基于MFCC 均值特征的电台语言类节目相似度比对算法研究
2022-06-15聂晨淅
聂晨淅
(中央广播电视总台,北京 100866)
0 引言
对于广播电台来说,广播节目的安全播出是十分重要的。播出监测系统随着技术的不断发展,逐渐智能化、自动化。现在的播出系统往往是由庞大的播出链路组成的,其中一些设备可能因为故障原因造成播出音频信号的内容不一致,混入杂音。另外,黑客等不法分子通过技术手段非法入侵播出系统,播出有害信息,特别是广播电台会播出大量的外语节目或者少数民族语言类节目,播控人员在非母语环境中无法有效识别这些错误和非法有害信息,特别是语言类节目,会造成恶劣影响。为了解决这样的问题,电台技术人员需要对播出的音频各个节点进行智能监控对比,及时发现异常并报警提醒。
1 音频对比
广播音频总体可以分为音乐音频和语言音频两大类。语言音频占比非常大,重大直播转播节目通常使用此类音频,因此防止此类音频被恶意混入和篡改是检测对比这类音频的关键,也是确保播出安全的重中之重,因此本文讨论的重点集中在语言音频。一般来说,现代播出电台的播出系统主要分为主、备双播出链路结构,可以对两个链路上的关键节点进行音频信号比对来发现问题,此外,也可以对播出通路的末级信号和接收的开路信号相比较,来发现原始信号和接收信号的不一致问题。两种方式的对比如图1 所示。

图1 主备通路和末级开路信号对比
1.1 音频的特点
声音的本质是一种在介质中振动的带有能量的波。而音频是个专业术语,音频一词用作一般性描述音频范围内与声音有关的设备及其作用,一般可以理解为储存在计算机里的声音。它有很多具体的特征,比如频率、幅度、节拍等。
在广播节目中,在播出源音频信号已知或者是主备其中一路能认定正常的情况下,音频对比可以不考虑其高级语义和情感,对音频信号的一些物理特征进行提取和判定即可。人们对音频信号对比技术已经进行了相当多的研究,目前常用的音频对比技术多数是以音频的某一物理特征作为参数进行对比。
1.2 常用的对比方法
通常,大多数音频对比方法将两段对比的音频信号放在时间域上,利用波形等特征,通过传统的图形技术识别技术进行对比[1],或者利用一些时域物理特征如短时平均能量、包络特征及过零率[2]等。在频域方面,可以利用子带能量比、频谱质心[3]、带宽特性、信息熵、线性预测系数和梅尔频率倒谱系数(Mel-scale Frequency Cepstral Coefficients,MFCC)[4],提取其特征参数,然后计算其特征参数之间的相似度来进行对比。
2 音频特征提取
2.1 梅尔倒谱系数
采样的广播节目音频不仅包括一些时域和频域的特征,同时也包含大量的冗余信息。对于语音音频信号来说,这些冗余信息可能是人耳听觉范围之外的声音以及被掩蔽掉的音频信号。特征提取的本质就是对这些大量冗余信息加以过滤。
根据声学知识可知[5],人类语音的大部分信息包含在低频分量中。人们听到的声音高低与该声音频率的对数近似呈线性正比关系。基于以上特征,本文选用一种基于梅尔频率倒谱系数(MFCC)的方法对语音信号进行特征提取。梅尔倒谱系数与频率的关系可用下式近似表示:
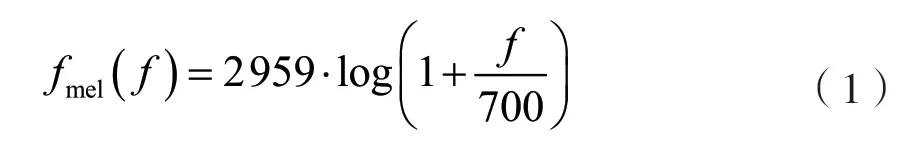
式中:fmel指的是感知频率,f代表实际频率。
2.2 提取流程
对音频的帧信号进行频域的特征提取,经过一系列操作后,这些特征值形成一系列的倒谱系数,称为MFCC 系数。具体的提取流程是:先对原始音频信号进行预加重、分帧、加窗以及快速离散傅里叶变换(Fast Fourier Transform,FFT),再计算能量谱,将得到的能量谱通过三角带通滤波器,滤波输出的结果,利用梅尔域与线性频率的关系式转为对数形式,最后进行离散余弦变换(Discrete Cosine Transform,DCT),得到MFCC 系数。整个提取流程如图2 所示。

