基于YOLOv5的试管检测算法
2022-06-16任克勤陶青川
任克勤,陶青川
(四川大学电子信息学院,成都 610065)
0 引言
试管是一种重要的通用医疗器具,新冠疫情带来的大批量检测需求,对试管批量检测自动化提出了要求,部分检测任务如计数、分类等机械、枯燥,耗费人工且易出错,计算机视觉的快速发展使得基于机器视觉的检测方法替代人工成为可能。试管批处理的第一步是从试管架上识别单根试管,然后再进行后续检测项目。传统方法主要通过滤波失真矫正、边缘检测、模板匹配等来识别试管,其抗干扰能力和泛化能力都较弱。基于卷积神经网络的目标识别算法通过对数据集的学习可以很好地提取目标的特征,但现有的目标识别算法存在模型大、检测速度慢,实际部署需要GPU 导致硬件成本高的问题,需要做轻量化改进,减少模型大小,以适应在嵌入式设备上运行。
1 主流目标检测网络介绍
当前的目标检测任务主要基于卷积神经网络CNN,卷积神经网络被证明能够很好地提取图像的特征,目标检测算法也主要分为一阶段和二阶段目标检测器两种。一阶段目标检测器直接在图中找出要检测的目标的定位和类别,如YOLO 系列、RetinaNet、SSD 等。二阶段目标检测器的第一阶段先选出候选框,第二阶段进行分类,识别候选框中的目标类别,如RCNN、SPPNet、Faster RCNN 等。一阶段目标检测器将图片直接网格化,物体中心所在的网格负责对该物体进行检测,因此检测速度快。二阶段目标检测器需要在图片上进行搜索,然后再进行分类和回归,检测精度高,不容易出现漏检,但检测速度不及一阶段的目标检测器,同时还面临着正负样本失衡的问题。一般在算法的选择上,速度仍然是个硬指标,一阶段目标检测器在添加FPN、注意力等机制的改进下,其检测精度也能与二阶段检测器相媲美,同时一阶段目标检测器的模型通常更小,适于嵌入式硬件环境中使用。
1.1 YOLOv5的网络结构
一个一阶段的目标检测网络由三个组件构成,如图1所示:backbone、neck和head,backbone 是一个卷积神经网络,对输入的图片提取特征;neck 通常使用SSD 或者FPN 等方法对特征图进行混合或者组合,形成一些更为复杂的特征;head 用于对图像特征进行预测,生成边界框并预测类别。

