基于相似样本特征提取的装备性能退化研究
2022-06-25张东东艾小川
张东东, 艾小川,*, 刘 畅
(1. 海军工程大学基础部, 湖北 武汉 430033; 2. 海军工程大学管理工程与装备经济系, 湖北 武汉 430033)
0 引 言
高新技术的发展引领着装备向高密封性、高安全性方向发展,工厂生产中,各类功能不同、质量不同的装备构成一个完整的装备生产系统。现阶段,对于装备系统中的各类装备的生产状态的判断是由在线监控预警系统完成的。监控设备定时采集各个子装备的实时性能参数,在线预警系统根据实时数据和历史样本数据及时对短时间内装备的性能情况做出预测,判断装备短时间内是否会出现故障风险,从而实现预维护的目的。
工程实际上,实时状态数据所包含的信息冗杂且多噪声,为了增加预测的准确性,提取更多有价值的信息,其性能退化研究多建立在历史样本数据上。然而历史数据来源广泛,不同样本的历史数据存在采集时间不同、数据长短不一等问题,过去的相关研究把状态数据视作理想的完美数据,忽略了数据不规范对研究的影响。
目前,基于实时数据的性能退化研究主要是使用数据驱动手段进行的,其性能退化研究主要涉及指标构建和时间序列预测问题,其中指标构建主要通过对高维数据的去噪和降维完成,常见的降维方法包括经典的降维方法和机器学习方法,经典降维手段包括主成分分析、局部线性嵌入等;机器学习方法的核心手段为神经网络。目前的指标构建手段多为对高维状态数据直接去噪和降维,无法充分体现退化的状态数据的时序性,且由于性能指标序列无法呈现单一的规律性,性能退化预测问题仍是研究中的侧重点。
针对目前装备性能退化研究中的难点,本文兼顾历史样本数据信息冗杂、数据不规范、性能变化不规律等问题,提出了一整套的研究方法和思路。该方法通过对历史样本数据进行规整,得到研究所用的规范数据,基于自组织映射(self-organizing maps, SOM)算法对相似样本集的相似样本特征进行提取,并利用堆栈自编码器(stacked autoencoder, SAE)对相似样本特征进行降噪和重构,根据最小特征圆法建立性能退化指标,最后采用了双指数模型对性能指标进行处理,得到了测试样本的性能退化轨迹。
1 样本数据预处理
复杂装备系统的性能退化指标构建涉及多参数多样本时间序列的处理问题,装备系统中同类传感器不同子系统及不同传感器记录的数据对应着时间序列中的不同参数,而每一个样本的状态数据对应着一个高维时间序列,由于样本的状态数据来源广泛,数据采集的时间点较难规范,故在性能指标构建之前需要对数据进行规整化处理。
1.1 时间标准化
单个装备系统的各个传感器一般在相同的时刻点采集数据,在线系统会设置间隔相同的时间进行数据采集,本文的数据规整主要考虑历史样本数据存在的数据采集时间间隔不规范问题。
假设已有个样本的状态数据,数据源自不同工厂的同一时期的装备,数据采集时间间隔不完全相等,为了尽量减少数据规整带来的误差,采用基于K-means聚类的方法来选择规整数据后的时间间隔,对数据采集时间间隔进行聚类,优选合理的聚类中心作为数据规整后的样本时间间隔。数据规整流程如图1所示。

