面向物业投诉的字符级短文本分类模型
2022-06-16陈一飞
朱 明 陈一飞
面向物业投诉的字符级短文本分类模型
朱明 陈一飞
(南京审计大学信息工程学院,江苏 南京 211815)
文章针对物业投诉短文本人工输入内容复杂、提取特征较困难等问题,提出一种基于字符级文本表示的CNBG深度学习联合模型。该模型首先将物业投诉工单文本进行字符向量表示,然后分别输入到卷积神经网络CNN和双向门控循环单元BiGRU提取特征,并将它们提取到的特征进行融合,最后实现文本分类。实验结果表明,基于字符级CNBG深度学习联合模型在物业投诉工单分类任务上得到的比其它基准模型平均高15%,在物业投诉工单数据集上能够取得更好的效果。
自然语言处理;文本分类;字符级文本表示;CNBG深度学习联合模型
引言
随着中国城市化的发展,房地产市场异常火热,小区的物业产业也得到了更加广阔的发展。但是,在这繁华景象的背后,也随之而来出现了许多问题,关于小区业主投诉的问题日益增多。物业投诉工单主要是由业主自行输入投诉文本,并且反馈到物业投诉平台,它作为暴露小区问题最直接的投诉方式,已经成为了物业管理人员解决物业问题、提高物业管理质量的重要途径。因此,本文从物业投诉工单短文本方面着手,对物业投诉工单数据进行文本分类,通过分类结果对解决物业问题提出科学性的指导。因此如何准确地对物业工单数据的短文本进行分类,成为了本文研究的重点问题。
1 文献综述
短文本分类的研究一直是自然语言处理领域研究的热点问题。文本分类的一般流程如图1所示。
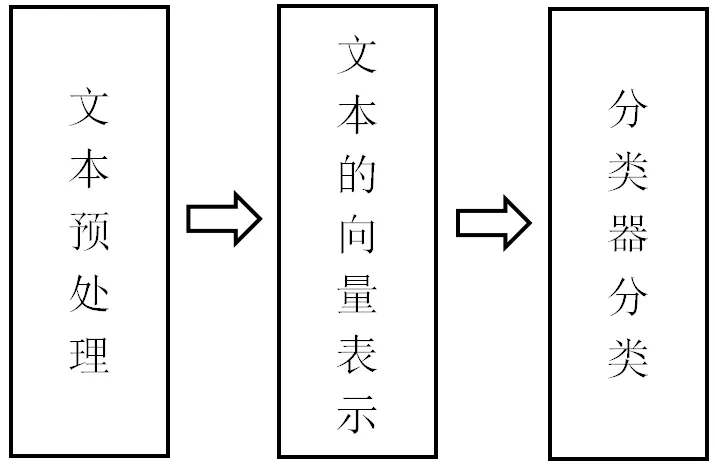
图1 短文本分类一般流程
文本分类模型的研究方法主要是基于传统机器学习模型和深度学习模型。在传统机器学习模型研究上,丁世涛等[1]通过词向量训练输入到SVM(支持向量机)模型进行文本分类,为网页分类任务提供了准确率更高、效率更高的解决方法。然而,例如支持向量机、朴素贝叶斯、决策树等传统的机器学习算法存在依靠人工标注特征、算法鲁棒性差等问题,无法应对目前大数据量和内容复杂的文本数据,而深度学习模型在解决这些问题上表现出更好的效果。张豪[2]针对恶意软件样本数据复杂等问题,采用一种融合恶意样本大小特征和字节统计特征的方法,输入到搭建的CNN(卷积神经网络)模型中进行训练、测试,实验结果表明深度学习CNN模型在恶意软件样本数据复杂的情况下得到的分类准确率更高。目前,深度学习模型在文本分类领域逐渐占据着主流,而深度学习领域的文本分类改进方向主要是基于短文本分类器模型的改进和基于短文本特征表示的改进。
1.1 基于分类器模型的改进
