基于会话推荐的动态层次意图建模①
2022-06-17张梦菲金佳琪辛增卫方金云陈树肖
张梦菲 郭 诚 潘 茂 金佳琪 辛增卫 方金云 陈树肖
(*中国科学院计算技术研究所 北京100190)
(**中国科学院大学 北京100190)
(***国防大学联合作战学院 石家庄050084)
0 引言
基于深度学习的推荐系统已经成为学术界的研究热点[1],并在工业界的新闻[2]、视频[3]、广告[4]、兴趣点推荐[5]等多个领域普遍应用。作为推荐系统领域的一个重要分支,基于会话的推荐系统(session-based recommender systems,SRS)专注于解决如何根据当前匿名会话中有限的用户行为数据来预测用户下一次可能点击的物品(item,项)的问题。SRS 可以用在各大公司平台中为未登录用户或新用户提供推荐服务的场景中,具有重要的现实意义。
由于用户会话中只包含短时间内用户的点击行为信息,缺少历史交互数据以及用户侧的特征,以往的SRS 工作主要将按时间排序的物品序列作为研究对象。这些工作主要建模了会话中可能影响推荐性能的以下因素:(1)会话的序列模式[6-7];(2)物品之间的复杂转移性[8-9];(3)局部/全局兴趣[10-11];(4)协同会话信息[12-13]。总结这些方法,均是通过训练深度神经网络得到物品的嵌入向量表示(也称embedding 表示)和会话的单个兴趣向量表示。这些方法本质上都只是沿着图的边或在序列的时间轴上传播信息,称之为扁平化SRS 模型。扁平化模型倾向于推荐与历史物品有相似细节的物品,而忽略了会话中隐含的高层次意图信息。例如用户点击3个某品牌的电脑,再点击2 个键盘。现有模型根据长期兴趣和当前兴趣可能推荐其他相似的电脑或键盘,然而实际上,点击序列中组合物品的共性可以抽取出更一般性的意图(电脑和电脑配件),从而为用户推荐出更高层次意图下的其他品牌电脑、鼠标、转接头等物品。
本文认为用户的兴趣具有层次性[14]以及动态性特点,据此可以提高SRS 任务的推荐准确率。在一个真实点击序列中,用户通常带着一个较为宽泛的意图去点击不同风格的具体物品。自下而上、由细粒度到粗粒度的建模这种层次化意图能在模型不同层匹配不同粒度意图的物品,增加推荐的覆盖面以及多样性。然而以往的扁平化方法局限于推荐出最细粒度意图中细节相似的物品,无法解决因用户的下一次点击落入更宽泛的意图时造成的错误推荐问题。其次,层次化意图是非常普遍的现象,现实场景中不仅有类目-子类目的显式层次性结构,还存在隐式的层次关系(比如相似的风格、物品之间的隐性关联等)。最后,不同用户的行为是多种多样的,每个用户的兴趣也是动态变化的,基于传统卷积神经网络(convolutional neural network,CNN)的方法用静态的卷积核对所有会话的物品生成固定的卷积核参数,难以捕获不同用户动态演化的兴趣。
为了解决以上两个问题,本文提出一种基于动态层次意图建模的SRS 算法(dynamic hierarchical intent network,DHIN)。该算法自下而上动态学习序列中物品的共性,捕获不同粒度的用户意图。具体地,用动态卷积(dynamic convolution,DyConv)自适应地针对不同的输入动态使用卷积核来提取多尺度上下文窗口内的物品特征,而非以往用固定卷积参数处理所有输入的方式。为了形成由细到粗粒度的多层次意图表达,提出一个兴趣聚集门(interest cluster gate,ICG)来衡量卷积窗口内物品兴趣点的强弱,并将ICG 与动态卷积抽取的特征融合得到特定粒度的意图,由下自上传递。最后利用一个意图聚合模块输出包含多层次意图的会话表示用于生成推荐结果。与扁平化模型相比,层次化模型打破了平面化的用户兴趣建模方式。此外,为了约束意图的层次性,设计了一个新的上下位意图损失函数用于模型训练。本文的主要贡献总结为以下3 点。
(1)提出一种SRS 任务中层次性意图建模和动态会话学习框架,缓解了SRS 模型意图粒度单一的问题,提高了会话的表达和预测能力。
(2)提出一个自动学习点击子序列的兴趣强弱判断门ICG,同时融合ICG 与动态卷积模块提取的物品共有特征得到用户的层次性意图表达。
(3)提出基于动态层次意图建模的SRS 算法DHIN。在3 个真实数据集上的实验结果表明,DHIN 模型不仅在准确率上超过现有的工作,还在多样性指标和运行效率上表现优异。
1 相关工作
本节详细阐述与本文工作相关的历史工作,包括传统的方法以及基于深度学习的推荐算法。
1.1 传统的会话推荐方法
