基于软硬件协同加速的关系网络推理优化方法①
2022-06-17张志超章隆兵肖俊华
张志超 王 剑 章隆兵 肖俊华
(*计算机体系结构国家重点实验室(中国科学院计算技术研究所) 北京100190)
(**中国科学院计算技术研究所 北京100190)
(***中国科学院大学 北京100049)
(****中国电子科技集团公司第十五研究所 北京100083)
0 引言
基于深度学习的卷积神经网络技术广泛应用于图像处理任务中,在大规模标注的ImageNet 数据集上提出的AlexNet[1]、VGG16[2]、ResNet[3]等大规模深度模型,展现了较高的识别准确率。然而,在少样本学习应用中,尤其是对新的未知类别分类任务中,需要新的学习模式和方法,包括Matching Nets[4]、Meta Nets[5]、MAML[6]、Prototypical Nets[7]、Relation Net[8]等少样本学习方法,通过构建多批次的不同类别任务对模型进行训练,引入支持集作为先验知识,用以处理未知类别任务的分类,关系网络[8](Relation Net)相对于其他模型[4-7],在Ominiglot[9]数据集和miniImageNet[4]数据集上取得了较高的识别准确率。
关系网络采用浅层卷积块的设计方式构建了特征提取模块和关系计算模块,通常的推理计算方式采用中央处理器(central processing unit,CPU)或者图形处理器(graphics processing unit,GPU)进行处理[8],使用CPU 处理速度较慢,使用GPU 处理能效不高。关系网络以及少样本学习技术[4-8]受限于少量样本在大模型网络的过拟合问题,通常采用浅层卷积块的方式构建特征提取模块和关系计算模块,计算复杂度和模型参数存储量相对较少,适合基于现场可编程门阵列(field programmable gate array,FPGA)处理的加速方式。
FPGA 由于其协助通用服务器进行高性能计算在亚马逊云计算数据中心[10]以及百度云计算数据中心[11]已经大规模部署,展现了高效能可重构计算的应用潜力。现有的基于FPGA 的加速处理卷积神经网络技术大多采用参数量化[12-15]等方式实现卷积神经网络计算加速,量化模型加速的方式通常对深度卷积大模型进行训练微调,而且会降低模型的精度,在浅层网络的量化加速问题上目前也缺少相关研究。基于FPGA 的浮点模型加速[16-23]采用循环优化、专用计算单元设计等方法,在一些卷积网络加速上取得了较好的计算效能。
针对关系网络推理计算的高效能处理需求,在不降低关系网络推理计算准确率的要求下,采用软硬件协同加速的方式解决处理效能问题。对于关系网络FPGA 片上计算单元设计采用高级综合(highlevel synthesis,HLS)循环优化、异构多核的方式在提升处理能效的同时提升处理吞吐量。
本文的主要贡献如下。
(1)提出了一种软硬件协同加速关系网络推理计算的方法,能够保持关系网络在实际应用中推理精度的同时,相对于GPU 平台处理达到较高的处理速度与处理效能。
(2)提出一种基于HLS 高级综合的方式优化卷积神经网络的卷积、池化以及全连接计算,通过设置不同的循环展开粒度,提升计算模块的并行度。
(3)提出了一种基于多核互联的加速器设计方法,避免由于单层卷积核过大造成的FPGA 大规模资源综合的时序收敛问题,从多核的角度提升了加速器的计算吞吐量。
1 关系网络推理优化方法
1.1 关系网络推理计算流程描述
典型的关系网络推理输入为支持集、测试图片,输出为关系分数,由多个支持集的关系分数最终选出测试图片的类别,同一张测试图片在不同的支持集相关的关系计算下会输出不同的结果。根据支持集的类别数(C-Way)、每类支持集的数量(K-Shot),可以构成不同的C-Way K-Shot 推理任务。关系网络推理计算包括两个模块的卷积计算部分,分别是特征提取模块和关系计算模块,主要由卷积计算、最大池化计算以及全连接计算组成。特征提取模块用于支持集和测试图片的特征提取,对于C-Way KShot 模式的支持集特征提取,K为1 时,输出为单张图片的卷积输出特征图;K大于1 时,则是多张图片的卷积输出特征对应元素累加值。经过特征提取模块提取了支持集特征和测试图片特征后,测试图片特征与支持集特征拼接起来构成输入特征图送入关系计算模块,分别计算特征的相似度为输出值,对于C-Way 的特征值,选取分数最大的作为该测试图片的类别输出。具体的关系网络推理计算流程如图1所示。

