政策信息学视角下政策文本量化方法研究进展
2022-06-18曹玲静张志强
曹玲静 张志强


摘 要:政策信息学是大数据科学范式下政策科学向大数据政策知识发现研究发展的跨学科研究方向,从该理论视角系统梳理政策文本量化的知识发现方法及最新研究进展,可以指导数据密集的政策文本分析实践。文章基于政策信息学理论分析政策文本量化研究兴起背景、概念内涵和研究框架,将现有研究归纳为面向政策结构特征的政策计量分析、面向政策内容特征的政策内容量化和面向政策语义特征的政策文本挖掘等三类研究方法,分别总结各类量化方法的研究流程、主要类型及优缺点,并系统论述政策文本量化知识发现研究进展。政策文本量化研究近年来发展迅速,集中体现在政策信息爆炸性增长、多领域方法交叉融合现象凸显、政策分析需求复杂多样。未来应重点关注:建设领域政策大数据库、开发针对性的方法工具以及注重理论研究实践落地。
关键词:政策信息学;政策量化;政策计量;文本分析
中图分类号:D035;G203 文献标识码:A DOI:10.11968/tsyqb.1003-6938.2022087
Research Progress on Quantitative Methods of Policy Texts from the Perspective of Policy Informatics
Abstract Policy Informatics is an interdisciplinary research direction developed from policy science to big data policy knowledge discovery research under the research paradigm of big data science. From this theoretical perspective, it systematically combs the current situation and latest progress of knowledge discovery research methods in policy text quantitative, which can guide the practice of policy text analysis of data density. This paper analyzes the background, concept connotation and research framework of quantitative research on policy text from the theory of Policy Informatics, and classifies the existing research into three types of research methods: policiometrics analysis based on policy structural features, policy content quantification based on policy content features, and policy text mining based on policy semantic features. It summarizes the research process, main types, advantages and disadvantages of various quantitative methods, and systematically discusses the research progress of knowledge discovery in policy text quantification. Knowledge discovery research on policy text quantification has developed rapidly in recent years, which is mainly reflected in the explosive growth of policy information, the prominent phenomenon of cross integration of multi domain methods, and the complex and diverse demand for policy analysis. In the future, we should focus on: building a large policy database in the field, developing targeted methods and tools, and paying attention to the implementation of theoretical research.
Key words policy informatics; policy quantification; policiometrics; text analysis
21世紀以来新一轮科技革命和产业变革加速演进,全球范围内科技竞争加剧和国家创新体系建设重要性凸显,世界各国进入了政策强供给时代,政策分析研究迎来了新的发展机遇。传统的政策分析源于文本解读,即依赖专家学者的学识储备和经验判断来定性分析政策文本的核心思想和观点,总结政策变迁规律并对政策发展趋势进行预测与研判。然而,随着政策数据指数级增长和政策相关议题愈发复杂,偏主观的政策文本定性解读无法满足政界和学术界对理性、科学的需求,如何利用多学科的技术方法开展大数据驱动下政策信息的知识分析和发现变得日益重要,政策文本量化研究作为其关键环节开始萌芽与发展。近年来,情报学界关于政策文本的知识发现研究逐渐增多,政策文本成为情报学继期刊论文、专利文献之后的又一重要研究对象,这种趋势契合了大数据时代“全样本”数据分析的发展需求,也迎合了知识经济时代学科交叉融合创新的发展逻辑。