基于物品的推荐方法[15]是一个经典的推荐系统解决方案,它通过计算物品间的相似性来为用户推荐。Session-KNN[16]扩展了该模型,通过计算整个会话与其他会话的共现相似度来推荐。这两种方法都忽略了会话的序列行为信息。最近的传统方法基于时间序列和邻域感知的会话推荐(sequence and time aware neighborhood for session-based remommendation,STAN)[17]整合序列和时序信息到近邻推荐模型中,取得了显著的进展。除了以上基于近邻的方法,还有一类方法基于马尔可夫链,根据用户的当前动作预测用户的下一个行为。例如,基于因式分解个性化马尔可夫的下一个购物篮推荐(factorizing personalized Markov chains for next-basket recommendation,FPMC)[18]提出融合马尔科夫链和矩阵分解技术来捕获序列行为和用户的一般兴趣,比只考虑一般偏好的方法获得了更好的性能。
1.2 基于深度学习的会话推荐方法
传统的会话推荐方法无法充分识别序列信号和探索丰富的辅助信息。近年来,深度学习在推荐领域取得了巨大的成功。基于深度学习的会话推荐方法主要包括探索序列模式、局部/全局兴趣、物品之间复杂转换关系和协作信号等4 类方法。
近年来,基于循环神经网络(recurrent neural networks,RNN)的方法因其具有建模序列的能力而备受关注。RNN 推荐模型主要研究用户按顺序点击的物品之间的不断演化。文献GRU4Rec[6]提出将门控循环网络(gate recurrent unit,GRU)用于SRS 任务上,该方法首先将物品映射为低维稠密的向量,再将序列输入到GRU 中来学习用户兴趣随时间演进的过程。基于该工作,RNN+[7]提出4 种优化策略,其中数据增广策略对后续工作有深远的影响。基于神经注意力的会话推荐(neural attentive session-based recommendation,NARM)[10]提出将注意力机制融入到GRU 模型中来计算每个物品的重要程度,从而得到用户的主要意图。
文献[11]提出用多层感知机(multilayer perceptron,MLP)来捕获用户的全局偏好,最后一个物品表示为用户的当前兴趣。该思想启发了后续方法[8,10,12]将会话表示分为局部和全局表示,比如局部表示用经过神经网络编码的最后一个时刻物品的隐状态表示,全局表示则通过整个序列来表达。
近期,图神经网络(graph neural networks,GNN)受到了推荐系统领域研究人员的广泛关注。文献[8]创新性地将会话序列看成一个图结构,并用图表示算法来学习物品之间的复杂转移关系,取得一定进展。文献[9]通过保持图中边的顺序和增加图的快捷连接来处理损失编码问题和无效的长依赖捕获问题。传统基于邻域的推荐方法性能不佳,但与神经网络相结合,仍然可以提供有竞争力的结果。文献[12]利用协作信息中邻域会话的表示来更好地预测当前会话的意图。
1.3 基于多兴趣的会话推荐方法
另外一个与本文工作相关的是多兴趣推荐方法。与多层次意图推荐方法不同,该方法用于解决以往单兴趣模型无法充分表达用户不同兴趣的问题。文献[19](MCPRN 模型)认为每个会话由多个物品子集组成,并通过意图路由网络将每个物品分配到特定的RNN 通道中。文献[20](HLN 模型)则提出一个兴趣跳跃网络自动跳过不相关的物品,从而实现学习出不同物品子集的目的。
与多兴趣建模方法不同,这些方法将多个兴趣以扁平的方式依次拆分到多个通道中。然而,本文方法通过逐步发现用户点击行为之间的共性,对用户的多粒度兴趣进行分层建模,从而确保用户表示的准确性。
2 问题定义
定义I={i1,i2,…,iN} 表示SRS 中无重复的所有物品集合,称为物品字典(item dictionary,ID),其中N是物品的总数量。S=<s1,s2,…,s|S| >是所有的会话数据,对于一个长度为n的匿名点击会话si,按照时间排序之后,点击序列表示为si=[x1,x2,…,xt,…,xn],其中xt∈I指用户在t时刻点击的物品ID。本文的目标是构建一个模型并输出I中每个候选物品被用户在下一时刻点击的概率^y,最终将前K个预测分值对应的物品推荐给用户。通过比较^y与真实标签值xn+1来评估推荐系统的性能。
3 模型
3.1 模型总体架构
图1 给出了基于动态层次意图建模方法的会话推荐模型DHIN 整体框架。该方法能够自适应地建模每个用户的层次性意图表示。DHIN 包括多层网络结构,每层输出一种特定粒度的意图表示,自下而上,意图逐渐泛化。为了约束各层之间形成上下位关系的意图表示,另外设计了上下位约束损失函数。具体地,每层网络主要包含以下2 个模块。(1)动态卷积模块。该模块为了解决传统卷积操作对一次输入网络的多组会话使用相同卷积核参数,无法捕捉不同用户动态兴趣的问题,用动态卷积策略自适应地为会话生成不同的卷积核参数来提取当前层物品反映的兴趣特征。(2)兴趣聚集门ICG 模块。该模块能够识别当前卷积窗口内物品之间共性的强弱程度。二者点乘融合得到当前层具有共性的用户意图表示,并传递到上层。上层的感受野更广,更大窗口尺度的全局信息被考虑进来,能够捕获粒度更粗、更加宽泛的意图。最后模型通过聚合模块得到包含多粒度意图的会话表示,并生成推荐物品列表。