图1 关系网络推理计算流程
关系网络的推理计算中存在测试图片与多批次支持集之间的关系计算需求,关系分数的准确率以及置信度依赖于支持集数量的大小。多批次的支持集关系计算引入了非常大的计算、存储开销,基于通用的CPU、GPU 处理的关系网络推理计算速度慢、能耗较高,需要设计一个高效能的推理计算加速器来提升关系网络推理计算的效能。
1.2 基于软硬件协同加速处理的关系网络计算流程
针对关系网络推理计算速度慢、能耗高的问题,本文采用软硬件协同加速计算的方式提升处理速度与处理效能。通过CPU 或者GPU 提取可复用的支持集特征供推理计算使用,降低计算开销;采用HLS循环优化设计的特征提取模块以及关系计算模块,提升关系网络推理计算的速度与效能;采用异构多核的设计方式综合利用多核的处理能力进一步提升关系网络推理计算速度。
基于关系网络的C-Way K-Shot 分类推理任务采用X86/GPU 平台与FPGA 平台协同计算的方式进行加速计算。X86/GPU 平台用于支持集的特征提取,FPGA 平台用于测试图片的特征提取以及支持集特征下的关系计算。具体的基于软硬件协同加速处理的关系网络计算流程如图2 所示。

图2 基于软硬件协同加速处理的关系网络计算流程
通常一个关系网络针对一个任务数据集训练后,可以用于图像分类,甚至对未学习类别的图像分类。图像分类的关键是依赖于支持集的特征作为关系计算的判据输入,不同的支持集会对测试图片的分类结果造成影响,越多的支持集越有助于待测图片的分类准确率提升。
支持集一般是由专家标注的标准数据集,其分类标签是固定的,支持集特征可以利用X86 或者GPU 平台提前计算出,支持集特征构成支持集特征池,便于后续计算使用,同时节省计算时间与能耗。对于不同的C-Way K-Shot 任务,可以构建不同的KShot 特征池,在Omniglot 数据集下K为1、5 和20,在miniImageNet 数据集下,K为1 和5。
FPGA 计算流程采用离线支持集特征直接缓存到动态随机存取存储器(dynamic random access memory,DRAM)的方式节约支持集特征的计算时间与能耗,在片上配置特征提取模块和关系计算模块,根据计算速度的要求和片上资源的约束,构建不同大小的计算模块,多个计算模块配置成异构多核的方式协同加速,进一步提升推理计算能力。
1.3 基于HLS 循环优化的计算单元设计
关系网络采用多个卷积块、最大池化层以及全连接层构成特征提取模块和关系计算模块。本部分采用基于HLS 的优化手段对卷积、池化、全连接的计算循环进行展开优化,增加计算模块的并行处理能力,从而提升计算模块的吞吐量。对于特征提取模块和关系计算模块的多层计算采用数据流的优化方式构成一个计算单元,简化计算模块的核外调度处理,使得输入为图像或者特征图,输出为特征图或者关系计算分数。以下阐述卷积、池化以及全连接层的关键设计部分。
(1)卷积乘累加计算
卷积乘累加计算完成输入特征图与权重数据的卷积乘累加计算。卷积乘累加模块的计算输入为输入特征图,维度为IH × IW × IC,其中IH为输入特征图高度,IW为输入特征图宽度,IC为输入特征图通道数;以及权重数据,维度为OC × K2× IC,其中OC为输出特征图通道数,K为卷积核大小。输出为输出特征图,维度为OH × OW × OC,其中OH为输出特征图高度,OW为输出特征图宽度,OC为输出特征图通道数。
卷积乘累加计算模块包含多个处理单元(process element,PE),每个神经元内部按照单指令多数据(single instruction multiple data,SIMD)进行并行计算设计。输入特征图调度为P × S宽度的数据,其中P为PE 的个数、S为SIMD 的个数。每个PE 计算的输出为一个神经元的计算输出,PE 内部采取S个计算单元并行计算进一步提升并行数,S个相关的数据完成神经元内部的乘累加计算。卷积的权重调度为P × S宽度的数据,对应相应的特征图输入维度。具体的卷积乘累加计算如算法1 所示,具有5 重循环,其中针对P和S并行展开两重循环,对应的并行数为P × S,每个卷积层可以根据计算量的大小以及前后层的计算输入输出速度进行单独的PE 和SIMD 配置,在提升处理速度的同时尽可能节约片上资源数量。