政策文本主要包括国家各级行政机构颁布的法律、法规和规划等官方政策文件;政策制定过程中因评估、咨询、听证和决议等形成的报告文档;政策活动过程中因演讲、辩论、报道、访谈、评论等形成的政策舆情文本。可见,政策文本不同于期刊论文、专利文献等结构化数据,具有来源渠道繁杂、数据类型多样、文本结构各异等特征。目前,缺乏政策文本分析特有方法,学术界围绕政策文本开展知识发现研究时多是借鉴参考其他學科的方法和工具,尚未形成系统的政策文本量化研究理论和框架。如黄萃将计量学方法应用到政策文本分析中,综合利用数理统计学、文献计量学、科学计量学和社会网络分析等方法对政策文本的内外部特征属性进行分析[1];付琳等通过编码的方式将政策文本进行归纳、分类和人工标引,形成可量化统计的分析单元[2];Baker等使用基于字典的方法来构建政策不确定性的度量[3];Beauchamp、Laver等将政策文本视为数据,利用计算机科学的相关方法和技术,挖掘文本中的政策立场[4-5]。
政策信息学是政策科学在数据密集型科学范式下发展形成的跨学科研究领域,其研究内容是基于政策文件数据、科研文献数据和社会媒体数据等政策相关的多源海量异构数据,利用数理统计学、文献计量学、科学计量学和计算机科学等多学科的技术方法,围绕政策科学研究的关键问题开展知识挖掘和知识发现研究[6]。从该视角全面梳理和总结政策文本量化研究的理论发展、方法体系和应用进展,能够为当前多样化的政策文本量化研究实践提供系统的理论框架和规范的方法范式。因此,本文基于政策信息学理论从政策文本量化的缘起入手,梳理、总结和归纳政策文本量化的概念内涵和基本框架,整理政策文本量化主流研究方法的分析流程、方法工具和应用场景等,构建系统的依赖政策文本量化开展政策知识发现的研究体系,以期为今后学者开展政策分析相关研究提供参考和借鉴。
1 政策文本量化研究的理论发展
1.1 政策文本量化研究的兴起
1.1.1 政策文本数量激增提供了可用的数据基础
随着大数据和数字时代的到来,政策相关文本数据爆炸式增长,主要体现在政策信息来源复杂化、政策文本信息碎片化、文本数据类型多样化。而开放政府、数字政府及电子政务的世界性发展趋势为政策文本量化研究提供了信息获取的机会和可能。如我国于2007年4月公布《中华人民共和国政府信息公开条例》(2008年5月1日起实施,2019年二次修订),明确要求政府必须公开行政法规、国民经济和社会发展规划、专项规划、区域规划等规范性政府文件;2014年颁布《关于加强政府网站信息内容建设的意见》,明确指出各级政府要将政府网站作为政府信息公开的第一平台。同时,政府信息管理系统的不断丰富和完善为政策文本量化研究提供了大量可用的基础性和结构化数据。可见,大数据时代背景下政策文本的完备性、时效性、可获取性、可计算性显著提升。
1.1.2 方法技术快速发展使量化分析成为可能
海量政策文本的出现使得传统的依靠定性解读或手动编码的政策分析方法不再适用,新兴信息技术的快速发展为政策数据的复杂计算、政策知识的深度挖掘和政策规律的可视化呈现提供了新的解决方案。计算机技术、文本挖掘技术的日臻成熟和广泛应用,使得公共管理、公共政策和其他社会科学的学者能够处理大量政策文本,以发现挖掘其中的潜在关系;另一方面,情报学、数理统计学、社会科学等学科知识和方法的交叉融合为政策文本量化研究提供了方法源泉,文献计量、内容分析和语义分析等成熟量化分析方法大大拓展了政策分析的研究边界,主题模型、知识图谱和可视化技术等扩展了对复杂政策过程的理解及向不同受众解释、传播的能力。近年来,计算机科学技术发展日新月异、学科交叉融合趋势愈发明显,政策量化研究作为政策质性分析的有效补充蓬勃发展。
1.1.3 政界及学界对政策分析日益精细的需求
政策文本量化研究是数据驱动科学研究范式下政策分析科学化、合理化发展的必然结果,也是学科交叉融合背景下学术界针对海量政策数据开展政策分析的必然选择。随着政策分析样本量的丰富性增长和多学科方法技术的成熟化发展,政策参与方(政策制定者与利益相关者)对政策分析提出了更高的要求。如何从多种类型的海量政策文本信息中提取知识,发现政策演化变迁规律、评估政府决策本身的效益或者预测相关领域发展走向?如何科学合理地运用相关工具和方法将政策文本量化为可复用的研究数据,使政策分析更加客观、系统和高效,为政策制定提供有力的证据?基于此,政策管理制定已经从依赖经验判断走向数据驱动的循证决策,政策分析亟需从小样本统计推断转向大样本知识发现,政策研究关注重点应从相关关系探讨转向因果关系分析。
1.2 政策文本量化研究内涵及特征
政策信息学视角下的政策文本知识发现研究并不局限于传统政策解读较为关注的规范性政策文本,更多关注大样本量、半结构化或非结构化政策文本的量化分析。与之相关且较为被学术界所熟知的概念有“政策文献计量”“政策文献量化”和“政策文本计算”。政策文献计量是将以“洛特卡定律”“布拉德福定律”与“齐夫定律”三大定律为理论基础的文献计量学方法迁移到政策量化分析的研究中[7],是参考论文结构属性开展计量分析的政策文本量化方法。政策文献量化是将内容分析法、文献计量法、社会网络分析法、知识图谱等方法应用到政策分析过程中,围绕政策文献内外部结构要素特性进行的计量分析[8],本质上仍然是政策计量的范畴;政策文本计算主张运用政策文本与语词之间的映射关系进行政策概念的自动识别和自动处理,构建从政策文本到政策语义的自动解析框架[9],偏重于利用计算机技术挖掘、呈现政策文本的语义信息[10]。可见,这些概念是政策文本量化内容的不同侧重,实际上均属于政策文本量化研究的范畴,故本文将其统称为政策文本量化。
实际上,政策信息学是一种理论框架和方法集成,也是一套系统完整的政策分析流程。政策文本量化是将政策信息学的研究对象聚焦到政策文本开展定量知识分析与发现的必备环节。其中,政策文本应该广义地理解为是一种政策相关文本,包括:结构化的学术文本(围绕政策问题、内容、过程形成的研究成果)、非结构化的媒体文本(新闻、评论等自然语言中存在一些政策主张)和半结构化的政策文本(最直接的政策信息来源)等多模态异构数据。基于此,将政策文本量化定义为通过某种转换方式将政策文本转换成抽象化、特征化、可计算的结构化数据,再根据研究目标融合数理统计学、文献计量学、科学计量学、计算机科学等多种方法对所得数据进行数学统计、主题建模、网络构建、相似性计算等定量分析,并辅以研究人员依赖专业知识和经验积累进行定性解读的研究过程。