王东等[3]通过提取数据集中多标签短文本的不同特征输入到一种结合Stacking技术改进的RCNN模型,实验表明该种改进的RCNN模型能够快速、准确地完成多标签短文本自适应分类;代丽等[4]针对文本情感信息和文本内容词语分错问题,通过一种以一条通道构造情感类型信息,以另一条通道构造文本字向量信息组成的双通道CNN模型来进行文本分类,实验表明这种通过改进的双通道CNN文本分类器模型的实验效果要比未改进的模型好。以上两种是对卷积神经网络模型的改进,而卷积神经网络只对局部特征的提取较为有效,忽略了文本信息的全局特征的提取,单独使用会造成特征丢失问题;杨兴锐等[5]利用BiLSTM_CNN复合模型进行文本分类,通过与其它深度学习模型进行比较,这种复合模型在准确率和F1值均优于现有模型,但是BiLSTM模型本身的模型参数多,结构相对复杂,训练比较耗费时间,在实际使用的过程中效果并不是很好。
1.2 基于特征表示的改进
宋文琴等[6]针对旅游评论短文本短小导致的特征稀疏问题,利用一种融合知识增强语义表示预训练模型,加强了文本的特征表示,获得了较好的分类的结果;高娟等[7]通过全局与局部的词向量训练,并通过主题词相关进行词的语义增强计算,提升了模型在短文本上分类的正确率。以上都是基于词级别方面文本表征的改进,但是基于词级别文本表征主要存在两个缺陷:一是基于词级别的文本表示需要考虑词语的语义信息上下文之间的联系,需要使用预训练好的词向量模型,而预训练词向量模型和调用词向量模型会造成时间和硬件资源的浪费;二是短文本中的词语组成相对较少,利用词级别文本表示更难提取到文本特征。因此,Zhang等[8]将文本表示为字符向量的形式,用字符级文本表征的方式将数据集输入到CNN模型来进行文本分类,采用这种文本表示的方法在英文数据集上表现出很好的分类效果。由此开启了字符级文本分类的新探索。
针对基于分类器改进和特征表示改进两方面目前的研究进展以及存在的问题,并受Zhang等[8]利用字符级卷积神经网络进行英文文本分类的启发,本文提出一种基于字符级CNBG深度学习联合模型。利用字符级文本表示来代替词级别文本表示,可以忽略词语的含义,也不需要使用预训练好的词向量模型,减少资源浪费,且一定程度上缓解了OOV(Out Of Vocabulary)问题,而且利用单词、短语层面的文本表示会存在信息提取不充分的问题,采用字符级文本表示比词级别文本表示的粒度更小,更能充分获取文本信息。此外将BiGRU模型和CNN模型进行联合,一方面两种模型全局和局部特征提取能力较强,能够对文本的信息进行更加深层次的提取;另一方面使用BiGRU模型解决了BiLSTM模型参数多、结构复杂等问题,减少了训练时间,对模型训练效率的提升更有帮助。