(2) 全连接乘累加计算
全连接乘累加计算完成输入特征图以及权重数据的全连接计算,输出为输出特征图。全连接计算模块的输入特征图、输出特征图跟卷积计算模块保持一致,均为H ×W ×C的数据维度,其中H为特征图的高度、W为特征图的宽度、C为特征图的通道数。全连接计算可以抽象为K=1 的卷积计算,具体的全连接乘累加计算算法如算法2 所示,包含3重循环。该算法对PE 循环和SIMD 循环进行展开,设计为包含P × S并行度处理模块,每个PE 计算一个全连接神经元的输出,神经元内部具有S个乘累加单元并行计算。每个全连接层实例可以根据前后层的输入输出速度进行特定的PE、SIMD 数量配置,在满足处理的同时,节约片上资源消耗量。

(3)最大池化计算
最大池化计算完成输入特征图的池化计算功能,输入输出特征图与卷积层、全连接层保持一致,偏于多层网络组合为数据流调度的计算单元。最大池化计算算法如算法3 所示,包含6 重循环,只对最内层循环展开,展开数为P,即并行度为P,每个池化层根据计算需要单独配置。其中Pool_Size为池化大小,max 为选取最大值。输入特征图In 的数据经过输入调度满足伪代码6 重循环的计算要求。

1.4 基于异构多核的片上处理系统设计
关系网络的构建由基本的卷积块组成,卷积块由3 ×3 的卷积、BatchNorm 和Relu 计算模块组成,卷积块的输出为64 个神经元。特征提取模块由4个卷积块和2 个最大池化计算组成,关系计算由2个卷积块、2 个最大池化计算以及2 个全连接计算组成。全连接1 的维度为H×8,全连接2 的维度为8 ×1,最终输出为关系分数。具体的关系网络结构如图3 所示。对于Omniglot 和miniImageNet 2 个不同大小的数据集,其输入图片维度分别为28 ×28 ×1 和84 ×84 ×3,全连接中的H分别为64 和576。由于2 个数据集输入大小以及内部配置的差异,导致具体的各个模块计算量也不同,因此针对Omniglot 数据集和miniImageNet 数据集分别设计不同的加速器进行推理加速。

图3 关系网络结构
Omniglot 28 片上多核设计如图4 所示,包含控制接口、AXI(advanced extensible interface) 互联、DRAM 以及计算模块。计算模块包括特征提取模块以及4 个关系计算模块。控制接口完成主机的控制指令传输、数据传输功能,对具体的关系计算和特征提取模块进行控制。多个计算模块共享使用一个DRAM 的4 GB 内存空间,多个计算模块可以同时并行运行,利用多核能力提供更高的运算吞吐量。

图4 Omniglot 28 片上多核互联设计
Omniglot 28 加速器配置如表1 所示,为了描述简便,将特征提取模块和关系计算模块的P、S配置放在一个表格进行描述。特征提取模块包括cnv1至cnv4 部分,关系计算模块包括cnv5 至fc2 部分。通过设置P和S的大小可以控制每个模块的并行粒度,进而控制其吞吐量,但是受限于浮点数据的32 位宽度和P、S带来的大线宽、大规模计算矩阵导致其在Vivado 综合时序难以收敛,故采用多核的方式进一步利用资源提升吞吐量。Omniglot 28加速器的特征提取模块设计速度为2198.39 fps,关系计算模块设计速度为7430.56 fps,相关吞吐量数据是在214 MHz 主频下估算得到。