政策文本量化具有如下特征:(1)可统计性。政策文本量化的根本要义就是将用语言表述的政策转化为可用“数量”统计的数据,通过对政策量化的分析,找出能够反映政策过程、政策意图、政策规律的特定要素以及易于计数的内外部特征,保证数据操作的可重复性和客观性;(2)非精确性。政策文本量化是针对大量政策文本利用编码处理或计算机语义降维的过程,实际上是一种损失精度的政策分析方法,在研究过程中需要与定性研究方法相结合[11],从而实现政策分析中宏观与微观、主观与客观的二元统一;(3)跨学科性。政策文本量化研究是融合统计学、情报学、公共政策学等多学科的理论基础和方法技术开展的政策文本定量分析,近年来是情报学、政策学界以及计算机科学的热门研究领域。
1.3 政策文本量化研究框架
政策信息学的核心是针对政策全生命周期信息的大数据分析和知识发现研究,其三大支柱是:多来源异构海量数据、多学科数据分析方法、多目标知识应用场景[6]。基于此将政策文本量化研究过程分为政策文本获取、政策文本处理和政策文本分析三个阶段[12],构建政策文本知识发现研究的基本框架(见图1)。其中,政策文本获取的关键是构建适合研究目标的政策语料库,目前主要有三种方式:利用现有的结构化政策数据库(如北大法宝、美国政府出版局等)直接下载所需数据;人工收集或计算机技术爬取开源政策文本保存到本地自建数据库;为保证获取到符合研究目标的完备性数据,在实践过程中往往将前两种方法相结合形成特定的政策语料库。政策文本处理在具体的政策文本量化方法中有不同的处理方式,本质上是将非结构化或半结构化的政策文本转换成可计算或可量化的分析单元,是一种语义降维处理过程。政策本文分析的基本遵循是政策实践需求驱动和政策研究问题导向,即根据政策目标和应用场景开展政策数据分析与知识发现研究。
2 政策文本量化的主要研究方法
按照政策文本分析的层次,政策文本量化研究可分为面向政策文本结构特征的政策计量分析、面向政策内容特征的政策内容量化分析和面向政策语义特征的政策文本挖掘三类典型研究方法(见图2)。其中,政策计量分析是通过统计、计算或可视化政策文本的若干规范属性对政策文本的演进、扩散及府际关系等开展研究;政策内容量化是按照一定的标引框架和量化标准对政策内容进行人工或者计算机辅助的编码处理,提升政策内容解析的效度;政策文本挖掘是借助自然语言处理技术挖掘政策隐含内涵或政策语义关系,便于生成政策知识图谱。为直观展现政策分析结果,各类政策文本量化方法的最终步骤均是可视化呈现,按照类型的不同主要可以分为:基于数理统计的可视化、基于主题内容的可视化和基于语义关系的可视化。
2.1 面向政策结构特征的计量分析方法
2.1.1 政策计量分析的内涵与流程
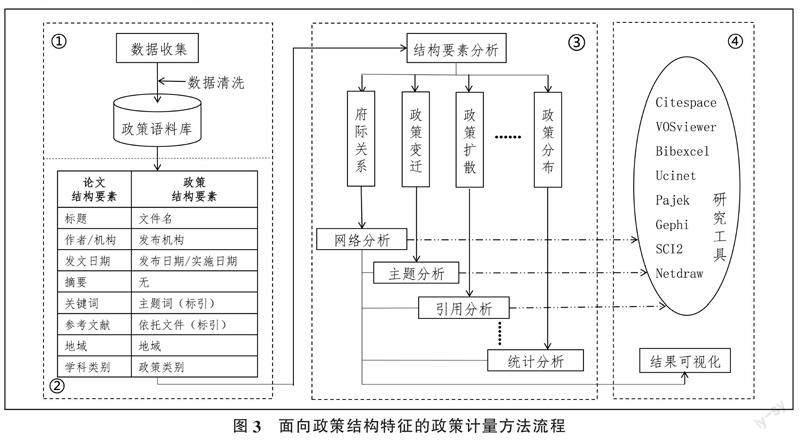
政策计量分析是将计量学的方法引入应用到政策对象,逐渐发展成为情报学和政策科学交叉的研究领域——政策计量[13],包括政策文献计量、政策科学计量[14]和政策替代计量指标[15-17]等一系列概念。该方法的基本核心是通过现有政策数据库下载或基于自建数据集将政策文本处理成类似论文文献的结构化数据,分析政策文本在颁布机构、发布时间、主题分布、政策引用以及政策主体关系等内外部属性要素进行计量分析,旨在揭示某个领域、某个主题或某个时段的政策分布特征、政策演化规律和政府合作关系等。政策文本计量分析方法流程(见图3)主要有:①构建政策文本研究数据集;②结构化政策文本属性要素;③统计分析、文献计量和社会网络分析;④结果可视化呈现及结果解读。
2.1.2 政策计量分析的主要类型
政策计量分析很大程度上依赖于政策文本的结构化程度,基于政策文本数据集的不同可以分为三种类型:一是利用政策文本数据库(如北大法宝和CNKI政府公报数据库)自带的字段信息开展计量分析,分析政策数量增长、机构合作、政策变化规律等。如卢小宾等、冯昌扬等利用北大法宝数据库分别对我国信息公开政策、文化扶贫政策进行了计量分析[18-19];二是通过自建政策文本数据库与语料库形成新的统计字段。如清华大学科教政策研究中心搜集了中国1949年以来中央政府颁布的科技政策构建了政府文献数据库,并对政策类型统计分析形成了《中国科技政策要目概览》[20];代欣玲等收集整理1996年以来创新培养人才政策,形成了发文机构、年份、地區、层级、文种类型、关键词等字段,并将相关字段处理成文献计量软件Citespace所需格式,开展主题聚类、主题变迁、机构合作等分析[21];赵洪等通过公文的内容解构、主题标引、摘要生成等方法,构建了应用于大规模政府公文的知识发现与分析系统[22];三是利用替代计量学(Altermetrics)方法[23]对社会媒体(如新闻、微博、演讲等)涉及的政策文本数据进行分析研究。如Somasundaran和Wiebe构建了政策辩论数据库[24],并通过对其相关文本分析发现政策立场和政治意识[25];Proksch等使用自动语音识别系统生成政治演讲文本,结合计算机处理技术可以对该文本语料库开展计量研究[26]。
2.1.3 政策计量分析的优缺点
政策计量分析方法对数据的结构化要求程度比较高,现有的政策数据库在开放性、完备性和结构化方面尚不能满足政策计量分析的需求,反映政策文本内容的信息较少,如主题词、政策摘要和引证关系等均无法从数据库直接下载获取,亟需构建类似文献数据库、专利数据库的政策大数据平台。文献计量指标应用于政策对象时主要聚焦在对政策内外部属性的宏观分析,有助于发现政策整体的分布特征和长时间序列的发展规律,并不能满足精细化的研究需求,对于政策文本细节、政策隐含语义、政策特色表征等的分析需要构建全面且个性化的分析指标。
2.2 面向政策内容特征的内容量化方法
2.2.1 政策内容量化的内涵与流程
