基于三种机器学习模型的太湖总氮浓度预测
2022-06-25桂峰兰柳后起
赵 朔,桂峰兰,柳后起
(1.辽宁省生态环境保护科技中心,沈阳 110161;2.中共辽宁省委党校,沈阳 110004;3.中国科学技术大学苏州高等研究院,江苏 苏州 215123)
0 引 言
市政污水处理厂出水是河流湖泊重要的外来污染排放源之一,对受纳水体的水质存在重要影响。当前,人类活动彻底改变了正常的氮循环,众多流域氮负荷显著增加,很多地区氮含量超过了地表水限值标准(1.0 mg/L)。非N2固定剂的大量使用,改变了湖泊营养收支和循环特征[1]。此外,在我国大规模和迅速改善废水处理是普遍采用措施(如市政污水出水标准的不断提高),但这种对受纳水体营养状况的影响很少在广泛的空间与时间尺度上得到验证。研究表明,我国东部的主要湖泊由于总氮和总磷浓度的不同变化显示出氮磷质量比增加,实际上湖泊氮磷质量比率的增加与城市污水处理的快速改善有关[2]。作为水体富营养化主要营养盐,氮已成为影响太湖东部大多数站点水质的主要因素[3],研究太湖氮浓度对于太湖水质监测与评价水体富营养化尤为重要。水质预测主要有机理性和非机理性两种,由于水环境的多因子、多介质的特性,常规的机理性水质模型如Streeter-Phelps(S-P)一维稳态氧平衡模型[4],WASP 富营养化模型[5],SWAT 水质预测模型等[6],这些方法多需要复杂的边界条件和大量完善的监测资料而难以推广应用,而非机理模型则是利用数学的方法进行模拟,将影响因子作为输入变量,被预测的指标作为输出变量进行分析同时又可以进行特征分析以评估影响因子的相关重要程度。如胡志洋[7]等利用BP 神经网络模型对太湖梅梁湾区域的叶绿素a 浓度进行预测,成浩科[8]等利用随机森立的方法对淮河流域河流总磷浓度进行预测,付泰然等[9]利用自编码式BP神经网络对养殖水体的亚硝态氮进行预测,李修竹等[10]人利用支持向量机的方法对长江口岸的叶绿素a浓度进行预测。这种水质预测模型具有自适应性强、容错率高等优点,此外也有着较高的预测精度[7],在水质预测应用的同时还能有效确定各项影响指标的重要性关系。因此,本文基于2007-2015年期间太湖水体八个监测站点的月度水质监测数据,首先借助皮尔逊相关系数分析市政污水处理厂各项运行指标与太湖水体总氮浓度的相关性以确定5项主要的影响因素,再结合16种太湖水质监测指标输入到三种机器学习模型(决策树,KNN 和AdaBoost)中对太湖流域总氮浓度进行预测。此外,从预测效果较好的模型中输出了5 项重要性特征以揭示太湖总氮浓度的重要影响因素。