2 字符级CNBG深度学习联合模型
2.1 整体架构
字符级CNBG深度学习联合模型整体架构图如图2所示。
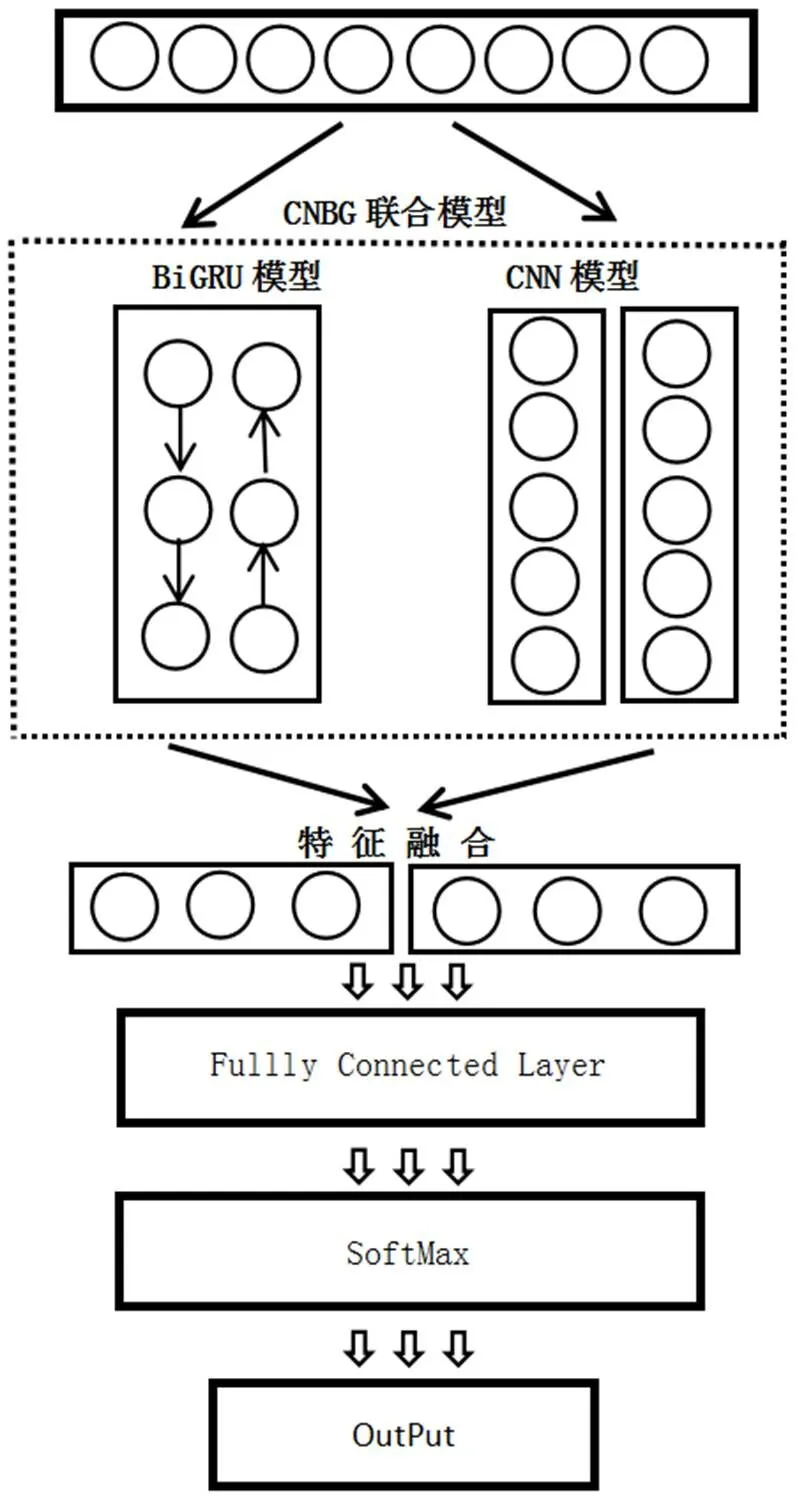
图2 字符级CNBG架构图
2.2 字符级文本表示
以Word2Vec[9]、Glove[10]等训练出的词向量模型,它们都是以词级别为基础,通过词向量形成句子向量的方式输入模型,且需要考虑词语的上下文的语义关系。字符级文本表示与词级别文本表示不同,它对文本表示的最基本的组成单位为字,字符级文本表示比词级别文本表示的粒度更小。字符级文本表示过程的算法伪代码如下所示。
算法1 字符级文本表示方法
输入:数据集S
输出:文本的字符向量表示K
1. Processed_text←text preprocessing o f S//文本预处理
2. Character_text←segmentation of Pro cessed text//分字处理
3. Char_list←Remove duplicate Charact er text //去重构建字汇表
4. for Character in Char_list:
Dic_list←According to the Statistical Character
end for//根据字汇表构建字典表
5. Dic_list←['
Dic_list←['
6. for Character_text in Dic_list:
Character_to_id←According to the Dic_list
end for//将数据文本按照字为单位分别对应字典表找到字符编码
7. K←According to the Character_to_id//根据每个样本的字符索引编码通过Embedding[11]转化为字符向量K
至此,通过字符级文本表示算法完成了由数据集S到文本字符向量K的转化。
2.3 卷积神经网络
CNN(Convolutional Neural Networ)卷积神经网络,它在图像应用领域得到了广泛的发展,后来用于NLP领域,在文本分类方面,CNN网络局部特征提取能力是最好的[12]。CNN架构图如图3所示。
2.3.1 卷积层
CNN中的卷积层目的就是提取出文本中的局部特征。文本中的每个字符向量的设定维度为50,采用三层卷积的方式。其中要设定的超参为卷积核的数目和卷积核的大小。卷积的过程如公式如下。
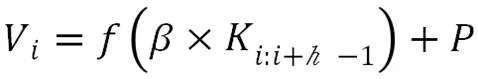