政策文本内容量化通过界定能反映政策语义与语词之间映射关系的编码标准和分析框架进行政策概念的识别和处理,是一种介于定性与定量之间的半定量研究方法。该方法的基本核心是建立合适的有价值的类目以分解政策文本内容,将政策文本中非量化的、非结构化的信息转换为可分析的定量数据,以便为政策效果评价、政策效力分析和影响因素探讨提供数据基础。政策文本内容量化方法流程(见图4)主要有:①构建政策文本数据集;②确定分析框架和分析维度;③定义分析单元与类目进行编码;④信度与效度检验;⑤数理统计分析和结果解释。
政策内容量化方法的关键在于分析维度的选择,其中,政策工具维度是政策内容量化分析实践中的必要组成部分。政策工具研究始于20世纪80年代,是为解决某一社会问题或达成一定政策目标所采用的手段和措施,实际上是一种调节政府行为的机制[27],其分类是定义分析单元分类标准和类目设置的重要依据。目前比较有代表性的政策工具分类有:Klein等根据政府资源类型将政策工具分为信息型、权威型、组织型和财政型[28];McDonnell 和Elmore根据政策效力的不同分为命令型、激励型、能力建设型和系统变化型四种[29],Phhal类似地分为自愿型、强制型和混合型工具[30];Hoppmann等根据政策制定层次将工具分为战略层、综合层及基本层[31];陈振明将政策工具分为市场化工具、工商管理技术与社会化手段[32];Rothwell和Zegveld根据政策产生影响层面的不同分为供给型、需求型和环境型三种[33],这也是政策内容量化应用最为广泛的分类标准。
2.2.2 政策内容量化的主要类型
政策内容量化分析实际上既包含了传统意义上对政策信息的定性判断,也包括了对政策内容的量化统计。基于此,政策内容量化分析主要分为三种类型:一是对编码处理后的政策文本研究类目的纯定量分析,主要聚焦于政策目标、政策主体、政策客体以及政策工具维度等在时间序列上的变化特征。如李浩等构建“基于政策目标、政策工具和政策力度”的三维框架,对国家层面DRG(Diagnosis Related Group,疾病诊断相关组)政策条目进行多维分类和交叉对比统计分析[34];黄如花和温芳芳利用Nvivo对国家层面政府数据开放共享政策文本进行编码,利用Excel表格进行描述性统计,以反映政策文本的形式和内容[35];二是基于政策文本描述性量化分析结果,再运用PMC指数、AHP层次分析法、BP神经网络综合评价法、灰色关联度分析法等对政策进行绩效评价。如李煜华和张敬怡运用内容分析法对国家先进制造业发展政策文本进行整体性的“政策工具-产业发展要素”二维量化分析,在此基础上引入神经网络理论的自编码技术构建先进制造业多维政策评价的PMC-AE指数模型评价典型先进制造业发展政策的优劣情况[36];李鹏红对土壤污染治理政策文本进行编码处理和质性分析,再运用AHP-熵权耦合方法对公众参与政策工具集进行了综合评价[37];三是对政策内容描述性定量分析与阐释性、预测性定性分析的结合,通常是在政策结构属性分布特征的基础上对政策演变规律和发展趋势进行研判和预测。如李梓涵昕和周晶宇分别从政策力度、政策工具、政策客体、孵化器生命周期四个维度对孵化器政策进行描述性统计分析,并结合中国孵化器發展阶段,分析不同阶段孵化器政策演变特点并预测了未来发展规律[38];李霞等构建基于“资源效用-技术结构-应用领域”的智慧城市政策工具分析框架,运用统计分析、政策网络分析与多维尺度方法展示了我国智慧城市政策阶段共现主题词和政策演进脉络[39]。
2.2.3 政策内容量化分析优缺点
政策内容量化分析沿袭了政治学中的政治话语研究和政治语词解读(政策主题归纳)的研究传统,在研究样本量较少、程序规则清楚、类目界定清晰的条件下能够更为恰当且深度地解析政策文本。但由于其对政策文本进行概念抽取时主要依赖人工处理,人力成本与使用难度会随着样本量和分析角度的增加而增长,不适用于对海量政策文本分析处理。除了方法本身的局限性外,政策内容量化方法的研究过程完全依赖于最初所界定的分析维度和分析单元,最终结果将受限于研究者的政策认知水平、专业知识基础以及对政策语言理解的能力。
2.3 面向政策语义特征的文本挖掘方法
2.3.1 政策文本挖掘的内涵与流程
随着计算机和大数据技术的蓬勃发展,政策文本挖掘方法逐渐成为提升政策文本量化成熟度的关键,为政策计量和内容量化等研究提供了坚实的数据处理基础和分析工具支撑。政策文本挖掘方法是指在大规模政策文本集合中发现潜在信息和隐含知识的过程,包括机器学习、自然语言处理、深度学习、可视化技术、数据库技术等多类技术方法[40]。该方法的基本核心是利用技术方法和机器效率完成对政策文本多种维度的特征识别和信息抽取,以便解读和获知政策立场、政策意见、政策行为、政策情感等深层的政策语义内涵。政策文本挖掘方法流程(见图5)主要有:①获取文本形成政策语料库;②文本数据预处理;③政策文本表示;④根据研究目标选择合适的模型;⑤结果可视化及模型评估。
政策文本挖掘方法的关键在于将政策文本处理成计算机容易处理和理解的数据,即政策文本表示。目前常用的文本表示方法主要有三种:第一种是词袋模型(Bag of Words,BOW)[41],BOW模型是最原始的文本表示方法,其忽略政策文本中的词序和语法,将单个文本看成若干独立词汇的集合,每个词不依赖于其他词是否出现;第二种是主题模型(Topic Model)[42],该模型假设每个文本是由一系列主题的概率分布表示而成,基于BOW模型做了降维处理,训练得到词和文档的特征向量,有效避免了文本在特征空间中的稀疏性;第三种是词向量模型(Word Embedding)[43],充分考虑了政策文本中词汇出现的上下文语境和相互依赖关系,将文本表示成一个低维且连续的稠密向量。实质上是将文本中每个词映射到一个向量空间中,而词之间的关系也可以通过向量計算表示,弥补了仅依赖词汇导致的语义不足问题。
2.3.2 政策文本挖掘的主要类型