1 数据与方法
1.1 数据来源
公开的数据集来自太湖水域的8 个常规监测站(图1),数据集的时间跨度为2007年至2015年[9],记录频率为每月一次。数据集主要包括透明度、pH,水深,水温,水位,电导率等指标,以及总磷(TP)、总氮(TN)、硝态氮(NO3-N)、亚硝酸盐氮(NO2-N)、氨氮(NH3-N)、溶解氧(DO)等10个浓度指标。
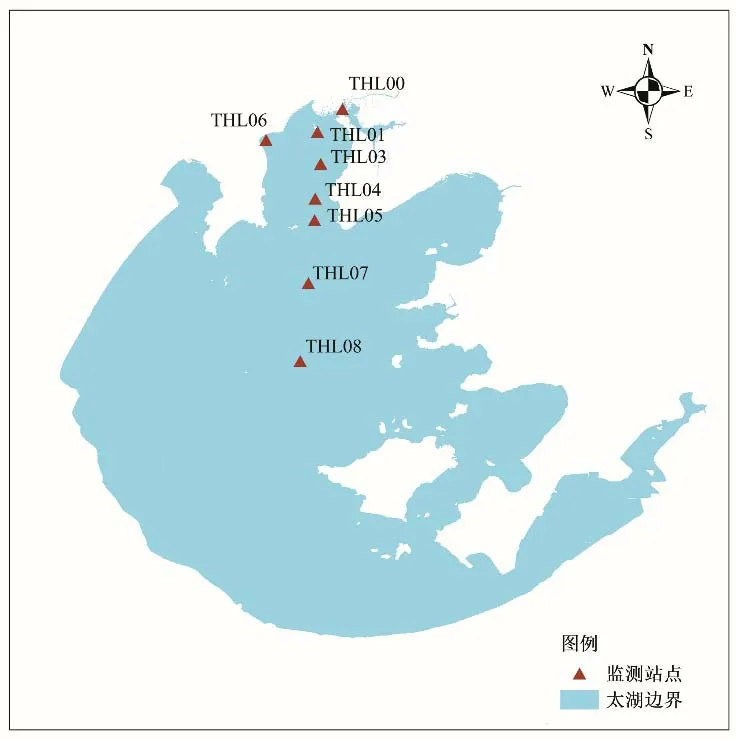
图1 太湖水质监测站点分布[11]Fig.1 Distribution of water quality monitoring stations in Taihu Lake
此外,收集了江苏和浙江等212 个太湖流域市政污水处理厂运行数据,时间跨度为2007年至2015年,频率为每月一次,主要指标包括污水处理量、进水量、出水量、污泥产量等10个质量信息指标以及进出水COD、氨氮、总氮、总磷、悬浮物等12 个浓度信息指标,共计22项指标。
1.2 基于皮尔逊相关系数法的指标筛选
皮尔逊相关系数本质为一种线性相关系数,相关系数的绝对值越大表明相关性越强。相关性系数越接近1 或者-1,相关度越强。越趋向于0,相关度越弱,我们首先评估了市政污水处理厂22项运行指标与太湖流域总氮的相关性。
步骤1 数据初始无量纲化。由于不同的监测数据量纲不同,在皮尔逊系数分析前对水质监测数据进行无量纲化处理,具体计算公式为:
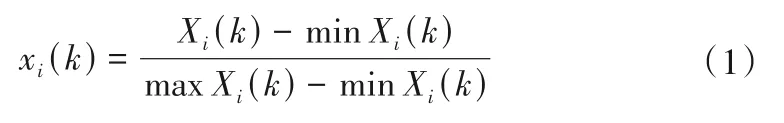
式中:i为不同的监测指标类别;k为不同类别对应的数据点。
步骤2计算离均差平方与离均差积和。
变量X的离均差平方和为:
变量Y的离均差平方和为:

X与Y的离均差积和为:
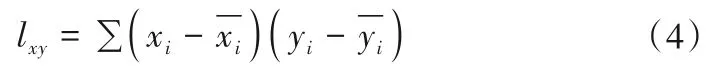
步骤3计算两个变量之间的皮尔逊相关系数,计算公式为:

按照上述步计算两个变量之间的皮尔逊相关系数并对相关系数进行排序。
1.3 决策树原理
决策树(decision tree)是一类常见的、较为简单的机器学习方法,其目的是根据损失函数最小化的原则产生一棵泛化能力强,处理未见示例能力强的决策树[12]。决策树方法具有易于理解和实现、分类规则简单符合人类思维方式等特点,研究人员已将其广泛应用于地震预警[13]、震后损失评估、地质灾害评价[14]等诸多防震减灾领域。决策树在处理大样本数据时存在易过拟合、对连续性字段较难预测等问题。现有的决策树学习主要包含ID3算法,C4.5算法以及CART算法。