图1 YOLOv5网络结构
YOLOv5 中 的backbone 主 要 包 含Focus、CBL、C3 和SPP 等层。Focus 是将图片先切片再按照通道维度进行拼接,最后通过卷积运算,将图片的长和宽均变为原来的一半,通道数变为原来的4倍;CBL操作其实由三个操作组合而成:Conv、BN 和SiLU 激活函数;C3 层包含了若干个残差结构,解决网络梯度信息重复的问题,既减少了参数量又加强了网络的特征融合能力;SPP是一个空间金字塔池化操作,输出特征图具备满足特定数目的通道,避免了RCNN对候选框进行裁剪和缩放带来的信息丢失和扭曲。YOLOv5 的neck 与YOLOv4类似,采用了FPN+PAN 的结构,将高层特征通过上采样与低层特征相融合,既保留了高分辨率下具有较高空间信息的特征又保留了低分辨率下具有丰富语义信息的特征。YOLOv5的检测层提供了两种优化方式:Adam 和SGD,默认使用Adam 优化。YOLOv5 定义的损失包含三个部分,分别是CIoU 损失、交叉熵损失和分类损失,它们之和作为反向传播的损失。
数据增强方法同YOLOv4 一样,采用了Mosaic方法,将多张图像进行随机缩放、裁剪、排列之后进行拼接,丰富了检测目标的背景,以便网络能从一张增强后的图像中学习到更多的特征。
YOLOv5 在公开数据集上有着一流的表现,模型的特征提取和预测能力都得到了认可,但其最小的模型文件都是十几兆级别的大小,参数量依然很大,难以直接在嵌入式设备上运行,因此,需要对其进行轻量化改进。
2 改进算法
本文使用ShuffleNetV2构建YOLOV5s 的主干网络,替换原有的DarkNet53网络,同时减少原YOLOv5 中检测头的通道数量、减少参数量、加快检测速度;并在主干网的最后一层添加SA注意力机制,将SA 机制中通道注意力的全局平均池化改为最大池化,以便更好地保留最明显的目标特征。
2.1 使用ShuffleNetV2网络构建主干网
ShuffleNetV2 降低了深度网络的计算量。作者通过大量实验和论证,提出了影响高效网络架构的4个发现,分别是“同等网络深度减少内存访问代价”、“过量使用组卷积会增加内存访问代价”、“网络碎片化会降低并行度”、“元素级操作的开销不可忽视”,并根据这4 个发现提出了ShuffleNetV2 网络,其主要有三个亮点。一是使用channel shuffle:具体做法是先将输入特征图在通道维度分成两个分支,将两个分支分别进行卷积运算,之后再做拼接,输出通道数与输入通道数相同,最后进行channel shuffle,使各分支间的信息得以交流。这样做既可以降低分组卷积的运算量,又避免了单纯使用可以降低分组带来的各组只学习到组内特征的局限;二是将shuffleNetV1中1*1 的组卷积改为普通卷积,因为之前的channel split 就相当于做了分组,并且减少使用组卷积也降低了计算量;三是将一个分支上的普通卷积改为深度可分离卷积,大幅减少计算量。
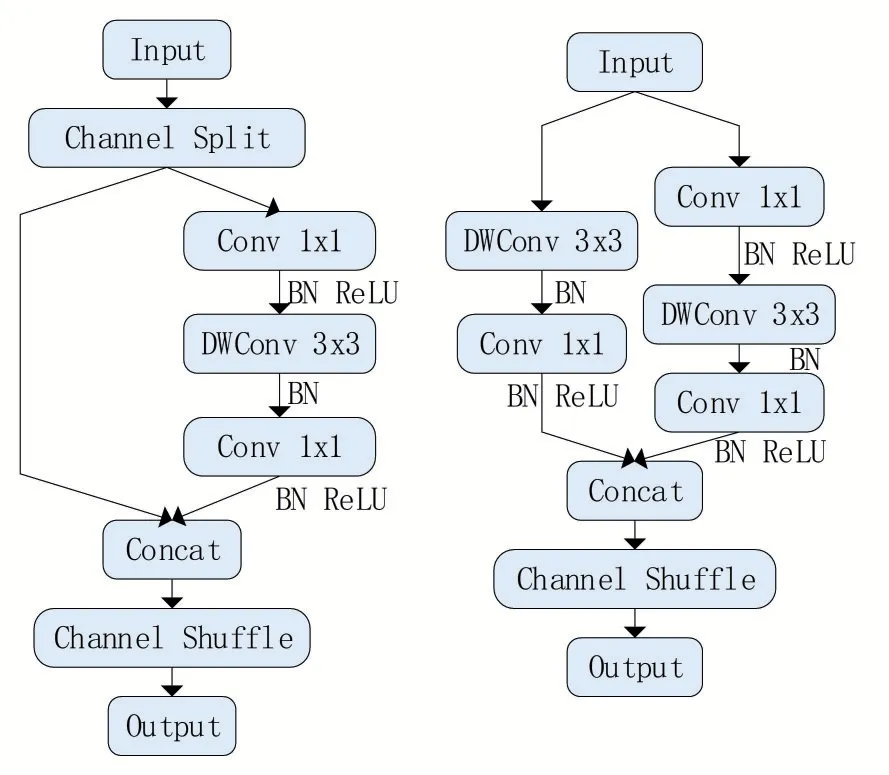
图2 ShuffleNetV2的stage模块
深度可分离卷积,如图3 所示,最早在Xception和MobileNet中开始使用,它将普通卷积分为一个深度可分离卷积和一个1*1的点卷积,对于一个输入通道数为,输出通道数为,特征图大小为D,卷积核大小为D的标准卷积,计算开销为:

图3 深度可分离卷积
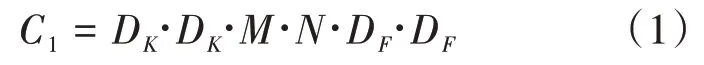
标准卷积操作具有基于卷积核过滤特征并组合特征以产生新表示的效果,深度可分离卷积将过滤和组合操作分别由一个深度卷积和点卷积完成,深度卷积对每个输入通道使用单个过滤器,跟着一个点卷积,使用一个1*1 卷积构建深度层输出的线性组合,在每一层后面都使用了BN 和ReLU 激活。对每个通道都使用单个过滤器的深度卷积可以写做:

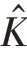

深度卷积过滤了通道,后续再跟一个1*1卷积将深度卷积的输出线性组合,从而生成新的特征,加上该1*1卷积之后,深度可分离卷积的计算开销为:
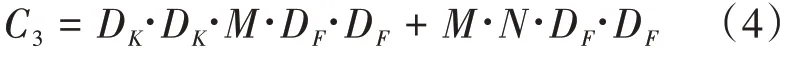
由此减少计算量:
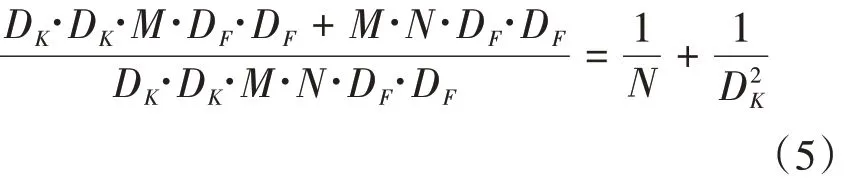
本文使用ShuffleNetV2 来构建主干网络,一方面其使用的深度可分离卷积相较于普通卷积的参数量减少,同时其网络的层数也少于YOLOv5 原网络使用的Darknet53,这样减少的参数量就很可观,模型大小也被大幅压缩了。
原YOLOv5的检测头中输出通道数量分别为256、512 和1024,考虑到试管类别少、特征简单,原网络的检测头输出通道数量有着大量冗余特征,于是减少通道数量。经过实验测试,三个检测头都输出256个通道时,能在大幅减少参数量的同时起到较好的检测效果。
2.2 添加混合注意力机制
注意力机制可以理解为对输入的不同区域赋予不同的权重,进而有侧重地进行特征选择或者区域选择,同时减少计算量。Hu 等提出了通道注意力机制,将输入映射之后通过一个Squeeze 操作,该操作跨空间维度聚合特征图来生成一个通道描述符,再将该描述符通过一个Excitation 操作,用自门控机制产生每个通道调制权重的集合,最后将这些权重应用到映射得到的特征图上生成SE 模块的输出。Woo 等将通道注意力串联起来,与ResNet 结构组合后很好地提高了SE 的性能。其空间注意力模块是将输入特征图同时通过平均池化和最大池化两个操作,将两个结果再通过一个带隐含层的多层感知机,生成通道注意力图。其空间注意力模块沿通道轴施加平均池化和最大池化操作,并将结果拼接起来,再将这个拼接的特征图通过一个卷积层,得到空间注意力图。


然后,再通过一个全连接层强化表达,最后使用sigmoid 激化:

其中,∈R,用来表示尺度缩放和平移的两个参数。
空间注意力模块使用GN(group norm)来获得空间统计数据,再通过一个全连接层来强化表达,最后通过sigmoid 激活,得到空间注意力图:
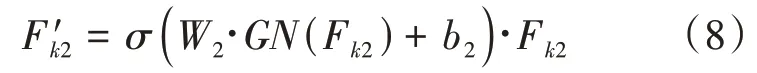
将F′与F′做拼接,得到的注意力图的通道数与原子特征通道数相同。
对所有的子特征都进行上述操作后,将所有结果聚合,再做channel shuffle,具体做法是先对特征图做分组卷积得到多个子特征图,但是这些子特征图可能各自表征了局部通道的信息,为了获得更具全局性的信息,将多个子特征图的特征沿着通道维度进行组合,使得每个组都包含其他组的特征信息,让组间信息沿着通道维度充分交流,然后再通过一个分组卷积,从各组中提取特征,得到最终的注意力图。改进后的模型如图4 所示。其中,SA 模块如图5所示。
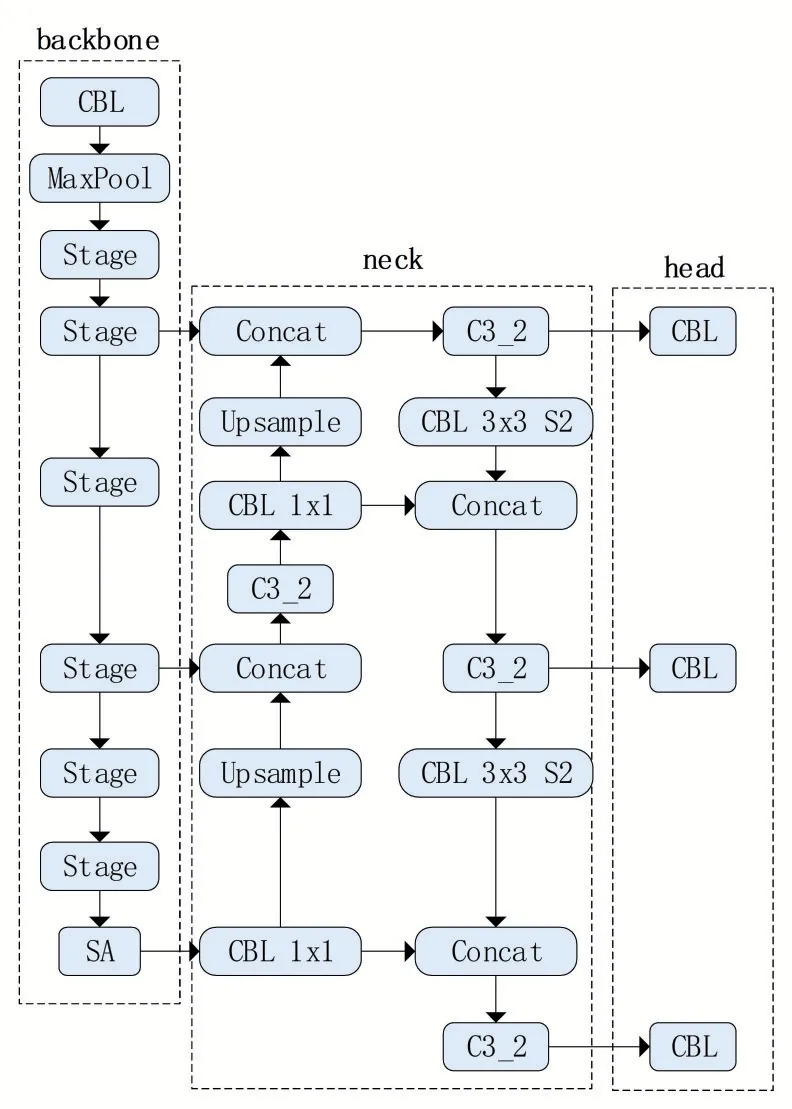
图4 改进后的网络结构