2.3.2 池化层
接着就进入了池化层(MaxPooling),它也称为下采样层。它的功能是特征降维,并且可以压缩模型运行中的数据和参数的数量,而其目的是为了减小模型过拟合,同时提升容错性。公式如下所示。
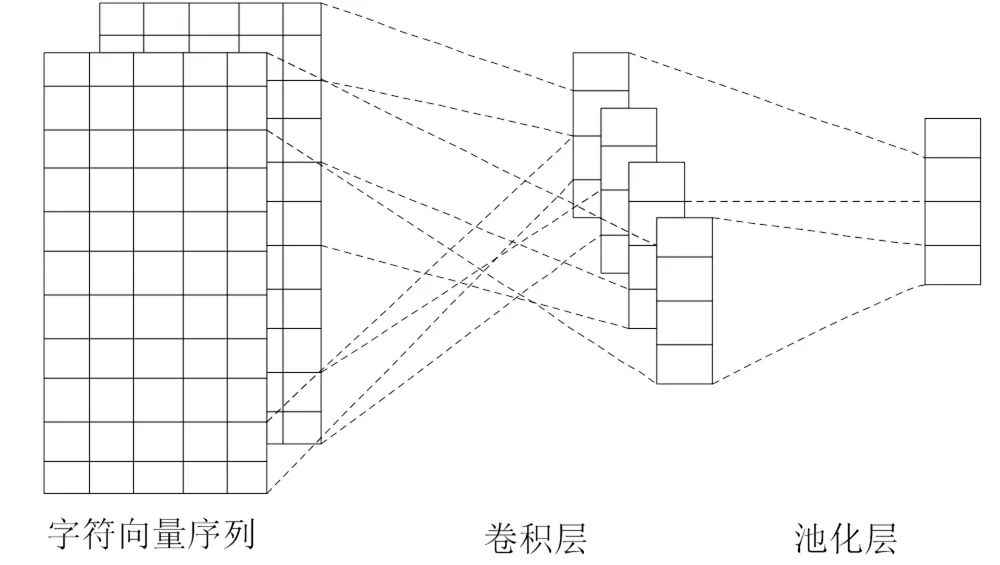
图3 CNN架构图
2.4 BiGRU模型
BiGRU(Bidirectional Gated Recurrent Unit)[13],是一种双向的门控循环单元模型。GRU的目的是提取句子上下文长距离的依赖特征,获取文本的全局特征。而BiGRU利用双向GRU模型,能够更深层次地提高对全文信息的特征提取。GRU的模型计算公式如下所示。
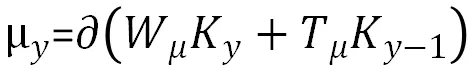
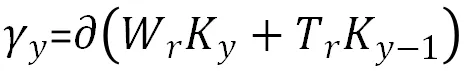
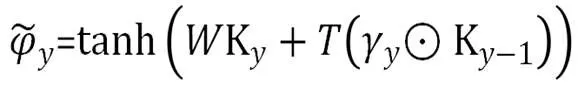
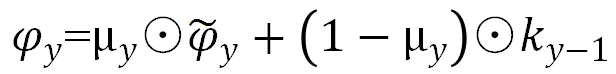
其中,和tanh分别表示为Sigmoid与tanh两种激活函数,μy和γy分别为更新门与重置门,对应模型超参为Cell_Size,ky为Y时刻输入的字符向量,ky-1表示的是上一状态输入的字符向量,代表的是元素的相乘,表示的是候选的状态,表示当前输出的全局特征向量。Wμ,Tμ,Wr,Tr,W,T为权值矩阵,GRU模型如图4所示。
其中,Sigmoid与tanh两种激活函数的数学表达式公式如下。
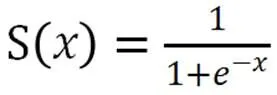

BiGRU是正向与反向GRU的结合,它在任意时刻都可以得到具有上下文相关性的文本特征信息,它的特征提取效果比单向GRU更好,更能够深层次提取到文本全局的特征信息。BiGRU模型图如图5所示。
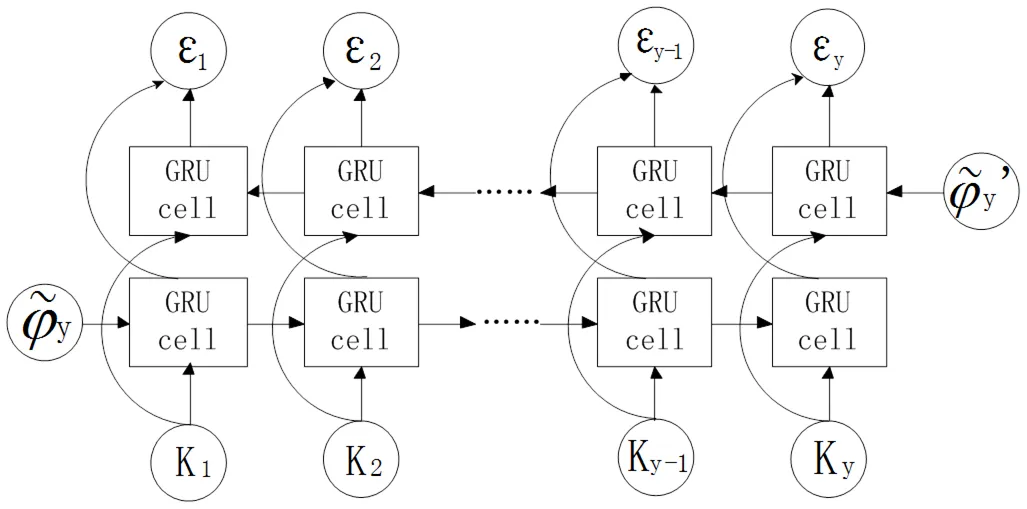
图5 BiGRU模型图
公式如下所示。
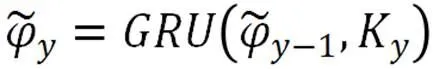
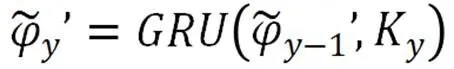
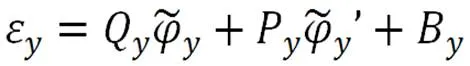
2.5 特征融合
将上述基于BiGRU的模型提取到的字符级文本的全局特征与基于卷积神经网络CNN提取到的局部特征进行局部特征向量和全局特征向量的融合,这样可以更加深层次的、全面的提取到数据文本的主要特征。特征融合如公式如下。