表1 Omniglot 28 加速器配置
miniImageNet 84 片上多核互联设计如图5 所示,包含控制接口、AXI 互联、DRAM 以及计算模块。计算模块包括1 个特征提取模块和2 个关系计算模块。
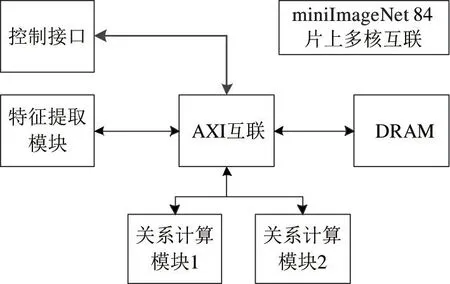
图5 miniImageNet 84 片上多核互联设计
miniImageNet 84 加速器配置如表2 所示,为了描述简便,将特征提取模块和关系计算模块的P、S配置放在一个表格进行描述。特征提取模块包括cnv1 至cnv4 部分,关系计算模块包括cnv5 至fc2 部分。通过设置P和S的大小可以控制每个模块的并行粒度,进而控制其吞吐量。miniImageNet 84 加速器的特征提取模块设计速度为221.02 fps,关系计算模块设计速度为642.78 fps,相关吞吐量数据是在214 MHz 主频下估算得到。