1.4 KNN模型原理
k 近邻法(k-nearest neighbor,k-NN)是1967年由Cover T和Hart P 提出的一种基本分类与回归方法[15]。基本概念为:存在一个样本数据集合,所有特征属性已知,并且样本集中每个对象都已知所属分类。对未知分类的待测对象,将待测对象的每个特征属性与样本集中数据对应的特征属性进行比较,然后计算提取样本最相似对象(最近邻)的分类标签。一般只选择样本数据集中前k个最相似的对象数据,最后根据k个数据的特征和属性判断待测数据的分类。
1.5 AdaBoost模型原理
AdaBoost 是一种迭代算法,核心思想是针对同一个训练集训练不同的分类器,即弱分类器,然后把这些弱分类器进行集合,构造一个更强的最终分类器[16]。算法本身是通过改变数据分布来实现,它根据每次训练集中的每个样本的分类是否正确,以及上次的总体分类的准确率来确定每个样本的权值。将修改权值后的新数据传至下层分类器进行训练,然后将每次训练得到的分类器融合起来作为最后的决策分类器。AdaBoost是一种具有高精度、操作简便的分类器,不用考虑特征筛选和过拟合等问题。
步骤1输入训练集D={(x1,y1),(x2,y2),(x3,y3),…,(xm,ym)},其中xi∈X X:训练样本集合,yi∈Y={-1,1};采用弱学习算法WeakLearn;迭代训练轮数N。初始化过程中令每个样本的初始权值为:

步骤2迭代开始,并给予当前分布Dn调用WeakLearn,得到弱分离器hn:

计算弱分离器hn在当前分布下的错误率:
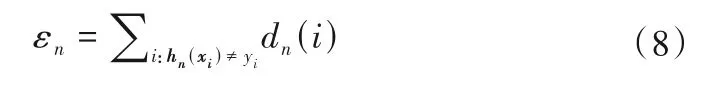
在迭代计算过程中,如果εn>0.5,则令N=n-1,同时终止迭代。
步骤3结合结果计算分类器hn在最终分类器集合中的加权系数:
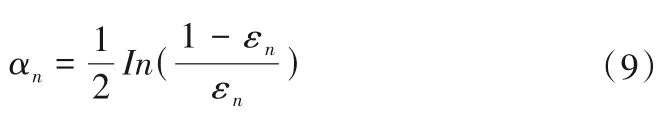
同时更新样本分布:
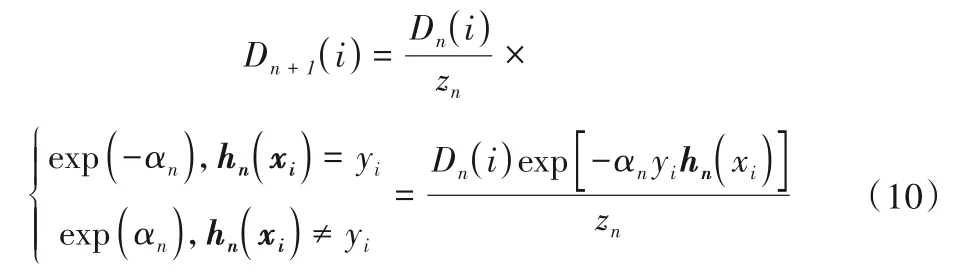
步骤4计算结果合并到模型输出函数结果:
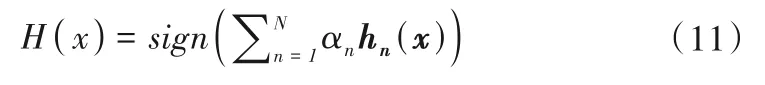
1.6 模型评价指标