政策文本挖掘注重在大量文本数据集合中探索深层或潜在语义关系、发现分类和聚类特征、挖掘隐形关联知识或关系牵连。当前研究类型主要可分为三种:一是政策文本分类研究,如Zhitomirsky等实现了无需任何人工标注的政治文本全自动分类[44];沈自强等利用BERT深度学习模型对科技政策进行自动分类实验,发现通过BERT模型,融合标题和TF-IDF政策关键词的分类效果最佳[45];二是政策主题模型研究,其与政策文本聚类、政策主题演化等研究密切相关。如曲靖野等提出了一种以科技报告为载体数据源,基于LDA主题识别与K-means聚类方法相融合的科技报告文本聚类的文本挖掘新方法,从主题的视角对科技报告文本进行聚类研究[46];刘建华等基于政策文本中多维政策实体及实体之间的直接语义关系、直接共现关系、间接共现关系、关联路径衰减指数等,构建综合计算科技政策实体关联的多指标模型,并结合实体时间属性,揭示科技政策演化路径[47];三是政策情感识别研究,其在识别政策立场倾向、政策意见分析和选举预测中应用较多。如Hopkins和King开发了一种自动非参数的文本数据分析方法,能够分析博客、演讲、报纸等非结构化文本中的政策倾向[48];Saremento等提出了一种自动创建政治参考语料库的方法,定义并使用一组由大型情感词典支持的人工制作的高精度规则识别相似文本语句,以挖掘用户评论中的政治意见[49]。
2.3.3 政策文本挖掘的优缺点
政策文本挖掘方法显著提高了处理大量政策文本的能力,一定程度上解决了大数据环境下政策计量和内容量化法分析效率较低、分析深度不够等问题,为跨语料分析和实时政策文本分析提供了可能。这也决定了政策文本挖掘方法对宏观政策问题和政策现象分析效果越好,在一些具体案例、细小问题、以及个别政策分析方面甚至不如定性分析来得准确。此外,应当注意到政策文本挖掘本质上是依赖计算机技术发展水平的衍生应用领域,要受到当前算法成熟度、系统误差以及硬件计算能力等客观水平的限制。
3 政策文本量化的知识发现应用研究
在计算机技术、信息通信技术和大数据技术蓬勃发展的时代,“方法技术不是难题”是社会科学研究的统一共识。政策信息学作为连接政策量化分析和政策问题求解的交叉学科,不仅仅是理想状态下的问题求解,而是必须明确解决方案最终实现所需要的各种约束条件[50]。近年来,情报学、政治学和公共管理学等领域的学者在数据拓展、方法融合、实践应用等方面进行了积极地探索,主要集中在以下几个方面。
3.1 政策分布特征和发展规律研究
多学科和多类型政策文本量化分析方法的应用极大程度上拓展了政策分析的精度和深度,突破了人工定性解读和单纯频次计算的研究范畴,可以更加显性化地挖掘政策间的关联关系,揭示政策分布、政策变迁和政策扩散等政策发展规律。在政策分布方面,Isoaho等对欧盟委员会能源联盟出台的5000多份政策文件进行主题建模分析,发现能源联盟的政策重点在于脱碳和能源效率,而气候安全和气候可负担性政策存在政策趋同的信号[51];Prior等使用文本挖掘策略与语义网络分析技术相结合的方法提炼政策文本的基本内容元素,了解了英国环境卫生领域的政策文件分布特征[52]。在政策变迁方面,Huang等利用文献计量学方法分析了不同时期不同部门的政策出台情况,梳理了中国科技创新政策体系的发展脉络[53],并提出一种基于“政策目标-政策工具”模式政策主题变迁的方法,分析了中国核领域政策的演变过程[54];Arenal等结合文本挖掘技术、主题聚类分析和定性评估等方法,分析了欧盟创业政策的周期曲线和主题演变[55]。在政策扩散方面,江雨薇等运用统计分析和文本挖掘方法对破除“唯论文”政策的时空演进、发文机构及主题内容进行分析,总结政策在不同层级间的主题扩散特征,预判政策发展趋向[56]; 王芳等运用政策文本挖掘从扩散主题维度和政策扩散倾向性两个方面分析了我国大数据政策扩散特征,利用可视化技术呈现从中央到省级、地市级政策扩散过程中的主题变迁,揭示了我国各级政府在政策扩散过程中的倾向性和特点[57]。
3.2 政策作用过程和效果评估研究
政策评价是科技评价的重要组成部分,随着经济社会环境变化加快、政策议题日益复杂多样和评价信息来源纷繁杂乱,大数据驱动下的政策信息学研究为政策评价工作带来了新的发展机遇。政策量化评价研究当前主要围绕政策文本特征和政策文本内容展开,为政策的制定、调整以及完善提供了重要的理论支撑和决策依据。基于政策文本特征的量化评价研究,指的是从政策文本的多个维度设置变量分析政策优劣。具有代表性的方法是Estrada建立的PMC指数[58-59]。学者们分别围绕科技服务业政策[60]、数字经济政策[61]、人工智能政策[62]等开展了大量研究。有学者进一步将PMC指数与AE技术相结合构建PMC-AE指数模型,实现了对制造业创新政策[63]和军民融合政策[64]的深入挖掘和量化评价研究。基于政策文本内容的量化评价研究,指的是从政策本身出发对政策内容进行细分,设定量化标准以评价政策影响和政策效果,核心是政策工具理论。如Libecap为美国矿产权相关法规政策设定法律变革指数,选择了15个范畴来计算政策得分,这是最早的政策量化评价研究[65]。彭纪生等则基于政策工具理论构建了“政策力度-政策措施-政策目标”三维评价指标体系[66],并形成了一套具体的政策量化标准操作手册,被学术界广泛应用[67-68]。
3.3 政策立场研判和博弈关系研究
政策制定离不开政策主体之间的合作与博弈,政策文本作为政治思想观点的直接载体,通过政策文本量化研究识别政策立场、解析政策情感和判断政策倾向可以避免显性的政策冲突,促进政策完善与创新,同时也能更好地跟踪政策利益关系,精准预测政策未来发展走向。政策文本挖掘研究,尤其是政策情感分析广泛应用于西方政党选情预测和政策立场预判,核心在于通过收集开源的舆情文本,将公众政策意见与政党支持相关联,进而做出政策预测。如Ceron 等使用情感分析方法监测分析社交媒体中选民的政策意图,以判断选在竞选过程中投票倾向[69];Sudhahar 等利用文本挖掘的方法对 13万余篇关于美国总统大选的新闻文章自动解析产生了一个由关键政治参与者和问题形成的网络,可以自动提取和分析政治立场[70]。政策利益博弈研究是政策实施过程中多个利益者相互竞争或合作的结果,也是政策文本量化的重要应用领域。如Laver 等分析了法国政党宣言和总统演讲的内容分析,揭示了2002 年法国立法和总统选举中的政策竞争关系[71];孙涛等和温雪梅、陈宇等基于府际关系视角,对环境治理政策演变、政策行动和主体关系结构进行量化研究,分析了政府在区域环境政策执行过程中的利益博弈和行为偏差的产生机制[72-73];Sun和Cao从中国的创新政策文本中提取政府机构之间的结构关系,并利用社会网络分析方法量化分析了中国创新政策网络的演变过程,从政策议程、权力集中和异质性依赖等政策网络特征揭示政策制定机构间竞争与合作关系[74]。