图1 基于动态层次意图建模方法的整体框架
3.2 嵌入表示层
由于原始物品ID 的表示能力非常有限,模型利用嵌入矩阵E∈Rd×N,将物品ID 转化为低维稠密向量。其中,d是向量的维度。首先将物品i(i∈I)编码为一个one-hot 向量(第i个值为1,其他值为0),然后物品i的嵌入向量表示为xi∈Rd。经过嵌入层的转换,输入表示为X=[x1,x2,…,xt,…,xn]。嵌入层的参数通过端到端训练的方式与模型其他层的参数一起学习。
3.3 动态多粒度会话意图提取
模型旨在识别每层会话中物品之间的共性特征,形成特定粒度的意图,同时每层都在前一层传递的序列基础上进行更粗粒度的意图建模。这种结构可以通过在捕捉层级结构信息上有天然优势的卷积神经网络来建模:在越来越广的上下文中提取层次化和更抽象的特征[21]。具体到每一层,模型均包含一个动态卷积运算和滑动窗口内的兴趣聚集门。动态卷积的优势在于为每个用户会话生成特定的卷积核,比如,对于两个意图分别是电子产品和衣服的会话,常规卷积方法使用相同的参数提取特征,而实际上,对不同的数据,特征的提取模式不同,动态卷积会针对不同序列使用不同的参数,从而真正实现个性化建模。具体实现上,受文献[22]启发,动态卷积使用一个注意力网络(attention network,Atten-Net)动态集成M个并行的卷积核为一个卷积核,生成只与当前输入Xl-1有关的卷积核,即:

同理,偏置同样通过线性聚合得到:


其中Watt1和Watt2分别是两个卷积核大小为1 的一维卷积,Watt1的输入输出维度为d,Watt2的输入维度为d,输出为M,batt1是可学习的偏置参数,*是卷积操作。经过两层网络之后得到矩阵A,A∈Rn×M。Pooling 操作将长度为n的序列A聚合为1,这里Pooling 是指平均池化或自适应平均池化等操作。最终经过式(5)的softmax 操作之后,算法生成
M个并行卷积核和偏置的注意力权重,共享该注意力权重。
接下来,使用该注意力网络生成的动态卷积核提取当前层候选意图表示:

其中,g 是激活函数(比如tahn、ReLU 等),*是卷积操作,是第l层经过意图特征提取的n个向量表示。分别是式(1)和式(2)中的一维动态卷积核和动态偏置,卷积核大小为k。Xl-1是上一层传递来的序列意图表示(起始第一层为输入层的物品序列)。为防止模型在t时刻看到未来的数据,以及保证输入输出长度均为n,每层输入都有一个k -1 大小的左侧补零操作。
以上动态卷积模块提取每层的用户兴趣特征之后,还需要ICG 模块将与当前层总体意图无关的特征过滤掉。ICG 控制了动态卷积模块每个卷积滑动窗口内抽取的多少特征传递到上层,过滤之后,物品的重要共性特征形成该层的通用意图表示。ICG 可以衡量窗口内物品间的关联性,如果各物品反映了用户相同的兴趣,那么物品的embedding 表示在向量空间中比较聚集,物品的共性比较强;反之,当物品组所表达的用户兴趣发生迁移时,物品之间共性比较弱,向量空间则比较离散。通过计算窗口内物品之间的相似度,得到一个k × k的大小相似度矩阵,并对矩阵的所有值取平均来表示该物品组的向量聚集程度。最后通过sigmoid 函数将其映射到0~1 区间得到该窗口的兴趣共性度。具体地,第t个卷积窗口内的共性度大小为

其中Kt∈Rk×d,Qt∈Rk×d是经过两个线性矩阵转换到兴趣空间的输入,Mt∈Rk×k是窗口内两两物品的相似度值矩阵。最后,ICG 与动态卷积抽取的特征通过点乘操作得到该层物品去除细节保留共性的粗粒度表示:

为了在每一层中生成一个聚合的意图表示,通过为每个物品表示分配不同的重要性,执行一个自注意力池化操作来聚合特定尺度的意图信息。第l层的注意力分数和意图表征定义如下:

其中q∈Rd,batt2∈Rd是学习参数,Watt3∈Rd×d是权重系数,Xl,t∈Rd是第l层t时刻的物品表示。
3.4 多意图聚合
最后,将多层意图向量融合,使得最后的意图表示包含多个粒度的用户兴趣,聚合方式定义如下:

其中Agg 是聚合函数,有多种实现,本文采用求和方式,并在4.7 节验证不同聚合函数的性能对比。
最后将意图表示输入到两层前馈神经网络(feed forward network,FFN)中以投影到高维空间。在高维空间中,兴趣表示向量的不同特征更容易区分,具体的FFN 操作为

其中LN 是归一化LayerNorm 操作,MLP 是两层全连接层。最后生成融合多种粒度意图的聚合表示用于模型的推荐。算法1 给出了基于动态层次意图建模的算法伪代码。

