一种基于改进TF-IDF的SQL注入攻击检测算法
2022-06-23盛靖媛曹同洲
关 慧,盛靖媛,曹同洲
(1.沈阳化工大学计算机科学与技术学院,辽宁 沈阳 110142; 2.辽宁省化工过程工业智能化技术重点实验室,辽宁 沈阳 110142)
0 引 言
随着互联网时代的到来,Web的安全问题也因其易用性和开放性日益显著[1-2],根据2017年开放式Web应用程序安全项目组织OWASP(Open Web Application Security Project) 10大安全漏洞评估的结果显示[3],注入类攻击仍排在前十位中的第一位。因此,如何准确有效地检测SQL注入攻击便成为一个值得研究者们思考的问题。
目前针对SQL注入攻击检测的研究,主要有基于污点分析的检测方法[4-5]、基于规则匹配的检测方法[6-8]和基于文本特征表示的方法。其中常用的基于文本特征表示的方法如基于改进查询规范化的方法[9]、基于Token图的方法[10]、基于Simhash指纹的方法[11]、基于N-gram的方法[12]、基于信息携带的方法[13]、基于六维特征(SDF)转化的方法[14]、基于TFIDF文本向量化的方法[15-17],利用了TFIDF算法中所具有的词频以及逆文档频率2个指标,通过总结SQL语句敏感字符并计算其TFIDF值,设计文本向量化方法以实现SQL语句数据集到特征向量的转化。
但传统方法进行数据处理并检测攻击时会存在以下问题:使用该算法进行向量化后,由于会出现SQL语句中包含的常规词与关键字的语句数量相等或相近的情况,从而使SQL语句所得特征向量属性表示稍弱,结果导致关键字权重描述不准确。
1 TFIDF文本向量化算法
1.1 TF的介绍
TF表示词ti出现在SQL语句dj中的频率。SQL语句中每个词的词频的计算方法如公式(1)所示:
(1)
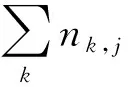
1.2 IDF的介绍
IDF表示SQL数据集中词ti的逆文档频率。SQL语句中每个词的逆文档频率的计算方法如公式(2)所示:
(2)
其中,|D|是数据集中的语句总数目,|{j:ti∈dj}|表示在数据集中出现词ti的语句数目。如果该词语不在D中,就会导致除数为0,因此一般情况下使用|{j:ti∈dj}|+1,即公式(2)改为公式(3):
(3)
传统的TF-IDF并不能很好地处理特征词的权重问题[18-19]。传统的TF-IDF算法思想认为,某个词t对于该文本内容的重要程度与它的数量呈现出正相关,但是如果词t在整个数据集中,也就是各个类型的文本中均有出现的话,其计算权值又会随着出现次数的增多而下降,从而说明词t的区分能力不强。但实际上,当某些词多次出现在一个类别的语句中,则该词几乎能够代表这个类的语句文本的特征,应给予较高的权重,并选来作为该类语句的特征词。
1.3 改进的TFIDF算法
计算IDF[20]的公式中可以看出,传统的IDF计算方法仅与数据集总数量、包含特征词的语句数量有关,针对以上不足,本文采用加入文本数量比因子γ对特征词出现的次数进行处理。计算方法如公式(4)所示:
(4)
其中,D为数据集中语句总数,Ci为类别,Nci为词ti在类别Ci中出现的语句数量,NDCi为类别Ci总的语句数量。
可以看出词频比因子的数值代表了词ti在某个类别Ci的重要程度,当词在一个类别中出现的次数越高,公式计算出的数值越大,这个词就越能很好地代表这个类别,应选取作为特征词。
然而当某个特征词在每个类别中出现的频率相同时得到的特征值仍然不能很好地区分,为解决这个问题引用卡方统计量CHI[21]。CHI的计算公式为:
(5)
其中,N为总语句数。表1给出了X、Y、M和Q的含义。CHI计算的值越大,说明词ti与类别Ci之间的相关程度越高,可以作为该类的特征词。

表1 类别特征表
为减小不同特征间的差异,加快训练速度,因此还要对TF-IDF进行归一化处理,采用min-max标准化(Min-Max Normalization),如公式(6)所示:
(6)
其中X表示当前样本数据值;min表示样本数据最小值;max表示样本数据最大值。
因此,改进后的TF-IDF算法公式为:
(7)
改进后的TF-IDF算法的处理流程如图1所示。
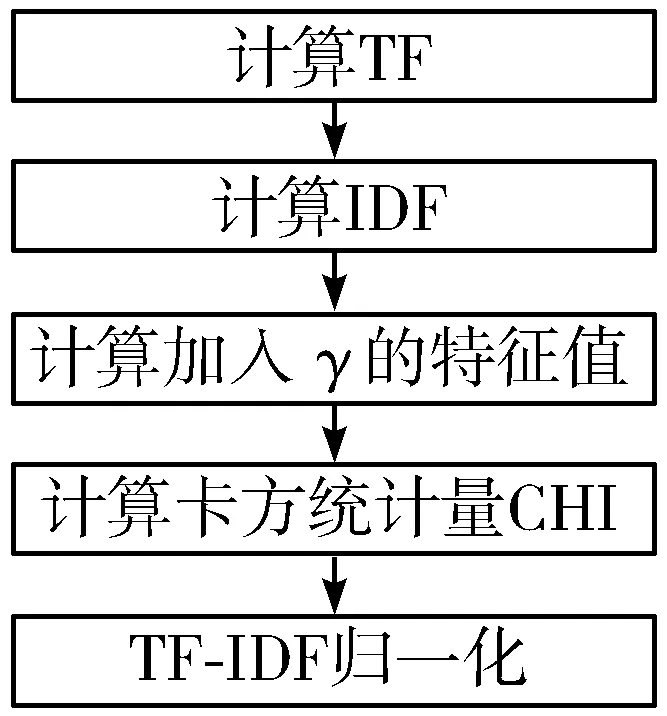
图1 改进TF-IDF算法的处理流程图
2 基于改进的TF-IDF算法的数据处理方法
2.1 实验流程
实验流程如图2所示。