图5 混合注意力机制
3 实验结果与分析
3.1 实验平台
训练所用硬件平台配置为Intel(R)Core(TM)i5-6500 CPU @3.2 GHz,Nvidia GeForce GTX 1080Ti 11GB GPU,8 G 内存的服务器,采用Ubuntu 20.04 操作系统,CUDA11.4,Python 3.7。
3.2 实验数据集
本文使用的是自建数据集,包含3 类目标:“长试管”、“短试管”和“盖帽”,总共11534张图片,为了增强学习到的模型的泛化能力,采用不同光照、试管架、拍摄距离、背景和角度,每次对多根试管进行拍摄,得到数据集,示例见图6。

图6 自建数据集
图像大小为547×364,送入网络后会先调整大小为640×640再进行训练。
3.3 评价指标
本文采用目标检测模型常用的评价指标:召回率(Recall)、(mean average precision)、模型大小以及检测速度。
召回率等于网络正确识别为正例的样本个数占总正例样本个数的比例。为各类别的平均值,其值等于(precision-recall)曲线下的面积,其中为,为,计算如下:
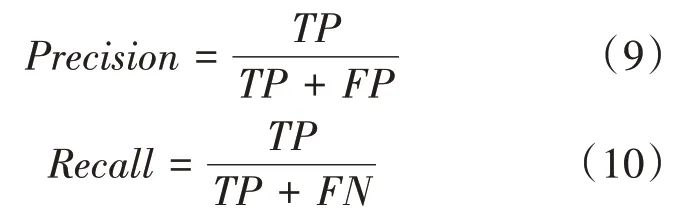

检测速度定义为每秒处理图像的帧数(frame per second,FPS)。
3.4 模型训练
训练轮次为200,批大小为8,采用YOLOv5s官方的预训练权重,将11534张图片按照8∶1∶1的比例进行随机划分,分别生成训练集、验证集和测试集。因为通过前期训练发现loss收敛很快,所以统一 采用epoch 为100,batch-size 为8,图片大小固定为640×640,线程数为8。
3.5 结果分析
将改进后的网络与原始YOLOv5s 网络以及YOLOv4 网络进行对比,检测结果如图7 所示。统计结果见表1。

表1 对比实验结果

图7 各模型检测结果
可以看出,在YOLOv5 网络中添加了SA 注意力机制之后,在增加一定参数量的情况下,模型的召回率有了0.8%的提高,而、和模型大小几乎没有变化;若单独使用ShuffleNet来构建YOLOv5s的主干网,可以显著降低参数量和模型大小,有了67.6%的提高,在召回率、则没有明显下降,说明对于试管检测任务来说,轻量级的ShuffleNetV2 的特征提取能力已经足够;若将ShuffleNetV2 作为主干网再添加SA 注意力机制,则在原YOLOv5 网络上有了89.9%的提高,有1.9%的提高,参数量只有原来的6.2%,模型大小只有原来的7.6%,在、、参数量和模型大小四个指标上达到最优,代价只是召回率较原YOLOv5s网络有1.6%的下降。说明对YOLOv5 网络的轻量化改进是成功的。
4 结语
本文针对试管检测任务,对YOLOv5网络进行轻量化改进:使用ShuffleNetV2 构建YOLOv5的主干网,减少检测头的通道数,并添加混合注意力机制。在自建数据集上实验证明,该改进在少量精度损失下,大大减少了模型大小,加快了检测速度。该改进网络在模型大小、检测速度和精度上取得了较好的平衡,利于在嵌入式设备上运行。