2.6 全连接层
随后进入全连接层,它将特征融合层的特征向量通过权值矩阵向量重组起来。全连接层使用Relu激活函数(Rectified Linear Unit,修正线性单元)和DropOut机制,DropOut为要设置的超参。使用的目的是为了加快模型运行速度并缓解模型的过拟合问题。公式如下所示。
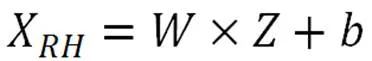
其中,表示权重,表示的是融合向量,为偏置矩阵,X而就为全连接层输出的结果。
2.7 输出层
最后用SoftMax函数(归一指数化函数)进行文本分类;SoftMax表达式如下所示:
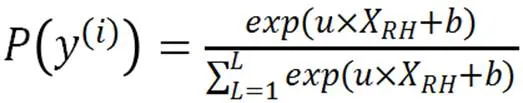
模型训练过程中用到的学习率(Learning_Rate)、批处理(Batch_Size)、迭代次数(Epochs)均为超参数,训练过程中用到的目标损失函数为交叉熵损失函数(Categorical_C-rossenTropy),如公式(15)所示:
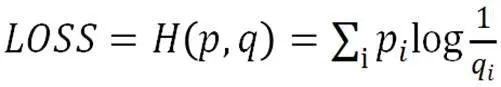
其中,为样本真实分布值,为估计分布值,而H()就是关于与的交叉熵。
3 实验与分析
3.1 实验数据
实验数据是爬取互联网上某服务平台公开的物业投诉工单数据集(http://fz12345.fuzhou.gov.cn/fzwp/webCitizenIndex.jsp),总共7个类别,分别有秩序管理、硬件设施维修、疫情防控、开发遗留问题、环境卫生、行政监管、服务态度等7个类别,总共13687条数据,将数据集去重过后共有8543条物业投诉数据。按照各个类别的训练集、验证集、测试集的顺序,划分数据集为5∶1∶1,得到训练集加验证集有7322条,测试集上有1221条工单数据。实验数据分布如表1所示。

表1 实验数据分布
3.2 评价指标
本次实验涉及到的评价指标有Precisio-n、Recall、F1,它们分别对应查准率、查全率、调和平均数,其值越高代表模型分类能力越好。它们的计算公式如下所示。
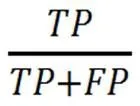
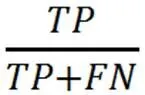
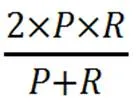
因为本次的各个类别的实验数据存在不均衡性,故本次采用国际评价指标中的微平均F值(F)作为模型的评价指标,其计算公式如下所示:
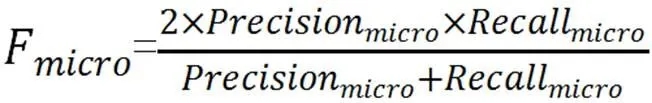
