基于SSD模型的PCB外观缺陷检测
2022-06-16李俊
李 俊
(安徽理工大学电气与信息工程学院,淮南 232000)
0 引言
自集成电路被应用于生产商业产品以来,工业生产过程对其每一步的生产和检测不断地进行更新迭代,其中对生产过程中印制电路板(Printed Circuit Board,PCB)的外观缺陷检测尤为重要,它关系着产品最后的品质。所以在PCB 板的工业生产的每一个环节都要进行缺陷检测,确保在贴片之前,贴片区域无异物、破损,进入回焊炉之前,元器件都完好等等,因为只要其中一个环节出了错,这个PCB 板就报废了,这对企业来说无疑是重大损失。现在PCB 板集成度高,成本更贵。目前中国大陆的PCB 产值已占全球50%以上,随着电子产品的不断更新换代,3C 产品对PCB 的需求逐渐加大,而在3C 产品中手机的更新换代最为频繁,销售量也是最大的。所以,针对手机部件从内到外的检测贯穿手机生产的每个环节,其中最为重要的是对手机主板生产过程中各种缺陷的检测。本文主要针对手机主板在生产过程中产生的缺陷进行检测,以提高生产效率。
1 研究背景
PCB 的功能是提供完成第一层级构装的元器件与其它必须的电子电路零件结合的基地,以组成一个具有特定功能的模组或者产品。所以PCB 在整个电子产品中,扮演着整合连结其它所有功能的角色,因此当电子产品功能故障时,最先被考虑的往往就是PCB。所以针对PCB 的检测一直以来是人们热门研究的课题。改革开放以来,我国工业化生产速度也大幅度加快,其中印制板是电子信息产业的基础,已成为电子信息的支柱产业。
然而,手机PCB 板生产的检测还存在短板,拖累生产效率。图1 为手机主板PCB 工业生产流程图,其中AOI部分为视觉检测部分,传统方式为人工检测、电气检测和自动光学设备检测。目前大多数工业流水线基本都是采用人工配合机器进行生产检测,太依赖于人的精神状况,易使人视觉疲劳,而产生漏检。电气检测投资成本大,不适于小批量生产,且电气检测设备安装调试时间长,不满足手机迭代频繁的需求。虽然自动光学检测设备,可以解决人工检测的一些弊端,但它严重依赖图像处理算法,如果图像处理算法效果不佳,会产生大量误判,且可移植性不强,开发难度大。

图1 手机主板生产流程图
近年来随着GPU 算力的增加,处理图像的速度大幅度提高,深度学习在图像领域发展迅速。为了满足工业生产对PCB 缺陷检测的需求,本文将深度学习的槪念引入PCB 板缺陷检测中。其中工业生产主要检测手机主板在生产流程中贴片区域是否存在飞件、脏污、元器件是否破损、异物、划痕等影响PCB 板电气特性的现象,以及外观的一些缺陷。如图2 所示,其中(a)为飞件,(b)为连接器破损,(c)为异物。通过这种技术,不仅可以有效避免人工检测中易疲劳,主观性强和效率低下的缺点,还可以实现24 h全天候的检测。

