面向HPC和DC的可重构光互连网络体系结构综述*
2022-06-23曹继军
曹继军
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
目前,高性能计算HPC(High Performance Computing)技术正处于从100P级向E级跨越发展的关键阶段,国际上首台E级系统将会在2021年~2022年实现。同时,随着云计算、大数据应用等技术的不断发展,用户数目和数据量也呈现快速爆炸增长态势,这对数据中心DC(Data Center)的海量数据存储、处理和传输提出了更高要求。高速互连网络是HPC系统和DC的重要组成部分和全局性基础设施,也是决定计算系统和服务平台整体性能的关键因素之一。为了追求更高的计算性能以获得更优的应用加速效果,尽量降低网络通信开销成为HPC应用和DC业务对高速互连网络提出的基本需求,因此高带宽和低延迟成为互连网络设计和选择的首要目标,也是HPC系统和高性能DC互连网络区别于普通局域网的显著特征。同时,为了获得较高的HPC聚合通信带宽或DC“东西向”流量带宽,高等分带宽也成为HPC系统和DC互连网络设计的重要指标。然而,高等分带宽意味着高成本,即构建互连网络需要使用更多的交换机和网络端口及链路。对于超大规模HPC系统和DC而言,如果采用常用的无带宽收缩的胖树互连结构,其成本代价和工程难度都是难以接受的。同时,高等分带宽也意味着网络资源利用率较低。因为就应用通信模式和流量特征而言,绝大部分应用的计算规模在较小的节点范围内。例如,相关研究表明,超过80%应用的计算规模不超过4 096个计算核数[1]。预期的E级HPC系统单机柜计算性能为10~20 PFlops,已经远超过TH-1A整个计算系统的峰值计算性能(4.701 PFlops)[2],这足够为大部分并行计算应用提供支撑。
高等分带宽网络所带来的网络资源整体利用率较低而代价较高的问题被称为网络过供问题(Overprovisioned Problem)。但是,如果单纯采用成比例缩减汇聚层和核心层带宽的方法,尽管可以降低成本代价和工程难度,提高网络资源整体利用率,但是可能导致网络出现通信瓶颈和性能显著下降,从而造成网络过载问题(Oversubscribed Problem)。解决网络过载问题通常有2种方法:一种是负载适配网络的方法,即设计优化的负载分配算法或进程映射算法,尽量避免严重的网络拥塞或通信瓶颈出现;另一种是网络适配负载的方法,即为工作负载较重的节点或部件动态调度更多的网络带宽资源,从而缓解网络部分链路负载过重的问题。目前,光交换网络技术能较好地应对上述网络过供或者过载问题带来的挑战。光交换网络能够按照通信需求在物理层实现网络资源重新分配和调度,从而允许以较少的资源构建能够灵活满足用户通信需求的互连网络。
因此,对于未来HPC和DC系统的互连网络,过分追求高等分带宽的拓扑结构设计难以满足成本要求,而根据应用通信模式和流量特征实现网络拓扑结构重构的互连网络,将是一种能够降低工程难度并提高网络资源利用率的最佳选择。当前,可重构光互连网络已成为高性能大规模网络技术研究的热点,本文对其研究现状进行了综述。
2 光互连网络的优势
在传输带宽方面,在基于100 Gbps偏振复用四相相移键控PM-QPSK(Polarization-Multiplexed Quadrature Phase Shift Keying)调制相干接收器高密度波分复用DWDM(Dense Wavelength Division Multiplexing)技术条件下,单模光纤的传输带宽就可达12 Tbps[3]。在交换容量方面,由于高速光信号的损耗和串扰远低于电信号,并且通过波分复用技术,单一光波导内承载的信道数目可以实现数十倍增长,所以光交换架构可以实现较大的交换容量。在成本方面,采用光互连交换技术不仅可以减少电交换机端口数量,而且还可以降低用电和制冷成本。在能耗方面,由于光信号具有更低损耗和更长传输距离,因此光链路可以使用更低的发送功率。同时,由于光交换架构可以采用无源或低能耗光器件,因此可进一步降低网络能耗。随着硅光和光集成技术的快速发展,光互连交换设备成本日益降低,这更促进了光互连交换技术在互连网骨干网和高端数据中心的应用和部署。总之,相比于电互连交换技术,光互连交换技术具有高带宽、大交换容量、低成本和低能耗等技术特点。将光互连交换技术引入到HPC和DC中,对于有效应对系统在成本和能耗等方面面临的挑战具有重要意义。
3 主要光交换器件简介
各种光互连网络体系结构差异性较大,其首要原因是它们所采用的光交换器件的功能和结构等方面存在差异。下面将对本文涉及的主要光交换器件的原理、性能和适用场景进行简单描述。
(1)MEMS(Micro Electro Mechanical System)光交换机:一种采用微电子机械技术MEMS的光交换机,它通过静电或磁力控制微镜阵列的镜面角度来改变光束在自由空间的传播方向,从而将从N条输入光纤进入的不同光束交换至N条不同输出光纤,实现N×N的交换。MEMS光交换机控制简单,插入损耗低,功耗较低,但是交换速度通常在毫秒级,因此适用于对交换延迟不敏感的场景。