表2 miniImageNet 84 加速器配置
2 实验结果和分析
2.1 基于HLS 的计算模块资源占用与性能分析
关系网络加速器的PE、SIMD 配置后,可以进入HLS 进行仿真分析,从而获得每个模块的具体资源占用情况。实验所用HLS 为Vivado_HLS 2019.1版本,通过C 语言综合获得具体的加速器资源使用数据。使用的FPGA 开发板卡为VCU 1525 开发板,板载芯片为VU9P。
(1)基于HLS 的Omniglot 28 关系网络推理设计分析
通过HLS 对Omniglot 28 加速器进行分析,特征提取模块资源占用如表3 所示,其中BRAM 为块随机存储器,DSP 为数字信号处理器,FF 为触发器,LUT 为查找表,URAM 为超级随机存储器。由表3可知,片上资源占用各部分不超过10%,超级逻辑区(super logic region,SLR)资源占用各部分不超过31%,其中使用最多的资源为数字信号处理(digital signal processing,DSP)资源,由于使用的是浮点乘累加设计的加速器,DSP 资源使用相对多些。关系计算模块资源占用如表4 所示。由表4 可知,片上资源占比不超过7%,SLR 资源占比不超过22%。数据表明,设计的Omniglot 28 加速器资源占用量较少,能够顺利地被Vivado 工具综合实现为FPGA 比特流。
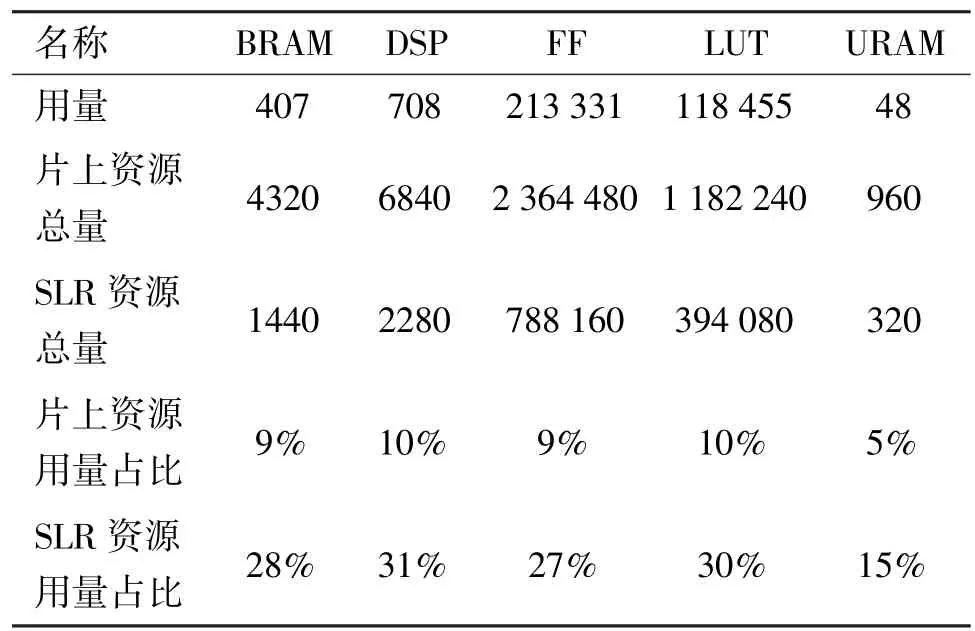
表3 Omniglot 28 特征提取模块资源占用表
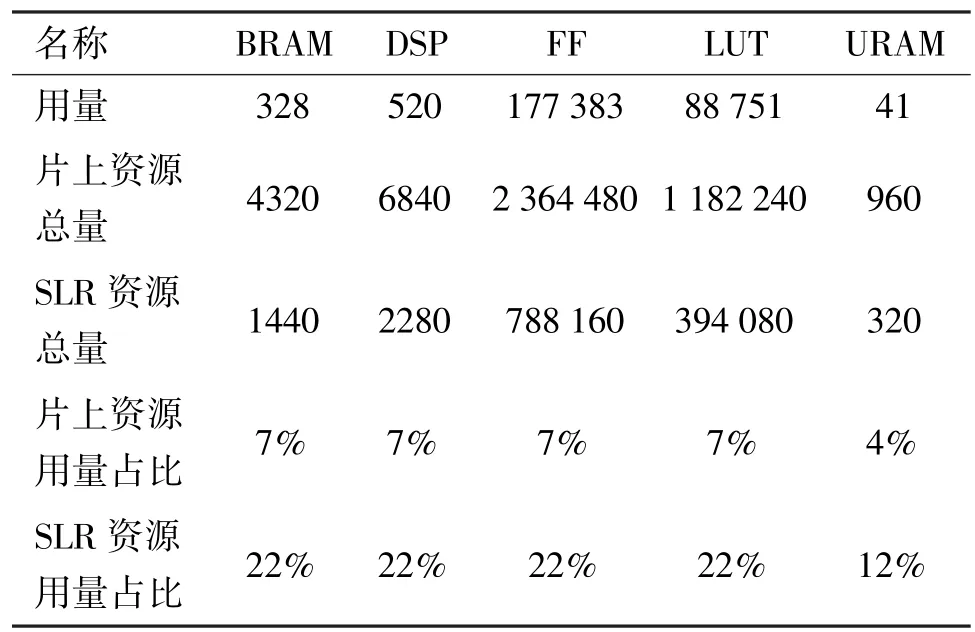
表4 Omniglot 28 关系计算模块资源占用表
(2)基于HLS 的miniImageNet 84 关系网络推理设计分析
通过HLS 对miniImageNet 84 加速器进行分析,特征提取模块资源占用如表5 所示。由表5 可知,片上资源占用各部分不超过10%,SLR 资源占用各部分不超过32%。关系计算模块资源占用如表6所示,片上资源占比不超过8%,SLR 资源占比不超过24%。数据表明,设计的miniImageNet 84 加速器资源占用量较少,能够顺利地被Vivado 工具综合实现为FPGA 比特流。