图1 数据规整流程Fig.1 Data alignment process
本文使用的插值方法为B样条插值,B样条插值具有较好的收敛性、稳定性和光滑性,相比分段线性插值,在节点处可导,更加光滑,次样条曲线表达式为
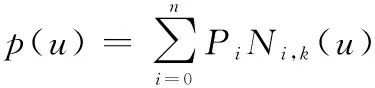
(1)
式中:,()为次B样条基函数,其求解方法由Cox-de Boor递归公式决定;为第+1个控制点。3次B样条插值已经具有了完美的拟合原数据分布的能力,且高次插值会增加计算难度,故选择3次B样条插值进行数据规整。
这样,综合考虑了样本的状态数据采集时刻点的分布特点,利用插值的方法使得每一个样本的规整后数据拥有相同的时间间隔,能够较好地保持原样本数据的分布特性,便于之后的降维运算,之后对装备系统性能退化轨迹建模所涉及到的状态数据均为规整后的新数据集。
1.2 多维时间序列的相似性匹配
多维时间序列匹配为相关领域较为麻烦的问题,其复杂度和准确度对之后结果会产生较大的影响。为了消除大样本数据对于单个样本的随机性差异不敏感的问题,本文利用一种基于大间隔最近邻(large margin nearest neighbor, LMNN)和动态时间规整(dynamic time warping, DTW)的多维时间序列相似性匹配的方法对样本空间进行筛选,优选出与测试样本相似的序列。
对于样本集中任意两个多维的时间序列和,=(,,…,),=(,,…,),其中(1≤≤)和(1≤≤)都是维列向量,表示样本的某一时刻的参数值,则和之间的距离用马氏距离定义为
(,)=(-)(-), 1≤≤;1≤≤
(2)
式中:为一个对称半正定矩阵,称为马氏矩阵,通过LMNN学习得到。这样,定义完多维时间序列的局部距离后,其最优规整路径通过如下动态规划问题解得
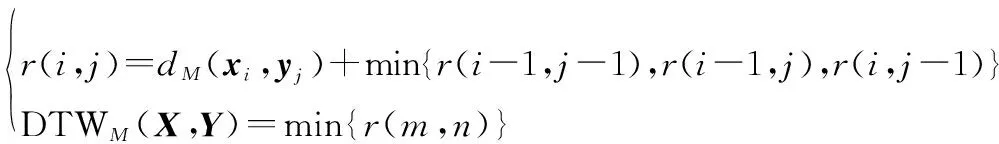
(3)
假设样本集为,测试样本为,在进行相似性匹配之前需要对数据进行区间切割处理,由于所研究装备系统为同类型装备系统,故可认为在相近的时间内不同样本的相似程度更高。若测试样本的时间区间为[,],对样本集中的单个样本的状态序列进行时间区间切割,保留在[-,+]之间的数据,再进行匹配,匹配后的相似样本集记作。
2 性能退化模型的构建
2.1 相似样本特征提取
基于SOM的相似样本集的样本特征提取,是利用其良好的保拓扑能力,通过对相似样本集进行无监督学习获得胜出神经元的权值矢量,此时的获胜神经元的权值矢量能够代表相似样本集的总体相似样本特征。


(4)
欧式距离最小的权值对应的神经元为获胜神经元,通过不断输入重组后状态的列向量,对权值和邻域不断更新,当重组后的单个状态数据的列向量训练完毕后代表一次完整的迭代结束,最后获胜神经元的权重代表此时刻的样本特征。
2.2 时序特征度量
2.2.1 特征降噪
利用SOM算法进行相似样本训练,提取到的是相似样本集的样本特征信息,得到的仍是高维时序序列,在度量其时序性特点之前,仍需要进一步对处理后的状态数据进行降噪和去冗余操作。
SAE通常包含多个自编码器,类似于深度置信网络的训练法则,采用逐层贪婪训练单个自编码器的方法,将单个自编码器进行单独训练寻优,把抽象的特征作为下一个自编码器的输入,在获得更抽象的输出的同时降低了运算复杂程度,尤其适合处理复杂数据的深层特征提取问题。
图2为典型的堆栈自编码器原理示意图,第一层为降噪自编码器,状态数据向量=经过降噪自编码器(denosing autoencoder, DAE)过滤,利用逐层贪婪训练方法进行训练学习,将得到的抽象特征向量输入第二层的稀疏自编码器进行训练,最终得到稀疏特征=(,,…,)。

图2 SAE示意图Fig.2 SAE schematic
2.2.2 指标建立
利用SOM和堆栈自编码器的状态数据进行训练操作,可以提取装备在具体时刻的性能特征,需要进一步对特征处理变成具体的性能指标,并将时序变化特征融入其中。性能指标的建立一直是本文方法中的重点,良好的性能指标应该要能够反映产品的退化趋势,过滤掉一些次要的因素,也要能反映出装备在退化时产生的性能波动,由此,本文建立一类基于最小特征圆的指标方法。
假设装备系统刚开始时处于较为稳定的状态,可以认为是健康状态,随着时间推移,装备会慢慢发生退化,偏离健康状态。故对上述训练得到的特征变量{},提取出正常运行时的特征集合,利用聚类分析得到中心特征,并以此为圆心作一个高维最小圆,将所有健康特征包裹在内。三维最小特征圆示意图如图3所示。