(2)阵列波导光栅路由器AWGR(Arrayed Waveguide Grating Router):一种根据光波长信息进行路由选择的阵列波导光栅路由器。在N×N的AWGR中,由端口i输入的波长编号为w的光束将被路由至[(i+w-2)modN]+1端口。同一输出端口可以接收不同波长的多个光信号,并复用在一条光纤上输出。AWGR功耗较低,交换延迟仅为纳秒至皮秒级,而且当前512端口的AWGR器件已经成熟[4]。AWGR通常需要与可调波长光调制器TWC(Tunable Wavelength Converters)和光通道适配器OCA(Optical Channel Adapter)等光器件一起构成光交换系统。
(3)可调波长光调制器TWC:可将输入的光信号变换成给定波长输出,目前160 Gbps的波长转换带宽的TWC已经商用,其重构时间低至纳秒级[5]。
(4)光通道适配器OCA:可将光信号转换为电信号,通常具有1∶N的多路解复用器,将光纤中混合光信号分离成多束单波长的光信号,并由后端的接收阵列将这N个光信号转换为电信号。
(5)波长选择开关WSS(Wavelength Selective Switch):对于1×K结构的WSS,可以将单个端口输入的光信号分配到K个输出端口中的任意端口输出。目前主流的WSS采用硅基液晶LCoS(Liquid Crystal on Silicon)方式实现。
4 几种典型可重构光互连网络
近年来SIGCOMM(Special Interest Group on data COMMunication)[6]等重要国际会议和期刊公布了多种系统级可重构光互连网络方面的研究成果。例如,2010年的c-Through[7]和OSA[8],2011年的Helios[9],2013年的Mordia[10],2014年的FireFly[11],2016年的ProjecToR[12]、Optical Dragonfly[13]和Ace-net[14],2017年的RotorNet[15]和2020年的Sirius[16]等,本节将对这些可重构光互连网络的工作原理及技术特点进行介绍与分析。
4.1 c-Through
c-Through[7]是在2010年SIGCOMM国际会议上公开的一种光电混合网络架构。在该架构中,每个柜顶ToR(Top of Rack)交换机同时连接至一个电交换网络和一个光交换网络。电交换网络为传统的层次式树形结构。光交换网络采用单一的微机电系统MEMS光交换机连接所有ToR交换机的方式构建。在同一时刻,该网络可为每个源机柜到另一个目的机柜分配一条高带宽的光传输链路。根据上层应用的通信需求,通过重配MEMS光交换机可以改变高带宽光链路在机柜间的分布,从而为数据量大的网络流在机柜间构造一条相对持续的光链路,而数据量较小的网络流则直接基于电交换网络进行通信。c-Through互连结构与流量管理方法如图1所示。
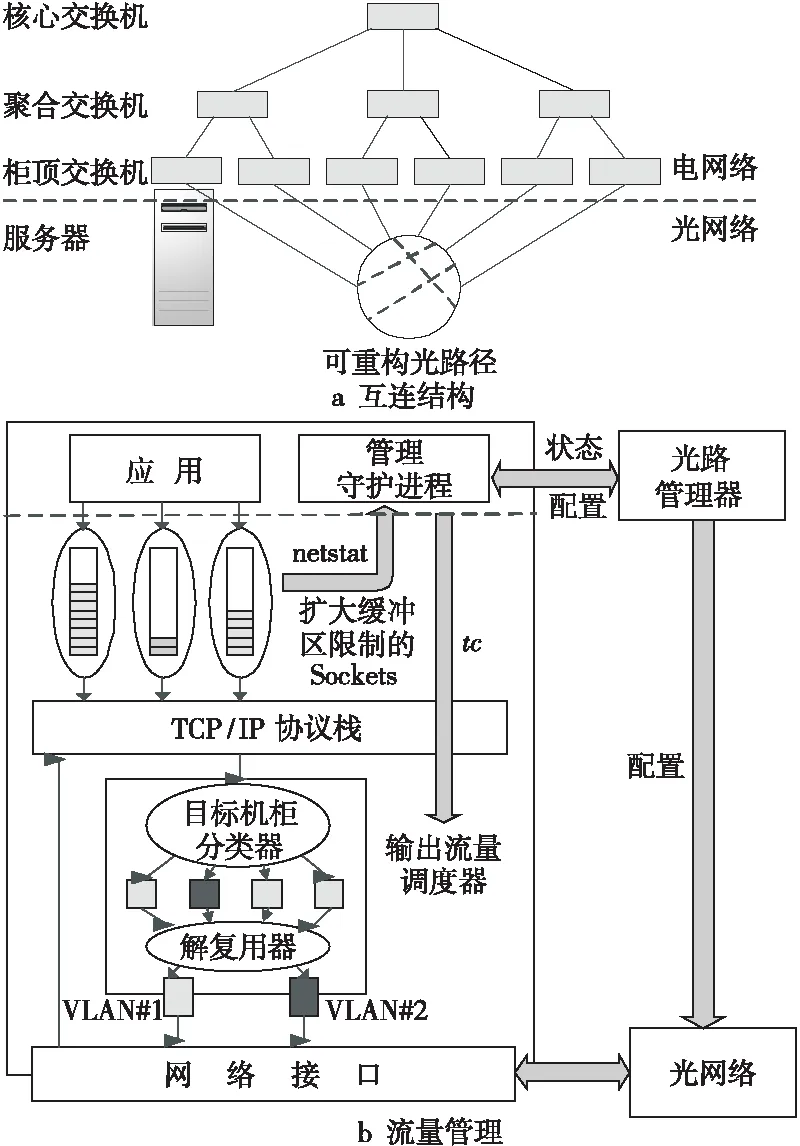
Figure 1 Interconnection structure and trafficmanagement of the c-Through图1 c-Through互连结构与流量管理
在网络控制平面,c-Through中各个服务器实时监测每条Socket队列所缓存的分组数目,并将该信息周期性地报告给集中式的光路管理器。通过收集所有服务器的Socket缓存状态,光路管理器可以计算出系统的流量矩阵,该矩阵反映了任意源机柜和目的机柜间等待发送的分组数目总和。对于根据流量矩阵分配MEMS最优配置的问题,光路管理器将该问题视为二分图的最大权重匹配问题,并使用经典Edmonds算法[17]求解。最后,光路管理器将配置下发到MEMS并通知服务器通过光网络传输,而未获得光连接的服务器仍采用电网络传输。在网络数据平面,c-Through对ToR进行基于端口的VLAN划分,并采用基于VLAN的路由算法将网络从逻辑上分离为电网络VLAN-s和光网络VLAN-c。每个服务器配置2个具有相同MAC和IP地址的虚拟网络接口,并分属于VLAN-s和VLAN-c。
c-Through通过VLAN划分方式隔离光网络和电网络,降低了拓扑重构对电网络稳定性造成的影响。该网络还通过增大服务器上每条流Socket缓冲区,对应用的通信流量进行存储和调度,这样既避免了头阻塞,又提高了通信需求评估的准确性,而且不会影响延迟敏感型应用的通信延迟。基于VLAN的光电网络隔离方法,保持了混合网络架构对上层应用的透明性。但是,由于采用了慢速MEMS光交换机,网络拓扑重构的延迟较大。此外,由于要求为每条流分配较大的Socket缓冲区,所以当通信连接数较大时,会对服务器系统的内存容量造成压力。
4.2 Helios