3.3 模型对照
为了验证字符级CNBG深度学习联合模型的预测能力,选取CNN、LSTM、BiLSTM、GRU、BiGRU、CNN-BiLSTM、CNN-BiGRU这7种基准模型来进行物业投诉工单数据集的训练、验证和测试,并在这些数据集上采用微平均F值(F)评价方式来和字符级CNBG深度学习联合模型进行预测效果的对比。
(1)CNN模型:采用三层卷积的架构方式提取字符文本的特征,最后用全连接层和Sigmoid激活函数作为输出层得到分类结果。
(2)LSTM模型:单向的LSTM模型提取字符文本特征,最后将得到的特征输入到全连接层,并用Sigmoid激活函数作为输出层最后得到分类结果。
(3)BiLSTM模型:利用双向的LSTM模型提取字符文本的特征,最后用全连接层和Sigmoid激活函数作为输出层得到分类结果。
(4)GRU模型:一种单向的门控循环单元模型,可以提取上下文长距离的依赖特征,获取文本的全局特征,最后将得到的特征输入到全连接层,并用Sigmoid激活函数作为输出层最后得到分类结果。
(5)BiGRU模型:一种双向的门控循环单元模型来提取字符文本的全局特征,最后将得到的特征输入到全连接层,并用Sigmoid激活函数作为输出层最后得到分类结果。
(6)CNN-BiLSTM模型:数据样本经过CNN提取到特征过后,再经过BiLSTM网络提取全局特征,最后用全连接层和Sigmoid激活函数作为输出层得到分类结果。
(7)CNN-BiGRU模型:数据样本经过CNN提取到特征过后,再经过BiGRU网络提取全局特征,最后用全连接层和Sigmoid激活函数作为输出层得到分类结果。
3.4 模型的超参设置
经过K折交叉验证(K取10)后,模型的具体超参设置如表2所示。
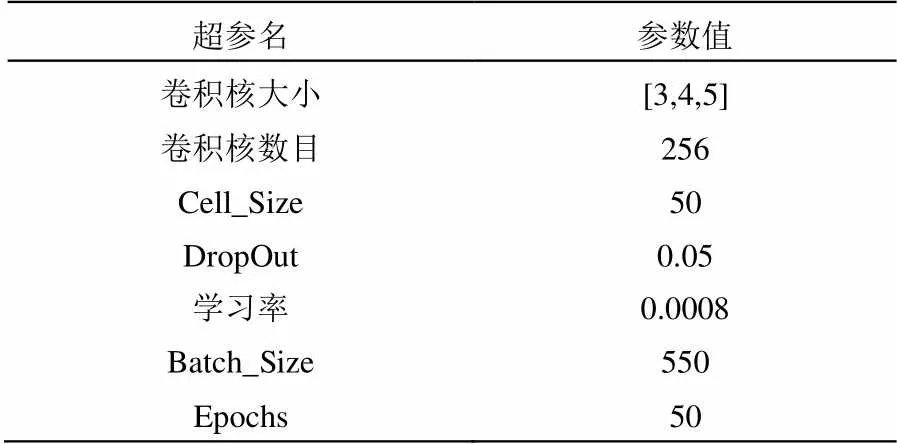
表2 模型超参设置
3.5 实验结果与分析
实验结果如表3所示。
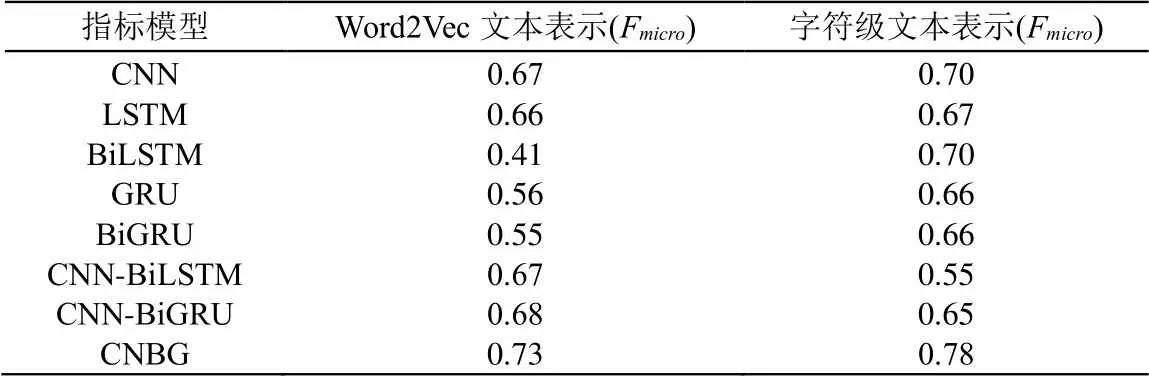
表3 实验结果
基于以上实验结果可以得到了两方面的结论:
(1)在文本内容的表征上,使用字符级的方式在CNN、LSTM、BiLSTM、GRU、BiGRU模型上的F均要优于Word2Vec文本表示的模型,分别高出0.03、0.01、0.29、0.10、0.11。主要因为物业投诉工单短文本内容短小,利用单词、短语层面的处理方式会存在信息提取不充分的问题,采用字符级文本表示比词级别文本表示的粒度更小,更能充分获取文本信息。基于词级别的文本表示需要考虑词语的语义信息上下文之间的联系,需要使用预训练好的词向量模型,而预训练词向量模型和调用词向量模型会造成时间和硬件资源的浪费。此外,基于词级别的文本表示很容易出现OOV(Out of Vocabulary)问题,而字符级文本表示无需考虑单词意义以及是否存在于词向量模型里,使用起来更加的便捷。因此采用字符级文本表示更加适合物业投诉工单短文本数据集。