3.5 模型预测
根据每个会话的意图表示vs,为每个候选物品xi∈I生成一个意图匹配得分,并用softmax 函数将得分转化成推荐每个候选物品的概率:
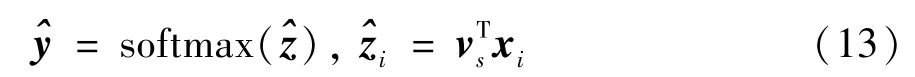
其中∈RN代表了所有物品的推荐概率值,本文通过优化概率最大的物品与实际下一个点击(也称为ground-truth)的交叉熵来训练模型。
另外,模型增加一个上下位损失函数用于优化上下层之间的关系。具体地,引入一个d ×d大小的矩阵Wtrans,来优化Wtransvl-1和vl的距离。为了保证上层意图包含下层意图,使每个会话的多个表示从上到下是由粗到细的上下位关系。最优情况下有一个矩阵可以使得Wtransvl-1=vl,即下位意图表示通过转换得到更粗粒度的上位意图表示,故通过尽量缩小二者的距离,可以让模型学到的用户多层意图之间具有上下位关系。具体模型损失函数为
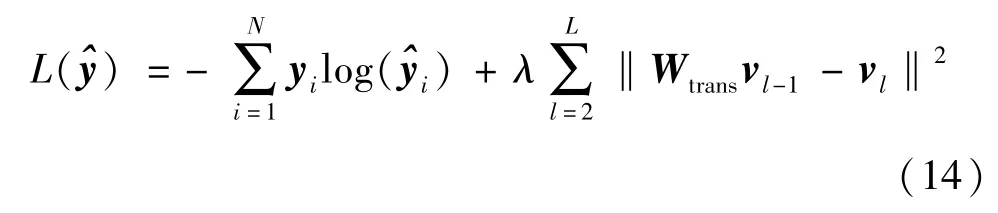
其中yi表示真实标签物品的one-hot 向量。
4 实验与结果分析
在本节中,在3 个数据集(Taobao、Yiwugo 和Diginetica)上进行详细的评估实验,并给出相关分析。
4.1 实验数据集
Taobao 和Diginetica 分别是CIKMCup 2016 和Alibaba 提供的2 个关于电子商务平台中零售用户点击行为的公开数据集。Yiwugo 是中国义乌小商品市场官方网站提供的关于批发用户点击行为的私有数据集。经过预处理,3 个数据集的统计数据如表1 所示。可以看出,Taobao 和Yiwugo 数据集包含比Diginetica 更多的类目,用户在会话中的兴趣更广泛,行为更复杂,而Diginetica 数据集中用户意图更集中。

表1 3 个数据集的统计情况
算法根据时间戳对每个会话中的物品进行排序。对Taobao 和Yiwugo 数据集,两个会话的时间间隔为20 min,并且控制每个会话的长度小于50。预处理操作过滤掉长度为1 的会话,并将Taobao、Yiwugo 和Diginetica 数据集中出现次数分别小于5、20、20 次的物品剔除。对Diginetica 数据集,将最后7 天的数据作为测试集,对Taobao 和Yiwugo 2 个数据集,将前27 天的数据作为训练集,后3 天的数据作为测试集。过滤掉测试集中未出现在训练集中的物品,对每个会话做数据增强处理,即对长度为n的会话序列生成n -1 条测试数据。比如在序列X=[x1,x2,…,xn]中,分别生成输入和标签:([x1],x2),([x1,x2],x3),…,([x1,x2,…,xn-1],xn),其中[x1,x2,…,xn-1]是输入,xn表示标签。
4.2 对比模型
为了验证模型的性能,本文将DHIN 与以下基线模型进行对比分析。
(1)S-POP :该方法直接推荐当前会话中热度最高的前K个物品。
(2)Item-KNN[15]:推荐与会话中最后一个物品相似的物品,相似度用两个物品向量的余弦距离来衡量。
(3)GRU4Rec[6]:该模型将序列输入到GRU中,为了提高训练效率,将不同的会话拼接起来,并用小批量样本进行学习。
(4)NextitNet[23]:将一维空洞卷积网络用于会话推荐,能在不增加参数的情况下更高效率地捕捉物品之间的长依赖。
(5)NARM[10]:该模型在GRU 网络中引入注意力机制,通过计算不同时刻隐状态的重要程度来衡量用户在当前会话的主要目的,同时结合GRU 建模序列行为进行推荐。
(6)SR-GNN[8]:该模型提出将会话数据构建为图结构,并利用图神经网络方法来更新物品的嵌入表示,捕获物品之间的复杂转移关系。最后融合会话图的表示和最后一个物品的表示进行推荐。
(7)LESSR[9]:为了解决图表示学习中的过平滑问题,该模型通过保留边的顺序以及添加必要的边连接,解决了以往基于图嵌入学习会话推荐中的损失编码和无效的长依赖问题。
(8)MCPRN[19]:该模型是一种多兴趣推荐方法,通过将不同的物品路由到预先设定的不同通道中,将每个通道视为一种用户兴趣,并把每个通道的物品输入到一个RNN 中来建模用户的兴趣表示。
(9)HLN[20]:不同于MCPRN 的多兴趣学习方法,该模型能自动将会话序列分成多组,并且每组子序列尽量保持与其他子序列的兴趣不同,从而使推荐的物品同时包含多种兴趣。
4.3 评价指标
在准确性方面,本文用经典的Recall@K(召回)和MRR@K(mean reciprocal rank,平均倒数排名)来评估模型,这两个指标在以往的工作中被大量应用。Recall@K是推荐列表的前K个物品中实际被点击的数量占所有标签数量的比例:

其中nhit是前K个物品中成功命中的物品数量,nlabel是测试集中的标签数量。MRR@K衡量推荐系统的排序性能,表示成功命中的物品在列表中的位置越靠前,该物品对推荐效果的贡献越大。计算方法如下:

其中Q是所有会话的数量,Rank是推荐列表中第一个出现在测试集中物品的位置。
在多样性评价方面,用推荐物品列表中物品类别分布的熵来度量多样性:

其中Pri是物品i所属类别的概率,通过计算该类别在数据集中的频率来得到。本文使用K=20 来报告表2 中的准确度评估结果,并使用K=10 以及K=20 来汇报图2 中的多样性评估结果。
4.4 实验设置
所有基线模型的参数和初始化策略与其论文中的表述一致,并在本文处理的数据集中进行模型优化。在DHIN 中,使用Adam 优化器,初始学习率设置为0.001,每3 轮训练后学习率衰减0.1。此外,批大小为100,物品embedding 维度大小d设置为100。其他超参数通过验证集来选择,验证集是从训练集中选取10%大小的数据。在DyConv 模块通道数设为100,卷积核大小k=3,注意力网络AttenNet的并行卷积核数量M设为2。卷积网络层数L对3个数据集分别设置为4、4、3。式(12)的Dropout 率设为0.3。MLP 网络大小为[100,200,100]。损失函数中的λ设为0.5,本文对模型进行3 次训练,并给出了3 次平均准确性和平均多样性结果。
4.5 与现有算法对比
表2 记录了DHIN 和其他基线方法在3 个数据集上的详细性能比较,最好的结果用黑体字突出显示,当前基线中的最好结果用下划线突出显示。可以得出以下结论。

表2 DHIN 方法在3 个数据集上与基准方法的对比实验结果
(1)本文提出的DHIN 模型在所有数据集上均优于现有的SRS 方法。在Recall@20 评测指标上,DHIN 相比最优基线模型在Taobao、Yiwugo、Diginetica 3 个数据集上分别提高了12.17%、6.38% 和4.95%。在MRR@20 指标上相对最优基线方法分别改善了6.75%、2.67%和6.12%。本文认为DHIN模型受益于两个方面的特点:1)层次意图的挖掘有利于命中用户在不同兴趣范围的意向点击行为。本文抓住了用户短时间内浏览网站时通常有一定目的的行为特点,为SRS 任务提供一种层次角度建模用户行为的新思路。2)本文有效建模了不同用户兴趣动态变化的点击行为,动态卷积模块的设计解决了以往CNN 模型(NextitNet)中固定卷积核捕捉用户静态偏好的劣势。与DHIN 比较,现有的工作忽略了以上两点重要因素,在召回和排序指标上表现均差于本文方法。综上所述,在3 个数据集上的实验结果表明了本文DHIN 模型的有效性。
(2)基于神经网络的方法在大多数情况下都优于传统方法,但在意图会话丰富的数据集上仍有改进空间。基于RNN 的方法(GRU4Rec、NARM)证明了RNN 在序列行为建模中的有效性。GRU4Rec 对会话进行编码,忽略了噪声项,这启发了后来的NARM 将注意力机制融入到RNN 中,取得了更好的效果。然而基于图神经网络的方法(SR-GNN、LESSR)由于其捕捉物品复杂转移关系的优势,性能整体上超过了RNN 模型。此外这些模型都没有充分发挥层次建模的优势。基于多兴趣的模型MCPRN 和HLN 在基线中表现良好,特别是在Taobao 和Yiwugo 数据集中,这与现实世界中用户行为复杂多变的情况是一致的。本质上,MCPRN 和HLN 都将序列中的不同物品分配到不同RNN 中,并受益于为用户区分不同的意图,却忽略了在一个简短的会话中多个意图可能存在隐含相关性。
4.6 层次意图学习的必要性
为了验证层次意图学习的必要性,本文对比了DHIN-1 和标准DHIN 方法在Taobao 和Diginetica 数据集上的实验结果,如表3 所示。