Helios[9]是在2011年SIGCOMM国际会议上公开的新型光电混合网络架构,是一种面向数据中心模块PoD(Point of Delivery,通常包括250~1 000个服务器的具有独立网络和制冷系统等模块的高度模块化数据中心[18])之间互连的网络结构。如图2所示,Helios为2层多根树(Multi-rooted Tree)结构,其2层分别由底层的PoD交换机和上层的核心交换机构成。核心交换机既包含传统的电交换机,也包含基于MEMS的光交换机。PoD内的服务器通过铜缆连接至PoD交换机,同一PoD内的服务器通过PoD交换机通信,而不同PoD之间通过核心层交换机进行通信。核心层的电交换机和光交换机分别用于处理All-to-All的突发流量和具有高带宽和长持续时间需求的流量。在图2的互连结构示意中,PoD交换机的一半上行链路端口与电交换机相连,另外一半上行链路端口通过无源的波分复用器WDM复用后连接到光交换机。

Figure 2 Interconnection structure andcontrol loop of the Helio图2 Helio互连结构与控制回路
用于拓扑重构的管理控制软件包含3个子模块,分别是拓扑管理器TM(Topology Manager)、电路交换管理器CSM(Circuit Switch Manager)和PoD交换管理器PSM(PoD Switch Manager),如图2所示。PSM运行在每个PoD交换机上,用于初始化交换机硬件,管理流表(Flow Table),和维护用于记录从本PoD发往不同PoD的流量计数器(按字节计数)。集中式的TM周期性地通过远程进程调用RPC(Remote Procedure Call)方式获得系统中各个PSM维护的流量计数器信息,并计算出记录任意PoD之间的流量计数的字节计数矩阵。通过当前周期和前一周期2个字节计数矩阵可以计算出PoD之间的流速率矩阵。为了实现只为具有高带宽需求的流量分配光交换链路,TM从流速率矩阵中过滤掉速率较低(即低于15 Mbps)的元素得到修改后的流速率矩阵。同时,为了获得真正反映通信需求的流量需求矩阵TDM(Traffic Demand Matrix),TM进一步采用Max-Min公平带宽分配算法由修改后的流速率矩阵生成PoD间的流量需求矩阵。以最大化光链路利用率为目标,TM再使用经典Edmonds算法[17]计算出最优的光链路连接关系。最后,TM通知CSM配置MEMS光交换机从而在PoD之间建立光链路,并通知PSM修改PoD交换机的路由表。
通过使用商用的全光交换机和WDM收发器实现了带宽和交换吞吐率的聚合,Helios网络降低了网络成本和能耗。与c-Through相比,Helios的优点是不需要对服务器软件栈进行任何修改。但是,由于仍然采用了MEMS光交换机,Helios也存在网络拓扑重构延迟较大的问题。
4.3 OSA
OSA[8]是于2010年HotNet(Hot Topit in Network)会议提出(也称为proteus[19])并在2016年TON (IEEE/ACM Transactions on Networking)国际期刊上正式公开的一种光互连网络。不同于c-Through和Helios等光电混合互连,OSA采用全光互连结构。如图3所示,OSA由ToR、MEMS和波长选择开关WSS 3种光交换机互连而成。每个ToR交换机配置多个工作在不同波长的光收发器,其发送的多波长光信号经过复用器(MUX)远程传输到WSS,WSS根据配置将波长重新分组,并通过多个端口将光信号输入MEMS光交换机。通过MEMS交叉开关矩阵,每个ToR交换机可以与其它多个ToR交换机直连通信。对于非直连ToR交换机之间的通信,需要借助中间节点通过光电转换识别报文头部信息并转发到目的ToR交换机,从而实现多跳步路由。

Figure 3 Interconnection structure and control step of the OSA图3 OSA互连结构与控制步骤
集中式的OSA管理器(OSA Manager)负责流量需求评估、拓扑计算、路由计算和波长分配等,并通过配置MEMS、WSS和ToR交换机等网络部件完成拓扑的建立与重构。OSA的拓扑控制步骤如图3所示:流量需求评估过程周期性地收集机柜间通信流量信息,利用TCP流的Max-Min公平带宽分配算法获得机柜间的流量矩阵。拓扑计算过程采用带权值的b-Matching问题求解算法[20],根据流量矩阵和ToR间的连接关系,生成MEMS光交换机的配置信息。路由计算过程优先保证具有高通信量的ToR交换机之间通过单跳步直接通信,而非高通信量的ToR交换机之间采用多跳步路由通信。波长分配过程采用多图的边着色算法为ToR交换的收发器分配波长。通过上述控制步骤,OSA实现了网络吞吐率的最大化。