通过以上分析可以发现,随着政策信息爆炸性增长、政策议题愈发复杂以及学科交叉现象凸显,政策文本量化研究已经广泛应用于政策制定咨询、政策比较评估和政策走向预测等政治活动领域。综合来看,在实际的政策分析研究开展过程中,多种量化方法的交叉融合使用为当前政策知识分析与发现提供了新的解决方案,有助于发现政策文本中隐藏的政策信息与内在逻辑、提升政策作用效果评估的效率和精细度、补充质化研究中察觉不到的演变轨迹并可视化呈现、验证带有主观色彩的思想观点输出与规律性预判等。
4 未来发展
立足政策信息学理论对政策文本量化研究方法及其知识发现研究应用进展进行系统的梳理和总结,可以发现数据驱动环境下的政策文本量化丰富了政策知识分析发现的研究范围和研究深度,极大程度上解密了政策制定“黑箱”、促进了政府科学决策。但同时基于结构化政策文本有限、文本量化方法宽泛等特点,当前学者大多集中在借助已有方法进行不同领域政策文本的知识分析发现实践,呈现应用研究有余、深层次创新不足、与实际政策问题融合不够的态势。基于此,本文提出以下发展建议。
4.1 建设领域政策大数据库及知识分析发现平台
政策数据库是政策文本量化分析的基础,没有规范化的政策领域大数据平台,就不可能支撑政策信息学发展及其领域知识发现。当前我国已经形成众多结构化政策数据平台,如北大法宝、中国科学技术信息研究所研发的科技情报成果与服务共享平台[75] 、中国科协创新战略研究院的政策法规库[76]、中国科学院文献情报中心的“科技政策汇”数据库平台[77]以及延伸发展形成的科技政策分析服务平台[78]等。但由于数据库构建、维护和管理成本的限制,其完备性、时效性和针对性都有所欠缺,政策研究者在研究实践中仍然需要自建数据库和语料库,在一定程度上会造成政策数据收集重复和冗余,以及人力和物力资源的浪费。因此,应当由国家机构进行宏观组织协调或者建立一个政策联盟,从上到下地进行宏观统筹和规划,将政策相关的全类信息汇总起来,促进数据整合与共享。特别是需要建设各个领域的政策大数据库和语料库,只有建设专业领域政策数据库才能支撑开展专业化的政策知识分析发现,为政策的精细化分析研究提供源源不断的知识供给。
4.2 开发针对性专门化的政策知识分析方法工具
政策文本与期刊论文、专利文献类似,具备基本结构要素和语义信息,但同时政策文本又有其自身独特性。首先,政策文本发布具备周期性,通常具有更高的知识密度,拥有更加规范的话语体系;其次,政策文本之间的关系更加复杂,基于政策引用、扩散和更新活动可能呈现出连续、组合和互补的网络结构;第三,政策文本基于其独特的政治属性,通常包含着丰富的语义信息,包括政治立场、政策倾向、政策价值、政策情感等。基于这样的特殊性,现有的分析技术方法和工具难以全面且恰当的应用于政策文本分析。这就需要注重政策分析的效度和信度檢验,并在不断借鉴其他学科方法的基础上结合政策文本特点进行整合和创新,设计和开发出适用于政策文本研究的针对性技术方法模块和数据分析工具包等,形成类似Citespace、VOSviewer类的开源软件,促进政策规律的探索发现和政策知识的挖掘分析。
4.3 开展领域政策问题研究与知识发现应用实践
政策文本量化研究是与政策分析密切相关的方法类研究范式,也是与实际应用需求紧密结合的研究领域,已经广泛应用于国际政策比较研究、智库政策思想输出和国家政策决策咨询活动。但在实践过程中,基于研究目标和身份角色的不同,政策分析者开展实践研究的角度与决策制定者之间往往是相对割裂的,很难同时兼顾理论研究和应用需求的二元统一。如利用计算机技术进行政策文本量化分析呈现时,更加注重技术创新和方法突破,结果往往是抽象的或数据化的,只有结合相关的应用背景进行解读才能完全理解。这说明政策文本量化研究绝不仅仅是利用一些新兴的方法和技术单纯的将政策文本作为研究样本,也不仅仅是为完成一项任务、工作和项目,而要以需求为引领、以问题为导向将定性研究和定量研究相结合开展政策分析实践,鼓励政策研究者与政策制定者充分交流合作,从而产生一些针对性的思想建议,为相关政策决策咨询提供服务和参考。
参考文献:
[1] 黄萃.政策文献量化研究[M].北京:科学出版社,2016.
[2] 付琳,张东雨,闫昊本,等.基于政策文本分析的中国碳减排政策工具研究[J/OL].科学学研究:1-19[2022-07-25].DOI:10.16192/j.cnki.1003-2053.20220627.001.
[3] Baker S R,Bloom N,Davis S J.Measuring economic policy uncertainty[J].The quarterly journal of economics,2016,131(4):1593-1636.
[4] Beauchamp N.Using text to scale legislatures with uninformative voting[J].New York University Mimeo,2011.
[5] Laver M,Benoit K,Garry J.Extracting Policy Positions from Political Texts Using Words as Data[J].American Political Science Review,2003,97(2):311-331.
[6] 曹玲静,张志强.政策信息学的发展与前瞻[J].图书情报工作,2021,65(21):38-50.
[7] 李江,刘源浩,黄萃,等.用文献计量研究重塑政策文本数据分析——政策文献计量的起源、迁移与方法创新[J].公共管理学报,2015,12(2):138-144.
[8] 黄萃,任弢,张剑.政策文献量化研究:公共政策研究的新方向[J].公共管理学报,2015,12(2):129-137,158-159.