(2)在模型的组合上,使用CNBG深度学习联合模型得到的F值要比CNN-BiLSTM和CNN-BiGRU的组合模型要高,其中采用Word2Vec文本表示方式分别高出0.06和0.05,采用字符级文本表示分别高出0.23和0.13。主要是因为CNN-BiLSTM和CNN-BiGRU模型由于经过了两层神经网络的特征提取,特征丢失较严重,而使用CNBG深度学习联合模型融合了CNN和BiGRU提取到的局部和全局特征,因此得到的特征更加全面,取得的F结果值要高于其它两种组合模型。使用CNBG深度学习联合模型得到F的值比CNN、LSTM、BiLSTM、GRU、BiGRU单一模型平均高出0.15左右,这是因为物业投诉工单短文本内容短小,采用单一模型较难充分提取文本信息,而CNBG深度学习联合模型利用CNN和BiGRU同时提取文本的局部和全局特征,这样能够更加深层次、全面地提取到文本信息,所以CNBG联合模型比其它的单一或者组合模型得到的结果要好,因此这里采用CNBG联合模型要优于其它模型。
综上所述,基于字符级CNBG深度学习短文本分类模型在物业投诉工单数据集分类结果上表现出更好的效果。
4 结束语
本次研究提出的基于字符级CNBG深度学习联合模型,采用字符级文本表示,它比词级别文本表示的粒度更小,更能充分获取文本信息。其次CNBG深度学习联合模型能全面深入的提取物业投诉工单数据的特征信息,有效解决了因为短文本内容短而导致特征提取较困难等问题。
除此之外,字符级CNBG模型因为不需要预训练好的词向量模型,在实验准备、模型运行上节省了时间和资源,训练快速且轻松;其次任何一种语言文本都是由字符构成,因此字符级文本表示适用于任何一种语言,它具有很强的适用性。
本次研究还有一些地方需要改进,具体如下:
(1)首先物业投诉工单数据集存在较严重的数据不均衡问题(各个类别样本数不均匀问题),后期可以从这方面考虑改进模型和相关策略,来进一步提高模型的准确度。
(2)因为短文本提供的特征相对较少,后期可以考虑从扩充语义信息(例如:知识图谱,Probase等语义特征扩展方法)的角度来进一步提高模型的准确度。
[1]丁世涛,卢军,洪鸿辉,等. 基于SVM的文本多选择分类系统的设计与实现[J]. 计算机与数字工程,2020,48(1): 147-152.