表3 层次意图学习的影响
其中DHIN-1 是将模型中层数设为1,其他参数不变,即只用动态卷积模块与ICG 门提取一次用户点击序列中的意图。可以看出模型性能下降明显,这表明单层意图建模不足以捕捉用户复杂的意图和兴趣,建模用户多层次意图表达有必要性。另外,DHIN-1 整体上仍然优于大部分现有的SRS 方法,这是因为本文提出的动态卷积模块和兴趣聚集门能够有效区分哪些物品反映了用户相同的兴趣,哪些物品是用户跨兴趣点击的,并提取了对下一次点击预测更有用的物品特征。因此,使用完整包含多层意图学习的模型具有更好的推荐性能。
4.7 关键模块对模型性能的影响
为了进一步探索模型中不同模块对性能的影响,本文设计了拆分各个模块的消融实验,结果如表4所示。其中:(1)DHIN 是标准模型;(2)DHIND 是指在相同条件下模型移除动态卷积模块,并用标准静态卷积核代替;(3)DHIN-G 是DHIN 在每一层去除ICG 模块,只用动态卷积核来抽取物品的特征。表5则是分析上下位约束损失对模型的影响,其中L-Rec 表示只用交叉熵损失训练模型,L-Rec +L-hier 则是交叉熵损失与层次约束损失组合,即DHIN 模型。
从表4 和表5 结果中可以看出,DHIN 在复杂和简单场景下的两个数据集上均优于3 个变体,DHIN-G 性能相较于其他模型性能下降最明显,其次是DHIN-D,最后是L-Rec。可以判断出对模型影响性能最大的分别是兴趣聚集门、动态卷积以及上下位约束损失。同时三者对模型均具有较大的重要性,需要3 个模块组合才能发挥出最大的优势,保证用户动态层次意图表示的准确性。

表4 不同模块对模型性能的影响

表5 层次约束损失对模型性能的影响
在多层次意图学习完成之后,如何聚合同样重要。本文对式(11)中的聚合函数进行分析,比较了取最上层(Last)、自注意力聚合(Att)、当前兴趣相关的注意力聚合(Att-GRU)以及默认求和(DHIN)4种多意图聚合方式,效果对比如图2 所示。
图2 中Att-GRU 是先将原始序列输入到GRU中编码,用最后时刻的向量表示与多层意图做注意力计算,保证融合的意图既有多粒度意图又与用户当前兴趣有关。可以看出,总体上Att-GRU 和DHIN效果相近,由于Att-GRU 考虑了当前兴趣,在排序指标上更优。另外,Last 方式效果最差,这是因为只选取最上一层的宽泛意图,忽略了细节与细粒度用户偏好,会造成错误推荐。为了简便计算,本文采用简单的求和方式融合用户多粒度意图。

图2 不同多意图聚合方式的对比
4.8 推荐的多样性指标分析
以往大多数SRS 模型只考虑准确性指标,而忽略了多样性对物品推荐也有重要作用。DHIN 可以使推荐列表包含多种意图层次的物品,因此能提高推荐的多样性。为了验证多样性指标,在3 个数据集上比较DHIN 与同样有利于多样性的多兴趣推荐模型MCPRN 和HLN。如图3 所示,DHIN 在Diversity@20 以及更严苛条件下的Diversity@10 多样性指标上均优于其他方法。多层次建模能够在更广范围的意图上匹配出符合用户兴趣的多种物品。假设用户先后点击了Nike 运动裤和Nike 运动上衣,多兴趣方法倾向于将两种偏好区分分别建模再融合两种偏好,匹配出同时包含两种偏好特征的物品,限制了匹配结果的范围。DHIN 则从意图粒度出发,找出两种偏好的共性,在更宽泛的意图表示下能计算出多样性更强的推荐物品列表。