图2 MFCC 提取流程
2.3 音频预处理
语音信号具有短时平稳性,特征提取计算需要在短时长的音频信号上采样。特征提取之前,要对音频预处理。预处理一般分为预加重、分帧处理及加窗操作三步。
预加重的目的是提高音频信号中的高频分量,使高低频分量之间的能量落差减小,还增加了部分语音能量,在一定程度上抑制随机噪声。实质是将音频信号通过一个高通滤波器。滤波器的传递函数H(z)为:

式中:μ接近于1。
分帧和加窗操作就是利用音频信号的短时平稳性,将音频分割成帧,作为特征提取的输入。总体来说,就是给音频信号乘以一个窗函数,一般选用Hamming 窗,因为它的通带更宽,通带外衰减更为迅速。同时,加窗只是对窗内的信号进行提取,以便后续操作。
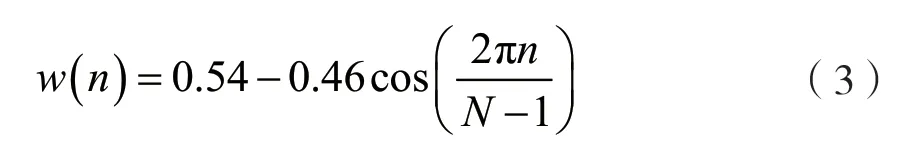
式中:N为窗长。
预处理完成后,对每一帧信号进行FFT 变换,将时域信号转换为频域信号进行后续频率分析。假设分帧加窗后的音频信号函数为x(n),快速离散傅里叶变换后帧频谱x(k)为:

式中:k代表频域中FFT 的第k条谱线,N为谱线数。丢弃相位谱保留信号的能量谱E(k),通过计算可得E(k)=|x(k)|2。
2.4 梅尔滤波器
滤波器是基于人耳的特性幵发出来的,是一种三角型滤波器组。三角形滤波本质是三角形的函数,具有上下限和中心频率。梅尔滤波器组的主要作用就是突出频谱内语音的波峰,并消除谐波,如图3 所示。梅尔滤波器组是一个含有M个三角带通滤波器的集合,其中每一个滤波器组对应着不同的中心频率f(m),这里M一般取24。

图3 梅尔滤波器组
用三角滤波器的中心频率f(m)来计算三角滤波器的频率响应Hm(k),梅尔滤波器的设计就是f(m)之间的间隔随着m的增大而增大,保证其面积不变。据此可以算出频率响应公式如下:

2.5 求MFCC 系数
音频帧信号梅尔滤波后,对滤波器组的输出进行对数运算来模拟人耳感受,求卷积后得对数能量S(m)。
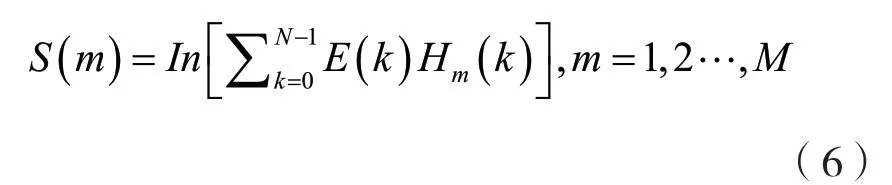
式中:Hm(k)为第m个滤波器第k条谱线对应的幅度。
为了使得各维特征向量值之间相互独立,需要进行离散余弦变换DCT,这样能较大程度地去除语音特征参数之间的相关性。离散余弦变换可以减少特征的维数,在实际的语音识别过程中,特征参数不取所有参数,一般取前12 个最有效的特征聚集。

