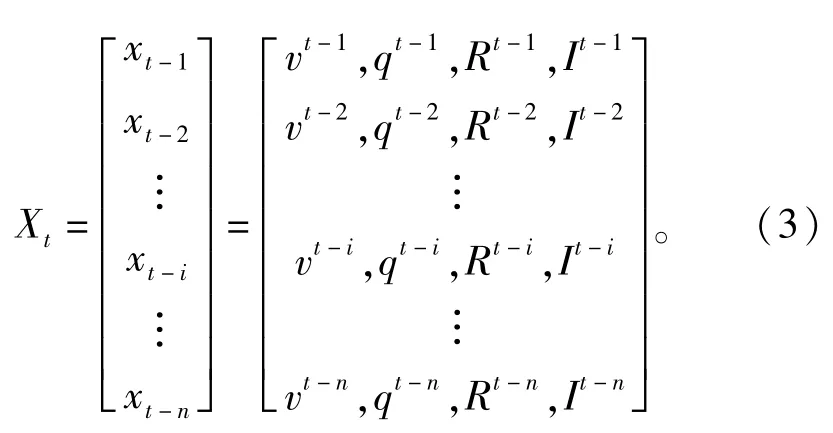
式中:vt-i为t-i时间段的速率;Rt-i为t-i时间段的降水强度;qt-i为t-i时间段的车流量;It-i为t-i时间段的能见度。
L-G模型训练目标设定为实际值Vt对应均方误差与最小化速率预估值^vt,见公式(4)。表达L2正则化项,可降低过拟合,λ是正则化常数。w表达模型中全部权重常数。
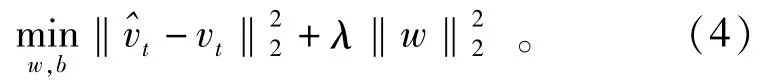
L-G预估模型的具体过程如下所述:
(1)样本数据选取雨天的气象及车流数据。把输入变量变为适当格式并开展预处理,通过最大、最小标准化公式把输入变量映射进[0,1];
(2)确定GRISTMILL双层深度学习相关的超参数以及神经网格的结构;
(3)选用历史训练数据和成果对L-G模型相关参数开展训练优化,并获得预估模型[8];
(4)通过测试数据及训练后的模型对降水条件下高速公路行车速率展开短时预估。
2 案例概况
案例高速公路是连通我国南北交通网络的大动脉,该线路G4段主线总长度大约294km。该路段设有交通调查设备站点总计48个,包括一类交调站点8个、二类交调站点40个;气象检测站点6个,包括能见度检测站4个,多因素检测站2个。基于案例高速公路气象检测站数据和交调站点测量数据,考虑一类交调设备多因素气象检测站数据丰富、数据准确性及完整性高等要素,选含一类交调站点及相对接近多因素气象检测站的代表性区段K1196+490m至K1198+400m作为降雨条件下高速公路行车安全评估及预警的分析对象。
案例路段包含121、122号车流测量器的区段(K1196+490m至K1198+400m),该车流测量器可测量不同种类车辆截面瞬时速率及车流量;多因素气象检测站(设备ID=38)能够检测风速、能见度、降水量、湿度、温度等气象参数。以2017年4月至2018年7月获得的车流和气象历史数据为支撑,对区段在降水条件下(2018年7月6日9:00至7月7日9:30)的高速公路行车安全情况开展事前评估和预警管理。
3 案例区段雨天速率预估
3.1 基于L-G深度学习模型的预估过程
3.1.1 描述数据样本
数据样本来源是2017年4月24日至2018年7月7日案例区段121、122号微波测量数据及气象检测数据。其中,车流数记录间隔是5min,气象数记录间隔是1min。为防止基于短时速率预估所得安全评估结果时效性较短,对车流数据和原始气象数据开展汇聚,调整数据记录间隔是15min。
通过L-G预估模型依次对121截面、122截面的货车及客车速率开展短时预估。筛选2017年4月24日至2018年7月5日该区段上行方向降水强度高出0的所有数据当作训练数据,总计37837条数据。选取2018年7月6日9:00至7月7日9:30连续降水天气的数据当作测试数据,总计99条。
3.1.2 L-G模型设置
根据前述输入特征选结果,把预估时间段前n个历史时间段的能见度I、降水强度R、交通量q及速率v作为模型输入变量,n是待定参数,表达时间窗长度,该参数影响模型预估精确度,将经过灵敏度分析并选取最优值。
以PC为试验平台,基于Python语言和Keras深度学习框架进行构建模型。L-G模型的部分超参数及优化算法设置如下:模型选用基于随机梯度降低算法的Adam优化器;训练迭代频次(epoch)设置为200;批大小(batchsize)是32;为了降低过拟合,将Dropout设置为0.5。隐藏层节点数是待定参数u,将经过灵敏度分析选取最优值。
3.1.3 分析待定参数灵敏度
针对待定参数u及n开展灵敏度分析过程中,为掌握L-G模型的预估功效,选均方根误差(以下简称:RMSE)、绝对百分误差方差(以下简称:VAPE)及平均绝对误差(以下简称:MAE)作为模型功效评价指标。VAPE能够对算法稳定性进行评价,MAE及RMSE能够对模型预估精确度进行评价,计算公式如下:

在隐藏层节点u及不同时间窗长度n取值组合情况下,L-G模型预估结果的RMSE和VAPE变化见图3。根据图3(a)发现时间窗长度的同时,伴随隐藏层节点增加RMSE对应变化趋势大体是:先加大后减小再加大。如果时间窗长度n=5,隐藏层节点u=64,此时预估结果RMSE有最小值,对应模型预估精确度最高。根据图3(b)能够发现,VAPE变化区域在5.5%~6.2%,显示时间窗长度变化及隐藏层节点数量对L-G预估模型稳定性的影响相对较小。如果时间窗长度n=5,隐藏层节点u=64,此时预估结果VAPE有最小值,对应模型预估稳定性最佳。综上所述,通过L-G模型开展速率短时预估时,时间窗长度及隐藏层节点数的最佳参数组合是u=64,n=5。

图3 L-G模型RMSE和VAPE变化
3.2 预估结果和比对分析
通过L-G模型依次对2018年7月6日9:00至7月7日9:30各时间段121截面及122截面的客货车平均速率开展预估。依次对不同预估模型的预估结果和输入特征选前后的模型预估结果开展比对及分析结果(见图4~7)。由图4~7揭示,在降水条件下的高速公路行驶时,货车和客车速率均十分不稳定,不同时间段速率变化和差异相对比较大,重点是受降水强度等天气变化的影响[9]。根据图中实际值及预估值对应变化曲线能够发现,预估曲线对应变化趋势同实际值曲线几乎始终保持一致,但是在速率实际值出现突变或者比较大波动的时间段,实际值与预估值误差相对比较大,其他时间段预估误差比较小。

图4 断面121客车速率预估与实际结果对比
3.3 特征选前后的预估结果比对分析
为进一步验证基于MIC输入特征选方法切实可行,通过所有特征变量(能见度、降水强度、温度、风速、湿度、车流量及速率)训练L-G模型并开展预估,然后同特征选后的L-G模型预估功效开展比对,如表1所示。
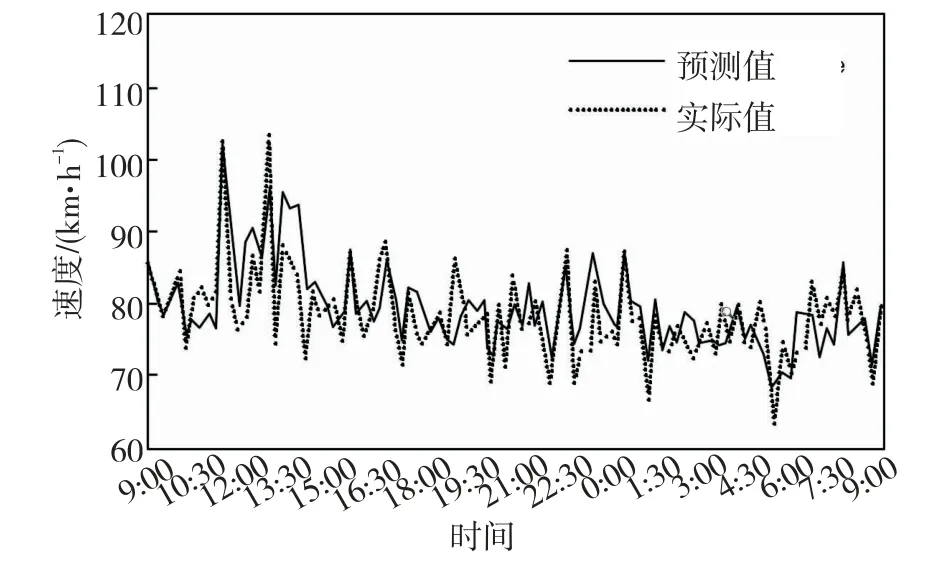
图5 断面121货车速率预估与实际结果对比
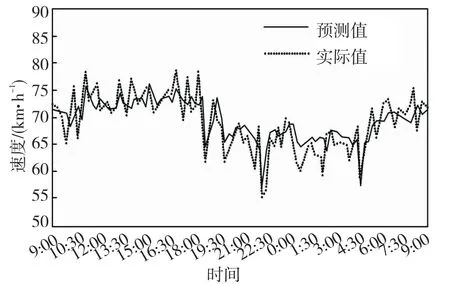
图6 断面122客车速率预估与实际结果对比

图7 断面122货车速率预估与实际结果对比

表1 特征选前后L-G模型预估功效对比
根据表1数据能够发现,特征选对训练误差影响相对较小,无论特征选是否开展,模型训练数据集对应的MAPE及RMSE均很小。而L-G模型将所有特征当作输入变量,对应测试数据集的MAPE及RMSE分别为13.80%及12.03km/h,相比于训练误差依次增加了11.42%及9.15km/h,由于存在非常明显的过拟合情况,也就是在测试数据上拟合功效不佳,训练数据上却拟合功效较好。针对特征选后的L-G模型,测试数据集的MAPE及RMSE依次是6.11%及6.60km/h,相比于特征选前,MAPE及RMSE依次减少了55.72%及45.14km/h,模型预估精确度有较大提升,与此同时,亦有效地减轻了过拟合现象。
4 结 语
本研究以案例路段(K1196+490m至K1190+400m)气象数据及车流为依据,对区段2018年7月6日9:00至7月7日9:30(降水天气)开展预警管理及事前安全评估。通过运用L-G预估模型依次对区段121、122截面的客货车速率开展预估,并进一步分析验证了降雨条件下基于速率预估的高速公路行车安全评估以及预警管理方法的可行性[10],有助于在雨天开展高速公路预警管理和安全评估工作。