与c-Through和Helios等早期提出的光电混合网络相比,OSA由于采用了全光交换架构并引入WSS等新型交换器件,具备较高的拓扑和带宽灵活性,提高了网络的利用率。OSA的缺点主要体现在:(1)多跳步路由的实现需要光电转换过程,因此增加了交换延迟并且要求中间ToR节点对报文进行缓存,实现难度增大;(2)仍然使用MEMS光交换机作为顶层交换机,而且没有电交换去平滑延迟敏感型应用的通信需求,导致其业务的适应性受到限制。
4.4 Optical Dragonfly
Optical Dragonfly[13]网络是在2016年的OFC(Optical Fiber Communication)会议上公开的以Dragonfly网络[21]为基础的拓扑可重构光电混合网络。Dragonfly(p,a,b)网络的互连结构分为3层:最底层的路由节点连接p个端节点,中间层每个局部组内的每个路由节点与组内的a-1个路由节点相连,最高层每个局部组内共(b×a)条全局通道与其余局部组互连。Dragonfly网络中用于组内连接的电链路被称为L-Link,用于实现组间互连的链路被称为D-Link。Dragonfly拓扑结构的网络直径较小,其实现代价比胖树等具有高等分带宽的网络低,因此被Cray[22]和PERCS(Productive, Easy-to-use, Reliable Computing System)[23]等实际HPC系统所使用。Optical Dragonfly网络改变了传统Dragonfly网络中D-Link所采用的固定链路连接,而采用根据网络流量需求可动态调整组间互连关系可重构光互连网络。图4所示为包含4个组的Optical Dragonfly网络互连结构,即将网络的D-Link连接在光交换机(例如基于MEMS的光交换机),而通过重配光交换机可以实现网络拓扑重构。
Optical Dragonfly网络的控制平面包括:检测组间流量特征的监测模块(Monitoring Module)、确定组间优化连接关系的网络优化器(Network Optimizer)和使用OpenFlow修改网络拓扑的拓扑管理器(Topology Manager)。该网络中用于重配组间光网络的软件结构如图4所示,上层采用ODL(OpenDayLight)作为网络控制器,底层路由节点支持OpenFlow协议,组内和组间通信使用不同的转发规则集。监测模块通过ODL REST API接口获取组间通信的流量特征。基于流量特征和网络拓扑结构图,并采用最大加权匹配MWM(Maximum Weight Matching)算法,优化模块得出全局链路分配方案。拓扑管理器根据全局链路分配方案产生出流规则并更新路由节点的流表和光交换机的端口连接关系。

Figure 4 Interconnection structure and controltechnique of the Optical Dragonfly图4 Optical Dragonfly互连结构与控制技术
Optical Dragonfly网络的优点主要体现在:(1)采用动态重构全局光链路的方法,缓解了传统Dragonfly网络等分带宽低引发的相关问题。在传统Dragonfly网络中,如果2个组间通信的流量较大,则采用直接和间接路由同时存在的多路径路由方法提高通信的吞吐率,但间接路由增加了网络跳步数,而且也可能会对其它组间通信性能造成影响。Optical Dragonfly网络采用可重构的光链路作为组间通信的全局链路,任意组间通信都采取直接路由,因此降低了网络跳步数和通信延迟。(2)在网络的控制平面采用成熟的软件定义网络SDN(Software-Defined Network)技术监测网络流量并对其进行配置,提高了Optical Dragonfly网络的可实现性。
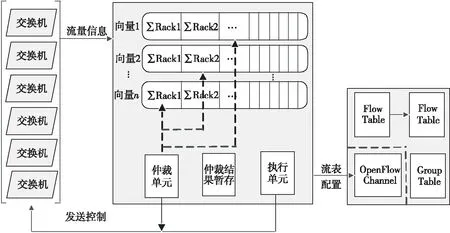
Figure 5 Measurement schematic diagram of flow requirements for the Ace-net图5 Ace-net流量需求测量原理
4.5 Ace-net
Ace-net[14]是由中国科学院计算技术研究所在2016年提出的一种面向DC的光电混合网络。在该网络中,机柜内的每台服务器使用电链路连接到本机柜内的ToR交换机上,机柜之间分别使用电网络和光网络互连。电网络可以使用任意拓扑结构,而光网络中所有ToR交换机都连接到同一个阵列波导光栅路由器AWGR。电网络在任意服务器间并行传输数量较小的网络流,而光网络在各组源和目的机柜间建立光链路从而传输数据量较大的网络流。
Ace-net通过仲裁控制系统完成服务器通信需求信息收集、光链路的调度、可调波长激光器TWC和ToR交换机的控制、数据传输过程的启动和停止等工作。在流量测量方面,如图5所示,通过在操作系统内核中监控Socket缓冲区的占用情况,将缓冲区的占用值按照目的地址聚合到虚拟队列中,虚拟队列中的每一表项记录本机与其对应机柜间的网络流信息,各个服务器虚拟队列中的信息构成整个网络的通信需求表征。在集中仲裁方面,中央控制器通过被动通告方式获得每台服务器的虚拟队列信息,并为每个机柜维护一个向量,向量的每一项分别记录本机柜与其对应机柜之间的累积流量需求。中央控制器根据不断接收服务器发送来的流量通知控制报文携带的流量需求信息,保持累积流量需求的实时性。在拓扑控制方面,通过扫描每个向量,获得与本机柜累积流量需求最多的机柜,然后控制对应的TWC进行波长变化,从而在2机柜之间建立一条持续的光链路。