[9] 裴雷,孙建军,周兆韬.政策文本计算:一种新的政策文本解读方式[J].图书与情报,2016(6):47-55.
[10] Wiedemann G.Computer-Assisted Text Analysis in the Social Sciences[M].Text Mining for Qualitative Data Analysis in the Social Sciences.Springer Fachmedien Wiesbaden,2016:17-53.
[11] Hollibaugh G E.The use of text as data methods in public administration:A review and an application to agency priorities[J].Journal of Public Administration Research and Theory,2019,29(3):474-490.
[12] Grimmer J,Stewart B M.Text as Data:The Promise and Pitfalls of Automatic Content Analysis Methods for Political Texts[J].Political Analysis,2013,21(3):267-297.
[13] 馬海群,张斌.我国政策计量研究:方法与模型[J].数字图书馆论坛,2019(5):2-8.
[14] 丁洁兰,刘细文,杨立英,等.科学计量方法在科技政策研究中应用的实证研究[J].图书情报工作,2017,61(24):77-86.
[15] BORNMANN L,HAUNSCHILD R,MARX W.Policy documents as sources for measuring societal impact:how often is climate change research mentioned in policy-related documents?[J].Scientometrics,2016,109(3):1477-1495.
[16] 余厚强,肖婷婷,王曰芬,等.政策文件替代计量指标分布特征研究[J].中国图书馆学报,2017,43(5):57-69.
[17] 余厚强,李龙飞.政策文件替代计量指标影响因素研究[J].情报理论与实践,2021,44(7):28-36.
[18] 卢小宾,霍帆帆,霍朝光.我国信息公开政策计量分析:权力主体、法律渊源与政策工具[J].情报理论与实践,2022,45(1):46-53.
[19] 冯昌扬,张佩玲.政策计量视角下的我国文化扶贫政策分析[J/OL].图书馆建设:1-22[2022-08-03].http://kns.cnki.net/kcms/detail/23.1331.G2.20220105.1732.004.html.
[20] 苏竣,黄萃.中国科技政策要目概览[M].北京:科学技术文献出版社,2012.
[21] 代欣玲,彭小兵,王京雷.中国情境下创新人才培养政策的文献计量分析[J].科研管理,2022,43(3):27-36.
[22] 赵洪,王芳,王晓宇,等.基于大规模政府公文智能处理的知识发现及应用研究[J].情报学报,2018,37(8):805-812.
[23] Piwowar H.Altmetrics:Value all research products[J].Nature,2013,493(7431):159.
[24] Somasundaran S,Wiebe J.Multi-Perspective Question Answer Opinion Corpus[EB/OL].[2022-07-20].http://mpqa.cs.pitt.edu/corpora/political_debates/.
[25] Somasundaran S,Wiebe J.Recognizing stances in ideological on-line debates[C].Proceedings of the NAACL HLT 2010 workshop on computational approaches to analysis and generation of emotion in text.2010:116-124.
[26] Proksch S O,Wratil C,W?ckerle J.Testing the Validity of Automatic Speech Recognition for Political Text Analysis[J].Political Analysis,2019,27(3):339-359.
[27] Hughes O E.Public management and administration[M].London:Bloomsbury Publishing,2017.
[28] KLEIN W R,LANKHUIZEN M,GILSING V.A system failure framework for innovation policy design[J].Technovation,2005,25(6):609-619.
[29] McDonnell L M,Elmore R F.Getting the job done:Alternative policy instruments[J].Educational evaluation and policy analysis,1987,9(2):133-152.
[30] PHAAL R,OSULLIVAN E,ROUTLEY M,et al.A framework for mapping industrial emergence[J].Technological Forecasting and Social Change,2011,78(2):217-230.
[31] HOPPMANN J,PETERS M,SCHNEIDER M,et al.The two faces of market support how deployment policies affect technological exploration and exploitation in the solar photovoltaic industry[J].Research Policy,2013,42(4):989-1003.
[32] 陳振明.政策科学:公共政策分析导论(第二版)[M].北京:中国人民大学出版社,2003.
[33] ROTHWELL R,ZEGVELD W.Reindustrialization and technology[M].London:Longman Group Limited,1985:83-84.
[34] 李浩,戴遥,陶红兵.我国DRG政策的文本量化分析——基于政策目标、政策工具和政策力度的三维框架[J].中国卫生政策研究,2021,14(12):16-25.
[35] 黄如花,温芳芳.我国政府数据开放共享的政策框架与内容:国家层面政策文本的内容分析[J].图书情报工作,2017,
61(20):12-25.
[36] 李煜华,张敬怡.先进制造业发展政策量化评价与优化路径[J].统计与决策,2022,38(10):175-179.
[37] 李鹏红.风险社会视角下公众参与土壤污染治理的政策文本分析——基于AHP-熵权耦合的综合评价[J].河北农业大学学报(社会科学版),2022,24(2):88-99.
[38] 李梓涵昕,周晶宇.中国孵化器政策的演进特征、问题和对策——基于政策力度、政策工具、政策客体和孵化器生命周期的四维分析[J].科学学与科学技术管理,2020,41(9):20-34.
[39] 李霞,陈琦,贾宏曼.中国智慧城市政策体系演化研究[J].科研管理,2022,43(7):1-10.
[40] 郭金龙,许鑫,陆宇杰.人文社会科学研究中文本挖掘技术应用进展[J].图书情报工作,2012,56(8):10-17.
[41] Miller G A.WordNet:An electronic lexical database[M].Cambridge:MIT press,1998.
[42] Ponte J M,Croft W B.A language modeling approach to information retrieval[C].ACM SIGIR Forum.New York,NY,USA:ACM,2017,51(2):202-208.
[43] 郑新曼,董瑜.政策文本量化研究的综述与展望[J].现代情报,2021,41(2):168-177.
[44] Zhitomirsky M,David E,Koppel M.Utilizing Overtly Political Texts for Fully Automatic Evaluation of Political Leaning of Online News Websites[J].Online Information Review,2016,40(3):362-379.
[45] 沈自强,李晔,丁青艳,等.基于BERT模型的科技政策文本分类研究[J].数字图书馆论坛,2022(1):10-16.