[2] 张豪. 基于CNN的恶意软件分类方法[J]. 计算机时代,2021(12): 48-51.
[3] 王东,夏梓渊. 基于改进RCNN模型的多标签短文本自适应分类[J]. 计算机仿真,2021,38(5): 388-392.
[4] 代丽,樊粤湘,陈思. 基于卷积神经网络的短文本情感分类[J]. 计算机系统应用,2021(1): 214-220.
[5] 杨兴锐,赵寿为,张如学,等. 结合自注意力和残差的BiLSTM_CNN文本分类模型[J]. 计算机工程与应用,2022(3): 172-180.
[6] 宋文琴,尚庆生,巩晴. 旅游评论短文本的改进ERNIE-RCNN模型分类[J]. 宜宾学院学报, 2021, 21(12): 53-56.
[7] 高娟,张晓滨. 基于语义增强的短文本主题模型[J]. 计算机系统应用. 2021,30(6): 141-147.
[8] Zhang X, Zhao J, Lecun Y. Character-level convolutional networks for txt classification[J]. MIT Press, 2015(28): 1626.
[9] 席笑文,郭颖,宋欣娜,等. 基于word2vec与LDA主题模型的技术相似性可视化研究[J]. 情报学报,2021,40(9): 974-983.
[10] 陈可嘉,刘惠. 文本分类中基于单词表示的全局向量模型和隐含狄利克雷分布的文本表示改进方法[J]. 科学技术与工程,2021,21(29): 12631-12637.
[11] 陶恺,陶煌. 一种基于深度学习的文本分类模型[J]. 太原师范学院学报(自然科学版),2020,19(4): 7.
[12] Alhudhaif A, Polat K, Karaman O. Determination of COVID-19 pneumonia based on generalized convolutional neural network model from chest X-ray images[J]. Expert Systems with Applications, 2021, 180: 115141.
[13] Zhang C, Wang D, Wang L, et al. Temporal data-driven failure prognostics using BiGRU for optical networks[J]. Journal of Optical Communications and Networking, 2020, 12(8): 277.
Character Level Short Text Classification Model for Property Complaint
Aiming at the problems of complex manual input content and difficult feature extraction of short text of property complaint, a CNBG deep learning joint model based on character level text representation is proposed. Firstly, the text of property complaint work order is represented by character vector, and then input into convolutional neural network CNN and bidirectional gated cyclic unit BiGRU respectively to extract features, fuse the extracted features, and finally realize text classification. The experimental results show that the joint model based on character level CNBG in-depth learning is 15% higher than other benchmark models in the property complaint work order classification task, and can achieve better results in the property complaint work order data set.
natural language processing; text classification; character level text representation; CNBG deep learning joint model
TP391
A
1008-1151(2022)04-0031-05
2022-02-20
朱明(1993-),男,南京审计大学信息工程学院在读硕士研究生,研究方向为数据挖掘。
陈一飞(1977-),女,南京审计大学信息工程学院副教授,博士,研究方向为数据挖掘。