表5 miniImageNet 84 特征提取模块资源占用表
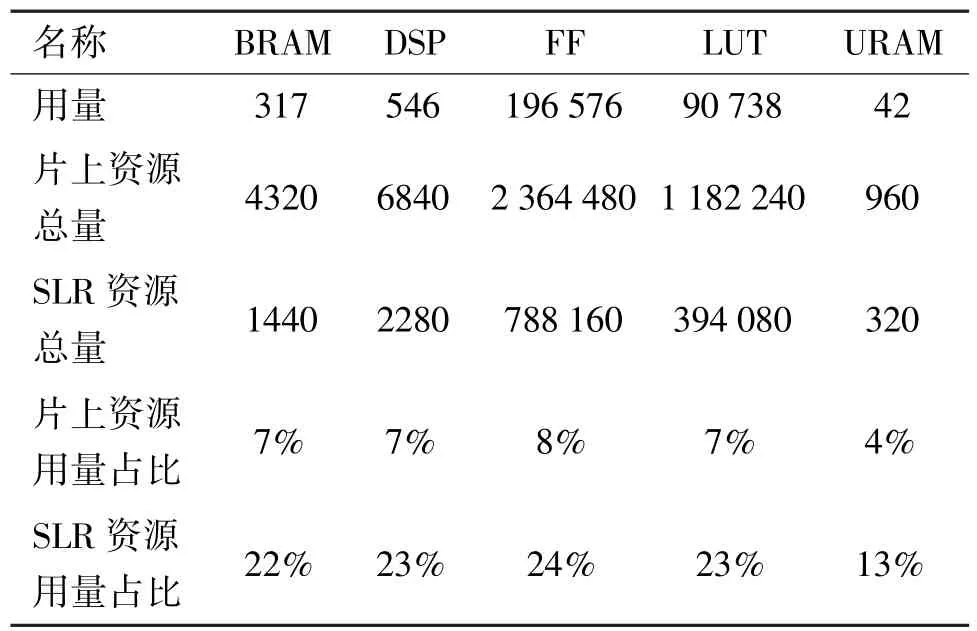
表6 miniImageNet 84 关系计算模块资源占用表
2.2 基于Vivado 综合后的推理设计分析
实验使用的Vivado 工具为2019.1 版本,对加速器的综合实现后获得资源占用及功耗数据。
(1)基于Vivado 综合的Omniglot 28 加速器资源占用与功耗分析
基于Vivado 的Omniglot 28 加速器资源占用如表7 所示,其中,LUTRAM 为基于查找表的随机存储器,IO 为输入输出,GT 为千兆位收发器,BUFG 为一般时钟缓存,MMCM 为混合模式时钟管理器,PLL为锁相环。由表7 可知,各部分资源占用约40%以下,能够在VU9P 芯片上综合加速器处理逻辑。具体的Omniglot 28 加速器功耗信息如表8 所示,片上功耗为15.867 W。
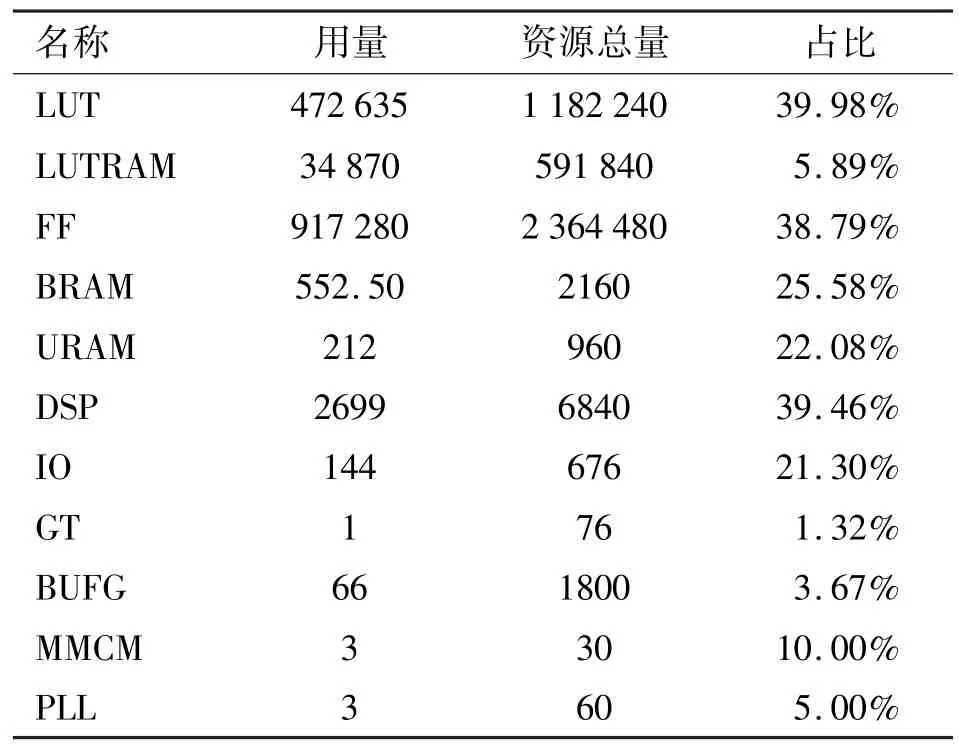
表7 基于Vivado 的Omniglot 28 加速器资源占用表