图3 三维最小特征圆示意图Fig.3 Three dimensional minimum characteristic circle diagram
由于装备正常运行时会存在正常的数据波动,故可假设此最小圆内的特征为健康特征,故第时刻的性能指标为

(5)
基于最小特征圆法可以将SAE提取的退化特征转化为具体的性能指标,但得到的一维时序数据存在随机性因素的干扰,数据仍然存在大量噪声,需要选择合适的时序数据拟合和预测算法对装备的性能退化规律和寿命进行预测。
2.3 性能退化轨迹拟合与寿命预测
2.3.1 退化轨迹预测
复杂装备系统的性能变迁受到多种复杂因素的共同影响,其性能变化轨迹无法呈现单一的规律性,且性能指标的变化包含大量的噪声。为了描述和预测性能指标的退化过程,采用动态的双指数模型来处理得到的性能指标,双指数模型广泛应用于多类型时间序列的拟合和预测问题,在金融、医疗等领域发挥了重要作用。
根据上文构建的性能退化指标,动态双曲线模型可以表示为
=1,·exp(1,·)+2,·exp(2,·)+
(6)
其中,1,,2,和1,,2,为时刻的状态参数,由于本文的指标序列为非规律变化的信号,此处默认为1,≠2,,为时刻的噪声。在大数据条件下,拟合误差一般均服从正态分布,且时间序列具有时序相关性,可构造状态参数空间如下:

(7)
故本文对于退化轨迹的拟合和预测问题可以等同为一个由上述状态空间描述的动态系统,此系统的状态转移方程可以概括为

(8)

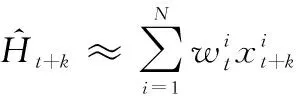
(9)
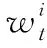
232 阈值设置
对复杂装备系统进行性能退化研究需要对系统的故障时间和指标阈值进行估计和选择,本文研究装备的退化规律主要是基于相似样本进行的,每一个相似样本对应一个故障时间和状态数据,将这些数据信息输入到SAE可以计算得到一个阈值集合,设置该集合为{,,…,}。
本文基于高维时序数据的相似样本选取得到了基于马氏距离的相似度,对于同一个测试样本,将相似度等比例缩小,且相似度之和为1,此测试样本的退化阈值由下面的表达式给出:
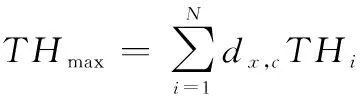
(10)
式中:,为相似样本集中样本与测试样本的相似度。
3 案例计算
3.1 数据说明
本文对某大型自动高压加热装备系统进行仿真,主要数据采集包括温度、锅内压力、出气口压力、涡轮转速等26项参数,数据采集时装备均处于运行状态,总随机因素主要考虑了电流冲击、温度、材料腐蚀,以及各项参数对应子系统中存在的环境因素,采集时间间隔均不相同,共采集了70个全寿命样本数据,另随机选取3个测试样本,测试样本均采集了前120个数据,为了体现个体差异,测试样本的初始监测时刻时间间隔较大,由于不同参数间数据差别较大,故模型训练前对原始数据进行了归一化处理。
3.2 模型训练与指标建立
(1) 数据预处理。根据本文的数据规整原则,对73个样本数据进行重建,对73个样本数据的采集时间间隔的聚类结果如图4所示。

图4 采集时间间隔聚类结果图Fig.4 Collecting time interval clustering result
73个样本数据共得到3个聚类中心,从小到大3个类别含样本数分别为13、40和20,故本文采取位于中间类别的聚类中心作为数据规整后的时间间隔,初始采集时间间隔为6.22 h,利用B样条插值即可得到规整后的新数据集。
(2) 相似性匹配。基于B样条插值得到73个样本的新状态数据集,在衡量样本数据间的相似度之前,对70个历史样本数据进行截断处理,仅保留前130个样本数据,设置相似阈值即最大相似距离为20。3个测试样本分别编号c -1、c -2、c -3,c -1共选取了23个相似样本,c -2共选取了19个相似样本,c -3选取了28个相似样本,将得到的3个测试样本集分别输入SOM网络,提取相似样本集的相似样本特征。
(3) 退化特征提取与重构。本文采用的SAE共存在3层,一层降噪自编码器,两层稀疏自编码,SAE的3个隐藏层分别有18、16、12个神经元,DAE采用Srivastava等人提出的Dropout技术来完成加噪过程,稀疏自编码器L2正则化权重衰减稀疏为0.000 1,稀疏性惩罚权重因子均为4,稀疏性系数为0.05。将3个测试样本的相似样本特征数据集依次输入训练,得到了3个12维的时间特征序列。3个测试样本部分退化特征如图5所示。