本次评价指标主要包括拟合优度(R2)和均方误差(RMSE)以及平均百分比误差(MAPE)。本次模型主要基于Python 中的sklearn库来实现。
拟合优度R2是指回归方程对观测值的拟合程度。度量拟合优度的统计量是判定系数R2。R2的取值范围是[0,1]。R2的值越接近1,说明回归方程对观测值的拟合程度越好;反之则表明回归方程对观测值的拟合程度越差,即:
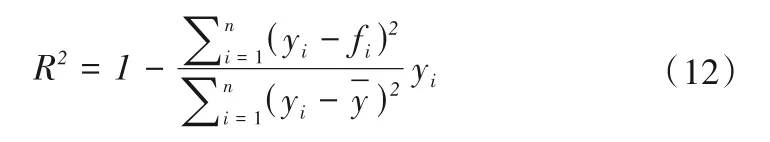
RMSE是均方根误差,指预测值与真实值偏差的平方和与观察次数比值的平方根,用来衡量预测值同观察值之间的偏差程度,即:
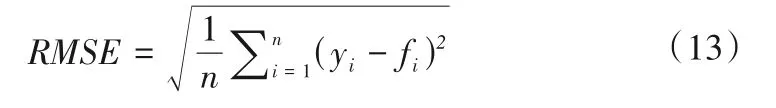
MAPE是平均百分比误差,是误差与原始数据值相比较的过程,结果越趋向于0 则为完美模型,大于100%则为劣质模型。即:
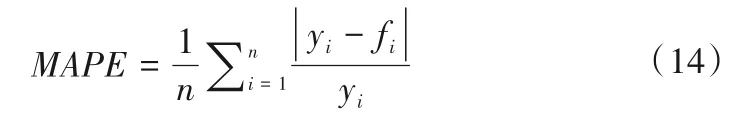
式中:yi为真实值;fi为预测值。
2 结果与分析
2.1 皮尔逊系数相关性结果分析
利用市政污水处理厂的22 项运行指标与太湖流域总氮浓度进行皮尔逊相关性分析,选取其中相关性较大的5 项指标。皮尔逊系数的相关性绝对值直接体现了影响因素与结果之间的关联程度,其绝对值越接近于1 表明指标间相关性越强。根据皮尔逊系数计算步骤分析了太湖水体总氮浓度与市政污水处理厂各出水排放指标的相关性,结果见表1。
由表1可知,经相关性分析后,市政污水处理厂出水氨氮浓度,污水排放总量,以及进出水总氮浓度与太湖总氮浓度有显著的影响,同时进水的BOD,COD,SS,以及总磷浓度有着较弱的相关性。因此,选取了污水处理厂的进出水的总氮浓度,氨氮浓度以及污水处理量等五项(表1)作为输入变量的一部分。
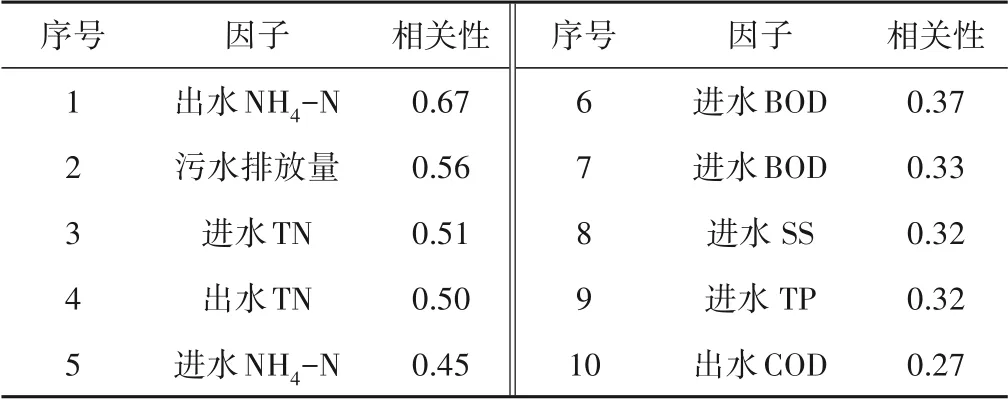
表1 皮尔逊系数相关性结果Tab.1 The result of Pearson coefficient analysis
市政污水处理厂运行指标与太湖水体总氮相关性较高的主要原因是市政污水处理厂的尾水排放是太湖N 输入的重要来源之一,实际上,环太湖流域的市政污水处理厂最早开始严格执行《城镇污水处理厂污染物排放标准》中的一级A 标准[17]。尽管如此,一级A 标准所规定的主要污染物的排放标准仍远远高于地表水V 类水要求的各项指标,例如一级A 标准中规定的总氮浓度是地表水V 类水体规定中的7.5 倍,氨氮浓度是其2.5倍。因此,尽管市政污水处理厂的出水排放严格达到了1 级A标准,却仍然是湖,库水体的富营养物质的重要污染源[18]。此外,污水排放的总氮和氨氮是影响太湖水体总氮浓度的直接因素,这也是市政污水中氨氮和总氮的相关指标高于其他指标(例如COD、BOD)的主要原因。