Ace-net的扩展性取决于AWGR路由器所能支持的最大端口数。目前,512×512端口的AWGR光器件已经问世,因此Ace-net网络可以实现512服务器机柜间的超大规模互连;由于采用了纳秒级波长变换特性的TWC和波长路由器AWGR,并设计了高效的网络重构控制平面,其延迟和吞吐率等性能优于采用MEMS光交换机的c-Through网络。但是,由于采用UDP协议传输控制报文,并且控制报文传输延迟也影响虚拟队列管理的时效,所以拓扑重构的仲裁会产生“轮空现象”,这在一定程度上会影响光网络的利用率。
4.6 Mordia
Mordia[10]是在2013年SIGCOMM国际会议上公开的面向DC的光交换网络。与之前提出的c-Through和Helios等网络结构类似,Mordia也采用了基于ToR的互连结构。为了避免同一源ToR到不同目的ToR流量出现头阻塞,Mordia的每个ToR需要为其它所有的ToR建立报文缓冲队列,从而实现基于虚拟输出队列VOQ(Virtual Output Queue)的数据交换。为了克服早期的光电混合网络采用MEMS光交换机所存在的链路切换速度过慢问题,Mordia选用了具有微秒级配置延迟的波长选择交换机WSS构建光互连网络,从而实现快速的拓扑重构。图6所示为Mordia网络的原型系统,该系统将WSS连接成环形构成24×24交换结构并实现与24个ToR交换机端口的互连,通过波长分配及相关配置,可以实现任意源ToR与目的ToR之间的通信,而改变配置引起的链路切换时间可以低至11.5 μs。
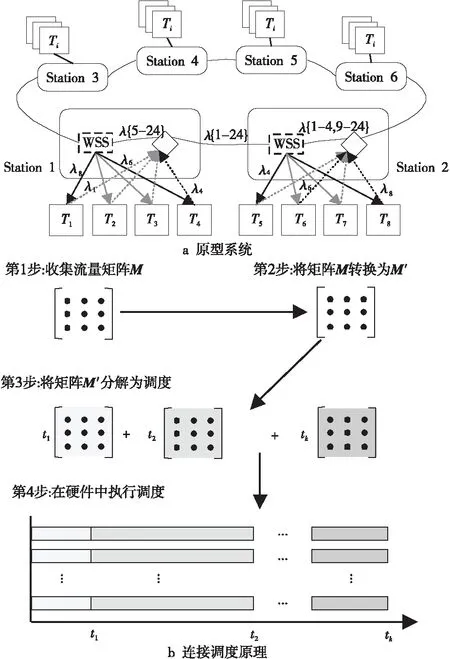
Figure 6 Prototype system and connection scheduling schematic diagram of the Mordia图6 Mordia原型系统与连接调度原理
在光链路调度方面,不同于传统光电混合网络采用的热点调度HSS(HotSpot Scheduling)方法,Mordia使用了一种流量矩阵调度TMS(Traffic Matrix Scheduling)方法。HSS方法可概括为:在每个时间槽内,首先测量机柜间的流量矩阵并以此计算流量需求矩阵,然后在流量需求矩阵中识别流量需求热点并通过重配光交换机为热点的源和目的机柜间建立光链路。TMS方法的调度原理如图6所示,在测量并评估获得流量需求矩阵TDM后,考虑光链路的实际带宽情况,使用Sinkhorn算法[24]可将该矩阵变换成为带宽分配矩阵BAM(Bandwidth Allocation Matrix),然后使用BvN(Birkhoff-von Neumann)算法[25]计算出该BAM对应的完美调度。
Mordia具有多方面优点:首先,使用的TMS流量调度方法克服了HSS调度方法存在的预测失真和局部最优等问题,提高了光网络的利用率;其次,由于采用配置时间非常短的光器件,光链路调度的时间槽可以设计得更短,这将降低ToR交换机的VOQ缓冲区的容量需求。Mordia的主要缺点是缺乏扩展性,Mordia原型系统实现了24×24的无阻塞光交换,沿用其所采用的C-band DWDM和单环技术,只能扩展到44×44的光交换规模。采用多环结构也只能将其扩展到数百端口,而且该结构是一种阻塞的交换结构。通过增加TWC可以提高其扩展性并解决阻塞交换问题,但这是以增加光器件和调度算法的复杂性为代价的。
4.7 Firefly
Firefly[11]是在2014年SIGCOMM国际会议上公开的一种基于ToR互连的新型网络架构。Firefly采用了自由空间光通信FSO(Free-Space Optical Communications)技术,其互连结构如图7所示。Firefly网络主要由部署在天花板的反射镜面(Ceiling Mirror)、配置在机柜顶部的可调FSO(Steerable FSO)设备和网络带外控制器等部件构成。Firefly光链路如图7所示,源机柜发送端将光信号直接从光纤输出到自由空间,并经过天花板镜面反射进入目标区域,目的机柜接收端也采用直接耦合方式将光信号输入光纤。为了解决光束从光纤进入自由空间时的散射问题和从自由空间耦合到光纤时的聚焦问题,在光信号的发送端和接收端都设置了透镜。Firefly提供了2种技术途径实现光链路的可重构,即分别是基于开关镜面SM(Switchable Mirrors)[26]和Galvo镜面GM(Galvo Mirrors)[27],在源和目的ToR之间建立可重配的光链路。