表8 基于Vivado 的Omniglot 28 加速器功耗分析
(2)基于Vivado 综合的miniImageNet 84 加速器资源占用与功耗分析
基于Vivado 的miniImageNet 84 加速器资源占用如表9 所示,其中各部分资源占用约30%以下,能够在VU9P 芯片上综合加速器处理逻辑。具体的miniImageNet 84 加速器功耗信息如表10 所示,片上功耗为15.359W。
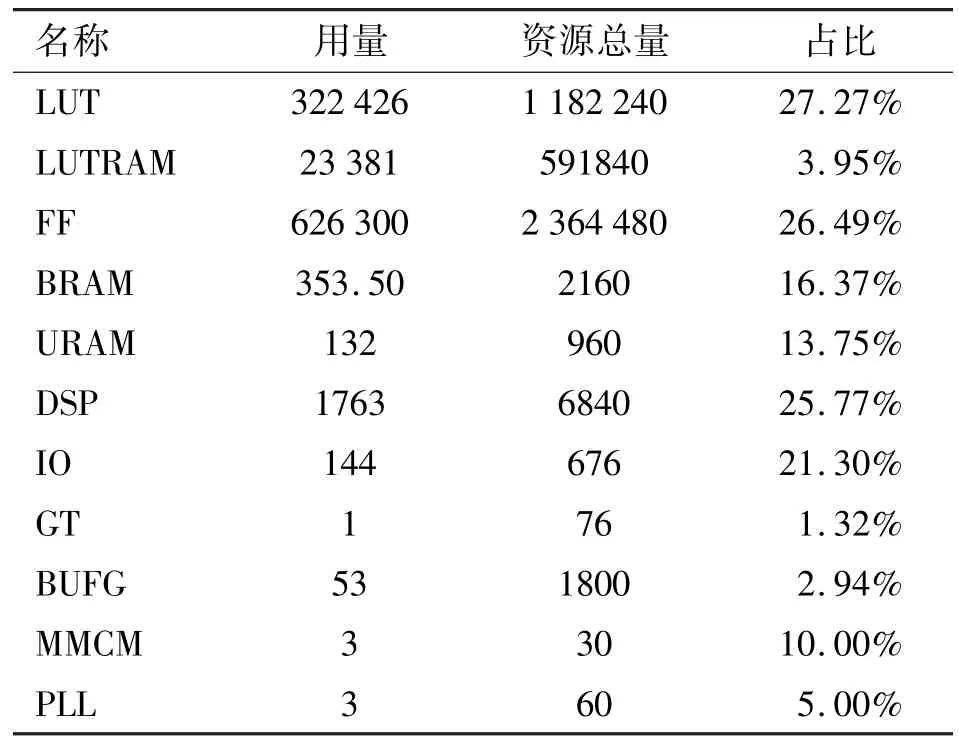
表9 基于Vivado 的miniImageNet 84 加速器资源占用表