[46] 曲靖野,陈震,郑彦宁.基于主题模型的科技报告文档聚类方法研究[J].图书情报工作,2018,62(4):113-120.
[47] 刘建华,张智雄,张琴.基于多维政策实体及其关系的科技政策演化路径揭示方法研究[J].数据分析与知识发现,2019,3(5):57-67.
[48] Hopkins D J,King G.A Method of Automated Nonparametric Content Analysis for Social Science[J].American Journal of Political Science,2010,54(1):229-247.
[49] Sarmento L,Carvalho P,Silva M J,et al.Automatic creation of a reference corpus for political opinion mining in user-generated content[C].Proceedings of the 1st international CIKM workshop on Topic-sentiment analysis for mass opinion.2009:29-36.
[50] 张楠,马宝君,孟庆国.政策信息学:大数据驱动的公共政策分析[M].北京:清华大学出版社,2019.
[51] ISOAHO K,MOILANEN F,TOIKKA A.A big data view of the European energy union:shifting from a floating signifier to an active driver of decarbonisation?[J].Politics and Governance,2019,7(1):28-44.
[52] PRIOR L,HUGHES D,PECKHAM S.The discursive turn in policy analysis and the validation of policy stories[J].Journal of Social Policy,2012,41:271-289.
[53] HUANG C,SU J,XIE X,et al.A bibliometric study of Chinas science and technology policies:1949-2010[J].Scientometrics,2015,102(2):1521-1539.
[54] HUANG C,YANG C,SU J.Policy change analysis based on“policy target-policy instrument”patterns:a case study of china's nuclear energy policy[J].Scientometrics,2018,117(2):1081-1114.
[55] Arenal A,Feijoo C,Moreno A.Entrepreneurship Policy Agenda in the European Union:A Text Mining Perspective[J].Review Of Policy Research,2021,38(2):243-271.
[56] 江雨薇,陳君沂,林丽娇,等.政策计量视角下破除“唯论文”政策扩散的特征分析[J].情报理论与实践,2022,45(6):89-97.
[57] 王芳,徐路路.基于智能化公文主题分析的我国政策层级扩散倾向性研究[J].情报学报,2021,40(4):387-401.
[58] Estrada M A R.The policy modeling research consistency index(PMC-Index)[J/OL].[2022-09-23].https://www.researchgate.net/publication/228302925_The_Policy_Modeling_Research_Consistency_Index_PMC-Index.
[59] ESTRADA M A R.Policy modeling:definition,classification and evaluation[J].Journal of policy modeling,2011,33(4):523-536.
[60] 杜宝贵,陈磊.基于PMC指数模型的科技服务业政策量化评价:辽宁及相关省市比较[J].科技进步与对策,2022,39(1):132-140.
[61] 蔡冬松,柴艺琳,田志雄.基于PMC指数模型的吉林省数字经济政策文本量化评价[J].情报科学,2021,39(12):139-145.
[62] 任莎莎.基于PMC指数模型的北京市人工智能政策量化评价[J].全球科技经济瞭望,2021,36(10):54-62.
[63] 吴卫红,盛丽莹,唐方成,等.基于特征分析的制造业创新政策量化评价[J].科学学研究,2020,38(12):2246-2257.
[64] 王进富,杨青云,张颖颖.基于PMC-AE指数模型的军民融合政策量化评价[J].情报杂志,2019,38(4):66-73.
[65] LIBECAP G D.Economic variables and the development of the law:the case of western mineral rights[J].The journal of economic history,1978,38(2):338-362.
[66] 彭纪生,仲为国,孙文祥.政策测量、政策协同演变与经济绩效:基于创新政策的实证研究[J].管理世界,2008(9):25-36.
[67] 程翔,鲍新中.科技金融政策效率研究——以京津冀地区为例[J].北京联合大学学报(人文社会科学版),2018,16(3):116-124.
[68] 王帮俊,朱荣.产学研协同创新政策效力与政策效果评估——基于中国2006-2016年政策文本的量化分析[J].软科学,2019,33(3):30-35,44.
[69] Ceron A,Curini L,Iacus S M.Using sentiment analysis to monitor electoral campaigns:Method matters—evidence from the United States and Italy[J].Social Science Computer Review,2015,33(1):3-20.
[70] Sudhahar S,Veltri G A,Cristianini N.Automated analysis of the US presidential elections using Big Data and network analysis[J].Big Data&Society,2015,2(1):1-28.
[71] Laver M,Benoit K,Sauger N.Policy competition in the 2002 French legislative and presidential elections[J].European Journal of Political Research,2006,45(4):667-697.
[72] 孙涛,温雪梅.府际关系视角下的区域环境治理——基于京津冀地区大气治理政策文本的量化分析[J].城市发展研究,2017,24(12):45-53.
[73] 陈宇,闫倩倩,王洛忠.府际关系视角下区域环境政策执行偏差研究——基于博弈模型的分析[J].北京理工大学学报(社会科学版),2019,21(5):56-64.
[74] SUN Y,CAO C.The evolving relations between government agencies of innovation policymaking in emerging economies:a policy network approach and its application to the Chinese case[J].Research policy,2018,47(3):592-605.
[75] 中国科学技术信息研究所.科技情报成果与服务共享平台[EB/OL].[2022-07-24].https://www.chinainfo.org.cn/index.
[76] 中国科协创新战略研究院.政策法规库[EB/OL].[2022-07-24].http://dev.anylangtech.com/cnais-policy-web/#/homePage.
[77] 中國科学院文献情报中心.科技政策汇[EB/OL].[2022-07-24].http://gopolicy.las.ac.cn/service.
[78] 马雨萌,黄金霞,王昉,等.基于政策文本量化研究的科技政策分析服务平台建设[J/OL].情报科学:1-15[2022-07-27].http://kns.cnki.net/kcms/detail/22.1264.g2.20220617.1845.034.html.
作者简介:曹玲静,女,中国科学院成都文献情报中心、中国科学院大学经济与管理学院图书情报与档案管理系博士研究生;张志强,男,中国科学院成都文献情报中心、中国科学院大学经济与管理学院图书情报与档案管理系研究员,博士生导师。