式中:C(l)为第l阶MFCC,l为MFCC 的阶数。
上述12 个梅尔倒谱系数构成了1 个音频帧的12 维特征参数。实际应用中会引入其一阶差分和二阶差分,与MFCC 系数共同构成音频特征参数矩阵。
2.6 一、二阶差分系数的提取
通常由上述步骤求得的MFCC 倒谱参数只反映了被测音频片段的静态特性,而其动态特性可以用这些静态特征的差分谱来描述。为了提高音频对比系统的识别准确率,通过大量实验得出结论:将动、静态特征参数结合起来进行判定比较可靠。差分参数的计算可以采用下面的公式:
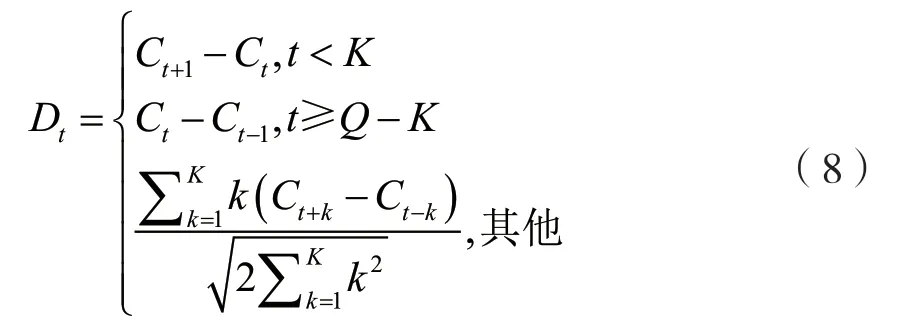
式中:Dt为第t个一阶差分,Ct为第t个倒谱系数,Q为倒谱系数的阶数,K是一阶导数的时间差,可取1 或2。式(8)的运算的结果再代入即可得到二阶差分的参数。MFCC 和其特征均值的系数分布如图4 所示。
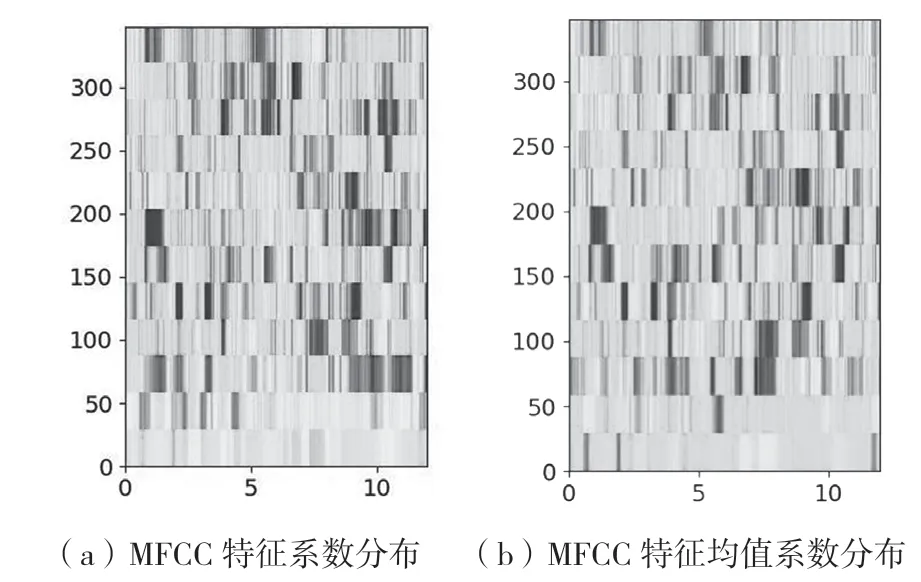
图4 MFCC 和其特征均值的系数图
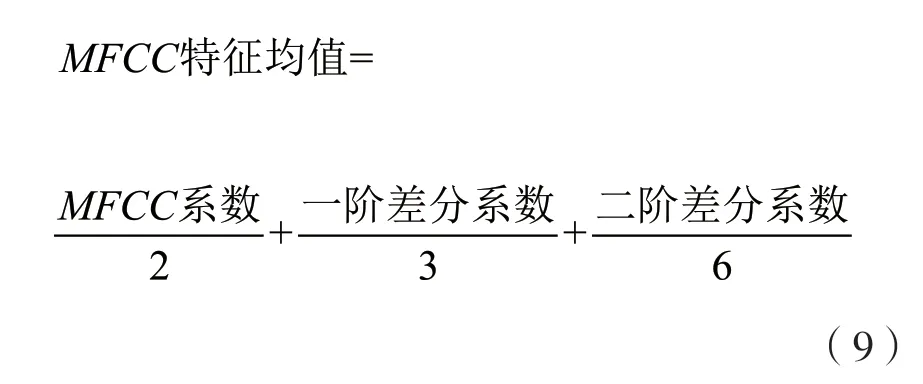
本文在实际应用中通常不对所得的MFCC 系数做统一的平均化处理,主要是因为通过大量的实验数据分析发现,不同的MFCC 特征值所表现的特性不同。考虑到各阶系数的权重并综合实验效果,本文将计算得到的各帧MFCC 系数及一阶差分序列和二阶差分序列系数,通过以下公式运算:
3 音频相似度判定
3.1 计算特征距离
上述12 个MFCC 特征均值系数构成了12 维的音频特征参数矩阵。本文选取主路信号和末级信号为样本音频,备路和开路信号为被测音频。计算出两者的欧氏距离,根据平均欧氏距离值来判定样本音频与被测音频之间的相似度。该距离越小,表示相似度越高;反之,相似度越低。两段音频信号特征矩阵的欧式距离Disti(d)为:
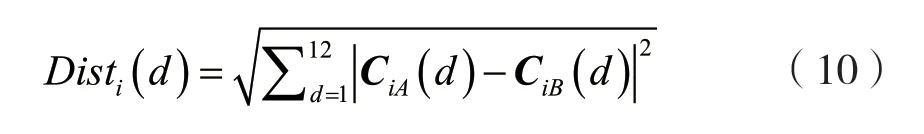
式中:CiA(d)为样本音频A的特征矩阵,CiB(d)为被测音频B的特征矩阵,i为取得音频帧数。将样本音频帧与被测音频帧的两个12 维均值倒谱系数矩阵的每一维特征向量,分别计算其间的欧氏距离,再根据计算出的欧氏距离值计算整个矩阵的平均欧氏距离,根据平均欧氏距离值AV(i)来判定样本音频与被测音频帧之间的相似度。
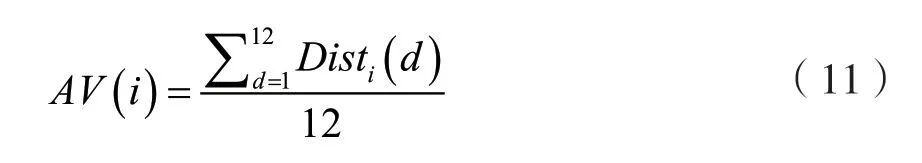
通常情况下,对所得相似度求倒数,将结果控制在[0,1]。最后以实际欧式距离计算两个矩阵间相似度Wi的公式为:

3.2 实验结果
本文实验数据的样本音频和被测音频取自中央广播电视总台广播节目中国之声的《新闻和报纸摘要》、经济之声《财经夜读》、大湾区之声《韵味岭南》以及维语广播《知书达理》这4 档节目的主备路、主控末级及卫星信号。其中,经济之声《财经夜读》和中国之声的《新闻和报纸摘要》为普通话播出,大湾区之声《韵味岭南》和维语广播《知书达理》为方言播出;《财经夜读》和《韵味岭南》为含有背景乐的语言类节目,《新闻和报纸摘要》和《知书达理》为纯语音播出。将以上音频截取5 s 时长,保存为“.wav”文件,以Python 为实现平台,同时以单纯波形图对比为参照实验,测试在不同采样率得到的实验数据如表1 所示,进行对比。

表1 结果对照表
实验采用4 个典型广播节目的主备路提取信号对比,当样本组合采用测试组的相似度W值大小来判定两者的相似度,W值越接近1,则认为两个音频越相似。实验选取的参照组为传统的波形图形比对技术。通过实验数据发现,在采样率相同的情况下,纯语言类节目使用传统的波形波对技术,对比结果与MFCC 均值算法几乎无异;而在含有背景音乐的语言类节目中,MFCC 均值算法的对比效果要优于传统算法。另外,采样频率和采样位数的提升,对于相似率比较结果的影响有限,但同时增加了系统的运算量。
4 结语
应用音频比对技术后,广播播控系统可以对播出节目的内容做到全面的监控,保障广播播出内容的安全性。本文实现了基于MFCC 均值特征的音频比对技术方案,能够有效提高音频比对效率,特别是对含有背景音乐的语言类节目。该方法特别适用于语言类节目的音频对比,具有较高的准确性。