Figure 7 Interconnection structure and link design of the Firefly图7 Firefly互连结构与链路设计
SM的特点是能够在电信号的控制下实现反射和透射2种状态的转换。SM类型的网络可重构控制原理是:为每个光信号发送端配置多个SM,每个SM在预配置(Pre-Configuration)阶段预先通过天花板反射镜面的反射点对准固定接收端。在链路配置和重配阶段,发送端的某个SM被设置为反射状态而其余SM被设置为透射状态,从而建立源机柜到目的机柜的光链路。改变SM的状态组合就可以建立任意机柜间的光链路。GM的特点是能够在电信号的控制下绕固定轴转动,从而借助天花板发射镜面将发送端的光信号传输到锥形目标区域。GM类型的网络可重构控制原理是:通过配置GM的角度,从源机柜发送端发射的光束可以到达指定接收区域的目的机柜。在运行之前的预配置阶段,预配置灵活拓扑PCFT(Pre-Configured Flexible Topology)设计需要设计每个SM镜面的反射点或GM镜面的覆盖区域,以形成多条备选网络光链路,并使得网络动态等分带宽最大化。分别采用随机图算法和基于块的启发式算法可以解决PCFT设计问题。在实时运行阶段,需要根据流量需求评估情况周期性地或由特定事件(大负载迁移或大流量生成等事件)触发性地重构网络链路,以使得网络流量最大化。采用贪婪匹配算法可有效解决周期性拓扑重构问题。
Firefly的优点体现在:采用了自由空间光技术实现互连,降低了光纤互连的实现代价和复杂性。该网络实现了分布式光互连,与集中式光互连网络相比,避免了需要内部结构复杂的核心光交换机实现光交换,因此提高了网络的扩展性和可靠性。利用SDN技术,Firefly不仅实现了数据平面重配,而且ToR交换机可以向网络控制器主动报告观测到的网络流量需求。Firefly的缺点主要体现在:(1)该网络采用的是自由空间光通信技术,空间的洁净程度会影响通信误码率,因此如何建立和维护具有高洁净度的数据中心空间成为了需要考虑的现实问题。(2)受限于所采用的光器件的属性,该网络的重配时间较长(20 ms),而且网络预配置后每个源ToR能够连接到的目的ToR数量有限(10),因此降低了网络的实用性。
4.8 ProjecToR
ProjecToR[12]是由Microsoft 研究院在2016年SIGCOMM国际会议上提出的面向DC的拓扑可重构光互连网络。与Firefly类似,ProjecToR也采用自由空间光通信技术来实现ToR间的可重构互连。如图8所示,每个ToR上集成若干个激光发射及接收装置和数字微镜设备DMD(Digital Micromirror Device)。DMD是集成了数十万个10 μm大小的镜片阵列,通过改变配置可以调整每个微镜片的方向。悬挂在数据中心上方空间的球状多面镜用来向目的ToR反射从源ToR发射来的激光,从而可以建立用于ToR间通信的光链路。ProjecToR把任意ToR间的所有可能的光链路分为2类:专用连接(Dedicated Link)和机会连接(Opportunistic Link)。专用连接支持单跳或多跳步通信,重配周期较大,主要用于传输数据量较小的流量;机会连接只支持单跳通信,重配周期较短,主要用于传输数据量较大的流量。
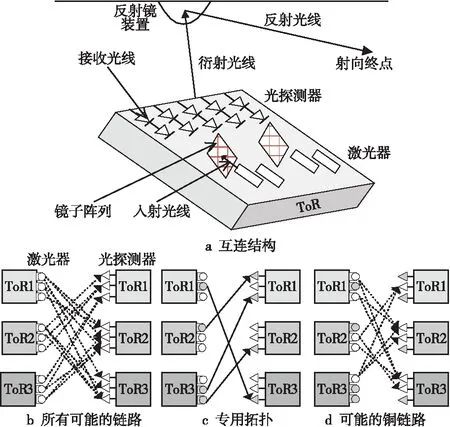
Figure 8 Interconnection structure and link planning method of the ProjecToR图8 ProjecToR互连结构与链路规划方法
ProjecToR使用了大量的激光器作为数据发送和接收器件,如何根据流量需求调整MDM微镜方向,动态建立激光发射器与接收器之间不同类型的连接并分配流量,成为了该网络需要解决的关键问题。在专用拓扑划分方面,首先根据每天的流量历史信息计算每个ToR每5 min的最大发送和接收速率,然后在约束最小值为2且最大值为ToR激光发送器数目减2的情况下为每个ToR计算出用于专用连接的发送器和接收器数目。再根据任意2个ToR间通信的概率排序为ToR间分配激光发送器和接收器对构成相对固定的连接。最后基于专用拓扑为每个ToR对计算一组最短路径,并在下发转发规则后开始传输数据。对于机会拓扑的连接调度问题,采用两阶异步稳定婚配(Tow-tier and Asynchronous Stable Matching)算法在每个时间槽启动时计算激光发送器和接收器之间的匹配关系。
ProjecToR的优点体现在:(1)实现了ToR的高扇出,例如对于具有1×105个服务器且每个机柜配置50个服务器的数据中心而言,使用768×1 024的MDM构建的网络可以保证每个源激光发射器平均与每个ToR的9个激光接收器建立连接关系。(2)参数重配改变MDM微镜角度的速度较快,可达到12 μs,因此拓扑重构的延迟较低,灵活性较高。但是,ProjecToR也存在明显的缺点:(1)该网络采用的自由空间光通信技术本身具有一定的缺点且尚不成熟(如前所述)。(2)基于现有商品化的MDM构建的光链路信号失真大约10.41 dB,仍然需要进一步提高信号传输质量。