2.2 三种机器学习模型构建
2.2.1 模型训练
依据上述皮尔逊结果,模型输入变量为从污水处理厂选取的五项指标以及太湖的水质监测数据集,输出为太湖水体的8个站点的月度均值总氮浓度。采用将随机选取80%的数据量为训练数据集,20%作为测试数据集,同时利用临近算法(KNN)和决策树以及AdaBoost 三种模型进行训练。实验采用Python编程语言实现算法。
2.2.2 模型训练与测试结果
利用已经训练好的模型对测试集数据值进行测试,三种机器模型的实测值与预测值对比如图2,模型的性能指标结果见表2。
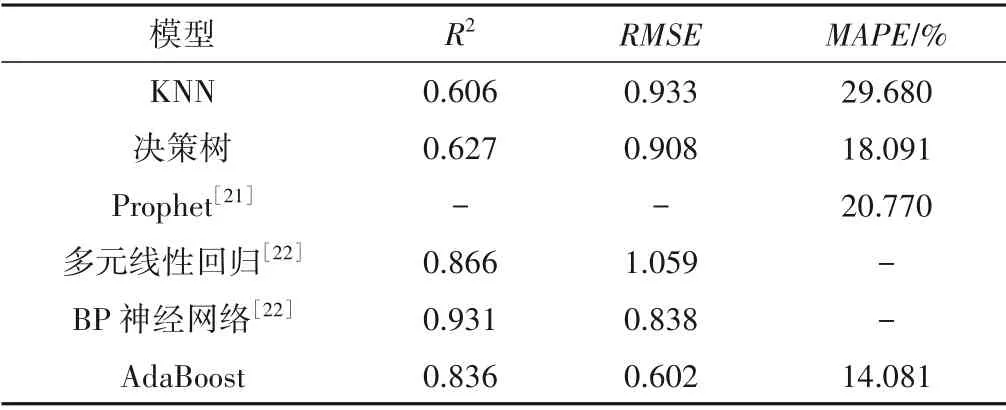
表2 模型输出结果Tab.2 performances of all Methods
由图2可知,相较于KNN 和决策树,AdaBoost 模型更好的反映了太湖总氮浓度的变化趋势,其平均百分比误差为14.081%,而KNN整体预测结果较为平缓,与实际浓度变化情况相差较大,有着最大的平均百分比误差29.680%,模型准确度远远低于其他两种模型。此外,AdaBoost 模型拟合优度(R2)达到0.836,表明模型更好地拟合了太湖总氮浓度变化情况。整体来看,相较于传统的机器学习模型KNN 和决策树,AdaBoost 模型可以更准确地预测市政污水处理厂出水排放对太湖流域氮浓度的影响。在特征种类和特征数目一定的情况下,由多种算法组成的集成学习有着更加明显的优势,不论是大尺度的地表水质预测[19],或者是河流水质预测[20],长江断面水质预测等[21],集成学习模型均具有更好的预测准确度和较低的拟合误差,模型预测效果得到了极大的提升。
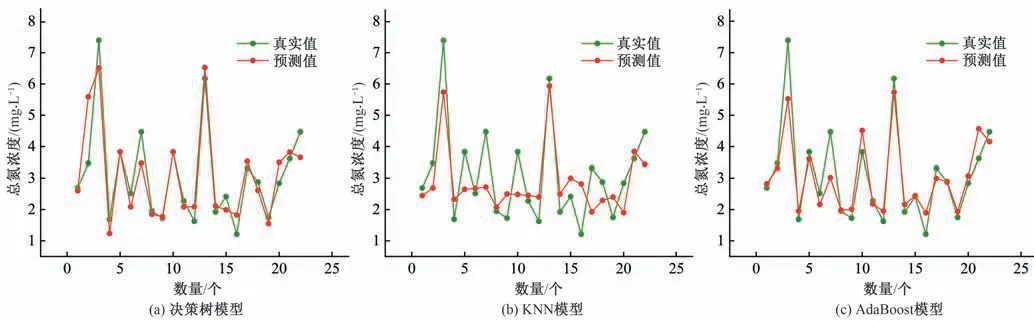
图2 模型决策树(Decision Tree Regressor),KNN和AdaBoost的训练输出与监测值的对比Fig.2 Comparison between and measured values of TN and predicted values of DTR,KNN and AdaBoost Model.