图5 测试样本部分退化特征Fig.5 Partial degeneration of the test sample
图5为经过SAE重构后的部分抽象退化特征,代表了测试样本退化过程中具有的突出退化特征,从结果可以看出,重构后的退化特征已经具有明显的退化特性,且在装备运行初期,退化特征波动较小,装备处于安全运行状态,验证了基于最小特征圆的指标构建方法的可行性。
3.3 结果分析
本文使用流行的深度学习方法对仿真后的样本数据进行处理,作为本文方法的对比实验。主要处理过程为利用SOM算法提取核心特征,使用卷积神经网络(convolutional neural network, CNN)对高维的核心特征直接进行降维成一维的性能指标集,最后采用非线性自回归网络(nonlinear auto regressive with extra input, NARX)对使用寿命进行预测。
利用双指数模型对最小特征圆得到的指标序列拟合结果如图6所示。从图5和图6可以看出,不同样本的退化轨迹既存在相似性,也存在差别,其最终失效的阈值也各不相同,表明本文基于相似样本集去研究装备退化规律是合理的。图6(a)中,装备预测指标在达到故障阈值之前,含噪声的原始退化轨迹存在两次达到阈值的情况,实际工程中,装备极有可能在此时刻周围遭受极端冲击,应该在该时刻附近注意装备的异常反应,以便及时应对可能的突发情况。

图6 测试样本退化轨迹与寿命预测图Fig.6 Test sample degradation trajectory and life prediction
图6中,装备的退化曲线会出现暂时的峰值,对应着实际生产中的外部载荷冲击导致性能发生变化,可以发现,在此后的一段时间内,装备的性能指标曲线会发生缓慢回落,体现了装备遭受外力冲击导致的性能突变会随着时间逐渐恢复;比较峰值左右的性能指标的平均大小,可以看出虽然突变的性能会随着时间恢复,但无法恢复到冲击前的水平。
从3个样本的退化轨迹可以看出,测试样本c -2和c -3在运行不久后性能发生了明显的退化,原因是样本在运行初期便遭受到了剧烈的冲击,而样本c -1的退化轨迹则相对较为缓慢,在850 h后才发生迅速的退化,这使得测试样本c -1的寿命和失效阈值要明显高于测试样本c -2和c -3。3个测试样本的估计寿命如表1所示。

表1 测试样本估计寿命对比
根据表1的估计寿命对比,本文模型的预测精度总体上比基于深度学习的直接降维方法的预测精度要高,且本文所提出的退化趋势分析方法对于略微平稳的系统,所得结果较为准确,对于遭受剧烈不规律冲击的装备系统,预测误差会稍大。
使用深度学习方法在估计样本c -3时误差比其他样本要明显,比较数据处理的过程,发现CNN直接将数据降维成一维的指标集,对周期性特征不敏感,无法充分体现数据特征时序性变化。
4 结 论
本文考虑了性能退化研究中大样本数据形式不规范、存在随机性误差等问题,建立了一类基于相似样本特征提取的最小特征圆的指标构造方法。方法主要立足于相似样本的相似特征提取,良好的相似特征提取方法可以有效提高预测精度,SOM算法在凝练核心特征方面具有非常大的优势,通过多样本学习,能够提取充分反映相似样本整体规律的特征。
经与流行的利用深度学习直接降维的方法进行对比,本文提出的指标构建体系,能够充分提取退化特征的时序性,过滤掉冗杂无关的信号。对比结果表明,本文所建立的模型可以很好地反映装备性能变迁过程,能够突出体现装备性能退化过程中受到外力作用时的变化特点,有助于实时监控装备的性能特性,对可能发生的潜在威胁实时预警。
