一种基于深度Q学习的移动自组网稳定路由
2022-06-16高翔马少斌张成文
高翔,马少斌,张成文
(兰州文理学院数字媒体学院,甘肃 兰州 730000)
认知无线电(cognitive radio,CR)技术允许未注册的节点以机会形式使用已注册的频谱资源。将CR应用于移动自组网(mobile ad hoc network,MANETs)[1],可以有效地提高MANETs的频谱利用率[2]。
然而,由于MANETs中设备移动性,如何有效地分配资源进而形成最佳路由是CR-MANETs网络亟待解决的问题。目前,CR-MANETs中多数路由是以泛洪方式在整个网络内寻找最佳路由,这消耗了大量资源,如控制开销、频谱、时延和能量[3]。
此外,由于物联网的快速发展,其对通信效率、时延和频谱资源的利用率提出了更高要求。为此,研究都对CR-MANETs的路由进行了大量研究。例如:文献[4]提出基于能效分簇的多跳路由;文献[5]提出基于分配集连通的簇路由,其通过构建稳定的簇,提高路由性能,如控制开销、数据包传递率和数据传输时延。
近期,为了提高无线网络的路由性能,研究者将深度学习算法应用于路由[6-8]。例如:文献[6]针对CR-MANETs网络,提出基于深度Q-学习的路由,旨在减少端到端传输时延;文献[9]提出基于Q-学习自适应路由模型(Q-learning based adaptive routing model,QLAR),其引用增强学习技术对节点的移动情况进行检测,进而使每个节点能够自动地更新路由指标。
作为增强学习的分支,博弈论成为构建簇的有效方法[2]。文献[2]提出基于博弈论的簇路由,其利用博弈论构建稳定簇,进而控制开销。
受上述文献的启发,本文针对CR-MANETs网络特点,提出了基于深度Q学习的稳定路由。本文的主要工作如下:(1)利用深度Q学习模型(deepQ-learning,DQL)建立低成本路由。通过节点队列尺寸空间和链路的连通时间构成链路成本;(2)通过DQL模型选择具有最小Q值的节点作为下一跳转发节点,形成稳定路由。
1 系统模型
考虑如图1所示的CR-MANETs网络模型,CR-MANETs由多个次级用户(secondary users,SU)和一个主级用户(primary user,PU)构成。由于PU的通信半径受限,它只有有限的通信区域。
将每个SU看成一个移动节点,并且SU遵照随机waypoint模型(random waypoint model,RWM)在二维平面内移动。图中的空心圆圈表示移动节点(SU)。
此外,假定节点通过全球定位系统[10]或者其他定位算法能够估计自己的位置和目的节点的位置。同时,假定每个节点有固定的通信范围。网络内的控制包沿着控制信道传输,其不影响PU的已注册信道的性能。本文引用两类控制包:RREQ和RREP。RREQ包表示路由请求包,即源节点向目的节点请求构建路由的控制包;RREP包表示路由回复包,即目的节点回复源节点的控制包,如图1所示。

图1 网络模型
2 DQLR路由
2.1 DQLR路由概述
DQLR路由按周期运行,且每个周期划分为路由建立阶段和数据传输阶段。在路由建立阶段,源节点通过传递RREQ包构建路由;在传输数据阶段,源节点依据已构建的路由向目的节点传输数据包。
2.2 路由建立阶段
若源节点需要向目的节点传输数据,且源节点目前没有通往该目的节点路由时,源节点就向其周围节点交互Hello包,进而与邻居节点建立邻居关系。
随后,源节点就产生一个RREQ包,然后将具有最小Q值的邻居节点作为最佳邻居节点(best neighbor node,BNN),并将RREQ包传输至此BNN。利用DQL模型计算邻居节点的Q值。
如果一个节点收到RREQ包,它就将发送节点作为上一跳节点存入路由表中。然后此节点再将此RREQ包转发至它的BNN,重复上述过程,直到RREQ包被传输至目的节点,如图2(a)所示。
一旦目的节点接收RREQ包,目的节点就沿着传输RREQ包的反向路径回复RREP包,直到RREP被传输至源节点,如图2(b)所示。
2.3 链路成本函数
DQLR路由依据节点的队列空间和链路的稳定计算链路成本。为了简化表述,令si表示源节点。Ni表示节点si的邻居节点集。对于Ni内的任意一个节点sj,源节点si链路li,j的成本:
(1)