4.9 RotorNet
RotorNet[15]是在2017年SIGCOMM国际会议上公布的一种基于ToR互连的光交换网络。与传统的基于ToR光交换网络Folded-Clos拓扑结构互连方案类似,RotorNet采用报文交换ToR交换机与机柜内服务器节点实现电互连,并通过光链路连接到Rotor光交换机,其互连结构如图9所示。Rotor光交换机由一组光交换机构成,而且每个光交换机都连接到系统中的任何一个ToR交换机。作为RotorNet网络的变种,ToR交换机的部分上行链路还可以连接到电交换机,从而形成与Helios网络[9]相类似的一种光电混合网络架构。
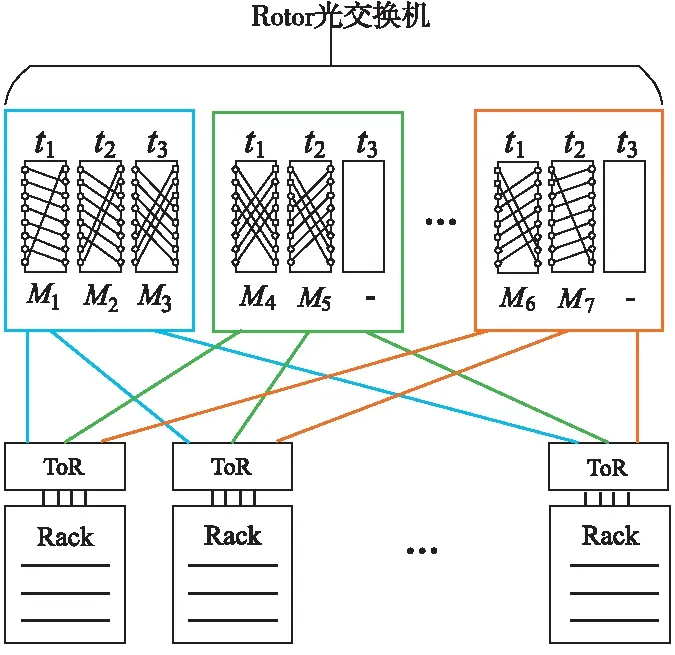
Figure 9 Interconnection structure and optical link scheduling of the RotorNet图9 RotorNet互连结构与光链路调度
不同于先前研究所提出的Helios[9]等光交换网络采用的光链路调度方法,即依据周期性测量和评估的通信流量需求集中式地对光链路进行重配,RotorNet网络的Rotor光交换机不考虑瞬时流量需求变化,也没有集中式的光链路调度控制,而是以Round-Robin循环方式在输入与输出端口之间实现预先确定的连接模式。Rotor光交换机的光链路调度基本原理如图9所示。从宏观上讲,Rotor光交换机在给定的时间间隔内能够为任意一对ToR交换机提供直接光链路连接。RotorNet网络采用2种路由策略,即单跳步直接转发和两跳步间接转发。单跳步直接转发在源和目的节点之间通过单个Rotor光交换机建立光链路,适用于均匀(Uniform)流量。两跳步间接转发在源和目的节点之间选择一个中间节点,源节点到中间节点和中间节点到目的节点间均采用单跳步直接转发。两跳步间接转发采用VLB variant算法[28],适用于非均匀的稀疏(Sparse)流量。为了自适应选择上述两种路由策略,RotorNet网络实现了一种全分布式的RotorLB协议,即默认采用单跳步直接转发,在空闲光链路上发送两跳步间接转发流量,并采用带内(in-Band)协议发现空闲链路。
RotorNet的优点体现在:由于采用了简单的Round-Robin交换模型,其控制实现较为简单,因此单个Rotor光交换机具有超过1 000个端口的扩展能力,而且交换延迟(20 μs)远低于同等规模交叉开关(Crossbar)的重配时间。同时,由于实现了两跳步间接转发策略,因此具备一定的路由容错能力。RotorNet的缺点主要体现在:对于非均匀流量,尽管RotorLB协议可以提高光交换链路的利用率,但是该协议破坏了数据流中报文序列到达目的节点的时间先后顺序,从而需要端节点增加报文重定序(Reordering)处理,这为端节点通信性能和通信代价有一定程度的影响。此外,相对于单跳步直接转发,两跳步间接转发增加了延迟并降低了整体吞吐率。
4.10 Sirius
Sirius[16]是在2020年SIGCOMM国际会议上公布的一种面向服务器或柜顶ToR交换机的光交换网络。Sirius采用扁平的高阶光互连结构,从而降低了传统低阶电互连多层结构带来的扩展代价(Scale Tax)。Sirius网络主要由可调谐激光器和AWGR连接而成,其中可调谐激光器由多波长光源和基于半导体光放大器SOA(Semiconductor Optical Amplifier)的波长选择器构成,固定激光体、可调激光体和组合激光器等方式均可产生多波长光源。如图10所示为一个由4个节点和4个AWGR构成的小规模Sirius网络,通过配置AWGR开关状态,每个源节点可以到达任意目的节点。
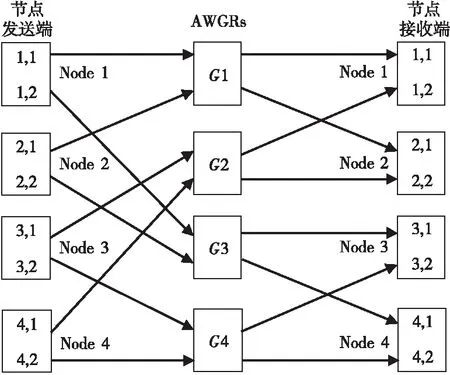
Figure 10 Interconnection structure and routing method of the Sirius图10 Sirius互连结构与路由方法
与RotorNet[15]网络类似,Sirius网络采用了基于VLB variant算法[28]的扩展算法,即任意源节点与目的节点之间都统一借助于某个中间节点进行路由。这种间接路由将数据中心的流量需求矩阵转换为较为均匀的流量需求矩阵,即任何节点发送到系统中其他节点的流量需求基本相同,从而能够较好地与Sirius网络拓扑特征相匹配。网络节点按照预定义的步骤周期性地改变光链路连接,即节点上的每个收发器周期性地调制到所有波长范围,从而以Round-Robin循环方式将报文发送到AWGR输出端口所连接到的所有节点。为了与基于时间槽的光链路调度相适应,注入到Sirius网络的报文采用固定长度。