图2 缺陷类型
2 机器视觉与目标检测算法
机器视觉(machine vision)是人工智能的一个分支,是通过相机拍取的图像联合计算机代替人眼和大脑对目标进行定位、识别、跟踪、测量等一系列任务,使处理后的信息更有利于人和机器的判断处理。工业相机主要有CMOS和CCD 两种,机器视觉系统将相机拍摄到的图像输入给图像处理系统,得到拍摄对象的形态信息,根据像素分布和亮度、颜色等信息,转变成数字化信号;图像系统对这些信号进行各种运算来抽取目标的特征,进而根据判别的结果来控制现场的设备动作。机器视觉的目标检测任务为计算机视觉领域中最基础的任务之一,但由于图像质量,光照,相机分辨率的不同导致目标检测也成为最具挑战性的任务。
目标检测算法主要有图像特征提取、候选区域生成与候选区域分类三个步骤。视觉检测技术分为传统技术与深度学习方法,传统算法基于人工设计的特征算子来提取图像,这些算子普遍基于底层视觉特征来设计,因此很难获取复杂图像的语义信息,严重影响了算法的泛化性。而且由于背景相似等原因,无法检测出目标缺陷的位置。当数据量越来越大的时候,传统算法的劣势就越发明显。因此引入深度学习模型引入显得尤为重要。
基于深度的目标检测算法主要分为两个流派:①以R-CNN 系列为代表的两阶段算法;②以YOLO,SSD为代表的一阶段算法。具体来说,两阶段算法是先在图像上生成候选区域,然后对每一个候选区域依次进行分类与回归。一阶段算法是直接在整张图像上完成所有目标的定位和分类,直接回归,略去了生成候选区域这一操作。本文采用的目标检测算法为一阶段检测算法中的代表算法SSD。
3 SSD算法介绍
SSD(single shot multibox detector)是2016 年由Liu 等人提出的一种单阶段目标检测算法,其主要思路是利用卷积网络提取特征后,均匀地在图片的不同位置进行密集抽样,抽样时采用不同尺度和长宽比,目标的分类和预测框的回归同时进行,整个过程只需要一步,所以其优势是速度快。SSD 网络以VGG-16 为主干网络,并将VGG16的两个全连接层转化为卷积层,使其成为一个全卷积网络(FCN),网络结构如图3所示。
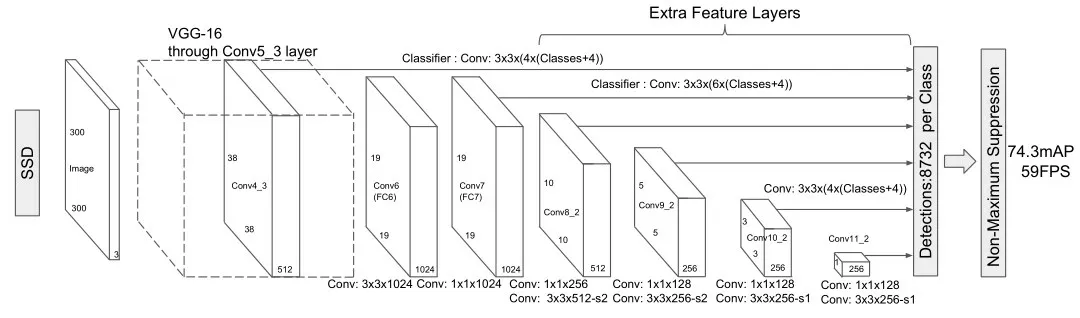
图3 SSD网络结构
主干网络作用到conv5_3 的输出结果,作为接下来卷积层的输入。采用多尺度Feature Map的预测,在预测的时候针对6个不同的尺度进行分别预测,这6个尺度的结果,分别作为后续检测层的输入,6 个连线代表6 个feature map,其中从19*19 到10*10 通过下采样的操作来完成。下采样时会采用padding 来进行补充,最后通过NMS(non maximum suppression)对检测结果进行合并和筛选。对每一层进行Default bounding boxes 的提取,每一个Default bounding boxes 都会针对每个类别的分数的预测以及相应的偏量值。
如何平衡网络模型的大小和计算资源之间的关系,这是设计网络需要考虑的地方。因此对VGGNet 而言,除了num_output 数量庞大以外,主要采用多卷积进行堆叠的方式来构造网络结构,为了加快网络inference 的时间,本文在保证检测精度的同时采用减少网络参数、去除一些网络层的做法达到检测目的。
4 实验方法
实验基于Caffe 深度学习框架进行,设备为工厂工控机,其配置为CPU Core i7-9750H,显卡NVIDIA 3080 10 G 显存,物理内存为32 G,使用编程语言版本为Python 3.8.2,操作系统为Ubuntu18.04。
本文的数据收集自工业生产过程中AOI 实时拍摄的照片,在AOI 设备运行过程中机器视觉系统发挥图像处理与检测的作用,根据运动控制的传感信号飞拍每一帧画面,将在每一个点位拍摄的图片拼接成一副完整的图片。根据客户出具的检测区域需求,先通过模板匹配定位PCB 上固定不变的两个点,通过矩形框画出需要检测的区域,通过位置仿射完成整个区域位置的标出,通过Halcon 对每个区域进行裁剪,将宽度和长度最大的尺度作为这个待检缺陷的尺寸,同样使用Halcon 将同一个待检缺陷类别区域扩张为统一大小。将裁剪得到的小图统一导入到精灵标注助手中,完成缺陷标注,数据集划分。由于待检区域众多,缺陷类别复杂,为了简化检测任务,每个AOI 由两个及以上缺陷检测模型检测,裁剪的目的也是为了将检测任务简化为二分类问题。接下来针对飞件异物模型进行训练。
实验将含有飞件的NG图片和无缺陷的OK图片共2025张,按照训练集和测试集的比例为7∶3划分,总共进行600 次迭代。实验结果如图4 和表1所示。
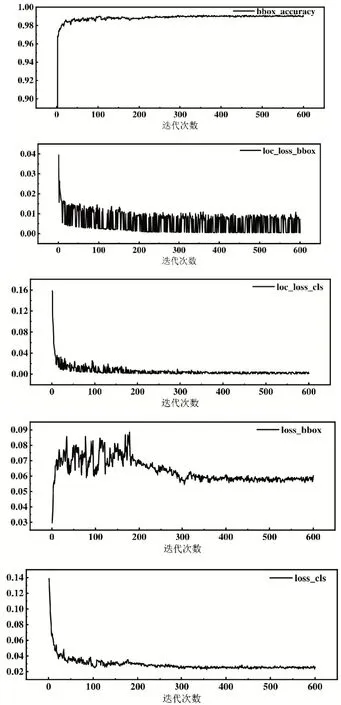
图4 实验结果

表1 实验结报表
bbox_accuracy 标注框类别,值越高说明学习效率越好;loc_loss_bbox 定位框位置回归的loss,值越低学习效果越好;loc_loss_cls 定位框类别和位置回归的loss,值越低学习效果越好;loss_bbox 实际类别分类和位置二次修正的loss,值越低学习效果越好;loss_cls 实际类别数分类和位置二次修正的loss,值越低学习效果越好。
5 结语
虽然降低网络参数和减少网络层数可以加快网络推理时间,满足客户对于CT 与检测的要求,但同时带来了由于深层次信息的丢失和小目标检测效果不好所导致的漏检,过检的问题,比如现场生产产生的毛丝等这些小尺度缺陷目标,检测效果不好。因此,在后期优化网络的时候可以考虑从以下方面进行改进:①数据打包的时候可以考虑多加入一些小样本信息;②训练样本规模尽可能增大,可以尝试获取合并多个不同数据集;③采用ResNet 网络和FPN 等特征的主干网络;④采用更好的loss进行训练。