式中:li,j表示由si与sj形成的链路;Qz(j)表示节点sj的队列空间;Qz,max表示最大的队列空间;r(li,j)表示链路li,j的稳定值;α1和α2表示权值系数,且α1+α2=1。
2.4 链路li,j的稳定值
假定节点的移动速度服从正态分布[11]。令ϑi表示节点si的移动速度。因此,移动速度ϑi的概率分布函数:
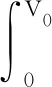
(2)
式中:g(ϑi)表示概率密度函数,则有
(3)
式中:μ,σ2分别表示速度的均值、方差[12]。
依据节点si与节点sj的相对移动速度,可计算链路li,j的持续时间ti,j:
(4)
式中:di,j表示节点si与节点sj间距离;Δϑi,j表示它们的相对速度。
结合式(6),计算ti,j的概率密度函数f(ti,j):
(5)

最后,依据式(6)计算链路的稳定li,j的稳定值[13]:
(6)
2.5 最小端到端成本
(7)
式(7)表示端到端成本。DQLR路由旨在建立从源节点至目的节点的最小端到端成本路由,将其称为最小端到端成本(minimum end-to-end cost,MEC)。
2.6 深度Q-学习模型
DQLR路由引用深度Q-学习选择下一跳节点。深度Q-学习算法主要由代理(Agent)、状态(State)、动作(Action)、环境(Environment)和奖惩函数(Reward Function)5个因素组成。Agent根据所在的状态,选择不同的动作,动作作用于环境形成奖惩函数。再依据奖惩函数,对动作进行修正。
Agent:在DQLR路由中,假定源节点旁边有一个机器人。该机器人在满足MEC条件下寻找通往目的节点的最佳路由。因此,将机器人称为Agent。
State:机器人拥有一个状态集S,其为节点集N。在特定时刻,如果机器人位于节点sk∈N,则认为机器人位于状态sk。
Action:若机器人移到节点sk,则此时它处于状态sk。令NBk表示节点sk的动态邻居节点集。机器人有|NBk|个选择移动的位置。因此,将NBk作为处于状态sk时Agent的动作集Ak,将sj∈Ak作为处于状态sk时的一个动作。
Environment:当Agent处于状态sk时,它具有一个环境,其包括网络内所有节点的位置、速度以及节点的队列尺寸。
Reward Function:当Agent处于状态si时,它选择一个动作sj∈Ai,所产生的奖励值:
(8)
式中:λ1,λ2为权重系数,且λ1+λ2=1;wgth表示跳数权重值,且wgth∈(0,1)。最初,λ1=1,λ2=0。随着深度Q-学习算法的迭代,源节点利用Q-值构建通往目的节点的路由。如果所构建的路由的跳数高于预定的路由跳数值hopthres,则对λ1和λ2值进行调整:λ1=λ1-0.1,λ2=λ2+0.1。
2.7 Q值的更新
当Agent处于状态si时,它选择一个动作sj∈Ai,它所形成的Q值:

(9)
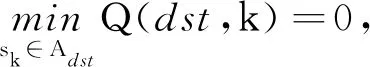
2.8 基于节点Q值的路由步骤
DQLR路由Q值选择下一跳节点,该Q值包含了基于队列尺寸和链路稳定性的成本值。网络内每个节点依据以下流程执行:
Step 1:如果节点si是源节点,其就进入Step1.1,否则就进入Step2。
Step1.1:如果源节点si需要向目的节点dst传输数据Data,si就广播请求包(Request Information Packet,RIP)获取邻居节点的位置、速度以及邻居节点的队列尺寸,再进入Step1.2。如果源节点si不需要向dst传输数据包,就直接进入第3步(Step3)。
Step1.2:源节点si就计算邻居节点的成本值,并从邻居节点中选择具有最小Q值的节点,将此节点作为下一跳邻居节点(假定是节点s*)。源节点si就向节点s*传输RREQ包。然后进入Step3。
Step2:如果节点si不是源节点,就进入Step2.1,否则就进入Step2.3。
Step2.1:如果节点si从源节点接收了RREQ包,它就记录发送节点(源节点)的ID,并将其作为自己的上一跳节点,然后节点si就向邻居节点广播RIP包,进而获取邻居节点的位置、速度以及邻居节点的队列尺寸,并进入Step2.2。