图2 实验流程
2.2 数据预处理
将数据集数据进行预处理,首先是使用分词工具将SQL语句划分为单词。分词过程如表2所示。

表2 SQL语句分词操作前后对比
2.3 SQL语句向量化及样本标记
在进行完分词操作后,接下来就是基于改进的TFIDF算法对数据集进行文本向量化,每条SQL语句经过处理后都可以表示成一个34维特征向量。首先通过对大量SQL注入攻击语句与合法语句进行分析,并利用总结的32个敏感字符[15]的i_tfidf值作为SQL语句部分特征点,同时还选择SQL语句长度和敏感关键词词频[15]作为SQL语句的另外2个特征点。3条SQL注入攻击样本如表3所示。样本经过文本向量化处理后得到的文本向量如表4所示。

表3 SQL注入语句样本

表4 SQL注入攻击样本特征
然后进行标记处理。如果该语句是攻击样本,则将其标记为-1;如果该语句是正常样本,则将其标记为1。
3 实验及分析
3.1 实验环境
实验的硬件环境是处理器Intel® CoreTM i7-8850U CPU@1.80 GHz,内存8 GB,64位的Win10家庭中文版操作系统。实验环境为Python 2.7、Happier Fun Tokenizing。
3.2 实验数据来源
SQL注入攻击使用的数据来自GitHub上的开源libinjection项目[22],为了使数据集具有更多的注入攻击特征,本文经过删除重复数据后挑选出1000条作为SQL注入攻击语句数据集。此外,选择1000条正常用户在一定时间内对数据库的访问记录作为本文实验中所使用的正常语句数据集。
实验数据分为训练集和测试集,其中每类中选出60%作为训练集,40%作为测试集,最后根据实验结果对不同种类的分类器进行结果分析。
3.3 实验评价指标
本文采用的评价指标包括准确率(Precision)、召回率(Recall)、正确率(Accuracy)和F1值(F-Score)作为检测分类器性能的综合评估标准,其计算公式如式(8)~式(11)所示。
准确率指的是在已经预测为真的SQL注入语句中,真正类所占的比例。其计算公式如式(8):
(8)
召回率指的是在所有为真的SQL注入语句中,被预测正确的个体所占的比例。其计算公式如式(9):
(9)
正确率指的是在正常语句和SQL注入语句中,正确分类的语句占总语句的比值。其计算公式如式(10):
(10)
为了能更加有效地衡量训练出的分类器的综合性能,通常会把F1值当作检测指标。其数学公式如式(11):
(11)
公式中的TP、TN、FP、FN[23]含义如表5所示。

表5 混淆矩阵
3.4 实验结果
实验过程中将经过向量化处理的数据集导入Python中,将本文提出的基于改进的TF-IDF文本向量化的SQL注入攻击检测方法与文献[14]中提出的基于SVM的检测方法和文献[15]提出的基于TF-IDF的检测方法进行对照实验。然后分别使用3种不同的分类器进行实验,排除模型的唯一性,从而使效果越发准确。
由表6可见,与其他2种方法相比,本文提出的算法的正确率、准确率、召回率和F1值均到达99.96%、99.95%、99.89%和99.92%。这是因为本文提出的改进方法很好地处理了特征词的权重问题,弥补了传统TF-IDF方法以术语频率作为文本向量的不足,从而具有更好的检测效果。

表6 实验结果
由于在实际情况下SQL注入攻击语句的数量要远远小于正常语句,因此将SQL注入攻击语句数据集选择500条,正常语句选择1000条做一组实验,以保证实验的现实性。实验结果如表7所示。

表7 实验结果
图3记录了模型的训练时间。

图3 3种模型的训练时间
通过图3可以发现,使用相同的2000条数据对3个分类器进行训练,训练时间最短的是Boosted Decision Tree。这说明,在同样的条件下,如果使用Boosted Decision Tree作为分类器的算法,则分类的效率是最高的。
由表6和图3分析可知,Boosted Decision Tree模型无论是从准确率、召回率、正确率,还是F1值的结果上来看,对于SQL注入攻击检测来说都是最好的分类模型。
4 结束语
本文提出了一种改进的TF-IDF算法的SQL注入检测方法。经过改进的TF-IDF算法对SQL语句的特征词计算出相对应的权值,通过卡方统计量改进传统TF-IDF算法的不足,提高了SQL注入攻击识别准确率。从实验结果可知,改进的TF-IDF算法提高了SQL注入攻击识别的正确率、准确率、召回率和F1值,这4方面最高可达到99.96%、99.95%、99.89%和99.92%。因此表明,本文改进方法的提出能够在SQL检测上具有更好的效果。