Sirius的优点体现在:(1)可扩展性高。假设每个机柜的ToR交换机有256个上行链路且AWGR为100端口,则其最大互连规模可以支持25 600(100×256)个机柜,这是现有大型数据中心规模的6倍。(2)重构速度快。由于将单步调制技术替换为多步调制技术,从而将激光器调谐时间从毫秒级降低为纳秒级,大大降低了光网络链路的重构时间。(3)延迟较低。Sirius光网络内部采用无缓冲设计,只在端节点上设置了缓冲区。并且通过拥塞控制机制,使得缓冲区较小,从而保证获得可预测的低延迟通信。假设时间槽设置为100 ns,报文长度为576 B,则16节点规模的Sirius网络的报文排队延迟最高为1.6 us,端端通信延迟较低。Sirius的缺点体现在:(1)需要精度高于100 ps的细粒度全局时间同步,实现难度较大;(2)需要接收端进行报文重定序,增加了通信开销;(3)任何通信报文都需要中间节点转发,其效率可能会低于RotorNet[15]网络的RotorLB路由协议。
4.11 其它
除了上述几种典型的光电混合网络体系结构外,近年来研究者还提出了HFA(Hybrid Accelerating Architecture)[29]、OpticV(Optical Viaduct network)[30]和FlyCast[31]等。下面具体介绍这3种可重构光互连网络的特点:
(1)HFA是由IBM公司提出的光电混合网络,其结构与c-Through类似。其特点主要体现在该网络支持2种工作模式:①周期性地监视实时业务及配置光路,以适应业务模式需求;②支持应用直接通过API访问控制器,从而根据应用自身需要配置光链路。此外,该网络支持多跳步和多路径路由,多跳步可以减少对机柜间链路重构的需求,而多路径可以提高机柜间的吞吐率。通过OpenFlow对网络进行重构控制,与采用VLAN分配方式相比,具有更低的网络重构延迟。
(2)OpticV光电混合网络的电网络部分采用较为常用的3层网络结构(即接入层、汇聚层和核心层)方式构建。区别于c-Through和Helios网络所采用的光网络与电网络相对分离的传统混合模式,OpticV将3层中的所有交换机连接到基于MEMS的光交换机。该网络使更多的报文可以通过光网络交换,因此具有更高的能效比。但是,将系统中所有电交换机连接到MEMS光交换机,将使得系统可扩展性受到限制,所以其较为适合中小规模的系统级互连。
(3)FlyCast网络结构与FireFly较为相似,其改进之处是为网络增加了分光镜BS(Beam Splitter),从而配合开关镜面SM支持反射、透射和混合3种工作模式。其中,混合模式下原始光束被分为反射和透射2部分,从而可将数据从发送者组播到多个目的接收者,这对于提高组播聚合通信效率具有优势。
4.12 综合比较
表1综合比较了上述几种典型的可重构光互连网络。就网络架构类型而言,目前的设计方案主要包括光电混合互连网络和全光互连网络。其中,光电混合互连网络在传统的电报文交换网络架构的基础上额外增加了光线路交换互连网络,因此这种架构对传统互连网络具有较强的兼容性。但是,与纯电互连网络相比,光电混合互连网络无法在设备开销、能耗和网络管理等方面做出显著改进,因此全光互连网络架构将更具有技术发展优势,也逐渐成为近期光互连网络研究的焦点,该研究发展趋势从表1中也可以看出来。

Table 1 Comprehensive comparison of typical reconfigurable optical interconnection networks
5 结束语
随着“光进电退”趋势的不断演进,光互连网络技术将最有希望成为解决传统电互连网络技术发展所面临问题的关键技术。目前,光互连技术发展主要体现在2方面,(1)在模块级方面,随着工艺的进步,光电子集成特别是硅基光电集成与共模封装CPO(Co-Packaged Optical)将成为未来面向HPC和DC互连网络技术发展的重要使能技术。(2)在系统级方面,寻求光电混合或全光互连等新型高速网络架构,突破当前以电互连为主要特征的网络体系结构,将从根本上解决电互连网络发展所面临的问题。可重构光互连网络是SDN技术在光网络控制层面上的扩展应用,有希望在未来较大规模的HPC和DC系统互连中得到实际应用。
不同于现有电网络的SDN技术,可重构光互连网络需要进一步考虑光网络的特殊性,包括物理传输损伤、网络性能的约束和按需分配带宽的需求等,以满足光网络的特殊需求。具体而言,可重构光互连网络需要动态管理和控制光调制、光层路由、波长分配和波长转换等任务,从而实现根据上层通信应用需求对各种光层资源进行统一且灵活的调度和控制。目前,随着大数据和云服务等新兴技术的快速发展,数据中心业务与应用的通信带宽需求出现快速增长的态势,正推动着光网络资源向着开放性以及支持软件定义的方向发展。支持软件定义的可重构光互连网络不仅可以缓解光网络和多种网络技术融合背景下的网络业务调度、网络资源管理和网络运营成本控制的难度,而且还可以提高网络资源利用率。