表10 基于Vivado 的miniImageNet 84 加速器功耗分析
2.3 与FPGA 平台的推理效能对比
本文将关系网络推理加速器的性能与之前的FPGA 加速浮点卷积神经网络相关工作对比,具体结果如表11 所示。其中,文献[18,20]的工作采用了基于硬核浮点DSP 的Intel Arria 10 器件,吞吐量较高。除了采用浮点硬核加速的相关工作,本文提出算法的运算吞吐量达到了最高值,分别为Omniglot 28 加速器为147.79 GFlops,miniImageNet 84 加速器为99.89 GFlops;运算效能也达到了最高值,分别为9.31 和8.08 GFlops/W。实验结果表明,本文提出的基于HLS 循环展开优化的方法取得了较高的加速计算效能。

表11 FPGA 浮点加速卷积网络相关工作对比
2.4 与GPU 平台的推理效能对比
在GPU 平台上对关系网络推理进行了性能测试,实验硬件配置为E5-2650-v4 CPU 以及Nvidia Titan Xp GPU,软件配置为Ubuntu14.04,Cuda 版本为9.0.176,Python 版本为2.7,Pytorch 版本为0.3。基于GPU 平台和FPGA 平台对关系网络的推理效能进行对比分析,测试数据集包括Omniglot 数据集和miniImageNet 数据集,分别对相应的加速器进行吞吐测试。原始的关系网络测试代码用的是多批处理进行测试,批次大小为2500,每批次包含多个测试图片,用以复用支持集特征减少计算时间,具体的多批次对比测试结果如图6 所示。在Omniglot 数据集上实现了5-Way K-Shot 任务2198 fps 的吞吐量,20-Way K-Shot 任务1473 fps 的吞吐量,K为1 和5。在miniImageNet 数据集上实现了5-Way K-Shot 任务220 fps的吞吐量,其中K为1 和5。数据表明,多批次的吞吐量测试,FPGA 平台优于GPU 平台。

图6 多批次测试结果对比
考虑推理任务一般为小批次测试,本文进行了单批次吞吐量实验,具体结果如图7 所示。在Omniglot 数据集上实现了5-Way 1-Shot 任务1779 fps的吞吐量,5-Way 5-Shot 任务2101 fps 的吞吐量,20-Way 1-Shot 任务2075 fps 的吞吐量,20-Way 5-Shot任务1482 fps 的吞吐量,K为1 和5。在miniImageNet 数据集上实现了5-Way K-Shot 任务220 fps的吞吐量,其中K为1 和5。单批次的实验GPU 和FPGA 吞吐量性能都略有下降,较小的批次数据导致处理器的流水线调度的开销占比偏大,导致了处理效率的低下,但是FPGA 针对流处理进行了优化,其单批次吞吐量性能优于GPU 的单批次性能。

图7 单批次测试结果对比
根据实验数据,本文对关系网络实现的两个加速器Omniglot 28 和miniImageNet 84 与GPU 平台进行了功耗以及加速比分析,具体结果如表12 所示。GPU 平台功耗较高,约为150 W,FPGA 平台的Omniglot 28 加速器功耗为15.867 W,多批次加速比为GPU 的1.4~5.24 倍,单批次加速比为GPU 的2.5~17.2 倍;FPGA 平台的miniImageNet 84 加速器功耗为12.359 W,多批次加速比为GPU 的1.5~2.0倍,单批次加速比为GPU 的3.1~3.4 倍。结果表明,相对GPU 平台的关系网络推理过程,FPGA 加速器达到了低功耗高能效的预期效果,对于小批量的数据集FPGA 加速器比GPU 加速器更有性能功耗优势。
3 结论
本文提出的基于软硬件协同加速的关系网络推理优化方法,充分利用了关系网络浅层卷积设计模式带来的计算与存储优势,通过对卷积计算的HLS循环优化、异构多核协同处理以及GPU 预处理支持集特征等方法,降低了软硬件协同开发的耦合度,达到了高效能的关系网络推理计算的目的,同时保持了原有模型的准确率。随着深度学习技术的发展,越来越需要揭开深度学习的黑盒面纱,提升模型的可解释性,降低应用的难度,在少样本学习、元学习以及可解释性学习等方面开展更深入的研究。在研究高精度、少样本适用、可解释的识别算法的同时,体系结构研究者可以跟进研究相关算法的计算效能问题,进一步针对新的少样本学习、元学习等技术展开相关的效能计算研究。