图3 DHIN 与其他基线的多样性指标对比
4.9 参数敏感度分析
本节测试了在2 个代表性数据集Taobao 和Diginetica 上模型层参数L和并行卷积核参数M对模型性能的影响,准确率方面选取Recall@20 为代表性指标,多样性方面以Diversity@20 为衡量指标。
(1) 模型层数参数
Recall@20 和Diversity@20 两个指标随着模型层数L的变化趋势如图4 所示。可以看出,在复杂数据集Taobao 上,层数为4 时准确率最高,在Diginetica 数据集上,这个值则为3。之后随着层数增加,2 个数据集的准确率都轻微下降。多样性则随着层数增加一直增加,最后趋于稳定,层数越多代表模型学出的粒度越多,有利于推荐结果的多样性。
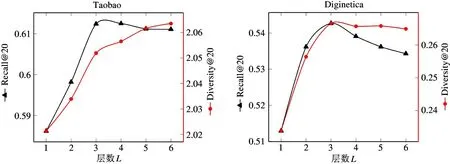
图4 层数L 对性能的影响
(2)并行卷积核参数
图5 展示了并行卷积核数量M的设置对模型准确率性的影响。可以看出,2 个数据集上M取2时都达到最好的准确率效果,当M为3 时多样性最佳。这表明适当的并行卷积核数量有利于学到不同用户的兴趣,提高实验性能。

图5 并行卷积核数量M 对性能的影响
4.10 ICG 可视化
为了解层次意图学习的效果,从Taobao 和Diginetica 数据集中随机选取一个会话来可视化每一层的ICG 分数分布。图6 显示了可视化结果,并有以下观察:
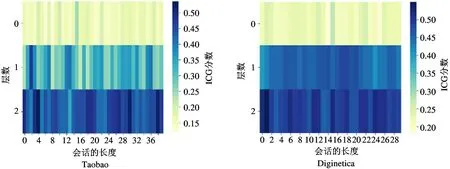
图6 ICG 在Taobao 和Diginetica 数据集的可视化
(1)在第一层,模型抽取的用户意图粒度较细,物品各具特色和风格,物品之间的共性较小。在每个窗口内ICG 的分布普遍较小。
(2)随着层数的增加,模型学到的粗粒度意图更宽泛,物品之间的注意力分数差异变小,窗口内物品的平均相似度更高,即ICG 门更大。这证明本文模型准确地捕获了从细粒度到粗粒度的多层次用户偏好。
4.11 模型性能效率
本文模型采用CNN 模型,并行计算可以节省大量的依赖计算时间。为了验证模型的运行效率,测试模型每轮的训练时间,并与当前最优的基线模型HLN 和LESSR 进行比较,结果如表6 所示。可以看出,基于RNN 的HLN 模型运行效率不佳,该模型需要在每层的序列计算中使用RNN,RNN 下一时刻物品的计算需要依赖上一时刻的状态,无法完成并行操作,并且在层与层之间,HLN 也存在依赖关系。基于GNN 的模型LESSR 在信息更新时采用GRU来聚合节点表示,故两个模型运行效率都低于本文模型。因此,DHIN 模型同时具备较好的准确性、多样性和时间效率。

表6 每个训练轮次的平均时间耗费对比
5 结论
由于会话数据的有限性和用户行为的复杂性,基于会话的推荐是一个具有实际意义和挑战性的问题。现有的研究大多集中在探讨诸如序列模式、物品转移关系、局部/全局兴趣和协作信号等因素上。然而,这些工作均未考虑用户的层次意图。本文提出一个动态层次化意图学习模型,该模型通过一个动态卷积神经网络提取出物品的共性特征,并通过一个兴趣门模块辅助决策哪些重要特征可以传递到下一层,从而逐步学习出针对每个用户的多种粒度意图。实验结果表明:本文提出的模型在3 个数据集上都达到了最优的性能,并且模型的多样性指标也高于其他模型,具有较高的可行性。