Step2.2:节点si就计算邻居节点的成本值,并从邻居节点中选择具有最小Q值的节点,将此节点作为下一跳邻居节点,并向此节点传输RREQ包。然后进入Step3。
Step2.3:如果目的节点dst接收一个RREQ包,就将产生RREP,并向源节点回复RREP包,再进入Step4。
Step3:如果节点si从目的节点dst接收了RREP包,就进入Step3.1,否则就进入Step4。
Step3.1:如果节点si不是源节点,它就将RREP转发到它的上一跳节点,并记录传输RREP包的ID,并将其作为自己下一跳转发节点,再进入Step4。若节点si是源节点,就进入Step3.2。
Step3.2:节点si是源节点,就将传输RREP的发送节点作为自己的下一跳节点,并将写入路由表,将数据Data传输至该下一跳节点,再进入Step4。
Step4:路由结束。
3 性能仿真
3.1 仿真环境
为了更好地分析算法性能,利用SimPy仿真框架建立仿真平台。50个移动节点(SUs)和一个PU分布于1 km×1 km的区域。移动节点依据RMM模型在区域内移动。令ϑmax表示最大的移动速度。仿真区域为1 km×1 km;移动节点数为50个;节点通信半径和PU的通信半径均为250 m;数据包到达队列率为10 packets/s;学习率为0.9;仿真时间为1 000 s。仿真参数如表1所示。每次实验独立进行20次,取平均值作为最终的实验数据。
此外,选择LSR路由[13]和QLAR路由[9]作为参照,并与 DQLR路由进行性能比较,分析它们时延、开销和数据包传递率性能。
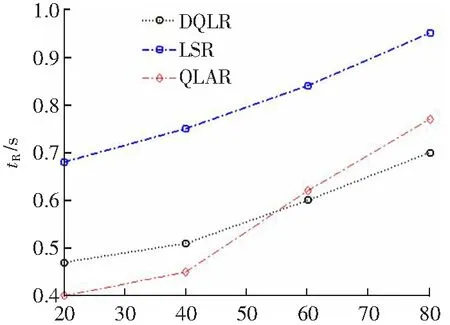
3.2 路由时延和队列时延的性能
图3、图4分别给出DQLR路由、QLAR路由和LSR路由的路由时延tR和队列时延tQ随ϑmax的变化情况。从图3可知,ϑmax值的增加,增加了路由时延和队列时延。原因在于:ϑmax越大,节点移动越多,降低了路由的稳定性。

ϑmax/(km·h-1)
ϑmax/(km·h-1)
此外,相比于LSR路由,DQLR路由降低了路由时延和队列时延。这主要是因为:DQLR路由利用通过选择满足MEC条件的节点作为下一跳转发节点,降低了时延。而LSR路由采用泛洪RREQ包构建路由,其需用更长时延构建路由。同时,LSR路由在选择下一跳转发节点时并没有考虑链路的稳定性,增加了构建路由的频率。
在ϑmax较小时,DQLR路由的时延性能劣于QLAR,但是当ϑmax在逐步增加时,QLAR的时延随之快速增加,并高于DQLR路由。原因在于:QLAR路由需要检测节点的移动速度,并动态地调整路由指标。节点移动速度越大,检测难度越大,必然增加了处理时延。
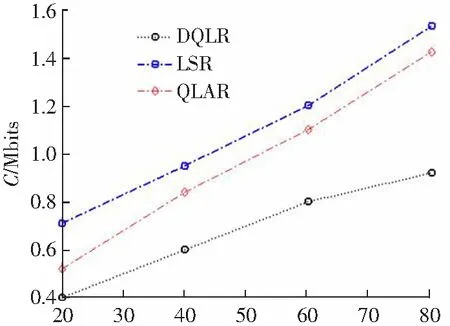
3.3 数据包传递率和控制开销
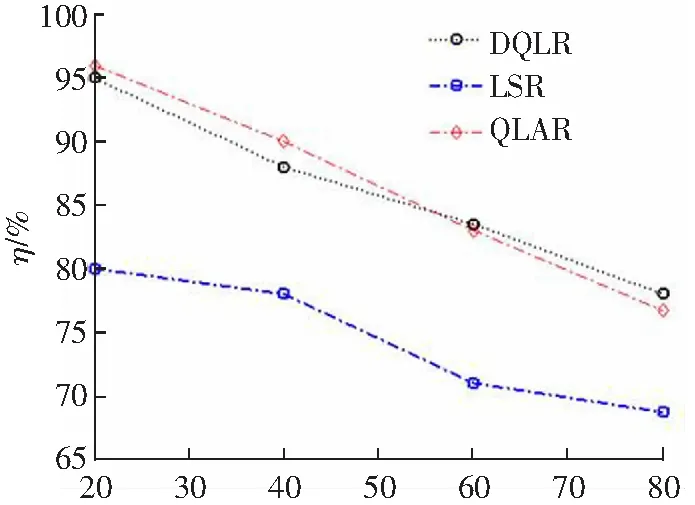
图5、图6分别给出DQLR路由、QLAR路由和LSR路由的控制开销C和数据包传递率η随ϑmax的变化情况。
ϑmax/(km·h-1)
ϑmax/(km·h-1)
从图5可知,控制开销C随ϑmax的增加而上升。这主要是因为:ϑmax值的增加,路由的连通时间短,需要频繁地构建路由,这增加了路由开销。但相比于LSR路由和QLAR路由,DQLR路由有效地降低控制开销。原因在于:DQLR路由是利用单播方式向下一跳转发节点传输RREQ包,而LSR路由采用泛洪方式传输RREQ包。QLAR路由需要检测节点的移动信息,这增加开销。
此外,从图6可知,ϑmax的增加降低了数据包传递率,这符合逻辑。节点移动速度的增加,降低了路由的稳定性,最终降低了数据包传递率。QLAR路由和DQLR路由的数据包传递率η相近。在ϑmax较低时,QLAR路由的数据包传递率略优于DQLR路由。但随着ϑmax的增加,QLAR路由的数据包传递率逐步低于DQLR路由的数据包传递率。这主要是因为:ϑmax越大,QLAR路由需要实时地调整模型,更新路由指标。
4 结语
针对认知无线电-移动自组网的路由问题,提出基于深度Q学习的稳定路由DQLR。DQLR路由通过深度Q学习模型选择最低成本的节点作为下一跳转发节点,提高了路由的稳定性。仿真结果表明,DQLR路由降低了控制开销以及路由时延,并提高了数据包传递率。