从同类型的总氮浓度预测模型横向对比来看(表2),BP 神经网络有着最高的拟合优度(R2),这主要是由于神经网络具有高度的非线性,可以更好拟合非线性关系,以及反向传播机制可以不断将误差反传回来以调整网络来修改各层神经元的权值直至达到期望目标[22]。而AdaBoost 有着最低的平均绝对误差和均方根误差,在回归预测类问题上具有更小的误差,体现出更高的预测准确度,明显优于其他模型。相比于最好的BP神经网络,RMSE数值也由0.838下降至0.832。
2.2.3 模型重要性特征提取
对于输入的综合指标(5 个相关性较高的市政污水处理厂相关指标以及16 项太湖水质监测指标),分别从结果较好的决策树和AdaBoost 模型中提取了前5 个相关性特征指标(图3),相关性特征对模型预测结果有重要影响的特征,因此输出并分析了前5个重要特征。
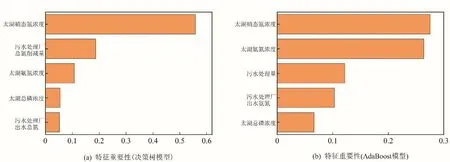
图3 模型的前5个重要特征Fig.3 The importance of the top 5 important features
结果表明太湖自身氮负荷(太湖水体硝态氮浓度和氨氮浓度)是影响太湖总氮浓度的重要特征,这在决策树和AdaBoost模型中均得到了体现。尤其在决策树模型中,硝态氮浓度这一指标的重要性远远大于其他特征,在AdaBoost 模型中两者也明显高于其他特征。说明太湖水体自身氮负荷对总氮浓度变化有着更显著的影响。在一些空间回归预测模型中也有类似的研究结论,水体自身的氮负荷是影响总氮浓度的显著因素[23],然而鉴于我们模型的输入数据的局限性,模型无法注意到土地类型,人口密度和土壤径流等影响因素[23]。值得关注的是,太湖中磷负荷对总氮也有一定的影响。这可能是由于水体的生物对氮磷富营养物质的同时利用所致[24]。
此外,太湖同时接受来自市政污水处理厂的点源污染,而这些重要的点源污染也是重要的N 负荷来源之一[23]。机器学习模型也考虑到了来自于市政污水的处理体积(AdaBoost,第三位)和出水氨氮的浓度(AdaBoost,第四位)是重要的影响特征指标。这说明市政污水处理厂出水氨氮是太湖流域重要的氮负荷来源[18],同时市政污水处理厂的排放水量也是重要的影响因素。由于在当前出水水质不断提高达到1 级A 后,市政污水处理厂尾水浓度也依然远高于地表水V 类标准。同时日益增加的尾水排放量,使得排入太湖水体的N 质量并没有明显减少,其绝对质量有增加趋势[25]。整体来看,对于太湖流域总氮浓度影响最大的是太湖自身水体的氮负荷,此外是外N 源的输入,如市政污水处理厂尾水中的氨氮等。
3 结 论
(1)本研究利用KNN、决策树和AdaBoost 三种机器学习模型分析了太湖水质的相关因素。三种模型中决策树模型的均方根误差和平均百分比误差分别比KNN降低2.68%和39.05%。而AdaBoost 可以将RMSE和MAPE更进一步降低且呈现更好的拟合优度(约0.80),为高精度的水质预测提供借鉴。
(2)模型特征重要性分析表明,对太湖流域总氮浓度影响最大的是太湖自身水体的硝态氮以及氨氮浓度,其次是污水排放的相关指标,如处理水量,出水氨氮浓度等。因此,为有效控制太湖氮浓度,既要控制污水处理厂出水氮浓度相关指标(氨氮,总氮等),也要对市政污水排放量加以控制。
(3)为了控制或降低太湖流域总氮浓度,首先需要控制太湖水体自身的总氮浓度(硝态氮以及氨氮浓度),并需要减少氨氮的外源排入。
